- lambda是包着一个函数的对象
- lambda传参数和返回值
- lambda 的语法糖
- lambda局部变量使用机制
- lambda底层实现
- JDK 数据结构中使用 lambda
- Collection: stream()方法
- Tips: 上下限通配查看方法
- list: forEach()方法:void forEach(Consumer<? super E> action)
- list: removeIf()方法 boolean removeIf(Predicate<? super E> filter)
- list: replaceAll()方法 void replaceAll(UnaryOperator
operator) - list: sort()方法 void sort(Comparator<? super E> c)
- map: forEach()方法 void forEach(BiConsumer<? super K,? super V> action)
- map: replaceAll()方法 replaceAll(BiFunction<? super K,? super V,? extends V> function)
- map: merge()方法 merge(K key, V value, BiFunction<? super V,? super V,? extends V> remappingFunction)
- map: compute() 方法 compute(K key, BiFunction<? super K,? super V,? extends V> remappingFunction)
- map: computeIfAbsent()方法 V computeIfAbsent(K key, Function<? super K,? extends V> mappingFunction)
- map: computeIfPresent()方法 V computeIfPresent(K key, BiFunction<? super K,? super V,? extends V> remappingFunction)
- 参考资料
tags: [Java 核心]
categories: [技术笔记]
lambda是包着一个函数的对象
lambda表达式非常简洁优雅。是把动态语言的特性嫁接到静态语言的一个典范。
在java中,我更加愿意认为lambda实际上是是包着一个函数的对象,我们在使用lambda表达式的时候,实际上定义了一个闭包的函数对象,这是lambda最大的意义所在。在过去,我们在函数之间传递一个函数,必须手动把它包装成类的对象,并用接口加以规范。现在,我们可以直接用lambda自动生成一个这样的对象。
如果你用过 Javascript/Python,你可以把刚刚定义的函数当做对象传给别的函数。现在,你用 lambda 也可以在 java 的里面传参时把函数用lambda形式“打包”传给别的函数,并且符合强类型的面向对象要求。
我们先用面向对象的方法理解 lambda 函数,他首先是一个对象,但是不需要我们手动new,他的类型是 一个接口
// 这是 Runnable 接口public interface Runnable {void run();}// 在以前,我们可能要这样创建一个 Runnable 对象(当然也可以用匿名内部类)class taskClass implements Runnable {@Overridepublic void run() {System.out.println("test");}}Runnable task = new taskClass();// 对象可以使用接口的方法task.run(); // 输出 test// 现在,有了 lambda,系统用了些黑魔法,自动实例化了类,并且给我们创建好了对象// 其实,这个task不是内部类而真的是一个私有的函数,是的,编译器就是可以为所欲为Runnable task = () -> {System.out.println("test");};// 你可以表面地理解成,系统把 小括号 和 大括号的内容,复制粘贴到上面去了
看到这里,你可能会问,系统依据什么来创建这个函数对象呢?如果一个接口里面有许多方法,我们的lambda表达式应该应用到(复制、粘贴到)哪个方法上面呢?lambda的输出类型怎么定义呢?
答案就是,这种接口,有且只能有一个抽象方法,系统会自动找到这一个方法(虽然这样看起来有些随意)作为创建这个函数对象的模板。
lambda传参数和返回值
和 Runnable 接口一样,JDK还给我们带来了几个比较常见的接口:如 Consumer 接口 和 Supplier 接口
// 这个接口的特点是,有一个参数,无返回值public interface Consumer<T> {void accept(T t);}// 用 lambda创建一个 consumer 对象Consumer<String> consumer = (String item) -> {System.out.println(item);};// 这个接口的特点是,无参数,有返回值public interface Supplier<T> {T get();}// 用 lambda 创建一个 supplier 对象Supplier<String> supplier = () -> {return "test";}
java.util.function 下有大量JDK8带来的接口
Predicate<T>— a boolean-valued property of an object | 输入T,返回 booleanConsumer<T>— an action to be performed on an object | 输入 T,返回voidFunction<T,R>— a function transforming a T to a R | 输入 T 返回 RSupplier<T>— provide an instance of a T (such as a factory) | 输入() 返回TUnaryOperator<T>— a function from T to T | 输入 T 返回 TBinaryOperator<T>— a function from (T, T) to T | 输入 (T,T) 返回 TIntSupplier等基础数值非泛型接口
我们在使用的时候,只用关心接口下面的唯一抽象方法的输入值和返回值即可,不用太关心名字
lambda 的语法糖
如果函数体只有一行,不需要大括号
如果函数的参数只有一个,不需要小括号
如果函数的参数可以由上下文推导,则不需要写参数类型
如果函数体只有一行,不用写 return
这四个比较好理解,比如,这样写是合法的:
Consumer<String> consumer = item -> System.out.println(item);Supplier<String> supplier = () -> "test";
- 还有我个人感觉做的比较随意的 双冒号 :: 语法糖,这种形式叫做方法引用(method references)
| 引用静态方法 | Integer::sum |
|---|---|
| 引用某个对象的方法 | list::add |
| 引用某个类的方法 | String::length |
| 引用构造方法 | HashMap::new |
比如,原来我们这么写
Consumer<String> consumer = item -> System.out.println(item);
现在用双冒号语法可以这么写,这样写也有好处,让你看起来这更像是传了一个方法进去
Consumer<String> consumer = System.out::println;
lambda局部变量使用机制
lambda中使用上下文定义的局部变量,必须是 final的,当然,如果你忘了加final,编译器会帮你自动加上。
当然,如果是类变量则没有这个限制
String x = "Hello "; // 如果下文有 lambda 使用了 x,这句等价于 final String x = "Hello "x = "test"; // 这句非法,无法通过编译Function<String,String> func1 = y -> y+x;System.out.println(func1.apply("luan.ma"));
lambda底层实现
Lambda表达式通过invokedynamic指令实现,书写Lambda表达式不会产生新的类。他在 class 文件中是一个私有函数
public class MainLambda {public static void main(String[] args) {new Thread(() -> System.out.println("Lambda Thread run()")).start();;}}
// javap -c -p MainLambda.classpublic class MainLambda {...public static void main(java.lang.String[]);Code:0: new #2 // class java/lang/Thread3: dup4: invokedynamic #3, 0 // InvokeDynamic #0:run:()Ljava/lang/Runnable; /*使用invokedynamic指令调用*/9: invokespecial #4 // Method java/lang/Thread."<init>":(Ljava/lang/Runnable;)V12: invokevirtual #5 // Method java/lang/Thread.start:()V15: returnprivate static void lambda$main$0(); /*Lambda表达式被封装成主类的私有方法*/Code:0: getstatic #6 // Field java/lang/System.out:Ljava/io/PrintStream;3: ldc #7 // String Lambda Thread run()5: invokevirtual #8 // Method java/io/PrintStream.println:(Ljava/lang/String;)V8: return}
所以,在使用层面,lambda中的 this 就是主类的 this,和主类的函数没有太大区别。而匿名内部类或者是内部类在使用中则要注意this的指向问题。
JDK 数据结构中使用 lambda
JDK中的数据结构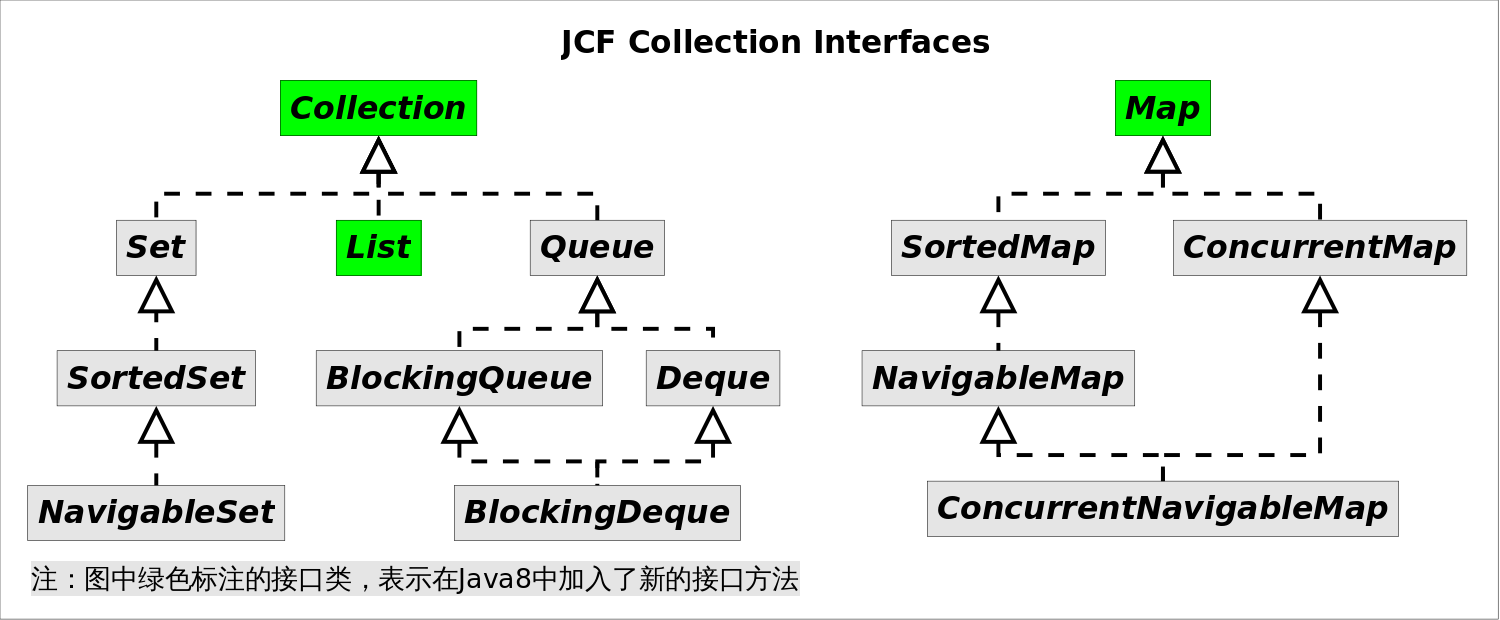
加入的 支持 lambda 的方法列表:
| 接口名 | Java8新加入的方法 |
|---|---|
| Collection | removeIf() spliterator() stream() parallelStream() forEach() |
| List | replaceAll() sort() |
| Map | getOrDefault() forEach() replaceAll() putIfAbsent() remove() replace() computeIfAbsent() computeIfPresent() compute() merge() |
Collection: stream()方法
这是最强大的支持lambda的方法,List所有lambda方法在 stream()中都可以完成,而且支持 set 和 queue
他还有一个可以自动多线程拆分、执行的兄弟 .parallelStream()
Tips: 上下限通配查看方法
看之前,我先说一下方法里面各种上下限通配的查看方法:<? extends T>用于方法返回,参数类型上界是T,因此子类不能随意传入,只读<? super T> 用于方法传入,参数的类型下界是 T,因此若传出只能是 Object 类型<T> 既要传入,又要返回? 既不能传入,也不能返回
list: forEach()方法:void forEach(Consumer<? super E> action)
作用是对容器中的每个元素执行action指定的动作,其中Consumer是个函数接口,里面只有一个待实现方法void accept(T t)
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));list.forEach( str -> {if(str.length()>3)System.out.println(str);});
遍历,并对每一项执行一个函数。forEach方法和原来的for()遍历,看起来更加简洁
list: removeIf()方法 boolean removeIf(Predicate<? super E> filter)
删除容器中所有满足filter指定条件的元素,其中Predicate是一个函数接口,里面只有一个待实现方法boolean test(T t)。传统,我们需要要迭代器来迭代删除数据,现在有了 removeIf 函数,我们可以传入一个 返回值 为 true 或者 false d lambda 表达式,如果 true,那么元素就会被删除
list.removeIf(str -> str.length()>3);
list: replaceAll()方法 void replaceAll(UnaryOperator operator)
对数据集合的每个数据执行一个方法。在之前,我们需要遍历,get出来,转换,再set回去,现在我们可以直接用 lambda 实现
list.replaceAll(str -> {if(str.length()>3)return str.toUpperCase();return str;});
list: sort()方法 void sort(Comparator<? super E> c)
排序方法,输入两个对象,返回一个int值,根据正负来确定排序位置
list.sort((str1, str2) -> str1.length()-str2.length());
map: forEach()方法 void forEach(BiConsumer<? super K,? super V> action)
作用是对Map中的每个映射执行action指定的操作,其中BiConsumer是一个函数接口,里面有一个待实现方法void accept(T t, U u)。
原来的方法非常繁琐,现在变得非常简单
map.forEach((k, v) -> System.out.println(k + "=" + v));
map: replaceAll()方法 replaceAll(BiFunction<? super K,? super V,? extends V> function)
作用是对Map中的每个映射执行function指定的操作,并用function的执行结果替换原来的value,其中BiFunction是一个函数接口,里面有一个待实现方法R apply(T t, U u)
map.replaceAll((k, v) -> v.toUpperCase());
map: merge()方法 merge(K key, V value, BiFunction<? super V,? super V,? extends V> remappingFunction)
如果
Map中key对应的映射不存在或者为null,则将value(不能是null)关联到key上;否则执行
remappingFunction,如果执行结果非null则用该结果跟key关联,否则在Map中删除key的映射.
传入的是key, value,以及一个备选方案:有两个值要如何处理
map.merge(key, newMsg, (v1, v2) -> v1+v2);
map: compute() 方法 compute(K key, BiFunction<? super K,? super V,? extends V> remappingFunction)
把remappingFunction的计算结果关联到key上,如果计算结果为null,则在Map中删除key的映射.
传入key, value由旧值的函数计算得到
要实现上述merge()方法中错误信息拼接的例子,使用compute()代码如下:
map.compute(key, (k,v) -> v==null ? newMsg : v.concat(newMsg));
map: computeIfAbsent()方法 V computeIfAbsent(K key, Function<? super K,? extends V> mappingFunction)
只有在当前Map中不存在key值的映射或映射值为null时,才调用mappingFunction,并在mappingFunction执行结果非null时,将结果跟key关联.
不存在才加,存在直接跳过
Function是一个函数接口,里面有一个待实现方法R apply(T t).
computeIfAbsent()常用来对Map的某个key值建立初始化映射.比如我们要实现一个多值映射,Map的定义可能是Map<K,Set<V>>,要向Map中放入新值,可通过如下代码实现:
Map<Integer, Set<String>> map = new HashMap<>();// Java7及以前的实现方式if(map.containsKey(1)){map.get(1).add("one");}else{Set<String> valueSet = new HashSet<String>();valueSet.add("one");map.put(1, valueSet);}// Java8的实现方式map.computeIfAbsent(1, v -> new HashSet<String>()).add("yi");
使用computeIfAbsent()将条件判断和添加操作合二为一,使代码更加简洁.
map: computeIfPresent()方法 V computeIfPresent(K key, BiFunction<? super K,? super V,? extends V> remappingFunction)
只有在当前Map中存在key值的映射且非null时,才调用remappingFunction,如果remappingFunction执行结果为null,则删除key的映射,否则使用该结果替换key原来的映射.
不存在直接跳过,存在才插进去
这个函数的功能跟如下代码是等效的:
// Java7及以前跟computeIfPresent()等效的代码
if (map.get(key) != null) {
V oldValue = map.get(key);
V newValue = remappingFunction.apply(key, oldValue);
if (newValue != null)
map.put(key, newValue);
else
map.remove(key);
return newValue;
}
return null;
参考资料

若有收获,就点个赞吧
0 人点赞
