前言
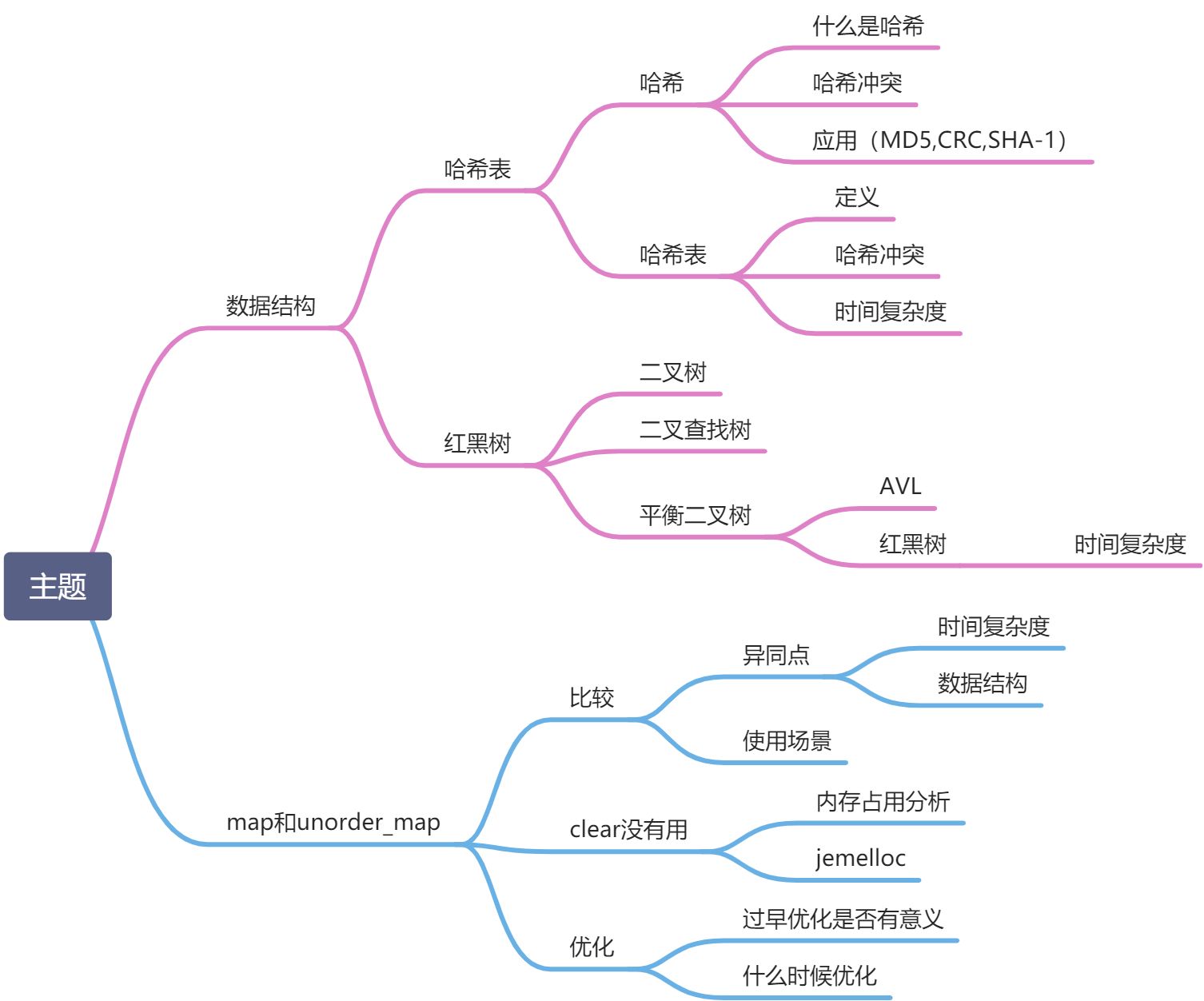
在实际的工作过程中,发现工作很多年的同事只知道std::map,并不知道unordered_map这个东西,更别提用上了,所以今天决定整理相关知识点,从底层数据结构分析,探寻map和unorder_map的异同点、适用场景及使用过程中可能存在的问题(unordered_map是boost的产物,boost可以看做是stl的扩展,实际使用过程中没必要太纠结)
上代码
#include <iostream>#include <string>#include <map>#include <utime.h>#include <ctime>#include<boost/unordered_map.hpp>using namespace std;#define MAX 1000000long get_time_ns(){struct timespec ts;clock_gettime(CLOCK_REALTIME,&ts);return ts.tv_sec*1000000000+ts.tv_nsec;}int main(void){std::map<std::string,std::string> order_map;std::map<std::string,std::string>::iterator order_map_it;boost::unordered_map<std::string,std::string> unorder_map;boost::unordered_map<std::string,std::string>::iterator unorder_map_it;long start,end;start = get_time_ns();for(int i=0;i<MAX;++i){order_map.insert(make_pair(std::string("key")+std::to_string((long long int)i),std::string("value")+std::to_string((long long int)i)));}end = get_time_ns();cout<<"order map insert cost time:"<<(end-start)<<"ns"<<endl;start = get_time_ns();for(int i=0;i<MAX;++i){unorder_map.insert(make_pair(std::string("key")+std::to_string((long long int)i),std::string("value")+std::to_string((long long int)i)));}end = get_time_ns();cout<<"unorder map insert cost time:"<<(end-start)<<"ns"<<endl;start = get_time_ns();for(int i=0;i<1;++i){order_map_it = order_map.find(std::string("key")+std::to_string((long long int)i));if(order_map_it == order_map.end()){cout<<"not find!"<<endl;}}end = get_time_ns();cout<<"order map find cost time:"<<(end-start)<<"ns"<<endl;start = get_time_ns();for(int i=0;i<1;++i){unorder_map_it = unorder_map.find(std::string("key")+std::to_string((long long int)i));if(unorder_map_it == unorder_map.end()){cout<<"not find!"<<endl;}}end = get_time_ns();cout<<"unorder map find cost time:"<<(end-start)<<"ns"<<endl;return 0;}
结果如下:
| 数据量级 | 插入时间(us) | 插找时间(us) | 消耗内存(kb) | |||
|---|---|---|---|---|---|---|
| map | unordered_map | map | unordered_map | map | unordered_map | |
| 10 | 26751 | 19199 | 745 | 679 | ||
| 100 | 144719 | 97420 | 1180 | 722 | ||
| 1000 | 882965 | 103495 | 2584 | 831 | ||
| 10000 | 10465007 | 11333225 | 5977 | 780 | ||
| 100000 | 113490955 | 125350013 | 3535 | 1007 | ||
| 1000000 | 1239087143 | 1864533322 | 4222 | 1008 | 112284 | 96920 |
| 10000000 | 103042120201 | 510355825285 | 6093 | 1672 |
基于同样量级的数据,为什么不同的两种map在插入和查找的时间上差异会这么大呢?
疑问:hash表的查找时间复杂度理论上的O(1),那这里为什么有明显的差别呢?答案是存在hash冲突
哈希
红黑树
map和unordered_map
异同点及使用场景
- 两种map都可存储基于map类型的数据结构,其中std::map是stl的产物,boost::unordered_map是boost产物(boost可以看做是stl的扩展)
- map是基于红黑树,unordered_map是基于hash表
- map的有序的,unordered_map是无序的
- map适用于范围查询,unordered_map适用于等值查询
clear没有用?

若有收获,就点个赞吧
0 人点赞
