The Adventures of OS
使用Rust的RISC-V操作系统 在Patreon上支持我! 操作系统博客 RSS订阅 Github EECS网站 这是用Rust编写RISC-V操作系统系列教程中的第10章。
文件系统
2020年5月4日。仅限PATREON
2020年5月11日。公开
视频和参考资料
我在大学里教过操作系统,所以我将在这里链接我在那门课程中关于virt I/O协议的笔记。这个协议多年来一直在变化,但QEMU实现的是传统的MMIO接口。
https://www.youtube.com/watch?v=OOyQOgHkVyI
上面的说明是针对一般的文件系统的,但它确实对Minix 3文件系统进行了更详细的说明。我们在这里构建的操作系统可能会做一些不同的事情。这主要是因为它是用Rust编写的—hahahahaha。
开箱即用的Rust
这个操作系统现在可以单独由 Rust 来编译了。我更新了 Chapter 0 中关于配置 Rust 的程序,以便在不需要工具链的情况下编译这个操作系统!
概述
存储是操作系统的一个重要部分。当我们运行一个shell,执行另一个程序时,我们是从某种二级存储中加载的,比如硬盘或U盘。我们在上一章谈到了块驱动,但这只是对存储的读写。存储器本身以一定的顺序排列其0和1。这个序列被称为文件系统。我选择使用的文件系统是Minix 3文件系统,我将在这里描述它的实际应用。关于Minix 3文件系统或一般文件系统的更多概述,请参考我上面发布的课程笔记和视频。
我将介绍Minix 3文件系统的每个部分,但下面的图表描述了Minix 3文件系统的各个方面和结构。
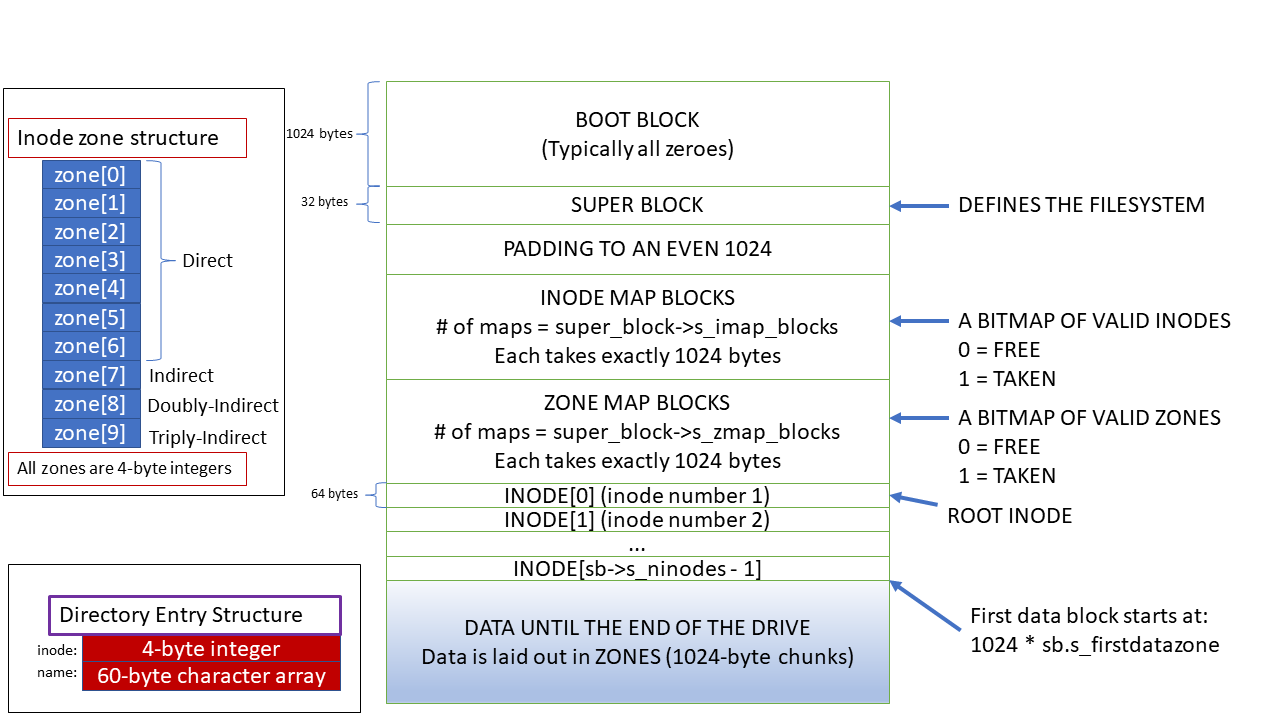
超级块
Minix 3文件系统的第一个块是boot块,它被保留给诸如bootloaders之类的东西,但我们被允许将第一个块用于任何我们想要的东西。然而,第二个区块是超级区块。超级块*是描述整个文件系统的元数据,包括块的大小和inodes的数量。
Minix 3文件系统的整个结构在文件系统被创建时就被设定了。节点和块的总数是根据二级存储的容量提前知道的。
由于超级块有一个已知的位置,我们可以查询文件系统的这一部分,得知我们在哪里可以找到索引节点(inodes),这些索引节点描述一个单一的文件。文件系统的大部分内容都可以通过基于块大小的简单数学计算来定位。下面的Rust结构描述了Minix 3文件系统的超级块。
#[repr(C)]pub struct SuperBlock {pub ninodes: u32,pub pad0: u16,pub imap_blocks: u16,pub zmap_blocks: u16,pub first_data_zone: u16,pub log_zone_size: u16,pub pad1: u16,pub max_size: u32,pub zones: u32,pub magic: u16,pub pad2: u16,pub block_size: u16,pub disk_version: u8,}
超级块不会改变,除非我们重新调整文件系统的大小,否则我们永远不会向超级块写入。我们的文件系统代码只需要从这个结构中读取。回顾一下,我们可以在引导块之后找到这个结构。Minix 3文件系统的默认块大小是1,024字节,这就是为什么我们可以用下面的方法要求块驱动器为我们获取超级块。
// descriptor, buffer, size, offsetsyc_read(desc, buffer.get_mut(), 512, 1024);
超级区块本身只有32个字节;但是,回顾一下,区块驱动必须以扇区的形式接收请求,也就是一组512个字节。是的,我们在读取超级块时浪费了相当多的内存,但由于I/O的限制,我们不得不这样做。这就是为什么我在我的大部分代码中使用缓冲区。我们可以将结构只指向内存的顶部部分。如果字段对齐正确,我们可以通过简单地引用Rust结构来读取超级块。 这就是为什么你会看到#[repr(C)]来改变Rust的结构为C风格的结构。
索引节点和区位图
为了跟踪节点和区域(块)的分配情况,Minix 3文件系统使用了一个位图。位图跟随超级区块,每个bit(因此是位图)代表一个节点或一个区块! 因此,这个位图的一个字节可以指代8个节点或8个块(8位=1字节)。

为了证明这一点,我的工作是弄清楚172区是被占用还是空闲。
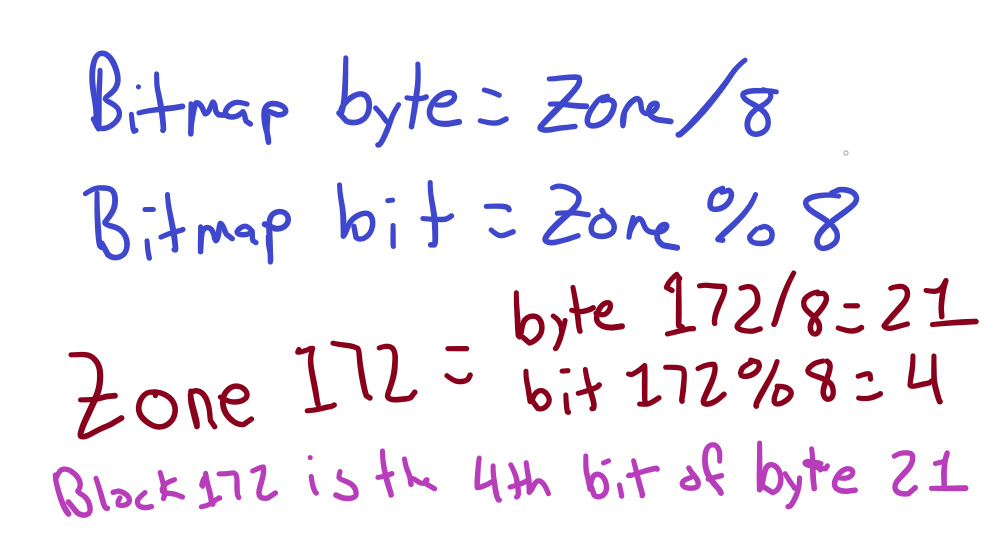
当我们测试第21字节的第4位时,我们将得到一个0或1。如果是1,意味着该区(块)已经被分配。如果是0,这意味着该区(块)是空闲的。如果我们想在一个文件中添加一个块,我们会扫描位图,寻找我们遇到的第一个0。每个位正好是一个块,所以我们可以把第一个1的位置乘以1024(或块的大小),就可以知道文件系统中的哪个位置是空闲的。
Minix 3文件系统有两个位图,一个是上面展示的区(块),另一个是inodes(下面解释)。
超级块的一个有趣的部分被称为magic。这是一个由两个字节组成的序列,有一个定义的值。当我们进入这个位置时,我们应该看到0x4d5a。如果我们没有看到,这要么不是Minix 3文件系统,要么是有什么东西被破坏了。你可以看到,我在下面的Rust代码中检查了这个神奇的数字。
// ...pub const MAGIC: u16 = 0x4d5a;// ...if super_block.magic == MAGIC {// SUCCESS!}
索引节点(inode)
我们需要能够用一个名字来指代存储元素。在unix风格的文件系统中,元数据,如文件的大小和类型,都包含在所谓的索引节点或简称inode中。Minix 3的inode包含有关文件的信息,包括模式(权限和文件类型)、大小、谁拥有该文件、访问、修改和创建时间,以及一组指向磁盘上可以找到实际文件数据的区指针。顺便提一下,注意到inode将文件的大小存储为u32,也就是4字节。然而,2^32大约是4GB,所以我们不能在任何一个文件中访问超过4GB的数据。
这些文件系统大多遵循所谓的索引分配。这与操作系统教程中通常使用的文件系统不同,它是依赖文件分配表(FAT)实现的。在索引分配中,我们的指针指向磁盘上某些块的数据。你看,一个块是文件系统中最小的可寻址单位。所有东西都是由块组成的。就我们的操作系统而言,所有的块都是1,024字节的小块。因此,如果我有两个文件,一个是10个字节,另一个是41个字节,这两个文件都正好需要1,024字节。对于第一个文件,前10个字节包含文件的数据,其余部分不包含任何内容。文件可以在这个块内展开。如果一个文件超过了一个块的大小,就必须分配另一个块,并由另一个区域指针来指向。
区域指针
在Minix 3文件系统中,有四种类型的区域指针:直接、间接、双重间接和三重间接。直接区域指针只是一个数字,我们可以用这个数字乘以块的大小来得到确切的块的位置。然而,我们只有7个直接区,这意味着我们只能寻址7 * 1,024(块大小)~= 7KB的数据!这就是间接区域指针的由来。间接区指针指向一个可以找到更多区指针的块。事实上,每个区块有1,024(区块大小)/4=256个指针。每个指针正好是4个字节。
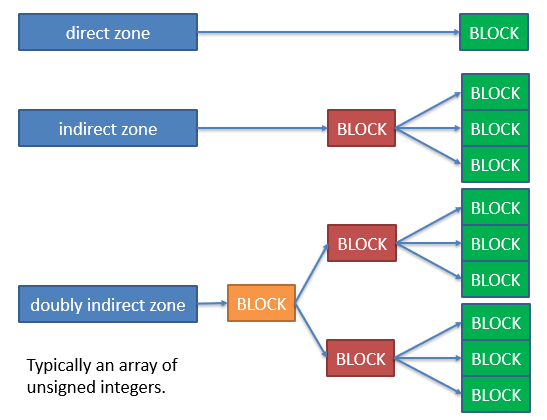
红色和橙色的块不包含任何与文件有关的数据。相反,这些块包含256个指针。单一间接指针可以寻址1,024 1,024 / 4 = 1,024 256 = 262 KB的数据。 请注意,我们从7个直接指针的约7KB变成了一个间接指针的262KB!这是很好的。
双重间接指针可以指向更多的块。双重间接指针指向一个256个指针的块。这256个指针中的每一个都指向另一个256个指针的块。这些指针中的每一个都指向文件的一个数据块。这样我们就得到了1,024 256 256 = 67 MB,也就是大约67兆字节的数据。三层间接指针是1,024 256 256 * 256 = 17 GB,大约是17千兆字节的数据!
当我们到了双倍和三倍间接指针时,Rust代码变得有点混乱了。我们在嵌套的循环嵌套循环! 直接指针是相当简单的,你可以在下面看到。
let zone_offset = inode.zones[i] * BLOCK_SIZE;syc_read(desc, block_buffer.get_mut(), BLOCK_SIZE, zone_offset);
一个直接指针乘以块的大小。这就给了我们区块的偏移量。然而,正如下面的代码所示,在读取间接区,也就是第8块区域(7号索引)时,我们必须多进行一步读取。
syc_read(desc, indirect_buffer.get_mut(), BLOCK_SIZE, BLOCK_SIZE * inode.zones[7]);let izones = indirect_buffer.get() as *const u32;for i in 0..num_indirect_pointers {if izones.add(i).read() != 0 {if offset_block <= blocks_seen {// descriptor, buffer, size, offsetsyc_read(desc, block_buffer.get_mut(), BLOCK_SIZE, BLOCK_SIZE * izones.add(i).read());}}}
为什么是0?在Minix 3中,当我们写文件或覆盖部分文件时,它们会变得*分散,这意味着文件的数据将被分散在不连续的块中。有时我们只是想完全跳过一个块。在这种情况下,我们可以将区域指针设置为0,在Minix 3中这意味着 “跳过它”。
双重和三重间接区分别多了一个和两个for循环。是的,很好,很容易阅读,对吗?
目录项
请注意,inode没有任何与之相关的名称,但我们总是通过名称访问文件。这就是目录项DirEntry结构发挥作用的地方。你看,一个文件可以被赋予多个名字。这些被称为硬链接。下面的Rust结构显示了目录项是如何布局的。
#[repr(C)]pub struct DirEntry {pub inode: u32,pub name: [u8; 60],}
再次使用#[repr(C)]来表示该结构是一个C风格的结构。注意,我们有一个4字节(32位)的inode,后面是一个60字节的名字。该结构本身是64字节。这就是我们如何将一个inode与一个名字联系起来。
这些目录条目存储在哪里?嗯,回顾一下,一个inode的模式告诉我们它是什么类型的文件。一种特殊类型的文件被称为目录。这些文件仍然有一个大小和与之相关的块。然而,当我们去找块的时候,我们会发现一堆这样的DirEntry结构。我们可以从节点1开始,这被称为根*节点。它是一个目录,所以当我们读取块时,我们会发现每个块有1,024 / 64 = 16个目录条目。每个文件,无论其类型如何,都会在某个地方得到一个目录条目。根节点只有紧靠根目录下的目录条目。然后,我们将进入另一个目录,例如/usr/bin/,并读取 “bin “的目录条目,以找到该目录中包含的所有文件。
布置目录条目使文件系统具有分层(树状)结构。要进入/usr/bin/shell,我们必须首先进入根目录/,然后是usr目录/usr,然后找到bin目录/usr/bin,最后找到shell文件/usr/bin/shell。/、usr和bin会有一个与之相关的inode,其模式会告诉我们这些是目录。当我们到达shell时,它将是一个普通的文件,也是用模式描述的。
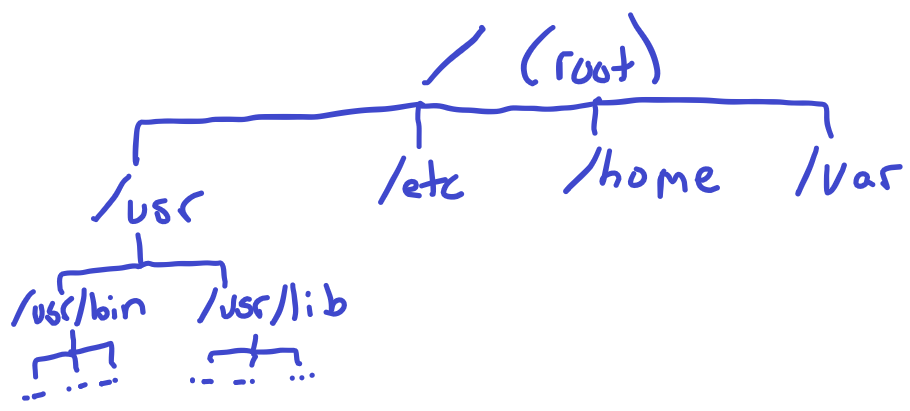
这些目录可以放在任何区块中,除了根目录/,它总是在1号节点。这给了我们一个稳定的、已知的起点。
操作系统的文件系统读取过程
回顾一下,块设备驱动发出一个请求,并将其发送给区块设备。块设备为请求提供服务,然后在完成后发送一个中断。我们真的不知道中断什么时候会来,而且我们也不能等着它。这就是为什么我决定把文件系统阅读器变成一个内核进程。我们可以把这个内核进程放在等待的状态下,这样它就不会被调度,直到收到来自块设备的中断。否则,我们将不得不自旋和轮询以查看中断是否被发送。
pub fn process_read(pid: u16, dev: usize, node: u32, buffer: *mut u8, size: u32, offset: u32) {let args = talloc::().unwrap();args.pid = pid;args.dev = dev;args.buffer = buffer;args.size = size;args.offset = offset;args.node = node;set_waiting(pid);let _ = add_kernel_process_args(read_proc, args as *mut ProcArgs as usize);}
由于我们的块驱动现在需要知道等待中断的进程,我们必须添加一个watcher,也就是它要通知中断的进程。所以,我们的块操作函数的原型是:
pub fn block_op(dev: usize, buffer: *mut u8, size: u32, offset: u64, write: bool, watcher: u16) -> Result<u32, BlockErrors>
正如你所看到的,我们已经添加了另一个参数,即watcher。这是watcher的PID,而不是一个引用。如果我们使用一个引用,进程在等待状态下需要保持驻留。否则,我们将解除对无效内存的引用。使用pid,我们可以通过进程ID来查找该进程。如果我们没有找到它,我们可以默默地丢弃这个结果。这仍然留下了空缓冲区的可能性,但一次只做一件事,ok?
现在,当我们处理块设备的中断时,我们必须匹配watcher并唤醒它。
let rq = queue.desc[elem.id as usize].addr as *const Request;let pid_of_watcher = (*rq).watcher;if pid_of_watcher > 0 {set_running(pid_of_watcher);let proc = get_by_pid(pid_of_watcher);(*(*proc).get_frame_mut()).regs[10] = (*rq).status.status as usize;}
regs[10]是RISC-V中的A0寄存器。这被用作函数的第一个参数,但它也被用作返回值。所以,当进程在系统调用后唤醒并继续运行时,A0寄存器将包含状态。状态为0表示OK,1表示I/O错误,2表示不支持的请求。这些数字是在VirtIO规范中为块设备定义的。
这里要做的一件好事是检查get_by_pid是否真的返回一个有效的Process指针,因为我们绕过了Rust的检查。
测试
我们需要hdd.dsk有一个有效的Minix 3文件系统。你可以在Linux机器上这样做,比如我使用的Arch Linux。你可以用losetup将一个文件设置成一个块设备。
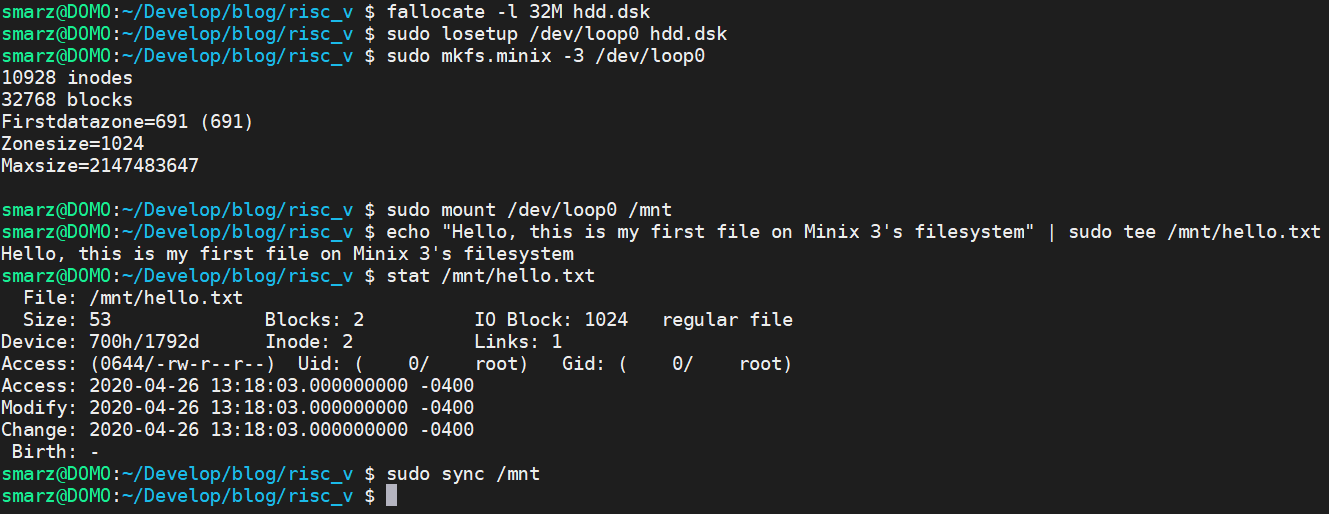
fallocate命令将分配一个空文件。在这个例子中,我们指定长度(大小)为32MB。然后,我们告诉Linux通过使用losetup使我们的hdd.dsk成为一个块设备,这是一个循环设置。每当我们读/写块设备/dev/loop0时,它实际上会读/写文件hdd.dsk。然后我们可以通过输入`mkfs.minix -3 /dev/loop0’在这个块设备上建立Minix 3文件系统。3很重要,因为我们正在使用Minix 3文件系统。Minix 1和2并不遵循我在本教程中介绍的所有结构。
文件系统建立后,我们可以在Linux中使用mount /dev/loop0 /mnt来挂载它。就像任何文件系统一样,我们可以向这个新的文件系统读/写。由于我们的操作系统还不能通过名字找到一个节点,我们必须通过节点号来指定它。如果我们看一下中间stat之后的第三行,我们可以看到Inode: 2. 这意味着如果我们读取inode #2,我们将找到所有必要的信息来读出 “你好,这是我在Minix 3的文件系统上的第一个文件”。当我们读取这个节点时,我们应该得到一个文件大小为53,模式为10644(八进制),权限是644,类型是10(普通文件)的文件。
你可以通过使用以下命令来卸载和删除该块设备。
sudo umount /mntsudo losetup -d /dev/loop0
现在,在main.rs中,我们可以写一个小测试,看看这是否有效。我们需要添加一个内核进程,它就像一个正常的进程,只是我们在机器模式下运行。在这种RISC-V模式下,MMU被关闭了,所以我们只处理物理地址。
fn test_read_proc() {let buffer = kmalloc(100);// device, inode, buffer, size, offsetlet bytes_read = syscall_fs_read(8, 2, buffer, 100, 0);if bytes_read != 53 {println!("Read {} bytes, but I thought the file was 53 bytes.", bytes_read);}else {for i in 0..53 {print!("{}", unsafe { buffer.add(i).read() as char });}println!();}kfree(buffer);syscall_exit();}
扩展系统调用
正如你所看到的,我们在上面为一个内核进程使用了syscall_fs_read和syscall_exit。我们可以在syscall.rs中定义这些,如下所示。
fn do_make_syscall(sysno: usize,arg0: usize,arg1: usize,arg2: usize,arg3: usize,arg4: usize,arg5: usize)-> usize{unsafe { make_syscall(sysno, arg0, arg1, arg2, arg3, arg4, arg5) }}pub fn syscall_fs_read(dev: usize,inode: u32,buffer: *mut u8,size: u32,offset: u32) -> usize{do_make_syscall(63,dev,inode as usize,buffer as usize,size as usize,offset as usize,0)}pub fn syscall_exit() {let _ = do_make_syscall(93, 0, 0, 0, 0, 0, 0);}
如果我们看一下asm/trap.S中的代码,在底部,我们会发现make_syscall。我指定63作为读取系统调用,93作为退出系统调用,以匹配newlib的libgloss。
.global make_syscallmake_syscall:mv a7, a0mv a0, a1mv a1, a2mv a2, a3mv a3, a4mv a4, a5mv a5, a6ecallret
编号63是libgloss库中的read()系统调用,它是newlib的一部分。这将执行以下内容。
let _ = minixfs::process_read((*frame).pid as u16,(*frame).regs[10] as usize,(*frame).regs[11] as u32,physical_buffer as *mut u8,(*frame).regs[13] as u32,(*frame).regs[14] as u32);
系统调用的编号现在在寄存器A7(由make_syscall汇编函数移动)。寄存器10到14(A0-A4),存储了这个系统调用的参数。当我们在这里调用process_read时,它将创建一个新的内核进程来处理从文件系统的读取。回顾一下,我们这样做是为了让块驱动器在等待块设备的回复时让我们进入睡眠状态。
结论
Minix 3文件系统是教学系统Minix 1和2版本的后继版本。Minix 3文件系统是一个相当规范的文件系统。你在这里看到的所有结构都是规范的,可以从Linux机器上用mkfs.minix制作的文件系统中读取。
Stephen Marz (c) 2020

若有收获,就点个赞吧
0 人点赞
