一、机器学习简单流程:
- 使用大量和任务相关的数据集来训练模型;
- 通过模型在数据集上的误差不断迭代训练模型,得到对数据集拟合合理的模型;
- 将训练好调整好的模型应用到真实的场景中;
我们最终的目的是将训练好的模型部署到真实的环境中,希望训练好的模型能够在真实的数据上得到好的预测效果,换句话说就是希望模型在真实数据上预测的结果误差越小越好。我们把模型在真实环境中的误差叫做泛化误差,最终的目的是希望训练好的模型泛化误差越低越好。
我们希望通过某个信号来了解模型的泛化误差,这样就可以指导我们得到泛化能力更强的模型:
- 使用泛化误差本身。这是很自然的想法,我们训练模型的最终目的就是希望模型的泛化误差最低,当然可以使用泛化误差本身来作为检测信号。如果泛化误差小的话还可以接受,但是通常情况下没有那么幸运,泛化误差可能很大,这个时候你肯定会将部署的模型撤回,重新训练,你可能需要部署和训练之间往复很多次,这种方式虽然能够更好的指导我们的模型,但是成本和效率非常的差;
使用模型在数据集上训练的拟合程度来作为评估模型的信号。但是往往我们获取的数据集并不是完全的干净以及有代表性,通常我们获取到的数据集可能很少、数据的代表性不够、包含太多的噪声或者是被一些无关特征污染,我们获取到的数据集或多或少都会有这些问题,那么模型对训练数据集的拟合程度不能指导泛化误差,也就是说训练的时候拟合的好并不代表模型的泛化误差就小,你甚至可以将模型在数据集上的误差减小到0,但是因为对模型训练时候的数据集往往不干净,所以这样的模型并不代表泛化能力就强。
二、训练集与测试集
前面说到我们既不能通过直接将泛化误差作为了解模型泛化能力的信号,因为在部署环境和训练模型之间往复,代价很高,也不能使用模型对训练数据集的拟合程度来作为了解模型泛化能力的信号,因为我们获得的数据往往不干净。
更好的方式就是将数据分割成两部分:训练集和测试集。我们可以使用训练集的数据来训练模型,然后用测试集上的误差作为最终模型在应对现实场景中的泛化误差。有了测试集,我们想要验证模型的最终效果,只需将训练好的模型在测试集上计算误差,即可认为此误差即为泛化误差的近似,我们只需让我们训练好的模型在测试集上的误差最小即可。
这里有几点需要注意:通常将数据集的80%(70%)作为训练集,20%(30%)作为测试集;
- 通常需要在开始构建模型之前把数据集进行划分,防止数据窥探偏误,也就是说我们避免了解太多关于测试集中的样本特点,防止我们认为的挑选有助于测试集数据的模型,这样的结果会过于乐观,但是实际上并没有预期的那样优秀;
- 通常我们在构建模型的时候需要将数据进行处理,包括一些数据的清洗,数据的特征缩放(标准化或者归一化),此时我们只需要在训练集上进行这些操作,然后将其在训练集上得到的参数应用到测试集中,也就是说,在工作流程中,你不能使用在测试数据集上计算的得到的任何结果。比如:我们得到的属性中可能有缺失值,因为在这些操作之前,我们已经把数据集分成了训练集和测试集,通常的做法是通过计算属性值的中位数来填充缺失值,注意此时计算属性值的中位数是通过训练集上的数据进行计算的,当我们得到一个模型的时候,如果想要测试模型的测试误差来近似泛化误差的时候,可能此时的测试集也会有一些缺失值,此时对应属性的缺失值是通过训练集计算的中位数来进行填充的;
- 由于测试集作为对泛化误差的近似,所以训练好模型,最后在测试集上近似估计模型的泛化能力。此时假设有两个不同的机器学习模型,犹豫不决的时候,可以通过训练两个模型,然后对比他们在测试数据上的泛化误差,选择泛化能力强的模型。
前面说了这么多,那如何划分数据集为训练集和测试集呢?其实很简单,可以自己编写程序,也可以使用sklearn提供的模块:
通过简单代码实现:
import numpy as npdef split_train_test(data,test_ratio):#设置随机数种子,保证每次生成的结果都是一样的np.random.seed(42)#permutation随机生成0-len(data)随机序列shuffled_indices = np.random.permutation(len(data))#test_ratio为测试集所占的百分比test_set_size = int(len(data) * test_ratio)test_indices = shuffled_indices[:test_set_size]train_indices = shuffled_indices[test_set_size:]#iloc选择参数序列中所对应的行return data.iloc[train_indices],data.iloc[test_indices]#测试train_set,test_set = split_train_test(data,0.2)print(len(train_set), "train +", len(test_set), "test")
通过sklearn实现:
from sklearn.model_selection import train_test_split#data:需要进行分割的数据集#random_state:设置随机种子,保证每次运行生成相同的随机数#test_size:将数据分割成训练集的比例train_set, test_set = train_test_split(data, test_size=0.2, random_state=42)
前面介绍的两种分割数据集的方式都是采用纯随机的采样方式,这种方式对于大量数据集以及对于目标值分布均匀的情况是可行的。比如对于分类任务,我们训练一个二值分类器,可能数据中包含大量的正例样本,仅仅包含10%的反例样本,此时的标签分布很不均匀,如果我们通过随机采样的方式,极端情况下可能将正例样本都划分到训练集上,而反例样本恰好都分到测试集,这样训练出来的模型,效果一定不会太好,所以我们需要采用分层采样的方式进行划分数据集,也就是说保证训练集中既包含一定比例的正例样本又要包含一定比例的负例样本。
幸运的是sklearn提供了我们分层抽样的函数,在这之前先看看官方提供的例子:
from sklearn.model_selection import StratifiedShuffleSplitX = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])y = np.array([0, 0, 1, 1])split = StratifiedShuffleSplit(n_splits=3, test_size=0.5, random_state=0)print(split ) # doctest: +ELLIPSIS# StratifiedShuffleSplit(n_splits=3, random_state=0, ...)for train_index, test_index in split.split(X, y):print("TRAIN:", train_index, "TEST:", test_index)X_train, X_test = X[train_index], X[test_index]y_train, y_test = y[train_index], y[test_index]"""StratifiedShuffleSplit(n_splits=3, random_state=0, test_size=0.5,train_size=None)TRAIN: [1 2] TEST: [3 0]TRAIN: [0 2] TEST: [1 3]TRAIN: [0 2] TEST: [3 1]"""
通过上面的例子我们可以了解使用分层进行划分数据集的大概流程,以及各个参数的含义:
- n_splits:分割迭代的次数,如果我们要划分训练集和测试集的话,将其设置为1即可;
- test_size:分割测试集的比例;
- random_state:设置随机种子;
下面通过两种方式对原始的mnist数据集进行划分,首先要准备数据集:
from sklearn.datasets import fetch_mldata#我将最原始的mnist数据集下载到当前路径下,指定data_homemnist = fetch_mldata('MNIST original',data_home=r"./")x_data = mnist["data"].reshape((mnist["data"].shape[0],-1))y_data = mnist["target"].reshape((mnist["target"].shape[0],-1))print(x_data.shape) #(70000, 784)print(y_data.shape) #(70000, 1)
- 使用随机采样的方式分割数据集:
```python
使用随机采样方式划分数据集
from sklearn.model_selection import train_test_split import numpy as np
data = np.hstack((x_data,y_data))
先将数据集进行拼接,要不然我们只针对样本进行采样的话,会找不到对应的标签的
train_set,test_set = train_test_split(data,test_size = 0.2,random_state = 42) print(len(train_set),len(test_set))
“”” 56000 14000 “””
- 使用分层采样的方式分割数据集:```pythonfrom sklearn.model_selection import StratifiedShuffleSplitsplit = StratifiedShuffleSplit(n_splits = 1,test_size = 0.2,random_state = 42)#根据mnist["target"]来进行分层采样for train_index,test_index in split.split(data[:,:-1],data[:,-1]):train_set = data[train_index,:]test_set = data[test_index,:]print(len(train_set),len(test_set))"""56000 14000"""
如果想要知道抽取的各个样本的比例,你可以将数据转换成DataFrame对象(当然在处理数据的开始你也可以将数据转换为DataFrame方便操作):
#将分割后的训练数据转换为DataFrame
#这里的参数data可以是分割之后的训练集或者测试集
train_data = pd.DataFrame(train_set)
#快速查看对数据的描述
train_data.info()
#查看各个类别的比例
print(train_data[784].value_counts() / len(train_data))
下面各图分别是:原始数据10个类别所占的比例、随机采样训练集中10个类别所占比例以及分层采样训练集中10个类别所占的比例(当然也可以对测试集进行统计)。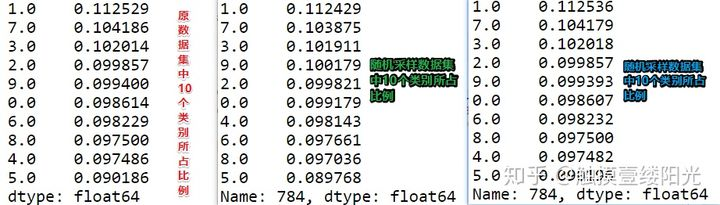
统计对比
通过上面的分析可以看出,分层采样出的10个类别所占的比例和原数据中的10个类别所占的比例很接近。
三、验证集
前面说到我们将数据集划分为训练集和测试集,我们让模型在训练集上进行训练,然后在测试集上来近似模型的泛化能力。我们如果想要挑选不同的模型的话,可以让两个模型分别在训练集上训练,然后将两个训练好的模型分别在测试集上进行测试,由于我们把测试集上的误差近似近似为泛化误差,所以我们自然可以选择在测试集上误差小的模型作为最终我们要选择的泛化能力强的模型。
但是我们要做的不仅是不同的模型与模型之间的对比,很多时候我们需要对模型本身进行选择,假如我们有两个模型,线性模型和神经网络模型,我们知道神经网络的泛化能力要比线性模型要强,我们选择了神经网络模型,但是神经网络中还有很多的需要人工进行选择的参数,比如神经网络的层数和每层神经网络的神经元个数以及正则化的一些参数等等,我们将这些参数称为超参数。这些参数不同选择对模型最终的效果也很重要,我们在开发模型的时候总是需要调节这些超参数。
现在我们需要调节这些超参数来使得模型泛化能力最强。我们使用测试集来作为泛化误差估计,而我们最终的目的就是选择泛化能力强的模型,那么我们可以直接通过模型在测试集上的误差来调节这些参数不就可以了。可能模型在测试集上的误差为0,但是你拿着这样的模型去部署到真实场景中去使用的话,效果可能会非常差。
这一现象叫做信息泄露。我们使用测试集作为泛化误差的近似,所以不到最后是不能将测试集的信息泄露出去的,就好比考试一样,我们平时做的题相当于训练集,测试集相当于最终的考试,我们通过最终的考试来检验我们最终的学习能力,将测试集信息泄露出去,相当于学生提前知道了考试题目,那最后再考这些提前知道的考试题目,当然代表不了什么,你在最后的考试中得再高的分数,也不能代表你学习能力强。而如果通过测试集来调节模型,相当于不仅知道了考试的题目,学生还都学会怎么做这些题了(因为我们肯定会人为的让模型在测试集上的误差最小,因为这是你调整超参数的目的),那再拿这些题考试的话,人人都有可能考满分,但是并没有起到检测学生学习能力的作用。原来我们通过测试集来近似泛化误差,也就是通过考试来检验学生的学习能力,但是由于信息泄露,此时的测试集即考试无任何意义,现实中可能学生的能力很差。所以,我们在学习的时候,老师会准备一些小测试来帮助我们查缺补漏,这些小测试也就是要说的验证集。我们通过验证集来作为调整模型的依据,这样不至于将测试集中的信息泄露。
也就是说我们将数据划分训练集、验证集和测试集。在训练集上训练模型,在验证集上评估模型,一旦找到的最佳的参数,就在测试集上最后测试一次,测试集上的误差作为泛化误差的近似。关于验证集的划分可以参考测试集的划分,其实都是一样的,这里不再赘述。
吴恩达老师的视频中,如果当数据量不是很大的时候(万级别以下)的时候将训练集、验证集以及测试集划分为6:2:2;若是数据很大,可以将训练集、验证集、测试集比例调整为98:1:1;但是当可用的数据很少的情况下也可以使用一些高级的方法,比如留出方,K折交叉验证等。
参考:
1.《Hands-On Machine Learning with Scikit-Learn and TensorFlow》
版权声明:本文转载于知乎博主触摸壹缕阳光,转载请附上原文出处链接及本声明。
原文链接:https://zhuanlan.zhihu.com/p/48976706?ivk_sa=1024320u

若有收获,就点个赞吧
0 人点赞
