:::info
本章内容改编自《Programming Rust, 2nd Edition》的第9章。
:::
Struct是一种用户自定义的复合数据类型。这里,“复合”指的是,用户可以把若干具有不同或相同类型的值按照某种顺序排列在一起,形成一个复合的值。给定一个Struct类型的值,我们可以通过特定的方式访问到其中包含的某一个分量。Rust中的Struct还具有一个重要特点,即:可以把方法附着到一个Struct类型的值上。
Rust中的Struct,可以大致对应到C/C++中的Struct、Python中的Class、以及JavaScript中的Object。当然,这仅仅是一种大致对应,在细节上仍然存在很多差异。
三种形式的Struct
Rust中的Struct具有三种不同的形式。下面,我们逐个说明。
Named-Field Struct (NFS)
在一个NFS中,每一个分量都具有一个名称。分量的名称由用户在定义一个NFS时指定。给定一个NFS类型的值v,可以通过分量的名称访问对应分量的值。例如,v.name可以访问到v中名称为name的分量的值。
struct ColorImage {size: (usize, usize),pixels: Vec<u32>}// 上面三行行代码定义/声明了一个NFS类型,名称为ColorImage// 该类型包含了两个分量,名称分别为size和pixels,类型分别为(usize, usize)和Vec<u32>fn main() {let width = 1024;let height = 768;let image = ColorImage {pixels: vec![0; width * height],size: (width, height)};// 上面三行代码创建了ColorImage的一个实例,并将其赋给变量image// 熟悉JavaScript的的同学,在看到这段代码后,一定有一种似曾相识的感觉// 这TMD不就是JavaScript中的Object Literal(对象字面量)吗!确实如此。// 我们在对类型检查最松散的JavaScript中和对类型检查异常严格的Rust中看到了一丝的共性// 其实这也不奇怪,因为这两种语言都与Mozilla有扯不开的关系// 仿照JavaScript中的命名方式,可以将这种声明Struct类型实例的方式称为Struct Literalprintln!("{:?}", image.size); //=> (1024, 768)println!("{}", image.pixels[0]); //=> 0// 上面两行展示了如何通过点操作符和分量名称,访问ColorImage实例中包含的某个分量}fn new_image(size: (usize, usize), pixels: Vec<u32>) -> ColorImage {assert_eq!(size.0 * size.1, pixels.len());ColorImage { size, pixels }// 上一行代码等价于 ColorImage { size: size, pixels: pixels }// 这是一种语法糖// 有时候,我望着这样的语法糖,竟然有些分不清Rust和JavaScript了呢!}
另外,上面程序也展示了Rust中关于标识符的一种命名习惯:
- 对于表示类型的标识符,通常采用CamelCase的方式进行命名;
- 对于表示变量、方法、分量名称的标识符,通常采用snake_case的方式进行命名。
在前面的章节中,我们已经看到了许多NFS的实例。其中需要注意的一个方面是:
- 我们在声明一个NFS类型时,可以为每一个分量指定不同的可见性;
若不指定,则一个分量缺省具有
private的可见性。可见性在前文中已经介绍,此处不再赘述。Partially Moved Struct
Struct这种复合类型的值,有一个重要的行为特点:可以将这个值的某一个分量的所有权转移给其它变量,进而得到一个partially-moved struct value。 ```rust fn main() { let monkey_king = Demon { name: String::from(“孙悟空”), age : 10000, addr: String::from(“花果山”) };
println!(“{:?}”, monkey_king); //=> Demon { name: “孙悟空”, age: 10000, addr: “花果山” }
let name = monkey_king.name; // value partially moved here // 上一行代码将monkey_king的分量name的所有权转移给了变量name // 这时,monkey_king就变成了一个partially moved struct
println!(“{}”, name); //=> 孙悟空 println!(“{}”, monkey_king.age); //=> 10000 // 对于一个partially moved的struct,那些没有发生所有权转移的分量仍然可以正常访问
println!(“{:?}”, monkey_king); // Compilation Error: borrow of partially moved value:
monkey_king// 一个partially moved的struct,无法再创建对它的引用 // 另外,一个partially moved的struct,其自身的所有权也无法被转移给其他变量 }
[derive(Debug)]
struct Demon { name: String, age : u32, addr: String }
<a name="oRAfU"></a>#### 分量缺省值在创建一个NFS类型的值时,经常会遇到这种情况:我们只需要给这个值中的若干个分量赋予特定的值;其他分量则从另一个同类型的NFS值中读取。<br />Rust提供了一种针对这种情况的简便语法,即:在一个Struct Literal最后一个分量赋值之后,添加一个逗号`,`,后面书写一个`..`操作符,其后再书写一个同类型NFS表达式`EXPR`。此时,这个Struct Literal中未声明的分量,会从`EXPR`中获得同名分量的值。```rust#[derive(Debug)]struct Demon {name: String,age : u32,addr: String}// 这个split函数的功能是把一个demon(精灵)一分为二,返回两个分裂后形成的精灵// 从该函数的参数类型可知,传入该函数的参数的所有权被转移到了函数内部fn split(demon: Demon) -> (Demon, Demon) {let mut d1 = Demon { age: demon.age / 2, .. demon };// 上一行代码创建了一个分裂后的精灵// 我们可以将其中的..demon理解为一种语法糖// 如果不使用这种语法糖,则上述Struct Literal必须被写为// Demon { age: demon.age/2, name: demon.name, addr: demo.addr }。// 显然可知,执行完这行代码后,demo变成了一个partially moved struct// 因为它的两个分量name和addr的所有权已经被转移给了新创建的精灵变量d1let mut d2 = Demon { name: d1.name.clone(),addr: d1.addr.clone(), .. d1 };// 上两行代码创建了另一个分裂后的精灵// 这里需要注意:为什么要使用name: d1.name.clone()这种形式,而不是name: d1.name呢?// 我想,如冰雪/顽石一般聪明的你,一定知道这背后的原因// 如果不知道,就在答疑的时候问吧d1.name.push_str(" 分身一");d2.name.push_str(" 分身二");(d1, d2)}fn main() {let monkey_king = Demon {name: String::from("孙悟空"),age : 10000,addr: String::from("花果山")};let (mk1, mk2) = split(monkey_king);println!("{:?}", mk1);println!("{:?}", mk2);}
Tuple-Like Struct (TLS)
TLS可以被视为一种具有名字的Tuple。下面的代码给出了TLS声明和使用的示例。
struct Bound(usize, usize);// 上一行代码声明了一个TLS,它的名称为Bound,内容则是一个二元组(usize, usize)// 它看起来,就是一个带有名字的Tuplefn main() {let b = Bound(1024, 768);// 上一行创建了Bound的一个实例// 其中,赋值操作符的右侧,你可以将它视为一种Struct Literal,因为它形成了Bound的一个实例// 但是,可以看到,Bound(1024, 768)看起来也是一次函数调用// 是的,它确实是一次函数调用// 对于一个TLS类型,Rust会自动构造一个同名函数,用于构造该TLS类型的实例println!("{}, {}", b.0, b.1); //=> 1024, 768let Bound (b0, b1) = b;println!("{}, {}", b0, b1); //=> 1024, 768}
关于TLS,有其他两点信息需要说明:
- 一个TLS的实例,可以被partially moved。
- 可以为一个TLS的不同分量声明不同的可见性。
Unit-Like Struct (ULS)
ULS可以被视为一种具有名字的0-Tuple。下面的代码给出了ULS声明和使用的示例。
#[derive(Debug)]struct OneSuch;// 上一行声明了一个ULS。没错,就是一个名字,其他全都不需要fn main() {let o = OneSuch;// 上一行展示了如何得到一个ULS类型的实例// 没错,ULS类型的名称就指代了这个ULS类型具有的唯一的那个实例// 你可能会有疑问:ULS类型的名称,既作为类型名称,又作为实例名称,不会造成歧义吗?// 其实,你多虑了// 类型和实例出现在不同的上下文中,编译器可以根据上下文的差异确定名称的含义// 另外需要注意一点:对于Rust编译器而言,它也不会为ULS类型的变量分配内存空间println!("{:?}", o); //=> OneSuch}
Struct在内存中的排布(Memory Layout)
在这三种形式的Struct中,ULS不涉及内存排布问题,因为它的实例根本就不占用内存空间。对于NFS和TLS,虽然它们在声明和使用时具有显而易见的差异,但是,这两者在内存中的排布方式是完全相同的。
例如,对于一个NFS类型的实例nfs和一个TLS类型的实例tls,对它们各自分量的访问可能表现为nfs.field和tls.2。这两种具有明显差异的分量访问方式,在经过编译后,都会被转换为分量相对于所在struct实例内存地址的偏移量。也就是说,无论对于NFS还是对于TLS,它们所包含的一组分量,大概都会被以一定的顺序和对齐(allignment)排布在内存中。进而,对于某个分量的访问自然转变为对struct实例内存地址某个偏移量的访问。
fn main() {let width = 1024;let height = 768;let image = ColorImage {pixels: vec![0; width * height],size: (width, height)};}struct ColorImage {size: (usize, usize),pixels: Vec<u32>}
对于上面代码中变量image所拥有的这个Struct值,其在内存中的一种可能排布方式如下图所示:
但是,在缺省情况下,Rust不会对Struct类型的值在内存中的排布做出任何承诺。也就是说,除非明确指定,我们应将Struct在内存中的排布视为一种黑盒。例如,在上面的示例中,我们不应假设分量pixels一定会被排布在size的前面。这样,在未来的版本中,Rust就可能可以根据优化的需要,对排布方式做出改变。
我们可以在声明一个Struct类型时,通过attribute声明指定Struct在内存中的排布方式。例如,属性声明#[repr(C)]表示按照C语言中Struct的排布方式对当前Struct进行表示(Representation)。
在Struct上附着方法
下面,我们通过实现一个具有先进先出行为的队列(Queue),展示如何在Struct上附着方法。
pub struct Queue {older: Vec<char>,ynger: Vec<char>}// 上面4行代码声明了一个Struct类型,包含两个分量older和ynger,类型均为Vec<char>// 看到这个类型,你可能会萌发两个问题:// 问题1:为什么有char类型?回答:这个队列中的元素是char类型的值。// 问题2:为什么要把一个队列实现为两个向量?回答:慢慢往下看,自然就知道了。// 以下声明了一个impl代码块 impl Queue { ... },其中声明了若干方法// 这些方法都是附着在Queue上的方法impl Queue {pub fn new() -> Queue {Queue { older: vec![], ynger: vec![] }}// 以上声明了一个new方法,该方法的功能是创建一个Queue的实例// 为什么说这个方法是附着在Queue上的一个方法呢?// 因为必须采用Queue::new这种形式才可以访问到这个方法pub fn is_empty(self: &Queue) -> bool {self.older.is_empty() && self.ynger.is_empty()}// 以上声明了一个is_empty方法,该方法具有一个类型为&Queue的参数// 该方法的功能是判断传入的这个队列是否是一个空队列(即:队列中不包含任何元素)pub fn push(self: &mut Queue, c: char) {self.ynger.push(c);}// 以上声明了一个push方法// 该方法具有两个参数,类型分别为&mut Queue和char// 该方法的功能是向传入的队列中添加一个元素// 可以看到,该功能的实现方式就是在ynger分量拥有的向量的末尾添加一个元素// 与new方法类似,可以采用Queue::push的形式访问到这个方法// 并按照其要求的参数类型传入实际参数pub fn pop(self: &mut Queue) -> Option<char> {if self.older.is_empty() {if self.ynger.is_empty() {return None;}use std::mem::swap;swap(&mut self.older, &mut self.ynger);self.older.reverse();}self.older.pop()}// 以上声明了一个pop方法;该方法具有一个参数,类型为&mut Queue// 该方法的功能是从传入的队列中取出一个元素// 该方法的返回值的类型为Option<char>:// --当成功地从队列中取出一个元素,则返回一个形状为Some(...)的值// --如果队列为空,则返回一个形状为None的值// 这个方法的逻辑稍微复杂一些// 但是,看懂了这个方法,你就能够理解“为什么要用两个向量而不是一个向量来实现队列”pub fn split(self: Queue) -> (Vec<char>, Vec<char>) {(self.older, self.ynger)}// 以上展示了一个split方法// 该方法具有一个参数,类型为Queue// 这表明,调用这个方法时,传入的队列的所有权会被转移到方法内部// 这个方法实现的功能很简单:// --将队列中包含的两个分量older和ynger组织成一个二元组后返回}fn main() {let mut q = Queue::new();Queue::push(&mut q, 'P'); //== (&mut q).push('P');// 上一行代码展示了push方法的两种调用方式// 可以看到,这两种方式具有明显的书写不友好性// 难道还有更简便的书写方式?有的,稍等一下就介绍Queue::push(&mut q, 'D'); //== (&mut q).push('D');assert_eq!(Queue::pop(&mut q), Some('P')); //== (&mut q).pop();Queue::push(&mut q, 'X'); //== (&mut q).push('X');let (o, y) = Queue::split(q); //== q.split(q)assert_eq!(o, vec!['D']);assert_eq!(y, vec!['X']);}
上面这段代码具有一些看起来很不友好的表达方式,与Rust如雷贯耳的大名格格不入。现在,让我们给它加一点语法糖,为程序员的生活增加一丝甜蜜的幻觉。
pub struct Queue {older: Vec<char>,ynger: Vec<char>}impl Queue {pub fn new() -> Self {Self { older: vec![], ynger: vec![] }}pub fn is_empty(&self) -> bool {self.older.is_empty() && self.ynger.is_empty()}pub fn push(&mut self, c: char) {self.ynger.push(c);}pub fn pop(&mut self) -> Option<char> {if self.older.is_empty() {if self.ynger.is_empty() {return None;}use std::mem::swap;swap(&mut self.older, &mut self.ynger);self.older.reverse();}self.older.pop()}pub fn split(self) -> (Vec<char>, Vec<char>) {(self.older, self.ynger)}}// 在以上impl Queue { ... }代码块中出现的所有Queue,均被替换为Self// 在一个impl代码块内,Self表示当前被implement的那个type// 在上面的示例中,那个type就是Queue// 对于impl Queue { ... }代码块中声明的每一个方法// 如果它的第一个参数的类型是Queue、mut Queue、&Queue、或&mut Queue// 那么,这个参数可以分别简写为self、mut self、&self、&mut self// 这个self参数,大致对应于C++或JavaScript中的this// 对于impl Queue { ... }代码块中声明的每一个方法// 如果它的第一个参数是self,那么,在调用这个方法时,可以使用一种简洁形式// 例如,方法调用Queue::push(&mut q, 'P'),可以被书写为q.push('P')// 你应该可以看到这种简洁方式所带来的便利:// --调用一个方法时,不再需要程序员手工确定传入参数的具体形式// dot操作符.很聪明,它知道该从左边的操作数上取得一个什么形式的值。fn main() {let mut q = Queue::new();q.push('P'); // 怎么样,这种函数调用方式是不是清爽多了q.push('D');assert_eq!(q.pop(), Some('P'));q.push('X');let (o, y) = q.split();assert_eq!(o, vec!['D']);assert_eq!(y, vec!['X']);}
dot操作符.可能比你想象的还要聪明,它甚至知道如何从Box、Rc、Arc等指针操作数上取到合适的值。请看下面的这个示例:
fn main() {let mut bq = Box::new(Queue::new());bq.push('P'); // 1. 从 mut Box<Queue> 获得一个 &mut Queuebq.push('D'); // 2. 获得方式: &mut *bqassert_eq!(bq.pop(), Some('P')); // 3. *bq 未发生所有权转移bq.push('X');println!("{}", bq.is_empty()); //=> true// ^ 从 Box<Queue> 获得一个 &Queue// 获得方式: &*bqlet (o, y) = bq.split(); // 从 Box<Queue> 获得一个 Queue// *bq 发生了所有权转移assert_eq!(o, vec!['D']);assert_eq!(y, vec!['X']);println!("{}", bq.is_empty()); // Compilation Error// ^ borrow of moved value: `*bq`}
在上面的代码示例中:
- 我们把
Queue的一个实例放在一个Box中,并赋值给可变变量bq。 - 然后,我们仍然可以在
bq上直接使用dot操作符.访问Queue上附着的各个方法。
下面,我们看看如果把dot操作符.作用到一个Rc类型的值上,会有什么效果。
fn main() {let mut q = Queue::new();q.push('P'); q.push('D'); q.pop(); q.push('X');use std::rc::Rc;let mut cq = Rc::new(q); // q is moved// 在以上代码中,我们把Queue的一个实例放在一个Rc中,并赋值给可变变量cqprintln!("{}", cq.is_empty()); //=> false// ^ 从 Rc<Queue> 获得一个 &Queue// 获得方式: &*cq//在上一行代码中,我们仍然可以直接在cq上通过dot操作符.访问到Queue上的方法is_emptycq.push('X'); // Compilation Error: cannot borrow as mutable// 但是,我们无法在cq上访问push方法// 因为cq指针指向的值是immutable value,而push方法会改变这个immutable value// 编译器看到这个矛盾,并报出编译错误。let (o, y) = cq.split(); // Compilation Error// ^ cannot move out of an `Rc`// 类似地,我们无法在cq上访问split方法。原因不难理解:// --被多个指针指向的一个Rc共享值// --如果通过一个指针把共享值的所有权转移走了// --其他指针就只能一起在风中凌乱了}
仔细思考一下,可以发现,上面两处编译错误,都有些过于严苛了。因为其中的那个Rc值,其引用计数仅为1。因此,通过唯一的引用指针去修改这个值或者转移这个值的所有权,应该也不会发生内存安全问题。只是,目前Rust编译器没有尝试在编译时刻去推断引用计数为1的这种边界情况。
Rc上的两个方法
虽然Rust编译器不会在编译时刻去考虑Rc值引用计数为1的情况,但我们可以在程序运行时刻进行检查,并基于此做出一些高级行为。
第一个方法是get_mut,其基本信息如下图所示:
这个方法附着在类型Rc<T>上,接收一个类型为&mut Rc<T>的参数,返回一个类型为Option<&mut T>的值。这个方法实现的功能是:当一个Rc值不存在其他引用的情况下,返回一个形状为Some(...)的值,其中包含了对共享值的一个可变引用(使用这个可变引用,自然就可以改变这个共享值了);否则,返回一个None值。该方法的实现代码如下图所示:
这段实现代码应该不难看明白。其中,方法Rc::is_unique用于判断这个共享值是否只存在唯一一个引用。unsafe{ .. }是一个容纳不安全代码的代码块,初学者就先别惦记它了。
第一个方法是try_unwrap,其基本信息如下图所示:
这个方法同样也附着在类型Rc<T>上,接收一个类型为Rc<T>的参数,返回一个类型为Result<T, RC<T>>的值。这个方法实现的功能是:当一个Rc值的引用计数为1时,返回一个形状为Ok(...)的值,其中包含了Rc值中包含的那个值;否则,返回一个形状为Err(...)值,其中包含了参数中传入的那个Rc值。需要注意的是,这个函数的参数类型为Rc<T>,前面没有引用操作符&,因此,传入参数的所有权会被转移到函数内部。该方法的实现代码如下图所示: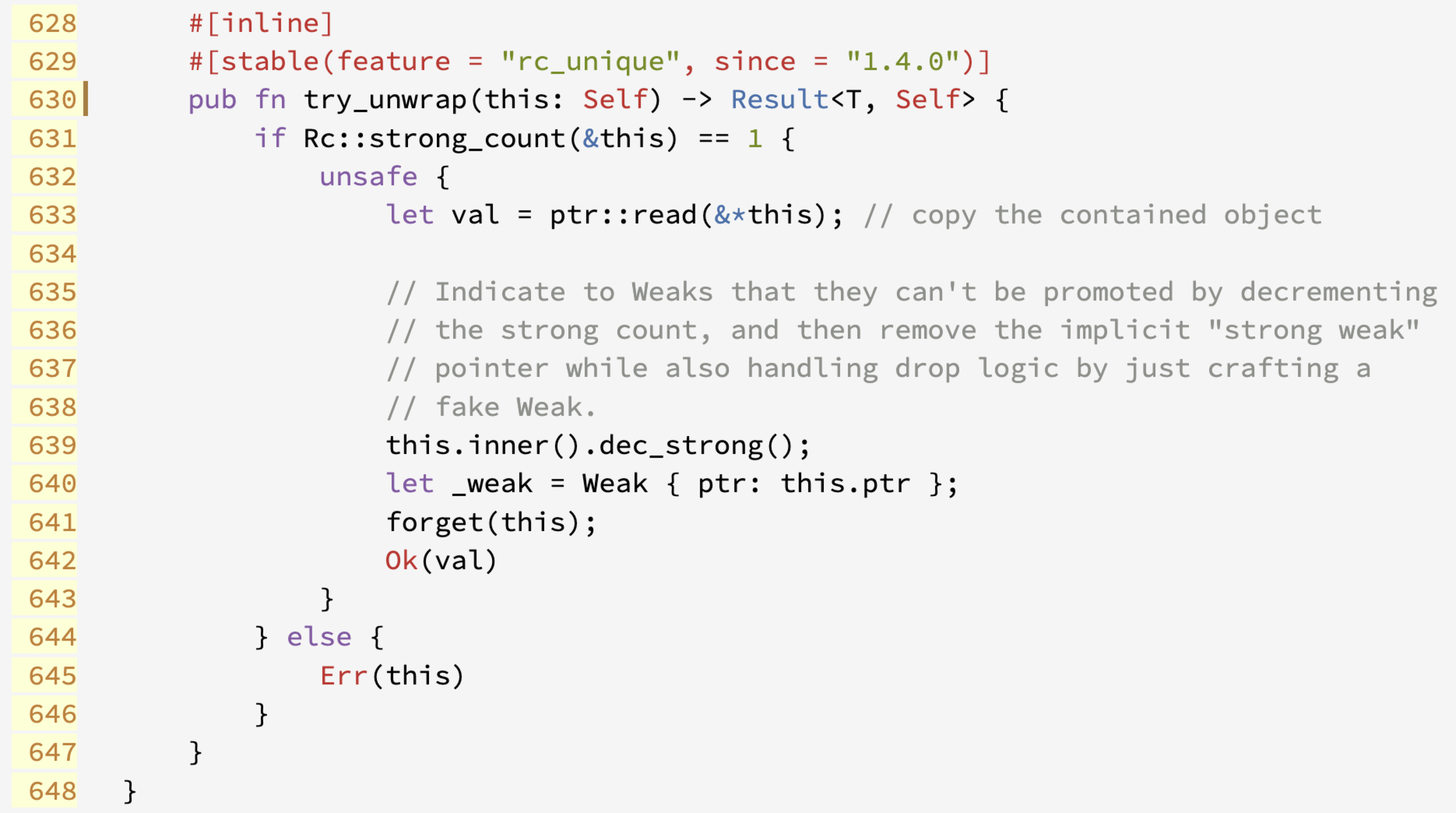
即使你看不懂上面这段代码,也不要悲伤,因为,我想,这个内容大概不会出现在试卷上。其实呢,你应该可以看到两个有点类似的方法Rc::is_unique和Rc::strong_count。两者的差别主要在于是否考虑针对共享值的weak pointer。有兴趣的话,自己到相关资料上学习吧。
我们通过一段代码来熟悉一下这两个方法的使用。
fn main() {use std::rc::Rc;let mut cq = Rc::new(Queue::new());let q = Rc::get_mut(&mut cq).unwrap(); // q is a &mut Queueq.push('P'); q.push('D'); q.pop(); q.push('X');println!("{}", q.is_empty()); //=> truelet q = Rc::try_unwrap(cq).unwrap(); // q is a Queue// ^ cq is movedlet (o, y) = q.split(); // q is movedassert_eq!(o, vec!['D']);assert_eq!(y, vec!['X']);}
为self参数声明类型
上文中讲到,一个类型附着的一个方法,如果具有self参数,其存在一种简便的书写方法,可以不必书写self参数的完整类型。但是,在一些特殊情况下,我们仍然需要为self参数声明完整的类型。请先看如下的代码示例:
use std::rc::Rc;#[derive(Debug)]struct Node {tag: String,children: Vec<Rc<Node>>}// 以上声明了一个类型Node,它包含两个分量。// 第一个分量的名称为tag,类型为String。其作用大概是给Node实例赋予一个名字。// 第二个分量的名称为children,类型为Vec<Rc<Node>>。// 这个分量的作用是用一个向量存放Node实例的子节点// 这里稍微奇怪的地方在于向量中元素的类型为Rc<Node>// 这样做的一个好处是:一个Node实例可以被多个变量共享。// 以下声明了一个impl Node { ... }代码块,其中包含了两个方法impl Node {fn new(tag: &str) -> Self {Self {tag: tag.to_string(),children: vec![]}}// 以上方法的作用是创建一个Node实例,其中不包含任何子节点。fn append_to(self, parent: &mut Node) {parent.children.push(Rc::new(self));}// 以上方法的作用是把一个节点self(类型为Node)添加到一个父节点parent上// 该方法的实现只包含一条语句,其含义不难理解}fn main() {let mut p = Node::new("parent");// 创建了一个父节点,并将其赋值给变量p;该变量的类型为 mut Nodelet mut c = Rc::new(Node::new("child"));// 创建了一个子节点,将其放入一个Rc中,并赋值给变量c;该变量的类型为mut Rc<Node>Rc::try_unwrap(c).unwrap().append_to(&mut p);// 这是一行惨不忍睹的代码// 1. 一个Rc中的值被取出来,然后被move到方法 append_to 中// 2. 在 append_to 方法中,这个值又被move到一个Rc中// 3. 这里存在明显不必要的操作println!("{:?}", p);}
如果上面代码示例中的情况在实际使用中广泛存在,那么,我们可以为apped_to方法的self参数明确声明一个对应的类型,来消除这种不必要的操作。修改后的代码如下:
use std::rc::Rc;#[derive(Debug)]struct Node {tag: String,children: Vec<Rc<Node>>}impl Node {fn new(tag: &str) -> Self {Self {tag: tag.to_string(),children: vec![]}}// 下面方法的self参数,其声明方式从 self 变为 self: Rc<Self>fn append_to(self: Rc<Self>, parent: &mut Node) {parent.children.push(self);// 因为self已经是一个Rc,可以直接把它push到children中}}fn main() {let mut p = Node::new("parent");let mut c = Rc::new(Node::new("child"));c.append_to(&mut p);// 1. c的所有权被move到方法 append_to 中// 2. 在 append_to 方法中,这个值又被move到一个向量中// 现在看起来,是不是清爽多了;简直就是强迫症的救星!println!("{:?}", p);}
在Struct上附着常量
类似于为Struct附着方法,我们也可以在impl代码块内为Struct附着常量。请看如下的代码示例:
#[derive(Debug)]pub struct Vec2D {x: f32,y: f32}impl Vec2D {const NAME: &'static str = "Vec2D";// 为什么要给NAME的类型指定静态生存期呢?// 如果你不知道原因,尝试把这个生存期去掉,看看编译器会报出什么错误const ZERO: Self = Self { x: 0.0, y: 0.0};const UNIT: Self = Self { x: 1.0, y: 0.0};fn scaled_by(&self, num: f32) -> Self {Self { x: self.x * num, y: self.y * num }}}fn main() {println!("{}", Vec2D::NAME);println!("{:?}", Vec2D::UNIT.scaled_by(2.0));}
在上面的文字中,我们介绍了如何通过impl代码块在Struct上附着方法和常量。需要进一步说明的信息有3点:
- 对Rust语言中的任何类型(不仅仅局限于Struct类型)而言,都可以通过impl代码块为其附着方法和常量
- 一个类型,可以具有多个impl代码块,但是它们必须全部出现在类型所在的crate中
- Rust不允许在一个类型所在的crate外声明该类型的impl代码块
Generic Struct
在上面的代码示例中,我们声明了Queue类型,它可以对一组char类型的值进行排队。这里存在一个明显的问题:如果需要对其他类型的值进行排队,我需要把Queue相关代码复制后把其中的char全部替换为另一种类型。与C++或其他语言类似,Rust提供了Generic机制来解决这个问题。请看下面的代码示例: ```rust[derive(Debug)]
pub struct Queue{ older: Vec , ynger: Vec } // 上面的Struct类型是一种Generic Struct,因为它带有类型参数T // 这个Struct类型,应做如下理解: // —对于任何类型T,Queue 是一个Struct类型,其中包含两个分量,类型均为Vec
// 下面的impl
pub fn is_empty(&self) -> bool {self.older.is_empty() && self.ynger.is_empty()}pub fn push(&mut self, t: T) {self.ynger.push(t);}pub fn pop(&mut self) -> Option<T> {if self.older.is_empty() {if self.ynger.is_empty() {return None;}use std::mem::swap;swap(&mut self.older, &mut self.ynger);self.older.reverse();}self.older.pop()}pub fn split(self) -> (Vec<T>, Vec<T>) {(self.older, self.ynger)}
}
// 下面的 impl Queue
fn main() {
let mut q = Queue::
q.push(2.1); q.push(3.1); q.pop(); q.push(1.1);println!("{}", q.sum()); //=> 4.2
}
<a name="xul8a"></a>## 带有生存期参数的Struct当一个Struct类型的某一个或多个分量的类型是引用类型时,或者分量的类型具有生命期参数时,我们需要为这个Struct类型声明生存期参数。请看下面的示例:```ruststruct Extrema<'elt> {min: &'elt i32, max: &'elt i32}// 以上声明的Struct类型具有两个分量,类型均为&i32// 我们通过声明生存期参数,指定这两个分量具有相同的生存期// 这下面这个函数的签名中,我们声明了它具有一个生存期参数,且声明其参数与返回值具有相同的生存期// 按照我们在前文中的叙述,这种情况下即使不声明生存期参数,编译器也会自动推断出相同的生存期效果fn find_extrema<'s>(slice: &'s [i32]) -> Extrema<'s> {let mut min = &slice[0];let mut max = min;for v in &slice[1..] {if v < min { min = v; }else if v > max { max = v; }}Extrema { min, max }}fn main() {let a = [0, -3, 8, -15, 42];let e = find_extrema(&a);println!("{}", e.min); //=> -15println!("{}", e.max); //=> 42}
为Struct附着常用Traits
可以看到,声明一个Struct是非常方便的。例如,使用下面的代码片段,我们可以声明一个Struct用于表示二维空间中的点:
struct Point {x: f64y: f64}
定义的方式很简洁直观。但是,使用起来却没有那么方便。例如:
- Point类型not copyable,虽然它的每一个分量都是copyable。这导致的一个后果是:当把Pointx类型的变量赋值给另一个变量或传入一个函数时,会发生所有权的转移;而有时,这并不是我们所期望的。
- Point类型not cloneable。如果要克隆一个Point类型的值,必须自己编写克隆函数;很麻烦。
- Point类型not printable:无法通过
println!("{:?}", ...)语句打印一个Point类型的值。这给程序的调试带来了显然的不便捷性。同样,你可以通过手工实现特定的方法来实现Point类型printable;很麻烦。 - 无法通过
==或!=操作符判断两个Point类型的值是否相等。
以上列出的每一种期望特性,在Rust中被称为一个trait。Tarit大概对应于Java语言中的interface,但绝对不是完全等价于interface;这一点,我们在后文中会详细介绍。
对于每一种自定义类型,如果都需要程序员手工实现这些常用的trait,实在是不方便。为此,Rust提供了相应的attribute声明,告诉编译器针对自定义的类型自动生成相应的trait。具体声明方式如下:
#[derive(Copy, Clone, Debug, PartialEq)]struct Point {x: f64y: f64}
其中:Copy、Clone、Debug、PartialEq是Rust语言中定义的4个trait,分别对应于上面的四种特性。其中,对于Copytrait的声明,如果当前Type无法被实现为copy type,则编译器会报错。
Interior Mutability
:::info
对于这部分的内容,我目前的理解还不够透彻。如果有错误或不合适的地方,请指出。
:::
Rust编译器在编译时刻确保如下性质成立:
:::warning
共享引用指向的值不可被改变
(Shared references are immutable)
:::
看到这样的性质,我们不禁要问:
- “共享”(Sharing)与“改变”(Mutating),两者在本质上互斥吗?这种互斥,闻所未闻。
- 既然如此,Rust为何要施加这样的限制呢?据说,同时拥有“共享”与“改变”,经常导致内存安全问题。
- 确实是“经常”,而非总是?是的,经常而非总是。
- 那么,会伤及非经常吗?emmm…
为了让“共享”和“改变”和谐共存,Rust提供了两种Struct类型:Cell<T>和RefCell<T>。这两种类型是一种shareable mutable containers,即:一种容器,可以让改变其中存在的被共享的值。
Cell<T>
在Rust文档中,Cell
可以看到:
- 一个
Cell实例中存放的值,既可以是定长(Sized)的,也可以是不定长的。 - 一个
Cell实例表示了内存中一块可以被改变的区域
下图给出了Cell<T>类型的使用示例。
在上面的示例中:
- 类型
SomeStruct的具有两个分量:分量regular_field的类型为u8;分量special_field的类型为Cell<u8>, - 我们创建了
SomeStruct的一个实例,并将其赋值给不可变变量my_struct - 如不可变变量的性质可知,我们无法改变
my_struct.special_field的值;编译器会确保这一点 - 但是,我们可以使用
Cell<T>上附着的set方法去修改其中存放的那个u8类型的值
从上面这个示例,我们可以大概感受到Interior Mutability(内部可变性)这个概念的含义:
- 从外部来看,
my_struct.special_field的值不可被改变- 也即:如果程序中出现了
my_struct.special_field = ...;这样的赋值语句,即使类型检查能够通过,编译器也一定会报出编译错误
- 也即:如果程序中出现了
- 从内部来看,
my_struct.special_field是一个Cell<T>类型的值;我们可以通过Cell<T>类型上附着的方法去修改cell中存放的那个值。
impl<T> Cell<T> { ... }中定义的方法
这个Generic代码块的含义是:对于任意定长类型T,Cell<T>上附着了一些方法。
方法new的功能是:创建Cell<T>类型的一个实例。其中存放的那个值通过方法的参数传入。显然可知:如果T不是一个Copy类型的值,则参数的所有权会被转移到方法内部。
方法set的功能是:通过Cell<T>实例的共享引用,改变其中存放的那个值。
方法swap的功能是:通过Cell<T>的两个实例的共享引用,交互各自拥有的值。
方法replace的功能是:通过Cell<T>的实例的共享引用,用一个值替换其中存放的值,并返回那个被替换的旧值。
函数into_inner的功能是:把一个Cell
impl<T: Copy> Cell<T> { ... }中定义的方法
这个Generic代码块的含义是:对于任意定Copy类型T,Cell<T>上附着了一些方法。
方法get的功能是:给定Cell<T: Copy>实例的共享引用,返回其中存放的那个值的一个拷贝。
impl<T: ?Sized> Cell<T> { ... }中定义的方法
这个Generic代码块的含义是:对于任意类型T(定长或者非定常),Cell<T>上附着了一些方法。
方法get_mut的功能是:给定Cell<T: ?Sized>实例的一个可变引用,返回对其中存放的那个值的可变引用。
方法from_mut的功能是:给定一个类型为&mut T的值,将这个值封装在一个cell中,并返回这个cell的共享引用。
其它代码块中定义的方法
Cell<T>还通过如下代码块附着了一些方法:
impl<T: Default> Cell<T> { … }impl<T> Cell<[T]> { … }impl<T, const N: usize> Cell<[T; N]> { … }
同时,Cell<T>还实现了一些trait,例如:Clone、Debug、Default等。
如果有兴趣,可以去Rust标准库文档中查阅这些方法。
关于Cell<T>,可以观察到如下事实:
- 对于任意定长类型T的任意实例,可以通过
new、set方法将该值放入一个cell中 - 如果cell中存放了一个定长类型的值,无论cell是否可变,都可通过
swap、replace方法改变其中存放的值 - 如果cell中存放了一个
Copy类型的值,可通过get方法读取其中存放的值;但get方法不适用非Copy类型值 - 若要获得cell中值的可变引用,必须获得cell的可变引用
不存在一个同时满足如下两个条件的cell:A. cell中存放的值非定长; B. cell可变
RefCell<T>Rust语法中存在对“一个值可以同时存在引用”的两条限制(在英文中被称为borrow rules):
对于任意一个值,如下两个条件不能同时成立:
- 存在对这个值的一个或多个共享引用(
&T) - 存在对这个值的一个可变引用(
&mut T)
- 存在对这个值的一个或多个共享引用(
- 对于任意一个值,不能同时存在对这个值的两个或多个可变引用
在一般情况下,Rust会在编译时刻会确保上述borrow rules得到满足;如果不满足,则报出编译错误。
但是,我们可以通过RefCell
**impl<T> RefCell<T> { ... }**
这个Generic代码块的含义是:对于任意定长类型T,RefCell<T>上附着了一些方法。
方法new的功能是:创建RefCell<T>类型的一个实例。其中存放的那个值通过方法的参数传入。
方法into_inner的功能是:获得RefCell
方法replace的功能是:用一个值,替换RefCell<T>类型的一个实例中存放的那个值。
这个方法有可能产生panic:如果RefCell<T>类型的这个实例存放的那个值已经被另一个变量所引用,则该方法会产生panic。这就是前面所说的:通过RefCell
方法swap的功能是:通过RefCell<T>类型的两个实例的共享引用,交互各自拥有的值。
这个方法也有可能发生panic。原因如前所述:该方法调用不满足borrow rules。
**impl<T: ?Sized> RefCell<T> { ... }**
这个Generic代码块的含义是:对于任意类型T(定长或者非定常),RefCell<T>上附着了一些方法。
方法borrow的功能是:获得RefCell<T: ?Sized>类型的一个实例中存放的那个值的共享引用。如果这个值已经存在了可变引用,则该方法调用会产生panic。
这个方法返回的值是一种专门针对RefCell<T>设计的共享引用类型;当该引用类型的值离开当前作用域后,对被引用值的引用就消失了。
下面给出了该方法的两个示例程序:

下面给出borrow方法的非panic版本:
这个方法返回一个Result类型的值:当成功获得RefCell<T: ?Sized>中值的共享引用时,返回一个Ok(...)值;否则,返回一个Err(...)值。
下面给出了该方法的一个使用示例:
下面介绍borrow和try_borrow两个方法对应的可变引用版本:borrow_mut和try_borrow_mut。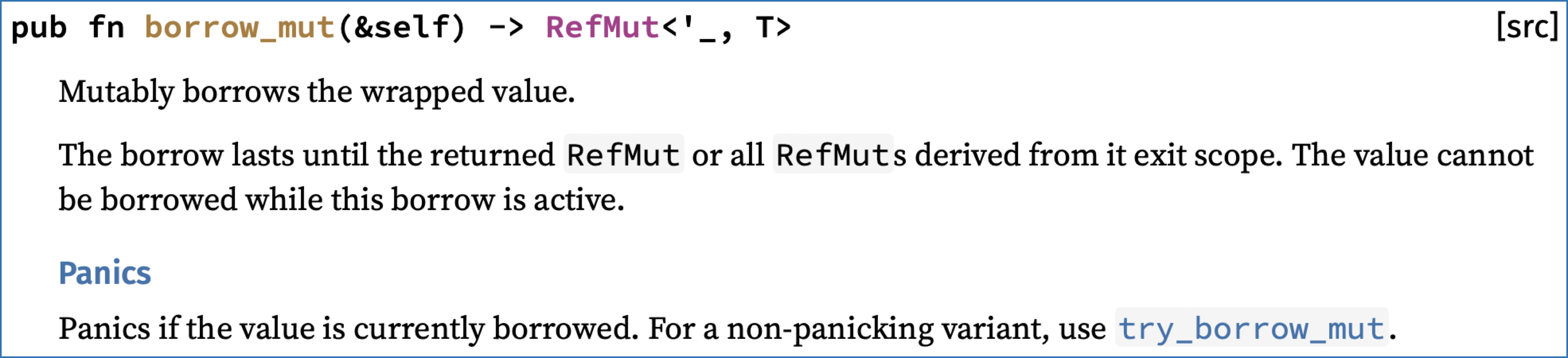
方法borrow_mut的功能是:获得RefCell<T: ?Sized>类型的一个实例中存放的那个值的可变引用。如果这个值已经存在了可变引用或共享引用,则该方法调用会产生panic。
这个方法返回的值是一种专门针对RefCell<T>设计的可变引用类型;当该引用类型的值离开当前作用域后,对被引用值的引用就消失了。
下面给出了该方法的两个示例程序:

下面给出borrow_mut方法的非panic版本:
该方法的一个使用示例如下图所示:
我们用一张表总结一下刚才介绍的这组方法:
| Cell |
RefCell |
|
|---|---|---|
| Sized | new()、set()、into_inner() |
new()、into_inner() |
| ?Sized | swap()、replace() |
_swap_() 、_replace_() |
| Copy | get() |
|
| ?Sized | _brrow_()、_brrow_mut_()try_brrow()、try_brrow_mut() |
上面表格中,斜体方法名表示该方法可能会产生panic。
Rust官方文档中的三个示例
在Rust语言标准库文档中,针对Interior Mutability,给出了三个示例。
Introducing mutability inside of something immutable
第一个示例主要关于如何在一个外表看起来不可变的变量内部引入可变性。请看如下代码示例。
在这个示例中:
- 声明了一个不可变变量
shared_map,其类型为Rc<RefCell<HashMap>>。 - 然后,在一个代码块内部,通过
borrow_mut方法获得RefCell中存放的那个HashMap值的可变引用,并利用这个可变引用对HashMap值进行了修改;这个代码块结束后,对HashMap值的可变引用生存期结束。 最后,通过
borrow方法获得RefCell中存放的那个HashMap值的共享引用,并利用这个共享引用调用了HashMap值上的只读方法values。Implementation details of logically-immutable methods
第二个示例主要关于如何实现一个逻辑上不可变的方法(即:该方法的执行不会在逻辑上改变所附着的那个值)。请看如下代码示例。

在这个示例中:Graph类型的一个分量是span_tree_cache,其类型为RefCell<Option<Vec<(i32, i32)>>>。这个分量的主要作用是作为计算过程中的一个缓存区。- 具体而言,当在一个
Graph实例上调用minumum_spanning_tree方法时,首先查看span_tree_cache中是否存在一个Some值;如果存在,则直接将其克隆后返回;否则,调用一个计算量很大的函数计算出span_tree,放入minumum_spanning_tree,然后对其中的值克隆后返回Mutating implementations of Clone
第三个示例主要关于Rc上的clone方法。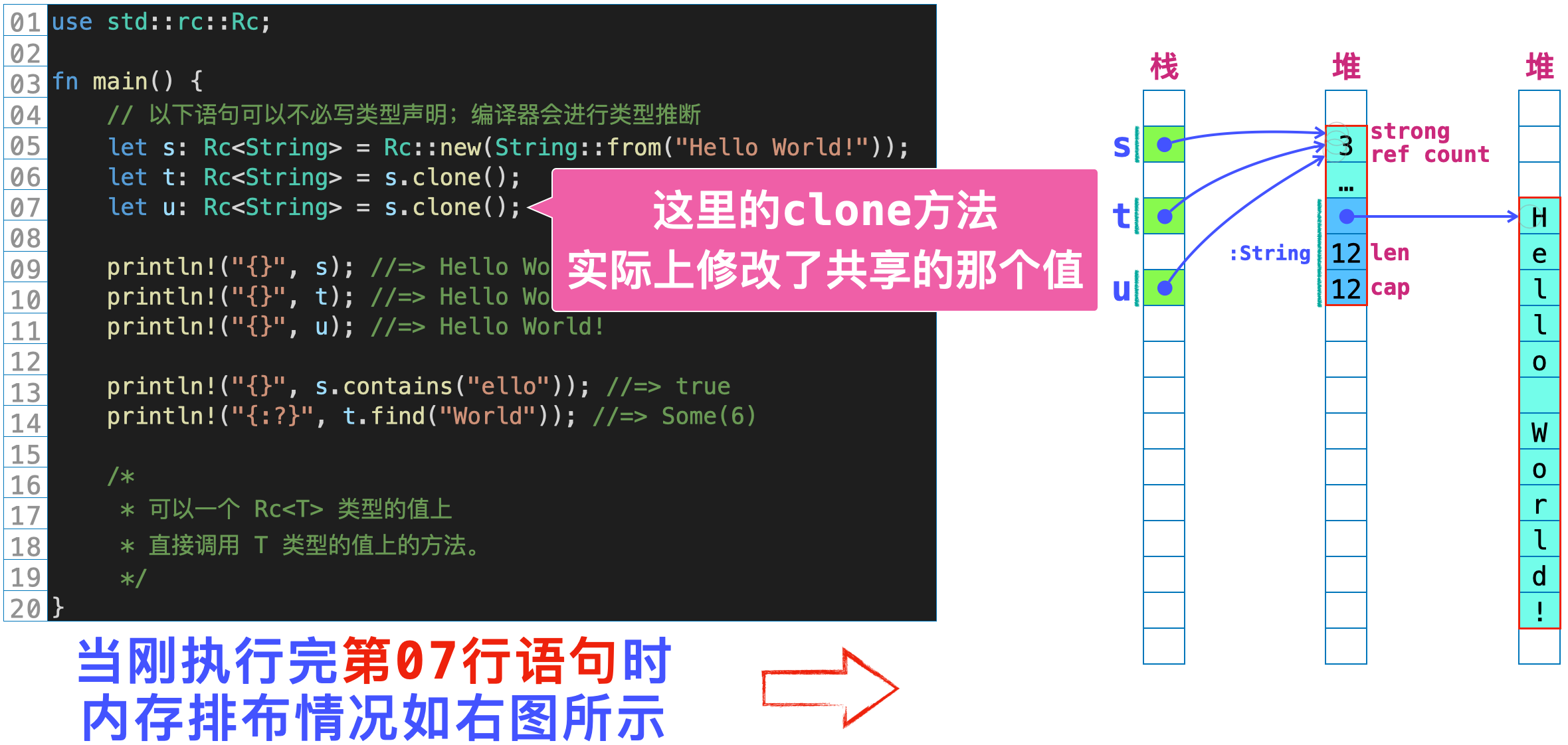
当我们在一个Rc值上调用clone方法时,实际上对Rc指向的那个值进行了改变。这种效果就是利用Interior Mutability实现的。
:::warning 本章内容到此结束 :::

若有收获,就点个赞吧
0 人点赞
