这是我们探索在绩效分析和能力规划中使用平均值的两个部分系列中的第二个。第 1 部分描述了一些简单的实验,揭示了负载平均值(LA Triplets)是如何在 UNIX 内核中计算的。在第 2 部分中,我将比较 UNIX 负载平均方法和其他平均方法,因为它们适用于容量规划和性能分析。
1. 回顾第 1 部分
这是两部分系列中的第二部分,我探讨了平均数在性能分析和容量规划中的使用。平均数有很多表现形式,例如,算术平均数(通常的)、移动平均数(经常用于财务规划)、几何平均数(用于SPEC CPU基准)、谐波平均数(使用得不够),仅举几例。
在第一部分中,我描述了一些简单的实验,揭示了UNIX®内核(好吧,反正是Linux内核,因为该源代码可以在线获得)中如何计算负载平均数(LA Triplets)。我们发现了一个叫做CALC_LOAD的C语言程序来完成所有的工作。以 1 分钟的平均值为例,CALC_LOAD与数学表达式相同:

对应于指数阻尼移动平均数。它说你当前的负载等于你上次的负载(由适合 1 分钟报告的指数系数衰减)加上当前活动进程的数量(由适合 1 分钟报告的指数增加系数加权)。这里显示的 1 分钟负载平均值与 5 分钟和 15 分钟负载平均值之间的唯一区别是指数因子的值;我在第一部分讨论的神奇数字。
我在第一部分中提出的另一个观点是,我们作为性能分析员,如果 LA Triplets 以相反的顺序报告,会更好。15,5,1,因为这个顺序与通常的惯例一致,即时间顺序从左到右流动。这样一来,就更容易把 LA Triplets 看成是一种趋势(我猜想这也是其原意的一部分)。
在这里,在第二部分,我将把 UNIX 负载平均法与其他平均法进行比较,因为它们适用于容量规划和性能分析。
2. 指数平滑
指数平滑(电气工程类型也称为滤波)是在进一步分析前对高度可变的数据进行预处理的一种通用方法。这种类型的过滤器在大多数数据分析工具中都可以使用,例如。EXCEL、Mathematica和Minitab。平滑化方程是一个迭代函数,具有一般的形式: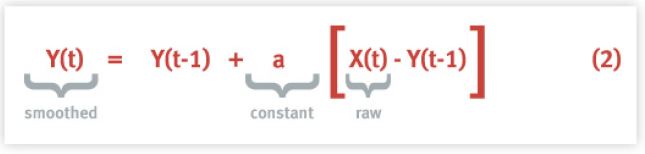
其中 是输入的原始数据,
是输入的原始数据, 是由于前一次平滑迭代的值,
是由于前一次平滑迭代的值, 是新的平滑值。如果它看起来有点乱七八糟,那应该是这样的。
是新的平滑值。如果它看起来有点乱七八糟,那应该是这样的。
2.1 平滑负载
以相同格式表示 UNIX 负载平均方法(参见方程 (1))会产生:
如果我们选择 ,公式(3)等同于(2)。常数a被称为平滑常数,范围在0.0和1.0之间(换句话说,你可以把它看作一个百分比)。EXCEL使用的术语是阻尼系数的数量(1-a)。
,公式(3)等同于(2)。常数a被称为平滑常数,范围在0.0和1.0之间(换句话说,你可以把它看作一个百分比)。EXCEL使用的术语是阻尼系数的数量(1-a)。
a的值决定了当前平滑迭代对产生先前平滑迭代的数据变化的百分比。a的值越大,对数据变化的反应越快,但产生的曲线越粗,而不是越平滑(阻尼越小)。相反,较小的a值产生非常平滑的曲线,但需要更长的时间来补偿数据的波动(阻尼更强)。那么,应该使用多大的a值呢?
2.2 关键阻尼
EXCEL 文档建议 0.20 到 0.30 是 a 的 “合理 “值。这是一个明显的误导,因为它没有考虑到你准备容忍多少数据的变化(例如,误差)。
从第1节的分析中,我们现在可以看到, 在 UNIX 负载平均值中起着阻尼系数的作用。因此,UNIX 负载平均值相当于一个指数阻尼的移动平均值。更常见的移动平均数(金融分析师经常使用的类型)只是一个简单的算术平均数,超过一些数据点。
在 UNIX 负载平均值中起着阻尼系数的作用。因此,UNIX 负载平均值相当于一个指数阻尼的移动平均值。更常见的移动平均数(金融分析师经常使用的类型)只是一个简单的算术平均数,超过一些数据点。
下面的表1显示了各自的平滑和阻尼系数,这些系数是基于第一部分中描述的神奇数字。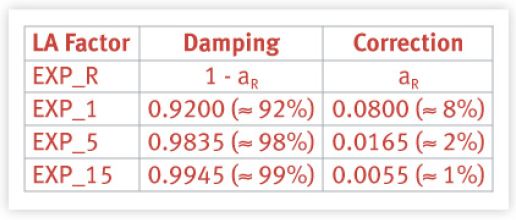
a的值由 计算,其中R=1、5或15。从表1中我们看到,对数据变化的修正越大(即aR),结果对这些变化的反应越大,因此我们看到输出中的阻尼(1-aR)越小。
计算,其中R=1、5或15。从表1中我们看到,对数据变化的修正越大(即aR),结果对这些变化的反应越大,因此我们看到输出中的阻尼(1-aR)越小。
这就是为什么 1 分钟的报告比 15 分钟的报告对负荷的变化反应更快。还要注意的是,对于 1 分钟报告来说,UNIX 负载平均值的最大修正值约为 8%,远没有达到 EXCEL 建议的 20% 或 30%。
3. 其他平均值
接下来,我们将这些随时间变化的平滑平均数与性能分析和容量规划中使用的一些更熟悉的平均数形式进行比较。
3.1 稳定状态平均值
在容量规划、基准测试和其他类型的性能建模中,最常用的平均值是稳态平均值。
就 UNIX 负载平均值而言,这相当于在足够长的时间(T)内观察报告的负载,如图1所示。
请注意,系统管理员几乎从未以这种方式使用负载平均指标。避免这种情况的部分原因在于,LA指标被嵌入到其他命令中(在不同的 UNIX 平台上有所不同),需要被提取出来。TeamQuest IT服务分析器是一个很好的例子,它部分地规避了传统UNIX性能工具中的这种经典限制。
3.2 示例应用程序
要确定上述时间系列的稳定状态平均值,我们首先需要将图下的区域拆分为等宽度的均匀列集。
- 每一列的宽度对应于统一时间步长Δt。
- 每一列的高度对应于
 的瞬时队列长度。
的瞬时队列长度。 - 每一列的面积由
 (长度*高度)给出。
(长度*高度)给出。 - 曲线下的总面积为

然后,时间平均队列长度 Q(稳定状态值)按分数近似:
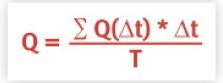
观测周期越长,稳定状态值越准确。
图2使这个想法更加明确。它显示了一个时间段,其中六个请求被排入(代表近似列的黑色曲线)。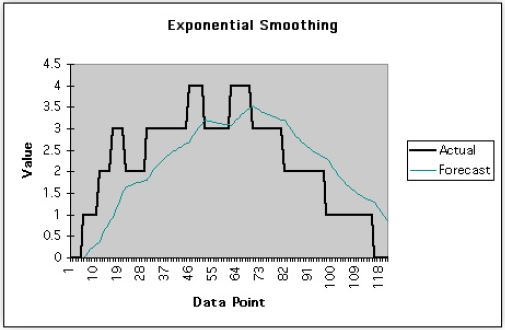
叠加在上面的是与1分钟负荷平均值相对应的曲线。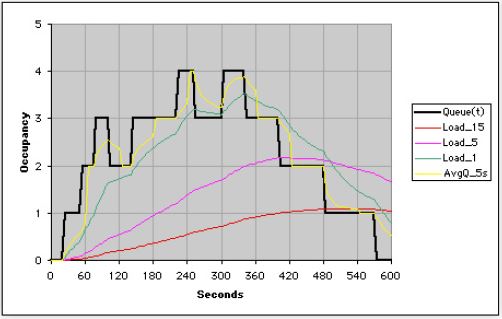
图 3 显示了所有三个负载平均指标的叠加,以及 5 秒钟的样本平均。
3.3 利特尔法则
考虑一下 UNIX 的 Timeshare 调度器。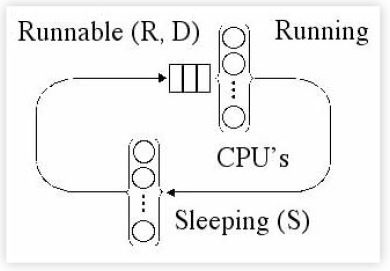
图4中的示意图根据通常的 UNIX 惯例描述了调度器的状态。:
- N: 系统中的进程
- R:运行或可运行的进程
- D:不间断的进程
- S: 处于睡眠状态的进程
将第 3.1 节中定义的稳态平均数应用于其他众所周知的性能指标,如:
- Z:睡眠状态下的平均时间
- X:平均进程完成率
- S: 平均执行量子(以CPU刻度计)
- W: 在运行和可运行状态下花费的总时间
允许我们表达它们与Q(稳态队列长度)之间一些非常强大的关系。
其中一个关系是利特尔定律

将平均队列长度(Q) 与平均吞吐量 (X) 和时间(W) 联系起来:
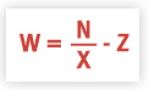
从某种意义上说,Q是负载平均值的平均值。
这些同样的平均数被用于性能分析工具,如Pretty Damn Quick和TeamQuest Model。
请注意,如果不采取稳态平均数,这种有洞察力的关系几乎不可能被认识。利特尔定律就是一个很好的例子。在1961年J.D.Little发表了他现在著名的关系证明之前,它已经作为一种表现的民间传说存在了很多年。
4. 摘要
那么,我们从这一切中学到了什么?在某些 UNIX 命令中无辜地藏着的那三个小数字毕竟不是那么微不足道。第一点是,负载在这里指的是运行队列的长度(即在运行队列中等待的进程数与当前执行的进程数之和)。因此,这个数字是绝对的(而不是相对的),因此它可以是无界的;与利用率(又称 “负载”,在队列理论的说法中)不同。
此外,它们必须在内核中计算,因此必须有效计算。因此,需要使用定点算术,这就产生了内核代码中那些看起来非常奇怪的常数。在第一部分的末尾,我向大家展示了魔法数字实际上只是用定点符号表示的指数衰减和上升常数。
在第二部分中,我们发现这些常数实际上是为原始瞬时负载值提供指数平滑。更正式地说,UNIX 的负载平均值是一个指数平滑的移动平均函数。通过这种方式,突然的变化可以被阻尼,这样它们就不会对长期的情况产生重大影响。最后,我们将指数阻尼平均数与更常见的平均数类型进行了比较,这些平均数在基准和性能模型中作为指标出现。
平均而言,UNIX 负载平均指标肯定不是你的平均数。
原文链接
https://www.helpsystems.com/resources/guides/unix-load-average-part-2-not-your-average-average

若有收获,就点个赞吧
0 人点赞
