hashMap的底层数据结构
hashMap底层数据结构是:1.7数组加链表的形式。1.8数组链表+红黑树。
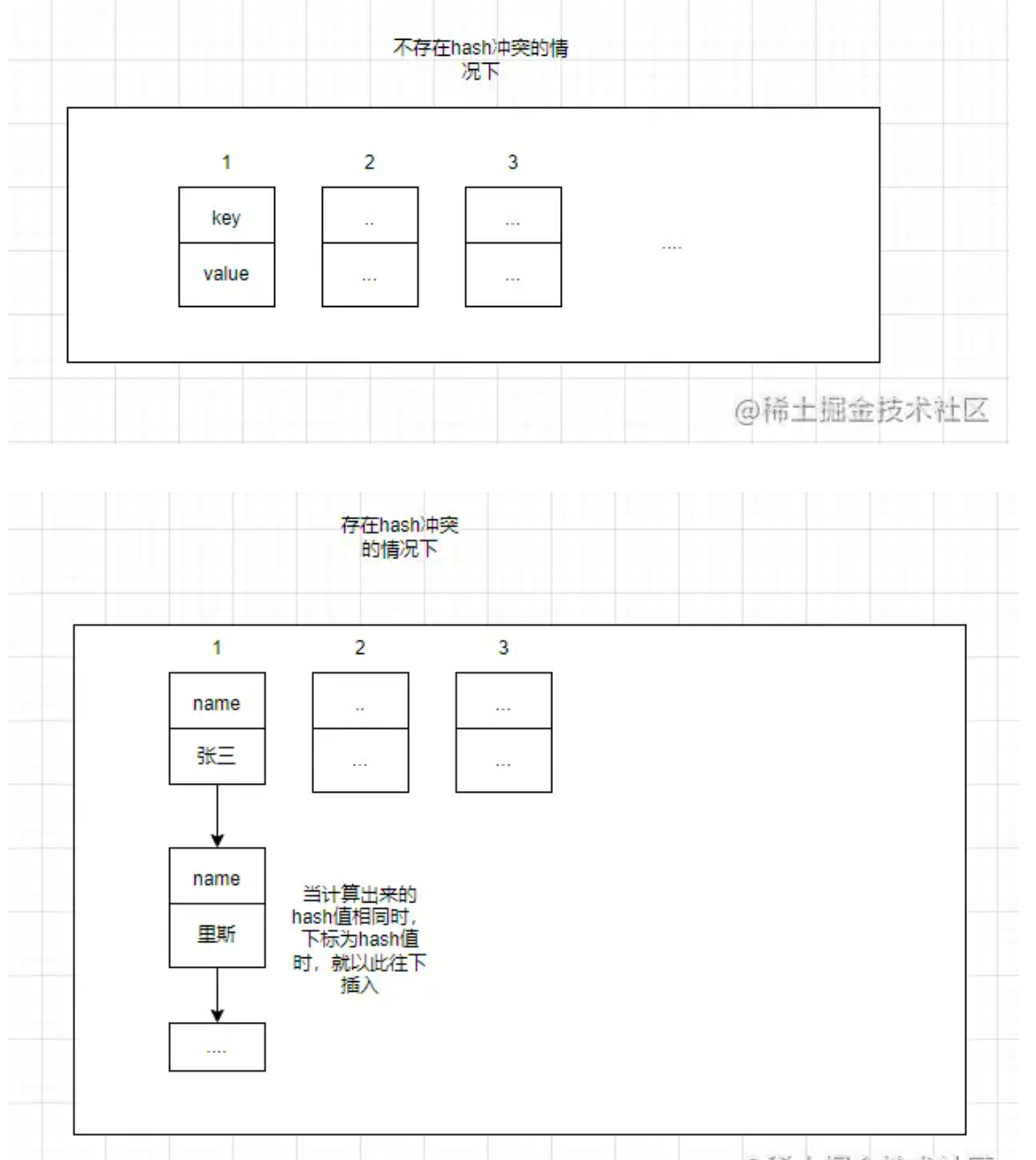
注意:为什么会出现hash冲突,我们在put数据进入hashmap中时,都是使用得hash算法,所以存在hash冲突,并且这也是为什么hashmap使用链表得原因。
hashmap得基本概念
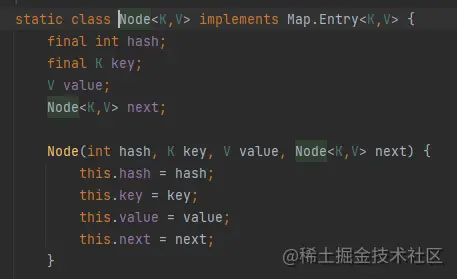
hashmap在jdk1.7之前,每个key-value都叫一个entry,1.8及其之后叫node,node包含hash值,key,value,和下一个节点。
hashMap得基本属性及其默认值:
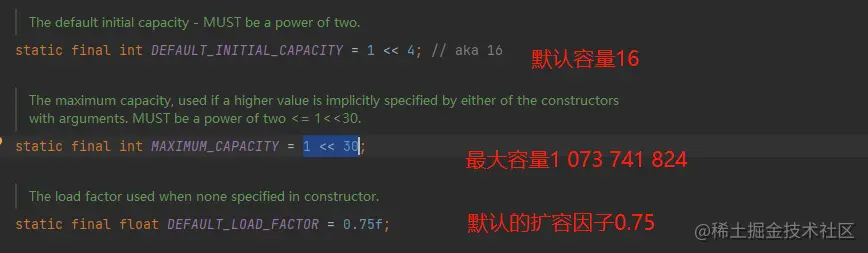
位与运算比算数计算的效率高了很多。默认16通常是一个经验值。
扩容机制
因为扩容因子是0.75,当我们插入的数据量大于总容量的75%时就扩容。分为两步
- 扩容:创建一个新的Entry空数组,长度是原数组的2倍。
- ReHash:遍历原Entry数组,把所有的Entry重新Hash到新数组。
- 为什么不直接复制,而是重新使用hash算法?
会,因为扩容后,hash规则改变,我们通过重新计算hash值。
头插法和尾插法
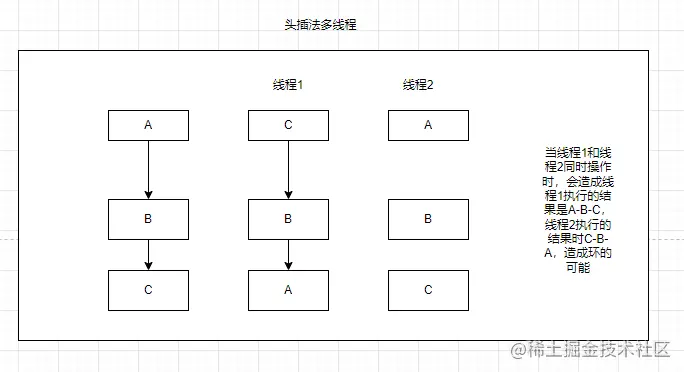
jdk1.7使用头插法。
在扩容的时候,可能会出现环的问题 a->b,b->a.
jdk1.8之后引入了红黑树,并且使用尾插法的形式。
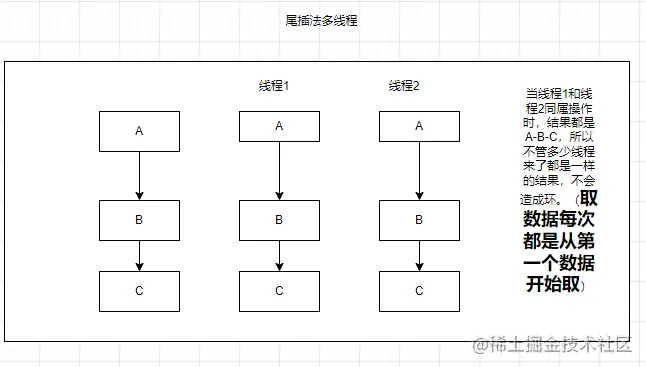
具体执行流程,借鉴如下:
为什么重新equals方法的时候最好要重写hashCode方法?
Object中的equals方法是为了比较两个对象是否相等,这里比较的是地址。比如hashMap通过hashCode计算hash值,当我们在只重新equals时,两个对象的地址不同,而hash值时相同的。是的,所以如果我们对equals方法进行了重写,建议一定要对hashCode方法重写,以保证相同的对象返回相同的hash值,不同的对象返回不同的hash值。
Hashmap中的链表大小超过八个时会自动转化为红黑树,当删除小于六时重新变为链表,为啥呢?
根据泊松分布,在负载因子默认为0.75的时候,单个hash槽内元素个数为8的概率小于百万分之一,所以将7作为一个分水岭,等于7的时候不转换,大于等于8的时候才进行转换,小于等于6的时候就化为链表。
进阶
HashMap在1.8之后是线程安全的吗?(不会改变数据的顺序)
不是线程安全的,我们在put/get值的时候,没加同步锁,所以无法保证,上一秒你put的值,下一秒你就能取到。

如何保证HashMap线程安全?
使用Collections.synchronizedMap(Map)创建线程安全的map集合
HashTable
HashTable直接在方法上直接使用synchronized关键字。
待补充
CurrentHashMap
待补充

若有收获,就点个赞吧
0 人点赞
