常用数据结构
- 数组(Array)
- 栈( Stack)
- 队列(Queue)
- 链表( Linked List)
- 树( Tree)
- 图(Graph)
- 堆(Heap)
-
栈
栈的应用场景
需要后进先出的场景。
- 比如:十进制转二进制、判断字符串的括号是否有效、函数调用堆栈…






队列


队列的应用场景
- 需要先进先出的场景。
- 比如:食堂排队打饭、JS异步中的任务队列、计算最近请求次数。


优先队列(PriorityQueue)
实现机制:
- Heap (Binary、Binomial、Fibonacci)
- Binary Search Tree
链表
- 链表是一种物理结构(非逻辑结构),类似于数组
- JS 中没有链表,但可以用 Object 模拟实现
- 数组需要一段连续的内存区间(连续即表示有序),而链表是零散的(数据可以存在任意地方,用指针连接)
- 链表节点的数据结构 {value,next?,prev?}
单向链表
使用 next 指针
双向链表
使用 next + prev 指针
链表VS数组
- 都是有序结构
- 数组:增删非首尾元素时往往需要移动元素。查询快O(1),新增和删除慢O(n)。因为数组只要知道索引就能快速找到对应的数据,而链表上的数据不是连续的,需要一个个的去比较。
- 链表:查询慢O(n),新增和删除快O(1)。增删非首尾元素,不需要移动元素,只需要更改 next 的指向即可。
链表和数组,哪个实现队列更快?
- 虽然数组也能实现队列,但是有性能问题的。数组元素入队列的话,需要 O(1),出队列的话,需要 O(n)。而链表入列和出列都是 O(1)。
- 空间复杂度都是O(n)
- add 时间复杂度:链表O(1);数组O(1)
- delete 时间复杂度:链表O(1);数组O(n)
题目
删除链表中的节点

反转链表


两数相加

删除排序链表中的重复元素

环形链表



集合
- 一种无序且唯一的数据结构。
- ES6 中就有集合,如:Set。
- 集合的常用操作:去重、判断某元素是否在集合中、求交集
HashSet
- HashTable
- Hash Function
- Collisions
TreeSet
- HashTable
- Hash Function
- Collisions
题目
两个数组的交集

散列表/哈希表/字典/映射
散列表/哈希表
- 维基百科定义:散列表(HashTable,也叫哈希表 HashMap ),是根据键(Key)而直接访问在内存存储位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。一个通俗的例子是,为了查找电话簿中某人的号码,可以创建一个按照人名首字母顺序排列的表(即建立人名 x 到首字母 F(x)的一个函数关系), 在首字母为 W 的表中查找“王”姓的电话号码,显然比直接查找就要快得多。这里使用人名作为关键字,“取首字母”是这个例子中散列函数的函数法则 F(), 存放首字母的表对应散列表。关键字和函数法则理论上可以任意确定。
- HashTable:哈希表,又称散列表,英文名为Hash Table。实质上是一种对数组进行了扩展的数据结构,可以说哈希表是在数组支持下标直接索引数据(value)的基础上进行优化并尽可能在常数时间内对数据进行增、删、改、查等操作。
- Hash Function:散列函数又称散列算法、哈希函数,是一种从任何一种数据中创建小的数字“指纹”的方法。散列函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来。该函数将数据打乱混合,重新创建一个叫做散列值(hash values,hash codes,hash sums,或 hashes)的指纹。散列值通常用一个短的随机字母和数字组成的字符串来代表。好的散列函数在输入域中很少出现散列冲突。在散列表和数据处理中,不抑制冲突来区别数据,会使得数据库记录更难找到。
- Collisions:不管什么数据结构,存储空间都是有限的,也就是说存储的数据量是一定的,那么当要存储的数据量超过这一数据结构当前容量(capacity),就会发生至少两个键值对应在哈希表的同一个位置。比如,哈希表中有十个位置,那么现在要存放十一个数字到十个位置,即至少有两个数字会存放到同一个位置,这也就是鸽巢原理(抽屉原理)。
字典/映射
- 映射(Map)/字典(Dictionary)也是一种的以 键-值对 形式存储唯一值的逻辑数据结构,JS 中对应的物理结构:Object、Map。
字典/映射和散列表/哈希表的区别
- 散列表是实现字典的方式之一:字典注重的是“一个键值(key)对应一个值(value)“的概念,而字典的实现既可以是二维数组,也可以是哈希表;
题目
两个数组的交集

有效的括号

括号生成
const generateParenthesis = function (n) {const set = new Set();const fn = (left, right, n, result) => {if (left === n && right === n) {set.add(result);return}if (left < n) {fn(left + 1, right, n, result + "(");}if (right < n && left > right) {fn(left, right + 1, n, result + ")");}}fn(0, 0, n, '');return Array.from(set);}
两数之和

无重复字符的最长子串



最小覆盖子串




有效的字母异位词
- 异位词:两个字符串长度一致,字符串里面用到的字母一致,唯一不同的是顺序。如:”anagram”、”nagaram”。
- 方法一:将两个字符串排序,排序好后直接比较是否相等;
- 方法二:使用 map 存储每个字母并记录每个字母出现的次数,然后比对两个 map;
树
- 一种分层数据的抽象模型。
- 前端工作中常见的树包括:DOM树、级联选择、树形控件.…

- JS中没有树,但是可以用 Object 和 Array 构建树。
- 树的常用操作:深度/广度优先遍历、先/中/后序遍历。

深度/广度优先遍历

深度优先遍历算法口诀
- 访问根节点。
- 对根节点的 children 挨个进行深度优先遍历。
const tree = {val: 'a',children: [{val: 'b',children: [{val: 'd',children: [],},{val: 'e',children: [],}],},{val: 'c',children: [{val: 'f',children: [],},{val: 'g',children: [],}],}],};const dfs = (root) => {console.log(root.val);root.children.forEach(dfs);};dfs(tree);
广度优先遍历算法口诀
- 新建一个队列,把根节点入队;
- 把队头出队并访问;
- 把队头的 children 挨个入队;
- 重复第二、三步,直到队列为空;
const tree = {val: 'a',children: [{val: 'b',children: [{val: 'd',children: [],},{val: 'e',children: [],}],},{val: 'c',children: [{val: 'f',children: [],},{val: 'g',children: [],}],}],};const bfs = (root) => {const q = [root];while (q.length > 0) {const n = q.shift();console.log(n.val);n.children.forEach(child => {q.push(child);});}};bfs(tree);
二叉树
- 树中每个节点最多只能有两个子节点(为什么不能有三个及以上的子节点?因为二分法,可以快速的查询树);
- 在 JS 中通常用 Object 来模拟二叉树;
二叉树的遍历方式
- 前序遍历:root->left->right
- 中序遍历:left->root->right
- 后序遍历:left->right->root
先序遍历算法口诀

const bt = {val: 1,left: {val: 2,left: {val: 4,left: null,right: null,},right: {val: 5,left: null,right: null,},},right: {val: 3,left: {val: 6,left: null,right: null,},right: {val: 7,left: null,right: null,},},};const preorder = (root) => {if (!root) { return; }console.log(root.val);preorder(root.left);preorder(root.right);};// 非递归版本// const preorder = (root) => {// if (!root) { return; }// const stack = [root];// while (stack.length) {// const n = stack.pop();// console.log(n.val);// // 栈的执行顺序是后进先出// if (n.right) stack.push(n.right);// if (n.left) stack.push(n.left);// }// };preorder(bt);
中序遍历算法口诀

const inorder = (root) => {if (!root) { return; }inorder(root.left);console.log(root.val);inorder(root.right);};// 非递归版本// const inorder = (root) => {// if (!root) { return; }// const stack = [];// let p = root;// while (stack.length || p) {// while (p) {// stack.push(p);// p = p.left;// }// const n = stack.pop();// console.log(n.val);// p = n.right;// }// };inorder(bt);
后序遍历算法口诀

const postorder = (root) => {if (!root) { return; }postorder(root.left);postorder(root.right);console.log(root.val);};// 非递归版本// const postorder = (root) => {// if (!root) { return; }// const outputStack = [];// const stack = [root];// while (stack.length) {// const n = stack.pop();// outputStack.push(n);// if (n.left) stack.push(n.left);// if (n.right) stack.push(n.right);// }// while(outputStack.length){// const n = outputStack.pop();// console.log(n.val);// }// };postorder(bt);
二叉搜索树


- 搜索树中的某个节点时,只需要比较当前树的根节点的大小,如果当前值小于根节点,那么只需要搜索左侧的子树就行;如果大于根节点,只需要搜索右侧的子树就行。
题目
二叉树的最大深度

二叉树的最小深度

二叉树的层序遍历


二叉树的中序遍历
路径总和

验证二叉搜索树
二叉树的最近公共祖先
二叉搜索树的最近公共祖先
字典树

- 核心思想:空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
- 特点:
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符。
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
- 每个节点的所有子节点包含的字符都不相同。
应用场景

题目
实现 Trie (前缀树)
单词搜索
单词搜索 II
并查集
题目
岛屿数量
省份数量
图
- JS中没有图,但是可以用 Object 和 Array 构建图;
- 图的表示法:邻接矩阵、邻接表、关联矩阵;
- 用了表示节点之间的关系;




图的深度优先遍历算法口诀

const graph = {0: [1, 2],1: [2],2: [0, 3],3: [3]};const visited = new Set();const dfs = (n) => {console.log(n);visited.add(n);graph[n].forEach(c => {if(!visited.has(c)){dfs(c);}});};dfs(2);
图的广度优先遍历算法口诀

const graph = {0: [1, 2],1: [2],2: [0, 3],3: [3]};const visited = new Set();const q = [2];while (q.length) {const n = q.shift();console.log(n);visited.add(n);graph[n].forEach(c => {if (!visited.has(c)) {q.push(c);}});}
题目
有效数字

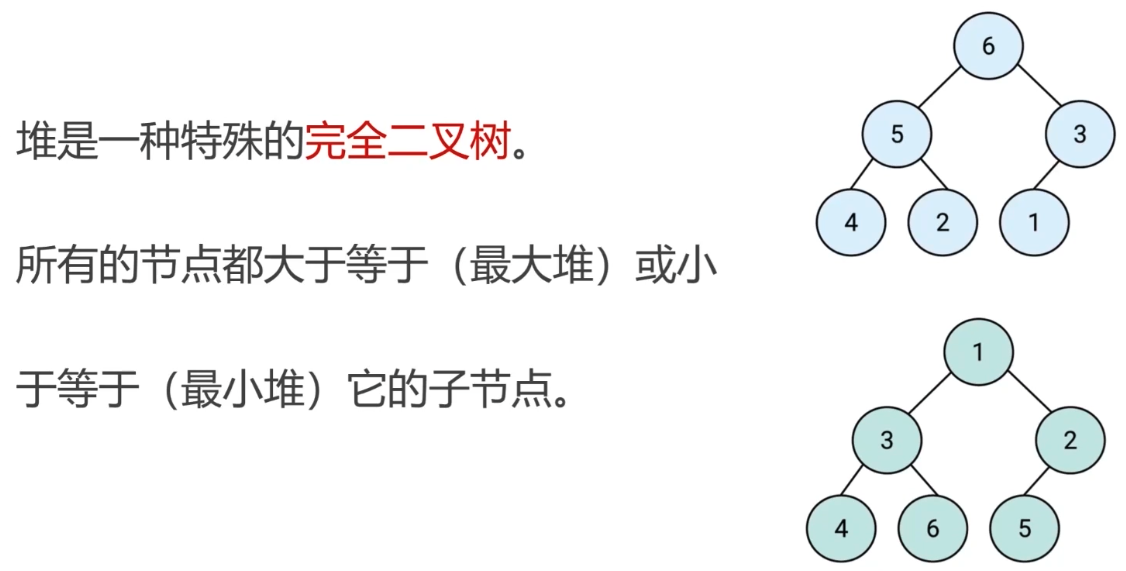
堆

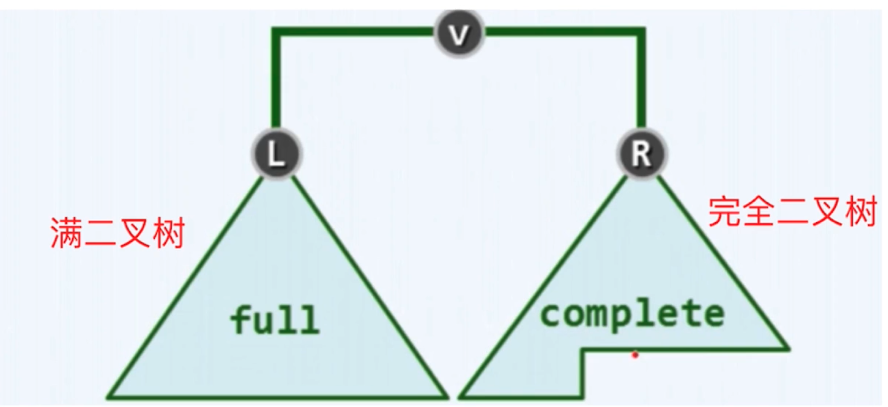
完全二叉树
- 堆是一种特殊的完全二叉树,如果一棵树丛根节点一直到叶子节点为止,每个节点(除了叶子节点外)都有两个子节点,那么我们称之为满二叉树,而如果有部分子节点只有0-1个子节点,那么我们称之为完全二叉树。
- 最大堆:父节点>=子节点,假设三个节点构成一棵子树,父节点的值一定大于子节点。
- 最小堆:父节点<=子节点
堆的节点查找公式
- 数组的首元素就是堆顶元素;

堆的应用
- 堆能高效、快速地找出最大值和最小值,时间复杂度:0(1)。
- 用来找出第 K 个最大(小)元素(常见的算法题就是用堆来解决的)。
- React Fiber 中的任务优先级排列方式就是通过最小堆算法实现的。
实现最小堆算法
https://github.com/yjdjiayou/react-scheduler-easy/blob/main/scheduler/src/SchedulerMinHeap.js
插入

class MinHeap {constructor() {this.heap = [];}swap(i1, i2) {// const tmp = this.heap[i1];// this.heap[i1] = this.heap[i2];// this.heap[i2] = tmp;[this.heap[i1], this.heap[i2]] = [this.heap[i2], this.heap[i1]]}getParentIndex(i) {// return Math.floor((i - 1) / 2);// 位运算:将二进制向右移一位,也就相当于除 2return (i - 1) >> 1;}// O(logn)shiftUp(index) {if (index === 0) return;const parentIndex = this.getParentIndex(index);if (this.heap[parentIndex] > this.heap[index]) {// this.swap(parentIndex, index);[this.heap[index], this.heap[parentIndex]] = [this.heap[parentIndex], this.heap[index]]this.shiftUp(parentIndex);}}insert(val) {this.heap.push(val);this.shiftUp(this.heap.length - 1);}}const a = new MinHeap();a.insert(3)a.insert(2)a.insert(1)console.log(a.heap);

删除堆顶
class MinHeap {constructor() {this.heap = [];}swap(i1, i2) {// const tmp = this.heap[i1];// this.heap[i1] = this.heap[i2];// this.heap[i2] = tmp;[this.heap[i1], this.heap[i2]] = [this.heap[i2], this.heap[i1]]}getParentIndex(i) {// return Math.floor((i - 1) / 2);// 位运算:将二进制向右移一位,也就相当于除 2return (i - 1) >> 1;}getLeftIndex(i) {return i * 2 + 1;}getRightIndex(i) {return i * 2 + 2;}// O(logn)shiftUp(index) {if (index === 0) return;const parentIndex = this.getParentIndex(index);if (this.heap[parentIndex] > this.heap[index]) {this.swap(parentIndex, index);this.shiftUp(parentIndex);}}// O(logn)shiftDown(index) {const leftIndex = this.getLeftIndex(index);const rightIndex = this.getRightIndex(index);if (this.heap[leftIndex] < this.heap[index]) {this.swap(leftIndex, index);this.shiftDown(leftIndex);}if (this.heap[rightIndex] < this.heap[index]) {this.swap(rightIndex, index);this.shiftDown(rightIndex);}}insert(val) {this.heap.push(val);this.shiftUp(this.heap.length - 1);}pop() {this.heap[0] = this.heap.pop();this.shiftDown(0);}}const a = new MinHeap();a.insert(3)a.insert(2)a.insert(4)a.insert(5)a.insert(1)console.log(a.heap);// [ 1, 2, 4, 5, 3 ]a.pop()console.log(a.heap);// [ 2, 3, 4, 5 ]
获取堆顶元素
class MinHeap {constructor() {this.heap = [];}swap(i1, i2) {// const tmp = this.heap[i1];// this.heap[i1] = this.heap[i2];// this.heap[i2] = tmp;[this.heap[i1], this.heap[i2]] = [this.heap[i2], this.heap[i1]]}getParentIndex(i) {// return Math.floor((i - 1) / 2);// 位运算:将二进制向右移一位,也就相当于除 2return (i - 1) >> 1;}getLeftIndex(i) {return i * 2 + 1;}getRightIndex(i) {return i * 2 + 2;}// O(logn)shiftUp(index) {if (index === 0) return;const parentIndex = this.getParentIndex(index);if (this.heap[parentIndex] > this.heap[index]) {this.swap(parentIndex, index);this.shiftUp(parentIndex);}}// O(logn)shiftDown(index) {const leftIndex = this.getLeftIndex(index);const rightIndex = this.getRightIndex(index);if (this.heap[leftIndex] < this.heap[index]) {this.swap(leftIndex, index);this.shiftDown(leftIndex);}if (this.heap[rightIndex] < this.heap[index]) {this.swap(rightIndex, index);this.shiftDown(rightIndex);}}insert(val) {this.heap.push(val);this.shiftUp(this.heap.length - 1);}pop() {this.heap[0] = this.heap.pop();this.shiftDown(0);}peek() {return this.heap[0];}size() {return this.heap.length;}}const a = new MinHeap();a.insert(3)a.insert(2)a.insert(4)a.insert(5)a.insert(1)console.log(a.heap);// [ 1, 2, 4, 5, 3 ]a.pop()console.log(a.heap);// [ 2, 3, 4, 5 ]console.log(a.peek());// 2console.log(a.size());// 4
题目
数组中的第K个最大元素
思路:让堆只能存 K 个元素,超过 K 数量的元素都删除,最终只剩下 K 个元素。等堆排序完后,堆顶就是最小的元素,即第 K 个最大的元素。
class MinHeap {constructor() {this.heap = [];}swap(i1, i2) {// const tmp = this.heap[i1];// this.heap[i1] = this.heap[i2];// this.heap[i2] = tmp;[this.heap[i1], this.heap[i2]] = [this.heap[i2], this.heap[i1]]}getParentIndex(i) {// return Math.floor((i - 1) / 2);// 位运算:将二进制向右移一位,也就相当于除 2return (i - 1) >> 1;}getLeftIndex(i) {return i * 2 + 1;}getRightIndex(i) {return i * 2 + 2;}shiftUp(index) {if (index === 0) return;const parentIndex = this.getParentIndex(index);if (this.heap[parentIndex] > this.heap[index]) {this.swap(parentIndex, index);this.shiftUp(parentIndex);}}shiftDown(index) {const leftIndex = this.getLeftIndex(index);const rightIndex = this.getRightIndex(index);if (this.heap[leftIndex] < this.heap[index]) {this.swap(leftIndex, index);this.shiftDown(leftIndex);}if (this.heap[rightIndex] < this.heap[index]) {this.swap(rightIndex, index);this.shiftDown(rightIndex);}}insert(val) {this.heap.push(val);this.shiftUp(this.heap.length - 1);}pop() {this.heap[0] = this.heap.pop();this.shiftDown(0);}peek() {return this.heap[0];}size() {return this.heap.length;}}const findKthLargest = function (nums, k) {const h = new MinHeap();nums.forEach(n => {h.insert(n);if (h.size() > k) {h.pop();}})return h.peek();}console.log(findKthLargest([3, 2, 3, 1, 2, 4, 5, 5, 6], 5));
前 K 个高频元素
解法一
const topKFrequent = function (nums, k) {const map = new Map();// forEach 的时间复杂度为 O(n)nums.forEach(n => {map.set(n, map.has(n) ? map.get(n) + 1 : 1)})// 数组原生的 sort 方法为 O(nlogn)const list = Array.from(map).sort((a, b) => b[1] - a[1]);return list.slice(0, k).map(n => n[0]);};// 两个时间复杂度取最大值,所以时间复杂度为 O(nlogn)。不满足题目要求。
解法二
class MinHeap {constructor() {this.heap = [];}swap(i1, i2) {// const tmp = this.heap[i1];// this.heap[i1] = this.heap[i2];// this.heap[i2] = tmp;[this.heap[i1], this.heap[i2]] = [this.heap[i2], this.heap[i1]]}getParentIndex(i) {// return Math.floor((i - 1) / 2);// 位运算:将二进制向右移一位,也就相当于除 2return (i - 1) >> 1;}getLeftIndex(i) {return i * 2 + 1;}getRightIndex(i) {return i * 2 + 2;}shiftUp(index) {if (index === 0) return;const parentIndex = this.getParentIndex(index);// 注意:这里的逻辑有所改动if (this.heap[parentIndex] && this.heap[parentIndex].value > this.heap[index].value) {this.swap(parentIndex, index);this.shiftUp(parentIndex);}}shiftDown(index) {const leftIndex = this.getLeftIndex(index);const rightIndex = this.getRightIndex(index);if (this.heap[leftIndex] && this.heap[leftIndex].value < this.heap[index].value) {this.swap(leftIndex, index);this.shiftDown(leftIndex);}if (this.heap[rightIndex] && this.heap[rightIndex].value < this.heap[index].value) {this.swap(rightIndex, index);this.shiftDown(rightIndex);}}insert(val) {this.heap.push(val);this.shiftUp(this.heap.length - 1);}pop() {this.heap[0] = this.heap.pop();this.shiftDown(0);}peek() {return this.heap[0];}size() {return this.heap.length;}}const topKFrequent = function (nums, k) {const map = new Map();nums.forEach(n => {map.set(n, map.has(n) ? map.get(n) + 1 : 1)})const h = new MinHeap();// forEach O(n)map.forEach((value, key) => {// O(logk)h.insert({value, key})if (h.size() > k) {// O(logk)h.pop();}})return h.heap.map(a => a.key);};// 最终的时间复杂度为 O(nlogk)
合并K个升序链表

滑动窗口最大值
- 使用最大堆实现:堆里只存3个元素,每次移动窗口就是添加一个元素。
- 使用优先队列实现:队列的队头永远存放最大的值,每次新进一个值时,都去和队头比较,如果比队头大就删除队列里的所有元素(包括队头),然后再将该元素入队。
参考
数据结构脑图
https://naotu.baidu.com/file/0a53d3a5343bd86375f348b2831d3610?token=5ab1de1c90d5f3ec
https://naotu.baidu.com/file/b832f043e2ead159d584cca4efb19703?token=7a6a56eb2630548c

若有收获,就点个赞吧
0 人点赞
