1 需求分析
- 读写模式. 使用userid查询行记录, 读写特征值.
- 存储结构.
- 不同场景特征需求结构不一样, 支持自定义Table, 各个Table数据隔离.
- 特征存储支持宽表存储, 需要支持指定列的高效读写.
- 扩展性. 存储和访问支持低成本的水平扩展.
- 高性能. ms级别访问延迟.
- 可靠性. 数据不丢, 写数据多副本.
- 离线支持. 支持离线特征对接, 方便支持bulk load from和dump to Hadoop.
- 一致性. 作为特征, 对数据一致性要求弱, 保障最终一致性.
2 结构设计
2.1 KV结构存储, key 为userid, value为byte array.
2.2 Client API
put(table, userId, list
get(table, userId, list
3 方案设计
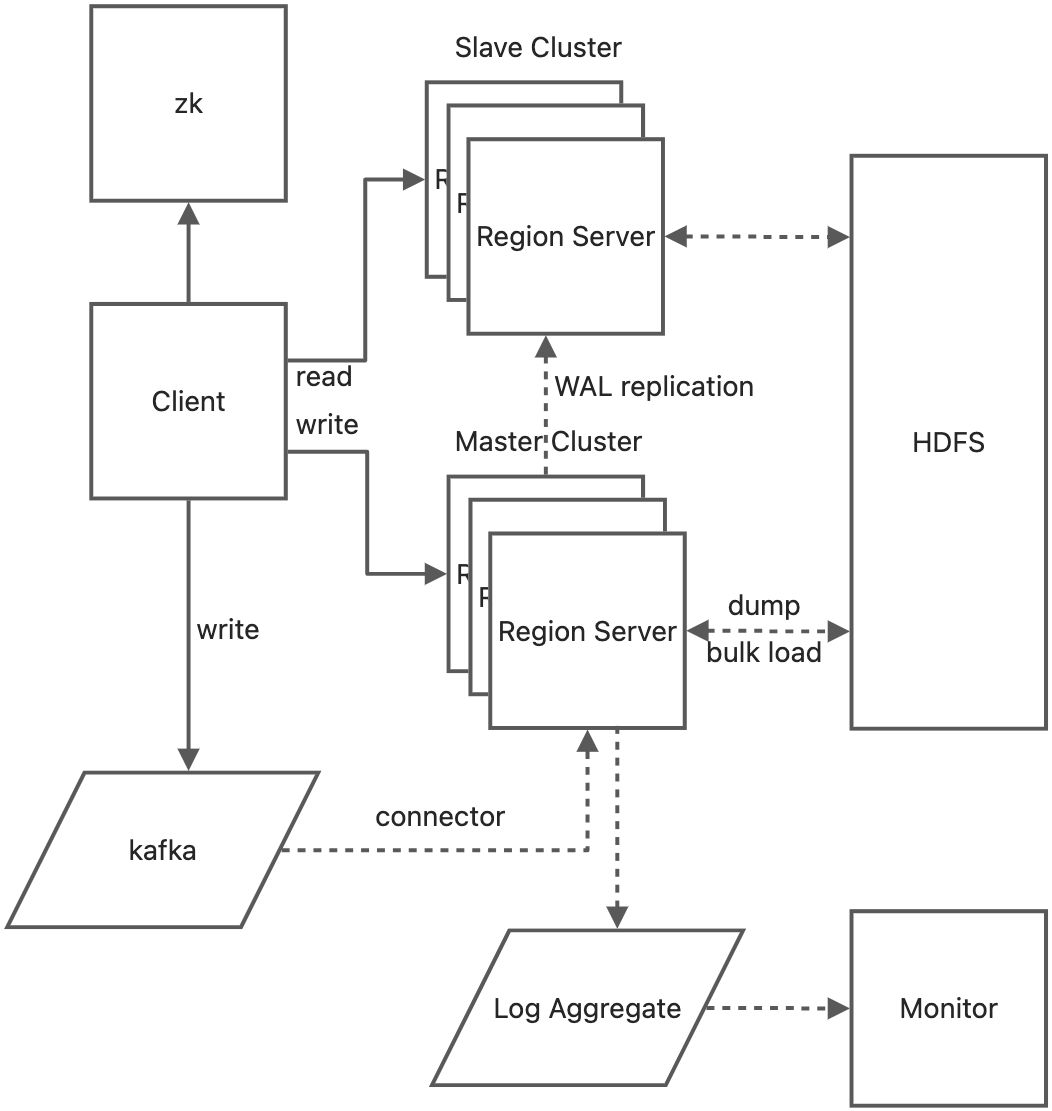
- 读写性能要求高, 并发量大, 存储量大. 一致性要求低, 关联和结构化查询要求低. 因此选择非结构化方案. BigTable like: HBase Cassandra.
- HBase vs Cassandra.
- 负载均衡 主从 vs 一致性hash.
- 一致性方案 Strong consistency vs read repair.
- 可用性 多HBase实例 vs NWR多副本.
HBase读写性能更好, 成本更低. 可用性相对较差, 但可以接受.
3.1 查询.
- 直接查询HBase
- hotkey可以做client-side cache
3.2 更新.
- 在线: 使用消息做异步更新. Region订阅table对应的消息, 更新到各自的Region Server.
- 离线: 离线MapReduce构造HFile, bulk load到Region Server.
3.3 持久化.
数据(HFile)持久化到Hadoop. Hadoop可以满足和离线数据导入导出, 以及离线数据多副本要求.
3.4 可用性
内存级别可靠性, 配置跨机房多HBase实例.

若有收获,就点个赞吧
0 人点赞
