hash是什么
通过哈希函数,将任意长度的输入转变为固定长度的输出(数组的下标,数据存储到数组的具体位置),输出的值就是哈希值(散列值)。
用于存储这些数据的结构称为哈希表。
为什么需要hash表
数组:查询快,增删慢。链表:查询慢,增删快。
当数据过多时,数组和链表无法解决快速查找数据的需求,索引需要hash表,hash表的综合效率更高。
哈希冲突
概念:当hash表通过哈希函数将不同的数据算出的哈希值相同时,就发生了哈希冲突。
解决办法:
1、链式地址法:hashmap采用的方式,将存储在数组相同位置的元素用链表的方式连起来。
2、线性探测法:将原有的输入依次+(1,2,3···)再计算哈希值,直到没有哈希冲突
3、跳跃线性探测法:将原有的输入依次+(1,3,5···)再计算哈希值,直到没有哈希冲突
HashMap1.7和1.8不同:
结构:1.7——数组+链表;1.8——数组+链表+红黑树
添加元素时:
1.7采用的头插法,新加入的元素变成链表的第一个元素(头节点)。他是将数组中内容由原来的指向原头节点变为指向新元素,新元素再指向原头节点的方式完成添加。
而1.8是采用尾插法的方式,将新加入的元素插入到最后面,不改变头节点。
为什么1.8采用尾插法,为什么头插法会链表成环?:
当多线程时,HashMap是不安全的,头插法会改变链表的头节点,出现链表成环的情况,这样会导致死循环。
在并发的情况下两个线程同时调用put方法存储数据,并且触发了扩容机制
当线程1 触发扩容并且数据都放好之后
因为是并发环境 并且hashmap不安全 所以线程2是在1上面弄好的链表里面操作
e.next =newTable[i] 那么2执行这个代码的时候 a就指向了b的位置
由于线程1 已经走完了 扩容逻辑 所以指向了 a (因为是头插法的原因)
所以当线程二放一个数据进链表的时候,那么就已经会发生链式循环
然后继续往下走 线程二 因为头插法的原因 把b 再放进去 b .next就指向了a
导致颠倒过来 形成最后的链式循环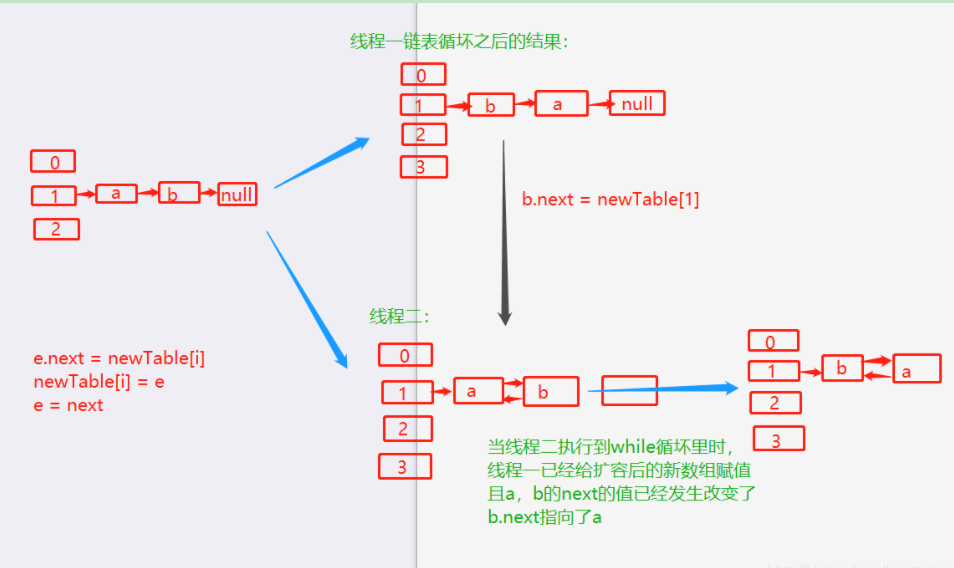
所以1.8采用了尾插法。
猜想:
首先hashmap是线程不安全的都知道,所以假设他在单线程时使用。
1.7:新加入的元素在后续的使用率会更高,提高查询效率,采用头插法。
而1.8:个人认为,发生哈希冲突时,会遍历链表或红黑树来比较key值,如果新元素key值唯一,则需要遍历完整个链表,或查到最后一级的红黑树。这样的话,直接从尾部插入的话,添加的效率就更高。
为什么1.8加入红黑树:
1.7时,当数组一处索引挂的链表过长,在对数据进行查找时就比较慢,加入红黑树提高查找效率。
且红黑树相比平衡二叉树来说,满足的条件不用那么苛刻,在树的一边数据过多时不用多次左右旋来满足平衡二叉树规则。
HashMap的扩容机制:
加载因子:0-1之间的一个系数,用于确定扩容的阈值
阈值:用于判断当前hashMap的数组是否需要扩容的一个值
hashmap默认建立的Entry数组长度是16,在添加元素时,先计算哈希值,找到数组对应下标,再判断对应下标是否已存在链表(是否为空)。如果为空,则需要新建链表,这个时候会先判断数组中的链表个数有没有达到阈值,如果达到了阈值就会将数组的长度扩容到原来的2倍。
1.8之后当链表长度大于8,且Entry数组长度大于64的时侯转化为红黑树,长度小于6时再转为链表。
设定转化阈值不同的原因是:避免频繁转换影响性能。
线程安全问题:
1.HashMap是线程不安全的,HashTable和concurrentHashMap是线程安全的。
HashMap可以有null作为key而HashTable不行:因为HashMap源码中,对key为null 的情况做的特殊的判断和方法处理,而HashTable没有。
HashTable是采用synchronized锁住整张表来实现线程安全的,效率较低。
concurrentHashMap是锁住每一个链表/红黑树来实现线程安全的,效率较高。
concurrentHashMap1.7采用Segment+HashEntry数组实现的,每一个HashEntry跟HashTable实现线程安全方式一样,而1.8是采用synchronized+CAS实现。
在多线程的时候,不同线程可以操作不同的链表/红黑树,效率就高了。
PUT流程
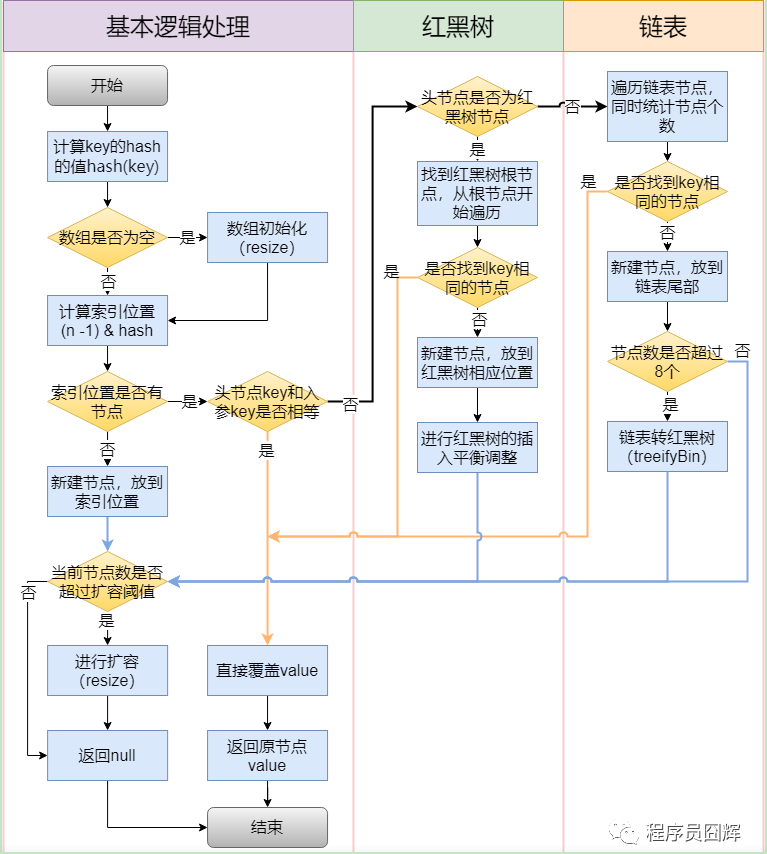

若有收获,就点个赞吧
0 人点赞
