1.MySQL系统组成
- 连接器:管理连接,对连接进行身份认证和权限判断。
- 查询缓存: 执行查询语句时,会首先会查询缓存,命中则直接返回。(8.0后移除)
- 分析器:词法分析,语法分析。
- 优化器:执行计划生成,索引选择。
- 执行器:将语句分发给对应的存储引擎,并返回结果。
- 存储引擎:存储数据,提供读写接口。

2.介绍
2.1 连接器
客户端需要通过连接器访问MySQL Server,连接器主要负责身份认证和权限鉴别的工作。也就是负责用户登录数据库的相关认证操作,例如:校验账户密码,权限等。在用户名密码合法的前提下,会在权限表中查询用户对应的权限,并且将该权限分配给用户。在连接完成以后可以通过图3看到连接状态,可以通过命令行“show processlist”生成图的查询结果。其中“Command”列返回的内容中,“Sleep”表示MySQL相同中对应一个空闲连接。而“Query”表示正在查询的连接。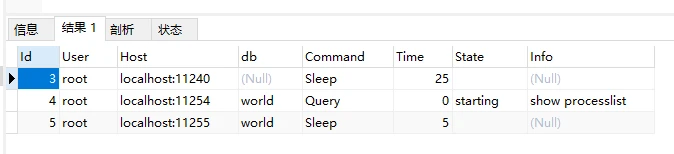
共有如下五种连接状态:
| Command | 含义 |
|---|---|
| sleep | 线程正在等待客户端发数据 |
| query | 连接线程正在执行查询 |
| locked | 线程正在等待表锁的释放 |
| sorting result | 线程正在对结果进行排序 |
| sending data | 向请求端返回数据 |
MySQL将连接器中的连接分为长连接和短连接。
- 长连接是指连接成功后,客户端请求一直使用是同一个连接。
- 短连接是指每次执行完SQL请求的操作之后会断开连接,如果再有SQL请求会重新建立连接。
由于短连接会反复创建连接消耗相同资源,因此多数情况下会选择长连接。但是为了保持长连接,会占用系统内存,而这些被占用的内存知道连接断开以后才会释放。这里提出了两个解决方案:
- 定期断开长连接,每隔一段时间或者执行一个占用内存的大查询以后断开连接,从而释放内存,当查询的时候再重新创建连接。
- MySQL 5.7 或者更高的版本,通过执行 mysql_reset_connection 来重新初始化连接。此过程不会重新建立连接,但是会释放占用的内存,将连接恢复到刚刚创立连接的状态。
2.2 查询缓存
连接建立完成后, 你就可以执行select语句了。 执行逻辑就会来到第二步: 查询缓存。
MySQL拿到一个查询请求后, 会先到查询缓存看看, 之前是不是执行过这条语句。 之前执行过
的语句及其结果可能会以key-value对的形式, 被直接缓存在内存中。 key是查询的语句, value是
查询的结果。 如果你的查询能够直接在这个缓存中找到key, 那么这个value就会被直接返回给客
户端。
如果语句不在查询缓存中, 就会继续后面的执行阶段。 执行完成后, 执行结果会被存入查询缓存
中。 你可以看到, 如果查询命中缓存, MySQL不需要执行后面的复杂操作, 就可以直接返回结
果, 这个效率会很高。
2.3 分析器
如果查询缓存没有命中,那么SQL请求会进入分析器,分析器是用来分辨SQL语句的执行目的,其执行过程大致分为两步:
第一步,词法分析(Lexical scanner)
主要负责从SQL 语句中提取关键字,比如:查询的表,字段名,查询条件等等。
第二步,语法规则(Grammar rule module)
主要判断SQL语句是否合乎MySQL的语法。
其实说白了词法分析(Lexical scanner) 就是将整个SQL语句拆分成一个个单词,而语法规则(Grammar rule module)则根据MySQL定义的语法规则生成对应的数据结构,并存储在对象结构当中。其结果供优化器生成执行计划,再调用存储引擎接口执行。
来看下面这个例子,假设有这样一个SQL语句“select username from userinfo”。先通过词法分析,从左到右逐个字符进行解析,获得四个单词。
| 关键字 | 非关键字 | 关键字 | 非关键字 |
|---|---|---|---|
| select | username | from | userinfo |
然后再通过语法规则解析,判断输入的SQL 语句是否满足MySQL语法,并且生成如下的语法树。由SQL语句生成的四个单词中,识别出两个关键字,分别是select 和from。根据MySQL的语法Select 和 from之间对应的是fields 字段,下面应该挂接username;在from后面跟随的是Tables字段,其下挂接的是userinfo。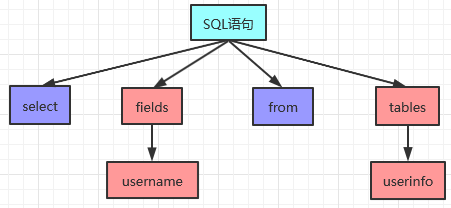
2.4 优化器
优化器的作用是对SQL进行优化,生成最有的执行方案。如图所示,前面提到的SQL解析器通过语法分析和语法规则生成了SQL语法树。这个语法树作为优化器的输入,而优化器(黄色的部分)包含了逻辑变换和代价优化两部分的内容。在优化完成以后会生成SQL执行计划作为整个优化过程的输出,交给执行器在存储引擎上执行。 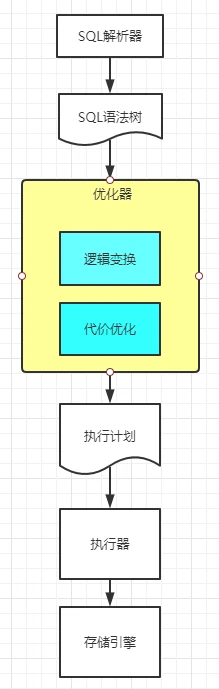
逻辑变换
逻辑变换也就是在关系代数基础上进行变换,其目的是为了化简,同时保证SQL变化前后的结果一致,也就是逻辑变化并不会带来结果集的变化。其主要包括以下几个方面:
- 否定消除:针对表达式“和取”或“析取”前面出现“否定”的情况,应将关系条件进行拆分,从而将外层的“NOT”消除。
- 等值常量传递:利用了等值关系的传递特性,为了能够尽早执行“下推”运算。“下推”的基本策略是,始终将过滤表达式尽可能移至靠近数据源的位置。
- 常量表达式计算:对于能立刻计算出结果的表达式,直接计算结果,同时将结果与其他条件尽量提前进行化简。

代价优化
代价优化是用来确定每个表,根据条件是否应用索引,应用哪个索引和确定多表连接的顺序等问题。为了完成代价优化,需要找到一个代价最小的方案。
因此,优化器是通过基于代价的计算方法来决定如何执行查询的(Cost-based Optimization)。
2.5 执行器
当分析器生成查询计划,并且经过优化器以后,就到了执行器。执行器会选择执行计划开始执行,但在执行之前会校验请求用户是否拥有查询的权限,如果没有权限,就会返回错误信息,否则将会去调用MySQL引擎层的接口,执行对应的SQL语句并且返回结果。
例如SQL:“SELECT * FROM userinfo WHERE username = ‘Tom’;”
假设 “username” 字段没有设置索引,就会调用存储引擎从第一条开始查,如果碰到了用户名字是“ Tom”, 就将结果集返回,没有查找到就查看下一行,重复上一步的操作,直到读完整个表或者找到对应的记录。
需要注意SQL语句的执行顺序并不是按照书写顺序来的,顺序的定义会在分析器中做好,一般是按照如下顺序: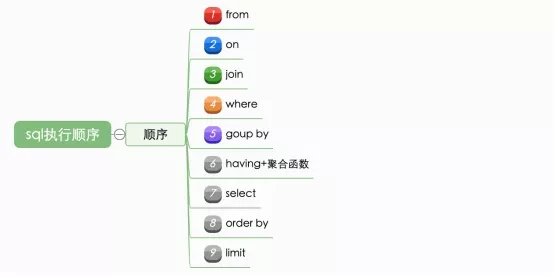

若有收获,就点个赞吧
0 人点赞
