1. Http到底是什么
HTTP,Hypertext Transfer Protocol,超文本传输协议,与HTML(Hypertext Markup Language超文本标记语言)一起诞生,用于在网络上请求和传输HTML内容;Hyper 超 非super ,是扩展的意思
超文本,即扩展型文本,类似如下:
- ⽤户输⼊地址后发起请求, 浏览器拼装 HTTP 报⽂并发送给服务器,服务器处理请求后发送响应报⽂给浏览器 ,浏览器解析响应报⽂并通过浏览器内核进行渲染显示(内核是浏览器的渲染引擎)
- Android 代码调⽤拼装 HTTP 报⽂并发送请求到服务器,服务器处理请求后发送响应报⽂给⼿机,Android 代码处理响应报⽂并作出相应处理
请求报文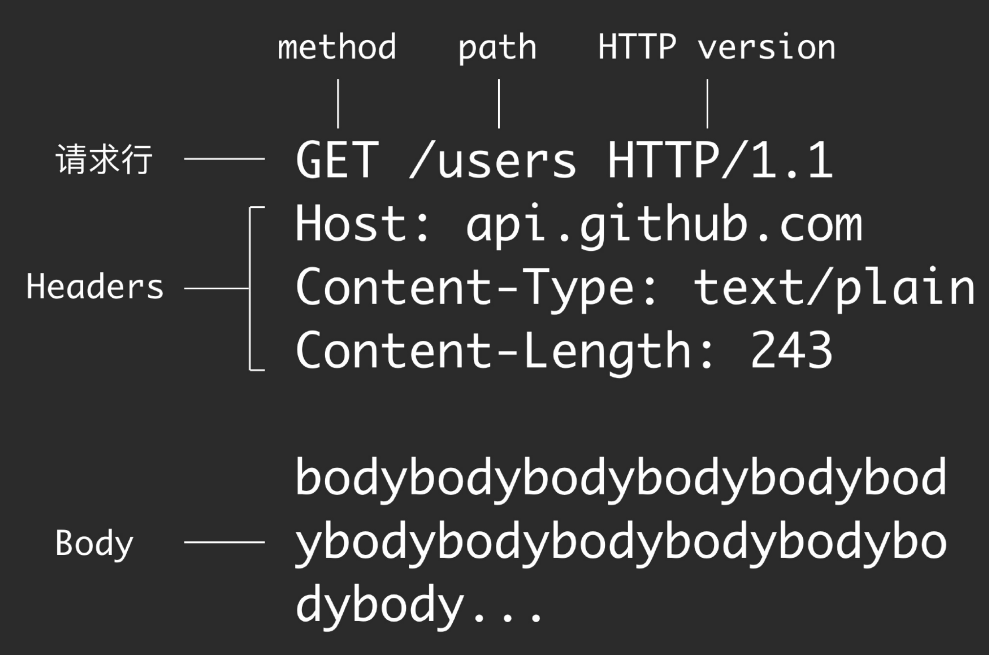
响应报文
2. 请求与响应
Request Method请求方法
1. GET
用于获取服务器资源,不对服务器资源进行修改,不发送Body,或者说使用GET方法传输Body是一种不规范的写法;(在Retrofit的GET方法中添加@Body属性,将会报错)
2. POST
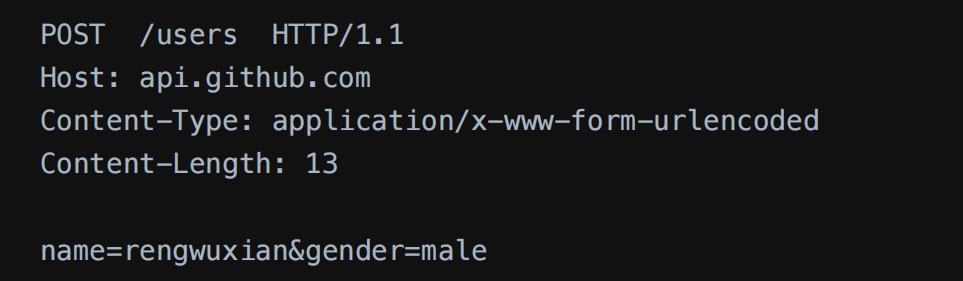
3. PUT
只用来修改资源,有Body;
那么问题来了,POST与PUT的区别是什么,在两者都可以使用的情况下应该用哪个更规范?
先回答后面问题:就比如在修改服务器资源的时候,其实两者都可以,和后端协同好,无论使用哪个都符合规范;POST与PUT的区别在于POST不具有幂等性,PUT具有幂等性;幂等是指多次操作的结果与一次操作的结果是一致的,GET也具有幂等性,因为取一次与取多次的结果是一样的
4. DELETE
用于删除资源,不发送Body,只需要锁定资源Id即可,也具有上文所说的幂等性
5. HEAD
与GET使用方法完全相同,唯一区别在于,返回的响应体终是没有Body的;它的作用主要是用于获取信息;比如在获取信息之前,先来一次HEAD,获取信息之后在去进行格外处理;
响应状态码Status Code
- 1XX: 临时性消息;如100 (继续发送)、101(Http协议切换)
- 2XX: 请求成功;如200(OK)、201(创建成功)
- 3XX: 重定向;301(永久移动)、302(暂时移动)、303(内容未改变)
- 4XX: 客户端错误;如 400(客户端请求错误)、401(认证失败)、403(被禁⽌)、404(找不到内容)
- 5XX: 服务器错误;如 500(服务器内部错误)
3. Header首部
Header是Http消息的元数据,(可以理解为数据的数据,或者数据的属性,描述数据的相关信息)
Host
首先要明确的是,host不是用来在网络上寻址的,而是到达目标服务器之后用于定位子服务器的(倘若在一个主机上面运行了多个服务器)
DNS: 域名系统 Domain Name System
域名,例如www.baidu.com 是方便我们人去记住网络中的某个地址,但计算机是通过IP地址进行查找的,我们在请求域名的时候,会先请求DNS,DNS可以帮助我们将域名转换为相应的IP
Content-Type
1. text/html
2. application/x-www-form-urlencoded (普通表单)

3. multipart/from-data
在含有多种类型文件时候的提交方式,例如普通文本加上 二进制文件时的提交方式,格式如下:
boundary是不同文件类型之间的分界线(普通表单使用boundary来分界,会造成带宽浪费),对应的Retrofit代码:
@Multipart@POST("/users")Call<User> addUser(@Part("name") RequestBody name,@Part("avatar") RequestBody avatar);//RequestBody构建RequestBody namePart = RequestBody.create(MediaType.parse("text/plain"),nameStr);RequestBody avatarPart = RequestBody.create(MediaType.parse("image/jpeg"),avatarFile);api.addUser(namePart, avatarPart);
另外需要注意:
- 使用普通表单加上base64来传递图片的行为是一种不合理的行为
4. application/json,image/jepg,application/zip…
单项内容,例如json格式,jepg类型格式,zip类型格式等等,类似如下
Content-Length
没什么可说的,表示body的字符长度,我们平时开发中看似也可有可无,那么它的主要作用是什么?
当我们传输的数据不是字符,而是二进制数据时,这个时候,我们没有办法去界定一个数据传输的结束,这个时候就可以使用字符长度来界定
分块传输 Chunked Transfer Encoding(只做了解)
分块传输是用在当我们发送数据请求时,服务端需要计算或者需要耗时操作才能返回数据(计算机中的时间优化是ms级别的),这个时候可以先返回一部分数据,让客户端先进行处理(当然,这个必须是在数据格式支持的情况下)
需要添加如下属性(具体使用方式,使用时再进行了解)
- Transfer-Encoding:chunked

Cache(待完善)
- Cache-Control:no-cache、no-store、max-age
cache与Buffer的区别
一个叫缓存,一个叫缓冲;缓存是暂时用过了,为了下次能够进行快速加载,节省资源性能,而将数据进行暂存的一种行为;缓冲是针对工作流的,用来处理上游生产过快,下游来不及消费或者下游即将进行爆发消费,上游先进行生产存在Buffer里的情况,例如网络请求爆发,路由器来不及处理,就会在Buffer里,路由器会不断地从Buffer里面取出请求进行操作
Cookie/Set-Cookie:发送Cookie/设置Cookie
Authorization
其他字段
- Location 重定向地址(在301的时候拿到的Response中会有该字段),浏览器会自动获取该字段进行跳转
- User-Agent 用户代理,客户端或者浏览器,网站会通过该字段确定是什么类型客户端(不重要)
- Range/Accept-Ranges 分段加载,两个作用断点续传与多线程下载
在网站支持的前提下(在Reponse的Header部分有Accept-Ranges字段就是支持,该字段后面会跟一个值是数据类型),通过该字段可以加载链接的部分资源,在请求头中添加
Range:bytes=0-300 就是取从第0到300字节的数据
- Content-Range:bytes 0-300/7098 分段加载时,会返回该字段,代表此次加载数据为从0到300字节,总长度7098字节
- Accept: 客户端能接受的数据类型。如text/html
- Accept-Charset: 客户端能接受的字符集。如utf-8
- Accept-Encoding: 客户端能接受的压缩编码类型。如gzip
-
4. RESTful HTTP
首先要明确的是,RESTful HTTP是一种架构风格;
C/S架构
要明确一个概念,此处的C/S架构并不是狭义的客户端/服务器架构,浏览器也包括在内(C/S是一种真正的架构风格,B/S是为了区分客户端与浏览器才出现的一种说法,可以这么理解)
- 无状态的 : 两个请求之间是没有关系的,客户端信息需要随请求携带
- 可缓存的
- 分层系统(Layered system): 当服务器不是一台主机,是一个集群时,对客户端来说应该是无感知的
- Code on demand : 服务器可以返回可执行代码
- 统一接口
- 通过请求可以对资源进行确认
- Resource manipulation through representations
- 自描述的信息:数据可能是各种格式,需要在请求中描述信息类型
- (HATEOAS) Hypermedia as the engine of application state : 大概理解为需要像网页一样提供一个页面去展示所有可查探的资源
来自扔物线的观点,RESTful Http是Http的最佳实践方法,两者是一种共生的关系,即规范使用Http就是RESTful HTTP;REST概念提出者对HTTP做了很大的贡献,很可能是在思考一种尽可能规范的C/S架构所衍生出来的产物;
包括以下几点:
- 规范使用method来定义网络请求操作
- 使用资源的格式来定义URL
- 规范使用status code来表示响应状态
- 其他符合HTTP规范的设计准则

若有收获,就点个赞吧
0 人点赞
