交叉验证
定义
交叉验证(Cross Validation),有的时候也称作循环估计(Rotation Estimation),是一种统计学上将数据样本切割成较小子集的实用方法,该理论是由Seymour Geisser提出的。
在给定的建模样本中,拿出大部分样本进行建模型,留小部分样本用刚建立的模型进行预报,并求这小部分样本的预报误差,记录它们的平方加和。这个过程一直进行,直到所有的样本都被预报了一次而且仅被预报一次。把每个样本的预报误差平方加和,称为PRESS(predicted Error Sum of Squares)。
基本思想
交叉验证的基本思想是把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set or test set),首先用训练集对分类器进行训练,再利用验证集来测试训练得到的模型(model),以此来做为评价分类器的性能指标
K折交叉验证
所谓K折交叉验证,就是将数据集等比例划分成K份,以其中的一份作为测试数据,其他的K-1份数据作为训练数据。然后,这样算是一次实验,而K折交叉验证只有实验K次才算完成完整的一次,也就是说交叉验证实际是把实验重复做了K次,每次实验都是从K个部分选取一份不同的数据部分作为测试数据(保证K个部分的数据都分别做过测试数据),剩下的K-1个当作训练数据,最后把得到的K个实验结果进行平分。
一般情况将K折交叉验证用于模型调优,找到使得模型泛化性能最优的超参值。,找到后,在全部训练集上重新训练模型,并使用独立测试集对模型性能做出最终评价。
K折交叉验证使用了无重复抽样技术的好处:每次迭代过程中每个样本点只有一次被划入训练集或测试集的机会。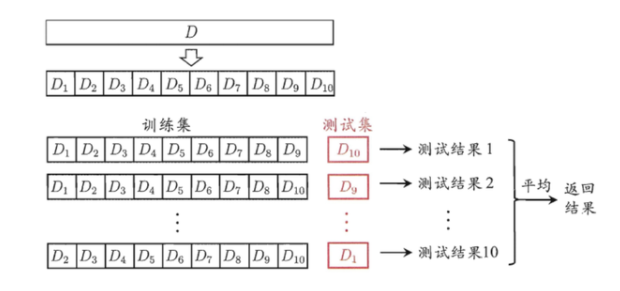
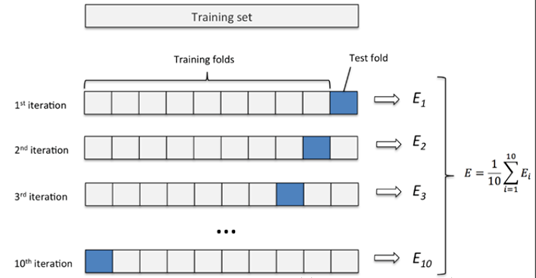
K折交叉验证的一个特例(留一法):
留一(LOO)交叉验证法:将数据子集划分的数量等于样本数(k=n),每次只有一个样本用于测试,数据集非常小时,建议用此方法。
K折交叉验证改进成的分层K折交叉验证:
获得偏差和方差都低的评估结果,特别是类别比例相差较大时。 也就是先对数据进行分层,然后按比例在每层中随机抽取,这样使得每份数据更加的具有代表性,降低了随机取样可能产生的样本不均衡问题。
from sklearn.model_selection import cross_val_scorescore = cross_val_score(estimator,X,Y,scoring='accuracy',cv = 10) # cv==k,默认5
网格搜索
网格搜索(Grid Search)名字非常大气,但是用简答的话来说就是你手动的给出一个模型中你想要改动的所用的参数,程序自动的帮你使用穷举法来将所用的参数都运行一遍。决策树中我们常常将最大树深作为需要调节的参数;AdaBoost中将弱分类器的数量作为需要调节的参数。
评分方法
为了确定搜索参数,也就是手动设定的调节的变量的值中,那个是最好的,这时就需要使用一个比较理想的评分方式(这个评分方式是根据实际情况来确定的可能是accuracy、f1-score、f-beta、pricise、recall等)
from sklearn.model_selection import GridSearchCV#knn的参数例子params = {'n_neighbors':[i for i in range(1,30)],'weights':['distance','uniform'],'p':[1,2]}# cross_val_score类似gcv = GridSearchCV(estimator,params,scoring='accuracy',cv = 6)gcv.fit(X_train,y_train)gcv.best_params_gcv.best_estimator_gcv.best_score_y_ = gcv.predict(X_test)gcv.score(X_test,y_test)# 取出了最好的模型,进行预测# 也可以直接使用gcv进行预测,结果一样的knn_best = gcv.best_estimator_y_ = knn_best.predict(X_test)accuracy_score(y_test,y_)

若有收获,就点个赞吧
0 人点赞
