前言
JS作为一种弱类型语言,没有静态变量类型。编译过程中会存在一些问题,在逻辑复杂、代码量大的情况下,导致运行速度难以提升。下面详细分析一下引起这一问题的具体原因,首先我们还得从浏览器编译运行流程说起。
解释器 vs 编译器
我们说的是人类语言,计算机说的是机器语言。javaScript或者其他高级语言可以看成是人类语言尽管我们不这么认为,但是他们的设计就是为了让人类认知,而不是为机器设计的。
所以JS引擎的工作就是把人类语言转换成机器所理解的语言。而解释器和编译器就是js引擎将人类语言翻译为机器语言的两种方式。
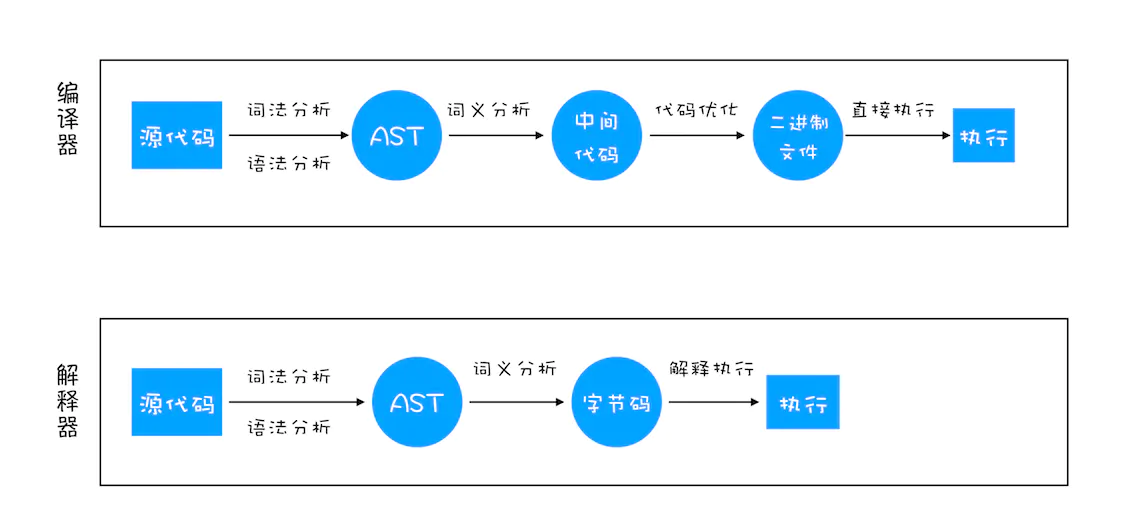
解释型语言 vs 编译器语言
这两个概念其实不太严谨,应该改为“主流实现为解释器的语言”和“主流实现为编译器的语言”更为妥当。事实上很多语言采用的是混合型实现,比如JavaScript需要先编译成字节码,而虚拟机又是解释执行的,执行过程中又会用到JIT即时编译,因此很难说它到底属于哪一种类型的语言。
实际上,编译型和解释型最大的区别在于是否保存和复用生成的目标代码(不管是存在磁盘还是内存),编译型会,而解释型则是逐条执行,用完就扔。因此,按语言的执行流程,可以把语言分为解释型语言和编译型语言。
解释型语言:在每次运行时,都需要通过解释器对程序进行动态的解释和执行。比如python、javascript…
编译型语言:在程序执行之前,需要由编译器进行编译,并且保留编译后的二进制文件,每次运行时,直接运行机器能够读懂的二进制文件,不需要重新编译。比如:C、C++等。
代码执行流程
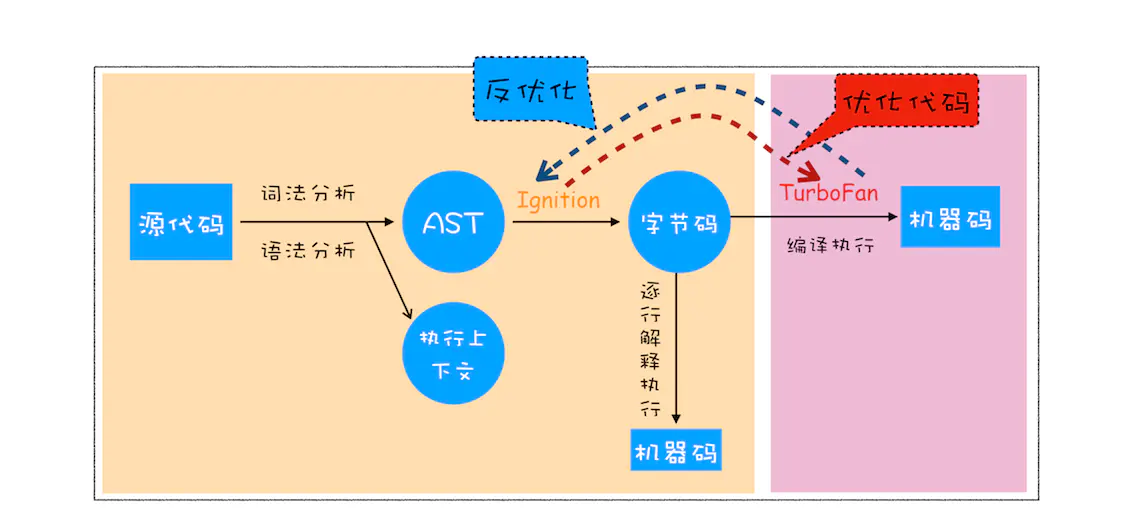
1. 生成抽象语法书(AST)和执行上下文
对于解释器和编译器来说,他们认识的是AST。抽象语法树(AST)的生成需要依靠的是js解析器(javascript Parser),整个解析过程分为两个阶段。
(1)词法分析
词法分析也就是分词也叫扫描,其作用是将一层层源码拆解成一个个Token,Token是指语法上不可拆分、最小的单个字符或字符串。同时,它会移除空白符,注释,等。最后,整个代码将被分割进一个tokens列表(或者说一维数组)无层级。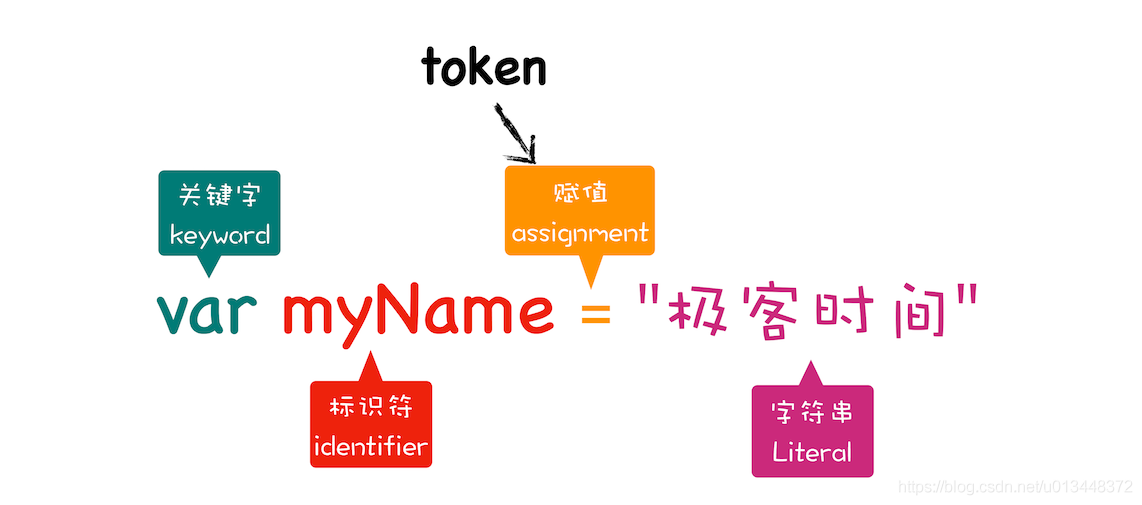
(2)语法分析
将上一步生成的Tokens,根据语法规则转换成AST,有层级的树形结构。如果源码符合语法规则,则顺利生成;吐过存在语法错误则抛出异常。
2. 生成字节码
有了AST和执行上下文以后,解释器Ignition根据AST生成字节码,并解释执行字节码。
字节码是介于AST和机器码之间的代码。与特定类型的机器码无关,字节码需要通过解释器转换为机器码之后才能执行。

字节码所占控件远远小于机器码,所以字节码可以减少系统内存的使用。
2. 执行代码
生成字节码之后进入执行阶段。
解释器除了生成字节码,还有一个作用就是解释执行字节码,对于一些重复的代码或者是循环使用的代码来说效率比较低。
编译器可以一次编译,编译之后执行速度有效提升,但是对于使用频率不高的代码来说,编译会浪费大量的时间。
因此,及时编译(JIT)技术出现了。
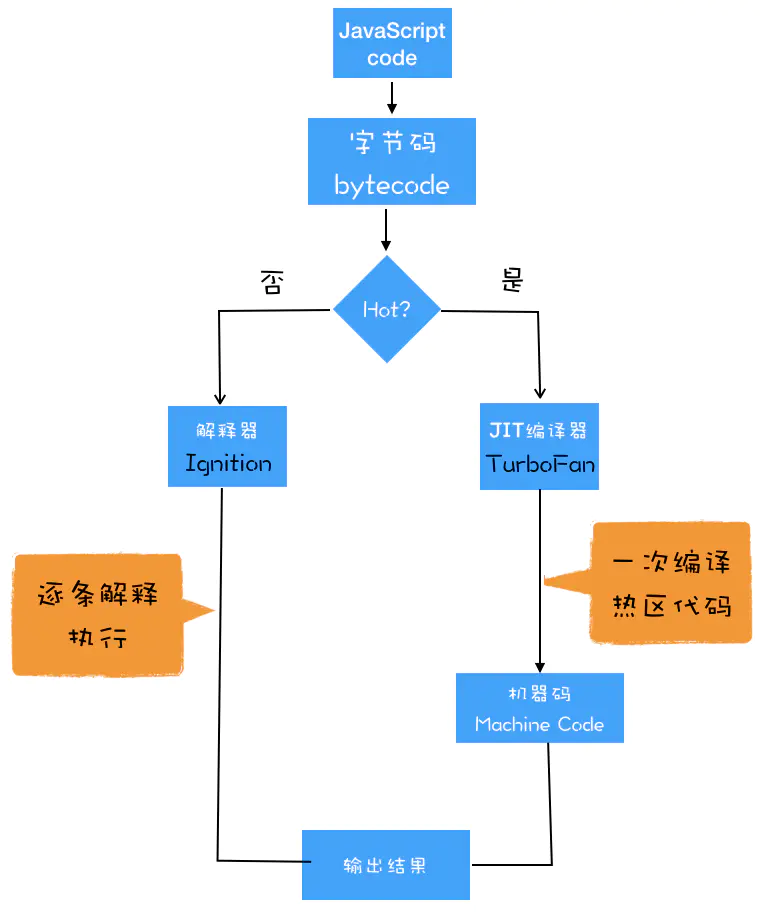
刚开始,还是一行一行的执行,但是JIT里包含了一个监视器(profilter),用于监视每行代码执行的次数。
如果一行代码被执行了好几次,这行代码被标记为’warm’,并交给基线编译器(base complier),基线编译器编译的时间不能过长,否则会导致程序卡住,被称为未经优化的编译结果。
如果一行代码被执行了好多好多次,则标记为‘hot’,然后送给优化编译器。优化编译器需要基于一定的假设:所有的类型必须具有相同的类型或者结构,但是javaScript是一种动态类型语言,变量的类型不确定,因此,不能满足假设时就会出现去优化的现象。
举个例子:优化编译器可能会假设arr[i]一定是int类型,并为其生成了一个优化编译版本。但是突然执行到sum += ‘a’;的时候就懵圈了,发现之前的类型推断不成立,只好推倒重来。。。
如果一直陷入“优化<–>去优化”的怪圈之中,性能就会大幅下降,甚至还不如直接使用基线编译器。
总结
归根到底,是由于Javascript被设计为了一种动态类型语言,编译器无法在编译之前获悉变量的确切类型。

若有收获,就点个赞吧
0 人点赞
