基本变量类型的字节大小
// 查看编译后的汇编go build -gcflags -S main.go
部分数据结构长度与系统字长有关
// 64位系统fmt.Printf("int :%d \n",unsafe.Sizeof(int(0))) //8字节fmt.Printf("int8 :%d \n",unsafe.Sizeof(int8(0))) //1fmt.Printf("int32 :%d \n",unsafe.Sizeof(int32(0))) //4fmt.Printf("int64 :%d \n",unsafe.Sizeof(int64(0))) //8fmt.Printf("uint :%d \n",unsafe.Sizeof(uint(0))) //8fmt.Printf("uint8 :%d \n",unsafe.Sizeof(uint8(0))) //1fmt.Printf("uint32 :%d \n",unsafe.Sizeof(uint32(0))) //4fmt.Printf("uint64 :%d \n",unsafe.Sizeof(uint64(0))) //8// 32系统fmt.Printf("int :%d \n",unsafe.Sizeof(int(0))) //4字节
有部分数据类型的字节大小是根据系统字长变化的:int类型
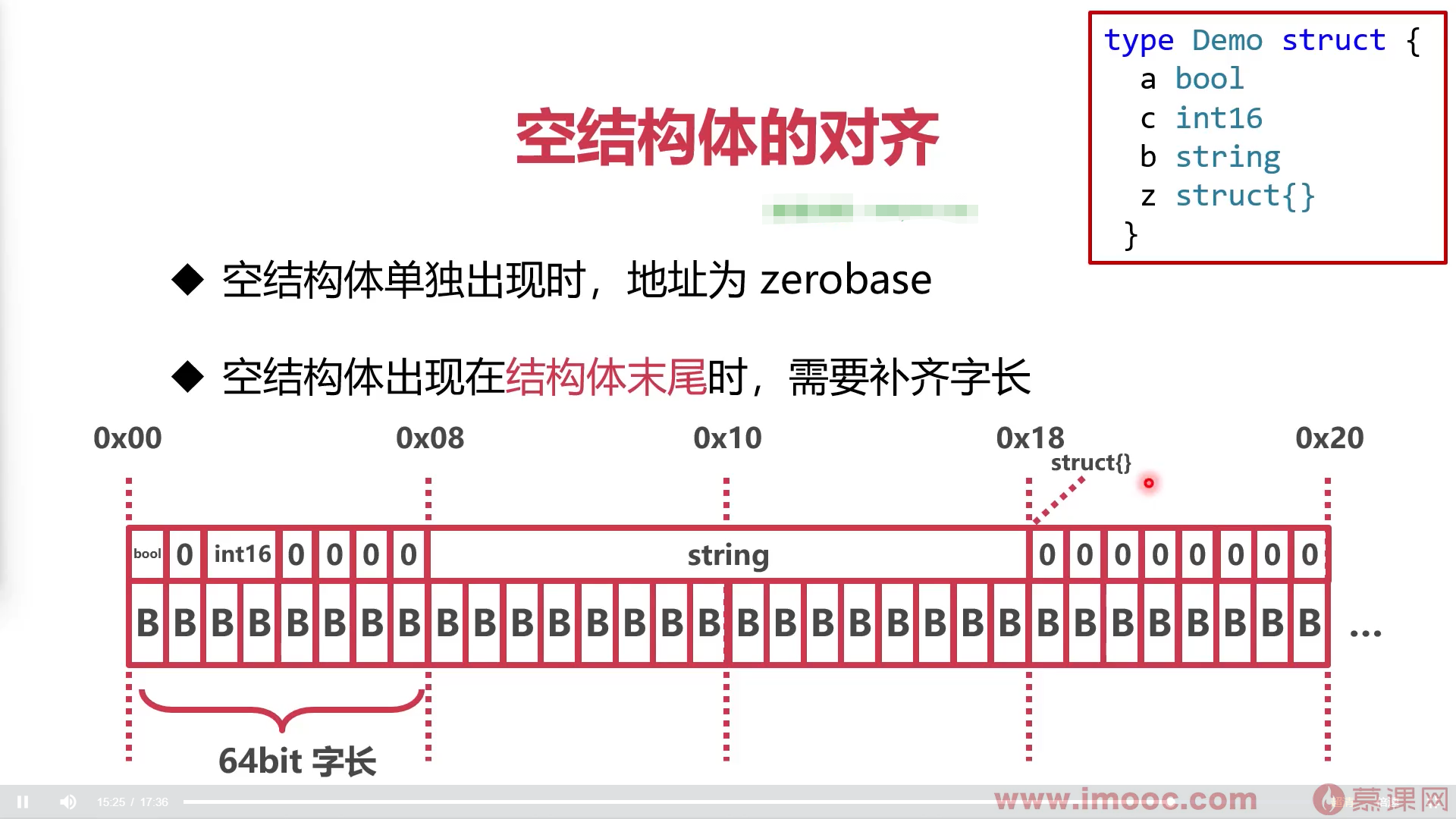
空结构体
空结构体独立使用,
- 长度为0
- 地址为zeroBase(zeroBase是所有字节长度为0的地址)
 ```go
type k struct {}
```go
type k struct {}
a:=k{} b:=”6666” c:=k{} fmt.Printf(“%d \n”,unsafe.Sizeof(a)) //0 fmt.Printf(“%p \n”,&a) //0x6bcde0 fmt.Printf(“%p \n”,&b) //0xc000088230 fmt.Printf(“%p \n”,&c) //0x6bcde0
<a name="fSJyr"></a>#### 空结构体和其他结构组合使用- 空结构体的地址为其父结构体的地址```gotype k struct {}type p struct {num1 knums2 string}func main() {a:=k{}c:=p{nums2: "666"}fmt.Printf("%d \n",unsafe.Sizeof(a)) //0fmt.Printf("%p \n",&a) //0x10cdde0fmt.Printf("%p \n",&c.nums2)// 0xc000088230fmt.Printf("%p \n",&c.num1)//0xc000088230fmt.Printf("%p \n",&c)//0xc000088230}
空结构体的使用
实现hashset
m := map[string]struct{}{} //key:null
实现信息传递
ch := make(chan struct{})
空结构体主要是可以节约内存
数组,字符串,切片底层是否一样
字符串
底层是一个结构体
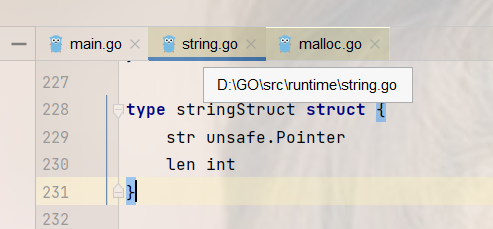
type stringStruct struct {str unsafe.Pointer //指针,可以指向任意数据类型len int //8字节}// len 表示字符串的底层byte数组的长度(字节数)
- Data指针指向底层Byte数组
- 如何获取字符串结构体的len
go的所有字符均采用的的Unicode字符集,使用的utf-8(utf-8:八位为一个字节,英文字母,英文标点一个字节,西方常用字符需要两个字节如希腊字母,中文至少需要3个字节表示,极少部分需要四个字节)编码
// 需要借助反射中的字符串结构体s := "李易峰"sh := (*reflect.StringHeader)(unsafe.Pointer(&s))fmt.Println(sh.Len) //9s2 := "李易峰abcde"sh2 := (*reflect.StringHeader)(unsafe.Pointer(&s2))fmt.Println(sh.Len) //14
遍历字符串
用range遍历字符串,被解码成rune(代表一个utf8字符) 类型的字符
// rune is an alias for int32 and is equivalent to int32 in all ways. It is// used, by convention, to distinguish character values from integer values.type rune = int32
遍历字符串解码(一个字符解码成多个字节)时采用了runtime包utf8.go文件的decoderune方法
// decoderune returns the non-ASCII rune at the start of// s[k:] and the index after the rune in s.//// decoderune assumes that caller has checked that// the to be decoded rune is a non-ASCII rune.//// If the string appears to be incomplete or decoding problems// are encountered (runeerror, k + 1) is returned to ensure// progress when decoderune is used to iterate over a string.func decoderune(s string, k int) (r rune, pos int) {pos = kif k >= len(s) {return runeError, k + 1}s = s[k:]switch {case t2 <= s[0] && s[0] < t3:// 0080-07FF two byte sequenceif len(s) > 1 && (locb <= s[1] && s[1] <= hicb) {r = rune(s[0]&mask2)<<6 | rune(s[1]&maskx)pos += 2if rune1Max < r {return}}case t3 <= s[0] && s[0] < t4:// 0800-FFFF three byte sequenceif len(s) > 2 && (locb <= s[1] && s[1] <= hicb) && (locb <= s[2] && s[2] <= hicb) {r = rune(s[0]&mask3)<<12 | rune(s[1]&maskx)<<6 | rune(s[2]&maskx)pos += 3if rune2Max < r && !(surrogateMin <= r && r <= surrogateMax) {return}}case t4 <= s[0] && s[0] < t5:// 10000-1FFFFF four byte sequenceif len(s) > 3 && (locb <= s[1] && s[1] <= hicb) && (locb <= s[2] && s[2] <= hicb) && (locb <= s[3] && s[3] <= hicb) {r = rune(s[0]&mask4)<<18 | rune(s[1]&maskx)<<12 | rune(s[2]&maskx)<<6 | rune(s[3]&maskx)pos += 4if rune3Max < r && r <= maxRune {return}}}return runeError, k + 1}
s := "李易峰dashi"for _, v := range s {fmt.Printf("%c",v)}//李 易 峰 d a s h i
- 使用下标访问字符串,得到是字节 ```go s := “李易峰dashi” for i := 0; i < len(s); i++ { fmt.Println(s[i]) }
230 157 142 230 152 147 229 179 176 100 97 115 104 105
5. 字符串需要切分时- 转为rune数组- 切片- 转为字符串```gos := "李易峰dashi"s = string([]rune(s)[:3])fmt.Println(s)//李易峰
-
切片
切片结构体,runtime下面的slice.go
切片的本质是对数组的一种引用
type slice struct {array unsafe.Pointerlen int //长度cap int //容量}
创建切片
根据数组创建
arr :=[5]int{1,2,3,4,5}s := arr[0:3]
字面量:根据编译时插入创建切片的代码 ```go slice := []int{1,2,3}
// 该方法创建原理 // 1先创建一个数组[3]int{1,2,3} // 2.实例切片结构体
3. make:运行时创建切片```goslice := make([]int,10)
运行时创建切片的原理,位于runtime的slice.go
func makeslice(et *_type, len, cap int) unsafe.Pointer {mem, overflow := math.MulUintptr(et.size, uintptr(cap))if overflow || mem > maxAlloc || len < 0 || len > cap {// NOTE: Produce a 'len out of range' error instead of a// 'cap out of range' error when someone does make([]T, bignumber).// 'cap out of range' is true too, but since the cap is only being// supplied implicitly, saying len is clearer.// See golang.org/issue/4085.mem, overflow := math.MulUintptr(et.size, uintptr(len))if overflow || mem > maxAlloc || len < 0 {panicmakeslicelen()}panicmakeslicecap()}return mallocgc(mem, et, true)}
切片的访问
- 下标直接访问元素
- range遍历元素
- len(slce)查看切片长度
- cap(clice)查看切片容量 ```go s :=[]int{1,2,3} 下标直接访问元素 s1 :=s[0] range遍历元素 for k,v := range s{ fmt.Println(k,v) }
len(s)//3 cap(s)//3
<a name="gXiCX"></a>##### 切片追加1. 追加的元素,加上原有的元素没有超过切片容量,则不应扩容2. 切片扩容会创建底层数组,因为数组内容字节地址是连续的,所以扩容就只能重开内存地址存储新的切片3. 如果期望容量大于当前容量的两倍就会使用期望容量4. 如果切片的长度小于1024,扩容容量会翻倍5. 如果切片长度大于1024,扩容容量每次增加25%6. 切片扩容时,**并发不安全**,切片并发要加锁7. 切片扩容编译时,会调用runtime.growslice()<a name="M2txl"></a>#### 总结1. 字符串与切片底层都是对数组的引用2. 字符串有UTF-8变长编码的特点3. 切片的容量和长度不同4. 切片追加时可能会重建底层数组<a name="xxN7Y"></a>### Map<a name="wTJ7Y"></a>#### map的底层是一个hashMaphashMap实现的基本方案- 开放寻址法- 拉链法(go的map就是这种)<a name="dqXWZ"></a>#### map结构体```go// A header for a Go map.type hmap struct {// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.// Make sure this stays in sync with the compiler's definition.count int // # live cells == size of map. Must be first (used by len() builtin)flags uint8B uint8 // log2为底buckets的对数noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for detailshash0 uint32 // hash seedbuckets unsafe.Pointer // 2的B次方。可以等于0oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growingnevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)extra *mapextra // optional fields}
map的初始化
字面量初始化
元素个数小于25时
// 创建一个maphash := map[string]int{"1":2,"3":4,"5":6,}// 编译时代码为hash := make(map[string]int,3)hash["1"] = 2hash["3"] = 4hash["5"] = 6
元素个数大于25 ```go // 创建一个长度26的map hash := map[string]int{ “1”:1, “2”:2, “3”:3, …. “26”:26, } // 编译时的代码 hash := make(map[string]int,26) vstatk := []string{“1”,”2”,”3”….”26”} vstatv := []int{1,2,3…..26} for i:=0;i<len(vstatk);i++{ hash[vstatk[i]] = vstatv[i] }
<a name="EsXlQ"></a>##### make初始化```gofunc makemap(t *maptype, hint int, h *hmap) *hmap {mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)if overflow || mem > maxAlloc {hint = 0}// initialize Hmap 初始化一个hmapif h == nil {h = new(hmap)}h.hash0 = fastrand()// Find the size parameter B which will hold the requested # of elements.// For hint < 0 overLoadFactor returns false since hint < bucketCnt.// 根据传进来的数据,计算出B,然后算出桶buckets的数量,如果B=3,桶为8个,B=4,buckets桶为16个B := uint8(0)for overLoadFactor(hint, B) {B++}h.B = B// allocate initial hash table// if B == 0, the buckets field is allocated lazily later (in mapassign)// If hint is large zeroing this memory could take a while.if h.B != 0 {var nextOverflow *bmap// 创建buckets数量的桶和一些溢出桶h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)// 存储创建的溢出桶if nextOverflow != nil {h.extra = new(mapextra)h.extra.nextOverflow = nextOverflow}}return h}
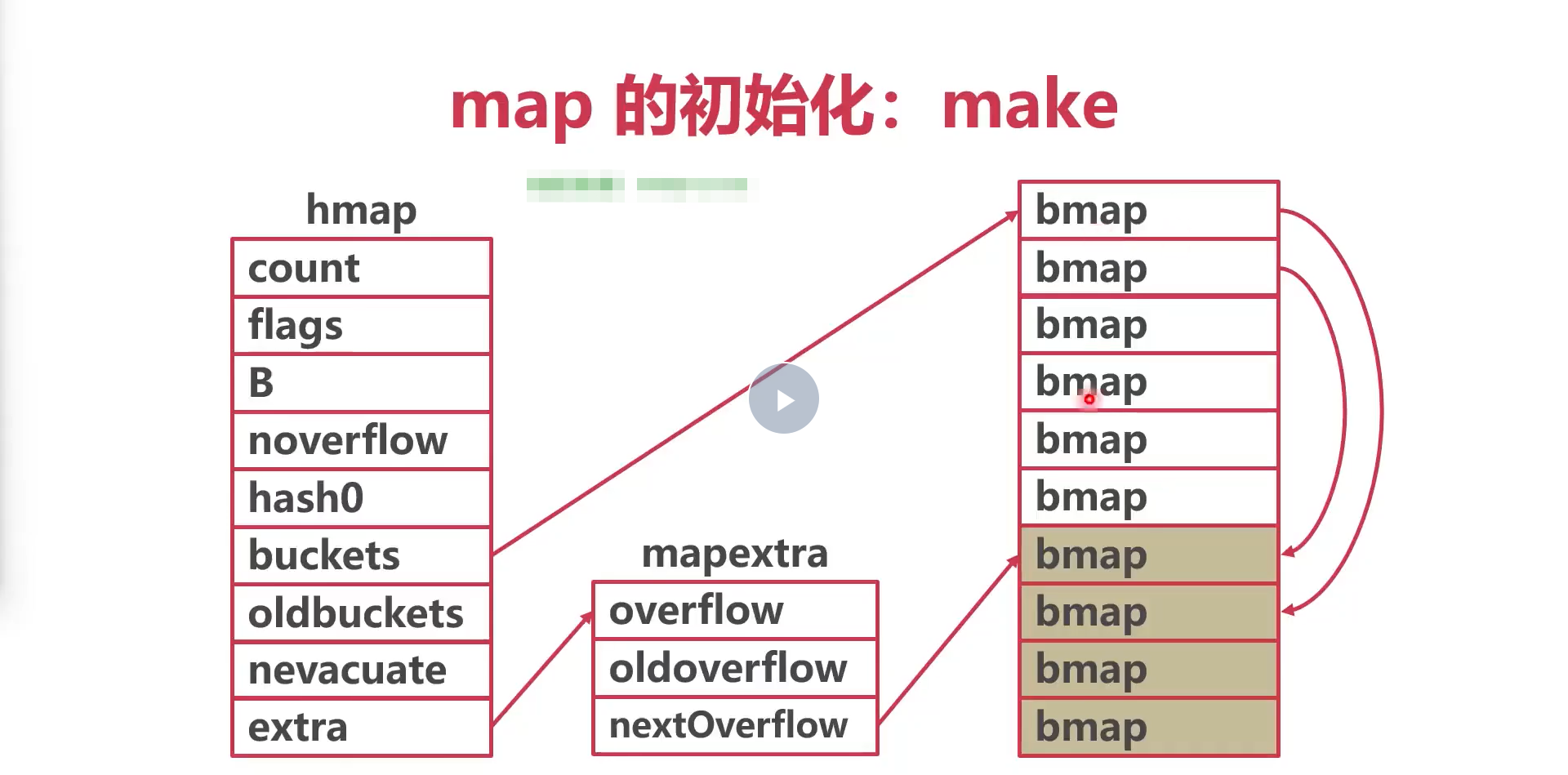
map的访问
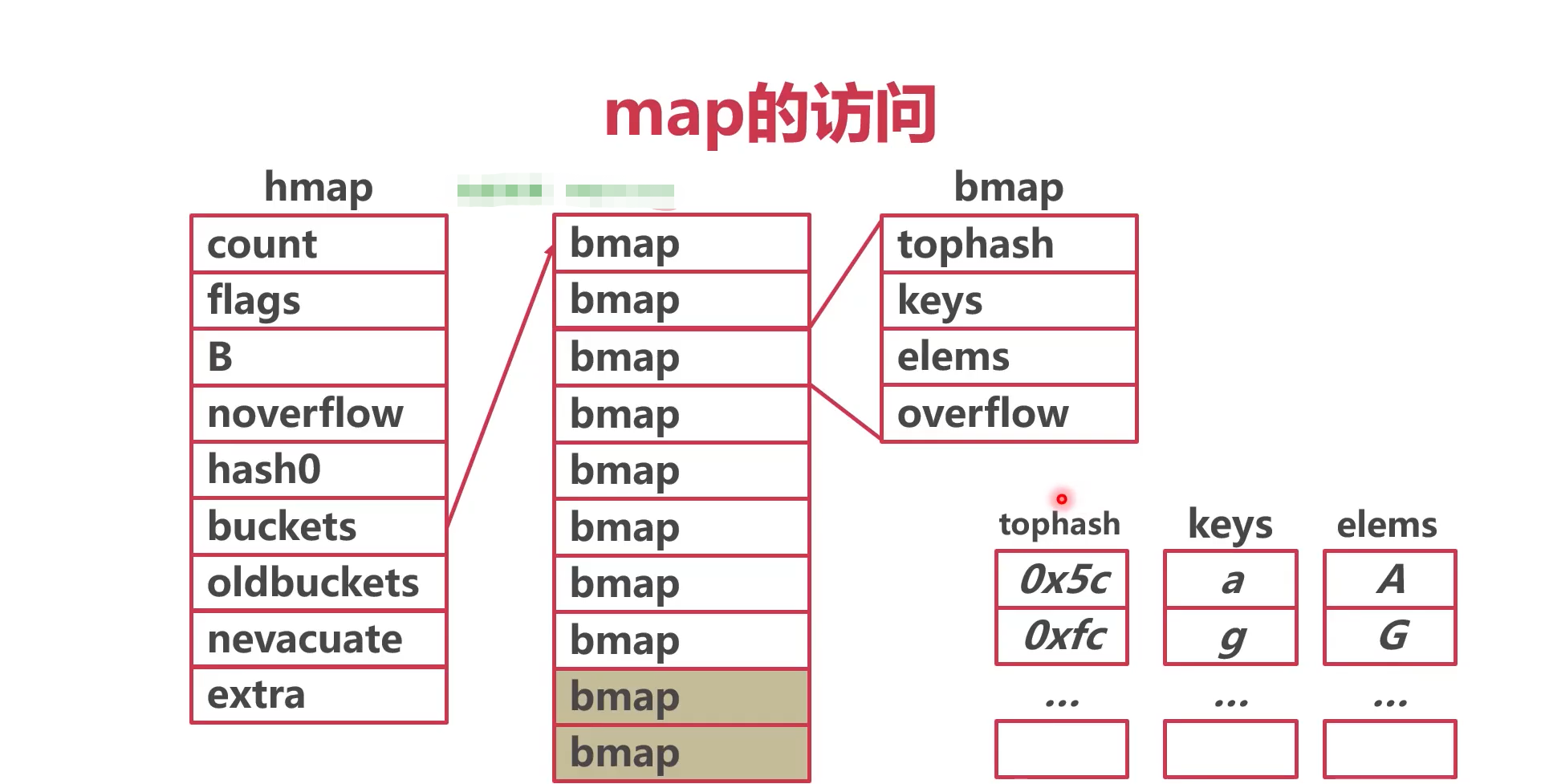
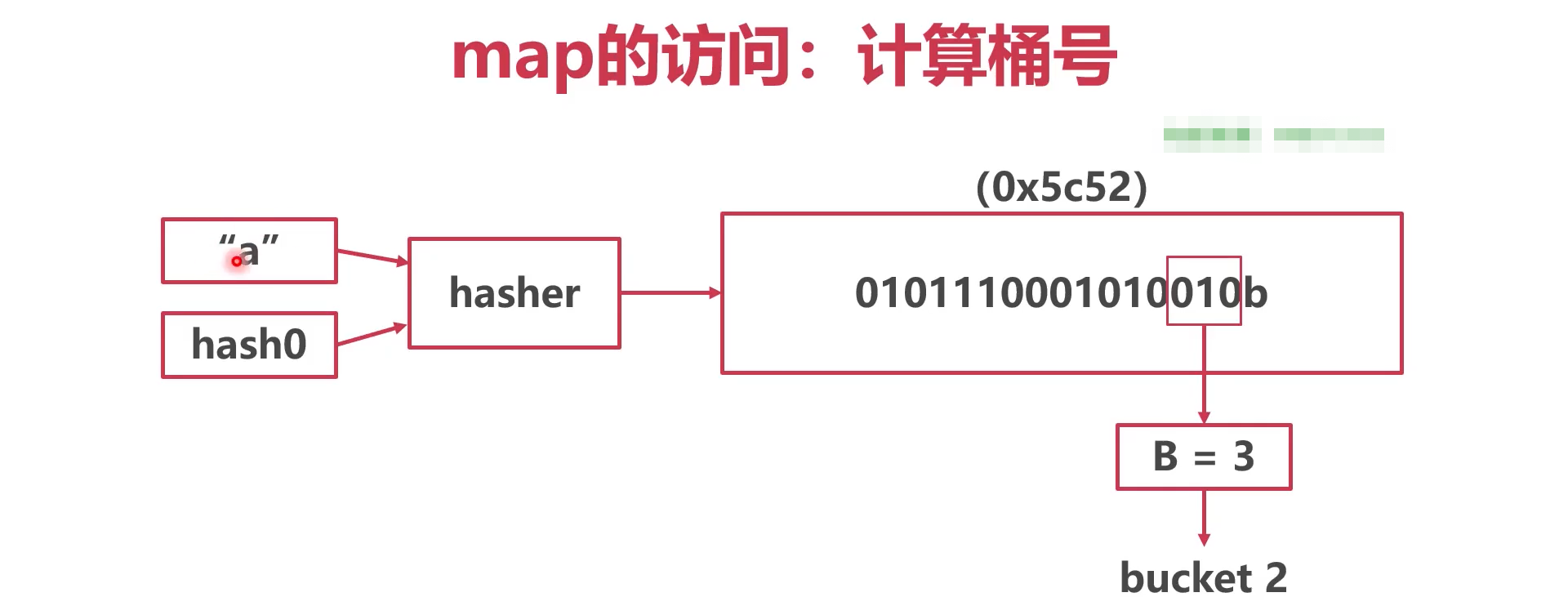
- 计算桶号
- 如果有8个正常桶,则B=3.
- B为3就要取hash值二进制的后3位
- 根据后三位得到的数量,就为桶号 2
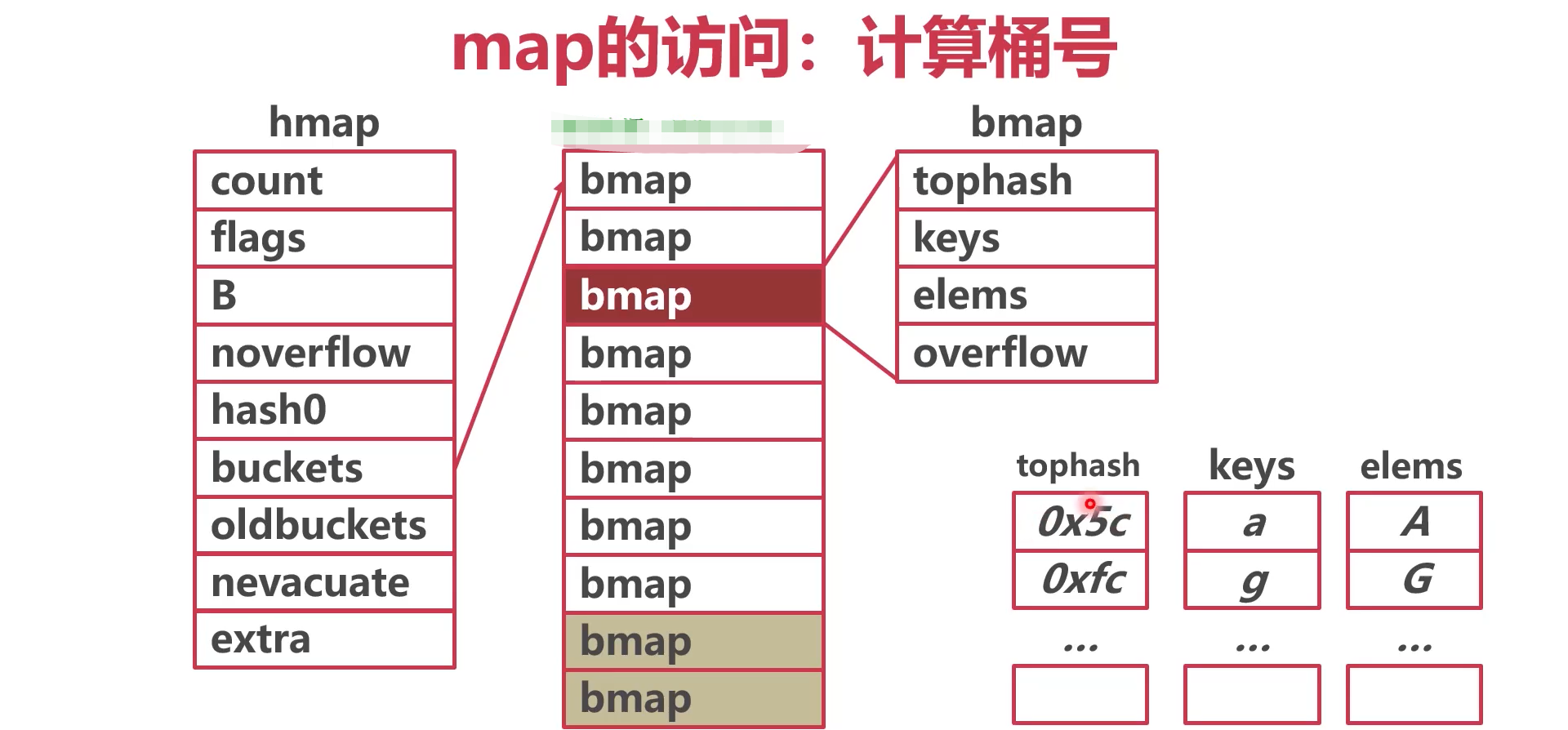
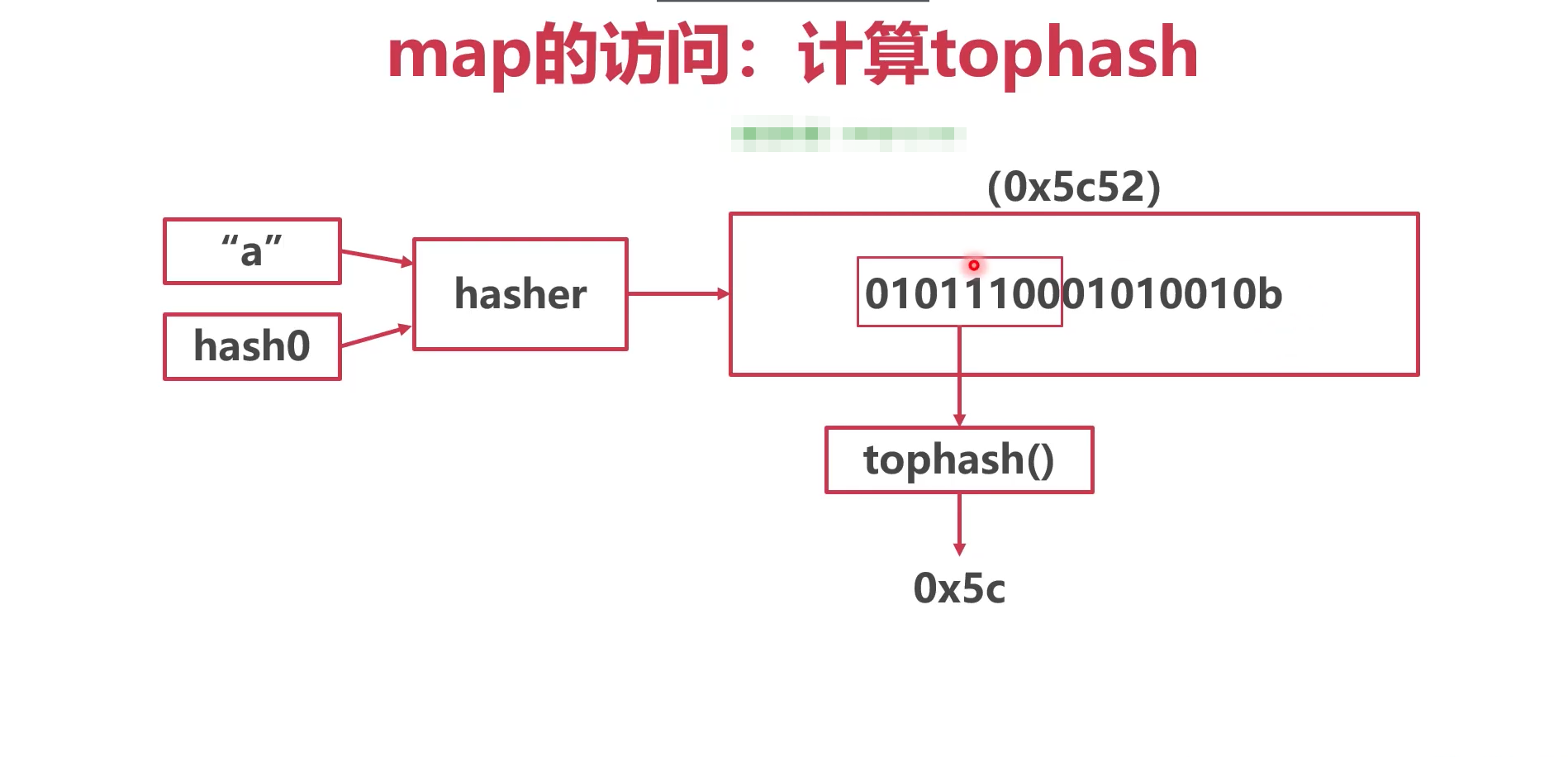
- 计算位置
- 取出key的高八位,计算tophash
- 匹配。
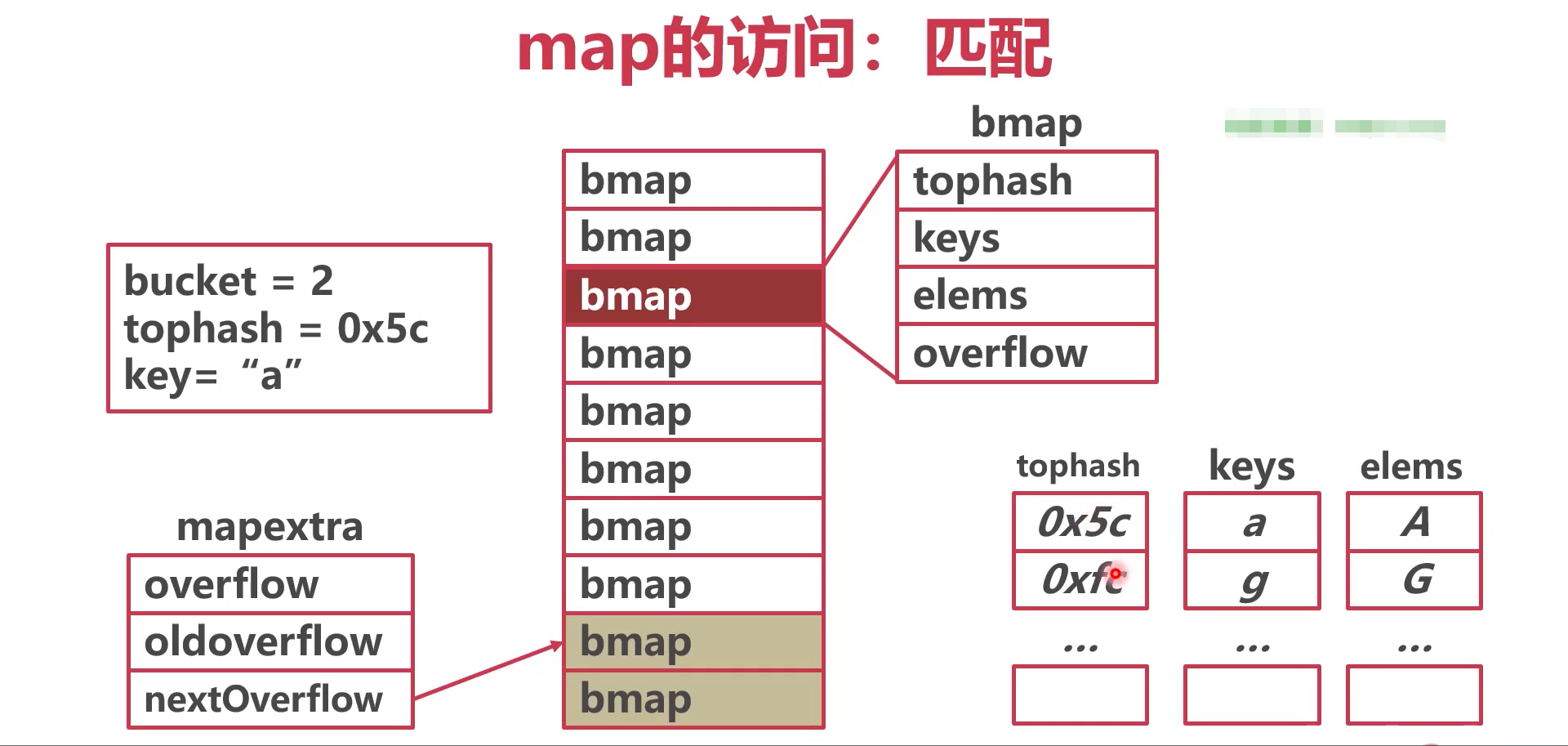
- 用计算出的tophash,在topshash数组中查找,或者用key在keys数组中找
- 如果正常桶中没找到,就去溢出桶overfow中找
- 如果在溢出桶中没找到,则代表key=“a”不存在
- tophash,keys,elems数组长度均为8
- tophash:记录了hash keys值的高八位,用于快速遍历
map扩容
扩容
- 装载系数或者溢出桶增加,会触发map扩容
- “扩容”可能不是增加桶的数量。可能是整理
-
sync.map
是一种并发安全的map结构
- map才扩容时可能会有并发问题
- sync.map使用了两个map,分离了扩容问题
- 不会引发扩容的操作(查,改)使用了read map
- 可能引发扩容的操作(新增)使用dirty map(带锁)
总结
- 只要实现了go接口的全部方法,就自动实现了这个接口
- 不修改代码情况下,抽象总结出新的接口 ```go type People interface { getName() string }
type Man struct { name string }
func (m Man) getName() string { return m.name }
func main(){ var p People = Man{} fmt.Pringtln(p) }
3. 接口的值的底层结构```go// 上述代码。p接口的底层type iface struct {tab *itab //记录了接口类型的信息和实现的方法,方便与类型断言data unsafe.Pointer //该指针指向的地址是上面代码的Man,}
类型断言
类型断言是使用在接口值上的操作
func main(){var p People = Man{}m := p.(Man)//类型断言,弱转换fmt.Pringtln(p)}
可以将接口值转换为其他类型值(或者兼容接口)
- 配合switch进行类型判断
var p People = Man{"男人"}m := p.(Man)fmt.Pringtln(m)switch p.(type) {case Man:fmt.Println("m")}
结构体和指针实现接口 | | 结构体实现接口 | 结构体指针实现接口 | | —- | —- | —- | | 结构体初始化变量 | 通过 | 不通过 | | 结构体指针初始化变量 | 通过 | 通过 |
结构体在实现接口方法时,如果未使用结构体指针实现接口的方法,在编译时会创建一个结构体指针实现接口的方法
package mainimport "fmt"type People interface {getName() string}type Man struct {name string}type Woman struct {name string}func (m Man) getName() string {return m.name}func (w *Woman) getName() string {return w.name}func main() {// man结构体使用结构体实体实现的接口方法var p1 People = Man{}var p2 People = &Man{}fmt.Println(p1,p2)// Woman结构体使用结构体指针实现的接口方法,在初始化时只能使用结构体指针初始化是只能使用var w People = &Woman{}fmt.Println(w)}

-
空接口
空接口底层结构体
type eface struct {_type *_typedata unsafe.Pointer}
空接口值
go的隐式接口更加方便系统的拓展和重构
- 结构体和指针都可以实现接口
-
nil,空接口和空结构体的区别
nil
nil的底层位于 builtin内,是go语言最基础的包
// nil是一下6中类型的零值(初始值)// pointer, channel, func, interface, map, or slice type.var nil Type // 类型可能是一个指针,通道、函数,接口,map,或切片类型
nil是空,并不一定是空指针
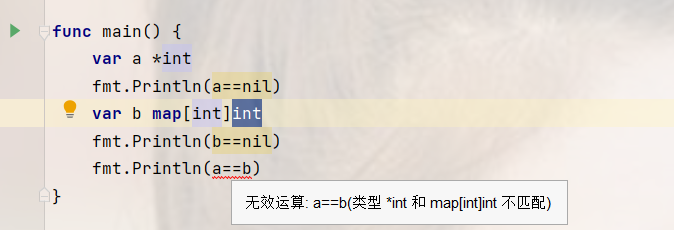
nil是一个变量,其类型可能是一个指针,通道,函数,接口,map,切片,是这6种类型的零值
var a *intfmt.Println(a==nil)//truevar b map[int]intfmt.Println(b==nil)//true
nil是一个有类型的变量,每种类型的nil是不同的,无法比较
-
空结构体
空结构体是go中非常特殊的类型
- 空结构体的值不是nil
-
空接口
空接口不一定是nil接口
空接口的两个属性为nil才为nil接口
var a *intfmt.Println(a==nil)//truevar b interface{}fmt.Println(b==nil)//true// 把空指针a赋值给空接口b后,空接口的结构体的属性 _type就会有值,b = afmt.Println(b==nil)//false
总结
nil是多个类型的零值或空值
- 空结构体的指针和值都不是nil
-
内存对齐
结构体对齐
结构体对齐分为内部对齐和结构体之间对齐
- 内部对齐:考虑成员大小成员的对齐系数
-
结构体内部对齐
指结构体内部成员的相对位置(偏移量)
- 每个成员的偏移量:自身大小与其对齐系数较小值的倍数
- 获取类型对齐系数 ```go func main() { // unsafe.Sizeof()获取大小,unsafe.Alignof()获取对齐系数 fmt.Printf(“bool szie %d, Alignof: %d \n”,unsafe.Sizeof(bool(false)),unsafe.Alignof(bool(false))) fmt.Printf(“int szie %d, Alignof: %d \n”,unsafe.Sizeof(int(0)),unsafe.Alignof(int(0))) fmt.Printf(“int8 szie %d, Alignof: %d \n”,unsafe.Sizeof(int8(0)),unsafe.Alignof(int8(0))) fmt.Printf(“int16 szie %d, Alignof: %d \n”,unsafe.Sizeof(int16(0)),unsafe.Alignof(int16(0))) fmt.Printf(“int32 szie %d, Alignof: %d \n”,unsafe.Sizeof(int32(0)),unsafe.Alignof(int32(0))) fmt.Printf(“int64 szie %d, Alignof: %d \n”,unsafe.Sizeof(int64(0)),unsafe.Alignof(int64(0))) fmt.Printf(“string szie %d, Alignof: %d \n”,unsafe.Sizeof(string(“0”)),unsafe.Alignof(string(0)))
bool szie 1, Alignof: 1
int szie 8, Alignof: 8
int8 szie 1, Alignof: 1
int16 szie 2, Alignof: 2
int32 szie 4, Alignof: 4
int64 szie 8, Alignof: 8
string szie 16, Alignof: 8
}
4. 试验```gotype Demo struct{a bool //大小为1,对齐系数为1b string //大小为16,对齐系数为8c int16//大小为2,对齐系数为2}
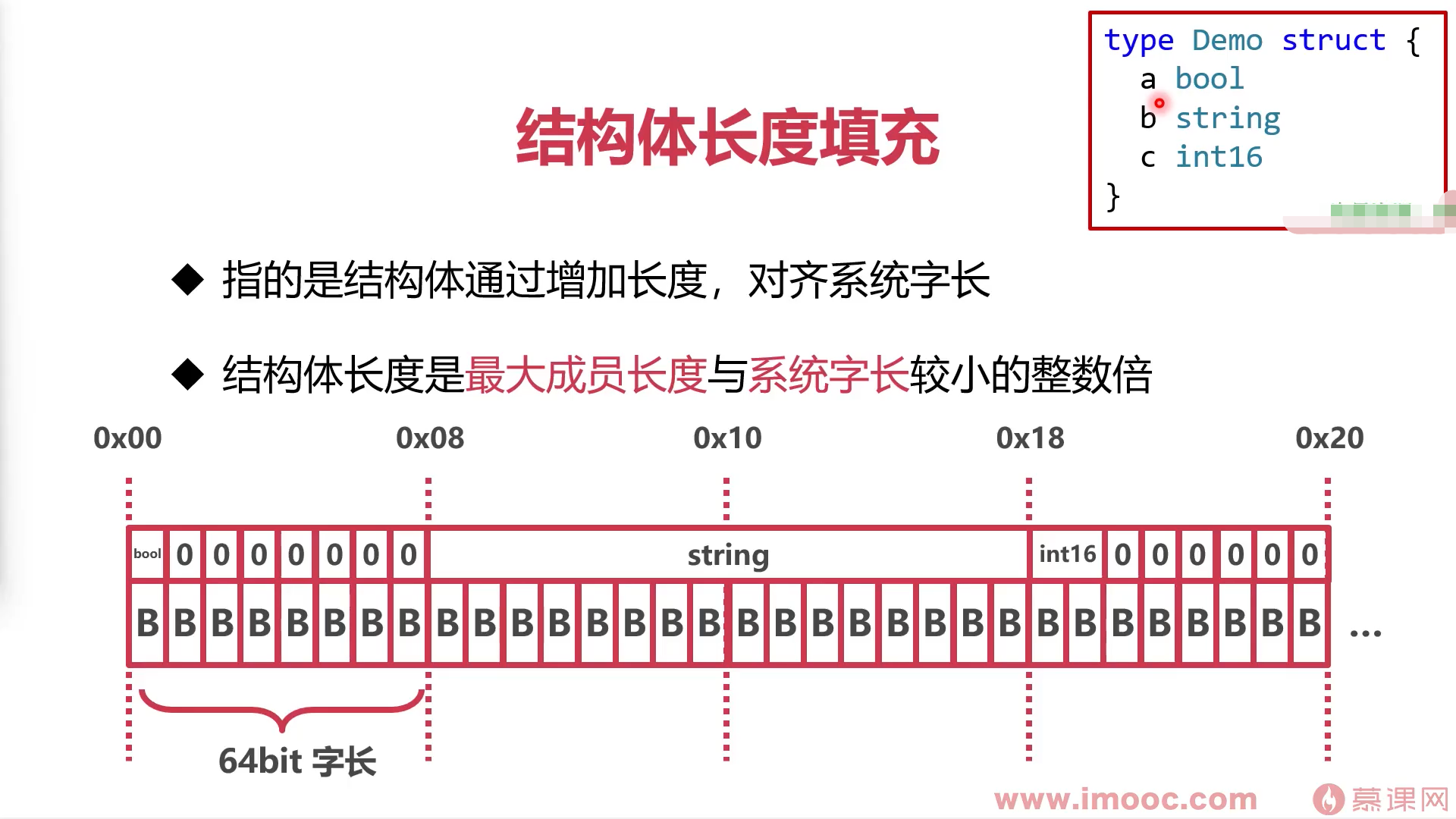
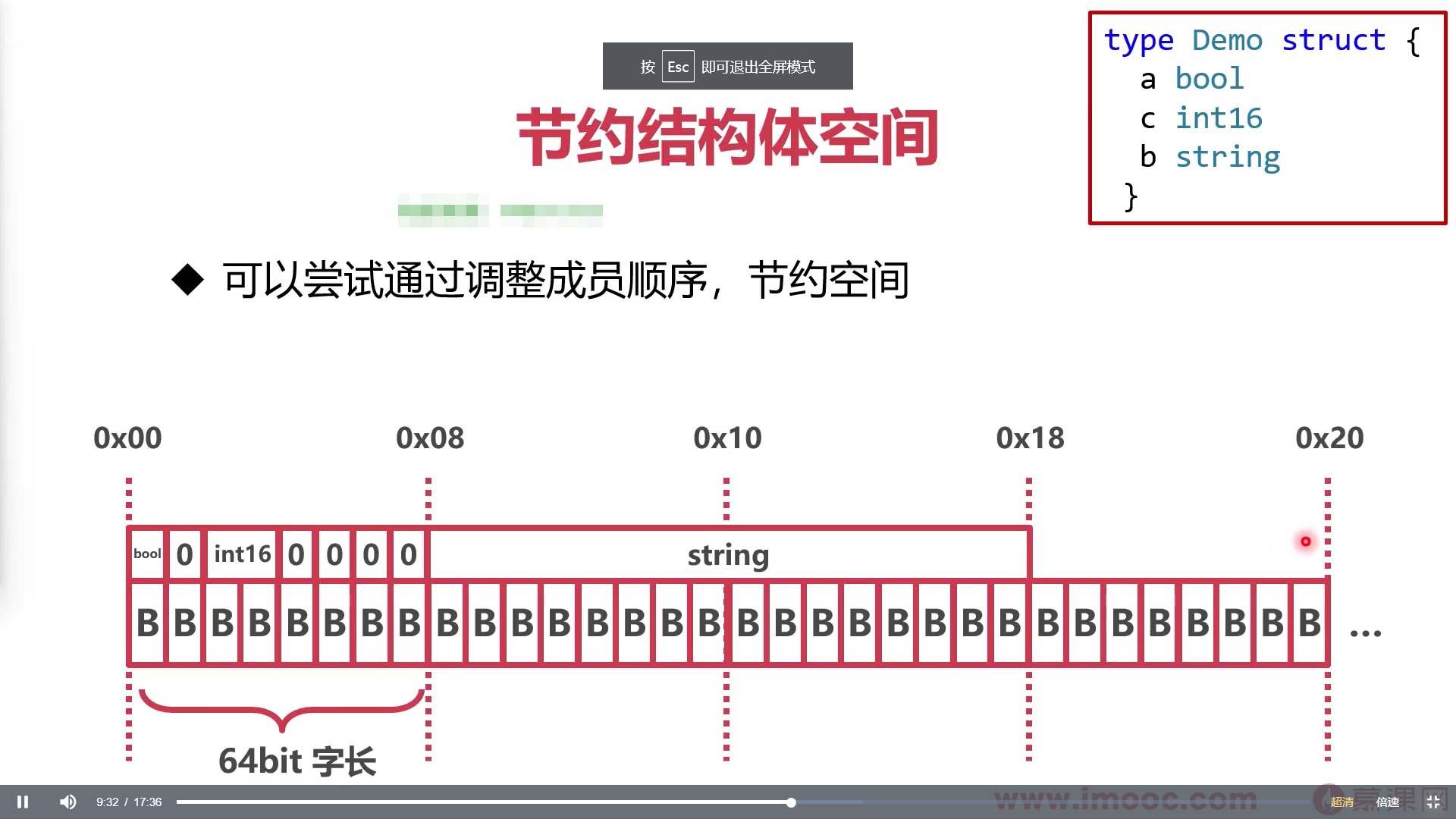
- 结构体对齐系数是其成员最大对齐系数
- 空结构体对齐


若有收获,就点个赞吧
0 人点赞
