- Redis
- 1 Redis简介
- 2 Redis特性优势
- 3 Redis与其他key-value存储有什么不同?
- 4 Redis安装
- 5 Redis基础配置文件介绍
- 6 Redis安全配置
- 7 Redis的单线程架构
- 8 Redis的数据结构
- 9 Redis基础命令
- 10 Redis消息队列
- 11 Redis持久化
- 12 Redis高可用与集群
- 13 Redis哨兵模式
- 14 Redis备份与恢复实战
- 15 Redis Cluster集群原理与部署
- 16 Redis应用中的问题与风险
- 17 Redis内存优化与系统优化
Redis
1 Redis简介
Redis 是完全开源的,遵守 BSD 协议,是一个高性能的 key-value 数据库。
Redis 与其他 key - value 缓存产品有以下三个特点:
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
2 Redis特性优势
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 持久化 - 存在脑子里的知识可能忘记丢失,持久化存储到硬盘的数据才相对于最稳定。
- 丰富的数据类型 – Redis支持二进制的 Strings, Lists, Hashes, Sets 及 Sorted Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
- 丰富的特性 – Redis同样也支持事务、流水线、发布/订阅、消息队列功能。
- 高可用以及分布式 - 主从配置简单,容易上手。可以提供基本的数据备份。在3.0以后的版本中,还提供了分布式的功能。
什么是原子性,什么是原子性操作?举个例子:A想要从自己的帐户中转1000块钱到B的帐户里。那个从A开始转帐,到转帐结束的这一个过程,称之为一个事务。在这个事务里,要做如下操作:1. 从A的帐户中减去1000块钱。如果A的帐户原来有3000块钱,现在就变成2000块钱了。2. 在B的帐户里加1000块钱。如果B的帐户如果原来有2000块钱,现在则变成3000块钱了。如果在A的帐户已经减去了1000块钱的时候,忽然发生了意外,比如停电什么的,导致转帐事务意外终止了,而此时B的帐户里还没有增加1000块钱。那么,我们称这个操作失败了,要进行回滚。回滚就是回到事务开始之前的状态,也就是回到A的帐户还没减1000块的状态,B的帐户的原来的状态。此时A的帐户仍然有3000块,B的帐户仍然有2000块。我们把这种要么一起成功(A帐户成功减少1000,同时B帐户成功增加1000),要么一起失败(A帐户回到原来状态,B帐户也回到原来状态)的操作叫原子性操作。如果把一个事务可看作是一个程序,它要么完整的被执行,要么完全不执行。这种特性就叫原子性。
2.1 Redis应用场景
1.缓存 - 键过期时间
缓存session会话;缓存用户信息,找不到再去Mysql查,查到然后回写到Redis;优惠券过期时间;
2.排行榜 - 列表 & 有序集合
热度排名排行榜
发布时间排行榜
3.计数器应用 - 天然支持计数器
帖子浏览数
视频播放次数
商品浏览数
4.社交网络 - 集合
踩/赞,粉丝,共同好友/喜好,推送
5.消息队列系统 - 发布订阅
配合ELK实现日志收集
3 Redis与其他key-value存储有什么不同?
- Redis有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个不同于其他数据库的进化路径。Redis的数据类型都是基于基本数据结构的同时对程序员透明,无需进行额外的抽象。
- Redis运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,因为数据量不能大于硬件内存。在内存数据库方面的另一个优点是,相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简单,这样Redis可以做很多内部复杂性很强的事情。同时,在磁盘格式方面他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问。
4 Redis安装
下载并安装
wget http://download.redis.io/releases/redis-5.0.2.tar.gztar xzf redis-5.0.2.tar.gzln -s redis-5.0.2 rediscd redismake (解释:编译redis源码)
遇到问题【adlist.o】Error 127
由于Redis是C语言开发的,因此需要安装gcc编译器来编译代码,我们下载的Redis包里面是源代码,需要编译:
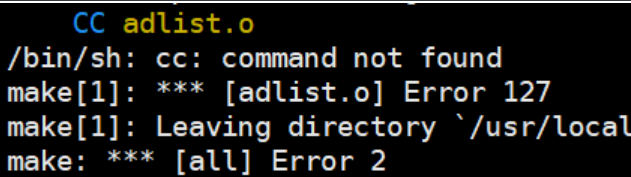
# 需要安装gccyum install gcc -y
然后再次make,又遇问题
请重新解压出Redis文件然后再次编译

安装成功之后,启动redis,并查看端口
# cd src# ./redis-server &# ss -lntp|grep 6379LISTEN 0 128 *:6379 *:* users:(("redis-server",pid=8990,fd=7))LISTEN 0 128 [::]:6379 [::]:* users:(("redis-server",pid=8990,fd=6))
进入redis
[root@mysql-65 redis-6.0.9]# ./redis-cli127.0.0.1:6379>
编辑redis服务启动文件
#1、创建redis用户并授权[root@centos7 ~]# useradd -M -s /sbin/nologin redis#2、创建目录和redis配置文件[root@mysql-65 6379]# mkdir -p /data/6379/[root@centos7 ~]# chown -R redis:redis /data/6379/ #注意目录权限[root@mysql-65 6379]# cp -a /usr/local/redis/redis.conf /data/6379/#3、编辑redis服务启动文件[root@mysql-65 6379]# cat /usr/lib/systemd/system/redis.service[Unit]Description=RedisAfter=network.target[Service]Type=forkingExecStart=/usr/local/redis/src/redis-server /data/6379/redis.confExecReload=/bin/kill -s HUP $MAINPIDExecStop=/usr/local/redis/src/redis-cli shutdownUser=redisGroup=redisPrivateTmp=true[Install]WantedBy=multi-user.target#4、验证redis启动[root@mysql-65 6379]# systemctl daemon-reload[root@mysql-65 6379]# systemctl enable redis[root@mysql-65 6379]# systemctl start redis[root@mysql-65 6379]# ss -lntp|grep redisLISTEN 0 511 192.168.1.65:6379 *:* users:(("redis-server",pid=17478,fd=7))LISTEN 0 511 127.0.0.1:6379 *:* users:(("redis-server",pid=17478,fd=6))
4.1 Redis安装警告问题解决
1.WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128backlog参数控制的是三次握手的时候server端收到client ack确认号之后的队列值,即全连接队列vim /etc/sysctl.confnet.core.somaxconn = 1024然后执行sysctl -p2.WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect0:表示内核将检查是否有足够的可用内存供应用进程使用。如果有足够的可用内存,内存申请允许。否则,内存申请失败,并把错误返回给应用程序1:表示内核允许分配所有的物理内存,而不管当前的内存状态如何2:表示内核允许分配超过所有物理内存和交换空间总和的内存vim /etc/sysctl.confvm.overcommit_memory = 1然后执行sysctl -p3.WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo madvise > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled (set to 'madvise' or 'never')警告:你在内核中启用了透明大页面(THP)支持。这将在Redis中造成延迟和内存使用问题。要解决此问题,请以根用户身份运行命令“echo never> / sys / kernel / mm / transparent_hugepage / enabled”,并将其添加到你的/etc/rc.local中,以便在重启后保留设置。禁用THP后,必须重新启动Redisecho never > /sys/kernel/mm/transparent_hugepage/enabledecho 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' >> /etc/rc.d/rc.localchmod +x /etc/rc.d/rc.local然后重启redis即可
5 Redis基础配置文件介绍
[root@mysql-65 redis]# cd /data/6379/[root@mysql-65 6379]# egrep -v "^#|^$" /data/6379/redis.confbind 127.0.0.1 192.168.1.65protected-mode yesport 6379tcp-backlog 511timeout 300tcp-keepalive 300daemonize yessupervised nopidfile /data/6379/redis.pidloglevel noticelogfile "/data/6379/redis.log"databases 16always-show-logo yessave 900 1save 300 10save 60 10000stop-writes-on-bgsave-error yesrdbcompression yesrdbchecksum yesdbfilename dump.rdbrdb-del-sync-files nodir /data/6379replica-serve-stale-data yesreplica-read-only yesrepl-diskless-sync norepl-diskless-sync-delay 5repl-diskless-load disabledrepl-disable-tcp-nodelay noreplica-priority 100acllog-max-len 128lazyfree-lazy-eviction nolazyfree-lazy-expire nolazyfree-lazy-server-del noreplica-lazy-flush nolazyfree-lazy-user-del nooom-score-adj nooom-score-adj-values 0 200 800appendonly noappendfilename "appendonly.aof"appendfsync everysecno-appendfsync-on-rewrite noauto-aof-rewrite-percentage 100auto-aof-rewrite-min-size 64mbaof-load-truncated yesaof-use-rdb-preamble yeslua-time-limit 5000slowlog-log-slower-than 10000slowlog-max-len 128latency-monitor-threshold 0notify-keyspace-events ""hash-max-ziplist-entries 512hash-max-ziplist-value 64list-max-ziplist-size -2list-compress-depth 0set-max-intset-entries 512zset-max-ziplist-entries 128zset-max-ziplist-value 64hll-sparse-max-bytes 3000stream-node-max-bytes 4096stream-node-max-entries 100activerehashing yesclient-output-buffer-limit normal 0 0 0client-output-buffer-limit replica 256mb 64mb 60client-output-buffer-limit pubsub 32mb 8mb 60hz 10dynamic-hz yesaof-rewrite-incremental-fsync yesrdb-save-incremental-fsync yesjemalloc-bg-thread yes配置文件说明:daemonize yes #Redis默认不是以守护进程的方式运行,可以通过该配置项修改,使用 yes 启用守护进程protected-mode yes #redis3.2之后加入的新特性,在没有设置bind IP和密码的时候,redis只允许访问127.0.0.1:6379,可以远程连接,但当访问将提示警告信息并拒绝远程访问port 6379 #指定Redis监听端口,默认端口为6379tcp-backlog 511 #三次握手的时候server端收到client ack确认好之后的队列值,即全队列长度tcp-keepalive 300 #tcp会话保持时间300ssupervised no #和OS相关参数,可设置通过upstart和systemd管理Redis守护进程,centos7后都使用systemdlogfile /data/6379/redis.log #日志文件位置dir /data/6379 #指定本地数据库存放目录dbfilename dump.rdb #指定本地数据库文件名,默认值为dump.rdbpidfile /data/6379/redis.pid #当rdis以守护进程方式运行时,redis会生成redis.pid文件,可以通过pidfile指定bind 192.168.1.65 127.0.0.1 #绑定主机地址,可以使本机IP也可以127.0.0.1timeout 300 #当客户端闲置超时时间默认单位为秒,默认为0,表示永不超时loglevel verbose #日志级别databases 16 #设置数据库的数量,默认数据库为0-15,共16个库always-show-logo yes #在启动redis时是否显示redis的logosave 900 1 #持久化同步到数据文件的配置,表示在900秒内有一个键内容发生更改就会触发快照机制stop-writes-on-bgsave-error yes #yes时因空间满等原因快照无法保存出错时,禁止redis写入操作,建议为nordbcompression yes #存储到本地数据文件是否压缩,默认为yes,redis采用LZF压缩,当数据量较小,为节省CPU可以考虑关闭。数据较大时,考虑磁盘空间以及I/O性能进行选择。rdbchecksum yes #是否对备份文件开启RC64校验,默认是开启dbfilename dump.rdb #指定本地数据库文件名,默认值为dump.rdbdir /data/6379 #指定本地数据库存放目录replica-serve-stale-data yes#当从库同主库失去连接或者复制正在进行,从库有两种运行方式:#1.设置为yes(默认设置),从库会继续响应客户端的读请求,此为建议值#2.设置为no,除去指定的命令之外的任何请求都会返回一个错误"SYNC with master in progress"replica-read-only yes #是否设置从库只读,建议值为yes,否则主库同步从库时可能会覆盖数据,造成数据丢失repl-diskless-sync no #是否使用socket方式复制数据(无盘同步),新slave连接连接时候需要做数据的全量同步,redis server就要从内存dump出新的RDB文件,然后从master传到slave,有两种方式把RDB文件传输给客户端:#1、基于硬盘(disk-backed):为no时,master创建一个新进程dump生成RDB磁盘文件,RDB完成之后由父进程(即主进程)将RDB文件发送给slaves,此为推荐值#2、基于socket(diskless):master创建一个新进程直接dump RDB至slave的网络socket,不经过主进程和硬盘基于硬盘(为no),RDB文件创建后,一旦创建完毕,可以同时服务更多的slave,但是基于socket(为yes), 新slave连接到master之后得逐个同步数据。当磁盘I/O较慢且网络较快时,可用diskless(yes),否则使用磁盘(no)repl-diskless-sync-delay 30 #diskless时复制的服务器等待的延迟时间,设置0为关闭,在延迟时间内到达的客户端,会一起通过diskless方式同步数据,但是一旦复制开始,master节点不会再接收新slave的复制请求,直到下一次同步开始才再接收新请求。即无法为延迟时间后到达的新副本提供服务,新副本将排队等待下一次RDB传输,因此服务器会等待一段时间才能让更多副本到达。推荐值:30-60repl-ping-replica-period 10 #slave根据master指定的时间进行周期性的PING master 监测master状态repl-timeout 60 #复制连接的超时时间,需要大于repl-ping-slave-period,否则会经常报超时repl-disable-tcp-nodelay no #是否在slave套接字发送SYNC之后禁用 TCP_NODELAY,如果选择"yes",Redis将合并多个报文为一个大的报文,从而使用更少数量的包向slaves发送数据,但是将使数据传输到slave上有延迟,Linux内核的默认配置会达到40毫秒,如果 "no" ,数据传输到slave的延迟将会减少,但要使用更多的带宽repl-backlog-size 512mb #复制缓冲区内存大小,当slave断开连接一段时间后,该缓冲区会累积复制副本数据,因此当slave 重新连接时,通常不需要完全重新同步,只需传递在副本中的断开连接后没有同步的部分数据即可。只有在至少有一个slave连接之后才分配此内存空间。repl-backlog-ttl 3600 #多长时间内master没有slave连接,就清空backlog缓冲区replica-priority 100 #当master不可用,Sentinel会根据slave的优先级选举一个master,此值最低的slave会当选master,而配置成0,永远不会被选举,一般多个slave都设为一样的值,让其自动选择min-replicas-to-write 3 #至少有3个可连接的slave,mater才接受写操作,并同步到slave中min-replicas-max-lag 10 #和上面至少3个slave的ping延迟不能超过10秒,否则master也将停止写操作slaveof <masterip> <masterport> #主从配置时的选项,设置为本机为slav服务时,通过配置好的master地址以及端口,在slave启动时,它会自动从master进行数据同步masterauth <master-password> #当master服务设置了密码保护时,slav服务连接master的密码,一般很少设置密码,特殊情况下使用requirepass foobared #设置redis连接密码,如果配置了连接密码,客户端在连接redis时需要通过AUTH<password>命令提供密码,默认关闭rename-command FLUSHALL SUPER_FLUSHALL #重命名一些高危命令,示例:rename-command FLUSHALL "" 禁用命令maxclients 10000 #设置同一时间最大客户端连接数,当前默认查询为10000.maxmemory 4294967296 #redis使用的最大内存,单位为bytes字节,0为不限制,建议设为物理内存一半,8G内存的计算方式8(G)*1024(MB)1024(KB)*1024(Kbyte),需要注意的是缓冲区是不计算在maxmemory内。appendonly no #指定是否在每次更新操作后进行日志记录,看数据的重要性,如果一条记录都不允许丢失的话,建议开启。appendfilename appendonly.aof #指定AOF文件名,默认为appendonly.aofappendfsync everysec #指定更新日志条件,共有3个可选值:#no:表示等操作系统进行数据缓存同步到磁盘(快)#always:表示每次更新操作后手动调用fsync()将数据写到磁盘(慢,安全)#everysec:表示每秒同步一次(折中,默认值)no-appendfsync-on-rewrite no #在aof rewrite期间,是否对aof新记录的append暂缓使用文件同步策略,主要考虑磁盘IO开支和请求阻塞时间。默认为no,表示"不暂缓",新的aof记录仍然会被立即同步,Linux的默认fsync策略是30秒,如果为yes 可能丢失30秒数据,但由于yes性能较好而且会避免出现阻塞因此比较推荐。vm-enabled no #指定是否启用虚拟内存机制,默认值为0vm-swap-file /tmp/redis.swap #虚拟内存文件路径vm-max-memory 0 #设置开启虚拟内存后,redis将使用的最大物理内存的大小,默认为0include /path/to/local.conf #指定包含其他的配置文件auto-aof-rewrite-percentage 100 # 当Aof log增长超过指定百分比例时,重写AOF文件, 设置为0表示不自动重写Aof 日志,重写是为了使aof体积保持最小,但是还可以确保保存最完整的数据auto-aof-rewrite-min-size 64mb #触发aof rewrite的最小文件大小aof-load-truncated yes #是否加载由于其他原因导致的末尾异常的AOF文件(主进程被kill/断电等),建议yesaof-use-rdb-preamble yes #redis4.0新增RDB-AOF混合持久化格式,在开启了这个功能之后,AOF重写产生的文件将同时包含RDB格式的内容和AOF格式的内容,其中RDB格式的内容用于记录已有的数据,而AOF格式的内存则用于记录最近发生了变化的数据,这样Redis就可以同时兼有RDB持久化和AOF持久化的优点(既能够快速地生成重写文件,也能够在出现问题时,快速地载入数据)。lua-time-limit 5000 #lua脚本的最大执行时间,单位为毫秒cluster-enabled yes #是否开启集群模式,默认是单机模式cluster-config-file nodes-6379.conf #由node节点自动生成的集群配置文件名称cluster-node-timeout 15000 #集群中node节点连接超时时间,超过此时间,会踢出集群cluster-replica-validity-factor 10 #在执行故障转移的时候可能有些节点和master断开一段时间数据比较旧,这些节点就不适用于选举为master,超过这个时间的就不会被进行故障转移,计算公式:(node-timeout * replica-validity-factor) + repl-ping-replica-periodcluster-migration-barrier 1 #集群迁移屏障,一个主节点至少拥有一个正常工作的从节点,即如果主节点的slave节点故障后会将多余的从节点分配到当前主节点成为其新的从节点。cluster-require-full-coverage yes #集群请求槽位全部覆盖,如果一个主库宕机且没有备库就会出现集群槽位不全,那么yes情况下redis集群槽位验证不全就不再对外提供服务,而no则可以继续使用但是会出现查询数据查不到的情况(因为有数据丢失)。建议为nocluster-replica-no-failover no #如果为yes,此选项阻止在主服务器发生故障时尝试对其主服务器进行故障转移。 但是,主服务器仍然可以执行手动强制故障转移,一般为no#Slow log 是 Redis 用来记录超过指定执行时间的日志系统, 执行时间不包括与客户端交谈,发送回复等I/O操作,而是实际执行命令所需的时间(在该阶段线程被阻塞并且不能同时为其它请求提供服务)slow log 保存在内存里面,读写速度非常快,因此可放心地使用,不必担心因为开启 slow log 而影响 Redis 的速度slowlog-log-slower-than 10000 #以微秒为单位的慢日志记录,为负数会禁用慢日志,为0会记录每个命令操作。slowlog-max-len 128 #最多记录多少条慢日志的保存队列长度,达到此长度后,记录新命令会将最旧的命令从命令队列中删除,以此滚动删除
5.1 生产环境配置文件
#生产环境的redis.conf配置信息bind 10.4.61.63 127.0.0.1protected-mode yesport 9005tcp-backlog 511timeout 0tcp-keepalive 300daemonize yessupervised nopidfile /var/run/redis_9005.pidloglevel noticelogfile /var/log/redis_9005.logdatabases 16always-show-logo yessave ""stop-writes-on-bgsave-error nordbcompression yesrdbchecksum yesdbfilename dump.rdbdir /var/lib/redis/9005replica-serve-stale-data yesreplica-read-only yesrepl-diskless-sync norepl-diskless-sync-delay 5repl-disable-tcp-nodelay noreplica-priority 100maxmemory 4294967296lazyfree-lazy-eviction nolazyfree-lazy-expire nolazyfree-lazy-server-del noreplica-lazy-flush noappendonly noappendfilename "appendonly.aof"appendfsync everysecno-appendfsync-on-rewrite noauto-aof-rewrite-percentage 100auto-aof-rewrite-min-size 64mbaof-load-truncated yesaof-use-rdb-preamble yeslua-time-limit 5000cluster-enabled yescluster-config-file nodes-9005.confcluster-node-timeout 15000cluster-require-full-coverage noslowlog-log-slower-than 10000slowlog-max-len 128latency-monitor-threshold 0notify-keyspace-events ""hash-max-ziplist-entries 512hash-max-ziplist-value 64list-max-ziplist-size -2list-compress-depth 0set-max-intset-entries 512zset-max-ziplist-entries 128zset-max-ziplist-value 64hll-sparse-max-bytes 3000stream-node-max-bytes 4096stream-node-max-entries 100activerehashing yesclient-output-buffer-limit normal 0 0 0client-output-buffer-limit replica 256mb 64mb 60client-output-buffer-limit pubsub 32mb 8mb 60hz 10dynamic-hz yesaof-rewrite-incremental-fsync yesrdb-save-incremental-fsync yesrename-command FLUSHALL SUPER_FLUSHALLrename-command FLUSHDB SUPER_FLUSHDB
配置好文件之后,我们重启redis:
[root@mysql-65 6379]# ss -lntp|grep redisLISTEN 0 128 *:6379 *:* users:(("redis-server",pid=8990,fd=7))LISTEN 0 128 [::]:6379 [::]:* users:(("redis-server",pid=8990,fd=6))[root@mysql-65 ~]# systemctl restart redis[root@mysql-65 ~]# systemctl status redis● redis.service - RedisLoaded: loaded (/usr/lib/systemd/system/redis.service; enabled; vendor preset: disabled)Active: active (running) since 四 2020-12-10 11:18:29 CST; 4s agoProcess: 17555 ExecStop=/usr/local/redis/src/redis-cli shutdown (code=exited, status=0/SUCCESS)Process: 17558 ExecStart=/usr/local/redis/src/redis-server /data/6379/redis.conf (code=exited, status=0/SUCCESS)Main PID: 17559 (redis-server)CGroup: /system.slice/redis.service└─17559 /usr/local/redis/src/redis-server 127.0.0.1:637912月 10 11:18:29 mysql-65 systemd[1]: Stopped Redis.12月 10 11:18:29 mysql-65 systemd[1]: Starting Redis...12月 10 11:18:29 mysql-65 systemd[1]: Started Redis.
6 Redis安全配置
- redis没有用户概念,只能设置密码
- redis默认工作在保护模式下,不允许远程用户登录
所以为了可以实现远程访问,我们需要加入以下几个配置:
[root@mysql-65 redis]# cat /data/6379/redis.confbind 192.168.1.65 127.0.0.1 #绑定远程服务器IP地址requirepass 123456 #设置密码#配置好之后,重启我们的redis[root@mysql-65 6379]# systemctl restart redis--------------- 验证 ---------------[root@mysql-65 redis]# ./src/redis-cli -h 192.168.1.65 -a 123456192.168.1.65:6379> set name zhangsanOK192.168.1.65:6379> get name"zhangsan"192.168.1.65:6379>
7 Redis的单线程架构
Redis使用了单线程架构和I/O多路复用模型来实现高性能的内存数据库服务
7.1 单线程模型
现在开启三个redis-cli客户端同时执行命令
客户端1设置一个字符串键值对:
10.4.60.96:7001> set hello world
客户端2对counter做自增操作:
10.4.60.96:7001> incr counter
客户端3对counter做自增操作:
10.4.60.96:7001> incr counter
Redis客户端与服务端的模型如下图所示,每次客户端调用都经历了发送命令、执行命令、返回结果三个过程。
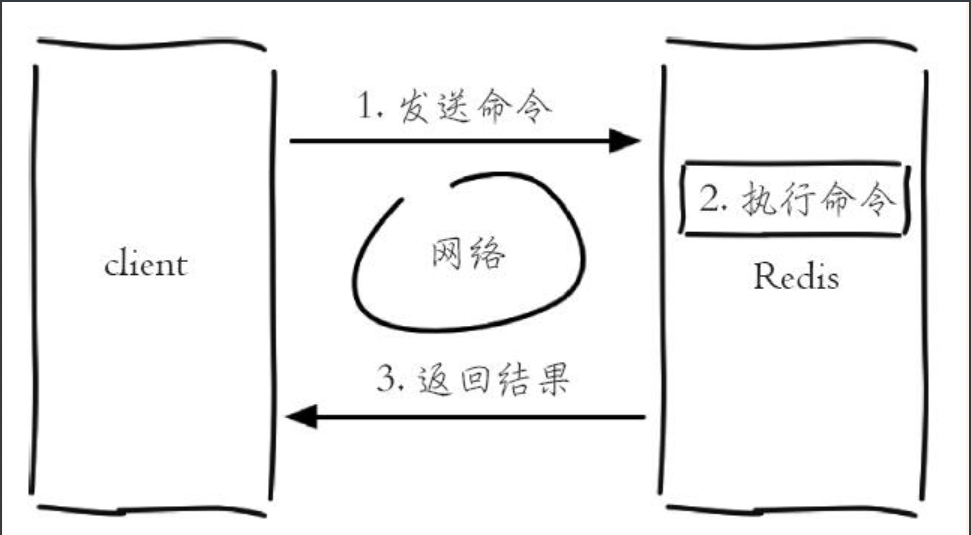
其中第二步是重点讨论的,因为Redis是单线程来处理命令的,所以一条命令从客户端达到服务端不会立刻被执行,所有命令都会进入一个队列中,然后逐个被执行。所以上面3个客户端命令的执行顺序是不确定的,如下图所示:

但是可以确定不会有两条命令被同时执行,如下图所示:

所以两条incr命令无论怎么执行最终结果都是2,不会产生并发问题,这就是Redis单线程的基本模型。
7.2 为什么单线程还能这么快
通常来说,单线程的处理能比要比多线程差,但是为什么Redis使用单线程模型会达到每秒万级别的处理能力呢?可以将其归结为三点:
- 纯内存访问,Redis将所有数据放在内存中,内存的响应时长大约为100纳秒,这是Redis达到每秒万级别访问的重要基础。
- 非阻塞I/O,Redis使用epoll作为I/O多路复用技术的实现,再加上Redis自身的事件处理模型将epoll中的连接、读写、关闭都转换为事件,不在网络I/O上浪费过多的时间,如下图所示:

- 单线程避免了线程切换和竞态产生的消耗。
8 Redis的数据结构
Redis主要支持的数据类型有5种:String、Hash、List、Set以及Sorted Set。
8.1 String字符串类型
String是Redis中最基本的数据类型,一个key对应的一个value。
String类型是二进制安全的,意思是redis的string可以包含任何数据。如数字,字符串,jpg图片或者序列化的对象。当然这个值也是有限制的,最大值不能超过512M。
#1.创建key用set,查看用get192.168.1.65:6379> set key1 helloOK192.168.1.65:6379> set key2 123OK192.168.1.65:6379> get key1"hello"192.168.1.65:6379> get key2"123"PS:如果当前key的值存在的话,则会覆盖#2.批量插入mset和批量查询mget192.168.1.65:6379> mset key3 three key4 four key5 fiveOK192.168.1.65:6379> mget key3 key4 key51) "three"2) "four"3) "five"PS:批量插入数据或者批量查询数据可以减少网络的开销#3.追加append与del删除192.168.1.65:6379> append key1 world(integer) 10192.168.1.65:6379> get key1"helloworld"192.168.1.65:6379> del key1 #删除key(integer) 1192.168.1.65:6379> get key1(nil)#4.其他操作#对key+1,自增192.168.1.65:6379> set key2 124OK192.168.1.65:6379> get key2"124"192.168.1.65:6379> incr key2 #对key进行+1的操作,非int类型会报错(integer) 125192.168.1.65:6379> get key2"125"#对key+N192.168.1.65:6379> incrby key2 10 #对key进行+N的操作(integer) 135192.168.1.65:6379> get key2"135"#对key-1,自减192.168.1.65:6379> decr key2 #对key进行-1的操作(integer) 134192.168.1.65:6379> get key2"134"#对key-N192.168.1.65:6379> decrby key2 5 #对key进行-N的操作(integer) 129192.168.1.65:6379> get key2"129"#计算字符串key长度192.168.1.65:6379> SET name wangOK192.168.1.65:6379> STRLEN name #返回字符串key长度(integer) 4#判断key是否存在,0不存在,1存在192.168.1.65:6379> SET name wangOK192.168.1.65:6379> EXISTS NAME #大小写敏感(integer) 0192.168.1.65:6379> EXISTS name(integer) 1#查看key的过期时间ttl #查看key的剩余生存时间-1 #负一为永不过期,默认创建的key是永不过期,重新对key赋值,也会从有剩余生命周期变成永不过期-2 #为没有此keynum #key的剩余有效期127.0.0.1:6379> TTL key1(integer) -1127.0.0.1:6379> SET name wang EX 100OK127.0.0.1:6379> TTL name(integer) 96127.0.0.1:6379> TTL name(integer) 93127.0.0.1:6379> SET name mage #重新设置,默认永不过期OK127.0.0.1:6379> TTL name(integer) -1127.0.0.1:6379> SET name wang EX 200OK127.0.0.1:6379> TTL name(integer) 198127.0.0.1:6379> GET name"wang"#重新设置key的过期时间127.0.0.1:6379> TTL name(integer) 148127.0.0.1:6379> EXPIRE name 1000(integer) 1127.0.0.1:6379> TTL name(integer) 999127.0.0.1:6379>#取消key的过期时间127.0.0.1:6379> TTL name(integer) 999127.0.0.1:6379> PERSIST name(integer) 1127.0.0.1:6379> TTL name(integer) -1
实战场景:
1.缓存:经典实用场景,把常用信息,字符串,图片或者视频等信息放到redis中,redis作为缓存层,mysql做持久化层,降低mysql的读写压力
2.计数器:redis是单线程模型,一个命令执行完才会执行下一个,同时数据可以一步落地到其他的数据源
3.session:常见方案spring session + redis实现session共享。
8.2 List列表类型
Redis列表是一个双向可读写的管道,其头部是左侧,尾部是右侧,一个列表最多可以包含2^32-1个元素,下标0表示列表的第一个元素,以1表示列表的第二个元素,以此类推。也可以使用负数下标,以-1表示列表的最后一个元素,-2表示列表的倒数第二个元素,元素值可以重复,常用于存入日志等场景,此数据类型比较常用。
#1.列表的增删改查192.168.1.65:6379> rpush list1 1 #增加数字1(integer) 1192.168.1.65:6379> rpush list1 2 #增加数字2(integer) 2192.168.1.65:6379> rpush list1 3 #增加数字3(integer) 3192.168.1.65:6379> rpush list1 4 #增加数字4(integer) 4192.168.1.65:6379> lrange list1 0 1 #lrange获取list下标0到11) "1"2) "2"192.168.1.65:6379> lindex list1 1 #获取1编号的元素"2"192.168.1.65:6379> lrange list1 0 -1 #获取所有元素1) "1"2) "2"3) "3"4) "4"192.168.1.65:6379> linsert list1 after 2 6 #在2之后插入6这个数据(integer) 5192.168.1.65:6379> lrange list1 0 -11) "1"2) "2"3) "6"4) "3"5) "4"192.168.1.65:6379> linsert list1 before 2 8 #在2之前插入8这个一个数据(integer) 6192.168.1.65:6379> lrange list1 0 -11) "1"2) "8"3) "2"4) "6"5) "3"6) "4"192.168.1.65:6379> lpop list1 #lpop从左侧开始移除一个元素"1"192.168.1.65:6379> lrange list1 0 -11) "8"2) "2"3) "6"4) "3"5) "4"192.168.1.65:6379> rpop list1 #从右侧开始移除一个元素"4"192.168.1.65:6379> lrange list1 0 -11) "8"2) "2"3) "6"4) "3"192.168.1.65:6379> ltrim list1 1 3 #保留下标1到3其余删除OK192.168.1.65:6379> lrange list1 0 -11) "2"2) "6"3) "3"192.168.1.65:6379> llen list1 #列表长度(integer) 3192.168.1.65:6379> lset list1 1 hello #替换下标1的元素OK192.168.1.65:6379> lrange list1 0 -11) "2"2) "hello"3) "3"192.168.1.65:6379> rpush list1 h e l #从右边添加数据,已添加的向左移(integer) 6192.168.1.65:6379> lrange list1 0 -11) "2"2) "hello"3) "3"4) "h"5) "e"6) "l"#从左边添加数据,已添加的需向右移127.0.0.1:6379> LPUSH list1 jack tom john #根据顺序逐个写入list1,最后的john会在列表的最左侧。(integer) 3#删除list127.0.0.1:6379> DEL list1(integer) 1127.0.0.1:6379> EXISTS list1(integer) 0
实战场景:
微博的时间轴,有人发布微博,用lpush加入时间轴,展示新的列表信息
8.3 Sets集合
在Redis中Set和list都是字符串的集合。但是Set是无序的集合,集合中的元素都是唯一的,是不允许出现重复数据的,常用于取值判断,统计,交集等场景。
192.168.1.65:6379> sadd set1 1 #生成一个集合key(integer) 1192.168.1.65:6379> sadd set1 2 3 4 5 #增加多个元素(integer) 4192.168.1.65:6379> smembers set1 #查看集合中所有元素1) "1"2) "2"3) "3"4) "4"5) "5"192.168.1.65:6379> sismember set1 3 #查看值是否在集合中,并返回1(integer) 1192.168.1.65:6379> sismember set1 6 #查看值是否在集合中,并返回0(integer) 0192.168.1.65:6379> sadd set1 a b c d(integer) 4192.168.1.65:6379> srem set1 2 #删除某个元素(integer) 1192.168.1.65:6379> srem set1 a(integer) 1192.168.1.65:6379> srem set1 b 4 #同时删除多个元素(integer) 2192.168.1.65:6379> smembers set11) "c"2) "1"3) "5"4) "3"5) "d"192.168.1.65:6379> scard set1 #查询集合中有多少个元素(integer) 5192.168.1.65:6379> srandmember set1 #随机获取一个元素"3"192.168.1.65:6379> srandmember set1"c"192.168.1.65:6379> sadd set2 1 2 3 4 5 6(integer) 6192.168.1.65:6379> smove set1 set2 3 #从set1中移除,存放到set2中(integer) 1192.168.1.65:6379> smembers set11) "c"2) "1"3) "5"4) "d"192.168.1.65:6379> smembers set21) "1"2) "2"3) "3"4) "4"5) "5"6) "6"192.168.1.65:6379> sunion set1 set2 #查看两个set的并集,输出不同值1) "4"2) "5"3) "6"4) "c"5) "3"6) "2"7) "1"8) "d"192.168.1.65:6379> sinter set1 set2 #查看set1 set2的交集,共同拥有的值1) "1"2) "5"192.168.1.65:6379> sdiff set1 set2 #对比set1和set2差异(以set1为基准)1) "d"2) "c"192.168.1.65:6379> sdiff set2 set1 #对比set2和set1的差异(以set2为基准)1) "2"2) "3"3) "4"4) "6"
实战场景:
1.标签,给用户添加标签,或者用户给消息添加标签,这样有同一标签或者类似标签的可以给推荐关注的事或者关注的人
2.点赞,或点踩,可以放到set中实现
8.4 Hash
hash是一个string类型的field和value的映射表。redis中每个hash可以存储2^32-1键值对,类似于字典,存放了多个k/V对,hash特别适合用于存储对象场景
192.168.1.65:6379> hset hash1 name guzhou #创建并插入单个值(integer) 1192.168.1.65:6379> hset hash1 aget 30(integer) 1192.168.1.65:6379> hget hash1 name #获取hash表中键值为name的值"guzhou"192.168.1.65:6379> hset hash1 name guzhou1 #原来已存在,插入则是修改(integer) 0192.168.1.65:6379> hget hash1 name"guzhou1"192.168.1.65:6379> hlen hash1 #查看元素数量(integer) 2192.168.1.65:6379> hexists hash1 name #判断键值name是否存在,真为1(integer) 1192.168.1.65:6379> hexists hash1 sex(integer) 0192.168.1.65:6379> hset hash1 sex man(integer) 1192.168.1.65:6379> hget hash1 sex"man"192.168.1.65:6379> hdel hash1 sex name #删除1个或者多个键值(integer) 2192.168.1.65:6379> hgetall hash1 #获取hash表内所有键值和数据1) "aget"2) "30"192.168.1.65:6379> hmset hash1 name guzhou sex man phone 15221111111 #插入多个键值和数据OK192.168.1.65:6379> hmget hash1 name phone #查看hash表中多个键值对1) "guzhou"2) "15221111111"192.168.1.65:6379> hkeys hash1 #查看hash表中所有的key1) "aget"2) "name"3) "sex"4) "phone"192.168.1.65:6379> hvals hash1 #查看hash表中所有的value1) "30"2) "guzhou"3) "man"4) "15221111111"
实战场景:
缓存:能直观,相比string更节省空间,如用户信息,视频信息等
8.5 Sorted Sets有序集合
Redis有序集合和集合一样也是string类型元素的集合,且不允许重复的元素。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复,集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1), 集合中最大的成员数为 2^32 – 1 (4294967295, 每个集合可存储40多亿个成员),经常用于排行榜的场景
注意:数据插入的时候值不可以重复,分数可以重复。可以理解为权重、值,两个部分组成,权重可以相同,值一定不能相同。否则插入时会覆盖。
192.168.1.65:6379> zadd zset 1 peiking #插入分支和数据,可以多个(integer) 1192.168.1.65:6379> zadd zset 2 shanghai(integer) 1192.168.1.65:6379> zadd zset 3 guangzhou(integer) 1192.168.1.65:6379> zadd zset 4 shenzhen(integer) 1192.168.1.65:6379> zadd zset 5 tianjin(integer) 1192.168.1.65:6379> zadd zset 6 beijing(integer) 1192.168.1.65:6379> zrange zset 0 -1 withscores #显示指定集合内所有key和value值1) "peiking"2) "1"3) "shanghai"4) "2"5) "guangzhou"6) "3"7) "shenzhen"8) "4"9) "tianjin"10) "5"11) "beijing"12) "6"192.168.1.65:6379> zrange zset 0 1 withscores #显示下标0到1的元素1) "peiking"2) "1"3) "shanghai"4) "2"192.168.1.65:6379> zrevrange zset 0 -1 #倒序排序后显示集合内所有的key1) "beijing"2) "tianjin"3) "shenzhen"4) "guangzhou"5) "shanghai"6) "peiking"192.168.1.65:6379> zcard zset #统计集合中有多少元素(integer) 6192.168.1.65:6379> zcount zset 1 5 #统计权重1到5之间有多少元素(integer) 5192.168.1.65:6379> zincrby zset 5 guangzhou #为广州这个元素增加5个权重"8"192.168.1.65:6379> zrank zset shanghai #返回某个数值的索引(integer) 1192.168.1.65:6379> zscore zset shanghai #获取集合元素中shanghai的权重"2"192.168.1.65:6379> zrevrank zset shanghai #获取元素的索引、下标,从大到小排序(integer) 4192.168.1.65:6379> zrem zset beijing #删除集合中一个元素或者多个元素(integer) 1192.168.1.65:6379> zrevrange zset 0 -11) "guangzhou"2) "tianjin"3) "shenzhen"4) "shanghai"5) "peiking"
实战场景:
1.排行榜:有序集合经典实用场景。列如小说视频等网站需要对用户上传的小说视频做排行榜,榜单可以按照用户关注数,更新时间,字数等打分,做排行。
9 Redis基础命令
9.1 auth
解锁redis密码,比如我们通过配置文件中requirepass这个值设置了密码,我们在使用redis时,需要通过auth这个命令来解锁。否则提示未认证。也可以登录时,使用-a参数,指定密码。
[root@mysql-65 redis]# ./src/redis-cli -h 192.168.1.65192.168.1.65:6379> auth root123OK192.168.1.65:6379> set name xujunOK[root@mysql-65 redis]# ./src/redis-cli -h 192.168.1.65 -a root123Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.192.168.1.65:6379>
9.2 select
我们在其他数据库。列如mysql的使用中,有数据库的概念,我们启动的是一个实列,具体使用某个库,需要use 某某数据库才行。
select命令就是在redis实列中,选择一个库。
选择这个库之后,才可以使用我们存储的数据,进行查询,或者创建修改等等。数据库编号,需要使用数字表示,这个索引的起始值为0,select 0的时候,就是我们默认登录的这个数据库。
在正式的生产环境中,建议一个Redis只使用一个库,总结起来有以下三点:
- Redis是单线程的。如果使用多个数据库,那么这些数据库仍然是使用一个CPU,彼此之间还是会受到影响的
- 多数据库的使用方式,会让调试和运维不同业务的数据库变得困难,假如有一个慢查询存在,依然会影响到其他数据库,这样会使得别的业务定位问题变得非常困难
- 部分Redis的客户端根本就不支持这种方式。即使支持,在开发的时候来回切换数字形式的数据库,很容易弄乱
所以以上总结就是,如果要使用多个数据库功能,完全可以在一台机器上部署多个Redis实例,彼此用端口来做区分,因此现代计算机或者服务器通常是有多个CPU的。这样既保证了业务之间不会受到影响,又合理地使用了CPU资源。
192.168.1.65:6379> keys * #在默认数据库0里面查看所有的key1) "hash1"2) "a"3) "key3"4) "list2"5) "kye1"6) "set2"7) "set1"8) "key5"9) "key4"10) "kye2"11) "key2"12) "name"13) "list1"14) "zset"15) "set"192.168.1.65:6379> select 1 #切换到索引为1的数据库OK192.168.1.65:6379[1]> keys * #在索引为1的数据库里面查看key,发现为空,说明不切换回0,是看不到数据的(empty array)192.168.1.65:6379[1]> select 0 #切换回到默认的数据库里OK
9.3 info
我们可以通过info命令查看我们redis的全部信息。也可以查看指定的信息,比如输入info cpu就可以看到CPU信息,或者info Replication可以查看目前主从复制的信息等等,输入info后不跟任何关键字,默认显示全部。
192.168.1.65:6379> info# Serverredis_version:6.0.9redis_git_sha1:00000000redis_git_dirty:0redis_build_id:35cd6ca328855102redis_mode:standaloneos:Linux 3.10.0-1062.el7.x86_64 x86_64arch_bits:64multiplexing_api:epollatomicvar_api:atomic-builtingcc_version:9.3.1process_id:9160run_id:466b444bc200909c9d593544e08e1d36af4c7939tcp_port:6379uptime_in_seconds:3430704uptime_in_days:39hz:10configured_hz:10lru_clock:13644761executable:/usr/local/redis-6.0.9/./src/redis-serverconfig_file:/data/6379/redis.confio_threads_active:0
9.4 config get和config set
查看数据库配置信息,比如config get *则是显示全部配置,如果config get save后边输入某一个配置项,则输出配置项信息
在redis中,如何去配置或者重新设置我们的redis的配置选项,我们可以通过config set命令来实现。比如config set maxmemory 1024
[root@mysql-65 redis]# ./src/redis-cli -h 192.168.1.65 -a 123456192.168.1.65:6379> config get * #查看所有redis配置信息,奇数行为键,偶数行为值1) "rdbchecksum"2) "yes"3) "daemonize"4) "yes"5) "io-threads-do-reads"6) "no"7) "lua-replicate-commands"8) "yes"9) "always-show-logo"10) "no".....192.168.1.65:6379> config set requirepass root123 #设置redis远程登录密码OK192.168.1.65:6379> quit[root@mysql-65 redis]# ./src/redis-cli -h 192.168.1.65 -a 123456 #用之前的密码登录,设置key和value失败Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.Warning: AUTH failed192.168.1.65:6379> set a b #用之前的密码登录,设置key和value失败(error) NOAUTH Authentication required.192.168.1.65:6379> quit[root@mysql-65 redis]# ./src/redis-cli -h 192.168.1.65 -a root123 #用新设置的密码登录,成功Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.192.168.1.65:6379> set a bOK192.168.1.65:6379>
9.5 KEYS
查看当前库下的所有key,此命令慎用!

1 27.0.0.1:6379[15]> SELECT 0OK127.0.0.1:6379> KEYS *1) "9527"2) "9526"3) "paihangbang"4) "list1"127.0.0.1:6379> SELECT 1OK127.0.0.1:6379[1]> KEYS *(empty list or set)127.0.0.1:6379[1]>
9.6 其他命令
1.client list查看当前连接的客户端2.client killip:port可以杀掉某个连接,需要输入ip和端口3.flushdb删除当前库内所有数据,慎重执行,命令不会有确认提示。执行一定成功。flushdb只对当前库生效,不会删除整个实列内全部的数据4.flushall删除实列中所有数据,更慎重使用,针对实列生效,执行完成之后,将全部数据被删除。5.bgsave在后台异步保存当前数据库的数据到硬盘。在我们执行bgsave命令的时候,会直接返回OK。redis会fork出一个新的子进程来处理这个请求,原来的父进程会继续处理客户端请求,子进程把数据保存完成后退出。数据量较大时,可以通过ps命令查看子进程信息。这个操作并不会生成新的文件,而是会重写原来的rdb文件,也可以通过ls -lrt的命令,查看rdb文件的更新时间。6.LASTSAVE这个命令查看上次执行的bgsave命令完成时间。返回的为Unix的时间戳7.SAVE命令保存当前redis实列的所有数据快照到磁盘,生产rdb文件的形式保存。这个命令执行时,和bgsave不同,save为同步操作,为阻塞客户端所有操作,直接由redis进程完成。导致在生产环境中,几乎不使用。简单来说,save在执行保存rdb文件的过程中,redis是不可访问的。由于这个特性,很少使用。8.DBSIZE返回当前库下的所有key数量192.168.1.65:6379> DBSIZE(integer) 15
10 Redis消息队列
10.1 消息队列模式
消息队列主要分为两种,这两种模式Redis都支持
- 生产者/消费者模式
- 发布者/订阅者模式
10.1.1 生产者消费者模式
在生产者/消费者模式下,上层应用接受到的外部请求后开始处理其当前步骤的操作,在执行完成后将已经完成的操作发送至指定的频道当中,并由其下层的应用监听该频道并继续下一步的操作,如果其处理完成后没有下一步的操作就直接返回数据给外部请求,如果还有下一步的操作就再将任务发布给另外一个频道,由另外一个消费者继续监听和处理。此模式应用广泛。
10.1.1.1 模式介绍
生产者消费者模式下,多个消费者同时监听一个队列,但是一个消息只能被最先抢到消息的消费者消费,即消息任务是一次性读取和处理,此模式在分布式业务架构中很常用,比较常用的消息队列软件还有RabbitMQ、Kafka、RocketMQ、ActiveMQ等。

10.1.1.2 队列介绍
队列当中的 消息由不同的生产者写入,也会有不同的消费者取出进行消费处理,但是一个消息一定是只能被取出一次也就是被消费一次。
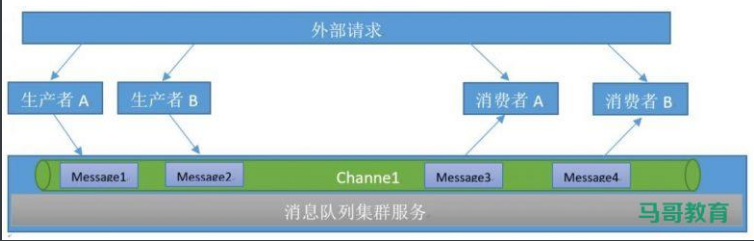
10.1.1.3 生产者发布消息
[root@redis-s4 ~]# redis-cli127.0.0.1:6379> AUTH 123456OK127.0.0.1:6379> LPUSH channel1 msg1 #从管道的左侧写入(integer) 1127.0.0.1:6379> LPUSH channel1 msg2(integer) 2127.0.0.1:6379> LPUSH channel1 msg3(integer) 3127.0.0.1:6379> LPUSH channel1 msg4(integer) 4127.0.0.1:6379> LPUSH channel1 msg5(integer) 5
10.1.1.4 查看队列所有消息
127.0.0.1:6379> LRANGE channel1 0 -11) "msg5"2) "msg4"3) "msg3"4) "msg2"5) "msg1"
10.1.1.5 消费者消费消息
127.0.0.1:6379> RPOP channel1 #从管道的右侧消费,用于消息的先进先出"msg1"127.0.0.1:6379> RPOP channel1"msg2"127.0.0.1:6379> RPOP channel1"msg3"127.0.0.1:6379> RPOP channel1"msg4"127.0.0.1:6379> RPOP channel1"msg5"127.0.0.1:6379> RPOP channel1(nil)
10.1.1.6 再次验证队列消息
127.0.0.1:6379> LRANGE channel1 0 -1(empty list or set) #队列中的消息已经被已全部消费完毕
10.1.2 发布者订阅模式
10.1.2.1 模式简介
在发布者订阅者模式下,发布者将消息发布到指定的channel里面,凡是监听该channel的消费者都会收到同样的一份消息,这种模式类似于是收音机的广播模式,即凡是收听某个频道的听众都会收到主持人发布的相同的消息内容。此模式常用语群聊天、群通知、群公告等场景。
- Publisher:发布者
- Subscriber:订阅者
- Channel:频道

10.1.2.2 订阅者监听频道
[root@redis-s4 ~]# redis-cli127.0.0.1:6379> AUTH 123456OK127.0.0.1:6379> SUBSCRIBE channel1 #订阅者事先订阅指定的频道,之后发布的消息才能收到Reading messages... (press Ctrl-C to quit)1) "subscribe"2) "channel1"3) (integer) 1
10.1.2.3 发布者发布消息
127.0.0.1:6379> PUBLISH channel1 test1 #发布者发布消息(integer) 2127.0.0.1:6379> PUBLISH channel1 test2(integer) 2
10.1.2.4 发布者发布消息

10.1.2.5 订阅多个频道
#订阅指定的多个频道127.0.0.1:6379> SUBSCRIBE channel1 channel2
10.1.2.6 订阅所有频道
127.0.0.1:6379> PSUBSCRIBE * #支持通配符*
10.1.2.7 订阅匹配的频道
127.0.0.1:6379> PSUBSCRIBE chann* #匹配订阅多个频道
11 Redis持久化
Redis虽然是一个内存级别的缓存程序,也就是redis是使用内存进行数据的缓存的,但是其可以将内存的数据按照一定的策略保存到硬盘上,从而实现数据持久保存的目的,目前redis支持两种不同方式的数据持久化保存机制,分别是RDB和AOF。
11.1 RDB模式
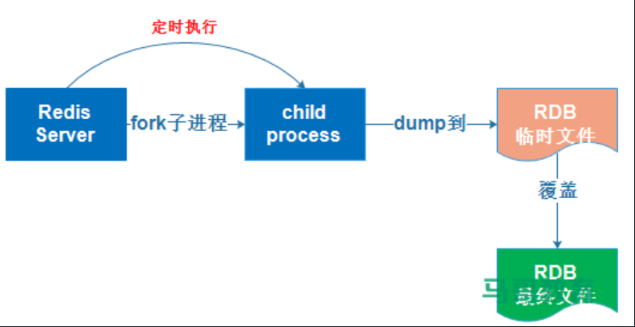
RDB:基于时间的快照,其默认只保留当前最新的一次快照,特点是执行速度比较快,缺点是可能会丢失从上次快照到当前时间点之间未做快照的数据。
RDB实现的具体过程Redis从master主进程先fork出一个子进程,使用写时复制机制,子进程将内存的数据保存为一个临时文件,比如dump.rdb.temp,当数据保存完成之后再将上一次保存的RDB文件替换掉,然后关闭子进程,这样可以保证每一次做RDB快照的时候保存的数据是完整的,因为直接替换RDB文件的时候可能会出现突然断电等问题而导致RDB文件还没有保存完整就突然关机停止保存而导致数据丢失的情况,可以手动将每次生成的RDB文件进程备份,这样可以最大化保存历史数据。

11.1.1 RDB模式触发机制
手动触发分别对应save和bgsave命令:
save命令:阻塞当前Redis服务器,直到RDB过程完成为止,对于内存比较大的实例会造成长时间阻塞,线上环境不建议使用。
bgsave命令:Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。
所以在日常的生产环境中,Redis内部所有的涉及RDB的操作都采用bgsave的方式,而save命令已经废弃。
11.2 RDB模式的优缺点
优点:RDB快照保存了某个时间点的数据,可以通过脚本执行bgsave(非阻塞,后台执行)或者save(阻塞,不推荐)命令自定义时间点备份,可以保留多个备份,当出现问题可以恢复到不同时间点的版本。
可以最大化IO的性能,因为父进程在保存RDB文件的时候唯一要做的是fork出一个子进程,然后操作都会有这个子进程操作,父进程无序任何的IO操作,RDB在大量数据比如几个G的数据,恢复的速度比AOF的快。
缺点:不能实时保存数据,会丢失自上一次执行RDB备份到当前的内存数据。数据量非常大的时候,从父进程fork的时候需要一点时间,可能是毫秒或者秒或者分钟,取决于磁盘IO性能。
daemonize yesport 6666requirepass 123logfile ./redislog_louie.logdir ./bind 192.168.250.132 127.0.0.1 # 0.0.0.0save 20 1 # 自动保存策略,20秒内有一个key发生变化就自动保存dbfilename rdb_louie.rdb # rdb文件名stop-writes-on-bgsave-error yes # 发生错误中断写入,建议开启rdbcompression yes # 数据文件压缩,建议开启rdbchecksum yes # 开启crc64错误校验,建议开启
11.3 AOF模式(推荐方案)

AOF:按照操作顺序依次将操作追加到指定的日志文件末尾。
AOF和RDB一样使用了写时复制机制,AOF默认为每秒钟fsync一次,即将执行的命令保存到AOF文件当中,这样即使redis服务器发生故障的话最多只丢失1秒钟之内的数据,也可以设置不同的fsync策略,或者设置每次执行命令的时候执行fsync,fsync会在后台实行线程,所以主线程可以继续处理用户的正常请求而不受到写入AOF文件的IO影响。
注:如果RDB与AOF同时存在的情况下,Redis默认优先使用AOF进行数据恢复。

11.4 AOF模式的优缺点
优点:
- 数据安全性相对较高,根据所使用的fsync策略(fsync是同步内存中redis所有已经修改的文件到存储设备)默认是appendfsync everysec,即每秒执行一次fsync。
- 由于该机制对日志文件的写入操作采用的是append模式,因此在写入过程中即使出现宕机现象,也不会破坏日志文件中已经存在的内容。然而如果我们本次操作只是写入了一半数据就出现了系统崩溃问题,不用担心,在Redis下一次启动之前,我们可以通过redis-check-aof工具来帮助我们解决数据一致性的问题。
- 如果日志过大,Redis可以自动启用rewrite机制。即Redis以append模式不断的将修改数据写入到老的磁盘文件中,同时Redis还会创建一个新的文件用于记录此期间有哪些修改命令被执行。因此在进行rewrite切换时可以更好的保证数据安全性。
- AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。事实上,我们也可以通过该文件完成数据的重建。
缺点:
- 即使有些操作是重复的也会全部记录,AOF的文件大小要大于RDB格式的文件
- RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快
daemonize yesport 6666requirepass 123logfile ./redislog_louie.logdir ./bind 192.168.250.132 127.0.0.1 # 0.0.0.0appendonly yes # 开启aofappendfilename aof_louie.aof # aof 日志文件名appendfsync everysec # 每秒记录一次日志,建议everysecno-appendfsync-on-rewrite yes # 重写过程中是否向日志文件写入,yes 代表rewrite过程中,不向aof文件中追加信息,rewrite结束后再写入,no 代表rewrite执行的同时,也向aof追加信息auto-aof-rewrite-percentage 100 # 触发重写文件增长百分比 默认100%auto-aof-rewrite-min-size 64mb # 触发重写最小aof文件尺寸
看到上面的配置,大家会有疑问,为什么会有 重写,主要是因为要压缩数据,产生的文件更小,防止同样的相同命令占用空间,比如如下:用最简短的命令来操作数据


12 Redis高可用与集群
为什么我们需要主从复制呢?
以下三点说明:
- Redis单机一旦故障,可以通过从服务器上进行恢复数据
- Redis要达到高可用、高并发,只有单个Redis是不够的,单个Redis也就只能支持几万的QPS,所以必须以集群的形式提供服务,而集群中又以多个主从组成
- 主从是多个Redis集合在一起,以一个master多个slave为模式对外提供服务,master主要以写为主,slave提供读,即使读写分离的情况,以读多写少为准。比如电商网站中的商品,读的多,写的少。
总的来说,单机版Redis问题概括:
- 机器故障
- 容量瓶颈
- QPS瓶颈
12.1 那么主从复制的原理是什么呢?
上面已经说明了为什么需要主从复制,现在我们来说说原理
主从复制分为全量同步和增量同步:
A、全量同步
Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。具体步骤如下:
- 从服务器连接主服务器,发送SYNC命令。
- 主服务器接收到SYNC命令后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令。
- 主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令。
- 从服务器收到快照文件后丢弃所有旧数据,载入收到的快照。
- 主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令
- 从服务器完成对快照的载入,开始接受命令请求,并执行来自主服务器缓冲区的写命令。

完成上面几个步骤后就完成了从服务器数据初始化的所有操作,从服务器此时可以接受来自用户的读请求。
B、增量同步
Redis增量复制是指Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
C、Redis主从同步策略
主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。当然,如果有需要,slave 在任何时候都可以发起全量同步。redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
D、Redis主从复制完整过程:

12.2 主从复制的特性是什么呢?
- 一个master可以有多个slave
- 一个slave只能有一个master
- 数据流是单向的,master到slave
- 主从复制底层依赖与RDB方式进行全量复制
注意说明:
针对与RDB方式保存有分为 save 和 bgsave 命令,两者的区别在于save为同步保存,即存在阻塞;而bgsave为异步保存,非阻塞。
在上面原理中有给出redis主从复制采用的是bgsave的方式,如若不清楚也可以看下面log日志中的内容。
12.3 Redis主从复制实战
12.3.1 环境配置
第一:准备三台服务器,一台master,两台slave
| 主机说明 | 主机IP | 端口 |
|---|---|---|
| master | 10.4.60.95 | 7000 |
| slave | 10.4.60.96 | 7001 |
| slave | 10.4.60.97 | 7002 |
第二:每台服务器安装redis版本保持一致(配置几乎一样,除了端口,路径不一致之外,其他保持不变)
#1、关闭selinux[root@localhost ~]# vi /etc/selinux/configSELINUX=disabled[root@localhost ~]# setenforce 0[root@localhost ~]# getenforcePermissive#2、关闭防护墙[root@localhost ~]# systemctl disable firewalld[root@localhost ~]# systemctl stop firewalld#3、配置主机名[root@localhost ~]# hostnamectl set-hostname slave-97#4、配置阿里源,安装软件[root@slave-97 ~]# mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup[root@slave-97 ~]# curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo[root@slave-97 ~]# yum clean all[root@slave-97 ~]# yum makecache[root@slave-97 ~]# yum install lrzsz vim wget net-tools gcc -y#5、安装redis[root@slave-97 ~]# cd /usr/local/src/[root@slave-97 src]# wget http://download.redis.io/releases/redis-5.0.2.tar.gz[root@slave-97 src]# tar xf redis-5.0.2.tar.gz[root@slave-97 src]# cd redis-5.0.2[root@slave-97 redis-5.0.2]# make[root@slave-97 src]# mv redis-5.0.2 ../[root@slave-97 src]# cd ../[root@slave-97 local]# lsbin etc games include lib lib64 libexec redis-5.0.2 sbin share src[root@slave-97 local]# ln -s redis-5.0.2/ redis#6、配置redis[root@slave-97 redis-5.0.2]# mkdir -p /data/7002[root@slave-97 redis-5.0.2]# useradd redis -s /sbin/nologin -M[root@slave-97 redis-5.0.2]# cat /data/7002/redis.confbind 127.0.0.1 10.4.60.97 #根据当前服务器IP地址修改protected-mode yesport 7002 #自定义tcp-backlog 511timeout 300tcp-keepalive 300daemonize yessupervised nopidfile /data/7002/redis.pid #路径根据当前服务器情况修改loglevel noticelogfile "/data/7002/redis.log" #日志也是根据当前服务器情况修改databases 16always-show-logo yessave 900 1save 300 10save 60 10000stop-writes-on-bgsave-error yesrdbcompression yesrdbchecksum yesdbfilename dump.rdbdir /data/7002 #根据路径修改appendonly yesappendfilename "appendonly-7001.aof" #自定义appendfsync everysecno-appendfsync-on-rewrite yesauto-aof-rewrite-percentage 100auto-aof-rewrite-min-size 64mbaof-load-truncated yesaof-use-rdb-preamble yeslua-time-limit 5000slowlog-log-slower-than 10000slowlog-max-len 128latency-monitor-threshold 0notify-keyspace-events ""hash-max-ziplist-entries 512hash-max-ziplist-value 64list-max-ziplist-size -2list-compress-depth 0set-max-intset-entries 512zset-max-ziplist-entries 128zset-max-ziplist-value 64hll-sparse-max-bytes 3000stream-node-max-bytes 4096stream-node-max-entries 100activerehashing yesclient-output-buffer-limit normal 0 0 0client-output-buffer-limit replica 256mb 64mb 60client-output-buffer-limit pubsub 32mb 8mb 60hz 10dynamic-hz yesaof-rewrite-incremental-fsync yesrdb-save-incremental-fsync yesrequirepass 123456#7、设置systemd[root@slave-97 redis-5.0.2]# cat /usr/lib/systemd/system/redis.service[Unit]Description=RedisAfter=network.target[Service]Type=forkingExecStart=/usr/local/redis/src/redis-server /data/7002/redis.confExecReload=/bin/kill -s HUP $MAINPIDExecStop=/usr/local/redis/src/redis-cli shutdownUser=redisGroup=redisPrivateTmp=true[Install]WantedBy=multi-user.target[root@slave-97 redis-5.0.2]# chown redis:redis /data/7002/ -R[root@slave-97 redis-5.0.2]# systemctl daemon-reload[root@slave-97 redis-5.0.2]# systemctl enable redis[root@slave-97 local]# systemctl start redis[root@slave-97 local]# systemctl status redis● redis.service - RedisLoaded: loaded (/usr/lib/systemd/system/redis.service; enabled; vendor preset: disabled)Active: active (running) since Thu 2020-12-10 21:23:20 EST; 4s agoProcess: 21989 ExecStart=/usr/local/redis/src/redis-server /data/7002/redis.conf (code=exited, status=0/SUCCESS)Main PID: 21990 (redis-server)CGroup: /system.slice/redis.service└─21990 /usr/local/redis/src/redis-server 127.0.0.1:7002Dec 10 21:23:20 slave-97 systemd[1]: Starting Redis...Dec 10 21:23:20 slave-97 systemd[1]: Started Redis.
12.3.2 主从复制配置
第一:进入master服务器的redis目录下
新建一个redis配置文件,数据持久化采用AOF,这也是官方推荐的,效率高。
[root@master-95 ~]# cat /data/7000/redis.confbind 127.0.0.1 10.4.60.95protected-mode yesport 7000tcp-backlog 511timeout 300tcp-keepalive 300daemonize yessupervised nopidfile /data/7000/redis.pidloglevel noticelogfile "/data/7000/redis.log"databases 16always-show-logo yessave 900 1save 300 10save 60 10000stop-writes-on-bgsave-error yesrdbcompression yesrdbchecksum yesdbfilename dump.rdbdir /data/7000appendonly yesappendfilename "appendonly-7000.aof"appendfsync everysecno-appendfsync-on-rewrite yesauto-aof-rewrite-percentage 100auto-aof-rewrite-min-size 64mbaof-load-truncated yesaof-use-rdb-preamble yeslua-time-limit 5000slowlog-log-slower-than 10000slowlog-max-len 128latency-monitor-threshold 0notify-keyspace-events ""hash-max-ziplist-entries 512hash-max-ziplist-value 64list-max-ziplist-size -2list-compress-depth 0set-max-intset-entries 512zset-max-ziplist-entries 128zset-max-ziplist-value 64hll-sparse-max-bytes 3000stream-node-max-bytes 4096stream-node-max-entries 100activerehashing yesclient-output-buffer-limit normal 0 0 0client-output-buffer-limit replica 256mb 64mb 60client-output-buffer-limit pubsub 32mb 8mb 60hz 10dynamic-hz yesaof-rewrite-incremental-fsync yesrdb-save-incremental-fsync yesrequirepass 123456masterauth 123 #服务器配置masterauth作用主要是为了后期sentinel引入后重新选举master并且7000端口redis重新加入主从复制时必备的,否则会出现权限不足
第二:进入slave(96,97)服务器的redis目录下
[root@slave-96 redis]# cat /data/7001/redis.confbind 127.0.0.1 10.4.60.96protected-mode yesport 7001tcp-backlog 511timeout 300tcp-keepalive 300daemonize yessupervised nopidfile /data/7001/redis.pidloglevel noticelogfile "/data/7001/redis.log"databases 16always-show-logo yessave 900 1save 300 10save 60 10000stop-writes-on-bgsave-error yesrdbcompression yesrdbchecksum yesdbfilename dump.rdbdir /data/7001appendonly yesappendfilename "appendonly-7001.aof"appendfsync everysecno-appendfsync-on-rewrite yesauto-aof-rewrite-percentage 100auto-aof-rewrite-min-size 64mbaof-load-truncated yesaof-use-rdb-preamble yeslua-time-limit 5000slowlog-log-slower-than 10000slowlog-max-len 128latency-monitor-threshold 0notify-keyspace-events ""hash-max-ziplist-entries 512hash-max-ziplist-value 64list-max-ziplist-size -2list-compress-depth 0set-max-intset-entries 512zset-max-ziplist-entries 128zset-max-ziplist-value 64hll-sparse-max-bytes 3000stream-node-max-bytes 4096stream-node-max-entries 100activerehashing yesclient-output-buffer-limit normal 0 0 0client-output-buffer-limit replica 256mb 64mb 60client-output-buffer-limit pubsub 32mb 8mb 60hz 10dynamic-hz yesaof-rewrite-incremental-fsync yesrdb-save-incremental-fsync yesslaveof 10.4.60.95 7000 #开启从,设置主的IP地址+端口requirepass 123456masterauth 123456 #设置主的登录密码
注意说明:
- slaveof后面绑定的是master服务器IP和端口
- 需要设置master的密码,否则会在连接的时候报权限不足
- 设置slave服务器的密码强烈建议与master服务器上的密码一致,因为这样在后面的哨兵模式自动选出主服务器有很大的帮助,否则会报错
以上配置完毕
第三:启动95、6、7的redis
systemctl restart redis
第四:验证是否启用主从复制
master上查看主从
[root@master-95 redis]# ./src/redis-cli -h 10.4.60.95 -p 7000 -a 12345610.4.60.95:7000> info replication# Replicationrole:masterconnected_slaves:2 #我们可以看到显示两个从slave0:ip=10.4.60.96,port=7001,state=online,offset=85806,lag=1slave1:ip=10.4.60.97,port=7002,state=online,offset=85806,lag=1master_replid:b0d1a2488891e8991877d01609195f88fb2a6e4emaster_replid2:0000000000000000000000000000000000000000master_repl_offset:85806second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:1repl_backlog_histlen:85806
slave上查看主从
[root@slave-97 redis]# ./src/redis-cli -h 10.4.60.97 -p 7002 -a 12345610.4.60.97:7002> info Replication# Replicationrole:slavemaster_host:10.4.60.95master_port:7000master_link_status:up #可以看到连接master的状态是upmaster_last_io_seconds_ago:5master_sync_in_progress:0slave_repl_offset:86758slave_priority:100slave_read_only:1connected_slaves:0master_replid:b0d1a2488891e8991877d01609195f88fb2a6e4emaster_replid2:0000000000000000000000000000000000000000master_repl_offset:86758second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:84561repl_backlog_histlen:2198
查看数据是否同步
#我们现在master上面插入一条数据10.4.60.95:7000> set name xujunOK#然后分别在96和97两台slave上面查看是否有数据10.4.60.96:7001> get name"xujun"10.4.60.97:7002> get name"xujun"我们可以看到在两台slave上面都已经同步了master的数据,那我们是否可以在slave上面写数据呢?10.4.60.97:7002> set name xujun1270(error) READONLY You can't write against a read only replica.#写入数据的时候报错,提示我们从库是只读的,不能写入
12.4 主从复制总结
- Slave服务器上面的数据都是从Master服务器上同步的,一旦Master挂掉,则slave服务器无法进行增量同步,假设某项目使用了Slave服务器进行写的操作,当Master服务器开启后,Slave服务器会进行与Master服务器进行全量同步,这样导致原先保存在Slave上的数据丢失,当然这个列子是假设,一般Slave只当做读的操作。
- 如果Master宕机后,如何保证Redis还可以正常使用呢?则我们就需要引入Sentinel进行的Master的选择啦
13 Redis哨兵模式
13.1 Redis集群介绍
主从架构无法实现master和slave角色的自动切换,即当master出现redis服务异常、主机断电、磁盘损坏等问题导致master无法使用,而redis高可用无法实现自故障转移(将slave提升为master),需要手动改环境配置才能切换到slave redis服务器,另外也无法横向扩展Redis服务的并行写入性能,当单台Redis服务器性能无法满足业务写入需求的时候就必须需要一种方式解决以上的两个核心问题,即:1.master和slave角色的无缝切换,让业务无感知从而不影响业务使用 2.可以横向动态扩展Redis服务器,从而实现多台服务器并行写入以实现更高并发的目的。
Redis集群实现方式:
- 客户端分片
- 代理分片
- Redis Cluster
13.2 哨兵工作原理
Sentinel 进程是用于监控Redis集群中Master主服务器工作的状态,在Master主服务器发生故障的时候,可以实现
Master和Slave服务器的切换,保证系统的高可用,其已经被集成在redis2.6+的版本中,Redis的哨兵模式到了2.8
版本之后就稳定了下来。一般在生产环境也建议使用Redis的2.8版本的以后版本。哨兵(Sentinel) 是一个分布式系
统,可以在一个架构中运行多个哨兵(sentinel) 进程,这些进程使用流言协议(gossip protocols)来接收关于Master
主服务器是否下线的信息,并使用投票协议(Agreement Protocols)来决定是否执行自动故障迁移,以及选择哪个
Slave作为新的Master。
每个哨兵(Sentinel)进程会向其它哨兵(Sentinel)、Master、Slave定时发送消息,以确认对方是否”活”着,如果发现对方在指定配置时间(可配置的)内未得到回应,则暂时认为对方已离线,也就是所谓的”主观认为宕机” ,主观是每个成员都具有的独自的而且可能相同也可能不同的意识,英文名称:Subjective Down,简称SDOWN。
有主观宕机,对应的就有客观宕机。当“哨兵群”中的多数Sentinel进程在对Master主服务器做出SDOWN 的判断,并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后,得出的Master Server下线判断,这种方式就是“客观宕机”,客观是不依赖于某种意识而已经实际存在的一切事物,英文名称是:Objectively Down, 简称 ODOWN。
通过一定的vote算法,从剩下的slave从服务器节点中,选一台提升为Master服务器节点,然后自动修改相关配置,并开启故障转移(failover)。Sentinel 机制可以解决master和slave角色的自动切换问题,但单个Master 的性能瓶颈问题无法解决
13.3 哨兵部署
哨兵的前提是已经实现了一个redis master-slave的运行环境,从而实现一个一主两从基于哨兵的高可用redis架构
| 主机说明 | 主机IP | 端口 | sentinel端口 |
|---|---|---|---|
| Master | 10.4.60.95 | 7000 | 26379 |
| Salve | 10.4.60.96 | 7001 | 26380 |
| Salve | 10.4.60.97 | 7002 | 26381 |
13.3.1 配置Master的sentinel.conf文件
[root@master-95 7000]# cd /data/7000/[root@master-95 7000]# cp -a /usr/local/redis/sentinel.conf sentinel.conf[root@master-95 7000]# cat sentinel.conf #sentinel.conf哨兵配置文件bind 0.0.0.0port 26379daemonize yespidfile "/data/7000/redis-sentinel.pid"logfile "/data/7000/redis-sentinel.log"dir "/data/7000"sentinel myid df2bbb5c317263d99bc882ad193f3df9873f1d5esentinel deny-scripts-reconfig yessentinel monitor mymaster 10.4.60.95 7000 2sentinel down-after-milliseconds mymaster 3000sentinel auth-pass mymaster 123456sentinel config-epoch mymaster 1配置文件详解:sentinel myid df2bbb5c317263d99bc882ad193f3df9873f1d5e #每个哨兵主机myid必须不一致,不需要添加,会自动添加进配置文件中sentinel monitor mymaster 10.0.0.95 6379 2 #指定master服务器的地址和端口,2为法定人数限制(quorum),即有几个slave认为master down了就进行故障转移,一般此值是所有节点的一半以上的整数值,比如,总数是3,即3/2=1.5,取整为2sentinel auth-pass mymaster 123456 #master的密码,注意此行要在上面行的下面sentinel down-after-milliseconds mymaster 30000 #(SDOWN)主观下线的时间,单位:毫秒,建议3000sentinel parallel-syncs mymaster 1 #发生故障转移后,同时向新master同步数据的slave数量,数字越小总同步时间越长,但可以减轻新master的负载压力sentinel failover-timeout mymaster 180000 #所有slaves指向新的master所需的超时时间,单位:毫秒sentinel deny-scripts-reconfig yes #禁止修改脚本#以下是自动生成,不需要修改protected-mode nosentinel known-replica mymaster 10.4.60.97 7002maxclients 4064sentinel known-replica mymaster 10.4.60.95 7000sentinel known-sentinel mymaster 10.4.60.97 26381 85696cc6170b82b07e52d315c45f1475088ce41bsentinel known-sentinel mymaster 10.4.60.96 26380 f086549a9593c8d18307ad076b25109b02a37032sentinel current-epoch 1#配置权限[root@master-95 7000]# chown -R redis:redis /data/7000/
13.3.2 配置sentinel systemd启动文件
[root@master-95 7000]# vim /usr/lib/systemd/system/redis-sentinel.service[Unit]Description=Redis-sentinelAfter=syslog.target network.target remote-fs.target nss-lookup.target[Service]Type=forkingPIDFile=/data/7000/redis-sentinel.pidExecStart=/usr/local/redis/src/redis-sentinel /data/7000/sentinel.confExecReload=/bin/kill -s HUP $MAINPIDExecStop=/bin/kill -s QUIT $MAINPIDUser=redisGroup=redisPrivateTmp=true[Install]WantedBy=multi-user.target[root@master-95 7000]# systemctl daemon-reload[root@master-95 7000]# systemctl enable redis-sentinel.service[root@master-95 7000]# systemctl start redis-sentinel.service[root@master-95 7000]# ss -lntp|grep redisLISTEN 0 511 10.4.60.95:7000 *:* users:(("redis-server",pid=31416,fd=7))LISTEN 0 511 127.0.0.1:7000 *:* users:(("redis-server",pid=31416,fd=6))LISTEN 0 511 *:26379 *:* users:(("redis-sentinel",pid=31365,fd=6))
13.3.3 配置Slave的sentinel.conf文件
[root@slave-97 7002]# cd /data/7002/[root@slave-97 7002]# cp -a /usr/local/redis/sentinel.conf sentinel.conf[root@slave-97 7002]# vim sentinel.confbind 0.0.0.0port 26381 #需要修改daemonize yespidfile "/data/7002/redis-sentinel.pid" #需要修改logfile "/data/7002/redis-sentinel.log" #需要修改dir "/data/7002" #需要修改sentinel myid 85696cc6170b82b07e52d315c45f1475088ce41b #myid必须不一致sentinel deny-scripts-reconfig yessentinel monitor mymaster 10.4.60.95 7000 2 #需要修改sentinel down-after-milliseconds mymaster 3000sentinel auth-pass mymaster 123456配置文件以及systemd的启动文件基本一致,除了一些路径、端口需要修改为外,其他保持一致#启动所有哨兵服务systemctl daemon-reloadsystemctl enable redis-sentinel.servicesystemctl start redis-sentinel.service
13.4 验证哨兵模式
#1、模拟故障,关闭master的redis[root@master-95 7000]# systemctl stop redis#2、查看master日志,发现redis已经关闭[root@master-95 7000]# tail -100f redis-sentinel.log31330:X 11 Dec 2020 14:20:02.958 # User requested shutdown...31330:X 11 Dec 2020 14:20:02.958 * Removing the pid file.31330:X 11 Dec 2020 14:20:02.958 # Sentinel is now ready to exit, bye bye...31346:X 11 Dec 2020 14:20:02.978 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo31346:X 11 Dec 2020 14:20:02.978 # Redis version=5.0.2, bits=64, commit=00000000, modified=0, pid=31346, just started31346:X 11 Dec 2020 14:20:02.978 # Configuration loaded31347:X 11 Dec 2020 14:20:02.981 * Increased maximum number of open files to 4096 (it was originally set to 1024).31347:X 11 Dec 2020 14:20:02.981 * Running mode=sentinel, port=26379.31347:X 11 Dec 2020 14:20:02.982 # Sentinel ID is df2bbb5c317263d99bc882ad193f3df9873f1d5e31347:X 11 Dec 2020 14:20:02.982 # +monitor master mymaster 10.4.60.95 7000 quorum 2#3、我们来到slave服务器,用info命令查看[root@slave-96 redis]# ./src/redis-cli -h 10.4.60.96 -p 7001 -a 12345610.4.60.96:7001> INFO replication# Replicationrole:master #这时候我们可以看到原先95的master自动切换至96上了,至此Redis的哨兵模式部署完成connected_slaves:1slave0:ip=10.4.60.97,port=7002,state=online,offset=1427058,lag=1master_replid:49c7d65fedd3d54b4b27ac0420f1ae6cc459c03emaster_replid2:d15e90434ded4b3256e8bec3311276fcb79b9464master_repl_offset:1427328second_repl_offset:57205repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:378753repl_backlog_histlen:1048576
13.4.1 恢复原先故障的master至集群中
[root@master-95 7000]# vim /data/7000/redis.confreplicaof 10.4.60.96 7001masterauth "123456"[root@master-95 7000]# systemctl restart redis[root@master-95 redis]# ./src/redis-cli -h 10.4.60.95 -p 7000 -a 12345610.4.60.95:7000> INFO replication# Replicationrole:slavemaster_host:10.4.60.96master_port:7001master_link_status:upmaster_last_io_seconds_ago:0master_sync_in_progress:0slave_repl_offset:1496668slave_priority:100slave_read_only:1connected_slaves:0master_replid:49c7d65fedd3d54b4b27ac0420f1ae6cc459c03emaster_replid2:0000000000000000000000000000000000000000master_repl_offset:1496668second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:448093repl_backlog_histlen:1048576#观察新的master的info信息10.4.60.96:7001> INFO replication# Replicationrole:masterconnected_slaves:2slave0:ip=10.4.60.97,port=7002,state=online,offset=1427058,lag=1slave1:ip=10.4.60.95,port=7000,state=online,offset=1426923,lag=1master_replid:49c7d65fedd3d54b4b27ac0420f1ae6cc459c03emaster_replid2:d15e90434ded4b3256e8bec3311276fcb79b9464master_repl_offset:1427328second_repl_offset:57205repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:378753repl_backlog_histlen:1048576
14 Redis备份与恢复实战
14.1 备份与恢复的意义
1.为什么要做备份?在日常的应用中,无时无刻不充满着危机。服务器down机、磁盘损坏、系统崩溃、数据误操作等等问题,都在影响着我们的数据安全。备份可以在出现问题时,保障数据的安全或者把数据损失以及业务上的损失降低到最低。
2.如何做好备份?既然我们知道了备份的重要性,我们应该怎么样去做好备份呢,这是一个值得研究的问题,什么样策略时得当的,什么样的策略时最符合我们需求的。
3.为什么有主从还要做备份?你是不是会有这样的疑问?主从不就已经是备份了么?当数据被误操作、前端代码不严谨导致数据被*、主库写入出现的脏数据,同样会同步到我们的从库中。所以,一定要做好文件的备份。
14.2 Redis备份演练(基于阿里云)
| 服务类型 | 角色 | IP | 端口 |
|---|---|---|---|
| redis-server | Master | 8.130.27.132 | 6379 |
| redis-server | Slave | 8.130.27.235 | 6379 |
| Rsync-备份机 | 8.130.31.14 |
14.2.1 异地备份操作(RDB文件为例)
#1、备份脚本mkdir -p /scripts/ #创建放置脚本的路径vim redis_backup.sh#!/bin/bashDATA_DIR=/data/redis/6379/db #设定redis文件目录BACKUP_DIR=/backup #设定本地备份目录TIME_NOW=$(date -d '+0 day' +'%Y-%m-%d-%H') #获取当前时间,精确到小时cd $DATA_DIR #进入redis文件目录tar zcf redis_backup_$TIME_NOW.tar.gz ./dump.rdb #打包dump.rdb文件mv redis_backup_$TIME_NOW.tar.gz $BACKUP_DIR #移动至备份目录下rsync -avz $BACKUP_DIR/ rsync_backup@172.25.221.156::backup/ --password-file=/etc/rsync.password #通过rsync远程同步到远程备份服务器上rsync的服务端以及客户端部署,请参考我之前的rsync部署文档。
14.2.2 定时计划的备份策略
我们可以通过系统的crontab命令,来完成定时的自动备份。那么这个定时策略该如何制定,我们通过以下几个维度来考虑:
- Redis的定位,首先确定Redis是否作为纯缓存,纯缓存的情况下,我们一般每天进行备份一次即可。如果没配置持久化,需要在备份前执行bgsave来生成rdb文件后进行备份。
- AOF和RDB的选择,其实在日常的使用中,在数据比较重要时,我们是打开RDB和AOF两种持久化模式,一般进行异地备份,我们都选择拷贝RDB快照文件作为备份。因为RDB文件是压缩过的比较小,AOF虽然可以通过重写收缩,但是大量备份的时候,还是会消耗较多磁盘。
- AOF可以作为本地临时紧急恢复的一种手段,AOF文件恢复重启的时候,恢复比较慢,另外AOF可以手动重写,一些能马上发现的错误,我们可以通过自己手动重写AOF来完成数据恢复,列如flushdb执行之后,我们可以重写AOF文件,删除这个命令后重启,就可以完成。
- AOF和RDB恢复对比,在Redis恢复的时候,当两个文件同时在,Redis会优先选择AOF文件,因为一般AOF文件的数据更为完整。但是从恢复时间来看,RDB文件的恢复时间,会优先于AOF文件。
14.2.3 AOF恢复演练
我们先连接Redis之后,执行flushall的操作,删除所有数据
172.25.221.155:6379> KEYS *1) "key1"2) "key3"3) "age"4) "name"5) "key2"172.25.221.155:6379> FLUSHALLOK172.25.221.155:6379> KEYS *(empty list or set)
想要恢复数据首先要停止数据库
[root@master ~]# systemctl stop redis
编辑AOF文件,AOF文件是记录数据库所有写操作。那么我们通过文件可以看到,执行了一次flushall的操作,我们通过编辑文件,来把最后执行的flushall命令删除掉,然后在启动Redis即可。
[root@master db]# tail appendonly.aof$6value3*2$6SELECT$10*1$8FLUSHALL #删除这行即可[root@master db]# systemctl start redis[root@master db]# cd /usr/local/redis[root@master redis]# ./src/redis-cli -h 172.25.221.155 -a 123456172.25.221.155:6379> KEYS *1) "name"2) "age"3) "key1"4) "key2"5) "key3"启动Redis服务,并连接服务查看数据已经恢复完成
注意事项:
1.当数据量较大时,或者写入比较频繁的时候,这种恢复方式并不太实用。因为文件写入的太多,而且文件比较大编辑查找需要恢复的数据,比较困难。针对这种数据,可以选择。
2.如果提示AOF文件损坏时,我们可以通过Redis附带的redis-check-aof程序,对需要恢复的AOF文件进行恢复,恢复完成之后再进行启动恢复。
3.恢复时比较消耗系统资源,恢复时Redis重新初始化加载数据,恢复时所需内存约为数据当量X2,所以恢复时要保证系统资源。这就是Redis在使用时正常,假如关闭或者做数据恢复重启的时候,无法启动的原因。
14.2.4 模拟RDB、AOF文件被删除的场景
1、模拟环境,首先我们先删除所有数据,并且删除现有的AOF和RDB文件。
[root@master db]# cd /usr/local/redis[root@master redis]# ./src/redis-cli -h 172.25.221.155 -a 123456172.25.221.155:6379> FLUSHALLOK172.25.221.155:6379> KEYS *(empty list or set)172.25.221.155:6379> quit[root@master redis]# cd /data/redis/6379/db/[root@master db]# lsappendonly.aof dump.rdb[root@master db]# rm -rf *
2、修改redis.conf,关闭appendonly参数,修改为no
appendonly no这里为什么要先关闭AOF呢?#原因是我们开启了AOF和RDB持久化,我们在恢复的时候虽然拷贝到RDB的数据,但是Redis重启的时候发现没有AOF文件,会重新创建一个空的AOF文件。启动初始化内存的时候,优先从AOF文件加载,AOF是新创建的空文件,这样就会导致查到的数据为空,显示数据未恢复。
3、关闭数据库,避免数据库重写导致重新生成AOF文件
systemctl stop redis
4、清空数据目录,尤其删除AOF文件
rm -rf /data/redis/6379/db/
5、拷贝备份的rdb文件到data目录
cp -a /backup/redis_backup_2020-12-17-15.tar.gz /data/redis/6379/db/tar xf redis_backup_2020-12-17-15.tar.gzrm -f redis_backup_2020-12-17-15.tar.gz
6、启动数据库,加载数据完成(根据实际需求,加载完数据后重新打开appendonly参数即可)
[root@master db]# systemctl start redis[root@master db]# cd /usr/local/redis[root@master redis]# ./src/redis-cli -h 172.25.221.155 -a 123456172.25.221.155:6379> KEYS *1) "age"2) "key1"3) "name"4) "key3"5) "key2"
15 Redis Cluster集群原理与部署
15.1 Redis Cluster工作原理特点
1、所有Redis节点使用PING机制互联
2、集群中某个节点的是否失效,是由整个集群中超过半数的节点监测都失效,才能算真正的失效
3、客户端不需要proxy即可直接连接Redis,应用程序需要写全部的Redis服务器IP地址和端口号
4、Redis Cluster把所有的Redis node平均映射到0-16383个槽位(slot)上,读写需要到指定的Redis node上进行
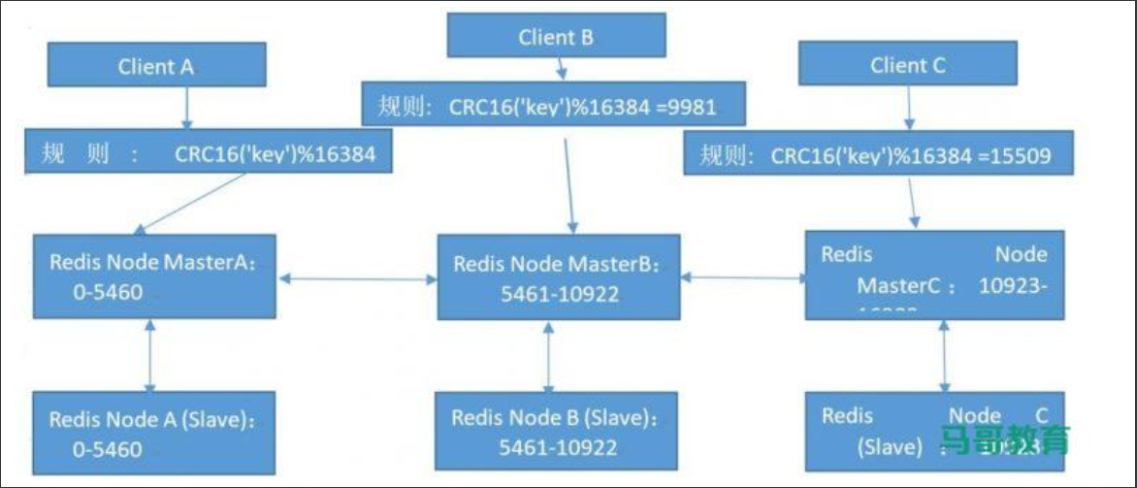
5、Redis Cluster预先分配到16384个槽位,当需要在Redis集群中写入一个key-value的时候,会使用CRC16(key) mod 16384之后的值,决定将key写入到哪一个槽位从而决定写入哪一个Redis节点上,从而有效解决单机瓶颈
15.2 Redis Cluster架构
假设有三个主节点,分别是:A、B、C三个节点,采用哈希槽(hash slot)的方式来分配16384个槽位的话,这三个节点分别承担的槽位区间是:
节点A覆盖:0 ~ 5460节点B覆盖:5461 ~ 10922节点C覆盖:10923 ~ 16383

15.2.1 Redis Cluster主从架构
Redis Cluster的架构虽然解决了并发的问题,但是又引入了一个新的问题,每个Redis Master的高可用如何解决?可以在每个Master节点,再部署一个从节点,这样就可以达到高可用了
15.2.2 Redis拓扑图
不太合理的拓扑:
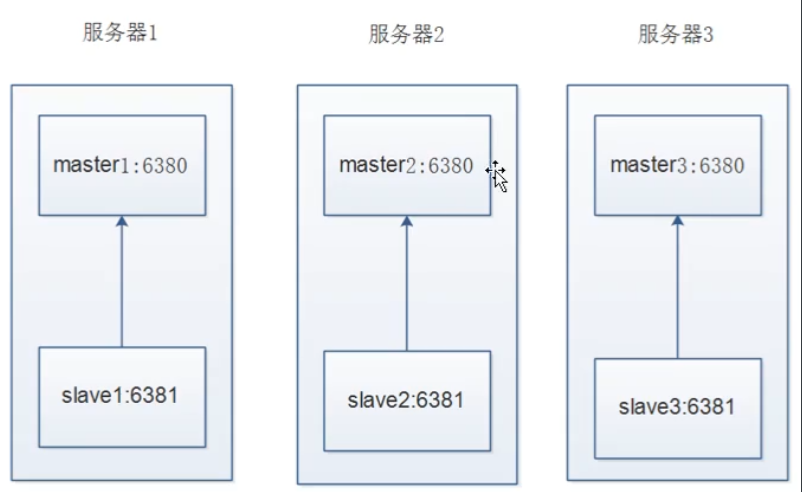
合理的拓扑图:

15.3 Redis Cluster部署
15.3.1 Redis Cluster环境配置
根据官方推荐,集群部署至少要3台以上的Master节点,所以我们准备3台服务器,每台服务器运行两个Redis
| 主机说明 | 主机IP | 端口 |
|---|---|---|
| Redis | 10.4.60.95 | 7000、7001 |
| Redis | 10.4.60.96 | 7002、7003 |
| Redis | 10.4.60.97 | 7004、7005 |
#10.4.60.95(多实列)部署(其他服务器和95一致,除了端口,IP,已经路径不一样之外,其他保持一致即可)#1、创建7000和7001目录,并且创建conf、data、logs目录[root@master-95 redis]# mkdir -p /data/redis/{7000,7001}/{conf,logs,data}#2、配置redis文件[root@master-95 conf]# vim redis.confbind 10.4.60.95 127.0.0.1 #IP地址需要更改,注意这边127.0.0.1要放到另外一个ip后面,否则后面构建集群会一直处于等待状态protected-mode yesport 7000 #端口需要更改tcp-backlog 511timeout 300tcp-keepalive 300daemonize yessupervised nopidfile "/data/redis/7000/redis.pid" #路径需要更改loglevel noticelogfile "/data/redis/7000/logs/redis.log" #路径需要更改databases 16always-show-logo yessave 900 1save 300 10save 60 10000stop-writes-on-bgsave-error yesrdbcompression yesrdbchecksum yesdbfilename "dump_7000.rdb" #文件名需要更改dir "/data/redis/7000/data" #路径需要更改appendonly yesappendfilename "appendonly-7000.aof" #文件名需要更改appendfsync everysecno-appendfsync-on-rewrite yesauto-aof-rewrite-percentage 100auto-aof-rewrite-min-size 64mbaof-load-truncated yesaof-use-rdb-preamble yeslua-time-limit 5000slowlog-log-slower-than 10000slowlog-max-len 128latency-monitor-threshold 0notify-keyspace-events ""hash-max-ziplist-entries 512hash-max-ziplist-value 64list-max-ziplist-size -2list-compress-depth 0set-max-intset-entries 512zset-max-ziplist-entries 128zset-max-ziplist-value 64hll-sparse-max-bytes 3000stream-node-max-bytes 4096stream-node-max-entries 100activerehashing yesclient-output-buffer-limit normal 0 0 0client-output-buffer-limit replica 256mb 64mb 60client-output-buffer-limit pubsub 32mb 8mb 60hz 10dynamic-hz yesaof-rewrite-incremental-fsync yesrdb-save-incremental-fsync yesmaxclients 4064maxmemory 2147483648#3、赋予redis权限[root@master-95 conf]# chown -R redis:redis /data/redis/#4、配置redis启动文件[root@master-95 conf]# vim /usr/lib/systemd/system/redis_7000.service[Unit]Description=RedisAfter=network.target[Service]Type=forkingExecStart=/usr/local/redis/src/redis-server /data/redis/7000/conf/redis.conf #路径需要更改ExecReload=/bin/kill -s HUP $MAINPIDExecStop=/usr/local/redis/src/redis-cli shutdownUser=redisGroup=redisPrivateTmp=true[Install]WantedBy=multi-user.target[root@master-95 conf]# systemctl daemon-reload[root@master-95 conf]# systemctl enable redis_7000.service[root@master-95 conf]# systemctl start redis_7000.service[root@master-95 7000]# ss -lntp|grep redisLISTEN 0 511 10.4.60.95:7000 *:* users:(("redis-server",pid=1772,fd=7))LISTEN 0 511 127.0.0.1:7000 *:* users:(("redis-server",pid=1772,fd=6))其他配置基本一致,记得改端口和路径即可,这边就不多做介绍了
15.3.2 配置Cluster集群
15.3.2.1 配置redis文件
#在每个配置文件中添加以下内容:cluster-enabled yes #开启集群模式cluster-config-file nodes_7000.conf #此处配置文件名需更改cluster-node-timeout 15000 #集群的超时时间配置好之后,重启我们的redis[root@salve-97 conf]# ss -lntp|grep redisLISTEN 0 128 10.4.60.97:7004 *:* users:(("redis-server",pid=1825,fd=7))LISTEN 0 128 127.0.0.1:7004 *:* users:(("redis-server",pid=1825,fd=6))LISTEN 0 128 10.4.60.97:7005 *:* users:(("redis-server",pid=1842,fd=7))LISTEN 0 128 127.0.0.1:7005 *:* users:(("redis-server",pid=1842,fd=6))LISTEN 0 128 10.4.60.97:17004 *:* users:(("redis-server",pid=1825,fd=11))LISTEN 0 128 127.0.0.1:17004 *:* users:(("redis-server",pid=1825,fd=10))LISTEN 0 128 10.4.60.97:17005 *:* users:(("redis-server",pid=1842,fd=11))LISTEN 0 128 127.0.0.1:17005 *:* users:(("redis-server",pid=1842,fd=10))
15.3.2.2 启动好之后就可以创建集群
注意:在Redis5.0之后,创建集群统一使用redis-cli,之前的版本使用redis-trib.rb,但是需要安装ruby软件,这个软件相对复杂,相比之前的版本5.0不需要安装额外的软件。
创建集群命令:其中cluster-replicas 1代表一个master后有几个slave,1代表为一个slave节点
[root@master-95 redis]# ./src/redis-cli --cluster create 10.4.60.95:7000 10.4.60.96:7002 10.4.60.97:7004 10.4.60.95:7001 10.4.60.96:7003 10.4.60.97:7005 --cluster-replicas 1 #构建集群的时候,会把前三个作为master,后三个作为slave>>> Performing hash slots allocation on 6 nodes...Master[0] -> Slots 0 - 5460Master[1] -> Slots 5461 - 10922Master[2] -> Slots 10923 - 16383Adding replica 10.4.60.96:7003 to 10.4.60.95:7000Adding replica 10.4.60.95:7001 to 10.4.60.96:7002Adding replica 10.4.60.97:7005 to 10.4.60.97:7004>>> Trying to optimize slaves allocation for anti-affinity[OK] Perfect anti-affinity obtained!M: ce5e55c0e17139865bb5820738e317148de314ce 10.4.60.95:7000 #带M的为masterslots:[0-5460] (5461 slots) master #当前master的槽位起始和结束位M: 4e6c347a318de0495919fe047a3a3a7984cf29b0 10.4.60.96:7002slots:[5461-10922] (5462 slots) masterM: f71ce5f010250662dc7b9ac0935536fffa657ece 10.4.60.97:7004slots:[10923-16383] (5461 slots) masterS: 830df48a8c00d49533d0600515a42bb8129f8b15 10.4.60.95:7001 #带S的是slavereplicates 4e6c347a318de0495919fe047a3a3a7984cf29b0S: 259e32d6dd805d75c486326225f9338c294ea197 10.4.60.96:7003replicates f71ce5f010250662dc7b9ac0935536fffa657eceS: 4b2685f00a08b7efafa9dacabf9e5985a42d6236 10.4.60.97:7005replicates ce5e55c0e17139865bb5820738e317148de314ceCan I set the above configuration? (type 'yes' to accept): yes #输入yes自动创建集群>>> Nodes configuration updated>>> Assign a different config epoch to each node>>> Sending CLUSTER MEET messages to join the clusterWaiting for the cluster to join...>>> Performing Cluster Check (using node 10.4.60.95:7000)M: ce5e55c0e17139865bb5820738e317148de314ce 10.4.60.95:7000slots:[0-5460] (5461 slots) master #已经分配的槽位1 additional replica(s) #分配了一个slaveS: 259e32d6dd805d75c486326225f9338c294ea197 10.4.60.96:7003slots: (0 slots) slave #slave没有分配槽位replicates f71ce5f010250662dc7b9ac0935536fffa657ece #对应的master的IDS: 830df48a8c00d49533d0600515a42bb8129f8b15 10.4.60.95:7001slots: (0 slots) slavereplicates 4e6c347a318de0495919fe047a3a3a7984cf29b0M: f71ce5f010250662dc7b9ac0935536fffa657ece 10.4.60.97:7004slots:[10923-16383] (5461 slots) master1 additional replica(s)S: 4b2685f00a08b7efafa9dacabf9e5985a42d6236 10.4.60.97:7005slots: (0 slots) slavereplicates ce5e55c0e17139865bb5820738e317148de314ceM: 4e6c347a318de0495919fe047a3a3a7984cf29b0 10.4.60.96:7002slots:[5461-10922] (5462 slots) master1 additional replica(s)[OK] All nodes agree about slots configuration. #所有节点槽位分配完成>>> Check for open slots... #检查打开的槽位>>> Check slots coverage... #检查插槽覆盖范围[OK] All 16384 slots covered. #所有槽位16384个分配完成
15.3.2.3 查看主从状态
[root@master-95 redis]# ./src/redis-cli -p 7000 info replication# Replicationrole:masterconnected_slaves:1slave0:ip=10.4.60.97,port=7005,state=online,offset=658,lag=1master_replid:0f4fb4c9a873b77c632fa46dd33c2c0bb74144ccmaster_replid2:0000000000000000000000000000000000000000master_repl_offset:658second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:1repl_backlog_histlen:658[root@slave-96 redis]# ./src/redis-cli -p 7002 info replication# Replicationrole:masterconnected_slaves:1slave0:ip=10.4.60.95,port=7001,state=online,offset=784,lag=1master_replid:330001b7ef2c34ed4726b0b8fb3490fe226ca1b8master_replid2:0000000000000000000000000000000000000000master_repl_offset:784second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:1repl_backlog_histlen:784[root@salve-97 redis]# ./src/redis-cli -p 7004 info replication# Replicationrole:masterconnected_slaves:1slave0:ip=10.4.60.96,port=7003,state=online,offset=1050,lag=1master_replid:d7fc76879584a1de7e7661196d2af015b4d2b5d0master_replid2:0000000000000000000000000000000000000000master_repl_offset:1050second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:1repl_backlog_histlen:1050可以看到三个master对应着三个从节点
15.3.2.4 验证集群状态
[root@master-95 redis]# ./src/redis-cli -p 7000 cluster infocluster_state:okcluster_slots_assigned:16384cluster_slots_ok:16384cluster_slots_pfail:0cluster_slots_fail:0cluster_known_nodes:6 #节点数cluster_size:3 #三个集群cluster_current_epoch:6cluster_my_epoch:1cluster_stats_messages_ping_sent:847cluster_stats_messages_pong_sent:800cluster_stats_messages_sent:1647cluster_stats_messages_ping_received:795cluster_stats_messages_pong_received:847cluster_stats_messages_meet_received:5cluster_stats_messages_received:1647#查看任意节点的集群状态[root@master-95 redis]# ./src/redis-cli -p 7000 --cluster info 10.4.60.96:700210.4.60.96:7002 (4e6c347a...) -> 0 keys | 5462 slots | 1 slaves.10.4.60.97:7004 (f71ce5f0...) -> 0 keys | 5461 slots | 1 slaves.10.4.60.95:7000 (ce5e55c0...) -> 0 keys | 5461 slots | 1 slaves.[OK] 0 keys in 3 masters.0.00 keys per slot on average.
15.3.2.5 模拟master故障,对应的salve节点自动提升为master
#关闭10.4.60.95:7000 master节点[root@master-95 ~]# systemctl stop redis_7000[root@master-95 ~]# cd /usr/local/redis[root@master-95 redis]# ./src/redis-cli -p 7001 --cluster info 10.4.60.97:7005Could not connect to Redis at 10.4.60.95:7000: Connection refused10.4.60.97:7005 (4b2685f0...) -> 0 keys | 5461 slots | 0 slaves. #可以看到之前对应的从节点10.4.60.97:7005变为master节点了10.4.60.97:7004 (f71ce5f0...) -> 0 keys | 5461 slots | 1 slaves.10.4.60.96:7002 (4e6c347a...) -> 0 keys | 5462 slots | 1 slaves.[OK] 0 keys in 3 masters.0.00 keys per slot on average.#恢复之前的故障节点[root@master-95 redis]# systemctl start redis_7000[root@master-95 redis]# ./src/redis-cli -p 7001 --cluster info 10.4.60.95:700010.4.60.96:7002 (4e6c347a...) -> 0 keys | 5462 slots | 1 slaves.10.4.60.97:7004 (f71ce5f0...) -> 0 keys | 5461 slots | 1 slaves.10.4.60.97:7005 (4b2685f0...) -> 0 keys | 5461 slots | 1 slaves.[OK] 0 keys in 3 masters.0.00 keys per slot on average.[root@master-95 redis]# ./src/redis-cli -p 7000 info replication# Replicationrole:slavemaster_host:10.4.60.97master_port:7005master_link_status:upmaster_last_io_seconds_ago:6master_sync_in_progress:0slave_repl_offset:1540slave_priority:100slave_read_only:1connected_slaves:0master_replid:478f87e358a1749639c5b89599d0d785606fb4a0master_replid2:0000000000000000000000000000000000000000master_repl_offset:1540second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:1457repl_backlog_histlen:84#可以看到之前的主节点,自动成为从节点
15.3.2.6 部署集群遇到的问题
#1、redis cluster 一直在等待 Waiting for the cluster to join网上有很多原因,一种是端口号+10000 的端口没有打开第二种是需要在集群里输入 cluster meet 127.0.0.1 7000第三种是绑定ip顺序,如果绑定两个ip ,要通过将绑定ip 127.0.0.1 放置到后面实现的。我目前遇到这种问题是通过第三种方法解决的。第四种就是防火墙或者selinux没有关闭
15.4 Redis Cluster集群节点维护
集群运行时间长久之后,难免由于硬件故障、网络规划、业务增长等原因对已有集群进行相应的调整, 比如增加Redis node节点、减少节点、节点迁移、更换服务器等。增加节点和删除节点会涉及到已有的槽位重新分配及数据迁移。
15.4.1 集群维护之动态扩容
因业务需求,需增加一台服务器10.4.60.98,将其动态添加至集群中,但不能影响业务使用和数据丢失
15.4.1.1 添加节点准备
增加Redis node节点,需要与之前的Redis node版本相同、配置一致,然后在启动节点,为一主一从。这边就不再多说了,详细安装方式请查看前面
15.4.1.2 添加节点到集群
使用以下命令添加新节点,要添加的新redis节点IP和端口添加到的已有的集群中任意节点的IP:端口
add-node new_host:new_port existing_host:existing_port说明:new_host:new_port #为新添加的主机的IP和端口existing_host:existing_port #为已有的集群中任意节点的IP和端口
[root@master-95 redis]# ./src/redis-cli --cluster add-node 10.4.60.98:7006 10.4.60.96:7002>>> Adding node 10.4.60.98:7006 to cluster 10.4.60.96:7002>>> Performing Cluster Check (using node 10.4.60.96:7002)M: 4e6c347a318de0495919fe047a3a3a7984cf29b0 10.4.60.96:7002slots:[5461-10922] (5462 slots) master1 additional replica(s)M: 4b2685f00a08b7efafa9dacabf9e5985a42d6236 10.4.60.97:7005slots:[0-5460] (5461 slots) master1 additional replica(s)S: 830df48a8c00d49533d0600515a42bb8129f8b15 10.4.60.95:7001slots: (0 slots) slavereplicates 4e6c347a318de0495919fe047a3a3a7984cf29b0M: f71ce5f010250662dc7b9ac0935536fffa657ece 10.4.60.97:7004slots:[10923-16383] (5461 slots) master1 additional replica(s)S: ce5e55c0e17139865bb5820738e317148de314ce 10.4.60.95:7000slots: (0 slots) slavereplicates 4b2685f00a08b7efafa9dacabf9e5985a42d6236S: 259e32d6dd805d75c486326225f9338c294ea197 10.4.60.96:7003slots: (0 slots) slavereplicates f71ce5f010250662dc7b9ac0935536fffa657ece[OK] All nodes agree about slots configuration.>>> Check for open slots...>>> Check slots coverage...[OK] All 16384 slots covered.>>> Send CLUSTER MEET to node 10.4.60.98:7006 to make it join the cluster.[OK] New node added correctly.[root@master-95 redis]# ./src/redis-cli --cluster add-node 10.4.60.98:7007 10.4.60.96:7002#我们可以看到已经添加两个新节点至集群中,但是没有slot位[root@master-95 redis]# ./src/redis-cli --cluster info 10.4.60.95:700010.4.60.96:7002 (4e6c347a...) -> 0 keys | 5462 slots | 1 slaves.10.4.60.98:7006 (ffa9e3b9...) -> 0 keys | 0 slots | 0 slaves.10.4.60.97:7004 (f71ce5f0...) -> 0 keys | 5461 slots | 1 slaves.10.4.60.97:7005 (4b2685f0...) -> 0 keys | 5461 slots | 1 slaves.10.4.60.98:7007 (edaf2031...) -> 0 keys | 0 slots | 0 slaves.[OK] 0 keys in 5 masters.0.00 keys per slot on average
15.4.1.3 重新分配槽位
新的node节点加到集群之后默认是master节点,但是没有slots数据,需要重新分配添加主机之后需要对添加至集群种的新主机重新分片否则其没有分片也就无法写入数据。
root@master-95 redis]# ./src/redis-cli -p 7000 --cluster reshard 10.4.60.98:7006>>> Performing Cluster Check (using node 10.4.60.98:7006)M: d6e2eca6b338b717923f64866bd31d42e52edc98 10.4.60.98:7006slots: (0 slots) master.....[OK] All nodes agree about slots configuration.>>> Check for open slots...>>> Check slots coverage...[OK] All 16384 slots covered.How many slots do you want to move (from 1 to 16384)?4096 #分配多少个槽位=16384/master个数What is the receiving node ID? d6e2eca6b338b717923f64866bd31d42e52edc98 #10.4.60.98:7006的IDPlease enter all the source node IDs.Type 'all' to use all the nodes as source nodes for the hash slots.Type 'done' once you entered all the source nodes IDs.Source node #1: all #将哪些源主机的槽位分配给新的节点,all是自动在所有的redis node选择划分,如果是从redis cluster删除某个主机可以使用此方式将指定主机上的槽位全部移动到别的redis主机......Do you want to proceed with the proposed reshard plan (yes/no)? yes #确认分配......#确定slot分配成功[root@master-95 redis]# ./src/redis-cli -p 7000 --cluster check 10.4.60.95:700010.4.60.96:7002 (4e6c347a...) -> 0 keys | 4096 slots | 1 slaves.10.4.60.98:7006 (ffa9e3b9...) -> 0 keys | 4096 slots | 0 slaves.10.4.60.97:7004 (f71ce5f0...) -> 0 keys | 4096 slots | 1 slaves.10.4.60.97:7005 (4b2685f0...) -> 0 keys | 4096 slots | 1 slaves.10.4.60.98:7007 (edaf2031...) -> 0 keys | 0 slots | 0 slaves.[OK] 0 keys in 5 masters.0.00 keys per slot on average.>>> Performing Cluster Check (using node 10.4.60.95:7000)S: ce5e55c0e17139865bb5820738e317148de314ce 10.4.60.95:7000slots: (0 slots) slavereplicates 4b2685f00a08b7efafa9dacabf9e5985a42d6236S: 830df48a8c00d49533d0600515a42bb8129f8b15 10.4.60.95:7001slots: (0 slots) slavereplicates 4e6c347a318de0495919fe047a3a3a7984cf29b0S: 259e32d6dd805d75c486326225f9338c294ea197 10.4.60.96:7003slots: (0 slots) slavereplicates f71ce5f010250662dc7b9ac0935536fffa657eceM: 4e6c347a318de0495919fe047a3a3a7984cf29b0 10.4.60.96:7002slots:[6827-10922] (4096 slots) master1 additional replica(s)M: ffa9e3b99f3492459982badfb8a30aecf6376bec 10.4.60.98:7006slots:[0-1364],[5461-6826],[10923-12287] (4096 slots) masterM: f71ce5f010250662dc7b9ac0935536fffa657ece 10.4.60.97:7004slots:[12288-16383] (4096 slots) master1 additional replica(s)M: 4b2685f00a08b7efafa9dacabf9e5985a42d6236 10.4.60.97:7005slots:[1365-5460] (4096 slots) master1 additional replica(s)M: edaf2031d38c239c64057901cfd5f84c23d629d7 10.4.60.98:7007slots: (0 slots) master[OK] All nodes agree about slots configuration.>>> Check for open slots...>>> Check slots coverage...[OK] All 16384 slots covered.
15.4.1.4 为新的master添加slave节点
需要再向当前的Redis集群中添加一个Redis单机服务器10.4.60.98:7007,用于解决当10.4.60.98:7006单机的潜在宕机问题,即实现响应的高可用功能。
[root@salve-97 redis]# ./src/redis-cli --cluster add-node 10.4.60.98:7007 10.4.60.96:7002 #把10.4.60.98:7007添加至集群中[root@salve-97 redis]# ./src/redis-cli -p 7007 #登录redis,添加slave节点127.0.0.1:7007> cluster nodes #查看当前集群节点,找到目标master的ID127.0.0.1:7007> cluster replicate ffa9e3b99f3492459982badfb8a30aecf6376bec #将其设置为slaveOK[root@salve-97 redis]# ./src/redis-cli -p 7007 info Replication #我们已经看到其节点已经成为从节点# Replicationrole:slavemaster_host:10.4.60.98master_port:7006master_link_status:upmaster_last_io_seconds_ago:4master_sync_in_progress:0slave_repl_offset:462slave_priority:100slave_read_only:1connected_slaves:0master_replid:e57f6e19ffd470b7c5cf84ead0c207d8cd5d756fmaster_replid2:0000000000000000000000000000000000000000master_repl_offset:462second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:1repl_backlog_histlen:462
15.4.2 集群维护之动态缩容
我们把之前动态扩容的10.4.60.98:7006和10.4.60.98:7007从集群中剔除掉。
15.4.2.1 删除节点过程
添加节点的时候是先添加node节点到集群,然后分配槽位,删除节点的操作与添加节点的操作正好相反,是先将被删除的Redis node上的槽位迁移到集群中的其他Redis node节点上,然后再将其删除,如果一个Redis node节点上的槽位没有被完全迁移,删除该node的时候会提示有数据且无法删除。
注意:迁移master的时候,必须保证其没有数据,否则迁移报错并会被强制中断。
#查看当前状态[root@master-95 redis]# ./src/redis-cli -p 7000 --cluster check 10.4.60.95:700010.4.60.96:7002 (4e6c347a...) -> 0 keys | 4096 slots | 1 slaves.10.4.60.98:7006 (ffa9e3b9...) -> 0 keys | 4096 slots | 1 slaves.10.4.60.97:7004 (f71ce5f0...) -> 0 keys | 4096 slots | 1 slaves.10.4.60.97:7005 (4b2685f0...) -> 0 keys | 4096 slots | 1 slaves.[OK] 0 keys in 4 masters.0.00 keys per slot on average.>>> Performing Cluster Check (using node 10.4.60.95:7000)S: ce5e55c0e17139865bb5820738e317148de314ce 10.4.60.95:7000slots: (0 slots) slavereplicates 4b2685f00a08b7efafa9dacabf9e5985a42d6236S: 830df48a8c00d49533d0600515a42bb8129f8b15 10.4.60.95:7001slots: (0 slots) slavereplicates 4e6c347a318de0495919fe047a3a3a7984cf29b0S: 259e32d6dd805d75c486326225f9338c294ea197 10.4.60.96:7003slots: (0 slots) slavereplicates f71ce5f010250662dc7b9ac0935536fffa657eceM: 4e6c347a318de0495919fe047a3a3a7984cf29b0 10.4.60.96:7002slots:[6827-10922] (4096 slots) master1 additional replica(s)M: ffa9e3b99f3492459982badfb8a30aecf6376bec 10.4.60.98:7006slots:[0-1364],[5461-6826],[10923-12287] (4096 slots) master1 additional replica(s)M: f71ce5f010250662dc7b9ac0935536fffa657ece 10.4.60.97:7004slots:[12288-16383] (4096 slots) master1 additional replica(s)M: 4b2685f00a08b7efafa9dacabf9e5985a42d6236 10.4.60.97:7005slots:[1365-5460] (4096 slots) master1 additional replica(s)S: edaf2031d38c239c64057901cfd5f84c23d629d7 10.4.60.98:7007slots: (0 slots) slavereplicates ffa9e3b99f3492459982badfb8a30aecf6376bec[OK] All nodes agree about slots configuration.>>> Check for open slots...>>> Check slots coverage...[OK] All 16384 slots covered.#连接到任意集群节点,保证其插槽上的数据迁移至其他节点,比如第一个master节点10.4.60.96:7002[root@master-95 redis]# ./src/redis-cli -p 7000 --cluster reshard 10.4.60.98:7006.....[OK] All nodes agree about slots configuration.>>> Check for open slots...>>> Check slots coverage...[OK] All 16384 slots covered.How many slots do you want to move (from 1 to 16384)? 1356 #共4096/3分别给其它三个master节点What is the receiving node ID? d34da8666a6f587283a1c2fca5d13691407f9462 #master 10.4.60.96Please enter all the source node IDs.Type 'all' to use all the nodes as source nodes for the hash slots.Type 'done' once you entered all the source nodes IDs.Source node #1: cb028b83f9dc463d732f6e76ca6bbcd469d948a7 #输入要删除10.4.60.98节点IDSource node #2: doneMoving slot 2719 from cb028b83f9dc463d732f6e76ca6bbcd469d948a7Moving slot 2720 from cb028b83f9dc463d732f6e76ca6bbcd469d948a7Do you want to proceed with the proposed reshard plan (yes/no)? yes #确定......#再将1365个slot从10.4.60.98:7006移动到第二个master节点10.4.60.97:7004上[root@master-95 redis]# ./src/redis-cli -p 7000 --cluster reshard 10.4.60.95:7000 --cluster-slots 1365 --cluster-from ffa9e3b99f3492459982badfb8a30aecf6376bec --cluster-to 4e6c347a318de0495919fe047a3a3a7984cf29b0 --cluster-yes#最后的slot从10.4.60.98:7007移动到第三master节点10.4.60.97:7005上[root@master-95 redis]# ./src/redis-cli -p 7000 --cluster reshard 10.4.60.95:7000 --cluster-slots 1375 --cluster-from ffa9e3b99f3492459982badfb8a30aecf6376bec --cluster-to 4b2685f00a08b7efafa9dacabf9e5985a42d6236 --cluster-yes注释:--cluster-from:被删除的masterID 10.4.60.98:7007的ID号--cluster-to:被添加新插槽的masterID 10.4.60.97:7005的ID号
15.4.2.2 从集群删除master
虽然槽位已经迁移完成,但是服务器IP信息还在集群当中,因此还需要将IP信息从集群删除
[root@master-95 redis]# ./src/redis-cli -p 7000 --cluster del-node 10.4.60.98:7006 ffa9e3b99f3492459982badfb8a30aecf6376bec#删除节点信息rm -f /data/redis/7006/data/nodes_7006.conf
15.4.2.3 从集群中删除slave
[root@master-95 redis]# ./src/redis-cli -p 7000 --cluster del-node 10.4.60.98:7007 edaf2031d38c239c64057901cfd5f84c23d629d7#删除节点信息rm -f /data/redis/7007/data/nodes_7007.conf
15.4.2.4 最后验证集群
[root@master-95 redis]# ./src/redis-cli -p 7000 --cluster check 10.4.60.95:700010.4.60.96:7002 (4e6c347a...) -> 0 keys | 5461 slots | 1 slaves.10.4.60.97:7004 (f71ce5f0...) -> 0 keys | 5452 slots | 1 slaves.10.4.60.97:7005 (4b2685f0...) -> 0 keys | 5471 slots | 1 slaves.[OK] 0 keys in 3 masters.0.00 keys per slot on average.>>> Performing Cluster Check (using node 10.4.60.95:7000)S: ce5e55c0e17139865bb5820738e317148de314ce 10.4.60.95:7000slots: (0 slots) slavereplicates 4b2685f00a08b7efafa9dacabf9e5985a42d6236S: 830df48a8c00d49533d0600515a42bb8129f8b15 10.4.60.95:7001slots: (0 slots) slavereplicates 4e6c347a318de0495919fe047a3a3a7984cf29b0S: 259e32d6dd805d75c486326225f9338c294ea197 10.4.60.96:7003slots: (0 slots) slavereplicates f71ce5f010250662dc7b9ac0935536fffa657eceM: 4e6c347a318de0495919fe047a3a3a7984cf29b0 10.4.60.96:7002slots:[1356-1364],[5461-6816],[6827-10922] (5461 slots) master1 additional replica(s)M: f71ce5f010250662dc7b9ac0935536fffa657ece 10.4.60.97:7004slots:[0-1355],[12288-16383] (5452 slots) master1 additional replica(s)M: 4b2685f00a08b7efafa9dacabf9e5985a42d6236 10.4.60.97:7005slots:[1365-5460],[6817-6826],[10923-12287] (5471 slots) master1 additional replica(s)[OK] All nodes agree about slots configuration.>>> Check for open slots...>>> Check slots coverage...[OK] All 16384 slots covered.
16 Redis应用中的问题与风险

通过上述图片,我们可以看出往往一些小小的举动,就会造成一个很大的线上问题,如何规避此类问题是我们运维人员所需要考虑的。
16.1 安全性的防范措施
首先我们在使用Redis的时候一般很少有人去设置密码,大部分的原因是因为我们把Redis是作为缓存的,没必要设置密码那么麻烦。但是随着数据量的增长现在大数据也好或者其他也好,Redis的定位已经不简单的是作为缓存了,是存放我们一些热点的数据信息等,同样和Mysql一样,也是我们的核心数据。所以设置安全密码是很有必要的。
16.2 误操作的防范措施
通过之前的学习,我们知道Redis的命令非常强大,比如在查询的时候使用keys *或者keys xxx匹配,这样都会消耗我们大量的资源,当数据的量级比较小的时候,可能做起来还比较方便,但是同样有隐患,首先Redis作为一个单线程的程序,如果你的一个命令执行的消耗资源严重并且无法很快返回结果,必然会导致我们其他的访问受损。
危险命令的禁用,也是我们防止有人出现误操作或者恶意操作的一个必要方法,列如开头那个有人使用keys *导致了Redis出现了死锁,也有可能会有人操作flushdb或者flushall等命令来删除我们的数据库或者重要数据,那么如何防止类似的情况发生,就是需要我们考虑的。另外,比如某些人没有经过授权,使用config命令来修改我们的配置,都会造成不可避免的损失,所以我们大家一定要进行提前的防范。下面让我们来讲解如何禁止使用一些命令。
flushdb #清空当前数据库的数据flushall #清空所有数据库的数据keys #禁止使用全量或者正则匹配检索我们的数据库的key,否则会导致进程出现死锁config #配置命令
以上这四个命令我们要全部禁用,使用配置文件的方式:
[root@salve-97 conf]# vim redis.confrename-command keys ""rename-command flushdb ""rename-command flushall ""rename-command config ""
下边我们重启数据库来查看配置是否生效,已经成功禁止了这些命令

我们可以通过上面的图片看出,使用set和get命令都可以正常的使用,但是当我们执行我们所预期的要禁用的命令的时候,系统提示我们为无效命令,那么这个结果是符合我们预期的。
16.3 缓存穿透
缓存穿透的概念主要是指查询一个一定不存在的数据的时候,由于缓存是不命中时的被动写的,并且由于频繁查询不存在的数据,所以这个空数据也不会写入缓存,这样就会导致每次查询都需要到存储层来查询这个数据,这样的话缓存就失去了存在的意义。在出现大量查询的时候,可能后端的DB就会出现问题,如果有人频繁的使用不存在的key来频繁的请求或者做*的话,就会导致我们的应用出现不同程度的问题。
那么我们如何解决这个问题呢?其实很简单,在查询一个返回为空的数据的时候,我们把这个空结果也进行缓存,但是给他设定一个比较短的过期时间,这样的话,我们就可以有效的避免了以上问题。
16.4 缓存雪崩
缓存雪崩主要是指我们设定了相同的过期时间,导致缓存在某一个时间点同时都失效了,这样的话,我们大部分的请求都直接转发给DB了,DB就不堪重负最终倒下。
这个问题解决起来也很简单,我们在key过期的时间上设置一个随机的值,比如十分钟内随机失效,那么缓存同时失效的时间就会降低很多,可以有效的避免同时集体失效的事件。
16.5 不使用默认端口
Redis的默认端口是6379,不使用默认端口从一定程度上可降低被入侵者发现的可能性,因为入侵者通常本身也是一些攻击程序,对目标服务器进行端口扫描,例如MySQL的默认端口3306、Memcache的默认端口11211、Jetty的默认端口8080等都会被设置成攻击目标,Redis作为一款较为知名的NoSQL服务,6379必然也在端口扫描的列表中,虽然不设置默认端口还是有可能被攻击者入侵,但是能够在一定程度上降低被攻击的概率。
17 Redis内存优化与系统优化
127.0.0.1:7004> info memory# Memoryused_memory:2373672 #Redis已使用的内存总量(单位是字节)used_memory_human:2.26M #仅仅是友好的显示出内存已使用的值used_memory_rss:12636160 #Redis进程占据操作系统的内存(单位字节)used_memory_rss_human:12.05M #友好的显示Redis进程占据操作系统的内存值used_memory_peak:2443608 #内存使用的最大值,也就是used_memory峰值used_memory_peak_human:2.33M #友好的显示used_memory_peak这个值used_memory_lua:37888 #lua引擎占用的内存used_memory_lua_human:37.00K #友好的显示used_memory_lua这个值mem_fragmentation_ratio:5.42 #内存碎片比例mem_allocator:jemalloc-5.1.0 #Redis使用内存分配器,在编译时指定
通过上边的描述我们简单的了解了一些参数,需要我们注意的是mem_fragmentation_ratio:5.42这个值,该值是used_memory_rss / used_memory的比值。如何理解内存碎片呢,简单来说,我们设置了100个key,占用100k,后来我删除或者过期了80个,那么释放出的80K,就是内存碎片。我们可以简单理解为Redis cache到的内存值,used_memory是Redis使用的内存值,比如cache到了100M,仅仅使用了1M,那么这个值应该是100,那么我们就不用担心,当比值小于1的时候,说明Redis使用了虚拟内存,我们知道虚拟内存的媒介是磁盘,比内存速度要慢很多,当这种情况出现时,应该及时排查,如果内存不足应该及时处理,如增加Redis节点、增加Redis服务器的内存、优化应用等。
17.1 Redis的内存划分
1.Redis对象内存:这部分主要是指我们的数据消耗,我们存放的key和value。
2.自身内存:这部分内存主要是Redis主进程本身运行需要占用的内存,大约几兆。
3.缓冲内存:这部分缓冲内存包括客户端缓冲区、复制积压缓冲区、AOF缓冲区等。
4.内存碎片:内存碎片是Redis在分配、回收物理内存过程中产生的。
17.2 Redis的内存使用和管理
- 最大使用内存 maxmemory
以16G内存服务器为列,个人建议设置Redis内存为物理服务器的一半,也就是8G,这样做的原因是可以保障我们的服务器不会因为Redis把内存撑满,导致物理服务器宕机。 - 数据淘汰
#Redis提供了6种数据淘汰策略volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰no-enviction(驱逐):禁止驱逐数据
最好为Redis指定一种有效的数据淘汰策略以配合maxmemory设置,避免在内存使用满后发生写入失败的情况。
一般使用淘汰策略的话,推荐volatile-lru。对于那些重要的,绝对不能丢弃的数据,应不设置有效期,这样Redis就永远不会淘汰这些数据。对于一些不怎么重要的数据,可以设置上有效期,这样在内存不够时Redis就会淘汰这部分数据。
淘汰的策略设置主要是针对用作缓存的场景,假如我们当做DB使用的话,那么不应该设置我们淘汰的策略。
redis.conf配置如下:
17.3 Linux下的内存配置
17.3.1 vm.overcommit_memory
Redis在启动时可能会出现这样的日志:

在分析这个问题之前,首先要弄清楚什么是overcommit?Linux操作系统对大部分申请内存的请求都回复yes,以便能运行更多的程序。因为申请内存后,并不会马上使用内存,这种技术叫做overcommit。如果Redis在启动时有上面的日志,说明vm.overcommit_memory=0,Redis提示把它设置为1。
vm.overcommit_memory用来设置内存分配策略,有三个可选值,如表所示:

日志中的Background save代表的是bgsave和bgrewriteaof,如果当前可用内存不足,操作系统应该如何处理fork操作。如果vm.overcommit_memory=0,代表如果没有可用内存,就申请内存失败,对应到Redis就是执行fork失败,在Redis的日志会出现:

Redis建议把这个值设置为1,是为了让fork操作能够在低内存下也执行成功。
配置内核参数:
vim /etc/sysctl.confvm.overcommit_memory = 1然后执行sysctl -p
17.3.2 swappiness
swap对于操作系统来比较重要,当物理内存不足时,可以将一部分内存页进行swap操作,已解燃眉之急。但世界上没有免费午餐,swap空间由硬盘提供,对于需要高并发、高吞吐的应用来说,磁盘IO通常会成为系统瓶颈。在Linux中,并不是要等到所有物理内存都使用完才会使用到swap,系统参数swppiness会决定操作系统使用swap的倾向程度。swappiness的取值范围是0~100,swappiness的值越大,说明操作系统可能使用swap的概率越 高,swappiness值越低,表示操作系统更加倾向于使用物理内存。swap的默认值是60,了解这个值的含义后,有利于Redis的性能优化。以下表对swappiness的重要值进行了说明:

从表中可以看出,swappiness参数在Linux3.5版本前后的表现并不完全相同,Redis运维人员在设置这个值需要关注当前操作系统的内核版本。
配置方法:
echo vm.swappiness=10 >> /etc/sysctl.conf
17.3.3 THP
Redis在启动时可能会看到如下日志:

从提示看Redis建议修改Transparent Huge Pages(THP)的相关配置,Linux kernel在2.6.38内核增加了THP特性,支持大内存页(2MB)分配,默认开启。当开启时可以降低fork子进程的速度,但fork操作之后,每个内存页从原来4KB变为2MB,会大幅增加重写期间父进程内存消耗。同时每次写命令引起的复制内存页单位放大了512倍,会拖慢写操作的执行时间,导致大量写操作慢查询,例如简单的incr命令也会出现在慢查询中。因此Redis日志中建议将此特性进行禁用,禁用方法如下:
echo never > /sys/kernel/mm/transparent_hugepage/enabledecho 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' >> /etc/rc.d/rc.localchmod +x /etc/rc.d/rc.local然后重启redis即可
17.3.4 NTP
NTP(Network Time Protocol,网络时间协议)是一种保证不同机器时钟一致性的服务。我们知道像Redis Sentinel和Redis Cluster这两种功能需要多个Redis节点的类型,可能会涉及多台服务器。虽然Redis并没有对多个服务器的时钟有严格要求,但是假如多个Redis实例所在的服务器时钟不一致,对于一些异常情况的日志排查是非常困难的,例如Redis Cluster的故障转移,如果日志时间不一致,对于我们排查问题带来很大的困扰(注:但不会影响集群功能,集群节点依赖各自时钟)。一般公司里都会有NTP服务用来提供标准时间服务,从而达到纠正时钟的效果,为此我们可以每天定时去同步一次系统时间,从而使得集群中的时间保持统一。
17.3.5 ulimit
在Linux中,可以通过ulimit查看和设置系统当前用户进程的资源数。其中ulimit -a命令包含的open files参数,是单个用户同时打开的最大文件个数:

Redis允许同时有多个客户端通过网络进行连接,可以通过配置maxclients来限制最大客户端连接数。对Linux操作系统来说,这些网络连接都是文件句柄。假设当前open files是4096,那么启动Redis时会看到如下日志:

日志解释如下:
第一行:Redis建议把open files至少设置成10032,那么这个10032是如何来的呢?因为maxclients默认是10000,这些是用来处理客户端连接的,除此之外,Redis内部会使用最多32个文件描述符,所以这里的10032=10000+32。
第二行:Redis不能将open files设置成10032,因为它没有权限设置。
第三行:当前系统的open files是4096,所以将maxclients设置成4096-74432=4064个,如果你想设置更高的maxclients,请使用ulimit-n来设置。
从上面的三行日志分析可以看出open files的限制优先级比maxclients大。
Open files的设置方法如下:
ulimit –Sn {max-open-files}

若有收获,就点个赞吧
0 人点赞
