1.1 通俗地理解什么是编程语言
学习编程语言之前,首先要搞清楚「编程语言」这个概念。
很小的时候,父母就教我们开口说话,也教我们如何理解别人讲话的意思。经过长时间的熏陶和自我学习,我们竟然在不知不觉中学会了说话,同时也能听懂其他小朋友说话的意思了,我们开始向父母要零花钱买零食和玩具、被欺负了向父母倾诉……
我们说的是汉语,是“中国语言”,只要把我们的需求告诉父母,父母就会满足,我们用“中国语言”来控制父母,让父母做我们喜欢的事情。
“中国语言”有固定的格式,每个汉字代表的意思不同,我们必须正确的表达,父母才能理解我们的意思。例如让父母给我们10元零花钱,我们会说“妈妈给我10块钱吧,我要买小汽车”。如果我们说“10元给我汽车小零花钱妈妈”,或者“妈妈给我10亿人民币,我要买F-22”,妈妈就会觉得奇怪,听不懂我们的意思,或者理解错误,责备我们。
我们通过有固定格式和固定词汇的“语言”来控制他人,让他人为我们做事情。语言有很多种,包括汉语、英语、法语、韩语等,虽然他们的词汇和格式都不一样,但是可以达到同样的目的,我们可以选择任意一种语言去控制他人。
同样,我们也可以通过”语言“来控制计算机,让计算机为我们做事情,这样的语言就叫做编程语言(Programming Language)。
编程语言也有固定的格式和词汇,我们必须经过学习才会使用,才能控制计算机。
编程语言有很多种,常用的有C语言、C++、Java、C#、Python、PHP、JavaScript、Go语言、Objective-C、Swift、汇编语言等,每种语言都有自己擅长的方面,例如:
| 编程语言 | 主要用途 |
|---|---|
| C/C++ | C++ 是在C语言的基础上发展起来的,C++ 包含了C语言的所有内容,C语言是C++的一个部分,它们往往混合在一起使用,所以统称为 C/C++。C/C++主要用于PC软件开发、Linux开发、游戏开发、单片机和嵌入式系统。 |
| Java | Java 是一门通用型的语言,可以用于网站后台开发、Android 开发、PC软件开发,近年来又涉足了大数据 领域(归功于 Hadoop 框架的流行)。 |
| C# | C# 是微软开发的用来对抗 Java 的一门语言,实现机制和 Java 类似,不过 C# 显然失败了,目前主要用于 Windows 平台的软件开发,以及少量的网站后台开发。 |
| Python | Python 也是一门通用型的语言,主要用于系统运维、网站后台开发、数据分析、人工智能、云计算 等领域,近年来势头强劲,增长非常快。 |
| PHP | PHP 是一门专用型的语言,主要用来开发网站后台程序。 |
| JavaScript | JavaScript 最初只能用于网站前端开发,而且是前端开发的唯一语言,没有可替代性。近年来由于 Node.js 的流行,JavaScript 在网站后台开发中也占有了一席之地,并且在迅速增长。 |
| Go语言 | Go语言是 2009 年由 Google 发布的一款编程语言,成长非常迅速,在国内外已经有大量的应用。Go 语言主要用于服务器端的编程,对 C/C++、Java 都形成了不小的挑战。 |
| Objective-C Swift |
Objective-C 和 Swift 都只能用于苹果产品的开发,包括 Mac、MacBook、iPhone、iPad、iWatch 等。 |
| 汇编语言 | 汇编语言是计算机发展初期的一门语言,它的执行效率非常高,但是开发效率非常低,所以在常见的应用程序开发中不会使用汇编语言,只有在对效率和实时性要求极高的关键模块才会考虑汇编语言,例如操作系统内核、驱动、仪器仪表、工业控制等。 |
可以将不同的编程语言比喻成各国语言,为了表达同一个意思,可能使用不同的语句。例如,表达“世界你好”的意思:
- 汉语:世界你好;
- 英语:Hello World
- 法语:Bonjour tout le monde
在编程语言中,同样的操作也可能使用不同的语句。例如,在屏幕上显示“小马学编程”:
- C语言:
puts("小马学编程"); - PHP:
echo "小马学编程"; - Java:
System.out.println("小马学编程");
编程语言类似于人类语言,由直观的词汇组成,我们很容易就能理解它的意思,例如在C语言中,我们使用 puts 这个词让计算机在屏幕上显示出文字;puts 是 output string(输出字符串)的缩写。
使用 puts 在屏幕上显示“小马学编程”:puts("小马学编程");
我们把要显示的内容放在(“和”)之间,并且在最后要有;。你必须要这样写,这是固定的格式。
总结:编程语言是用来控制计算机的一系列指令(Instruction),它有固定的格式和词汇(不同编程语言的格式和词汇不一样),必须遵守,否则就会出错,达不到我们的目的。
C语言(C Language)是编程语言的一种,学习C语言,主要是学习它的格式和词汇。下面是一个C语言的完整例子,它会让计算机在屏幕上显示”小马学编程“。
这个例子主要演示C语言的一些固有格式和词汇,看不懂的读者不必深究,也不必问为什么是这样,后续我们会逐步给大家讲解。
#include <stdio.h>int main(){puts("C语言中文网");return 0;}
这些具有特定含义的词汇、语句,按照特定的格式组织在一起,就构成了源代码(Source Code),也称源码或代码(Code)。
那么,C语言肯定规定了源代码中每个词汇、语句的含义,也规定了它们该如何组织在一起,这就是语法(Syntax)。它与我们学习英语时所说的“语法”类似,都规定了如何将特定的词汇和句子组织成能听懂的语言。
编写源代码的过程就叫做编程(Program)。从事编程工作的人叫程序员(Programmer)。程序员也很幽默,喜欢自嘲,经常说自己的工作辛苦,地位低,像农民一样,所以称自己是”码农“,就是写代码的农民。也有人自嘲称是”程序猿“。
1.2 C语言究竟是一门怎样的语言?
对于大部分程序员,C语言是学习编程的第一门语言,很少有不了解C的程序员。
C语言除了能让你了解编程的相关概念,带你走进编程的大门,还能让你明白程序的运行原理,比如,计算机的各个部件是如何交互的,程序在内存中是一种怎样的状态,操作系统和用户程序之间有着怎样的“爱恨情仇”,这些底层知识决定了你的发展高度,也决定了你的职业生涯。
如果你希望成为出类拔萃的人才,而不仅仅是码农,这么这些知识就是不可逾越的。也只有学习C语言,才能更好地了解它们。有了足够的基础,以后学习其他语言,会触类旁通,很快上手,7 天了解一门新语言不是神话。
C语言概念少,词汇少,包含了基本的编程元素,后来的很多语言(C++、Java等)都参考了C语言,说C语言是现代编程语言的开山鼻祖毫不夸张,它改变了编程世界。
正是由于C语言的简单,对初学者来说,学习成本小,时间短,结合本教程,能够快速掌握编程技术。
在世界编程语言排行榜中,C语言、Java 和 C++ 霸占了前三名,拥有绝对优势,如下表所示:
| 2015年01月榜单 | ||
|---|---|---|
| 排名 | 语言 | 占有率 |
| 1 | C | 16.703% |
| 2 | Java | 15.528% |
| 3 | Objective-C | 6.953% |
| 4 | C++ | 6.705% |
| 5 | C# | 5.045% |
| 6 | PHP | 3.784% |
| 7 | JavaScript | 3.274% |
| 8 | Python | 2.613% |
| 9 | Perl | 2.256% |
| 10 | PL/SQL | 2.014% |
| 2015年06月榜单 | ||
| 排名 | 语言 | 占有率 |
| 1 | Java | 17.822% |
| 2 | C | 16.788% |
| 3 | C++ | 7.756% |
| 4 | C# | 5.056% |
| 5 | Objective-C | 4.339% |
| 6 | Python | 3.999% |
| 7 | Visual Basic .NET | 3.168% |
| 8 | PHP | 2.868% |
| 9 | JavaScript | 2.295% |
| 10 | Delphi/Object Pascal | 1.869% |
| 2018年01月榜单 | ||
| 排名 | 语言 | 占有率 |
| 1 | Java | 14.215% |
| 2 | C | 11.037% |
| 3 | C++ | 5.603% |
| 4 | Python | 4.678% |
| 5 | C# | 3.754% |
| 6 | JavaScript | 3.465% |
| 7 | Visual Basic .NET | 3.261% |
| 8 | R | 2.549% |
| 9 | PHP | 2.532% |
| 10 | Perl | 2.419% |
2017年,由于小型软件设备的蓬勃发展以及汽车行业底层软件的增加,C语言还拿下了「年度编程语言」的桂冠,成为 2017 年全球增长最快的编程语言。下表列出了最近 10 年的“年度编程语言”
| 年份 | 优胜者 |
|---|---|
| 2017 |  C C |
| 2016 |  Go Go |
| 2015 |  Java Java |
| 2014 |  JavaScript JavaScript |
| 2013 |  Transact-SQL Transact-SQL |
| 2012 |  Objective-C Objective-C |
| 2011 |  Objective-C Objective-C |
| 2010 |  Python Python |
| 2009 |  Go Go |
| 2008 |  CC语言的三套标准:C89、C99和C11 CC语言的三套标准:C89、C99和C11 |
C语言诞生于20世纪70年代,年龄比我们都要大,我们将在《C语言的三套标准:C89、C99和C11》一节中讲解更多关于C语言的历史。
当然,C语言也不是没有缺点,毕竟是70后老人,有点落后时代,开发效率较低,后来人们又在C语言的基础上增加了面向对象的机制,形成了一门新的语言,称为C++,我们将在《C语言和C++到底有什么关系》中讲解。
C语言难吗?
和 Java、C++、Python、C#、JavaScript 等高级编程语言相比,C语言涉及到的编程概念少,附带的标准库小,所以整体比较简洁,容易学习,非常适合初学者入门。

编程语言的发展大概经历了以下几个阶段:汇编语言 --> 面向过程编程 --> 面向对象编程
- 汇编语言是编程语言的拓荒年代,它非常底层,直接和计算机硬件打交道,开发效率低,学习成本高;
- C语言是面向过程的编程语言,已经脱离了计算机硬件,可以设计中等规模的程序了;
- Java、C++、Python、C#、PHP 等是面向对象的编程语言,它们在面向过程的基础上又增加了很多概念。
C语言出现的时候,已经度过了编程语言的拓荒年代,具备了现代编程语言的特性,但是这个时候还没有出现“软件危机”,人们没有动力去开发更加高级的语言,所以也没有太复杂的编程思想。
也就是说,C语言虽然是现代编程语言,但是它涉及到的概念少,词汇少,思想也简单。C语言学习成本小,初学者能够在短时间内掌握编程技能,非常适合入门。
C语言是计算机产业的核心语言
也许是机缘巧合,C语言出现后不久,计算机产业开始爆发,计算机硬件越来越小型化,越来越便宜,逐渐进入政府机构,进入普通家庭,C语言成了编程的主力军,获得了前所未有的成功,操作系统、常用软件、硬件驱动、底层组件、核心算法、数据库、小游戏等都使用C语言开发。
雷军说过,站在风口上,猪都能飞起来;C语言就是那头猪,不管它好不好,反正它飞起来了。

C语言在计算机产业大爆发阶段被万人膜拜,无疑会成为整个软件产业的基础,拥有核心地位。
软件行业的很多细分学科都是基于C语言的,学习数据结构、算法、操作系统、编译原理等都离不开C语言,所以大学将C语言作为一门公共课程,计算机相关专业的同学都要学习。
C语言被誉为“上帝语言”,它不但奠定了软件产业的基础,还创造了很多其它语言,例如:
- PHP、Python 等都是用C语言开发出来的,虽然平时做项目的时候看不到C语言的影子,但是如果想深入学习 PHP 和 Python,那就要有C语言基础了。
- C++ 和 Objective-C 干脆在C语言的基础上直接进行扩展,增加一些新功能后变成了新的语言,所以学习 C++ 和 Objective-C 之前也要先学习C语言。
C语言是有史以来最为重要的编程语言:要进入编程行业高手级别必学C语言,要挣大钱必学C语言,要做黑客、红客必学C语言,要面试名企、外企、高薪职位必学C语言。
你也许会质疑,都 202X 年了,还有人在使用C语言这种古董吗?答案是肯定的!
1.3 C语言是菜鸟和大神的分水岭
作为一门古老的编程语言,C语言已经坚挺了好几十年了,初学者从C语言入门,大学将C语言视为基础课程。不管别人如何抨击,如何唱衰,C语言就是屹立不倒;Java、C#、Python、PHP、Perl 等都有替代方案,它们都可以倒下,唯独C语言不行。
程序是在内存中运行的(我们将在《载入内存,让程序运行起来》一节中详细说明),一名合格的程序员必须了解内存,学习C语言是了解内存布局的最简单、最直接、最有效的途径,C语言简直是为内存而生的,它比任何一门编程语言都贴近内存。
所谓内存,就是我们常说的内存条,就是下图这个玩意,相信你肯定见过。
图:内存条
所有的程序都在拼尽全力节省内存,都在不遗余力提高内存使用效率,计算机的整个发展过程都在围绕内存打转,不断地优化内存布局,以保证可以同时运行多个程序。
不了解内存,就学不会进程和线程,就没有资格玩中大型项目,没有资格开发底层组件,没有资格架构一个系统,命中注定你就是一个菜鸟,成不了什么气候。
C语言就是为内存而生的,C语言的设计和内存的布局是严密贴合的,学会C语言才能吃透内存,了解了计算机内存是如何分布和组织的。
C语言无时无刻不在谈内存,内存简直就是如影随形,你不得不去研究它。
至关重要的一点是,我能够把内存和具体的编程知识以及程序的运行过程结合起来,真正做到了学以致用,让概念落地,而不是空谈,这才是最难得的。
值得开心的是,攻克内存后你也能够理解进程和线程了,原来进程和线程也是围绕内存打转的,从一定程度上讲,它们的存在也是为了更加高效地利用内存。
从C语言到内存,从内存到进程和线程,环环相扣:不学C语言就吃不透内存,不学内存就吃不透进程和线程。
「内存 + 进程 + 线程」这几个最基本的计算机概念是菜鸟和大神的分水岭,也只有学习C语言才能透彻地理解它们。Java、C#、PHP、Python、JavaScript 程序员工作几年后会遇到瓶颈,有很多人会回来学习C语言,重拾底层概念,让自己再次突破。
1.4 学编程难吗?多久能入门?
这篇文章主要是解答初学者的疑惑,没有信心的读者看了会吃一颗定心丸,浮躁的读者看了会被泼一盆冷水。
学编程难吗?
编程是一门技术,我也不知道它难不难,我只知道,只要你想学,肯定能学会。每个人的逻辑思维能力不同,兴趣点不同,总有一部分人觉得容易,一部分人觉得吃力。
在我看来,技术就是一层窗户纸,是有道理可以遵循的,最起码要比搞抽象的艺术容易很多。
但是,隔行如隔山,学好编程也不是一朝一夕的事,想“吃快餐”的读者可以退出编程界了,浮躁的人搞不了技术。
在技术领域,编程的入门门槛很低,互联网的资料很多,只要你有一台计算机,一根网线,具备初中学历,就可以学习。
不管是技术还是非技术,要想有所造诣,都必须潜心钻研,没有几年功夫不会鹤立鸡群。所以请先问问你自己,你想学编程吗,你喜欢吗,如果你觉得自己对编程很感兴趣,想了解软件或网站是怎么做的,那么就不要再问这个问题了,尽管去学就好了。
多久能学会编程?
这是一个没有答案的问题。每个人投入的时间、学习效率和基础都不一样。如果你每天都拿出大把的时间来学习,那么两三个月就可以学会C/C++,不到半年时间就可以编写出一些软件。
但是有一点可以肯定,几个月从小白成长为大神是绝对不可能的。要想出类拔萃,没有几年功夫是不行的。学习编程不是看几本书就能搞定的,需要你不断的练习,编写代码,积累零散的知识点,代码量跟你的编程水平直接相关,没有几万行代码,没有拿得出手的作品,怎能称得上“大神”。
每个人程序员都是这样过来的,开始都是一头雾水,连输出九九乘法表都很吃力,只有通过不断练习才能熟悉,这是一个强化思维方式的过程。
知识点可以在短时间内了解,但是思维方式和编程经验需要不断实践才能强化,这就是为什么很多初学者已经了解了C语言的基本概念,但是仍然不会编写代码的原因。
程序员被戏称为”码农“,意思是写代码的农民,要想成为一个合格的农民,必须要脚踏实地辛苦耕耘。
也不要压力太大,一切编程语言都是纸老虎,一层窗户纸,只要开窍了,就容易了。
“浸泡”理论
一个人要想在某一方面有所成就,就必须有半年以上的时间,每天花 10 个小时“浸泡”在这件事情上,最终一定会有所收获。
很多领域都是「一年打基础,两年见成效,三年有突破」,但是很多人在不到一年的时间里就放弃了,总觉得这个行业太难,不太适合自己。
轻言放弃是很可怕的,你要知道,第一次放弃只是浪费了时间,第二次放弃会打击你的信心,第三次放弃会摧毁你的意志,你就再也没有尝试的勇气了,“蹉跎人生”就是这么来的。
你也不要羡慕那些富二代官二代,你以为人生就是一次百米短跑,你赢了就是赢了,其实人生是一场接力赛,你的父辈祖辈都得赢,那些富二代官二代从好几十年以前就开始积累了。
所以,沉下一颗心来,从现在开始积累吧,有执念的人最可怕。也最可爱。
1.5 英语和数学不好,能学编程吗?
很多初学者认为,编程语言是由英文组成的,而且会涉及很多算法,自己的英语和数学功底不好,到底能不能学会编程呢?
英语基础不好可以学会编程吗?
首先,学习编程需要你有英语基础;但是,要求并不高,原则上来讲,只要你能认全24个英文字母。那就能学。
当然了,如果你对上面这句话并没有异议。我劝你还是不要学了。因为你并不知道英文字母实际上是26个!嘻嘻
编程语言起源于美国,是由英文构成的,其中包括几十个英文的关键字以及几百个英文的函数,除非需要对文本进行处理,否则一般不会出现中文。但是,它们都是孤立的单词,不构成任何语句,不涉及任何语法。
几十个关键字不多,用得多了自然会记住,相信大家也不会担心。下面是C语言中的 32 个关键字:
| int | float | double | char | short | long | signed | unsigned |
|---|---|---|---|---|---|---|---|
| if | else | switch | case | default | for | while | do |
| break | continue | return | void | const | sizeof | struct | typedef |
| static | extern | auto | register | enum | goto | union | volatile |
不用背下来,学习的过程中潜移默化就认识了
几百个函数就没人能记住了,查询文档即可,每种编程语言都会提供配套的文档。常用到的函数也就几十个,记住它们就足够应付日常开发了,生僻的函数查询文档即可。
对于英文资料
如果你希望达到很高的造诣,希望被人称为“大神”,那么肯定要阅读英文的技术资料(不是所有资料都被翻译成了中文),初中水平就有点吃力了。
不过,长期阅读英文会提高你的英文水平,只要你坚持一段时间,即使只有初中水平,我相信借助翻译软件也会提高很快。
数学基础不好可以学编程吗?
谈到数学,那真是多虑了,它根本不构成障碍,会加减乘除就能学编程。
编程语言确实涉及到很多算法,有一些还需要高等数学知识,但是,这些算法都已经被封装好了,你直接拿来用就可以,根本不用你重复造轮子。
另外,这些算法都是在很深的底层为我们默默的工作,初级程序员根本不会涉及到算法,即使是别人已经封装好的算法,一般也没有机会使用,所以,你就别瞎操心了。
1.6 初中毕业能学会编程吗?
首先,初中毕业能学会编程,但是,不得不承认的是,大概率来讲,达不到太高的造诣。
编程是知识密集型的行业,需要很强的学习能力。初中就毕业了,肯定学习不好。大家的智商都差不多,成绩不好一般都是学习能力差。什么是学习能力呢?这包括专注能力、理解能力、自律能力等。
专注能力
有很多人不能专注于一件事情,容易走神,人虽然在,心已经飞了,根本钻研不进去。
理解能力
也可以说是逻辑思维能力。
同一道题目,有些人一看就知道思路,就知道如何切入;也有些人绞尽脑汁都想不到方案,不知道从哪里下手。
同一个现象,有些人觉得就应该这样,这是理所当然的,就像公理一样,不需要理由;也有些人觉得很费解,为什么是这样呢,理由是什么呢?
自律能力
学习是一件枯燥的事情,有些人能坚持下来,有些人就熬不住。
我也不知道为什么人的学习能力有差异,难道是与生俱来的?有没有心理学家给科普一下,在评论区给大家涨涨见识。
拥有良好的学习能力是一件幸事,你将终生受益,这个社会越来越奖励知识分子。
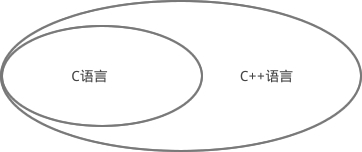
1.7 C语言和C++到底有什么关系?
C++ 读作”C加加“,是”C Plus Plus“的简称。
顾名思义,C++是在C的基础上增加新特性,玩出了新花样,所以叫”C Plus Plus“,就像 iPhone 6S 和 iPhone 6、Win10 和 Win7 的关系。
C语言是1972年由美国贝尔实验室研制成功的,在当时算是高级语言,它的很多新特性都让汇编程序员羡慕不已,就像今天的Go语言,刚出生就受到追捧。C语言也是”时髦“的语言,后来的很多软件都用C语言开发,包括 Windows、Linux 等。
但是随着计算机性能的飞速提高,硬件配置与几十年前已有天壤之别,软件规模也不断增大,很多软件的体积都超过 1G,例如 PhotoShop、Visual Studio 等,用C语言开发这些软件就显得非常吃力了,这时候C++就应运而生了。
C++ 主要在C语言的基础上增加了面向对象和泛型的机制,提高了开发效率,以适用于大中型软件的编写。
C++和C的血缘关系
早期并没有”C++“这个名字,而是叫做”带类的C“。”带类的C“是作为C语言的一个扩展和补充出现的,目的是提高开发效率,如果你有Java Web开发经验,那么你可以将它们的关系与 Java 和 JSP 的关系类比。
这个时期的C++非常粗糙,仅支持简单的面向对象编程,也没有自己的编译器,而是通过一个预处理程序(名字叫 cfront),先将C++代码”翻译“为C语言代码,再通过C语言编译器合成最终的程序。
随着C++的流行,它的语法也越来越强大,已经能够很完善的支持面向对象编程和泛型编程。但是一直也没有诞生出新的C++编译器,而是对原来C编译器不断扩展,让它支持C++的新特性,所以我们通常称为C/C++编译器,因为它同时支持C和C++,例如 Windows 下的微软编译器(cl.exe),Linux 下的 GCC 编译器。
也就是说,你写的C、C++代码都会通过一个编译器来编译,很难说C++是一门独立的语言,还是对C的扩展。
关于C++的学习
从“学院派”的角度来说,C++支持面向过程编程、面向对象编程和泛型编程,而C语言仅支持面向过程编程。就面向过程编程而言,C++和C几乎是一样的,所以学习了C语言,也就学习了C++的一半,不需要从头再来
1.8 二进制、八进制和十六进制
我们平时使用的数字都是由 0~9 共十个数字组成的,例如 1、9、10、297、952 等,一个数字最多能表示九,如果要表示十、十一、二十九、一百等,就需要多个数字组合起来。
例如表示 5+8 的结果,一个数字不够,只能”进位“,用 13 来表示;这时”进一位“相当于十,”进两位“相当于二十。
因为逢十进一(满十进一),也因为只有 0~9 共十个数字,所以叫做十进制(Decimalism)。
十进制是在人类社会发展过程中自然形成的,它符合人们的思维习惯,例如人类有十根手指,也有十根脚趾。
进制也就是进位制。进行加法运算时逢X进一(满X进一),进行减法运算时借一当X,这就是X进制,这种进制也就包含X个数字,基数为X。十进制有 0~9 共10个数字,基数为10,在加减法运算中,逢十进一,借一当十。
二进制
我们不妨将思维拓展一下,既然可以用 0~9 共十个数字来表示数值,那么也可以用0、1两个数字来表示数值,这就是二进制(Binary)。例如,数字 0、1、10、111、100、1000001 都是有效的二进制。
在计算机内部,数据都是以二进制的形式存储的,二进制是学习编程必须掌握的基础。本节我们先讲解二进制的概念,下节讲解数据在内存中的存储,让大家学以致用。
二进制加减法和十进制加减法的思想是类似的:
- 对于十进制,进行加法运算时逢十进一,进行减法运算时借一当十;
- 对于二进制,进行加法运算时逢二进一,进行减法运算时借一当二。
下面两张示意图详细演示了二进制加减法的运算过程。
1) 二进制加法:1+0=1、1+1=10、11+10=101、111+111=1110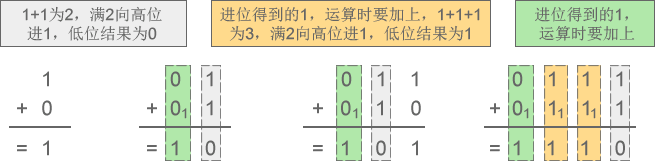
图1:二进制加法示意图
2) 二进制减法:1-0=1、10-1=1、101-11=10、1100-111=101
图2:二进制减法示意图
八进制
除了二进制,C语言还会使用到八进制。
八进制有 0~7 共8个数字,基数为8,加法运算时逢八进一,减法运算时借一当八。例如,数字 0、1、5、7、14、733、67001、25430 都是有效的八进制。
下面两张图详细演示了八进制加减法的运算过程。
1) 八进制加法:3+4=7、5+6=13、75+42=137、2427+567=3216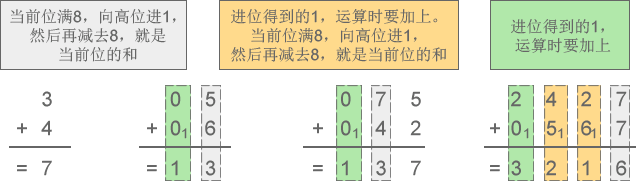
图3:八进制加法示意图
2) 八进制减法:6-4=2、52-27=23、307-141=146、7430-1451=5757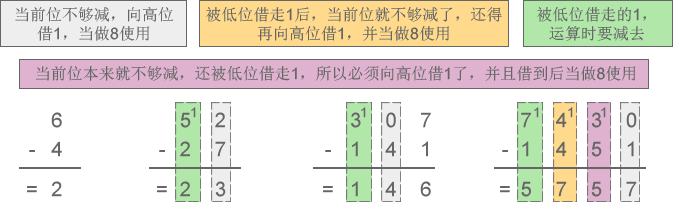
图4:八进制减法示意图
十六进制
除了二进制和八进制,十六进制也经常使用,甚至比八进制还要频繁。
十六进制中,用A来表示10,B表示11,C表示12,D表示13,E表示14,F表示15,因此有 0~F 共16个数字,基数为16,加法运算时逢16进1,减法运算时借1当16。例如,数字 0、1、6、9、A、D、F、419、EA32、80A3、BC00 都是有效的十六进制。
注意,十六进制中的字母不区分大小写,ABCDEF 也可以写作 abcdef。
下面两张图详细演示了十六进制加减法的运算过程。
1) 十六进制加法:6+7=D、18+BA=D2、595+792=D27、2F87+F8A=3F11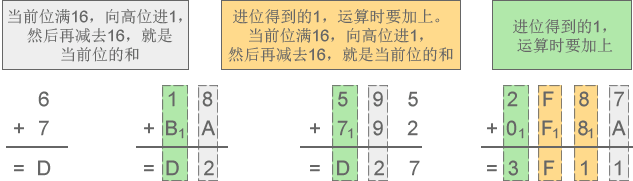
图5:十六进制加法示意图
2) 十六进制减法:D-3=A、52-2F=23、E07-141=CC6、7CA0-1CB1=5FEF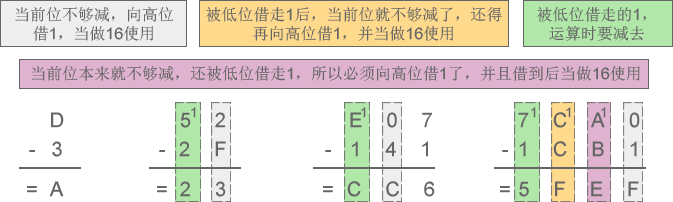
图6:十六进制减法示意图
1.9 不同进制之间的转换
对于基础薄弱的读者,本节的内容可能略显晦涩和枯燥,如果你觉得吃力,可以暂时跳过,基本不会影响后续章节的学习,等用到的时候再来阅读。
上节我们对二进制、八进制和十六进制进行了说明,本节重点讲解不同进制之间的转换,这在编程中经常会用到,尤其是C语言。
将二进制、八进制、十六进制转换为十进制
二进制、八进制和十六进制向十进制转换都非常容易,就是“按权相加”。所谓“权”,也即“位权”。
假设当前数字是 N 进制,那么:
- 对于整数部分,从右往左看,第 i 位的位权等于Ni-1
- 对于小数部分,恰好相反,要从左往右看,第 j 位的位权为N-j。
更加通俗的理解是,假设一个多位数(由多个数字组成的数)某位上的数字是 1,那么它所表示的数值大小就是该位的位权。
1) 整数部分
例如,将八进制数字 53627 转换成十进制:
53627 = 5×84 + 3×83 + 6×82 + 2×81 + 7×80 = 22423(十进制)
从右往左看,第1位的位权为 80=1,第2位的位权为 81=8,第3位的位权为 82=64,第4位的位权为 83=512,第5位的位权为 84=4096 …… 第n位的位权就为 8n-1。将各个位的数字乘以位权,然后再相加,就得到了十进制形式。
注意,这里我们需要以十进制形式来表示位权。
再如,将十六进制数字 9FA8C 转换成十进制:
9FA8C = 9×164 + 15×163 + 10×162 + 8×161 + 12×160 = 653964(十进制)
从右往左看,第1位的位权为 160=1,第2位的位权为 161=16,第3位的位权为 162=256,第4位的位权为 163=4096,第5位的位权为 164=65536 …… 第n位的位权就为 16n-1。将各个位的数字乘以位权,然后再相加,就得到了十进制形式。
将二进制数字转换成十进制也是类似的道理:
11010 = 1×24 + 1×23 + 0×22 + 1×21 + 0×20 = 26(十进制)
从右往左看,第1位的位权为 20=1,第2位的位权为 21=2,第3位的位权为 22=4,第4位的位权为 23=8,第5位的位权为 24=16 …… 第n位的位权就为 2n-1。将各个位的数字乘以位权,然后再相加,就得到了十进制形式。
2) 小数部分
例如,将八进制数字 423.5176 转换成十进制:
423.5176 = 4×82 + 2×81 + 3×80 + 5×8-1 + 1×8-2 + 7×8-3 + 6×8-4 = 275.65576171875(十进制)
小数部分和整数部分相反,要从左往右看,第1位的位权为 8-1=1/8,第2位的位权为 8-2=1/64,第3位的位权为 8-3=1/512,第4位的位权为 8-4=1/4096 …… 第m位的位权就为 8-m。
再如,将二进制数字 1010.1101 转换成十进制:
1010.1101 = 1×23 + 0×22 + 1×21 + 0×20 + 1×2-1 + 1×2-2 + 0×2-3 + 1×2-4 = 10.8125(十进制)
小数部分和整数部分相反,要从左往右看,第1位的位权为 2-1=1/2,第2位的位权为 2-2=1/4,第3位的位权为 2-3=1/8,第4位的位权为 2-4=1/16 …… 第m位的位权就为 2-m。
更多转换成十进制的例子:
- 二进制:1001 = 1×23 + 0×22 + 0×21 + 1×20 = 8 + 0 + 0 + 1 = 9(十进制)
- 二进制:101.1001 = 1×22 + 0×21 + 1×20 + 1×2-1 + 0×2-2 + 0×2-3 + 1×2-4 = 4 + 0 + 1 + 0.5 + 0 + 0 + 0.0625 = 5.5625(十进制)
- 八进制:302 = 3×82 + 0×81 + 2×80 = 192 + 0 + 2 = 194(十进制)
- 八进制:302.46 = 3×82 + 0×81 + 2×80 + 4×8-1 + 6×8-2 = 192 + 0 + 2 + 0.5 + 0.09375= 194.59375(十进制)
十六进制:EA7 = 14×162 + 10×161 + 7×160 = 3751(十进制)
将十进制转换为二进制、八进制、十六进制
将十进制转换为其它进制时比较复杂,整数部分和小数部分的算法不一样,下面我们分别讲解。
1) 整数部分
十进制整数转换为 N 进制整数采用“除 N 取余,逆序排列”法。具体做法是:
将 N 作为除数,用十进制整数除以 N,可以得到一个商和余数;
- 保留余数,用商继续除以 N,又得到一个新的商和余数;
- 仍然保留余数,用商继续除以 N,还会得到一个新的商和余数;
- ……
- 如此反复进行,每次都保留余数,用商接着除以 N,直到商为 0 时为止。
把先得到的余数作为 N 进制数的低位数字,后得到的余数作为 N 进制数的高位数字,依次排列起来,就得到了 N 进制数字。
下图演示了将十进制数字 36926 转换成八进制的过程: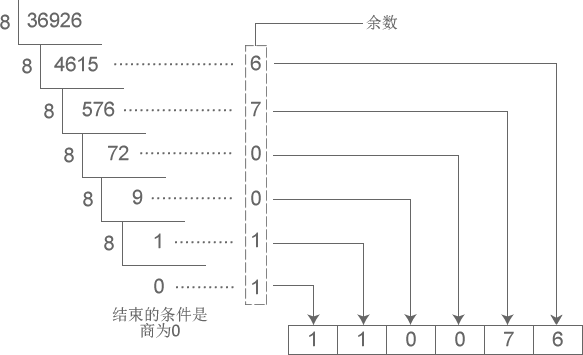
从图中得知,十进制数字 36926 转换成八进制的结果为 110076。
下图演示了将十进制数字 42 转换成二进制的过程: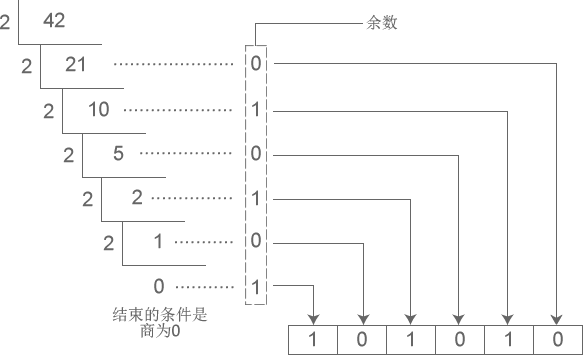
从图中得知,十进制数字 42 转换成二进制的结果为 101010。
2) 小数部分
十进制小数转换成 N 进制小数采用“乘 N 取整,顺序排列”法。具体做法是:
- 用 N 乘以十进制小数,可以得到一个积,这个积包含了整数部分和小数部分;
- 将积的整数部分取出,再用 N 乘以余下的小数部分,又得到一个新的积;
- 再将积的整数部分取出,继续用 N 乘以余下的小数部分;
- ……
- 如此反复进行,每次都取出整数部分,用 N 接着乘以小数部分,直到积中的小数部分为 0,或者达到所要求的精度为止。
把取出的整数部分按顺序排列起来,先取出的整数作为 N 进制小数的高位数字,后取出的整数作为低位数字,这样就得到了 N 进制小数。
下图演示了将十进制小数 0.930908203125 转换成八进制小数的过程: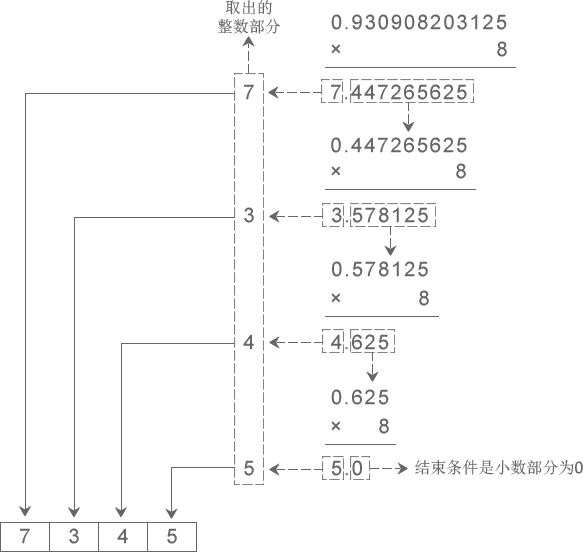
从图中得知,十进制小数 0.930908203125 转换成八进制小数的结果为 0.7345。
下图演示了将十进制小数 0.6875 转换成二进制小数的过程: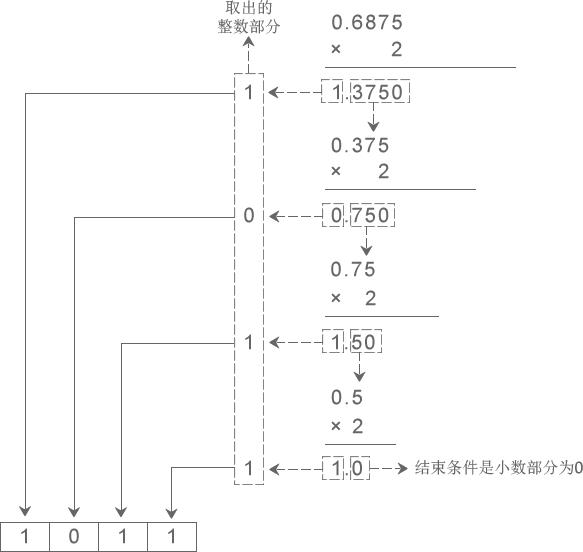
从图中得知,十进制小数 0.6875 转换成二进制小数的结果为 0.1011。
如果一个数字既包含了整数部分又包含了小数部分,那么将整数部分和小数部分开,分别按照上面的方法完成转换,然后再合并在一起即可。例如:
- 十进制数字 36926.930908203125 转换成八进制的结果为 110076.7345;
- 十进制数字 42.6875 转换成二进制的结果为 101010.1011。
下表列出了前 17 个十进制整数与二进制、八进制、十六进制的对应关系:
| 十进制 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 二进制 | 0 | 1 | 10 | 11 | 100 | 101 | 110 | 111 | 1000 | 1001 | 1010 | 1011 | 1100 | 1101 | 1110 | 1111 | 10000 |
| 八进制 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 20 |
| 十六进制 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | 10 |
注意,十进制小数转换成其他进制小数时,结果有可能是一个无限位的小数。请看下面的例子:
- 十进制 0.51 对应的二进制为 0.100000101000111101011100001010001111010111…,是一个循环小数;
- 十进制 0.72 对应的二进制为 0.1011100001010001111010111000010100011110…,是一个循环小数;
- 十进制 0.625 对应的二进制为 0.101,是一个有限小数。
二进制和八进制、十六进制的转换
其实,任何进制之间的转换都可以使用上面讲到的方法,只不过有时比较麻烦,所以一般针对不同的进制采取不同的方法。将二进制转换为八进制和十六进制时就有非常简洁的方法,反之亦然。1) 二进制整数和八进制整数之间的转换
二进制整数转换为八进制整数时,每三位二进制数字转换为一位八进制数字,运算的顺序是从低位向高位依次进行,高位不足三位用零补齐。下图演示了如何将二进制整数 1110111100 转换为八进制: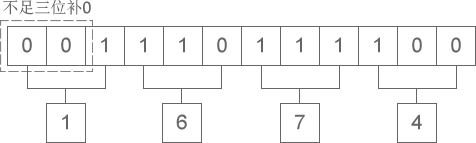
从图中可以看出,二进制整数 1110111100 转换为八进制的结果为 1674。
八进制整数转换为二进制整数时,思路是相反的,每一位八进制数字转换为三位二进制数字,运算的顺序也是从低位向高位依次进行。下图演示了如何将八进制整数 2743 转换为二进制: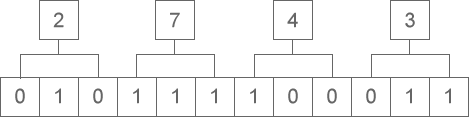
从图中可以看出,八进制整数 2743 转换为二进制的结果为 10111100011。
2) 二进制整数和十六进制整数之间的转换
二进制整数转换为十六进制整数时,每四位二进制数字转换为一位十六进制数字,运算的顺序是从低位向高位依次进行,高位不足四位用零补齐。下图演示了如何将二进制整数 10 1101 0101 1100 转换为十六进制: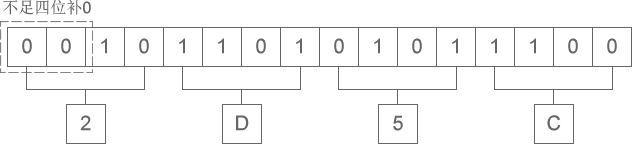
从图中可以看出,二进制整数 10 1101 0101 1100 转换为十六进制的结果为 2D5C。
十六进制整数转换为二进制整数时,思路是相反的,每一位十六进制数字转换为四位二进制数字,运算的顺序也是从低位向高位依次进行。下图演示了如何将十六进制整数 A5D6 转换为二进制:
从图中可以看出,十六进制整数 A5D6 转换为二进制的结果为 1010 0101 1101 0110。
在C语言编程中,二进制、八进制、十六进制之间几乎不会涉及小数的转换,所以这里我们只讲整数的转换,大家学以致用足以。另外,八进制和十六进制之间也极少直接转换,这里我们也不再讲解了。
总结
本节前面两部分讲到的转换方法是通用的,任何进制之间的转换都可以采用,只是有时比较麻烦而已。二进制和八进制、十六进制之间的转换有非常简洁的方法,所以没有采用前面的方法。
1.10 数据在内存中的存储
计算机要处理的信息是多种多样的,如数字、文字、符号、图形、音频、视频等,这些信息在人们的眼里是不同的。但对于计算机来说,它们在内存中都是一样的,都是以二进制的形式来表示。
要想学习编程,就必须了解二进制,它是计算机处理数据的基础。
内存条是一个非常精密的部件,包含了上亿个电子元器件,它们很小,达到了纳米级别。这些元器件,实际上就是电路;电路的电压会变化,要么是 0V,要么是 5V,只有这两种电压。5V 是通电,用1来表示,0V 是断电,用0来表示。所以,一个元器件有2种状态,0 或者 1。
我们通过电路来控制这些元器件的通断电,会得到很多0、1的组合。例如,8个元器件有 28=256 种不同的组合,16个元器件有 216=65536 种不同的组合。虽然一个元器件只能表示2个数值,但是多个结合起来就可以表示很多数值了。
我们可以给每一种组合赋予特定的含义,例如,可以分别用 1101000、00011100、11111111、00000000、01010101、10101010 来表示 小、马、学、编、程 这几个字,那么结合起来 1101000 00011100 11111111 00000000 01010101 10101010 就表示小马学编程。
一般情况下我们不一个一个的使用元器件,而是将8个元器件看做一个单位,即使表示很小的数,例如 1,也需要8个,也就是 00000001。
1个元器件称为1比特(Bit)或1位,8个元器件称为1字节(Byte),那么16个元器件就是2Byte,32个就是4Byte,以此类推:
- 8×1024个元器件就是1024Byte,简写为1KB;
- 8×1024×1024个元器件就是1024KB,简写为1MB;
- 8×1024×1024×1024个元器件就是1024MB,简写为1GB。
现在,你知道1GB的内存有多少个元器件了吧。我们通常所说的文件大小是多少 KB、多少 MB,就是这个意思。
单位换算:
- 1Byte = 8 Bit
- 1KB = 1024Byte = 210Byte
- 1MB = 1024KB = 220Byte
- 1GB = 1024MB = 230Byte
- 1TB = 1024GB = 240Byte
- 1PB = 1024TB = 250Byte
- 1EB = 1024PB = 260Byte
我们平时使用计算机时,通常只会设计到 KB、MB、GB、TB 这几个单位,PB 和 EB 这两个高级单位一般在大数据处理过程中才会用到。
你看,在内存中没有abc这样的字符,也没有gif、jpg这样的图片,只有0和1两个数字,计算机也只认识0和1。所以,计算机使用二进制,而不是我们熟悉的十进制,写入内存中的数据,都会被转换成0和1的组合。
我们将在《C语言调试》中的《查看、修改运行时的内存》一节教大家如何操作C语言程序的内存。
程序员的幽默
为了加深印象,最后给大家看个笑话。
程序员A:“哥们儿,最近手头紧,借点钱?”
程序员B:“成啊,要多少?”
程序员A:“一千行不?”
程序员B:“咱俩谁跟谁!给你凑个整,1024,拿去吧。”
你看懂这个笑话了吗?请选出正确答案。
A) 因为他同情程序员A,多给他24块
B) 这个程序员不会数数,可能是太穷饿晕了
C) 这个程序员故意的,因为他独裁的老婆规定1024是整数
D) 就像100是10的整数次方一样,1024是2的整数次方,对于程序员就是整数
1.11 载入内存,让程序运行起来
如果你的电脑上安装了QQ,你希望和好友聊天,会双击QQ图标,打开QQ软件,输入账号和密码,然后登录就可以了。
那么,QQ是怎么运行起来的呢?
首先,有一点你要明确,你安装的QQ软件是保存在硬盘中的。
双击QQ图标,操作系统就会知道你要运行这个软件,它会在硬盘中找到你安装的QQ软件,将数据(安装的软件本质上就是很多数据的集合)复制到内存。对!就是复制到内存!QQ不是在硬盘中运行的,而是在内存中运行的。
为什么呢?因为内存的读写速度比硬盘快很多。
对于读写速度,内存 > 固态硬盘 > 机械硬盘。
机械硬盘是靠电机带动盘片转动来读写数据的,而内存条通过电路来读写数据,电机的转速肯定没有电的传输速度(几乎是光速)快。虽然固态硬盘也是通过电路来读写数据,但是因为与内存的控制方式不一样,速度也不及内存。
所以,不管是运行QQ还是编辑Word文档,都是先将硬盘上的数据复制到内存,才能让CPU来处理,这个过程就叫作载入内存(Load into Memory)。完成这个过程需要一个特殊的程序(软件),这个程序就叫做加载器(Loader)。
CPU直接与内存打交道,它会读取内存中的数据进行处理,并将结果保存到内存。如果需要保存到硬盘,才会将内存中的数据复制到硬盘。
例如,打开Word文档,输入一些文字,虽然我们看到的不一样了,但是硬盘中的文档没有改变,新增的文字暂时保存到了内存,Ctrl+S才会保存到硬盘。因为内存断电后会丢失数据,所以如果你编辑完Word文档忘记保存就关机了,那么你将永远无法找回这些内容。(所谓的每隔2分钟或者10分钟自动备份,其实还是定时保存到了硬盘的意思。说白了就是软件帮你ctrl+s了)
虚拟内存
如果我们运行的程序较多,占用的空间就会超过内存(内存条)容量。例如计算机的内存容量为2G,却运行着10个程序,这10个程序共占用3G的空间,也就意味着需要从硬盘复制 3G 的数据到内存,这显然是不可能的。
操作系统(Operating System,简称 OS)为我们解决了这个问题:当程序运行需要的空间大于内存容量时,会将内存中暂时不用的数据再写回硬盘;需要这些数据时再从硬盘中读取,并将另外一部分不用的数据写入硬盘。这样,硬盘中就会有一部分空间用来存放内存中暂时不用的数据。这一部分空间就叫做虚拟内存(Virtual Memory)。
3G - 2G = 1G,上面的情况需要在硬盘上分配 1G 的虚拟内存。
硬盘的读写速度比内存慢很多,反复交换数据会消耗很多时间,所以如果你的内存太小,会严重影响计算机的运行速度,甚至会出现”卡死“现象,即使CPU强劲,也不会有大的改观。如果经济条件允许,建议将内存升级为 4G或8G,在 win7、win8、win10 下运行软件就会比较流畅了。目前的电脑8G已经成为标配,16G或者32G的内存配置也开始流行起来。
关于内存的更多知识,大家可以阅读《C语言内存精讲》,我敢保证你将会顿悟。
总结:CPU直接从内存中读取数据,处理完成后将结果再写入内存。

1.12 ASCII编码,将英文存储到计算机
前面我们已经讲到,计算机是以二进制的形式来存储数据的,它只认识 0 和 1 两个数字,我们在屏幕上看到的文字,在存储之前都被转换成了二进制(0和1序列),在显示时也要根据二进制找到对应的字符。
可想而知,特定的文字必然对应着固定的二进制,否则在转换时将发生混乱。那么,怎样将文字与二进制对应起来呢?这就需要有一套规范,计算机公司和软件开发者都必须遵守,这样的一套规范就称为字符集(Character Set)或者字符编码(Character Encoding)。
严格来说,字符集和字符编码不是一个概念,字符集定义了文字和二进制的对应关系,为字符分配了唯一的编号,而字符编码规定了如何将文字的编号存储到计算机中。我们暂时先不讨论这些细节,姑且认为它们是一个概念,本节中我也混用了这两个概念,未做区分。
字符集为每个字符分配一个唯一的编号,类似于学生的学号,通过编号就能够找到对应的字符。
可以将字符集理解成一个很大的表格,它列出了所有字符和二进制的对应关系,计算机显示文字或者存储文字,就是一个查表的过程。
在计算机逐步发展的过程中,先后出现了几十种甚至上百种字符集,有些还在使用,有些已经淹没在了历史的长河中,本节我们要讲解的是一种专门针对英文的字符集——ASCII编码。
拉丁字母(开胃小菜)
在正式介绍 ASCII 编码之前,我们先来说说什么是拉丁字母。估计也有不少读者和我一样,对于拉丁字母、英文字母和汉语拼音中的字母的关系不是很清楚。
拉丁字母也叫罗马字母,它源自希腊字母,是当今世界上使用最广的字母系统。基本的拉丁字母就是我们经常见到的 ABCD 等26个英文字母。
拉丁字母、阿拉伯字母、斯拉夫字母(西里尔字母)被称为世界三大字母体系。
拉丁字母原先是欧洲人使用的,后来由于欧洲殖民主义,导致这套字母体系在全球范围内开始流行,美洲、非洲、澳洲、亚洲都没有逃过西方文化的影响。中国也是,我们现在使用的拼音其实就是拉丁字母,是不折不扣的舶来品。
后来,很多国家对 26 个基本的拉丁字母进行了扩展,以适应本地的语言文化。最常见的扩展方式就是加上变音符号,例如汉语拼音中的ü,就是在u的基础上加上两个小点演化而来;再如,áà就是在a的上面标上音调。
总起来说:
- 基本拉丁字母就是 26 个英文字母;
- 扩展拉丁字母就是在基本的 26 个英文字母的基础上添加变音符号、横线、斜线等演化而来,每个国家都不一样。
ASCII 编码
计算机是美国人发明的,他们首先要考虑的问题是,如何将二进制和英文字母(也就是拉丁文)对应起来。
当时,各个厂家或者公司都有自己的做法,编码规则并不统一,这给不同计算机之间的数据交换带来不小的麻烦。但是相对来说,能够得到普遍认可的有 IBM 发明的 EBCDIC 和此处要谈的 ASCII。
我们先说 ASCII。ASCII 是“American Standard Code for Information Interchange”的缩写,翻译过来是“美国信息交换标准代码”。看这个名字就知道,这套编码是美国人给自己设计的,他们并没有考虑欧洲那些扩展的拉丁字母,也没有考虑韩语和日语,我大中华几万个汉字更是不可能被重视。
但这也无可厚非,美国人自己发明的计算机,当然要先解决自己的问题
ASCII 的标准版本于 1967 年第一次发布,最后一次更新则是在 1986 年,迄今为止共收录了 128 个字符,包含了基本的拉丁字母(英文字母)、阿拉伯数字(也就是 1234567890)、标点符号(,.!等)、特殊符号(@#$%^&等)以及一些具有控制功能的字符(往往不会显示出来)。
在 ASCII 编码中,大写字母、小写字母和阿拉伯数字都是连续分布的(见下表),这给程序设计带来了很大的方便。例如要判断一个字符是否是大写字母,就可以判断该字符的 ASCII 编码值是否在 65~90 的范围内。
EBCDIC 编码正好相反,它的英文字母不是连续排列的,中间出现了多次断续,给编程带来了一些困难。现在连 IBM 自己也不使用 EBCDIC 了,转而使用更加优秀的 ASCII。
ASCII 编码已经成了计算机的通用标准,没有人再使用 EBCDIC 编码了,它已经消失在历史的长河中了。
ASCII 编码一览表
标准 ASCII 编码共收录了 128 个字符,其中包含了 33 个控制字符(具有某些特殊功能但是无法显示的字符)和 95 个可显示字符。
完整的ASCII码对照表以及各个字符的解释
| 二进制 | 十进制 | 十六进制 | 字符/缩写 | 解释 |
|---|---|---|---|---|
| 00000000 | 0 | 00 | NUL (NULL) | 空字符 |
| 00000001 | 1 | 01 | SOH (Start Of Headling) | 标题开始 |
| 00000010 | 2 | 02 | STX (Start Of Text) | 正文开始 |
| 00000011 | 3 | 03 | ETX (End Of Text) | 正文结束 |
| 00000100 | 4 | 04 | EOT (End Of Transmission) | 传输结束 |
| 00000101 | 5 | 05 | ENQ (Enquiry) | 请求 |
| 00000110 | 6 | 06 | ACK (Acknowledge) | 回应/响应/收到通知 |
| 00000111 | 7 | 07 | BEL (Bell) | 响铃 |
| 00001000 | 8 | 08 | BS (Backspace) | 退格 |
| 00001001 | 9 | 09 | HT (Horizontal Tab) | 水平制表符 |
| 00001010 | 10 | 0A | LF/NL(Line Feed/New Line) | 换行键 |
| 00001011 | 11 | 0B | VT (Vertical Tab) | 垂直制表符 |
| 00001100 | 12 | 0C | FF/NP (Form Feed/New Page) | 换页键 |
| 00001101 | 13 | 0D | CR (Carriage Return) | 回车键 |
| 00001110 | 14 | 0E | SO (Shift Out) | 不用切换 |
| 00001111 | 15 | 0F | SI (Shift In) | 启用切换 |
| 00010000 | 16 | 10 | DLE (Data Link Escape) | 数据链路转义 |
| 00010001 | 17 | 11 | DC1/XON (Device Control 1/Transmission On) |
设备控制1/传输开始 |
| 00010010 | 18 | 12 | DC2 (Device Control 2) | 设备控制2 |
| 00010011 | 19 | 13 | DC3/XOFF (Device Control 3/Transmission Off) |
设备控制3/传输中断 |
| 00010100 | 20 | 14 | DC4 (Device Control 4) | 设备控制4 |
| 00010101 | 21 | 15 | NAK (Negative Acknowledge) | 无响应/非正常响应/拒绝接收 |
| 00010110 | 22 | 16 | SYN (Synchronous Idle) | 同步空闲 |
| 00010111 | 23 | 17 | ETB (End of Transmission Block) | 传输块结束/块传输终止 |
| 00011000 | 24 | 18 | CAN (Cancel) | 取消 |
| 00011001 | 25 | 19 | EM (End of Medium) | 已到介质末端/介质存储已满/介质中断 |
| 00011010 | 26 | 1A | SUB (Substitute) | 替补/替换 |
| 00011011 | 27 | 1B | ESC (Escape) | 逃离/取消 |
| 00011100 | 28 | 1C | FS (File Separator) | 文件分割符 |
| 00011101 | 29 | 1D | GS (Group Separator) | 组分隔符/分组符 |
| 00011110 | 30 | 1E | RS (Record Separator) | 记录分离符 |
| 00011111 | 31 | 1F | US (Unit Separator) | 单元分隔符 |
| 00100000 | 32 | 20 | (Space) | 空格 |
| 00100001 | 33 | 21 | ! | |
| 00100010 | 34 | 22 | “ | |
| 00100011 | 35 | 23 | # | |
| 00100100 | 36 | 24 | $ | |
| 00100101 | 37 | 25 | % | |
| 00100110 | 38 | 26 | & | |
| 00100111 | 39 | 27 | ‘ | |
| 00101000 | 40 | 28 | ( | |
| 00101001 | 41 | 29 | ) | |
| 00101010 | 42 | 2A | * | |
| 00101011 | 43 | 2B | + | |
| 00101100 | 44 | 2C | , | |
| 00101101 | 45 | 2D | - | |
| 00101110 | 46 | 2E | . | |
| 00101111 | 47 | 2F | / | |
| 00110000 | 48 | 30 | 0 | |
| 00110001 | 49 | 31 | 1 | |
| 00110010 | 50 | 32 | 2 | |
| 00110011 | 51 | 33 | 3 | |
| 00110100 | 52 | 34 | 4 | |
| 00110101 | 53 | 35 | 5 | |
| 00110110 | 54 | 36 | 6 | |
| 00110111 | 55 | 37 | 7 | |
| 00111000 | 56 | 38 | 8 | |
| 00111001 | 57 | 39 | 9 | |
| 00111010 | 58 | 3A | : | |
| 00111011 | 59 | 3B | ; | |
| 00111100 | 60 | 3C | < | |
| 00111101 | 61 | 3D | = | |
| 00111110 | 62 | 3E | > | |
| 00111111 | 63 | 3F | ? | |
| 01000000 | 64 | 40 | @ | |
| 01000001 | 65 | 41 | A | |
| 01000010 | 66 | 42 | B | |
| 01000011 | 67 | 43 | C | |
| 01000100 | 68 | 44 | D | |
| 01000101 | 69 | 45 | E | |
| 01000110 | 70 | 46 | F | |
| 01000111 | 71 | 47 | G | |
| 01001000 | 72 | 48 | H | |
| 01001001 | 73 | 49 | I | |
| 01001010 | 74 | 4A | J | |
| 01001011 | 75 | 4B | K | |
| 01001100 | 76 | 4C | L | |
| 01001101 | 77 | 4D | M | |
| 01001110 | 78 | 4E | N | |
| 01001111 | 79 | 4F | O | |
| 01010000 | 80 | 50 | P | |
| 01010001 | 81 | 51 | Q | |
| 01010010 | 82 | 52 | R | |
| 01010011 | 83 | 53 | S | |
| 01010100 | 84 | 54 | T | |
| 01010101 | 85 | 55 | U | |
| 01010110 | 86 | 56 | V | |
| 01010111 | 87 | 57 | W | |
| 01011000 | 88 | 58 | X | |
| 01011001 | 89 | 59 | Y | |
| 01011010 | 90 | 5A | Z | |
| 01011011 | 91 | 5B | [ | |
| 01011100 | 92 | 5C | \ | |
| 01011101 | 93 | 5D | ] | |
| 01011110 | 94 | 5E | ^ | |
| 01011111 | 95 | 5F | _ | |
| 01100000 | 96 | 60 | ` | |
| 01100001 | 97 | 61 | a | |
| 01100010 | 98 | 62 | b | |
| 01100011 | 99 | 63 | c | |
| 01100100 | 100 | 64 | d | |
| 01100101 | 101 | 65 | e | |
| 01100110 | 102 | 66 | f | |
| 01100111 | 103 | 67 | g | |
| 01101000 | 104 | 68 | h | |
| 01101001 | 105 | 69 | i | |
| 01101010 | 106 | 6A | j | |
| 01101011 | 107 | 6B | k | |
| 01101100 | 108 | 6C | l | |
| 01101101 | 109 | 6D | m | |
| 01101110 | 110 | 6E | n | |
| 01101111 | 111 | 6F | o | |
| 01110000 | 112 | 70 | p | |
| 01110001 | 113 | 71 | q | |
| 01110010 | 114 | 72 | r | |
| 01110011 | 115 | 73 | s | |
| 01110100 | 116 | 74 | t | |
| 01110101 | 117 | 75 | u | |
| 01110110 | 118 | 76 | v | |
| 01110111 | 119 | 77 | w | |
| 01111000 | 120 | 78 | x | |
| 01111001 | 121 | 79 | y | |
| 01111010 | 122 | 7A | z | |
| 01111011 | 123 | 7B | { | |
| 01111100 | 124 | 7C | | | |
| 01111101 | 125 | 7D | } | |
| 01111110 | 126 | 7E | ~ | |
| 01111111 | 127 | 7F | DEL (Delete) | 删除 |
上表列出的是标准的 ASCII 编码,它共收录了 128 个字符,用一个字节中较低的 7 个比特位(Bit)足以表示(27 = 128),所以还会空闲下一个比特位,它就被浪费了。
如果您还想了解每个控制字符的含义,请转到:完整的ASCII码对照表以及各个字符的解释
ASCII 编码和C语言
稍微有点C语言基本功的读者可能认为C语言使用的就是 ASCII 编码,字符在存储时会转换成对应的 ASCII 码值,在读取时也是根据 ASCII 码找到对应的字符。这句话是错误的,严格来说,你可能被大学老师和C语言教材给误导了。
C语言有时候使用 ASCII 编码,有时候却不是,而是使用后面两节中即将讲到的 GBK 编码和 Unicode 字符集,我们将在《C语言到底使用什么编码?谁说C语言使用ASCII码,真是荒谬!》一节中展开讲解。
1.13 GB2312编码和GBK编码,将中文存储到计算机
计算机是一种改变世界的发明,很快就从美国传到了全球各地,得到了所有国家的认可,成为了一种不可替代的工具。计算机在广泛流行的过程中遇到的一个棘手问题就是字符编码,计算机是美国人发明的,它使用的是 ASCII 编码,只能显示英文字符,对汉语、韩语、日语、法语、德语等其它国家的字符无能为力。
为了让本国公民也能使用上计算机,各个国家(地区)也开始效仿 ASCII,开发了自己的字符编码。这些字符编码和 ASCII 一样,只考虑本国的语言文化,不兼容其它国家的文字。这样做的后果就是,一台计算机上必须安装多套字符编码,否则就不能正确地跨国传递数据,例如在中国编写的文本文件,拿到日本的电脑上就无法打开,或者打开后是一堆乱码。
下表列出了常见的字符编码:
| 字符编码 | 说明 |
|---|---|
| ISO/IEC 8859 | 欧洲字符集,支持丹麦语、荷兰语、德语、意大利语、拉丁语、挪威语、葡萄牙语、西班牙语,瑞典语等,1987 年首次发布。 |
ASCII 编码只包含了本的拉丁字母,没有包含欧洲很多国家所用到的一些扩展的拉丁字母,比如一些重音字母,带音标的字母等,ISO/IEC 8859 主要是在 ASCII 的础上增加了这些衍生的拉丁字母。 | | Shift_Jis | 日语字符集,包含了全角及半角拉丁字母、平假名、片假名、符号及日语汉字,1978 年首次发布。 | | Big5 | 繁体中文字符集,1984 年发布,通行于台湾、香港等地区,收录了 13053 个中文字、408个普通字符以及 33 个控制字符。 | | GB2312 | 简体中文字符集,1980 年发布,共收录了 6763 个汉字,其中一级汉字 3755 个,二级汉字 3008 个;同时收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的 682 个字符。 | | GBK | 中文字符集,是在 GB2312 的*础上进行的扩展,1995 年发布。
GB2312 收录的汉字虽然覆盖了中国大陆 99.75% 的使用频率,满足了本的输入输出要求,但是对于人名、古汉语等方面出现的罕用字(例如**的“*”就没有被 GB2312 收录),GB2312 并不能处理,所以后来又对 GBK 进行了一次扩展,形成了一种新的字符集,就是 GBK。
GBK 共收录了 21886 个汉字和图形符号,包括 GB2312 中的全部汉字、非汉字符号,以及 BIG5 中的全部繁体字,还有一些生僻字。 | | GB18030 | 中文字符集,是对 GBK 和 GB2312 的又一次扩展,2000 年发布。
GB18030 共收录 70244 个汉字,支持中国国内少数民族的文字,以及日语韩语中的汉字。 |
由于 ASCII 先入为主,已经使用了十来年了,现有的很多软件和文档都是于 ASCII 的,所以后来的这些字符编码都是在 ASCII 础上进行的扩展,它们都兼容 ASCII,以支持既有的软件和文档。
兼容 ASCII 的含义是,原来 ASCII 中已经包含的字符,在国家编码(地区编码)中的位置不变(也就是编码值不变),只是在这些字符的后面增添了新的字符。
如何存储
标准 ASCII 编码共包含了 128 个字符,用一个字节就足以存储(实际上是用一个字节中较低的 7 位来存储),而日文、中文、韩文等包含的字符非常多,有成千上万个,一个字节肯定是不够的(一个字节最多存储 28 = 256 个字符),所以要进行扩展,用两个、三个甚至四个字节来表示。
在制定字符编码时还要考虑内存利用率的问题。我们经常使用的字符,其编码值一般都比较小,例如字母和数字都是 ASCII 编码,其编码值不会超过 127,用一个字节存储足以,如果硬要用多个字节存储,就会浪费很多内存空间。
为了达到「既能存储本国字符,又能节省内存」的目的,Shift-Jis、Big5、GB2312 等都采用变长的编码方式:
- 对于原来的 ASCII 编码部分,用一个字节存储足以;
- 对于本国的常用字符(例如汉字、标点符号等),一般用两个字节存储;
- 对于偏远地区,或者极少使用的字符(例如藏文、蒙古文等),才使用三个甚至四个字节存储。
总起来说,越常用的字符占用的内存越少,越罕见的字符占用的内存越多。
具体讲一下中文编码方案
GB2312 —> GBK —> GB18030 是中文编码的三套方案,出现的时间从早到晚,收录的字符数目依次增加,并且向下兼容。GB2312 和 GBK 收录的字符数目较少,用 1~2个字节存储;GB18030 收录的字符最多,用1、2、4 个字节存储。
1) 从整体上讲,GB2312 和 GBK 的编码方式一致,具体为:
- 对于 ASCII 字符,使用一个字节存储,并且该字节的最高位是 0,这和 ASCII 编码是一致的,所以说 GB2312 完全兼容 ASCII。
- 对于中国的字符,使用两个字节存储,并且规定每个字节的最高位都是 1。
例如对于字母A,它在内存中存储为 01000001;对于汉字中,它在内存中存储为 11010110 11010000。由于单字节和双字节的最高位不一样,所以字符处理软件很容易区分一个字符到底用了几个字节。
2) GB18030 为了容纳更多的字符,并且要区分两个字节和四个字节,所以修改了编码方案,具体为:
- 对于 ASCII 字符,使用一个字节存储,并且该字节的最高位是 0,这和 ASCII、GB2312、GBK 编码是一致的。
- 对于常用的中文字符,使用两个字节存储,并且规定第一个字节的最高位是 1,第二个字节的高位最多只能有一个连续的 0(第二个字节的最高位可以是 1 也可以是 0,但是当它是 0 时,次高位就不能是 0 了)。注意对比 GB2312 和 GBK,它们要求两个字节的最高位为都必须为 1。
- 对于罕见的字符,使用四个字节存储,并且规定第一个和第三个字节的最高位是 1,第二个和第四个字节的高位必须有两个连续的 0。
例如对于字母A,它在内存中存储为 01000001;对于汉字中,它在内存中存储为 11010110 11010000;对于藏文གྱུ,它在内存中的存储为 10000001 00110010 11101111 00110000。
字符处理软件在处理文本时,从左往右依次扫描每个字节:
- 如果遇到的字节的最高位是 0,那么就会断定该字符只占用了一个字节;
- 如果遇到的字节的最高位是 1,那么该字符可能占用了两个字节,也可能占用了四个字节,不能妄下断论,所以还要继续往后扫描:
- 如果第二个字节的高位有两个连续的 0,那么就会断定该字符占用了四个字节;
- 如果第二个字节的高位没有连续的 0,那么就会断定该字符占用了两个字节。
可见,当字符占用两个或者四个字节时,GB18030 编码要检测两次,处理效率比 GB2312 和 GBK 都低。
GBK 编码牛批
GBK 于 1995 年发布,这一年也是互联网爆发的元年,国人使用电脑越来越多,也许是 GBK 这头猪正好站在风口上,它就飞起来了,后来的中文版 Windows 都将 GBK 作为默认的中文编码方案。
注意,这里我说 GBK 是默认的中文编码方案,并没有说 Windows 默认支持 GBK。Windows 在内核层面使用的是 Unicode 字符集(严格来说是 UTF-16 编码),但是它也给用户留出了选择的余地,如果用户不希望使用 Unicode,而是希望使用中文编码方案,那么这个时候 Windows 默认使用 GBK(当然,你可以选择使用 GB2312 或者 GB18030,不过一般没有这个必要)。
1.14 Unicode字符集,将全世界的文字存储到计算机
Unicode 也称为统一码、万国码;看名字就知道,Unicode 希望统一所有国家的字符编码。
Unicode 于 1994 年正式公布第一个版本,现在的规模可以容纳 100 多万个符号,是一个很大的集合。
有兴趣的读取可以转到 https://unicode-table.com/cn/ 查看 Unicode 包含的所有字符,以及各个国家的字符是如何分布的。
Windows、Linux、Mac OS 等常见操作系统都已经从底层(内核层面)开始支持 Unicode,大部分的网页和软件也使用 Unicode,Unicode 是大势所趋。
不过由于历史原因,目前的计算机仍然安装了 ASCII 编码以及 GB2312、GBK、Big5、Shift-JIS 等地区编码,以支持不使用 Unicode 的软件或者文档。内核在处理字符时,一般会将地区编码先转换为 Unicode,再进行下一步处理。
Unicode 字符集是如何存储的
本节我们多次说 Unicode 是一套字符集,而不是一套字符编码,它们之间究竟有什么区别呢?
严格来说,字符集和字符编码不是一个概念:
- 字符集定义了字符和二进制的对应关系,为每个字符分配了唯一的编号。可以将字符集理解成一个很大的表格,它列出了所有字符和二进制的对应关系,计算机显示文字或者存储文字,就是一个查表的过程。
- 而字符编码规定了如何将字符的编号存储到计算机中。如果使用了类似 GB2312 和 GBK 的变长存储方案(不同的字符占用的字节数不一样),那么为了区分一个字符到底使用了几个字节,就不能将字符的编号直接存储到计算机中,字符编号在存储之前必须要经过转换,在读取时还要再逆向转换一次,这套转换方案就叫做字符编码。
有的字符集在制定时就考虑到了编码的问题,是和编码结合在一起的,例如 ASCII、GB2312、GBK、BIG5 等,所以无论称作字符集还是字符编码都无所谓,也不好区分两者的概念。而有的字符集只管制定字符的编号,至于怎么存储,那是字符编码的事情,Unicode 就是一个典型的例子,它只是定义了全球文字的唯一编号,我们还需要 UTF-8、UTF-16、UTF-32 这几种编码方案将 Unicode 存储到计算机中。
Unicode 可以使用的编码方案有三种,分别是:
- UTF-8:一种变长的编码方案,使用 1~6 个字节来存储;
- UTF-32:一种固定长度的编码方案,不管字符编号大小,始终使用 4 个字节来存储;
- UTF-16:介于 UTF-8 和 UTF-32 之间,使用 2 个或者 4 个字节来存储,长度既固定又可变。
UTF 是 Unicode Transformation Format 的缩写,意思是“Unicode转换格式”,后面的数字表明至少使用多少个比特位(Bit)来存储字符。
1) UTF-8
UTF-8 的编码规则很简单:
- 如果只有一个字节,那么最高的比特位为 0,这样可以兼容 ASCII;
- 如果有多个字节,那么第一个字节从最高位开始,连续有几个比特位的值为 1,就使用几个字节编码,剩下的字节均以 10 开头。
具体的表现形式为:
- 0xxxxxxx:单字节编码形式,这和 ASCII 编码完全一样,因此 UTF-8 是兼容 ASCII 的;
- 110xxxxx 10xxxxxx:双字节编码形式(第一个字节有两个连续的 1);
- 1110xxxx 10xxxxxx 10xxxxxx:三字节编码形式(第一个字节有三个连续的 1);
- 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx:四字节编码形式(第一个字节有四个连续的 1)。
xxx 就用来存储 Unicode 中的字符编号。
下面是一些字符的 UTF-8 编码实例(绿色部分表示本来的 Unicode 编号):
| 字符 | 字母N | 符号æ | 中文⻬ |
|---|---|---|---|
| Unicode 编号(二进制) | 01001110 | 11100110 | 00101110 11101100 |
| Unicode 编号(十六进制) | 4E | E6 | 2E EC |
| UTF-8 编码(二进制) | 01001110 | 11000011 10100110 | 11100010 10111011 10101100 |
| UTF-8 编码(十六进制) | 4E | C3 A6 | E2 BB AC |
对于常用的字符,它的 Unicode 编号范围是 0 ~ FFFF,用 1~3 个字节足以存储,只有及其罕见,或者只有少数地区使用的字符才需要 4~6个字节存储。
2) UTF-32
UTF-32 是固定长度的编码,始终占用 4 个字节,足以容纳所有的 Unicode 字符,所以直接存储 Unicode 编号即可,不需要任何编码转换。浪费了空间,提高了效率。
3) UTF-16
UFT-16 比较奇葩,它使用 2 个或者 4 个字节来存储。
对于 Unicode 编号范围在 0 ~ FFFF 之间的字符,UTF-16 使用两个字节存储,并且直接存储 Unicode 编号,不用进行编码转换,这跟 UTF-32 非常类似。
对于 Unicode 编号范围在 10000~10FFFF 之间的字符,UTF-16 使用四个字节存储,具体来说就是:将字符编号的所有比特位分成两部分,较高的一些比特位用一个值介于 D800~DBFF 之间的双字节存储,较低的一些比特位(剩下的比特位)用一个值介于 DC00~DFFF 之间的双字节存储。
如果你不理解什么意思,请看下面的表格:
| Unicode 编号范围 (十六进制) |
具体的 Unicode 编号 (二进制) |
UTF-16 编码 | 编码后的 字节数 |
|---|---|---|---|
| 0000 0000 ~ 0000 FFFF | xxxxxxxx xxxxxxxx | xxxxxxxx xxxxxxxx | 2 |
| 0001 0000—-0010 FFFF | yyyy yyyy yyxx xxxx xxxx | 110110yy yyyyyyyy 110111xx xxxxxxxx | 4 |
位于 D800~0xDFFF 之间的 Unicode 编码是特别为四字节的 UTF-16 编码预留的,所以不应该在这个范围内指定任何字符。如果你真的去查看 Unicode 字符集,会发现这个区间内确实没有收录任何字符。
UTF-16 要求在制定 Unicode 字符集时必须考虑到编码问题,所以真正的 Unicode 字符集也不是随意编排字符的。
对比以上三种编码方案
首先,只有 UTF-8 兼容 ASCII,UTF-32 和 UTF-16 都不兼容 ASCII,因为它们没有单字节编码。
1) UTF-8 使用尽量少的字节来存储一个字符,不但能够节省存储空间,而且在网络传输时也能节省流量,所以很多纯文本类型的文件(例如各种编程语言的源文件、各种日志文件和配置文件等)以及绝大多数的网页(例如百度、新浪、163等)都采用 UTF-8 编码。
UTF-8 的缺点是效率低,不但在存储和读取时都要经过转换,而且在处理字符串时也非常麻烦。例如,要在一个 UTF-8 编码的字符串中找到第 10 个字符,就得从头开始一个一个地检索字符,这是一个很耗时的过程,因为 UTF-8 编码的字符串中每个字符占用的字节数不一样,如果不从头遍历每个字符,就不知道第 10 个字符位于第几个字节处,就无法定位。
不过,随着算法的逐年精进,UTF-8 字符串的定位效率也越来越高了,往往不再是槽点了。
2) UTF-32 是“以空间换效率”,正好弥补了 UTF-8 的缺点,UTF-32 的优势就是效率高:UTF-32 在存储和读取字符时不需要任何转换,在处理字符串时也能最快速地定位字符。例如,在一个 UTF-32 编码的字符串中查找第 10 个字符,很容易计算出它位于第 37 个字节处,直接获取就行,不用再逐个遍历字符了,没有比这更快的定位字符的方法了。
但是,UTF-32 的缺点也很明显,就是太占用存储空间了,在网络传输时也会消耗很多流量。我们平常使用的字符编码值一般都比较小,用一两个字节存储足以,用四个字节简直是暴殄天物,甚至说是不能容忍的,所以 UTF-32 在应用上不如 UTF-8 和 UTF-16 广泛。
3) UTF-16 可以看做是 UTF-8 和 UTF-32 的折中方案,它平衡了存储空间和处理效率的矛盾。对于常用的字符,用两个字节存储足以,这个时候 UTF-16 是不需要转换的,直接存储字符的编码值即可。
Windows 内核、.NET Framework、Cocoa、Java String 内部采用的都是 UTF-16 编码。UTF-16 是幕后的功臣,我们在编辑源代码和文档时都是站在前台,所以一般感受不到,其实很多文本在后台处理时都已经转换成了 UTF-16 编码。
不过,UNIX 家族的操作系统(Linux、Mac OS、iOS 等)内核都采用 UTF-8 编码,我们就不去争论谁好谁坏了。
宽字符和窄字符(多字节字符)
有的编码方式采用 1~n 个字节存储,是变长的,例如 UTF-8、GB2312、GBK 等;如果一个字符使用了这种编码方式,我们就将它称为多字节字符,或者窄字符。
有的编码方式是固定长度的,不管字符编号大小,始终采用 n 个字节存储,例如 UTF-32、UTF-16 等;如果一个字符使用了这种编码方式,我们就将它称为宽字符。
Unicode 字符集可以使用窄字符的方式存储,也可以使用宽字符的方式存储;GB2312、GBK、Shift-JIS 等国家编码一般都使用窄字符的方式存储;ASCII 只有一个字节,无所谓窄字符和宽字符。

若有收获,就点个赞吧
0 人点赞
