必要性
流处理框架的重要性自不待言。在需要低延迟更新的大数据处理中经常用到。
流处理在低延迟和高吞吐之外,还应该能保证准确和容错。
演变过程
Storm:低延迟的流处理,但是高吞吐和正确性有所欠缺。能保证正确性就需要极大的开销。
↓
Lambda框架:将Storm和MapReduce结合。MapReduce提供有延迟但准确的结果,Storm提供最新数据的初步展示。但是两个方法之间有延迟,Storm出错到MapReduce出结果的期间只能获取错误结果。而且批量处理系统与流处理系统有两套代码库,维护不便。
↓
Spark Streaming:Spark中的近似流处理方法,能保证正确性。将作业分割为极小的子作业,这样并发起来就和流处理差不多。虽然不可能真正实时,但延迟会变得很小。但是这样要求完成批处理和新数据到来的时间必须紧密耦合,否则会出现不一致的结果。并且这种实现方式在优化时会很艰难。
↓
Flink:功能齐全的流处理框架,而不需要付出额外的消耗。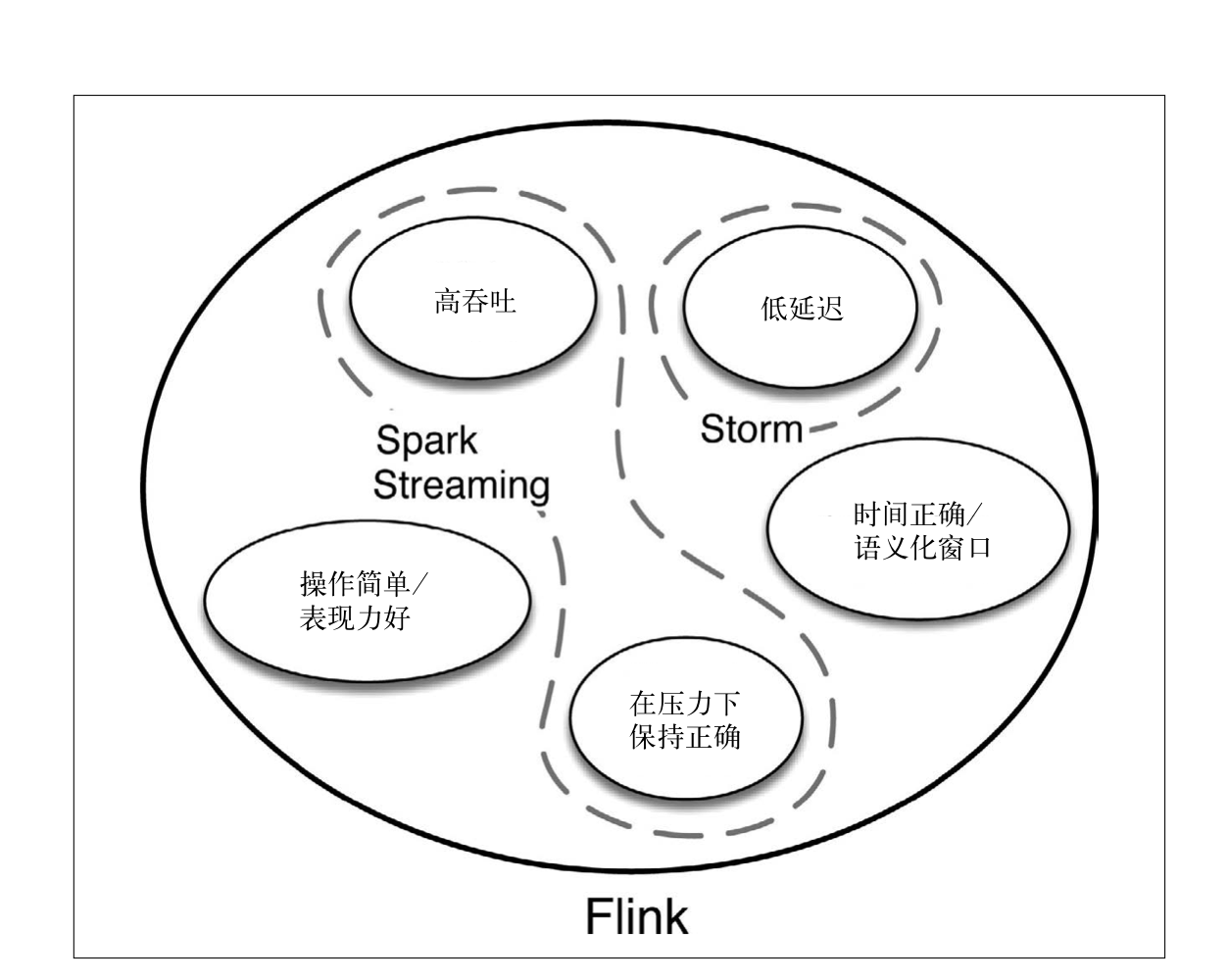

若有收获,就点个赞吧
0 人点赞
