题目:无重复字符的最长子串
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: "abcabcbb"输出: 3解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例 2:
输入: "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例 3:
输入: "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
思路分析:
遍历这个字符串,然后我得保存每次得到的不重复字符串,记录长度最大值。
首先 int max = 0; 记录最大值
然后我需要记录字符串,那么可以使用两个指针来代表字符串的两头,一个i一个j,最开始的时候i和j指向第一个元素,然后i往后移,把扫描过的元素都放到map中,如果i扫描过的元素没有重复的就一直往后移,顺便记录一下最大值max,如果i扫描过的元素有重复的,就改变j的位置,我们就以pwwkew为例画个图看一下
i继续往右移动,碰到重复元素后j再次移动到之前重复字符的下一位 (注意,这里并不是移动到重复字符的下标,因为这里要求的是无重复字符),以此类推,每次移动的时候都校对一次最大值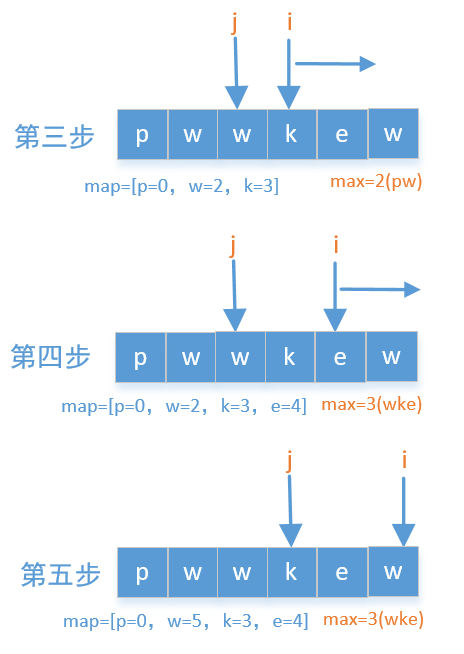
那么如何来判断是否出现重复字符呢???我们可以使用hashmap来解决这个问题。每当新的字符已经hashmap中,那么用新字符创建一个hashmap继续遍历,同时将之前的hashmap长度记录下来,与前前次的hashmap长度做比较,取最大值,此题可解。
Java解法一:双指针标记法
/**
* 双指针标记法
* @param s
* @return
*/
public static int lengthOfLongestSubstring(String s) {
// 记录最大值
int max = 0;
// 入参校验
if (s == null || s.length() == 0)
return max;
HashMap<Character, Integer> map = new HashMap<>();
for (int i = 0, j = 0; i < s.length(); ++i) {
// 如果map中有重复字符,将j移动到之前字符下标+1的位置,重新计算长度
if (map.containsKey(s.charAt(i))) {
j = Math.max(j, map.get(s.charAt(i)) + 1);
}
// 存入字符和最新下标
map.put(s.charAt(i), i);
// 求出最大长度
max = Math.max(max, i - j + 1);
}
return max;
}
复杂度分析:
- 时间复杂度:O(N),其中 N 是字符串的长度。i指针会遍历整个字符串N次,所以是O(N)。
- 空间复杂度:O(∣Σ∣),其中Σ 表示字符集(即字符串中可以出现的字符),∣Σ∣ 表示字符集的大小。在本题中没有明确说明字符集,因此可以默认为所有 ASCII 码在[0,128) 内的字符,即∣Σ∣ = 128。我们需要用到哈希集合来存储出现过的字符,而字符最多有 ∣Σ∣ 个,因此空间复杂度为O(∣Σ∣)。
LeetCode用时:

Java解法一优化:数组代替map (性能最佳)
由于都是字符,所以我们还可以使用数组来代替map
/**
* 双指针标记法(数组)
* @param s
* @return
*/
public static int lengthOfLongestSubstring11(String s) {
// ASCII 的取值范围为 0到127,所以我们需要一个大小为128的数组
int[] array = new int[128];
int max = 0;
for (int i = 0, j = 0; i < s.length(); ++i) {
// 如果map中有重复字符,将j移动到之前字符下标+1的位置(这里j不需要+1了,因为之前春如的时候已经+1),重新计算长度
if (array[s.charAt(i)] != 0) {
j = Math.max(j, array[s.charAt(i)]);
}
// 存入字符和新的下标 这里下标要+1,因为数组的默认值是0
array[s.charAt(i)] = i+1;
// 求出最大长度, 这里依然要加1,因为i和j有可能在同一个位置,此时长度为1
max = Math.max(max, i - j + 1);
}
return max;
}
复杂度分析:
LeetCode用时:
由于用数组代替了hashmap简化了储存结构,整体性能得到极大的优化,缺点是ASCII不支吃中文等特殊字符
Java解法二:特征法(LeetCode官方滑动窗口法)
我们换一种思路,我们要找一个最长无重复的字符串,会有那些特征?
最长字符串首先必须有左端点,假设一个字符串为pwwkew
那么他的左端点可能在 p-w-w-k-e-w 中的任意一个字符开始
所以我们只需要找到每种左端点开始的最长字符串,然后比较他们的大小即可
- 以 (**p**)wwkew 作为左端点的最长无重复字符串为 (**pw**)wkew; 2
- 以 p(**w**)wkew 作为左端点的最长无重复字符串为 p(**w**)wkew; 1
- 以 pw(**w**)kew 作为左端点的最长无重复字符串为 pw(**w)kew**; 1
- 以 pww(**k**)ew 作为左端点的最长无重复字符串为 pww(**kew**); 3
- 以 pwwk(**e**)w 作为左端点的最长无重复字符串为 pwwk(**ew**); 2
- 以 pwwke(**w**) 作为左端点的最长无重复字符串为 pwwke(**w**); 1
这个过程有点像是在滑动窗口,从开始一直滑动到最后 (**pw) -> (w) ->(w)->(kew)->(ew)->(w),所以我们需要一个结构来充当这个滑动窗口,HashSet就是一个很好的选择,同时他的hash算法可以帮我们判断是否出现重复的字符。然后我们需要一个指针i来记录每次左端点的下标,需要一个j**来标识右端点,最终代码如下:
/**
* 特征法(滑动窗口法)
* @param s
* @return
*/
public static int lengthOfLongestSubstring(String s) {
// 记录最大值
int max = 0;
// 入参校验
if (s == null || s.length() == 0)
return max;
Set<Character> set = new HashSet<Character>();
int length = s.length();
// 右指针j,初始值为 0
int j = 0;
for (int i = 0; i < length; ++i) {
if (i != 0) {
// 每当左指针向右移动一格,移除前一个字符
set.remove(s.charAt(i - 1));
}
// 如果不存在重复选项
while (j < length && !set.contains(s.charAt(j))) {
// 则不断地移动右指针,在后面添加一个字符
set.add(s.charAt(j));
++j;
}
// 第 i 到 j 个字符是一个极长的无重复字符子串,需要注意的是这里max里的j-i不需要进行+1操作,因为每次while过后j都会自增
max = Math.max(max, j - i);
}
return max;
}
复杂度分析:
- 时间复杂度:O(N),其中 N 是字符串的长度。其中 N 是字符串的长度。左指针和右指针分别会遍历整个字符串一次。
- 空间复杂度:O(∣Σ∣),其中Σ 表示字符集(即字符串中可以出现的字符),∣Σ∣ 表示字符集的大小。在本题中没有明确说明字符集,因此可以默认为所有 ASCII 码在[0,128) 内的字符,即∣Σ∣ = 128。我们需要用到哈希集合来存储出现过的字符,而字符最多有 ∣Σ∣ 个,因此空间复杂度为O(∣Σ∣)。
LeetCode用时:
这种方法的右指针遍历次数较多,所以性能比上一个方法来说差了一点
Java解法三:双边队列法
由上一种解法的思路,我们联想到可以使用双边队列来解决这个问题。
我们把元素不停的加入到队列中,如果有相同的元素,就把队首的元素移除,这样我们就可以保证队列中永远都没有重复的元素,同样用pwwkew 距离,如图所示:

经过两次入队,现在的字符串为pw,当出现重复字符w时,保存当前的字符串w,依次将之前的字符串出队直到之前的重复字符出队为止
代码如下:
/**
* 使用双端队列来实现
* @param s
* @return
*/
public static int lengthOfLongestSubstring3(String s) {
// 记录最大值
int max = 0;
// 入参校验
if (s == null || s.length() == 0)
return max;
Queue<Character> queue = new LinkedList<>();
for (char c : s.toCharArray()) {
// 链表的遍历性能是很差的
while (queue.contains(c)) {
//如果有重复的,则一直从头部取出,清除队列内的重复字符,重新开始记录一段字符串
queue.poll();
}
//添加到队尾
queue.add(c);
max = Math.max(max, queue.size());
}
return max;
}
复杂度分析:
- 时间复杂度:O(N)O(x),其中 N 是字符串的长度。其中 N 是字符串的长度,左指针会遍历整个字符串一次,而链表的contain会遍历整条链表,每次链表发生变化时遍历次数都会变化,不清楚咋算暂定为x
- 空间复杂度:O(∣Σ∣),其中Σ 表示字符集(即字符串中可以出现的字符),∣Σ∣ 表示字符集的大小。在本题中没有明确说明字符集,因此可以默认为所有 ASCII 码在[0,128) 内的字符,即∣Σ∣ = 128。我们需要用到哈希集合来存储出现过的字符,而字符最多有 ∣Σ∣ 个,因此空间复杂度为O(∣Σ∣)。
LeetCode用时:
由于链表查询性能低,contain会遍历整条链表,所以性能上是最差的

若有收获,就点个赞吧
0 人点赞
