社交 Web 应用允许用户之间相互联系。不同的应用以不同的名称称呼这样的关系,例如关注者、好友、联系人、联络人、伙伴或粉丝。不管使用什么名称,其功能都是一样的,都要记录两个用户之间的定向联系,在数据库查询中也要使用这种关系。
在本文,将介绍如何在 Flasky 中实现关注功能,让用户 “关注” 其他用户,并在首页只显示关注用户发布的博客文章列表。
再论数据库关系
数据库使用关系建立记录之间的联系。其中,一对多关系是最常见的关系类型,它把一个记录和一组相关的记录联系在一起。实现这种关系时,要在 “多” 这一侧加入一个外键,指向 “一” 这一侧的连接的记录。
多数其它关系类型都可以从一对多类型中衍生。多对一关系从 “多” 这一侧看,就是一对多关系。一对一关系是简化版的一对多关系,限制 “多” 这一侧最多只能有一个记录。唯一不能从一对多关系中简单演化出来的类型就是多对多关系,这种关系的两侧都有多个记录。
多对多关系
一对多关系,多对一关系和一对一关系至少都有一侧是单个实体,所以记录之间得了联系通过外键实现,让外键指向那个实体。但是,两侧都是 “多” 的关系应如何实现呢?
下面以一个典型的多对多关系为例,即一个记录学生和他们所选课程的数据库。很显然,你不能在学生表中加入一个指向课程的外键,因为一个学生可以选择多门课程,一个外键不够用。同样,你也不能在课程表中加入一个指向学生的外键,因为一个课程有多个学生选择。两侧都需要一组外键。
这种问题的解决方法是添加第三张表,这个表成为关联表。现在,多对多关系可以分解成原表和关联表之间的两个一对多关系。
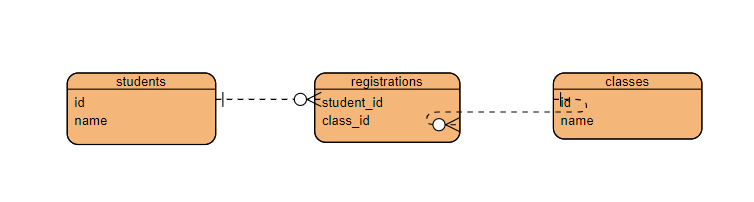
这个例子中的关联表是 registrations,表中的每一行表示一个学生注册的一门课程。
registrations = db.Table('registrations',db.Column('student_id',db.Integer,db.ForeignKey('students.id')),db.Column('class_id',db.Integer,db.ForeignKey('classes.id')))class Student(db.Model):id = db.Column(db.Integer,primary_key = True)name = db.Column(db.String)classes = db.relationship('Class',secondary=rergistrations,backref=db.backref('students',lazy='dynamic'),lazy='dynamic')class Class(db.Model):id = db.Column(db.Integer,primary_key = True)name = db.Column(db.String)
多对多关系仍使用定义一对多关系的db.relationship()方法定义,但在多对多关系中,必须把secondary参数设为关联表。多对多关系可以在任何一个类中定义,backref参数会处理好关系的另一侧。关联表就是一个简单的表,不是模型,SQLAlchemy会自动接管这个表。
classes关系使用列表语义,这样处理多对多关系特别简单。
假设学生是 s,课程是 c,学生注册课程的代码为:
>>> s.classes.append(c)>>> db.session.add(s)
列出学生 s 注册的课程以及注册了课程 c 的学生也很简单:
>>> s.classes.all()>>> c.students.all()
Class模型中的students关系有参数db.backref()定义。注意,这个关系中还指定了lazy='dynamic'参数,所以关系两侧返回查询都可以接受额外的过滤器。
如果后来学生 s 决定不选课程 c 了:
>>> s.classes.remove(c)
自引用关系
多对多关系可用于实现用户之间的关注,但存在一个问题。在学生和课程的例子中,关联表链接的是两个不同的实体。但是,表示用户关注其他用户时,只有用户一个实体,没有第二个实体。
如果关系中的两侧都在同一个表中,这种关系成为自引用关系。在关注中,关系的左侧时用户实体,可以成为 “关注者”;关系的右侧也是用户实体,但这些是 “被关注者”。从概念上看,自引用关系和普通用户没什么区别,只是不易理解。
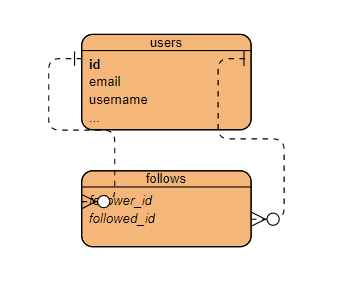
本例的关联表是follows ,其中每一行表示一个用户关注了另一个用户。图中左边表示一对多关系把用户和follows表中的一组记录联系起来,用户是关注者。图中右边表示的一对多关系把用户和follows表中的一组记录联系起来,用户是被关注者。
高级多对多关系
使用上一节介绍的自引用多对多关系可在数据库中表示用户之间的关注,但却有个限制。使用多对多关系时,往往需要存储所连两个实体之间的额外信息。对用户之间的关注来说,可以存储用户关注另一个用户的日期。这样就能按照时间顺序列出所有关注者。这种信息只能存储在关联表中,但是在之前实现的学生和课程之间的关系中,关联表时完全由SQLALchemy掌控的内部表,我们无法插手。
为了能在关系中处理自定义的数据,我们必须提升关联表的地位,使其变成应用可访问的模型。
#app/models.py 关注关系中关联表模型实现class Follow(db.Model):__tablename__ = 'follows'follower_id = db.Column(db.Integer,db.ForeignKey('users.id'),primary_key = True)followed_id = db.Column(db.Integer,db.ForeignKey('users.id'),primary_key = True)timestamp = db.Column(db.DateTime,default=datetime.utcnow)
SQLAlchemy不能直接使用这个关联表,因为如果这么做应用就无法访问其中的自定义字段。相反的,要把这个多对多关系的左右两侧拆分成两个基本的一对多关系,而且要定义成标准的关系。
#app/models.py 使用两个一对多关系实现的多对多关系class User(UserMixin,db.Model):#...followed = db.relationship('Follow',foreign_keys=[Follow.follower_id],backref=db.backref('follower',lazy='joined'),lazy='dynamic',cascade='all,delete-orphan')followers= db.relationship('Follow',foreign_keys=[Follow.followed_id],backref=db.backref('followed',lazy='joined'),lazy='dynamic',cascade='all,delete-orphan')
在这段代码中,followed和followers关系都定义为单独的一对多关系。注意,为了消除外键间的歧义,定义关系时必须使用foreign_keys指定外键。而且,db.backref()参数并不是指定这两个关系之间的引用关系,而是回引Follow模型。
回引中的lazy参数指定为joined。这种lazy模式可以实现立即从联结查询中加载相关对象。例如,如果某个用户关注了 100 个用户,调用user.followed.all()后返回一个列表,其中包含 100 个Follow实例,每一个实例的follower和followed回引属性都指向相应的用户。设定为lazy='joined'模式,就可在一次数据库查询中完成这些操作。如果把lazy设为默认值select,那么首次访问follower和followed属性时才会加载对应的用户,而且每个属性都需要一个单独的查询,这就意味着获取全部被关注用户时需要增加 100 次额外的数据库查询。
这两个关系中,User一侧设定的lazy参数作用不一样。lazy参数都在 “一” 这一侧设定,返回的结果是”多“这一侧的记录。上述代码使用的是dynamic,因此关系属性不会直接返回记录,而是返回查询对象,所以在执行查询之前还可以添加额外的过滤器。
cascade参数配置在父对象上执行的操作对相关对象的影响。比如,层叠选项可设为:将用户添加到数据库会话后,要自动把所有关系的对象都添加到会话中。层叠选项的默认值能满足多数情况的需求,但对这个多对多关系来说却不合适。删除对象时,默认的层叠行为是把对象连接的所有相关记录的外键设为空值。但在关联表中,删除记录后正确的行为应该是把指向该记录的实体也删除,这样才能有效销毁连接,这就是层叠选项值delete-orphan的作用。
cascade参数的值是一组由逗号分隔的层叠选项,其中all表示除了delete-orphan之外的所有层叠选项,这看起来可能让人有点困惑。设为all,delete-orphan的意思是启用所有默认层叠选项,而且还要删除孤儿记录。
应用现在要处理两个一对多关系,以便实现多对多关系。由于这些操作经常需要重复执行,所以最好在 User 模型中为所有可能的操作定义辅助方法。
#app/models.py 关注关系的辅助方法class User(db.Model):#...def follow(self,user):if not self.is_following(uesr):f = Follow(follower=self,followed=user)db.session.add(f)def unfollow(self,user):f = self.followed.filter_by(followed_id=user.id).first()if f:db.session.delete(f)def is_following(self,user):if user.id is None:return Falsereturn self.followed.filter_by(followed_id=user.id).first() is not Nonedef is_followed_by(self,user):if user.id is None:return Falsereturn self.followers.filter_by(follower_id=user.id).first() is not None
follow()方法手动把Follow实例插入关联表,从而把关注者和被关注者连接起来,并让应用有机会设定自定义字段。连接在一起的两个用户手动传入Follow类的构造器,创建一个Follow新实例。unfollow()方法使用followed关系找到连接用户和被关注用户的Follow实例。若要销毁这两个用户之间的连接,只需删除这个Follow属性即可。is_following方法和is_followed_by方法分别在左右两边的一对多关系中搜索指定用户。如果找到就返回 True。
在资料页面中显示关注者
#app/main/views.py ”关注“路由和视图函数@main.route('/follow/<username>')@login_required@permission_required(Permission.Follow)def follow(username):user = User.query.filter_by(username=username).first()if user is None:flash('无效的用户')return redirect(url_for('.index'))if current_user.is_following(user):flash('您已关注该用户,无需重复操作!')return redirect(url_for('.user',username=username))current_user.follow(user)db.session.commit()flash('你已关注了用户 %s。' % username)return redirect(url_for('.user',username=username))
#app/main/views.py ”取消关注“路由和视图函数@mian.route('/unfollow/<uesrname>')@login_required@permission_required(Permission.Follow)def unfollow(username):user = User.query.filter_by(username=username).first()if user is None:flash('无效的用户')return redirect(url_for('.index'))if not current_user.is_following(user):flash('您没有关注该用户,无效的操作!')return redirect(url_for('.user',username=username))current_user.unfollow(user)db.session.commit()flash('你已取消关注用户 %s。' % username)return redirect(url_for('.user',username=username))
#app/main/views.py ”被关注者“路由和视图函数@main.route('/followed_by/<username>')@login_requireddef followed_by(username):user = User.query.filter_by(username=username).first()if user is None:flash('无效的用户')return redirect(url_for('.index'))page = request.args.get('page',1,type=int)pagination = user.followed.paginate(page,per_page=current_app.config['FLASKY_FOLLOWED_PER_PAGE'],error_out=False)follows = [{'user':item.followed,'timestamp':item.timestamp}for item in pagination.items]return render_template('followers.html',user=uesr,title='关注来自',endpoint='.followed_by',pagination=pagination,follows=follows)
#app/main/views.py ”关注者“路由和视图函数@main.route('/followers/<username>')@login_requireddef followers(username):user = Uesr.query.filter_by(username=username).first()if user in None:flash('无效的用户')return redirect(url_for('.index'))page = request.args.get('page',1,type=int)pagination = user.followers.paginate(page,per_page=current_app.config['FLASKY_FOLLOWERS_PER_PAGE'],error_out=False)follows = [{'user':item.follower,'timestamp':item.timestamp}for item in pagination.items]return render_template('followers.html',user=user,title='粉丝来自',endpoint='.followers',pagination=pagination,follows=follows)
这个函数加载并验证请求的用户,然后使用分页显示该用户的followed和followers关系。由于查询关注者返回的是Follow实例列表,为了方便渲染,我们将其转换成一个新列表,列表中的各元素都包含user和timestamp字段。
渲染关注者列表的模板可以写的通用一点,以便能用来渲染关注的用户列表和被关注的用户列表。模板接收的参数包括用户对象、页面的标题、分页链接使用的端点、分页对象和查询结果列表。
使用数据库联结查询所关注用户的文章
若想显示所关注用户发布的所有文章,第一步显然先要获取这些用户,然后获取各用户的文章,再按一定顺序排列,写入一个列表。可是这种方式伸缩性不好,随着数据不断变大,生成这个列表的工作量也不断增长,而且分页等操作也无法高效完成。这是一个常见的问题,人们称之为 “N+1” 问题,因为这里需要发起 N+1 次数据库查询,其中 N 是第一次查询返回的结果数量。高效获取博客文章,而不管数据库有多大,最好的方法是在一次查询中完成所有操作。完成这个操作的数据库操作成为联结。联结操作用到两个或更多的数据表,在其中查找满足指定条件的记录组合,再把记录组合插入一个临时表中,这个临时表就是联结查询的结果。
示例:
下面是一个users表,表中有三个用户。
users 表
| id | username |
|---|---|
| 1 | john |
| 2 | susan |
| 3 | david |
下面是一个posts表,表中有几篇博客文章。
posts 表
| id | author_id | body |
|---|---|---|
| 1 | 2 | susan 发布的博客文章 |
| 2 | 1 | john 发布的博客文章 |
| 3 | 3 | david 发布的博客文章 |
| 4 | 1 | john 发布的第二篇博客文章 |
下面是一个follows表。
follows 表
| follower_id | followed_id |
|---|---|
| 1 | 3 |
| 2 | 1 |
| 2 | 3 |
若想获得 susan 所关注用户发布的文章,必须合并posts表和follows表。首先过滤follows表,只留下关注者为 susan 的记录,然后过滤posts表,留下author_id和过滤后和follows表中followed_id相等的记录,把两次过滤结果合并,组曾临时联结表,这样就能高效查询 susan 所关注用户发布的文章列表。下面是此次联结操作得到的结果,用户执行此次联结操作的列在表中加上了*标记。
联结表
| id | author_id* | body | follower_id | followed_id* |
|---|---|---|---|---|
| 2 | 1 | john 发布的博客文章 | 2 | 1 |
| 3 | 3 | david 发布的博客文章 | 2 | 3 |
| 4 | 1 | john 发布的第二篇博客文章 | 2 | 1 |
使用Flask-SQLAlchemy执行这个联结操作的查询相当复杂:
return db.session.query(Post).select_from(Follow).filter_by(follower_id=self.id).\join(Post,Follow.followed_id == Post.author_id)
在此之前见到的查询都是从所查询模型的query属性开始的。这里不能这样做,因为查询要返回posts记录,所以首先要做的操作是在follows表上执行过滤器。因此,这里使用来了一种更基础的查询方式。
db.session.query(Post)只能这个查询将返回Post对象;select_from(Follow)的意思是这个查询从Follow模型开始;filter_by(follower_id=self.id)使用关注用户过滤follows表;join(Post,Follow.followed_id == Post.author_id)联结filter_by()得到的结果和Post对象。
调换过滤器和联结顺序可以简化这个查询:
return Post.query.join(Follow,Follow.followed_id == Post.author_id).\filter(Follow.follower_id == self.id)
如果首先执行联结操作,那么这个查询就可以从Post.query开始,此时唯一需要使用的两个过滤器是join()和filter()。先执行联结操作再过滤看起爱工作量会更大一些,但实际上这两种查询是等效的。SQLAlchemy首先会收集所有过滤器,然后再以最高效的方式生成查询。这两种生成的原生 SQL 指令几乎一样。
#app/models.py 获取所关注用户的文章class User(db.Model):#...@propertydef followed_posts(self):return Post.query.join(Follow,Follow.followed_id = author_id).\filter(Follow.follower_id == self.id)
注意,followed_posts()方法定义为属性,因此调用时无需加()。如此一来,所有关系的句法就一样了。
在首页显示所关注用户的文章
#app/main/views.py 显示所有博客文章或只显示所关注用户的文章@main.route('/',methods=['GET','POST'])def index():#...show_followed = Falseif current_user.is_authenticated:show_followed = bool(request.cookies.get('show_followed',''))if show_followed:query = current_user.followed_postselse:query = Post.querypagination = query.order_by(Post.timestamp.desc()).paginate(page,per_page=current_app.config['FLASKY_POSTS_PER_PAGE'],error_out=False)posts = pagination.itemsreturn render_template('index.html',form=form,posts=posts,show_followed=show_followed,pagination=pagination)
决定显示所有博客文章还是只显示所关注用户文章的选项存储在名为show_followed的cookie中,如果其值为非空字符串,表示只显示所关注用户的文章。cookie以request.cookies字典的形式存储在请求对象中。这个cookie的值会转换成为布尔值,根据得到的值设定本地变量query的值。
#app/main/views.py 查询所有文章还是所关注用户的文章@main.route('/all')@login_requireddef show_all():resp = make_response(redirect(url_for('.index')))resp.set_cookie('show_followed','',max_age=30*24*60*60) #30天return resp@main.route('/followed')@login_requireddef show_followed():resp = make_response(redirect(url_for('.index')))resp.set_cookie('show_followed','1',max_age=30*24*60*60)return resp
指向这两个路由的链接添加在首页模板中,点击这两个链接后为show_followed cookie设定适当的值,然后从定向到首页。
cookie只能在响应对象中设置,因此这两个路由不能依赖 Flask,要使用make_response()方法创建响应对象。
如果你现在访问网站,切换到所关注的用户文章列表,会发现自己的文章不在列表中,这是肯定的,因为用户不能关注自己。
虽然查询能按设计正常执行,但是用户查看好友文章时还是希望能看到自己的文章,这个问题最简单的解决方法就是,注册时把用户设为自己的关注者。
#app/models.py 创建用户时把用户设为自己的关注者class User(UserMixin,db.Model):#...def __init__(self,**kwargs):#...self.follow(self)
#app/models.py 把用户设为自己的关注者class User(UserMixin,db.Model):#...@staticmethoddef add_self_follows():for user in User.query.all():if not user.is_following(user):user.follow(user)db.session.add(user)db.session.commit()#...

若有收获,就点个赞吧
0 人点赞
