一、定义配置文件信息
有时候我们为了统一管理会把一些变量放到 yml 配置文件中
例如: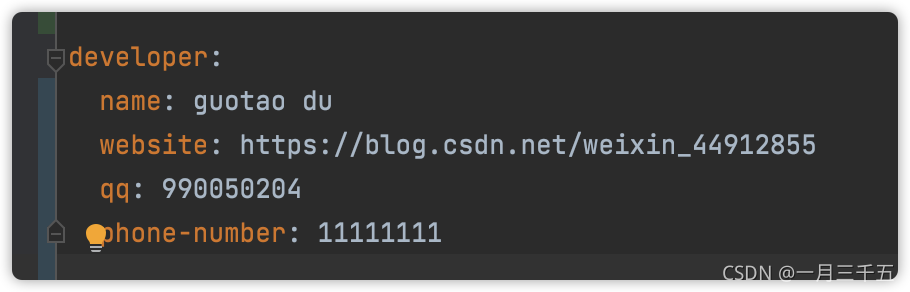
用 @ConfigurationProperties 代替 @Value
使用方法
定义对应字段的实体
@Data// 指定前缀@ConfigurationProperties(prefix = "developer")@Componentpublic class DeveloperProperty {private String name;private String website;private String qq;private String phoneNumber;}
使用时注入这个bean
@RestController@RequiredArgsConstructorpublic class PropertyController {final DeveloperProperty developerProperty;@GetMapping("/property")public Object index() {return developerProperty.getName();}}
二、用@RequireArgsConstructor 代替 @Autowired
我们都知道注入一个 bean 有三种方式哦(set 注入, 构造器注入, 注解注入),Spring 推荐我们使用构造器的方式注入 Bean
我们来看看上段代码编译完之后的样子
RequiredArgsConstructor:lombok提供
三、代码模块化
阿里巴巴 Java 开发手册中说到每个方法的代码不要超过50行,在实际的开发中我们要善于拆分自己的接口或方法,做到一个方法只处理一种逻辑,说不定以后某个功能就用到了,拿来即用。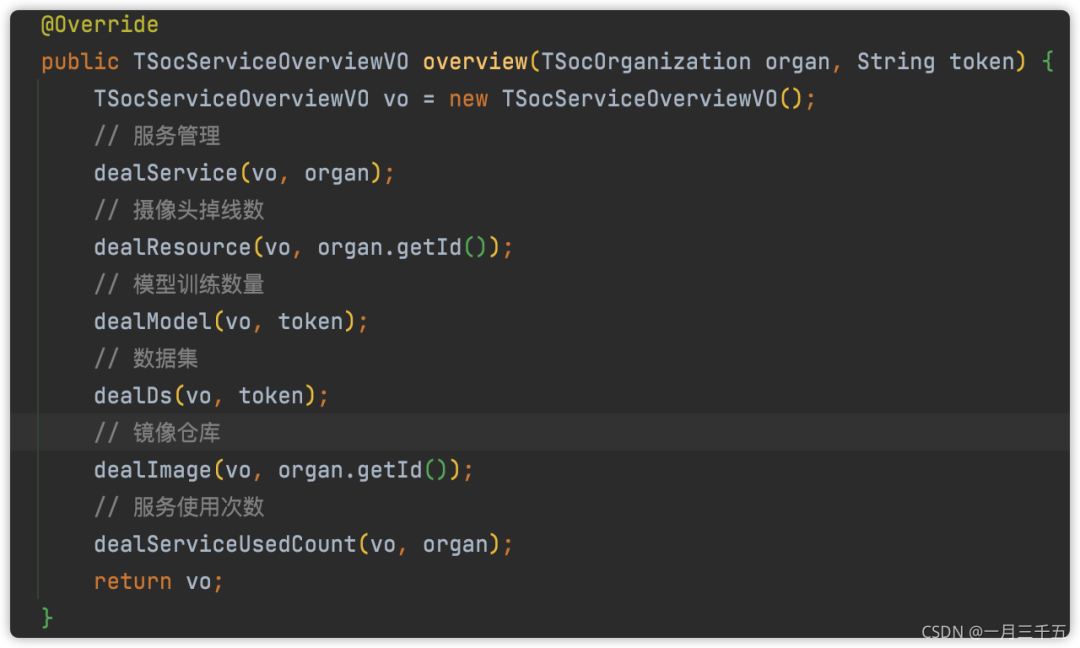
四、抛异常而不是返回
在写业务代码的时候,经常会根据不同的结果返回不同的信息,尽量减少返回,会显得代码比较乱
反例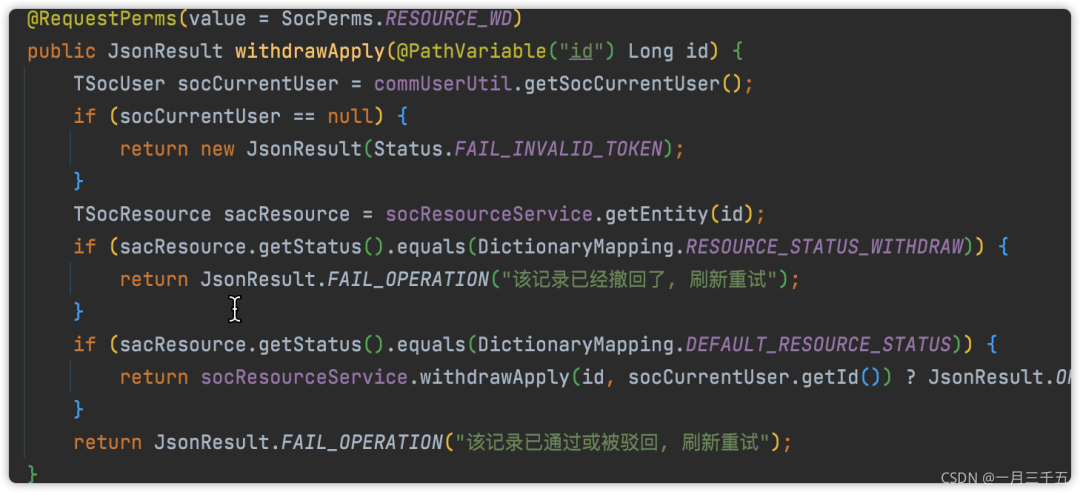 正例
正例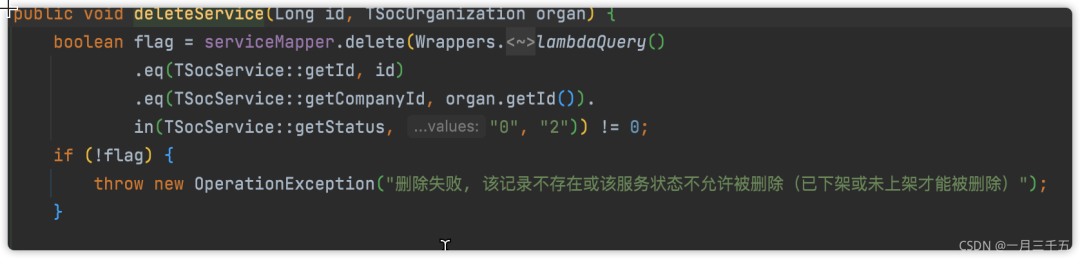
五、减少不必要的 db
尽可能的减少对数据库的查询
举例子
删除一个服务(已下架或未上架的才能删除),之前有看别人写的代码,会先根据id查询该记录,然后做一些判断
反例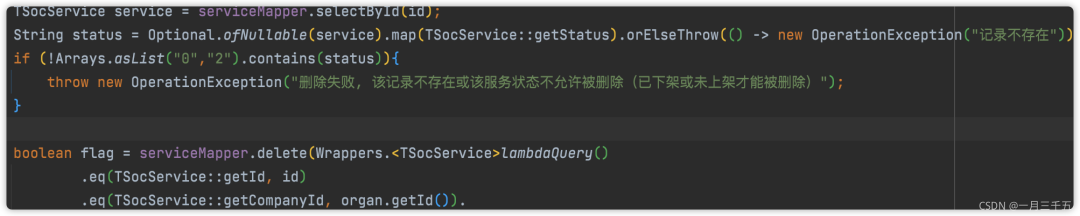
正例
六、不要返回 null
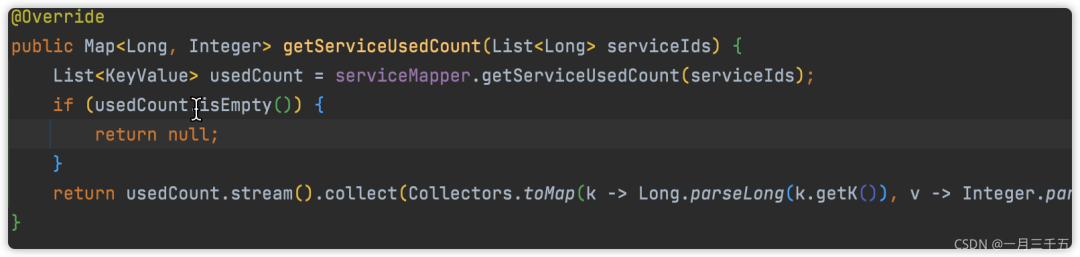
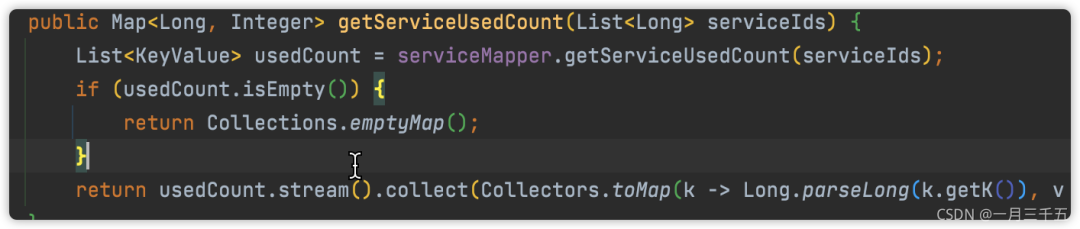
七、if else
八、减少 controller 业务代码
业务代码尽量放到service层进行处理,后期维护起来也好操作而且美观
反例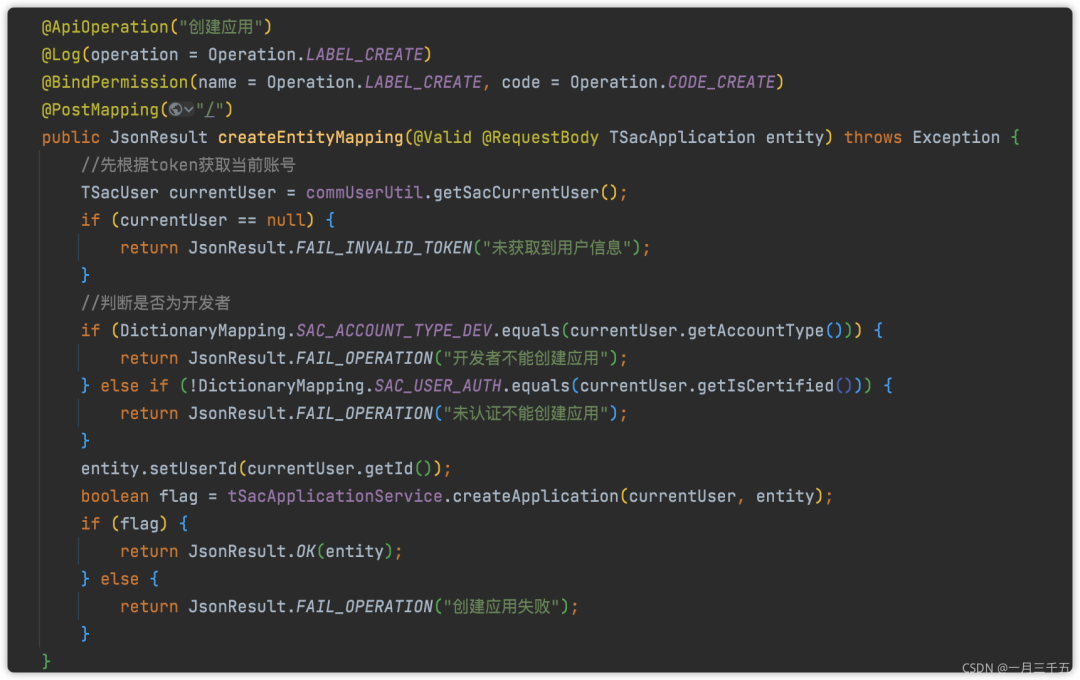
正例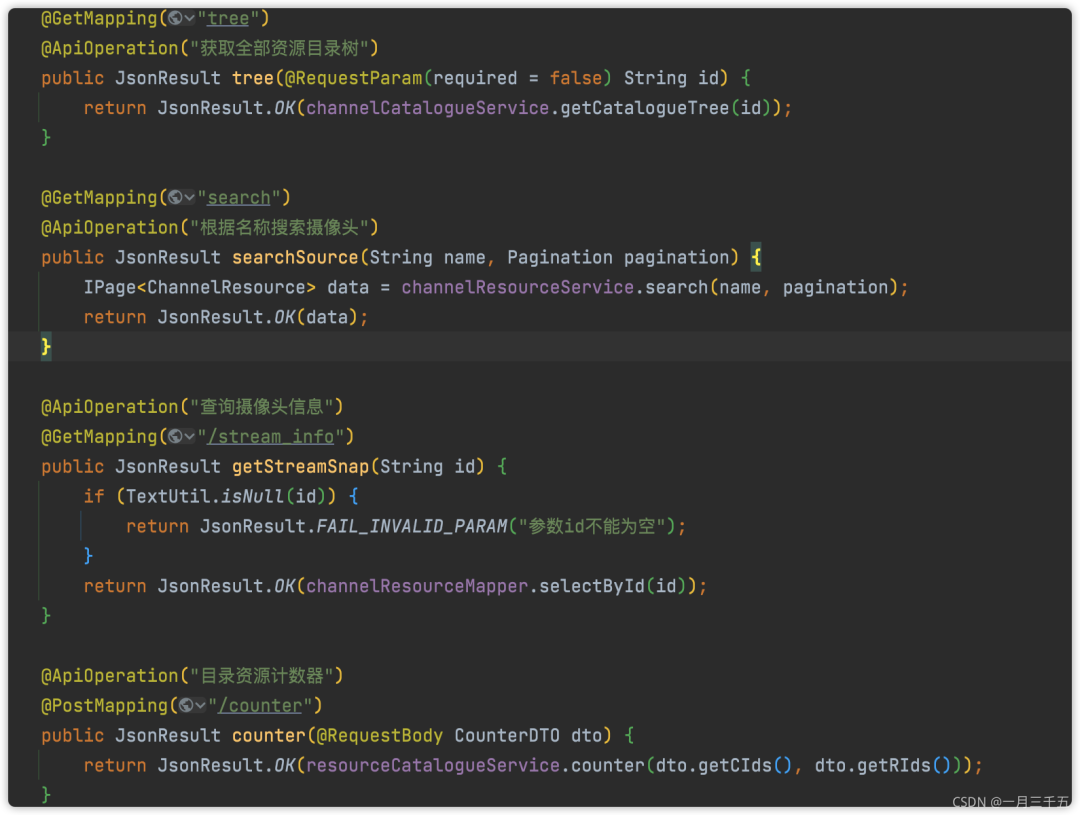
九、利用好 IDEA
目前为止市面上的企业基本都用idea作为开发工具了吧
举一个小例子
idea会对我们的代码进行判断,提出合理的建议
例如:
它推荐我们用lanbda的形式代替,点击replace
十、阅读源码
一定要养成阅读源码的好习惯包括优秀的开源项目 GitHub 上 starts:>1000,会从中学到好多知识包括其对代码的设计思想以及高级API,面试加分
十一、设计模式
23种设计模式,要尝试代码中运用设计模式思想,写出的代码即规范又美观还高大上哈哈。
十二、拥抱新知识
要多学习自己认知之外的知识,不要每天 crud,有机会多用用有点难度的知识
十三、基础问题
map 遍历
HashMap<String, String> map = new HashMap<>();map.put("name", "du");for (String key : map.keySet()) {String value = map.get(key);}map.forEach((k, v) -> {});// 推荐for (Map.Entry<String, String> entry : map.entrySet()) {}
optional 判空
//获取子目录列表public List<CatalogueTreeNode> getChild(String pid) {if (V.isEmpty(pid)) {pid = BasicDic.TEMPORARY_DIRECTORY_ROOT;}CatalogueTreeNode node = treeNodeMap.get(pid);return Optional.ofNullable(node).map(CatalogueTreeNode::getChild).orElse(Collections.emptyList());}
递归
大数据量的递归时,避免在递归方法里new对象,可以试试把对象当作方法参数进行传递使用
注释
类 接口方法 注解 较复杂的方法 注释都要写而且要写清楚, 有时候写注释不是给别人看的 而是给自己看的
十四、判断元素是否存在
hashSet 而不是 list
list 判断一个元素是否存在的代码
ArrayList<String> list = new ArrayList<>();// 判断a是否在list中for (int i = 0; i < list.size(); i++)if ("a".equals(elementData[i]))return i;
由此可见其复杂度为On,而hashSet底层采用hashMap作为数据结构进行存储,元素都放到map的key(即链表中)
HashSet<String> set = new HashSet<>();// 判断a是否在set中int index = hash(a);return getNode(index) != null
由此可见其复杂度为O1。

若有收获,就点个赞吧
0 人点赞
