Java基础
封装的步骤:
- 属性私有化
- 一个属性对外提供两个方法(set,get),外部程序只能通过SET方法修改,GET方法获取!
- 可以在SET方法中设立关卡来保护数据的安全性。
强调:set和get都是实例方法,不可以带static。
不带static的方法称为实例方法,实例方法的调用必须先new对象。
set方法和get方法有严格的格式要求:
set: public void setName(String name){
this.name=name;
}
get:: public String getName(){
retuen name;
}
this和static
static
a.所有static修饰的都是类相关的,类级别的。
b.所有static修饰的,都是采用“类名.”的方式访问的。
c.static修饰的变量称为静态变量,修饰的方法称为静态方法。
变量的分类
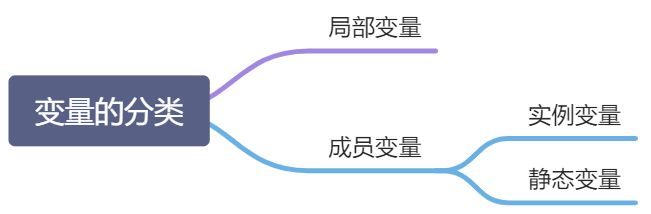
局部变量:存栈当中(在一个函数内部或复合语句内部定义的变量)
实例变量:对象级别,堆内存当中,引用. 访问
静态变量:static修饰,类级别,方法区中 类名. 访问。但 引用. 也可以访问,但不建议。
实例的,都是对象相关的,访问时采用“引用.”的方式访问,需要先new对象实例相关的,必须先有对象,才能访问,可能会出现空指针异常。
静态的,都是类相关的,访问时采用“类名.”的方式访问。不需要new对象不需要对象的参与即可访问,没有空指针异常的发生。
什么时候变量声明为实例,什么时候静态呢?
当一个类的所有对象的某个“属性值”不会随着对象的改变而变化的时候,建议将该属性定义为静态属性(或者说把这个变量定义为静态变量) 可以节省空间。
什么时候方法声明为实例,什么时候静态?
如果该方法中直接访问了实例变量,该方法必须是实例方法。
静态方法:当方法体中需要直接访问当前对象的实例变量或者实例方法的时候,该方法必须定义为实例方法。因为只有实例方法中才有 this,静态方法中不存在 this。
—-方法描述的是动作,当所有的对象执行这个动作时,最终产生的影响是一样的,那么这个动作就不再属于某一个对象的动作了,可以将这个动作提升 为类级别的动作,模板级别的动作。
——静态方法中不能直接访问实例方法和实例变量。
//实例方法不同的客户购物,最终的效果都不同,另外在 shopping()方法中访问了当前对象的实例变量 name,以及调用了实例方法 pay(),所以 shopping()方法不能定义为静态方法,必须声明为实例方法public class Customer {String name;public Customer(String name){this.name = name;}public void shopping(){//直接访问当前对象的 nameSystem.out.println(name + "正在选购商品! ");//继续让当前对象去支付pay();}public void pay(){System.out.println(name + "正在支付! ");}}public class CustomerTest {public static void main(String[] args) {Customer jack = new Customer("jack");jack.shopping();Customer rose = new Customer("rose");rose.shopping();}}
/*工具类”当中的方法一般定义为静态方法,因为工具类就是为了方便大家的使用,将方法定义为静态方法,比较方便调用,不需要创建对象,直接使用类名就可以访问。请看以下工具类,为了简化“System.out.println();”代码而编写的工具类*/public class U {public static void p(int data){System.out.println(data);}public static void p(long data){System.out.println(data);}public static void p(float data){System.out.println(data);}public static void p(double data){System.out.println(data);}public static void p(boolean data){System.out.println(data);}public static void p(char data){System.out.println(data);}public static void p(String data){System.out.println(data);}}public class HelloWorld {public static void main(String[] args) {U.p("Hello World!");U.p(true);U.p(3.14);U.p('A');}}
总结:所有实例相关的,包括实例变量和实例方法,必须先创建对象,然后通过“引用”的方式去访问,
如果空引用访问实例相关的成员,必然会出现空指针异常。
实例方法会出现空指针异常,静态方法不会。
所有静态相关的,包括静态变量和静态方法,直接使用“类名”去访问。
虽然静态相关的成员也能使用“引用.”去访问,但这种方式并不被主张。
静态代码块
语法:static{
java语句;
}
什么时候执行?
类加载时执行,在main方法执行之前执行,并且只执行一次。
自上而下依次执行。
this
定义:
- this是一个变量,是一个引用。this保存当前对象的内存地址,指向自身。 所以,严格意义上来讲,this代表的就是“当前对象”。
- this存储在堆内存中,对象的内部。
- this只能使用在实例方法中,谁调用这个实例方法,this就是谁,所以this代表的是当前对象。
- this.大部分情况下可以省略。
static方法中为什么不可以使用this?
因为static用类.访问,不需要对象访问,而this代表当前对象。
什么时候不可以省略?
区分实例变量与局部变量时不可以省略。
this()
通过当前构造方法去调用另一个本类的构造方法,可以使用this(实际参数列表)。
作用:代码复用。
对于this()的调用只能出现在构造方法的第一行。
继承
定义:在不同的类中也可能会有共同的特征和动作,可以把这些共同的特征和动作放在一个类中,让其它类共享。因此可以定义一个通用类,然后将其扩展为其它多个特定类,这些特定类继承通用类中的特征和动作。继承是 Java 中实现软件复用的重要手段,避免重复,易于维护。
作用:继承可以解决代码臃肿的问题。换句话说,继承解决了代码复用的问题(代码复用就是代码的重复利用),这是继承机制最基本的作用。
重要作用:继承之后才会衍生出方法的覆盖和多态机制。
特性:
- B类继承 A类,则称 A类为超类(superclass)、父类、基类, B类则称为子类(subclass)、派生类、扩展类。
- java 中的继承只支持单继承,不支持多继承, C++中支持多继承,这也是 java 体java 中不允许这样写代码: class B extends A,C{ }。
- 虽然 java 中不支持多继承,但有的时候会产生间接继承的效果,例如: class C,class B extends A,也就是说, C 直接继承 B,其实 C 还间接继承 A。
- java 中规定,子类继承父类,除构造方法不能继承外,剩下都可以继承。但是私有属性无法在子类中直接访问。(父类中private修饰的不能再子类中直接访问,可以通过间接的方式访问(get方法))
- java 中的类没有显示的继承任何类,则默认继承 Object 类, Object 类是 java 语言Object 类型中所有的特征。
- 继承也存在一些缺点,耦合度高,父类修改,子类受到牵连。
- 例如:CreditAccount 类继承 Account 类会导致它们之间的耦合度非常高, Account 类发生改变之后会马上影响到 CreditAccount 类。
子类继承父类之后,能使用子类对象调用父类方法么?
可以。其实本质上,子类继承父类之后,是将父类继承过来的方法归自己所有了。实际上调用的也不是父类的方法,是他自己的方法!
实际开发中,满足什么条件的时候,可以使用继承?
凡是可以用“is a”能描述的,都可以继承。
eg: Cat is a Animal Dog is a Animal
方法重写/覆盖
方法覆盖与方法重载的区别?
方法重载
定义:当一个类中,如果功能相似,建议将名字定为一样的,这样代码美观,并且方便编程。
方法重载的三个条件:
1. 在同一个类中1. 方法名相同1. 参数列表不同(个数,顺序,类型)
定义:父类中继承过来的方法已经不够用了,子类有必要将这个方法重新再写一遍,所以方法覆盖又被称为方法重写。当该方法被重写之后,子类对象一定会调用重写之后的方法 。
必要条件:
- 方法覆盖发生在具有继承关系的父子类之间,这是首要条件;相同的返回值类型、相同的方法名、相同的形式参数列表;
- 相同的返回值类型:
对于返回值类型是基本数据类型的来说,必须一致。
对于返回值类型是引用数据类型的来说,覆盖之后返回值的类型可以变得更小(意义不大)
- 访问权限不能更低,可以更高。
- 重写之后的方法不能比之前的方法抛出更多的异常,可以相同或更少。
注意事项:
- 由于覆盖之后的方法与原方法一模一样,建议在开发的时候采用复制粘贴的方式,不建议手写,因为手写的时候非常容易出错。
—讲了多态就明白了。—
- 私有的方法不能被继承,所以不能被覆盖; ✔
- 构造方法不能被继承,所以也不能被覆盖;✔
- 方法覆盖只是和方法有关,和属性无关;✔
- 静态方法不存在覆盖(不是静态方法不能覆盖,是静态方法覆盖意义不大,学习 ✔
多态
定义:它的前提是封装形成独立体,独立体之间存在继承关系,从而产生多态机制。多态是同一个行为具有多个不同表现形式或形态的能力。 多态就是“同一个行为”发生在“不同的对象上”会产生不同的效果。向上转型/向下转型
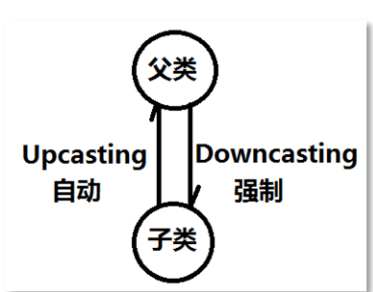
java 中允许这样的两种语法出现,一种是向上转型( Upcasting),一种是向下转型(Downcasting),
向上转型是指 子类型转换为父类型,又被称为自动类型转换,
向下转型是指 父类型转换为子类型,又被称为强制类型转换。
⭐:无论是向上转型还是向下转型,两种类型之间必须要有继承关系,没有继承关系情况下进行向上转型或向下转型的时候编译器都会报错。
eg: Animal a = new Cat();
a.catchMouse();
此代码会编译错误,因为“Animal a = new Cat();”在编译的时候,编译器只知道 a 变量的数据类型是 Animal,也就是说它只会去Animal.class 字节码中查找 catchMouse()方法(Animal父类中没有catchMouse(),是cat类中独有的方法。),结果没找到,自然“静态绑定”就失败了,编译没有通过。
就像以上描述的错误信息一样:在类型为 Animal 的变量 a 中找不到方法catchMouse()。
向上转型
子类型转换为父类型,,也称自动类型转换。
eg:Animal a = new Cat();
a.move();
分析: java程序分为编译阶段和运行阶段
编译阶段:对于编译器来说,编译器只知道a2的类型是Animal,所以编译器在检查语法的时候,会去Animal.class字节码文件中找move()方法,找到了,绑定上move()方法,编译通过,静态绑定成功。(编译阶段属于静态绑定。)
运行阶段:运行阶段时,实际上在堆内存中创建的java对象是Cat对象,所以move的时候,真正参与move的对象是一只猫,所以运行阶段会动态执行Cat对象的move()方法。这个过程属于运行阶段绑定。(运行阶段绑定属于动态绑定。)
多态表示多种形态:
编译的时候一种形态。
运行的时候一种形态。
向下转型
父类型转换为子类型,为了调用子类对象特有的方法。
eg:Animal a = new Cat();
Cat c = (Cat) a; //将Animal类型强制转换为Cat类型。
c.catchMouse();
分析:代码修改后, 就可以正常运行。直接使用 a 引用是无法调用 catchMouse()方法的,因为这个方法属于子类 Cat中特有的行为,不是所有 Animal 动物都可以抓老鼠的,要想让它去抓老鼠,就必须做向下转型(Downcasting),也就是使用强制类型转换将 Animal 类型的 a 引用转换成 Cat 类型 的引用c(Cat c = (Cat)a;),使用 Cat 类型的 c 引用调用 catchMouse()方法。
instanceof 运算符
在进行任何向下转型的操作之前,要使用 instanceof 进行判断。<br />为什么要用instanceof运算符?<br />因为向下转型有风险。<br />eg:<br />Animal a = new Bird()<br />Cat y = (Cat)a;<br />a.catchMouse():<br />**//分析程序**<br />编译阶段:编译器检测a这个引用是Animal类型,和Cat存在继承关系,所以可以向下转型。<br />运行阶段:会出错,因为堆内存中实际上创建的对象 是 Bird对象。拿Bird对象转换为Cat对象是不可以的,他俩不存在继承关系。<br />会出现异常:java.lang.ClassCastException:类型转换异常。<br />**知识点: **
- instanceof可以在运行阶段动态判断引用指向的对象的类型。
- instanceof的语法:(引用 instanceof 类型)
- instanceof运算符的结果只能是:true/false
- c是一个引用,c变量保存了内存地址指向了堆内存中的对象。
假设(c instancof Cat)为true表示:
c引用指向的堆内存中的java对象是一个Cat。
假设(c instanceof Cat)为false表示:
c引用指向的堆内存中的java对象不是一个Cat。
public class Master{
public void feed(Dog d){}
public void feed(Cat c){}
}
以上代码的 Master和Cat,Dog的关系很紧密(耦合度高),导致扩展力很差。
public class Master{
public void feed(Pet pet){}
}
以上代码 Master和Cat,Dog的关系就脱离了(耦合度低),Master关注的是Pet类,提高了软件的扩展性。
一个软件开发原则:
七大原则最基本的原则:OCP(对扩展开放,对修改关闭)
目的:降低程序耦合度,提高程序扩展力。
要面向抽象编程,不建议面向具体编程。
覆盖遗留问题解答
- 方法覆盖需要和多态机制联合起来使用才有意义。
没有多态机制的话,方法覆盖没什么意义,如果父类无法满足子类业务 需求时,子类完全可以定义一个全新方法。
- 静态方法存在方法覆盖么?
多态和对象相关,而静态方法的执行不需要对象,所以 一般情况下我们会说静态方法“不存在”方法覆盖。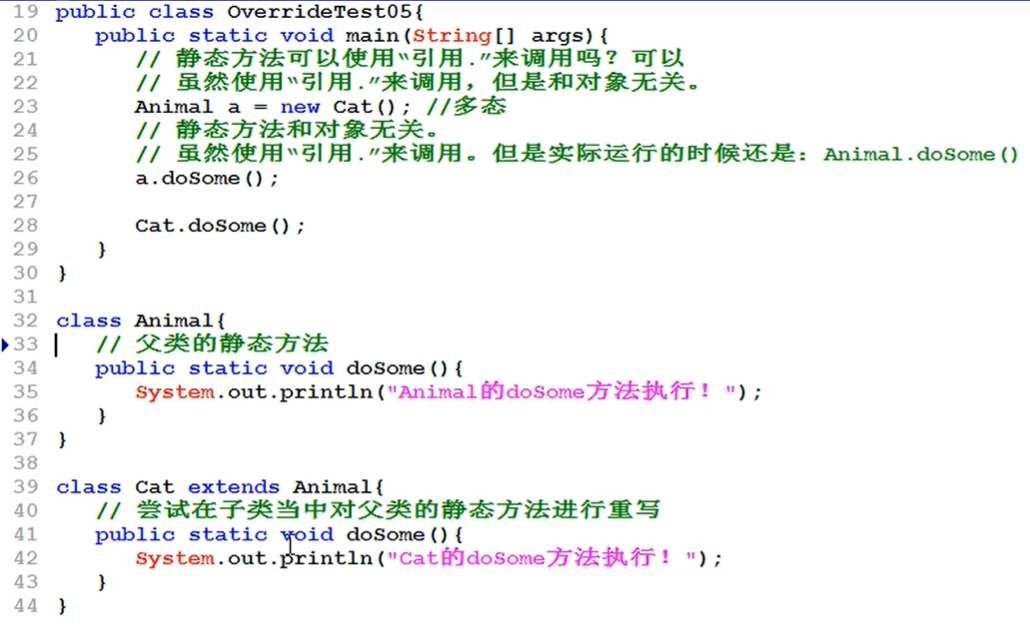
- 私有方法不能覆盖 :记住就行。
super
super与this的对比
- this表示当前对象
- super表示的是当前对象的父类特征。(super是this指向的那个对象中的一块空间)
this:
- this能出现在构造方法和实例方法中。
- this的语法是:”this.”,”this()”.
- this不能使用在静态方法中。
- this.大部分情况下是可以省略的。
- this.什么时候不可以省略呢?
在区分局部变量和实例变量的时候不可以省略。
this()只能出现在构造方法的第一行,通过当前的构造方法去调用“本类”中其他的构造方法
目的是:代码复用。
super:super能出现在实例方法和构造方法中。
- super的语法是:”super.”,”super()”.
- super不能使用在静态方法中。
因为 super 代表了当前对象上的父类型特征,静态方法中没有 this,肯定也是不能使用 super 的。
- super.大部分情况下是可以省略的。
super.什么时候不可以省略呢?
当父类中有该实例变量或方法,子类中又重新定义了同名的实例变量或方法,如果想在子类中访问父类的实例变量或方法, super. 不能省略。
this.name:当前对象的name属性
super.name:当前对象的父类型特征中的name属性。super()只能出现在构造方法的第一行,通过当前的构造方法去调用“父类”中的构造方法。
目的是:创建子类对象的时候,先初始化父类型特征。
- super() :表示通过子类的构造方法调用父类的构造方法。 模拟现实世界里的场景:要想有儿子,先要有父亲。
- 当一个构造方法第一行: 既没有this()又没有super()的话,默认会有一个super();
表示通过当前子类的构造方法调用父类的无参构造方法。
所以必须保证父类的无参构造方法是存在的。
this()和super()不能共存,都只能在第一行。
- 无论如何折腾,父类的构造方法是一定会执行的。
- super不是引用,super也不保存内存地址,super也不指向任何对象。 super只是代表当前对象内部的那一块父类型特征。
eg:
public class SuperTest {public static void main(String[] args) {new C(); //执行顺序 1-3-6-5-4 ,栈的原理:最后调用的,最先执行结束。 后进先出原则}}class A{public A() {//实际上这个地方也有一个super() 是老祖宗Object类的无参构造方法。System.out.println("A的无参数构造方法执行"); //1}}class B extends A{public B() {System.out.println("B的无参数构造方法执行"); //2}public B(String name){//默认有个super() 调用ASystem.out.println("B的有参数构造方法执行"); //3}}class C extends B{public C() {this("zhangsan");System.out.println("C的无参数构造方法执行"); //4}public C(String name){this("zhangsan",20);System.out.println("C的有参数构造执行(String)"); //5}public C(String name,int age){super(name);System.out.println("C的有参数构造方法执行(String,int)"); //6}}
super(实际参数列表):通过当前的构造方法调用父类的构造方法,代码复用性增强了。
初始化对象的父类型特征。
super()的作用主要是
第一,调用父类的构造方法,使用这个构造方法来给当前子类对象初始化父类型特征;
第二,代码复用。
进阶-面向对象
final关键字
定义:
- 采用 final 修饰的类不能被继承 ```java final class A1 { public void test1() {} }
//错误 不可以继承 class B1 extends A1 { public void test2() {} }
2. 采用 final 修饰的方法不能被重写```javaclass A1 {public final void test1() {}}class B1 extends A1 {//覆盖父类的方法,改变其行为//错误,因为父类的方法是 final 修饰的,所以不能覆盖public void test1() {}public void test2() {}}
- 采用 final 修饰的变量(基本数据类型)不能被修改,只能赋一次值。

final 修饰的变量必须显示初始化
//如果是 final 修饰的变量必须初始化private static final long CARD_NO = 0L;public static void main(String[] args) {int i;//局部变量必须初始化//如果不使用可以不初始化System.out.println(i);}
如果修饰的引用,那么这个引用只能指向一个对象,也就是说这个引用不能再次赋值,但被指向的对象里的值是可以修改的。
final Person p = new Person(30);
p = new Person(30); //✖,final修饰的引用不能再次赋值。
p.setAge(40);//✔
- 实例变量如果没有手动赋值的话,系统会赋默认值(实例变量在new对象(构造方法执行时)的时候赋默认值)。
但是final修饰的实例变量,系统不给赋默认值,要求程序员必须手动赋值。这个手动赋值,在变量后面赋值可以,在构造方法中赋值也可以。
- static final联合修饰的变量称为“常量”,常量名建议全部大写,每个单词之间采用下划线连接。
static final String country = “中国”;
常量实际上和静态变量一样,区别在于:
常量的值不能变,常量和静态变量都是存储在方法区,并且都在类加载时初始化。
常量一般都是公开的,因为公开了你也改不了。
8. 构造方法不能被 final 修饰
抽象类
类 —> 对象:实例化
对象 —> 类 :抽象
定义:类和类之间具有共同特征,将这些共同特征提取出来,形成的就是抽象类。
- 什么是抽象类?
类和类之间具有共同的特征,将这些共同特征提取出来,形成的就是抽象类。
类本身也是不存在的,所以抽象类无法创建对象(无法实例化)。
抽象类属于引用数据类型。
- 抽象类怎么定义?
[修饰符列表] abstract class 类名{
类体;
}
- 抽象类是无法实例化的,无法创建对象的,所以抽象类是用来被子类继承的。
- 抽象类的子类可以是抽象类。
- 抽象类无法实例化,但是抽象类有构造方法,这个构造方法是给子类使用的。
- 什么是抽象方法?
抽象方法表示没有实现的方法,没有方法体的方法。
eg:public abstract void dosome();
a.没有方法体,以分号结尾。
b.前面修饰符列表中没有abstract关键字。
- 如果一个类中含有抽象方法,那么这个类必须定义成抽象类
如果有一个方法为抽象的,那么此类必须为抽象的
如果一个类是抽象的,并不要求具有抽象的方法
- 一个非抽象类继承抽象类,必须将抽象类中的抽象方法 实现/覆盖/重写 了,一个抽象类继承抽象类,则不用。
- 抽象的方法只需在抽象类中,提供声明,不需要实现,起到一个强制约束作用,要求子类必须实现。
面试题:java语言中凡是没有方法体的方法都是抽象方法。(✖)
Object类中就有很多都没有方法体,都是以分号结尾。调用了C++的底层代码。
<br />P338
接口
定义:接口我们可以看作是抽象类的一种特殊情况,在接口中只能定义抽象的方法和常量
- 接口是一种引用数据类型,编译之后也是一个class字节码文件
- 接口是完全抽象的。(抽象类是半抽象的。)或者也可以说接口是特殊的抽象类。
- 接口怎么定义?语法是什么?
[修饰符列表] interface 接口名{}
- 接口支持多继承,一个接口可以继承多个接口
- 接口中只包含两部分内容,一部分是:常量。一部分是:抽象方法。
- 接口中所有的元素都是public修饰的。
接口中的抽象方法定义时:public abstract 修饰符可以省略
void addStudent(int id, String name); == public abstract void addStudent(int id, Stringname);
接口中的方法都是抽象方法,所以接口中的方法不能有方法体。
- 接口中的常量的 public static final 可以省略
double PI = 3.14; == public static final double PI = 3.14;
- 接口不能被实例化,接口中没有构造函数的概念
1.接口之间可以继承,但接口之间不能实现
//接口可以继承interface inter3 extends inter1 {public void method4();}//接口不能实现接口//接口只能被类实现interface inter4 implements inter2 { //接口不能实现接口public void method3();}
2.接口中的方法只能通过类来实现,通过implements 关键字
⭐3.如果一个非抽象类,实现了接口,那么必须将接口中所有的方法实现。
4.一个类可以实现多个接口
//实现多个接口,采用逗号隔开//这样这个类就拥有了多种类型//等同于现实中的多继承//所以采用 java 中的接口可以实现多继承//把接口粒度划分细了,主要使功能定义的含义更明确//可以采用一个大的接口定义所有功能,替代多个小的接口,//但这样定义功能不明确,粒度太粗了class InterImpl implements Inter1, Inter2, Inter3 {****}
5.extends和implements都存在的话,代码怎么写?——extends在前,implements在后。
6.使用接口,写代码时,可以使用多态(父类型引用指向子类型对象)。
接口在开发中的作用(解耦合):
理解:
1.扩展性好,可插拔。
2.面向接口编程,可以降低程序的耦合度,提高程序的扩展力,符合OCP开发原则。
3.接口的使用离不开多态机制,因为接口是抽象的无法创建对象,必须指向子类。(接口+多态才可以达到降低耦合度。)
4.接口可以解耦合,解开的是谁和谁的耦合?
任何一个接口都有调用者和实现者,
接口可以将调用者(顾客)和实现者(厨师)解耦合。
调用者面向接口调用,实现者面向接口编写实现。
5.进行大项目开发时,一般都是将项目分离成多模块,模块和模块之间衔接。降低耦合度。
接口的优点:
- 采用接口明确的声明了它所能提供的服务
- 解决了 Java 单继承的问题
- 实现了可接插性(重要)
接口和抽象的区别
主要是语法上的区别,至于使用上的区别,在后期项目中体会学习。
1.抽象类是半抽象的,接口是完全抽象的。
2.抽象类中有构造方法,接口中没有构造方法。
3.接口和接口之间支持多继承,类和类之间只能单继承。
4.一个类可以实现多个接口,一个抽象类只能继承一个类(单继承)。
5.接口中只允许出现常量和抽象方法。
a) 接口描述了方法的特征,不给出实现,一方面解决 java 的单继承问题,实现了强大的可接插性
b) 抽象类提供了部分实现,抽象类是不能实例化的,抽象类的存在主要是可以把公共的代码移植到抽象类中
c) 面向接口编程,而不要面向具体编程(面向抽象编程,而不要面向具体编程)
d) 优先选择接口(因为继承抽象类后,此类将无法再继承,所以会丧失此类的灵活性)
类之间的关系(先不学)
- 泛化关系:类和类之间的继承关系及接口与接口之间的继承关系
- 实现关系:类对接口的实现
- 关联关系:类与类之间的连接,一个类可以知道另一个类的属性和方法,在 java 语言中使用成员变量体现 。
- 聚合关系:是关联关系的一种,是较强的关联关系,是整体和部分的关系,如:汽车和轮胎,它与关联关系不同,关联关系的类处在同一个层次上,而聚合关系的类处在不平等的层次上,一个代表整体,一个代表部分,在 java 语言中使用实例变量体现
- 合成关系 :是关系的一种,比聚合关系强的关联关系,如:人和四肢,整体对象决定部分对象的生命周期,部分对象每一时刻只与一个对象发生合成关系,在 java语言中使用实例变量体现 。
- 依赖关系:依赖关系是比关联关系弱的关系,在 java 语言中体现为返回值,参数,局部变量和静态方法调用 。
is a(继承)、has a(关联)、like a(实现)
is a:(继承)
Cat is a Animal(猫是一个动物)
凡是能够满足is a的表示“继承关系”
Cat extends Animalhas a:(关联)
I has a Pen(我有一支笔)
customer has a foodmenu
凡是能够满足has a关系的表示“关联关系”
关联关系通常以“属性”的形式存在。
costomer{
Foodmenu foodmenu;
}
like a: (实现)
Cooker like a FoodMenu(厨师像一个菜单一样)
凡是能够满足like a关系的表示“实现关系”
实现关系通常是:类实现接口。
A implements B
Object类
定义:
a) Object 类是所有 Java 类的根基类
b) 如果在类的声明中未使用 extends 关键字指明其基类,则默认基类为 Object 类
Object类中的常用方法:
protected Object clone() //负责对象克隆
int hashCode() //获取对象哈希值的方法
boolean equals(object obj) //判断两个对象是否相等
String toString() //将对象转换成字符串形式
protected void finalize() //垃圾回收器负责调用的方法
toString()
定义:返回该对象的字符串表示。
通常 toString 方法会返回一个“以文本方式表示”此对象的字符串, Object 类的 toString 方法返回一个字符串,
该字符串由类名加标记@和此对象哈希码的无符号十六进制表示组成
源代码:Object 类 toString 源代码如下:
public String toString(){
return getClass().getName() + ‘@’ + Integer.toHexString(hashCode())
}
eg:
Person@757aef(类名@对象的内存地址转换为十六进制的形式)
作用:
- 通过调用这个方法可以将一个java对象转换成字符串表示形式。
- 建议所有子类都重写toString()方法。toString()方法应该是一个简洁的,详实的,已阅读的。
输出引用时,会自动调用该引用的toString()方法。-> System.out.println(引用);
==与euals方法
equals是判断:两个变量或者实例指向同一个内存空间的值是不是相同
(如果没有重写,equals比较的也是内存地址)
==是判断:两个变量或者实例是不是指向同一个内存空间
通俗的讲:==是判断两个人是不是住在同一个地址,而equals是判断同一个地址里住的人是不是同一个。 ```java //实际上String也是一个类,不属于基本数据类型 //既然String是一个类,那么一定存在构造方法。 //String类中 已经重写了euqals()方法。⭐⭐⭐int a=10;int b=10;String str1=new String("justice");String str2=new String("justice");String str3;str3=str1;//a和b都是基本数据类型,变量存储值,所以==为true,基本数据类型无equals方法(没有意义)System.out.println(a==b);//str1和str2都是String类型,属于引用类型,变量存储地址,所以==为false,equals为trueSystem.out.println(str1==str2);System.out.println(str1.equals(str2));//创建str3的时候,str3指向了str1,所以str1和str3的指向同一个地址,存储的数据自然相同,所以均为trueSystem.out.println(str1==str3);System.out.println(str1.equals(str3));
}
**源代码:**<br />public boolean euqals(object obj){<br />return (this==obj);<br />}<br />**作用:**1.判断两个对象是否相等。<br /> 2.根据需求选择equals()方法;<br />**总结: 1.**JAVA中什么类型的数据可以使用"=="判断?<br /> Java中基本数据类型比较是否相等,使用==。<br /> 2.JAVA中什么类型的数据需要使用equals()判断?<br /> java中所有的引用数据类型统一使用equals()方法来判断是否相等。重写toString()方法和equals()方法例题:(P373)<a name="CFKpJ"></a>####<a name="JUo6a"></a>####<a name="V63Vj"></a>### finalize (了解)**定义:**垃圾回收器(Garbage Collection),也叫 GC<br />**源码:**protected void finalize() throws Throwable()<br />这个方法只有一个方法体,里面没有代码。**特点:**1.当对象不再被程序使用时,垃圾回收器将会将其回收,不需要程序员手动调用。只需要将其重写,<br /> 将来自动会有程序来调用。<br />2.垃圾回收是在后台运行的,我们无法命令垃圾回收器马上回收资源,<br /> 但是我们可以告诉他,尽快回收资源(System.gc 和Runtime.getRuntime().gc())<br />3.垃圾回收器在回收某个对象的时候,首先会调用该对象的 finalize 方法<br />4.GC 主要针对堆内存<br />5.单例模式的缺点<a name="1Df1u"></a>### 包和 import<a name="Kb6ac"></a>#### 1.包(package):**定义:**package是java中的包机制,包其实就是目录,特别是项目比较大, java 文件特别多的情况下,<br /> 我们应该分目录管理,在 java中称为分包管理,包名称通常采用小写<br />**作用:**为了方便程序的管理,不同功能的类分别存放在不同的包下。(按照功能划分的,不同的软件包具有不同的功能。)**知识点:**1.包名最好采用小写字母<br /> 2.包的命名有规则,不能重复,一般采用公司网站的逆序(因为公司域名具有全球唯一性。)。<br />如: package com.bjpowernode.项目名称.模块名称.功能名<br /> package com.bjpowernode.exam<br /> 3.package 必须放到 所有语句的第一行,注释除外。<a name="eUVRi"></a>#### 2.import**什么时候用?**<br />当A类中使用B类,<br />A类和B类都在同一个包下,不需要import。<br />A类和B类不在一个包下,需要使用import。<br />**怎么用?**<br />import语句只能出现在package语句之下,class之上。<br />import还可以使用 import xx.xx.*; 表示导入该包下的所有类。<a name="R2Qjq"></a>#### 3.JDK常用开发包1.java.lang,此包 Java 语言标准包,使用此包中的内容无需 import 引入,自动导入。<br />2.java.sql,提供了 JDBC 接口类<br />3.java.util,提供了常用工具类<br />4.java.io,提供了各种输入输出流<a name="RP3u7"></a>### 访问控制权限**定义:**java 访问级别修饰符主要包括: private protected 和 public,可以限定其他类对该类、属性和方法的使用权限。**知识点:**<br />1. ⭐:以上对类和接口的修饰只有: public 和 default, 内部类除外<br /> default就是什么都不写,写上语法错误。<br />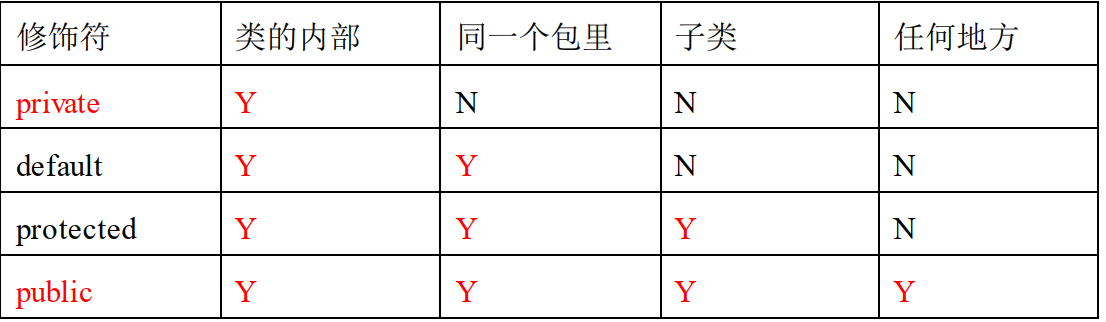<br />2.private 私有的,只能在本类中访问,<br /> public 公共的,在哪都可以访问。<br /><a name="nZURt"></a>### 内部类**定义:**在一个类的内部定义的类,称为内部类。<br />**内部类的分类**:静态内部类(类似于静态变量)<br /> 实例内部类(类似于实例变量)<br /> 局部内部类(类似于局部变量)<br />使用内部类编写的代码,可读性很差,能不用就别用。<a name="BOPCJ"></a>#### 匿名内部类定义:是局部内部类的一种,因为这个类没有名字,所以叫匿名内部类。```javapublic static void main(String[] args){MyMath m1 = new Mymath();m1.mySum(new ComputeImpl(),1,2);//用匿名内部类改写以上代码,可以不写实现类,不建议使用!代码太乱,可读性差,无法重复使用。m1.mySum(new Compute(){public int sum(int a,int b){return a+b;}},1,2);}interface Compute{int sum(int a,int b);}class ComputeImpl implements Compute{public int sum(int a,int b){return a+b;}}public class MyMath{public void mySum(Compute c,int a,int b){sout(c.sum(a,b));}}
进阶-数组
1.数组概要
定义:数组是一种引用数据类型。
内存中存储示意图:
知识点:1.数组是一组数据的集合。
2.数组作为一种引用类型,在堆内存中分配,父类是object。
3.数组元素的类型可以是基本类型,也可以是引用类型,但同一个数组只能是同一种类型。
4.数组作为对象。数组中的元素作为对象的属性,除此之外数组还包括一个成员属性length,
length表示数组的长度。
5.数组的长度在数组创建之后就确定了,就无法再修改了。
6.数组元素是有下标的,下标从0开始,也就是第一个元素的下标为0,最后一个元素的下标为n-1,
我们可以通过数组的下标来访问数组的元素。
7.数据当中如果存储的是“Java对象”的话,实际上存储的是对象的“引用(内存地址)”。
8.数组在内存中存储的时候,数组中的元素内存地址是连续(每一个元素都是有规则的挨着排列)的,
这是数组存储元素的特点,数组实际上是一种简单的数据结构。
9.数组中的第一个元素的内存地址就是整个数组对象的内存地址。
因为数组中的内存地址是连续的,有了第一个就能得到后面的。
10.数组的优缺点:
优点:
查询/查找/检索某个下标上的元素时效率极高,可以说是查询效率最高的一个数据结构。
why?
第一:每一个元素的内存地址在空间存储上是连续的。
第二:每一个元素的类型相同,所以占用的空间大小一样。
第三:知道第一个元素内存地址,知道每一个元素占用空间的大小,又知道下标,所以通过一个数学表达式就可以计算出某个下标上的元素的内存地址。直接通过地址定位元素。
所以数组的检索效率是最高的。
数组中存储100个元素和存储100W个元素,在元素查询/检索方面,效率是相同的,
因为数组中元素查找的时候不会一个一个找,是通过数学表达式计算出来的。
缺点:
第一:为了保证数组中每个元素的内存地址连续,所以在数组上随机删除或者增加元素的时候,效率较低,因为随机增删元素会涉及到后面元素统一向前或者向后位移的操作。
⭐:对于数组中最后一个元素的增删,是没有效率影响的。
第二:数组不能存储大数据量,why?
因为很难在内存空间上找到一块特别大的连续的内存空间。
2.一维数组的声明和使用
数组的声明:
格式:1.数组元素的类型[] 变量名称; (常用)
eg: int[] a;
int[] a,b,c;
Student[] stu;
2.数组元素的类型 变量名称[]
数组的初始化:
静态初始化:
int[] array = {100,200,300,400};
动态初始化:
int[] array = new int[5]; //这里的5表示初始化一个长度为5的int类型数组,每个元素默认为0.
String[] nmaes = new String[6]; //这里的6表示初始化一个长度为6的Stirng类型数组,每个元素默认为null.
什么时候采用静态初始化?什么时候采用动态初始化?
当你创建数组的时候,已知数组中存储哪些元素,采用静态初始化。
当你创建数组的时候,不确定数组中存储哪些元素,采用动态初始化,预先分配内存空间。
一维数组的遍历:
🏀//静态初始化int[] a ={1,2,5,6};//动态初始化int[] a = new int[4];a[0]=1;🏀//一维数组的遍历for (int i=0;i<a.length;i++){System.out.println(a[i]);}倒着遍历for (int i = a.length-1;i>=0;i--){System.out.println(a[i]);}🏀//存储Object对象1.第一种方式:Object o1 = new Object();Object o2 = new Object();Object o3 = new Object();Object[] objects = {o1,o2,o3};2.第二种方式:Object[] objects = {new Object(),new Object(),new Object()};for (int i=0;i<objects.length;i++){System.out.println(objects[i]);}🏀//数组下标越界,会抛出ArrayIndexOutOfBoundsException 异常!System.out.println("data[4]=" + data[4]); // 错误✖🏀//方法的参数是数组时,如何传参?public static void printArray(int[] array){for (int i=0;i<array.length;i++){System.out.println(array[i]);}}int[] x={1,2,3,5};ArrayTest02.printArray(x);1.如果想直接传递一个静态数组printArray(new int[]{1,2,3});2.想直接传递动态的可以直接传printArray(new int[3]);
引用数据类型的数组:
package day22.onearray;import test06.Car;//对于数组来说,实际上只能存储java对象的“内存地址”,数组中存储的每个元素是“引用”。public class ArrayTest03 {public static void main(String[] args) {Animal a1 = new Animal();Animal a2 = new Animal();/* Animal型的数组只能存储Animal类型的,Product类型的不可以Product p1 = new Product();✖ Animal[] animals ={a1,a2,p1};*//*静态初始化:Animal[] animals ={a1,a2};*///动态初始化一个长度为2的Animal类型的数组Animal[] animals = new Animal[2];animals[0]=a1;//Animal数组中可以存储Cat类型的数据,因为Cat是Animal的子类,是一个Animal。animals[1]=new Cat();for (int i=0;i<animals.length;i++){/* Animal a = animals[i];a.move();*///代码合并animals[i].move();}Animal[] anis = new Animal[2];anis[0]=new Cat();anis[1]=new Bird();for (int i=0;i<anis.length;i++){//如果调用的是父类中存在的方法不需要向下转型。anis[i].move();//如果是子类特有的方法需要向下转型if (anis[i] instanceof Cat){Cat c = (Cat)anis[i];c.catchMouse();}else if (anis[i] instanceof Bird){Bird b = (Bird)anis[i];b.sing();}}}}class Animal{public void move(){System.out.println("Animal move....");}}class Product{public void mai(){System.out.println("被买了1");}}class Cat extends Animal{@Overridepublic void move() {System.out.println("Cat move.....");}public void catchMouse(){System.out.println("猫抓老鼠!");}}class Bird extends Animal{@Overridepublic void move() {System.out.println("鸟儿飞.....");}public void sing(){System.out.println("鸟儿在歌唱!");}}
一维数组的扩容与拷贝:
在java开发中,数组长度一旦确定不可变,那如果数组满了怎么办?
数组满了,需要进行扩容。
扩容方法:先新建一个大容量的数组,然后将小容量数组中的数据一个一个拷贝到大数组中。
结论:数组扩容效率较低,因为涉及到数组拷贝问题。所以在今后的开发中请注意:尽可能少的进行数组的拷贝。
可以在创建数组对象的时候预估计一下多长合适,这样可以减少数组的扩容次数,提高效率。
拷贝:
源码:public static native void arraycopy(Object src, int srcPos, Object dest, int destPos,int length);
参数:
src:要复制的数组(源数组)
srcPos:复制源数组的起始位置
dest:目标数组
destPos:目标数组的下标位置
length:要复制的长度
eg: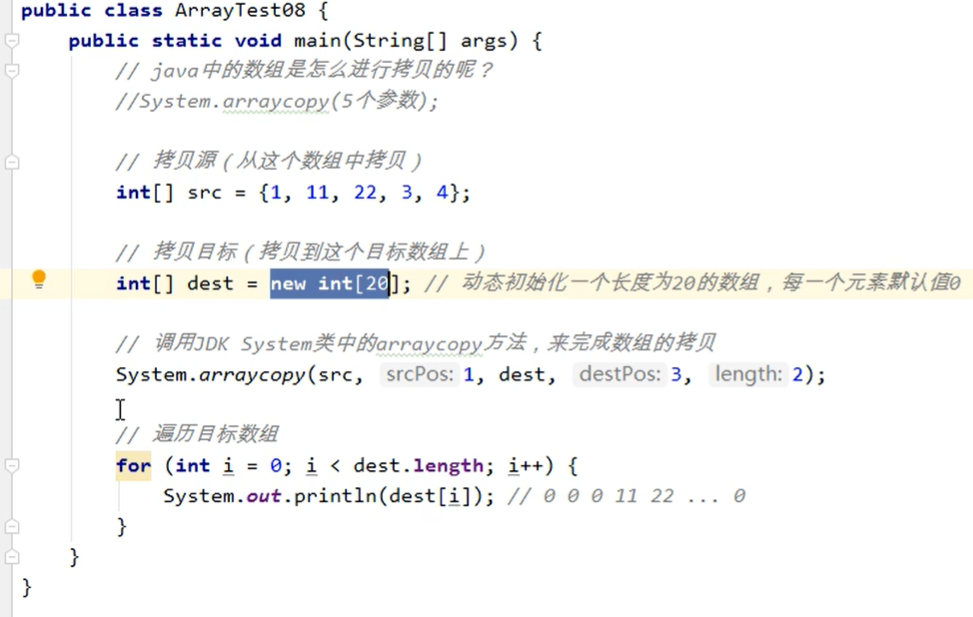
3.二维数组的声明和使用
数组的声明:
二维数组其实是一个特殊的一维数组,特殊在这个一维数组当中的每一个元素是一个一维数组。
1. 数组元素的数据类型[][] 变量名;
2. 数组元素的数据类型 变量名[][];
其中方括号的个数就是数组的维数,
声明二维数组如下:int [][] data;
数组的初始化
静态初始化:
int[][] array = {{100,200},{300,400},{500}};
读:
a[二维数组中的一维数组的下标][一维数组的下标]
a[0][0]:表示第一个一维数组的第一个元素。
改:
a[2][1]=666;
动态初始化:
int[][] array = new int[5][4]; //五行四列,每一个一维数组中有4个元素。
二维数组的遍历
package day22.onearray;public class ArrayTest04 {public static void main(String[] args) {String[][] array={{"java","c++","c#","python"},{"zs","ls","ww"},{"james","kobe","paul"}};//外层循环3次(负责纵向)for (int i=0;i<array.length;i++){//内层循环负责输出一行for (int j=0;j<array[i].length;j++){System.out.println(array[i][j]);//第i个一维数组的第j个元素}System.out.println();}}}
4.数组的排序
冒泡排序(以后再看)
选择排序(以后再看)
5.数组的搜索
二分法查找(以后再看)
6.Arrays工具类
SUN公司已经为我们程序员写好了一个数组工具类:java.util.Arrays;
介绍:所有方法都是静态的,直接用类名调用
主要使用两个方法:二分法查找(Arrays.binarySearch)
排序(Arrays.sort)
进阶-常用类
String类
java.lang.String
- String类表示字符串类型,属于引用数据类型,不属于基本数据类型。
- 在java中用双引号括起来的都是String对象。
- java中规定,双引号括起来的字符串,是不可变的,也就是说“abc”自出生到死亡不可变。如果对字符串修改,那么将会创建新的对象。
- 面试题:String为什么是不可变的?
我看过源代码,String类中有一个byte[]数组,这个byte[]数组采用了final修饰,
因为数组一旦创建长度不可变,并且被final修饰的引用一旦指向某个对象之后,
不可再指向其他对象,所以String是不可变的。
- 面试题:StringBuilder/StringBuffer为什么是可变的?
我看过源代码,StringBuilder/StringBuffer内部实际上是一个byte[]数组,没有被final修饰,StringBuilder/StringBuffer的初始化容量是16,当存满之后,底层调用了数组拷贝的方法arrayCopy()。所以StringBuilder/StringBuffer适合用于字符串拼接。
- 在JDK当中双引号括起来的字符串,“abc””def”都是直接存储在方法区的字符串常量池当中的。
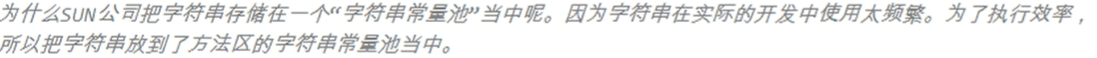
- eg:
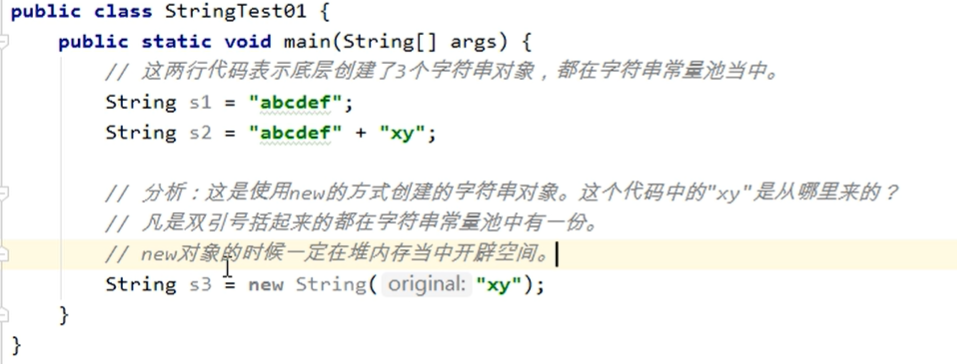
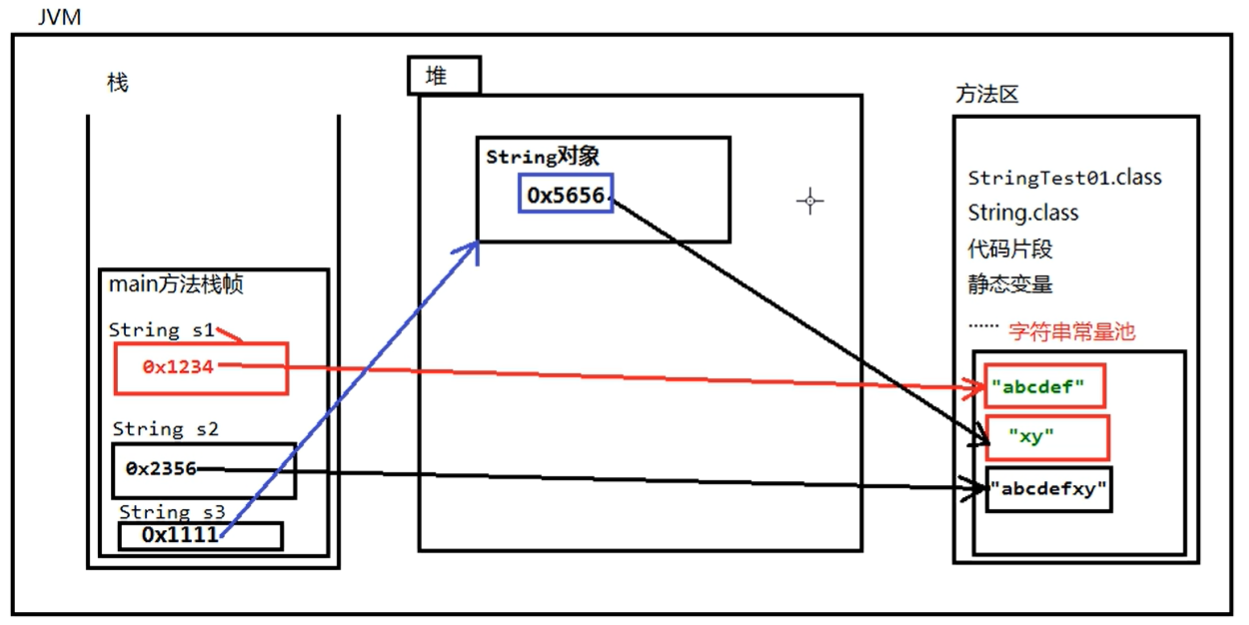
String s1 = “abc”和 String s2 = new String(“abc”):
String s1 = "abc";String s2 = "abc";String s3 = new String("abc");System.out.println("s1==s2, " + (s1==s2)); //tureSystem.out.println("s2==s3, " + (s2==s3)); //falseSystem.out.println("s2 equlas s3," + (s2.equals(s3))) //true
- 如果是采用双引号引起来的字符串常量,首先会到常量池中去查找,如果存在就不再分配,如果不存在就分配,常量池中的数据是在编译期赋值的,也就是生成 class 文件时就把它放到常量池里了,所以 s1 和 s2 都指向常量池中的同一个字符串“abc”
- 关于 s3, s3 采用的是 new 的方式,在 new 的时候存在双引号,所以他会到常量区中查找“abc”,而常量区中存在“abc”,所以常量区中将不再放置字符串,而 new 关键子会在堆中分配内存,所以在堆中会创建一个对象 abc, s3 会指向 abc
如果比较 s2 和 s3 的值必须采用 equals, String 已经对 eqauls 方法进行了覆盖
String类中常用的构造方法
String s = new String(“zs”);
- String s = “zs”; //最常用
- String s= new String(char数组);
- String s = new String(char数组,起始下标,长度);
- String s = new String(byte数组);
String s = new String(byte数组,起始下标,长度);
String类常用方法简介
char charAt(int index) ⭐ //返回索引处字符
char c = “中国人”.charAt(1); //“中国人”是一个字符串String对象,只要是对象就能“点.”.
System.out.println(c); //国
- int compareTo(String anotherString);
会从第一个字母开始比较,如果分出胜负会直接出结果,若相同向后继续比较。
⭐3. boolean contains(CharSequence s) //判断前面的字符串中是否包含后面的子字符串。
System.out.println(“Lebron James”.contains(“James”)); //true
⭐ 4. boolean endsWith(String suffix) //判断当前字符串是否已某个字符串结尾。
System.out.println(“mu.exe”.endsWith(“.exe”)); //true
boolean startWith(String suffix) //判断当前字符串是否已某个字符串开始。
System.out.println(“mu.exe”.endsWith(“mu”)); //true
⭐ 5. boolean equals(Object anObject)//判断两个字符串是否相等,必须使用equals方法,不能使用==。
⭐ 6. boolean equalsIgnoreCase(String anotherString)//判断两个字符串是否相等,并且同时忽略大小写。
System.out.println(“AbC”.equalsIgnoreCase(“abc”));//true
⭐ 7. byte[] getBytes()//将字符串对象转换成字节数组。
byte[] bytes = “abcdef”.getBytes();
for (int i = 0; i
}
⭐ 8. int indexOf(String str) //判断某个子字符串在当前字符串中第一次出现处的索引。
System.out.println(“jameskobedavisjames”.indexOf(“kobe”)); //5
int lastIndexOf(String str) //判断某个子字符串在当前字符串中最后一次出现处的索引。
System.out.println(“jameskobedavisjames”.lastIndexOf(“james”));//14
⭐ 9. boolean isEmpty() //判断某个字符串是否为空
String s=””;
System.out.println(s.isEmpty()); //true
String s = null;
System.out.println(s.isEmpty()); //空指针异常
⭐ 10. int length() //返回此字符串的长度。
System.out.println(“muyuantong”.length());//10
面试题:判断字符串长度与数组长度一样么?
不一样,数组是length属性,字符串是length()方法。
⭐ 10. String replace(char oldChar, char newChar) //返回一个新的字符串,通过newchar替换oldchar得到的。
String s1=”xumuxu”;
System.out.println(s1.replace(‘u’,’m’));//xmmmxm
⭐⭐String replace(CharSequence target, CharSequence replacement)
String s1=”xumuxu”;
System.out.println(s1.replace(“xu”,”mu”));//mumumu
⭐ 11. String[] split(String regex) //拆分字符串
String[] birth=”1999-09-17”.split(“-“);
for (int i = 0; i 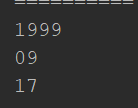
}
⭐ 12. String substring(int beginIndex) //截取字符串
System.out.println(“muyuantong”.substring(2));//yuantong
String substring(int beginIndex, int endIndex) //截取字符串,左闭右开。[begin,end)
(包含begin,不包含end)
System.out.println(“xuyoubo”.substring(2,5));//you 从0开始数
⭐ 12. char[] toCharArray() //将字符串转换为char数组
char[] chars =”我是中国人”.toCharArray();
for (int i = 0; i
}
⭐ 13. String toLowerCase() //转换为小写
System.out.println(“NBA”.toLowerCase());//nba
⭐ 14. String toUpperCase() //转换为大写
System.out.println(“muxu”.toUpperCase());//MUXU
⭐ 15. String trim() //去除字符串前空白与后空白
System.out.println(“ james is NBA player! “.trim());//james is NBA player!
⭐⭐⭐16. static String valueOf() //将“非字符串”转换成“字符串”
String中只有一个方法不需要new对象是static的—-valueOf()
String s6 = String.valueOf(3.14); //将3.14转为字符串输出。
System.out.println(s6);//3.14
//当参数是一个对象时,会自动调用对象的toString()方法么?会
String s9 = String.valueOf(new Customer());System.out.println(s9);//没有重写toString()方法时会输出内存地址:day25_String.Customer@1540e19dSystem.out.println(s9);//我是VIPclass Customer{@Overridepublic String toString() {return "我是VIP";}}
StringBuffer 和 StringBuilder
我们在实际开发中,如果需要频繁的进行字符串拼接,会有什么问题?
因为java中的字符串是不可变的,每一次拼接都会产生新的字符串。
这样会占用大量的方法区内存,造成内存空间的浪费。
eg: String s = “abc”;
s+=”hello”;
//以上两行代码就导致在方法区字符串常量池当中创建了3个对象: “abc” “hello” “abchello”
StringBuffer
定义:称为字符串缓冲区,它的工作原理是:预先申请一块内存,存放字符序列,如果字符序列满了,
会重新改变缓存区的大小,以容纳更多的字符序列。
StringBuffer 是可变对象,这个是与 String 最大的不同。
public class StringBufferTest01 {public static void main(String[] args) {//构造一个没有字符的字符串缓冲区,初始容量为16个字符。StringBuffer stringBuffer = new StringBuffer();//构造一个没有字符的字符串缓冲区,和指定的初始容量。StringBuffer stringBuffer = new StringBuffer(100);//拼接字符串,以后统一调用append()方法//append是追加的意思。//append方法底层在进行追加时,如果byte数组满了,会自动扩容。stringBuffer.append("mu");stringBuffer.append("xu");stringBuffer.append(".");stringBuffer.append(112688);System.out.println(stringBuffer);//muxu.112688}}
如何优化StringBuffer的性能?
在创建StringBuffer的时候尽量给定一个初始化容量。
最好减少底层数组的扩容次数。预估计一下,给一个大一些的初始化容量。
关键点:给一个合适的初始化容量,可以提高程序的执行效率。
StringBuilder
用法同 StringBuffer。
StringBuffer与StringBuilder的区别?
StringBuilder 和 StringBuffer 的区别是
StringBuffer 中所有的方法都是同步的,是线程安全(synchronized)的,但速度慢,
StringBuilder 的速度快,但不是线程安全的。
如果使用局部变量的话
建议使用:StringBuilder。
因为局部变量不存在线程安全问题。选择StringBuilder。
StringBuffer效率比较低。
基本数据类型对应的8个包装类
1.包装类的概述
知识点:
1.Java中为8种基本数据类型又对应准备了8种包装类型,8种包装类属于引用数据类型,父类是Object。
2.思考:为什么要再提供8种包装类呢?
因为8种数据类型不够用。所以SUN又提供对应的8种包装类型。
3. 8种基本数据类型对应的包装类型名是什么?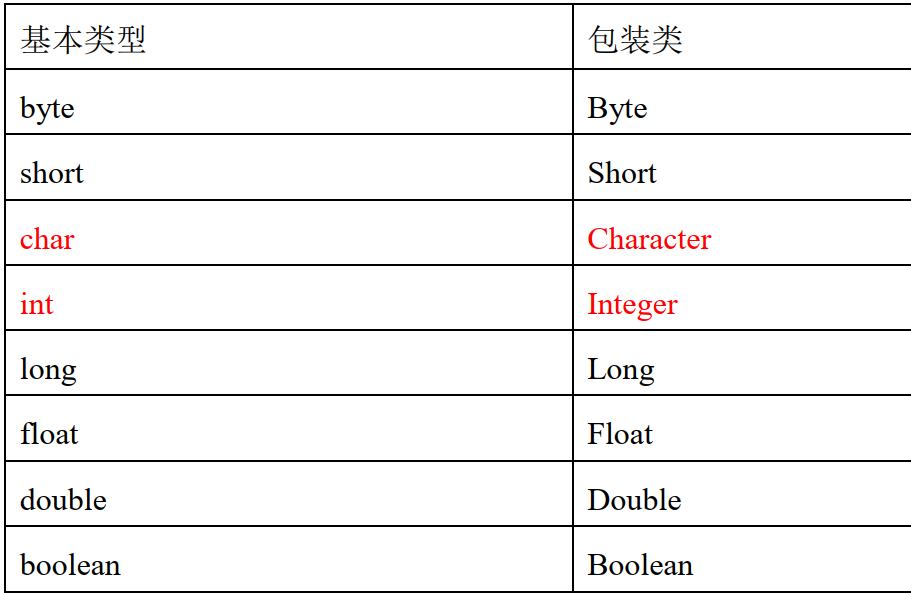
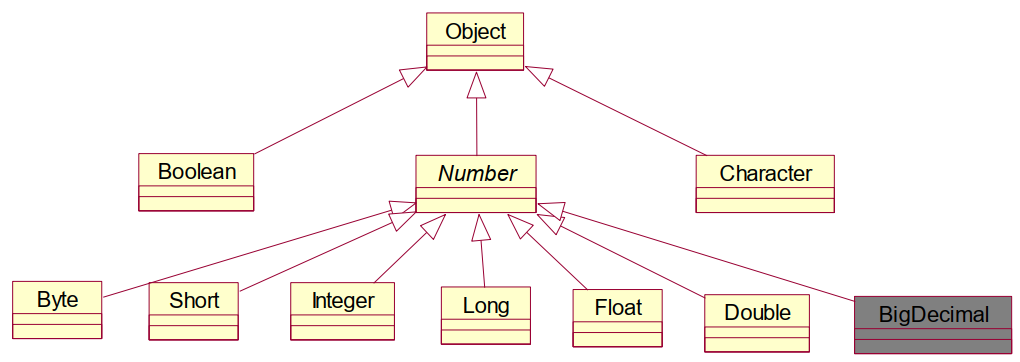
8种包装类中的6个都是数字对应的包装类,他们的父类都是Number,
可以先研究一下Number类中公共的方法:
Number是一个抽象类,无法实例化对象。
//JDK1.5后支持自动装拆箱。
手动装箱(基本数据类型→引用数据类型):Integer i = new Integer(123);
自动装箱:Integer i = 123;
手动拆箱(引用数据类型→基本数据类型)int retValue = i.intValue();
自动拆箱:int retValue = i;
4.. java.lang.Integer (其他包装类照葫芦画瓢)
//构造方法:Integer(int) //将int类型的数字转换成Integer包装类型。Integer(String)//将String类型的数字,转换成Integer包装类型。Integer integer = new Integer(123);System.out.println(integer);//123Integer integer1 = new Integer("123");System.out.println(integer1);//123//通过访问包装类常量,来获取最大值和最小值。System.out.println(Integer.MAX_VALUE);//2147483647System.out.println(Integer.MIN_VALUE);//-2147483648
⭐自动装箱与拆箱(重要面试题)
//自动装箱Integer a = 900;System.out.println(a);//自动拆箱int b = a;System.out.println(b);//为何没报错?+号两边要求是基本数据类型的数字,c是包装类,不属于基本数据类型。使用算术运算符时会进行自动拆箱,将c转换为基本数据类型,所以没报错。Integer c =1000;System.out.println(c+1);//1001// ==因为 d和e 都是引用,保存内存地址指向对象。==比较的是内存地址。Integer d =1000;Integer e=1000;System.out.println(d==e);//false⭐⭐//java中为了提高执行效率,将[-128,127]之间所有的包装对象提前创建好,放到了方法区中的“整数型常量池”中了,目的是只要用这个区间的数据不需要再new了,直接从整数型常量池中取出来。Integer m = 127;Integer n =127;System.out.println(m==n);//true 直接从整形常量池中取得,所以地址一样。
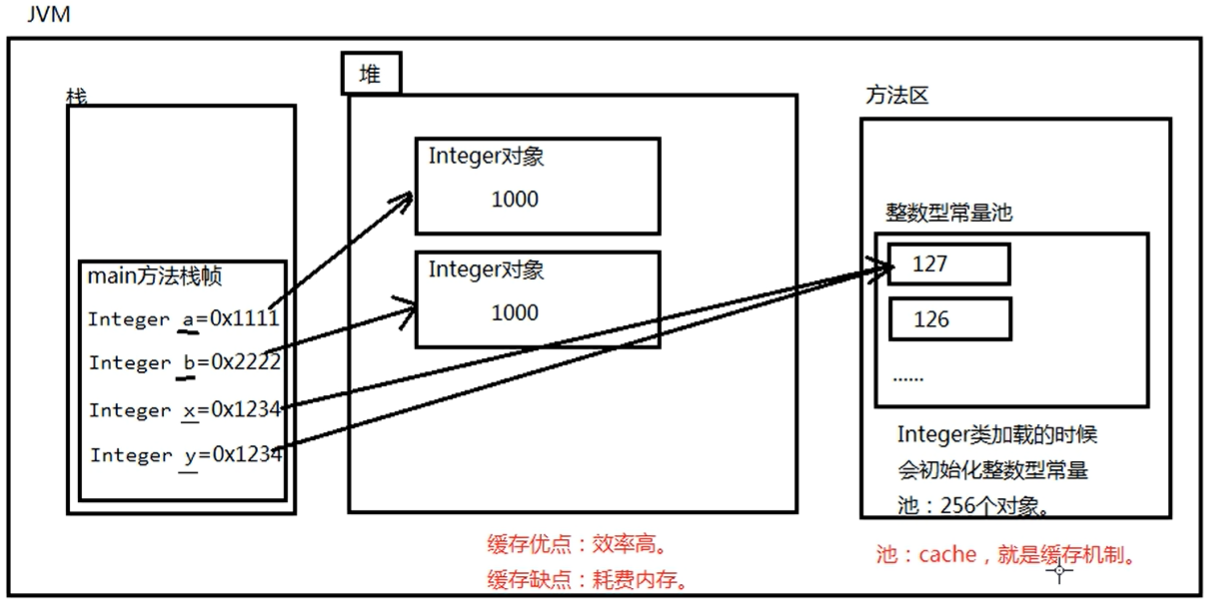
Integer常用方法:
// parseIntstatic int parseInt(String s)//静态方法,传参String,返回int。//网页上文本框中输入的100实际上是“100”字符串,后台数据库要求存储100数字,此时java程序需要将Sting字符串转为int。int x = Integer.parseInt("23");System.out.println(x+10);//33int x = Integer.parseInt("mu");System.out.println(x+10);//java.lang.NumberFormatException(数字格式异常)//valueOf()
插曲:int String Integer 三种类型的互相转换
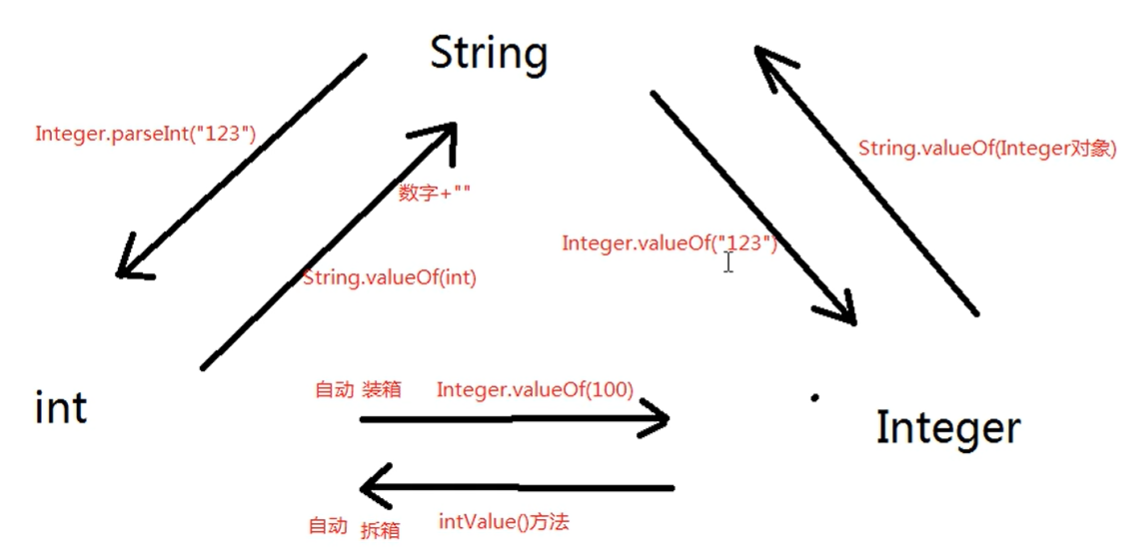
//String→int[Integer.parseInt()]String s1 = "100";int i1 = Integer.parseInt(s1); //将s1变为int类型100System.out.println(i1+1);//101//int→String[数字+""]String s2 = s1 + "";//将s1变为String类型"100"System.out.println(s2+1);//1001//int→Integer[自动装箱]Integer x = 100;//Integer→int[自动拆箱]int y = x;//String→Integer[Integer.valueOf()]Integer m = Integer.valueOf("123");//Integer→String[String.valueOf()]String k = String.valueOf(m);
日期类
<br />1、获取系统当前时间<br /> Date d = new Date();
// 获取系统当前时间(精确到毫秒的系统当前时间)// 直接调用无参数构造方法就行。Date nowTime = new Date();// java.util.Date类的toString()方法已经被重写了。// 输出的应该不是一个对象的内存地址,应该是一个日期字符串。System.out.println(nowTime); //Thu Mar 05 10:51:06 CST 2020
2、日期格式化:Date --> String (format)<br /> yyyy-MM-dd HH:mm:ss SSS<br /> SimpleDateFormat sdf = new SimpleDate("yyyy-MM-dd HH:mm:ss SSS");<br /> String s = **sdf.format**(new Date());
Date d1 = new Date();// 日期可以格式化吗?// 将日期类型Date,按照指定的格式进行转换:Date --转换成具有一定格式的日期字符串-->String// SimpleDateFormat是java.text包下的。专门负责日期格式化的。/*yyyy 年(年是4位)MM 月(月是2位)dd 日HH 时mm 分ss 秒SSS 毫秒(毫秒3位,最高999。1000毫秒代表1秒)注意:在日期格式中,除了y M d H m s S这些字符不能随便写之外,剩下的符号格式自己随意组织。*/SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");//SimpleDateFormat sdf = new SimpleDateFormat("dd/MM/yyyy");//SimpleDateFormat sdf = new SimpleDateFormat("yy/MM/dd HH:mm:ss");String s= sdf.format(d1);System.out.println(s);//2021-04-22 10:51:47
3、String --> Date (parse)<br /> SimpleDateFormat sdf = new SimpleDate("yyyy-MM-dd HH:mm:ss");<br /> Date d = **sdf.parse**("2008-08-08 08:08:08");
String time = "1997-12-26 12:25:30";//("格式不能随便写,要和日期字符串格式相同");⭐注意:字符串的日期格式和SimpleDateFormat对象指定的日期格式要一致。不然会出现异常:java.text.ParseExceptionSimpleDateFormat sdf2 = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");Date d = sdf.parse(time);System.out.println(d);//Fri Dec 26 12:25:30 CST 1997
4、获取毫秒数<br /> long begin = System.currentTimeMillis();<br /> Date d = new Date(begin - 1000 * 60 * 60 * 24);//获取昨天的当前时间
统计执行一个方法耗费时间:
package com.bjpowernode.javase.date;/*获取自1970年1月1日 00:00:00 000到当前系统时间的总毫秒数。1秒 = 1000毫秒简单总结一下System类的相关属性和方法:System.out 【out是System类的静态变量。】System.out.println() 【println()方法不是System类的,是PrintStream类的方法。】System.gc() 建议启动垃圾回收器System.currentTimeMillis() 获取自1970年1月1日到系统当前时间的总毫秒数。System.exit(0) 退出JVM。*/public class DateTest02 {public static void main(String[] args) {// 获取自1970年1月1日 00:00:00 000到当前系统时间的总毫秒数。long nowTimeMillis = System.currentTimeMillis();System.out.println(nowTimeMillis); //1583377912981⭐⭐// 统计一个方法耗时long begin = System.currentTimeMillis(); // 在调用目标方法之前记录一个毫秒数print();long end = System.currentTimeMillis(); // 在执行完目标方法之后记录一个毫秒数System.out.println("耗费时长"+(end - begin)+"毫秒");}// 需求:统计一个方法执行所耗费的时长public static void print(){for(int i = 0; i < 1000000000; i++){System.out.println("i = " + i);}}}
通过毫秒构造Date()对象
package com.bjpowernode.javase.date;import java.text.SimpleDateFormat;import java.util.Date;public class DateTest03 {public static void main(String[] args) {// 这个时间是什么时间?// 1970-01-01 00:00:00 001Date time = new Date(1); // 注意:参数是一个毫秒SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss SSS");String strTime = sdf.format(time);// 北京是东8区。差8个小时。System.out.println(strTime); // 1970-01-01 08:00:00 001// 获取昨天的此时的时间。//当前毫秒数减去24个小时的毫秒数Date time2 = new Date(System.currentTimeMillis() - 1000 * 60 * 60 * 24);String strTime2 = sdf.format(time2);System.out.println(strTime2); //2020-03-04 11:44:14 829// 获取“去年的今天”的时间// 自己玩。}}
数字类
数字格式化
package com.bjpowernode.javase.number;import java.text.DecimalFormat;/*关于数字的格式化。(了解)*/public class DecimalFormatTest01 {public static void main(String[] args) {// java.text.DecimalFormat专门负责数字格式化的。//DecimalFormat df = new DecimalFormat("数字格式");/*数字格式有哪些?# 代表任意数字, 代表千分位. 代表小数点0 代表不够时补0###,###.##表示:加入千分位,保留2个小数。*/DecimalFormat df = new DecimalFormat("###,###.##");//String s = df.format(1234.56);String s = df.format(1234.561232);System.out.println(s); // "1,234.56"DecimalFormat df2 = new DecimalFormat("###,###.0000"); //保留4个小数位,不够补上0String s2 = df2.format(1234.56);System.out.println(s2); // "1,234.5600"}}
BigDecimal 可以精确计算,特别是财务数据
package com.bjpowernode.javase.number;import java.math.BigDecimal;/*1、BigDecimal 属于大数据,精度极高。不属于基本数据类型,属于java对象(引用数据类型)这是SUN提供的一个类。专门用在财务软件当中。2、注意:财务软件中double是不够的。咱们之前有一个学生去用友面试,经理就问了这样一个问题:你处理过财务数据吗?用的哪一种类型?千万别说double,说java.math.BigDecimal*/public class BigDecimalTest01 {public static void main(String[] args) {// 这个100不是普通的100,是精度极高的100BigDecimal v1 = new BigDecimal(100);// 精度极高的200BigDecimal v2 = new BigDecimal(200);// 求和// v1 + v2; // 这样不行,v1和v2都是引用,不能直接使用+求和。BigDecimal v3 = v1.add(v2); // 调用方法求和。System.out.println(v3); //300BigDecimal v4 = v2.divide(v1);//除法System.out.println(v4); // 2}}
Random
/*** 随机数*/public class RandomTest01 {public static void main(String[] args) {// 创建随机数对象Random random = new Random();// 随机产生一个int类型取值范围内的数字。int num1 = random.nextInt();System.out.println(num1);// 产生[0~100]之间的随机数。不能产生101。// nextInt翻译为:下一个int类型的数据是101,表示只能取到100.int num2 = random.nextInt(101); //不包括101System.out.println(num2);//生成 5 个 0~100 之间的整数随机数Random r1 = new Random();for (int i = 0; i <5 ; i++) {System.out.println(r1.nextInt(101));}}}
未学:P464
/*编写程序,生成5个不重复的随机数[0-100]。重复的话重新生成。最终生成的5个随机数放到数组中,要求数组中这5个随机数不重复。*/public class RandomTest02 {public static void main(String[] args) {// 创建Random对象Random random = new Random();// 准备一个长度为5的一维数组。int[] arr = new int[5]; // 默认值都是0for(int i = 0; i < arr.length; i++){arr[i] = -1;}// 循环,生成随机数int index = 0;while(index < arr.length){// 生成随机数//int num = random.nextInt(101);//int num = random.nextInt(6); // 只能生成[0-5]的随机数!int num = random.nextInt(4); // 只能生成[0-3]的随机数!永远都有重复的,永远都凑不够5个。System.out.println("生成的随机数:" + num);// 判断arr数组中有没有这个num// 如果没有这个num,就放进去。if(!contains(arr, num)){arr[index++] = num;}}// 遍历以上的数组for(int i = 0; i < arr.length; i++){System.out.println(arr[i]);}}/*** 单独编写一个方法,这个方法专门用来判断数组中是否包含某个元素* @param arr 数组* @param key 元素* @return true表示包含,false表示不包含。*/public static boolean contains(int[] arr, int key){/*// 这个方案bug。(排序出问题了。)// 对数组进行升序//Arrays.sort(arr);// 进行二分法查找// 二分法查找的结果 >= 0说明,这个元素找到了,找到了表示存在!//return Arrays.binarySearch(arr, key) >= 0;*/for(int i = 0; i < arr.length; i++){if(arr[i] == key){// 条件成立了表示包含,返回truereturn true;}}// 这个就表示不包含!return false;}}
Enum
知识点
1、枚举是一种引用数据类型
2、枚举类型怎么定义,语法是?
enum 枚举类型名{
枚举值1,枚举值2
}
3、结果只有两种情况的,建议使用布尔类型。
结果超过两种并且还是可以一枚一枚列举出来的,建议使用枚举类型。
例如:颜色、四季、星期等都可以使用枚举类型。
进阶-异常处理
异常的基本概念
定义:在程序运行过程中出现的错误,称为异常。
作用:增强程序的健壮性。
java语言中异常是以什么形式存在的?
1.以类的形式存在,每一个异常类都可以创建对象。
2.异常在生活中的实例?
火灾(异常类):
小明家着火(异常对象)
小刚家着火(异常对象)
异常的层次结构(P473)
异常在java中以类和对象的形式存在。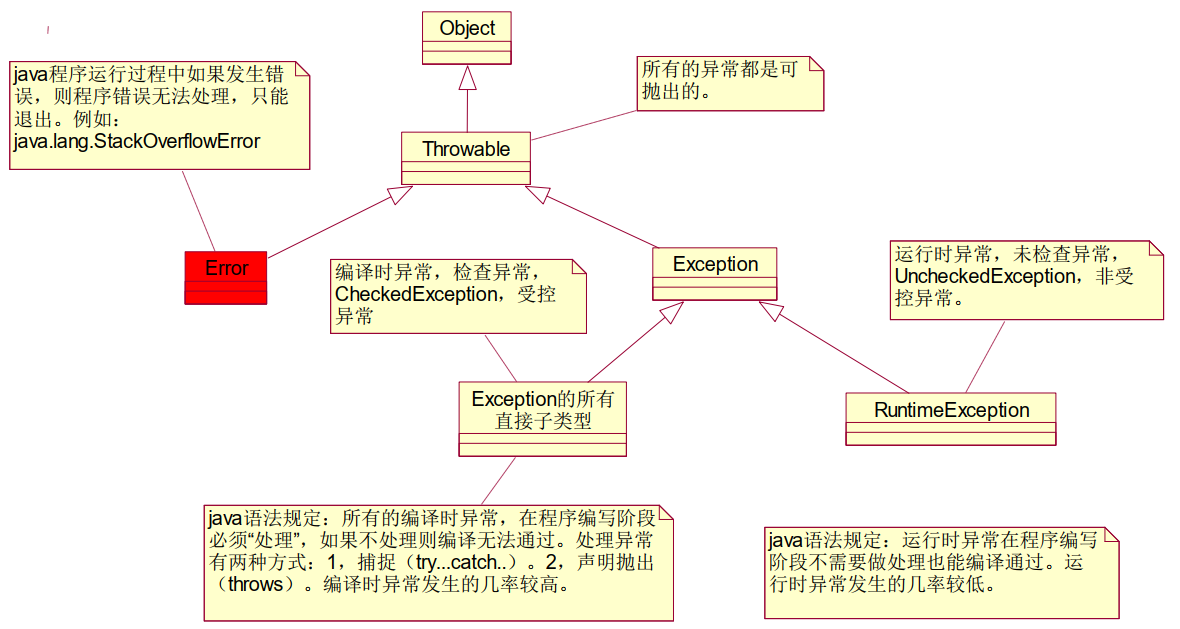
- 异常的层次结构
Object下有Throwable(可抛出的)
Throwable下有两个分支:Error(不可处理的,直接退出JVM)和Exception(可处理的)。
Exception下有两个分支:
Exception的所有直接子类:编译时异常(在程序编写阶段必须处理)。
RuntimeException(运行时异常)
- 编译时异常和运行时异常,都是发生在运行阶段。编译阶段异常是不会发生的。
编译时异常是因为必须在编译前预先处理,不处理编译器报错所以得名。
所有异常都是在运行阶段发生的,因为只有程序运行阶段才可以 new对象。异常的发生就是new对象。
- 编译时异常与运行时异常的区别
编译时异常:发生概率比较高。
eg:你看到外面下雨了,倾盆大雨。
你出门前会预料到:如果不打伞,我可能会生病(生病是一种异常)。
而且这个异常发生的概率很高,所以我们出门之前要拿一把伞。
“拿一把伞”就是对“生病异常”发生之前的一种处理方式。
对于一些发生概率较高的异常,需要在运行之前对其进行预处理。
运行时异常:发生的概率比较低。
eg:你去打篮球,被篮球架砸了。
被篮球架砸也算一种异常。但是这种异常发生的概率极低。
再出门之前你没必要提前对这种异常进行预处理。
4.假设java中没有对异常进行划分,没有分为:编译时异常和运行时异常。所有的异常都需要在编写阶段进行预处理,将会发生什么?
首先,程序会绝对的安全。但是,程序员会很累,到处都是处理异常的代码。
5 编译时异常—检查异常—受控异常(CheckedException)
运行时异常—未检查异常—非受控异常(UnCheckedException)
6 Java语言对异常处理的两种方式:
a. 在方法声明的位置上,使用throws关键字。(谁调用我,我就抛给谁。抛给上一级。)
b. 使用try..catch语句进行异常的捕捉。(这件事发生了,谁也不知道,因为我给抓住了。)
举个例子: 我是某集团的一个销售员,因为我的失误,导致公司损失了1000元,
“损失1000元”这可以看做是一个异常发生了。我有两种处理方式,
第一种方式:我把这件事告诉我的领导【异常上抛】
第二种方式:我自己掏腰包把这个钱补上。【异常的捕捉】
思考:异常发生之后,如果我选择了上抛,抛给了我的调用者,
调用者需要对这个异常继续处理,那么调用者处理这个异常同样用这两种处理方式。
比如:我处理不了1000块钱这个异常,我就要抛给李四,李四如果能处理就处理,处理不了他就要抛给王五,王五处理不了就抛给CEO,
CEO处理不了,就只能倒闭。 张三 —> 李四 —-> 王五 —> CEO
7 注意:Java中异常发生之后如果一直上抛,最终抛给了main方法,
main方法继续 向上抛,抛给了调用者JVM,
JVM知道这个异常发生,只有一个结果。终止java程序的执行。
方法声明位置使用throws:
/*以下代码报错的原因是什么?因为doSome()方法声明位置上使用了:throws ClassNotFoundException而ClassNotFoundException是编译时异常。必须编写代码时处理,没有处理编译器报错。*/public class ExceptionTest04 {public static void main(String[] args) {// main方法中调用doSome()方法// 因为doSome()方法声明位置上有:throws ClassNotFoundException// 我们在调用doSome()方法的时候必须对这种异常进行预先的处理。// 如果不处理,编译器就报错。//编译器报错信息: Unhandled exception: java.lang.ClassNotFoundExceptiondoSome();}/*** doSome方法在方法声明的位置上使用了:throws ClassNotFoundException* 这个代码表示doSome()方法在执行过程中,有可能会出现ClassNotFoundException异常。* 叫做类没找到异常。这个异常直接父类是:Exception,所以ClassNotFoundException属于编译时异常。* @throws ClassNotFoundException*/public static void doSome() throws ClassNotFoundException{System.out.println("doSome!!!!");}}第一种方式(throws)://上抛类似于推卸责任。(继续把异常传给调用者。)public static void main(String[] args) throws ClassNotFoundException {doSome();}public static void doSome() throws ClassNotFoundException{System.out.println("dosome!");}第二种方式(try..catch)://捕捉类似于承担责任,异常真正的解决了。public static void main(String[] args) {try {doSome();} catch (ClassNotFoundException e) {e.printStackTrace();}}public static void doSome() throws ClassNotFoundException{System.out.println("dosome!");}
throws与try..catch
处理异常的第一种方式:在方法声明的位置上使用throws关键字抛出,谁调用我这个方法,我就抛给谁。抛给调用者来处理。这种处理异常的态度:上报。处理异常的第二种方式:使用try..catch语句对异常进行捕捉。这个异常不会上报,自己把这个事儿处理了。异常抛到此处为止,不再上抛了try {// try尝试m1();// 以上代码出现异常,直接进入catch语句块中执行。System.out.println("hello world!");} catch (FileNotFoundException e){ // catch后面的好像一个方法的形参。// 这个分支中可以使用e引用,e引用保存的内存地址是那个new出来异常对象的内存地址。// catch是捕捉异常之后走的分支。// 在catch分支中干什么?处理异常。System.out.println("文件不存在,可能路径错误,也可能该文件被删除了!");System.out.println(e); //java.io.FileNotFoundException: D:\course\01-课\学习方法.txt (系统找不到指定的路径。)}⭐注意:只要异常没有捕捉,采用上报的方式,此方法的后续代码不会执行。另外需要注意,try语句块中的某一行出现异常,该行后面的代码不会执行。try..catch捕捉异常之后,后续代码可以执行。//例子/*运行结果:main beginm1 beginm2 begin捕捉了异常main over*/public static void main(String[] args) {// 一般不建议在main方法上使用throws,因为这个异常如果真正的发生了,一定会抛给JVM。JVM只有终止。// 异常处理机制的作用就是增强程序的健壮性。怎么能做到,异常发生了也不影响程序的执行。所以// 一般main方法中的异常建议使用try..catch进行捕捉。main就不要继续上抛了。System.out.println("main begin");try {m1();System.out.println("hello");//不会执行。} catch (FileNotFoundException e) {// 这个分支中可以使用e引用,e引用保存的内存地址是那个new出来异常对象的内存地址。System.out.println("捕捉了异常");System.out.println(e);//java.io.FileNotFoundException: D:\course\01-开课\学习方法.txt (系统找不到指定的路径。)}// try..catch把异常抓住之后,这里的代码会继续执行。System.out.println("main over");}//使用throws抛出异常时,可以比此异常大,不能小,可以抛出多个异常。private static void m1() throws FileNotFoundException {System.out.println("m1 begin");m2();System.out.println("mi over");}private static void m2() throws FileNotFoundException {System.out.println("m2 begin");m3();System.out.println("m1 over");}private static void m3() throws FileNotFoundException {//一个方法体当中的代码出现异常后,采用上报的话,此方法结束。new FileInputStream("D:\\course\\01-开课\\学习方法.txt");编译报错的原因是什么?第一:这里调用了一个构造方法:FileInputStream(String name)第二:这个构造方法的声明位置上有:throws FileNotFoundException第三:通过类的继承结构看到:FileNotFoundException父类是IOException,IOException的父类是Exception,最终得知,FileNotFoundException是编译时异常。 编译时异常就必须进行处理。System.out.println("执行");//不会执行}
try..catch的深入
1、catch后面的小括号中的类型可以是具体的异常类型,也可以是该异常类型的父类型。
2、catch可以写多个。建议catch的时候,精确的一个一个处理。这样有利于程序的调试。
3、catch写多个的时候,从上到下,必须遵守从小到大。
4. JDK8的新特性!:可以使用 | 运算符 表示或
// 1、catch后面的小括号中的类型可以是具体的异常类型,也可以是该异常类型的父类型。try {FileInputStream fis = new FileInputStream("D:\\course\\02-JavaSE\\document\\JavaSE进阶讲义\\JavaSE进阶-01-面向对象.pdf");}catch (Exception e或IOException io或FileNotFoundException f){System.out.println("失败");}//2、catch可以写多个。建议catch的时候,精确的一个一个处理。这样有利于程序的调试。try {FileInputStream fis = new FileInputStream("D:\\course\\02-JavaSE\\document\\JavaSE进阶讲义\\JavaSE进阶-01-面向对象.pdf");}catch (NullPointerException n){System.out.println("失败");}catch (IOException io){System.out.println("失败");}//3、catch写多个的时候,从上到下,必须遵守从小到大。try {FileInputStream fis = new FileInputStream("D:\\course\\02-JavaSE\\document\\JavaSE进阶讲义\\JavaSE进阶-01-面向对象.pdf");}catch (FileNotFoundException f){ //写在它俩后面不行System.out.println("失败");}catch (IOException io){System.out.println("失败");} catch (Exception e){System.out.println("失败");}//4. JDK8的新特性!:可以使用 | 运算符 表示或try {//创建输入流FileInputStream fis = new FileInputStream("D:\\curse\\02-JavaSE\\document\\JavaSE进阶讲义\\JavaSE进阶-01-面向对象.pdf");// 进行数学运算System.out.println(100 / 0); // 这个异常是运行时异常,编写程序时可以处理,也可以不处理。} catch(FileNotFoundException | ArithmeticException | NullPointerException e) {System.out.println("文件不存在?数学异常?空指针异常?都有可能!");}
⭐:在以后的开发中,处理编译时异常,应该上报还是捕捉呢,怎么选?
答:如果希望调用者来处理,选择throws上报。 其它情况使用捕捉的方式。
异常对象的常用方法
1.获取异常简单的描述信息: String msg = exception.getMessage();
2.打印异常追踪的堆栈信息:exception.printStackTrace();
查看异常追踪信息进行程序调试:
从上往下一行一行的看,看自己写的代码,SUN公司的就不用看了。
//1.获取异常简单的描述信息: String msg = exception.getMessage();NullPointerException e = new NullPointerException("空指针异常fdsafdsafdsafds");String msg = e.getMessage(); //空指针异常fdsafdsafdsafdsSystem.out.println(msg);//空指针异常fdsafdsafdsafds2.打印异常追踪的堆栈信息:exception.printStackTrace();// java后台打印异常堆栈追踪信息的时候,采用了异步线程的方式打印的。NullPointerException e = new NullPointerException("空指针异常fdsafdsafdsafds");e.printStackTrace();
finally
关于try..catch中的finally子句:
1、在finally子句中的代码是最后执行的,并且是一定会执行的,即使try语句块中的代码出现了异常。
finally子句必须和try一起出现,不能单独编写。
2、finally语句通常使用在哪些情况下呢?
通常在finally语句块中完成资源的释放/关闭。
因为finally中的代码比较有保障。
即使try语句块中的代码出现异常,finally中代码也会正常执行。
3、那么finally语句什么时候不执行?
退出JVM之后,finally语句中的代码就不执行了!只有这一个方法。
System.exit(0);
public static void main(String[] args) {FileInputStream fis = null; // 声明位置放到try外面。这样在finally中才能用。try {// 创建输入流对象fis = new FileInputStream("D:\\course\\02-JavaSE\\document\\JavaSE进阶讲义\\JavaSE进阶-01-面向对象.pdf");// 开始读文件....String s = null;// 这里一定会出现空指针异常!s.toString();System.out.println("hello world!");// 流使用完需要关闭,因为流是占用资源的。// 即使以上程序出现异常,流也必须要关闭!fis.close();// 放在这里有可能流关不了,因为如果出现异常下面的语句就执行不了了。} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();} catch (NullPointerException e) {e.printStackTrace();} finally {System.out.println("HELLO");// 流的关闭放在这里比较保险。// finally中的代码是一定会执行的。// 即使try中出现了异常!if (fis != null) { // 避免空指针异常!try {// close()方法有异常,采用捕捉的方式。fis.close();} catch (IOException e) {e.printStackTrace();}}}}
finally面试题
public static void main(String[] args) {int result = m();System.out.println(result); //100}/*java语法规则(有一些规则是不能破坏的,一旦这么说了,就必须这么做!):java中有一条这样的规则:方法体中的代码必须遵循自上而下顺序依次逐行执行(亘古不变的语法!)java中海油一条语法规则:return语句一旦执行,整个方法必须结束(亘古不变的语法!)*/public static int m(){int i = 100;try {// 这行代码出现在int i = 100;的下面,所以最终结果必须是返回100// return语句还必须保证是最后执行的。一旦执行,整个方法结束。return i;} finally {i++;}}为什么是100?/*反编译之后的效果public static int m(){int i = 100;int j = i;i++;return j;}*/
final finally finalize 的区别
final 关键字
final修饰的类无法继承
final修饰的方法无法覆盖
final修饰的变量不能重新赋值。
finally 关键字
和try一起联合使用。
finally语句块中的代码是必须执行的。
finalize 标识符
是一个Object类中的方法名。
这个方法是由垃圾回收器GC负责调用的。
⭐如何自定义异常?
1.SUN提供的JDK内置的异常肯定是不够的用的。
在实际的开发中,有很多业务, 这些业务出现异常之后,JDK中都是没有的。和业务挂钩的。
2.自定义异常步骤:
第一步:编写一个类继承Exception或者RuntimeException.
第二步:提供两个构造方法,一个无参数的,一个带有String参数的。
public class MyException extens Exception{//编译时异常public MyException(){}public MyException(String s){super(s);}}// 创建异常对象(只new了异常对象,并没有手动抛出)MyException e = new MyException("用户名不能为空!");手动抛出异常: throw e;合并:throw new MyException("用户名不能为空!");// 打印异常堆栈信息e.printStackTrace();// 获取异常简单描述信息String msg = e.getMessage();System.out.println(msg);
异常与方法覆盖
重写之后的方法不能比重写之前的方法抛出更多(更宽泛)的异常,可以更少。
开发时一般父类抛啥子类就抛啥,不瞎搞。
class Animal {public void doSome(){}public void doOther() throws Exception{}}class Cat extends Animal {// 编译正常:运行时异常随便抛,无所谓public void doSome() throws RuntimeException{}// 编译报错:更多public void doSome() throws Exception{}// 编译正常:更少public void doOther() {}// 编译正常:一样public void doOther() throws Exception{}// 编译正常:更窄public void doOther() throws NullPointerException{}}
总结异常中的关键字:
异常捕捉:
try
catch
finally
throws 在方法声明位置上使用,表示上报异常信息给调用者。<br /> throw 手动抛出异常!
作业:
MyException.java
Test.java
UserService.java
进阶-集合
集合概述
什么是集合?有什么用?
数组其实就是一个集合。集合实际上就是一个容器。可以来容纳其他类型的数据。
集合为什么在开发中使用较多?
集合是一个容器,是一个载体。可以一次容纳多个对象。
在实际开发中,假设连接数据库,数据库中有10条记录,那么假设将这10条记录查询出来,
在Java中会将10条数据封装成10个Java对象,然后将10个java对象放到某一个集合中,
将集合传到前端,然后遍历集合,将一个一个数据展现出来。
- 集合不能直接存储基本数据类型,另外集合也不能直接存储java对象,(集合中存储的是引用)
集合当中存储的都是java对象的内存地址。(或者说集合中存储的是引用)
list.add(100);//进行了自动装箱变成了Integer类型。
⭐:集合在java中本身是一个容器,是一个对象。
集合中任何时候存储的都是“引用”。
- 在java中每一个不同的集合,底层会对应不同的数据结构。
往不同的集合中存储元素,等于将数据放到了不同的数据结构当中。
new ArrayList(); 创建一个集合对象,底层是数组。
new TreeSet(); 创建一个集合对象,底层是二叉树。
- 集合在java JDK中哪个包下?
java.util.*;
所有的集合类和集合接口都在java.util包下。
- java集合分为两大类:
一类是单个方式存储元素:
单个方式存储元素,这一类集合中的超级父接口:java.util.Collection;
一类是以键值对的方式存储元素
以键值对的方式存储元素,这一类集合中的超级父接口:java.util.Map;
集合继承结构图—Collection部分
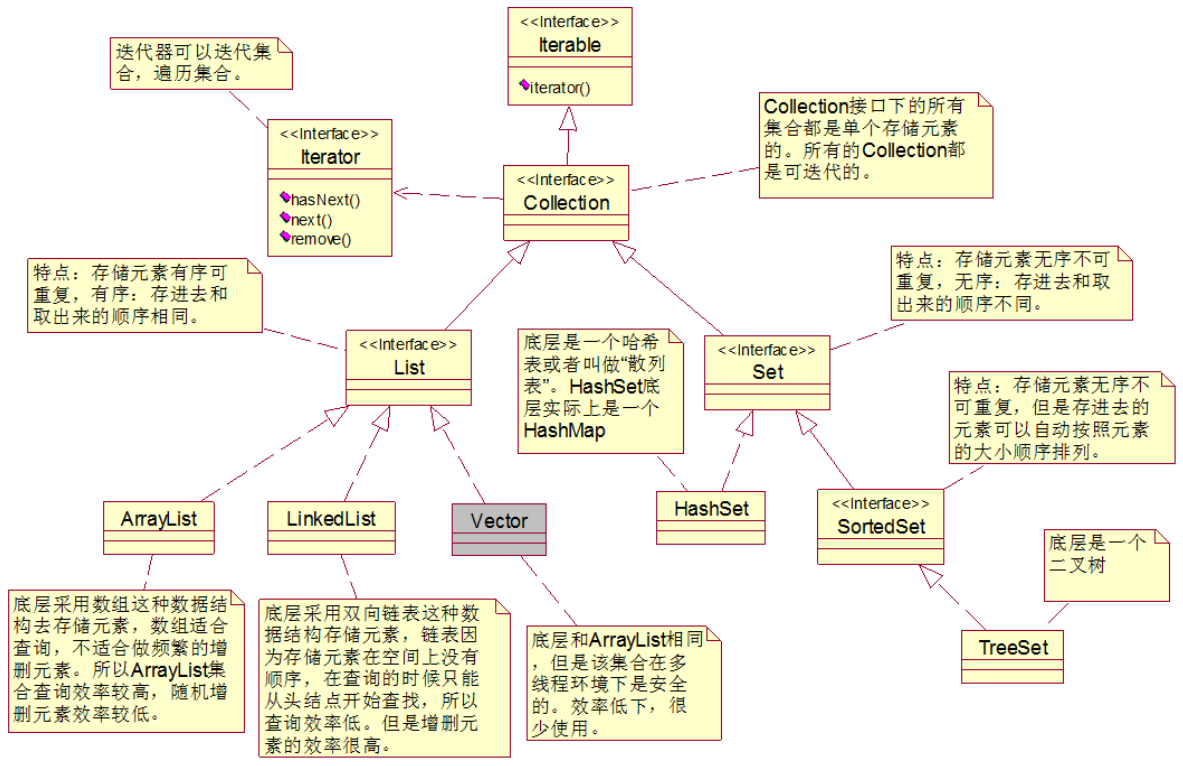
List集合
ArrayList:底层是数组。
LinkedList:底层是双向链表。
Vector:底层是数组,线程安全的,效率低的,使用较少。
List集合存储元素的特点:
- 有序可重复
Set集合存储元素的特点: 无序不可重复
无序:存进去的顺序和取出的顺序不一定相同,另外Set集合中元素没有下标。
不可重复:存进去1,不能再存储1.
SortedSet集合存储元素特点:无序不可重复,但是集合中的元素是可排序的。
无序:存进去的顺序和取出的顺序不一定相同,另外Set集合中元素没有下标。
不可重复:存进去1,不能再存储1。
可排序:可以按照大小顺序排列
Map集合的key,就是一个Set集合。往Set集合中放数据,实际上放到了Map集合的key部分。
集合继承结构图—Map部分
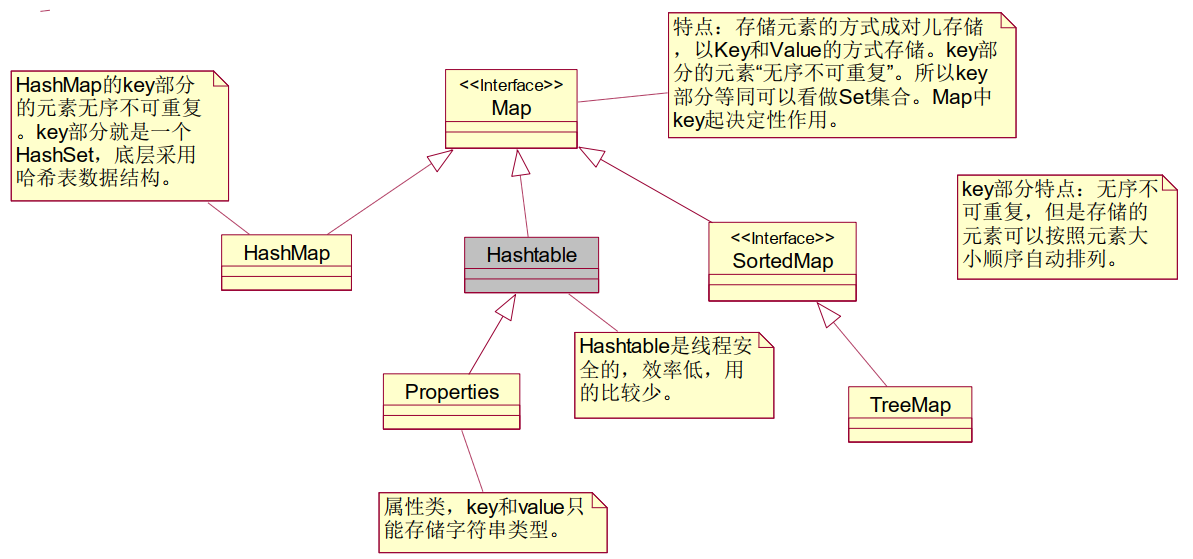
Map集合
HashMap:底层是哈希表。非线程安全。
HashMap集合的默认初始化容量是16,默认加载因子是0.75。
补充:在JDK8之后如果哈希表单向链表中元素超过8个,
单向链表这种数据结构会变成红黑树数据结构。
当红黑树上的节点数量小于6时,会重新把红黑树变成单向链表数据结构。
这种方式是为了提高检索效率,二叉树的检索会再次缩小扫描范围。
HashTable:底层是哈希表,只不过是线程安全的,效率较低,使用较少。
Properties:是线程安全的,并且key和value只能存储字符串String。
TreeMap:底层是二叉树。TreeMap集合的key可以自动按照大小顺序排序。
(根据TreeSet进行学习。)
Map集合存储元素的特点:
- 无序不可重复
- 无序:存进去的顺序和取出的顺序不一定相同,另外Set集合中元素没有下标。
- 不可重复:存进去1,不能再存储1.
SortedMap集合存储元素特点:
- 无序不可重复,但是集合中的元素是可排序的。
- 无序:存进去的顺序和取出的顺序不一定相同,另外Set集合中元素没有下标。
- 不可重复:存进去1,不能再存储1。
- 可排序:可以按照大小顺序排列
Map集合的key,就是一个Set集合。往Set集合中放数据,实际上放到了Map集合的key中。
——————-Collection部分————
Collection接口中的常用方法
- Collection中能存放什么元素?
没有使用“泛型”之前,Collection中可以存储Object的所有子类型。
使用了“泛型”之后,Collection中只能存储某个具体类型。
Collection中什么都能存。只要Object的子类型都可以。
(集合中不能直接存储基本数据类型,也不能存java对象,只是存储java对象的内存地址)
- Collection中的常用方法
boolean add(Object e): 向集合中添加元素
int size()::获取集合中元素的个数。
void clear():清空集合。
boolean contains(Object o):判断当前集合中是否包含元素o。包含返回ture,否则返回false。
boolean remove(Object o):删除元素o。
boolean isEmpty():判断集合中是否为空。
Object[] toArray():调用这个方法可以把集合转换成数组。(了解)
//创建一个集合对象Collection c = new Collection();✖ //因为Collection是一个接口,接口是抽象的无法实例化。//多态Collection c = new ArrayList();//测试接口中常用方法//添加元素--add()c.add(1200);//进行了自动装箱,实际上存进去了内存地址。Integer i = new Integer(1200);c.add(new Student());class Student(){}//获取元素中的个数--size()System.out.println("集合中的元素个数"+c.size());//输出2//清空集合--clear()c1.clear();System.out.println("集合中的元素个数"+c1.size());//输出0//是否包含--contains()String s1 = new String("绿巨人");c1.add(s1);c1.add("美国队长");System.out.println(c1.contains("绿巨人"));//ture//删除集合中某个元素--remove()c1.remove("绿巨人");System.out.println(c1.contains("绿巨人"));//false//将集合转换成数组--toArray()Object[] objects = c1.toArray();for (int i = 0; i <objects.length ; i++) {System.out.println(objects[i]);}
contains方法的深入
//创建集合对象Collection c1= new ArrayList();//添加元素String s1 = new String("abc");String s2 = new String("def");c1.add(s1);c1.add(s2);//查询个数System.out.println("集合中元素的个数:"+c1.size());//新建String对象xString x = new String("abc");//C集合中是否包含X?是的System.out.println(c1.contains(x));//true,因为判断的集合中是否存在“abc”
最终结论:因为contains方法底层调用了euqals方法,String的equals方法已经重写,所以true。
所以,放在集合中的元素必须重写equals方法。
JVM解析: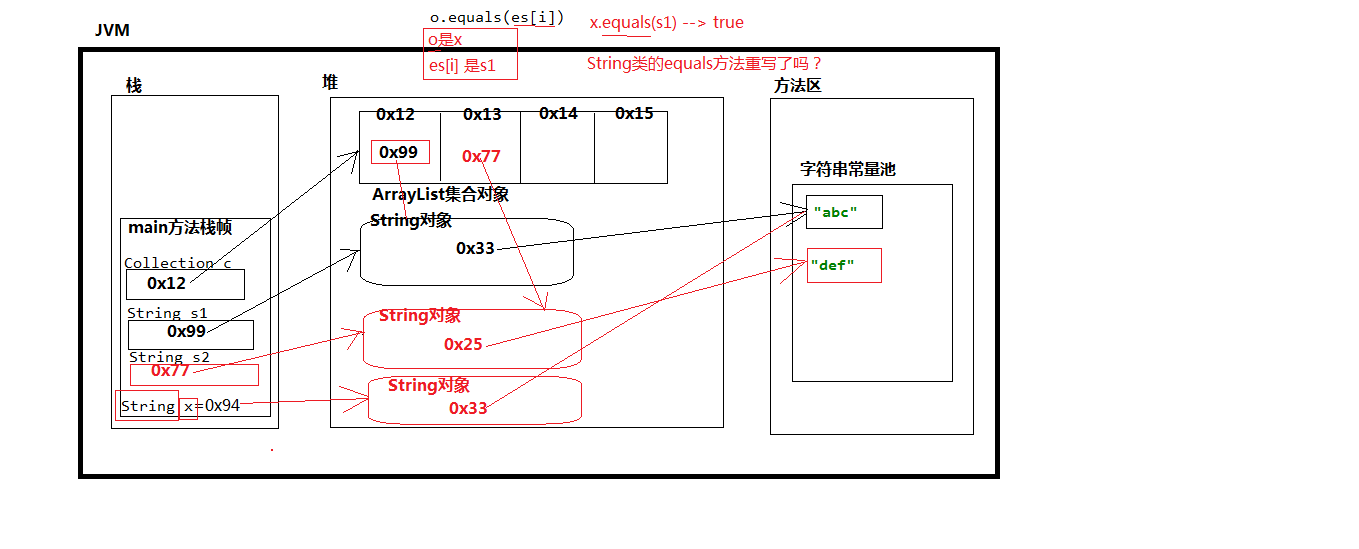
contains在底层是怎么判断集合中是否包含某个元素的?
调用了equals方法进行比较,equals方法返回true,就表示包含。
remove源码分析
Collection c1 = new ArrayList();String s1 = new String("abc");c1.add(s1);String s2 = new String("abc");c1.remove(s2);System.out.println(c1.size()); //结果是0为什么是0?底层也调了 equals方法。
Collection集合 迭代专题⭐
Iterator的使用
boolean hasNext():如果仍有元素可以迭代,返回true。
Object next():返回迭代的下一个元素。
Collection c = new HashSet();c.add("JAMES");c.add("Kobe");c.add("Davis");//对集合c进行迭代//第一步:获取集合对象的迭代器对象Iterator。Iterator it = c.iterator();//第二步:通过以上获取的迭代器对象开始迭代集合。boolean hasNext():如果仍有元素可以迭代,返回true。boolean hasNext = it.hasNext();//这个方法返回true表示有元素可以迭代,false表示没有。Object next():返回迭代的下一个元素。Object obj= it.next();//这个方法让迭代器前进一位,并且将指向的元素返回。while (it.hasNext()){//不管add进去的是什么类型的元素,取出来的类型都是Object。Object object = it.next();System.out.println(object);}
使用迭代器时集合结构不能改变,一旦改变需要重新获取迭代器。
Collection c1 = new ArrayList();Iterator it = c1.iterator();✖✖✖!/*此时获取的迭代器,指向的是集合中没有元素状态下的迭代器。一定要注意:集合结构只要发生改变,迭代器必须重新获取。当集合结构发生了改变,迭代器没有重新获取时,调用next()方法时:java.util.ConcurrentModificationException*/c1.add(1);c1.add(2);c1.add(3);//获取迭代器Iterator it2 = c1.iterator();while (it2.hasNext()){Object obj=it2.next();System.out.println(obj);}/* Iterator it2 = c1.iterator();while (it2.hasNext()){Object obj=it2.next();c2.remove(obj); //错误,同样改变了集合结构,会报java.util.ConcurrentModificationException//想要删除可以使用迭代器的remove,可以自动更新迭代器。it2.remove();System.out.println(obj);}*/
List接口中常用方法
List集合存储元素特点:有序可重复。
- 有序:list集合中的元素有下标。从0开始,以1递增。
- 可重复:存储一个1,还可以在存储一个1。
List是Collection接口的子接口,除了可以使用Collection的方法,还有自己特有的方法。
List接口特有的常用的方法:
- void add(int index,Object element)
像集合指定位置插入元素,第一个元素是下标。
使用不多,因为对于ArrayList集合来说效率较低。
- Object get(int index):根据下标获取元素。
//通过下标遍历(List集合特有方式,Set没有。)
for (int i = 0; i
System.out.println(obj);
}
- int indexOf(Object o):获取指定对象第一次出现处的索引。
int i =myList.indexOf(“myt”);
System.out.println(i);
- int lastIndexOf(Object o):获取指定对象最后一次出现处的索引。
int e = myList.lastIndexOf(“A”);
System.out.println(e);
Object remove(int index):删除索引处对象。
myList.remove(2);
Object set(int index,Object o):修改指定位置的元素。
ArrayList集合
- ArrayList集合默认初始化容量是10。
(底层先创建了一个长度为0的数组,当添加第一个元素的时候,初始容量为10).
- ArrayList集合底层是Object类型的数组Obeject[]。
- ArrayList集合的三种构造方法。
(1)List list1 = new ArrayList();//默认初集合初始化容量为10,数组长度为10.
(2)List list2 = new ArrayList(20);//指定集合容量为20,数组长度为20.
(3)Collection c = new HashSet();
c.add(10);
c.add(20);
c.add(30);
List list3 = new ArrayList(c);//将set集合转换为ArrayList集合。
for (int i = 0; i
}
- ArrayList集合的扩容:
自动扩容后会变为原集合容量的1.5倍。
ArrayList集合底层是数组,怎么优化?
尽可能少的扩容,因为数组扩容效率较低,
建议使用ArrayLsit集合的时候预估计元素的个数,给定一个初始化容量。
数组优点:检索效率比较高。
(每个元素占用空间大小相同,内存地址是连续的,知道首元素内存地址。
然后知道下标,通过数学表达式计算出元素的内存地址,所以检索效率最高。)
数组缺点:随机增删效率较低。另外数组无法存储大数据量。(很难找到一块非常巨大的连续的内存空间。)
向数组末尾添加元素,效率很高,不受影响。面试官常问的一个问题
这么多的集合中,你用哪个集合最多?
ArrayList集合。因为往数组末尾添加元素,效率不受影响,并且我们检索某个元素的操作比较多。
- ArrayList集合是非线程安全的。
LinkedList集合
单向链表数据结构
- 基本的单元是节点Node。
- 任何一个节点Node都有两个属性:
- 存储的数据
- 下一节点的内存地址
- LinkedList集合底层也是有下标的。
链表的优点:随机增删元素效率较高。
(因为增删元素不涉及到大量元素位移,在内存中的存储地址是不连续的。)
所以在以后的开发中,如果遇到随机增删集合中元素的业务比较多时,建议使用LInkedList。
链表的缺点:查询效率较低,每一次查找某个元素的时候都需要从头节点开始往下遍历,直到找到为止。
图解:
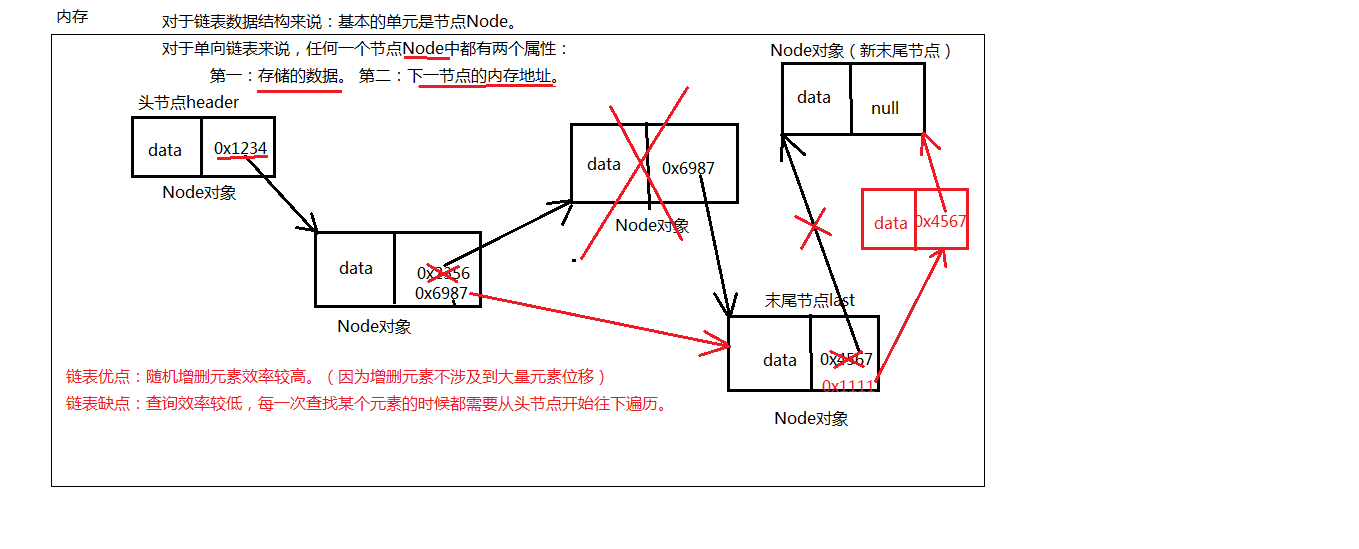
双向链表数据结构
- 基本的单元是节点Node。
- 任何一个节点Node都有三个属性:
- 上一节点的内存地址。
- 存储的数据。
- 下一节点的内存地址。
图解: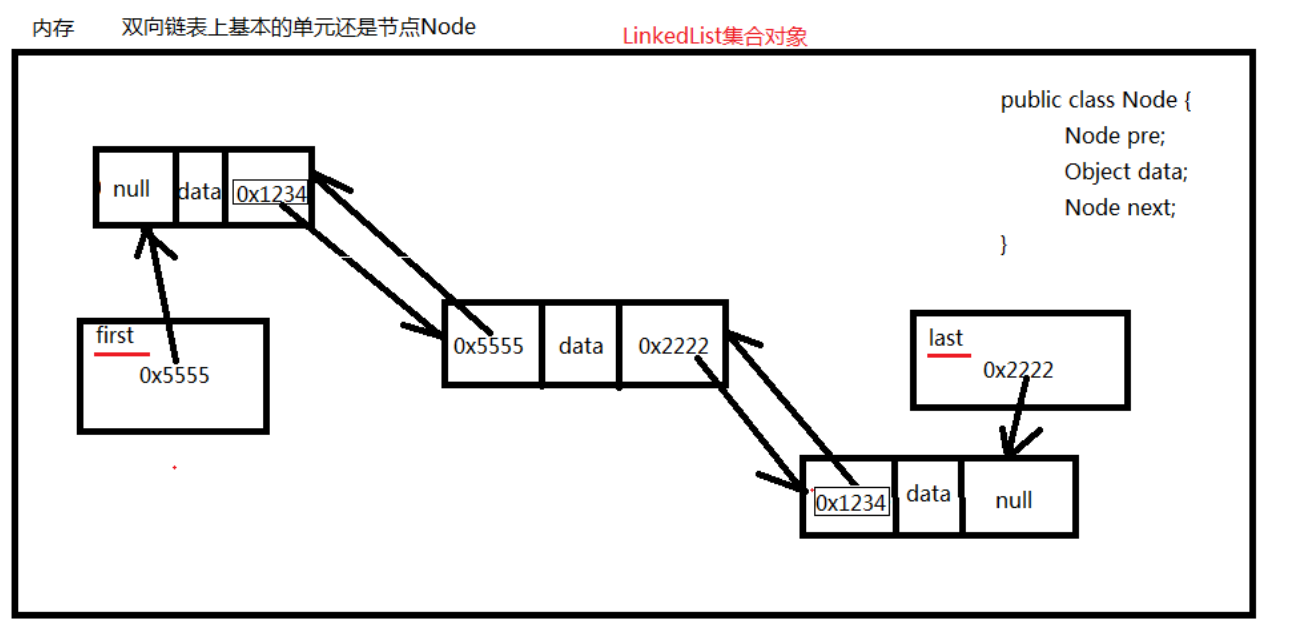
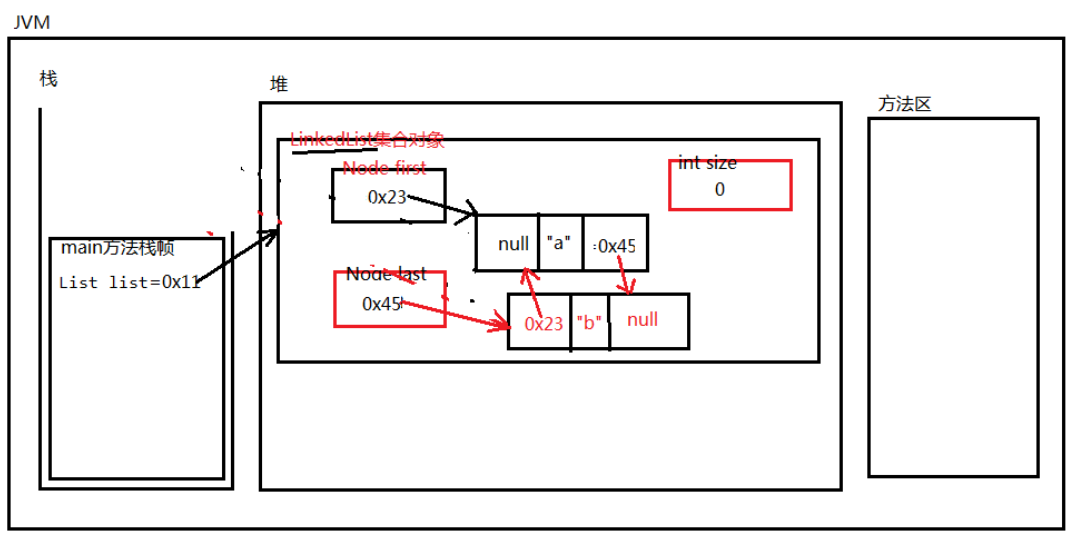
LinkedList总结:
- LinkedList集合没有初始化容量。
- 最初这个链表中没有任何元素,first和last引用都是null。
- 不管是LinkedList还是ArrayList写代码时不需要关心具体是哪个集合。
因为我们要面向接口编程,调用的方法都是接口中的方法。
Vector集合
- 底层也是一个数组。
- 初始化容量:10
怎么扩容的?
扩容之后是原容量的2倍。<br /> 10--> 20 --> 40 --> 80
ArrayList集合扩容特点:
ArrayList集合扩容是原容量1.5倍。
Vector中所有的方法都是线程同步的,都带有synchronized关键字,
是线程安全的。效率比较低,使用较少了。
怎么将一个线程不安全的ArrayList集合转换成线程安全的呢?
使用集合工具类:<br /> java.util.Collections;java.util.Collection 是集合接口。<br /> java.util.Collections 是集合工具类。
// 这个可能以后要使用!!!!List myList = new ArrayList(); // 非线程安全的。// 变成线程安全的Collections.synchronizedList(myList); // 这里没有办法看效果,因为多线程没学,你记住先!// myList集合就是线程安全的了。myList.add("111");myList.add("222");myList.add("333");
TreeSet集合
TreeSet集合底层实际上是一个TreeMap。
- TreeMap集合底层是一个二叉树。
- 放到TreeSet集合中的元素,等同于放到TreeMap集合key部分了。
- TreeSet集合中的元素:无序不可重复,但是可以按照元素的大小顺序自动排序。
称为:可排序集合。
- 怎么可排序的?
```java
⭐//创建String类型的集合
TreeSet
set = new TreeSet<>(); //添加元素
//遍历set.add("LJ");set.add("MJ");set.add("KB");set.add("KD");set.add("AD");
for (String s:set) {System.out.println(s);//按照字典顺序,升序!(AD KB KD LJ MJ)}
⭐//创建Integer类型的集合
TreeSet
/* 数据库中有很多数据:
userid name birth-------------------------------------1 zs 1980-11-112 ls 1980-10-113 ww 1981-11-114 zl 1979-11-11编写程序从数据库当中取出数据,在页面展示用户信息的时候按照生日升序或者降序。这个时候可以使用TreeSet集合,因为TreeSet集合放进去,拿出来就是有顺序的。
*/
6.TreeSet可以对自定义类型排序么?<br />不可以!<br />以下程序中对于Person类型来说,无法排序。<br />因为没有指定Person对象之间的比较规则。 谁大谁小并没有说明!<br />以下程序运行的时候出现了这个异常:<br />java.lang.ClassCastException: class com.bjpowernode.javase.collection.Personcannot be cast to class java.lang.Comparable<br />出现这个异常的原因是:<br />Person类没有实现java.lang.Comparable接口。```javaclass Person{ //未实现Comeparable接口,报错✖!int age;public Person(int age) {this.age = age;}@Overridepublic String toString() {return "Person{" +"age=" + age +'}';}}public class TreeSetTest02 {public static void main(String[] args) {Person p1 = new Person(36);System.out.println(p1);Person p2 = new Person(25);Person p3 = new Person(42);Person p4 = new Person(18);TreeSet<Person> set = new TreeSet<>();//添加数据set.add(p1);set.add(p2);set.add(p3);set.add(p4);//遍历for (Person pp:set) {System.out.println(pp);}}}
自定义类型进行排序的方法
第一种:需要实现Comeparable接口
将6中的Person类进行实现接口class Person implements Comparable<Person>{int age;public Person(int age) {this.age = age;}@Overridepublic String toString() {return "Person{" +"age=" + age +'}';}@Override//需要在这个方法中编写比较的规则,按照什么进行比较。//k.compareTo(t.key)//拿着参数k和集合中的每一个k进行比较,返回值可能是>0 <0 =0//比较规则最终还是由程序员指定的:例如按照年龄升序。或者按照年龄降序。public int compareTo(Person p) {//p1.compareTo(p2) this是p1,p是p2。 p1与P2比较就是 this与P比较。/* if (this.age==p.age){return 0; //代表相同,value会覆盖。}else if (this.age>p.age){return 1; // >0 会继续在右子树上找}else {return -1; // <0 会继续在左子树上找}*///改写以上代码⭐⭐return this.age-p.age; //升序return p.age-this.age;//降序}}
第二种:实现比较器(Comparator)接口
class Person{int age;public Person(int age) {this.age = age;}@Overridepublic String toString() {return "人{" +"age=" + age +'}';}}//单独在这里编写一个比较器class PersonComparator implements Comparator<Person>{@Overridepublic int compare(Person o1, Person o2) {return o1.age-o2.age;}}public class TreeSetTest06 {public static void main(String[] args) {// 创建TreeSet集合的时候,需要使用这个比较器。//Set<Person> set = new TreeSet<>(); 不可以,没有通过构造方法传递一个比较器进去。//给构造方法传递一个比较器Set<Person> set = new TreeSet<>(new PersonComparator());set.add(new Person(18));set.add(new Person(16));set.add(new Person(32));set.add(new Person(25));for (Person pp:set) {System.out.println(pp);}}}
匿名内部类的方式(这个类没有名字。直接new接口。)
⭐⭐Set<Person> set = new TreeSet<>(new Comparator<Person>() {@Overridepublic int compare(Person o1, Person o2) {return o1.age-o2.age;}});代替了/*class PersonComparator implements Comparator<Person>{@Overridepublic int compare(Person o1, Person o2) {return o1.age-o2.age;}}Set<Person> set = new TreeSet<>(new PersonComparator());*/
最终结论: 放到TreeSet或者TreeMap集合key部分的自定义类型元素要想做到排序,包括两种方式:
第一种:放在集合中的元素实现java.lang.Comparable接口。
第二种:在构造TreeSet或者TreeMap集合的时候给它传一个比较器对象。
Comparable和Comparator怎么选择呢?
当比较规则不会发生改变的时候,或者说当比较规则只有1个的时候:建议实现Comparable接口。
如果比较规则有多个,并且需要多个比较规则之间频繁切换:建议使用Comparator接口。
Comparator接口的设计符合OCP原则。
比较规则的写法
实现需求:先按照年龄升序,若年龄相同按照姓名升序。
compareTo方法的返回值很重要:
返回0表示相同,value会覆盖。
返回>0,会继续在右子树上找。【10 - 9 = 1 ,1 > 0的说明左边这个数字比较大。所以在右子树上找。】
返回<0,会继续在左子树上找。
class Vip implements Comparable<Vip>{int age;String name;public Vip(int age, String name) {this.age = age;this.name = name;}@Overridepublic String toString() {return "Vip{" +"age=" + age +", name=" + name +'}';}⭐⭐⭐:比较规则public int compareTo(Vip v) {if (this.age-v.age==0){//年龄相同,按名字升序。// 姓名是String类型,可以直接比。调用compareTo来完成比较。return this.name.compareTo(v.name);}else {// 年龄不一样return this.age-v.age;}}}
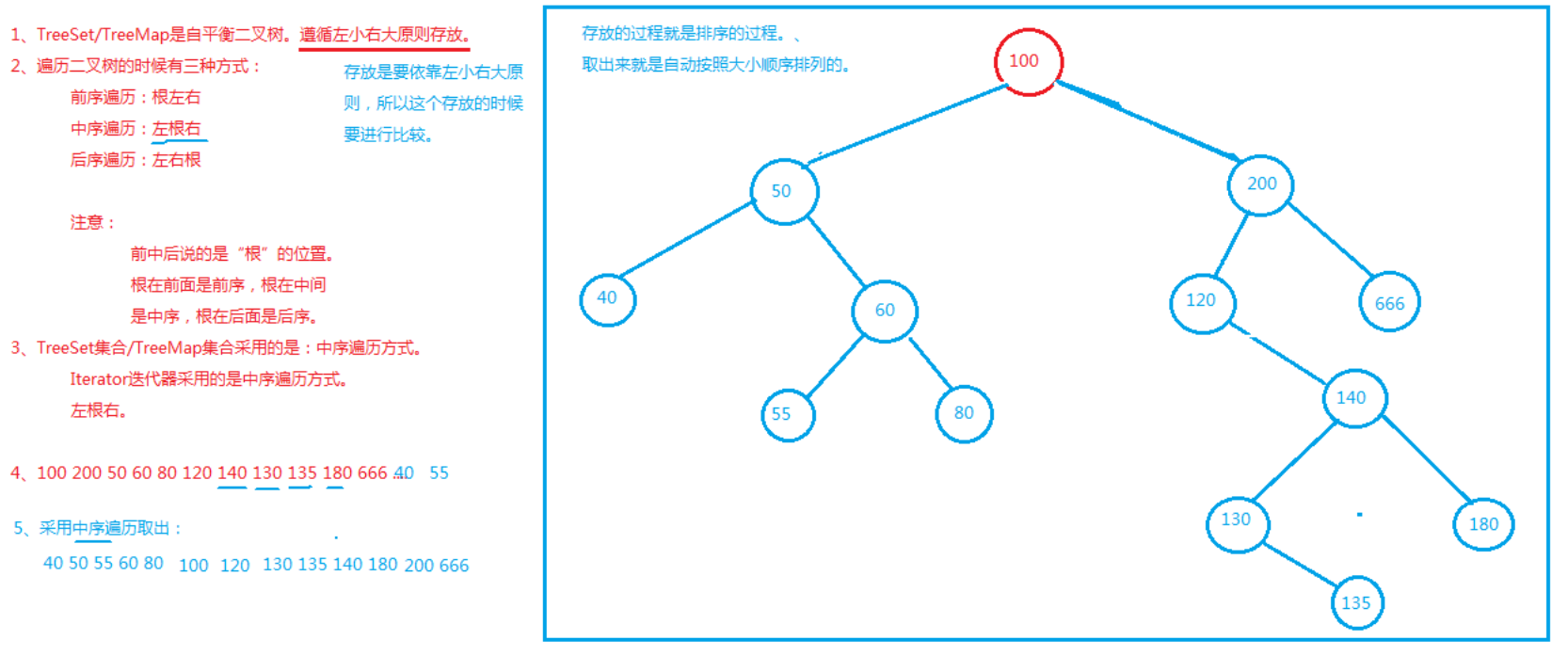
自平衡二叉树数据结构
Collections工具类
- Collections.synchronizedList(list);
Collections.sort(list);
// ArrayList集合不是线程安全的。List<String> list = new ArrayList<>();⭐// 变成线程安全的Collections.synchronizedList(list);⭐//排序Collections.sort(list);// 注意:对List集合中元素排序,需要保证List集合中的元素实现了:Comparable接口。// 对Set集合怎么排序呢?// 将Set集合转换成List集合List<String> myList = new ArrayList<>(set);
泛型机制
JDK5.0之后推出的新特性:泛型
- 泛型这种语法机制,只在程序编译阶段起作用,只是给编译器参考的。(运行阶段泛型没用!)
使用了泛型好处是什么?
第一:集合中存储的元素类型统一了。
第二:从集合中取出的元素类型是泛型指定的类型,不需要进行大量的“向下转型”!泛型的缺点是什么?
导致集合中存储的元素缺乏多样性!
但是大多数业务中,集合中元素的类型还是统一的。所以这种泛型特性被大家所认可。
使用泛型与不使用泛型的对比案例:
public class Test08 {public static void main(String[] args) {//未使用泛型List myList = new ArrayList();Animal a1 = new Cat();Animal a2 = new Bird();myList.add(a1);myList.add(a2);Iterator it = myList.iterator();while (it.hasNext()){//通过迭代器取出的就是Object类型的。Object obj = it.next();//必须进行向下转型。if (obj instanceof Animal){Animal a = (Animal)obj;a.move();}}使用泛型改写以上程序:// 使用泛型List<Animal>之后,表示List集合中只允许存储Animal类型的数据。// 用泛型来指定集合中存储的数据类型。List<Animal> myList = new ArrayList<Animal>();Animal a1 = new Cat();Animal a2 = new Bird();myList.add(a1);myList.add(a2);// 获取迭代器// 这个表示迭代器迭代的是Animal类型。Iterator<Animal> it = myList.iterator();while (it.hasNext()){// 使用泛型之后,每一次迭代返回的数据都是Animal类型。Animal a =it.next();// 这里不需要进行强制类型转换了。直接调用。a.move();// 调用子类型特有的方法还是需要向下转换的!}}}class Animal{public void move(){System.out.println("动物在移动!");}}class Cat extends Animal{public void catchMouse(){System.out.println("猫抓老鼠!");}}class Bird extends Animal{public void fly(){System.out.println("鸟儿飞!");}}
自动类型推断
//List<Animal> myList = new ArrayList<Animal>();//将以上代码用钻石表达式改写,=后面的<>里的内容可以不写,会自动进行推断。(前提:JDK8之后)List<Animal> myList = new ArrayList<>();
自定义泛型
自定义泛型可以吗?
可以 自定义泛型的时候,<> 尖括号中的是一个标识符,随便写。
java源代码中经常出现的是:
E是Element单词首字母。
T是Type单词首字母。
public class GenericTest03<标识符随便写> {public void doSome(标识符随便写 o){System.out.println(o);}public static void main(String[] args) {// new对象的时候指定了泛型是:String类型GenericTest03<String> gt = new GenericTest03<>();// 不用泛型就是Object类型。GenericTest03 gt3 = new GenericTest03();gt3.doSome(new Object());// 类型不匹配//gt.doSome(100);gt.doSome("abc");// =============================================================GenericTest03<Integer> gt2 = new GenericTest03<>();gt2.doSome(100);// 类型不匹配//gt2.doSome("abc");}}class MyIterator<T> {public T get(){return null;}MyIterator<String> mi = new MyIterator<>();String s1 = mi.get();MyIterator<Animal> mi2 = new MyIterator<>();Animal a = mi2.get();}
插曲:foreach(增强for循环)
JDK5.0之后推出了一个新特性:叫做增强for循环,或者叫做foreach
语法: for(元素类型 变量名 : 数组或集合){
System.out.println(变量名);
}
缺点:没有下标。在需要使用下标的循环中,不建议使用增强for循环。
foreach遍历数组
普通for循环遍历数组// int类型数组int[] arr = {432,4,65,46,54,76,54};// 遍历数组(普通for循环)for(int i = 0; i < arr.length; i++) {System.out.println(arr[i]);}foreach遍历数组// 增强for(foreach)// 以下是语法/*for(元素类型 变量名 : 数组或集合){System.out.println(变量名);}*/// foreach有一个缺点:没有下标。 在需要使用下标的循环中,不建议使用增强for循环。for(int data : arr) {// data就是数组中的元素(数组中的每一个元素。)System.out.println(data);}
foreach遍历集合
// 遍历,使用迭代器方式Iterator<String> it = myList.iterator();while (it.hasNext()){String s = it.next();System.out.println(s);}// 使用下标方式(只针对于有下标的集合,get())for (int i = 0; i <myList.size() ; i++) {System.out.println(myList.get(i));}//使用foreach进行遍历for (String s: // 因为泛型使用的是String类型,所以是:String smyList) {System.out.println(s);}
———————Map部分——————-
Map接口中的常用方法
Map集合以key和value的方式存储数据:键值对
- key和value都是引用数据类型
- key和value都是存储对象的内存地址
- key起到主导地位,value是key的一个附属品。
Map接口中常用的方法
V put(K key,V value): 向Map集合中添加键值对。
V get(Object key): 通过key获取某个value。
V remove(Object key):通过key删除某个键值对。
void clear():清空Map集合。
int size():获取Map集合中键值对的个数。
boolean containsKey(Object key): 判断Map中是否包含某个key
boolean containsValue(Object value): 判断Map中是否包含某个valu
boolean isEmpty(): 判断Map集合中元素个数是否为0.
Collection
通过下面两个方法对Map集合进行遍历:
⭐ Set
Set
/创建一个集合对象Map<Integer,String> map = new Map<>();✖ //因为Map是一个接口,接口是抽象的无法实例化。//多态Map<Integer,String> map = new HashMap<>();//测试接口中常用方法//添加键值对--put()map.put(1,"James");//进行了自动装箱,实际上存进去了内存地址。Integer i = new Integer(1);map.put(2,"Kobe");map.put(3,"Davis");map.put(4,"Curry");//通过key获取value--get()System.out.println(map.get(1)); //输出James//获取键值对的数量-size()System.out.println(map.size());//通过key删除某个键值对--remove()map.remove(2);System.out.println(map.get(2));//null//清空集合--clear()map.clear();System.out.println("集合中的元素个数"+map.size());//输出0//是否包含某个key--containsKey()System.out.println(map.containsKey(1));//true//是否包含某个value--containsValue()System.out.println(map.containsValue("Davis")); //true//获取Map集合中所有的Value--values()Collection<String> values = map.values();for (String s:values) {System.out.println(s);}
Map集合的遍历
遍历Map集合的第一种方式:keySet() 获取所有的key,通过遍历key,来遍历value。
Map<Integer,String> map = new HashMap<>();map.put(1,"zs");map.put(2,"ls");map.put(3,"ww");//获取所有的key,是一个Set集合Set<Integer> keys=map.keySet();//遍历key,通过key获取value://一:迭代器Iterator<Integer> it =keys.iterator();while (it.hasNext()){//取出其中一个keyInteger key = it.next();//通过key获取valueString value = map.get(key);System.out.println(key+"="+value);}//二:foreachfor (Integer key:keys) {String value = map.get(key);System.out.println(key+"="+value);}
遍历Map集合的第二种方式: entrySet() 适合大数据量,效率高。
//此方法是把Map集合直接全部转换成Set集合//Set集合中元素的类型是:Map.EntrySet<Map.Entry<Integer,String>> set = map.entrySet();//一:迭代器,遍历Set集合,每一次取出一个NodeIterator<Map.Entry<Integer,String>> it2 = set.iterator();while (it2.hasNext()){Map.Entry<Integer,String> node =it2.next();Integer key = node.getKey(); //获取keyString value = node.getValue(); //获取valueSystem.out.println(key+"="+value);}//二:foreachfor (Map.Entry<Integer,String> node:set) {System.out.println(node.getKey()+"="+node.getValue());}
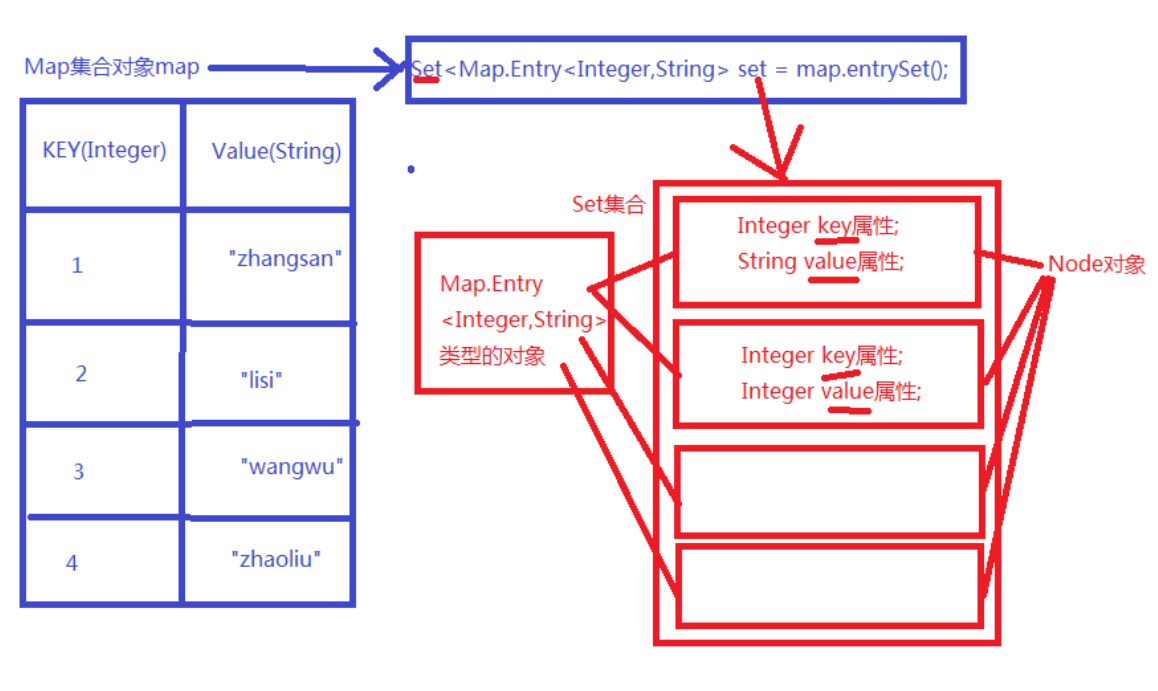
HashMap集合
哈希表数据结构
重点掌握:map.put(k,v)和v = map.get(k)这两个方法的实现原理,必须掌握。
- 哈希表是一个数组和单向链表的结合体,哈希表将以上的两种数据结构融合在一起,充分发挥他们各自的优点。
- 数组:在查询方面效率很高,随机增删方面效率很低。
- 单向链表:在随机增删方面效率很高,查询效率低。
- 为什么哈希表的随机增删,以及查询效率都很高?
因为增删是在链表上完成的,查询也不需要都扫描,只需部分扫描。
HashMap集合底层的源代码:
public class HashMap{// HashMap底层实际上就是一个数组。(一维数组)Node<K,V>[] table;// 静态的内部类HashMap.Nodestatic class Node<K,V> {final int hash; // 哈希值(哈希值是key的hashCode()方法的执行结果。hash值通过哈希函数/算法,可以转换存储成数组的下标。)final K key; // 存储到Map集合中的那个keyV value; // 存储到Map集合中的那个valueNode<K,V> next; // 下一个节点的内存地址。}}
哈希表/散列表:一维数组,这个数组中每一个元素是一个单向链表。(数组和链表的结合体。)
map.put(k,v) 实现原理:
- 先将k,v封装到Node对象当中。
- 底层会调用k的hashCode()方法得出哈希值。然后通过哈希函数/算法,将hash值转换成数组下标,
如果下标位置上如果没有任何元素,就把Node添加到这个位置上。
如果下标对应位置上有链表,此时会拿着k和链表上每一个节点上的k进行equals:
如果所有的equals方法都返回false,那么这个新节点将被添加到链表的末尾。
如果其中有一个equals返回了true,那么这个节点的value将会被替换。
- v=map.get(k) 实现原理:
- 先调用k的hashCode()方法得出哈希值,通过哈希算法转换成数组下标,通过数组下标快速定位到某个位置。
如果这个位置上什么也没有,返回NULL。
如果这个位置上有单向链表,那么会拿着参数k和单向链表上的每个节点中的k进行equals:
如果所有equals方法返回false,那么get方法返回null。
只要其中有一个节点的k和参数k的equals返回true,那么此时这个value就是我们要找的value,
get方法最终返回这个要找的value.
向Map集合中存(put)或者取(get),都是首先调用key的hashCode方法,然后再调用equals方法!
equals方法有可能调用,也有可能不调用。
put(k,v)中,什么时候equals不会调用?
底层会调用k的hashCode()方法得出哈希值。然后通过哈希函数/算法,将hash值转换成数组下标,
如果下标位置上如果没有任何元素时,不会调用equals。
get(k)中,什么时候equals不会调用?
如果下标位置上如果没有任何元素时,不会调用equals。
- 通过讲解可以得出HashMap集合的key,会先后调用两个方法,hashCode()和equals(),
所以这个两个方法都需要重写(工具自动重写即可。)。
并且当equals方法返回true时,hashCode方法返回的值必须一样。
- HashMap集合的key部分特点:无序,不可重复。
- 为什么无序?
因为不一定挂到哪个单向链表上。
b. 不可重复是怎么保证的?
equals方法来保证HashMap集合的key不可重复。如果key重复了,value会覆盖。
- 哈希表HashMap使用不当时无法发挥性能!
- 假设将所有的hashCode()方法返回值固定为某个值,那么会导致底层哈希表变成了 纯单向链表。
这种情况我们称为:散列分布不均匀。
- 什么是散列分布均匀?
假设有100个元素,10个单向链表,那么每个单向链表上有10个节点,这是最好的,是散列分布均匀的。
- 假设将所有的hashCode()方法返回值都设定为不一样的值,可以吗,有什么问题?
不行,因为这样的话导致底层哈希表就成为一维数组了,没有链表的概念了。也是散列分布不均匀。
散列分布均匀需要你重写hashCode()方法时有一定的技巧。
- 重点:放在HashMap集合key部分的元素,以及放在HashSet集合中的元素,需要同时重写hashCode和equals方法。
终极结论:放在HashMap集合key部分的元素和放在HashSet集合中的元素,
必须同时重写hashCode方法和equals方法。
HashMap集合的默认初始化容量是16,默认加载因子是0.75。 扩容之后的容量是原容量2倍。
这个默认加载因子是当HashMap集合底层数组的容量达到75%的时候,数组开始扩容。
重点:HashMap集合初始化容量必须是2的倍数,这也是官方推荐的。
因为为了达到散列分布均匀,为了提高HashMap集合的存取效率,所必须的。HashMap集合key部分允许为null么?
允许,但是要注意:HashMap集合的key null值只能有一个。
图解: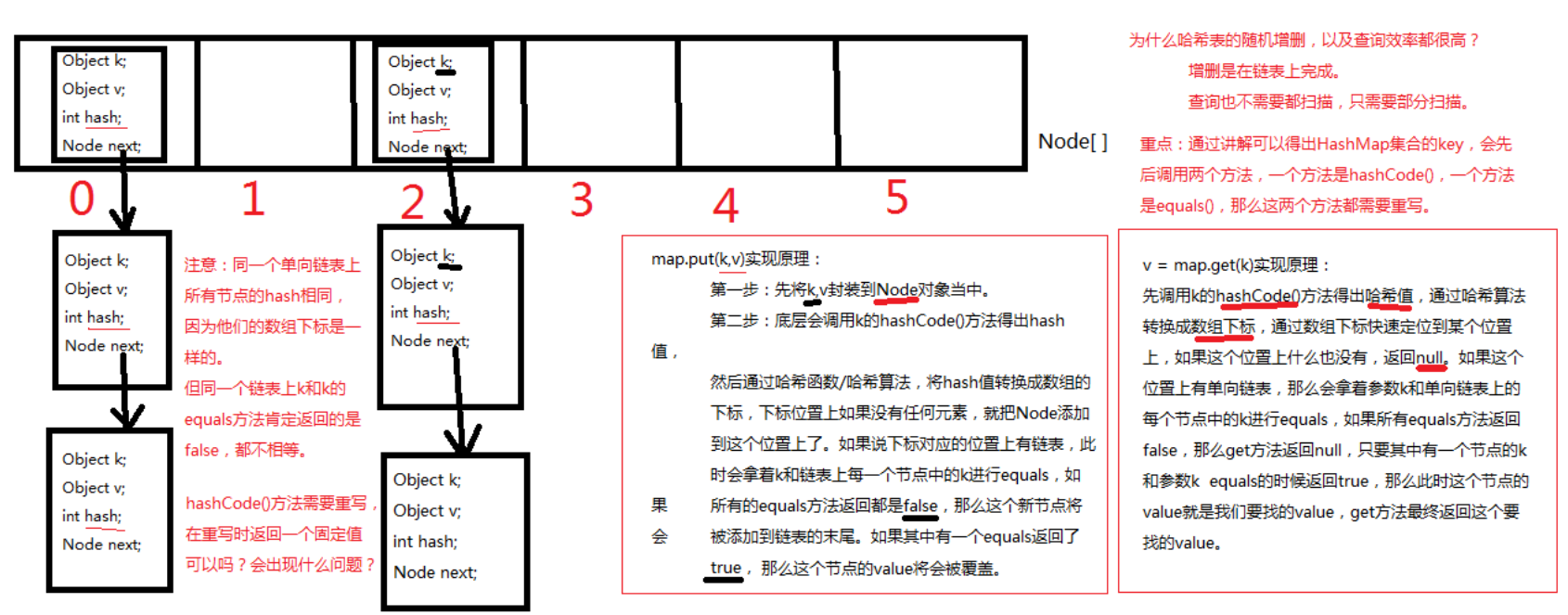
测试HashMap集合key部分的元素特点
验证结果:HashMap集合key部分元素:无序不可重复。
//Integer是key,它的hashCode和equals都重写了。Map<Integer,String> map = new HashMap<>();map.put(11,"LJ");map.put(22,"KB");map.put(666,"KP");map.put(33,"AD");map.put(33,"KD");// key重复 覆盖之前的。System.out.println(map.size());//4遍历集合Set<Map.Entry<Integer,String>> set=map.entrySet();for (Map.Entry<Integer,String> node:set) {System.out.println(node.getKey()+"="+node.getValue());} //输出:33=KD22=KB666=KP11=LJ验证结果:HashMap集合key部分元素:无序不可重复。
HashTable集合
- Hashtable的key可以为null吗?
Hashtable的key和value都是不能为null的。
HashMap集合的key和value都是可以为null的。
- Hashtable方法都带有synchronized:线程安全的。线程安全有其它的方案,这个Hashtable对线程的处理
导致效率较低,使用较少了。
- Hashtable和HashMap一样,底层都是哈希表数据结构。
Hashtable的初始化容量是11,默认加载因子是:0.75f
Hashtable的扩容是:原容量 * 2 + 1
Properties属性类
目前只需要掌握Properties属性类对象的相关方法即可。(需要掌握Properties的两个方法,一个存,一个取。)
- Properties是一个Map集合,继承Hashtable,Properties的key和value都是String类型。
- Properties被称为属性类对象。
- Properties是线程安全的。
//创建Properties对象Properties pro = new Properties();//存(setProperty())pro.setProperty("url", "jdbc:mysql://localhost:3306/bjpowernode");pro.setProperty("driver","com.mysql.jdbc.Driver");pro.setProperty("username", "root");pro.setProperty("password", "123");//取(getProperty())String url = pro.getProperty("url");String driver = pro.getProperty("driver");String username = pro.getProperty("username");String password = pro.getProperty("password");//输出System.out.println(url);System.out.println(driver);System.out.println(username);System.out.println(password);
———————————————————
集合部分大总结
集合这块最主要掌握什么内容?
1.1、每个集合对象的创建(new)
1.2、向集合中添加元素
1.3、从集合中取出某个元素
1.4、遍历集合
1.5、主要的集合类:
ArrayList
LinkedList
HashSet (HashMap的key,存储在HashMap集合key的元素需要同时重写hashCode + equals)
TreeSet
HashMap
Properties
TreeMapArrayList主要知识点(List集合)
```java package com.bjpowernode.javase.review;
import java.util.ArrayList; import java.util.Iterator; import java.util.LinkedList;
/
1.1、每个集合对象的创建(new)
1.2、向集合中添加元素
1.3、从集合中取出某个元素
1.4、遍历集合
/
public class ArrayListTest {
public static void main(String[] args) {
// 创建集合对象
//ArrayList
// while循环修改为for循环/*for(Iterator<String> it2 = list.iterator(); it2.hasNext(); ){System.out.println("====>" + it2.next());}*/// 遍历(foreach方式)for(String s : list){System.out.println(s);}}
}
<a name="PYZcv"></a>### HashSet主要知识点```javapackage com.bjpowernode.javase.review;import java.util.HashSet;import java.util.Iterator;import java.util.Objects;import java.util.Set;/*1.1、每个集合对象的创建(new)1.2、向集合中添加元素1.3、从集合中取出某个元素1.4、遍历集合1.5、测试HashSet集合的特点:无序不可重复。*/public class HashSetTest {public static void main(String[] args) {// 创建集合对象HashSet<String> set = new HashSet<>();// 添加元素set.add("abc");set.add("def");set.add("king");// set集合中的元素不能通过下标取了。没有下标// 遍历集合(迭代器)Iterator<String> it = set.iterator();while(it.hasNext()){System.out.println(it.next());}// 遍历集合(foreach)for(String s : set){System.out.println(s);}set.add("king");set.add("king");set.add("king");System.out.println(set.size()); //3 (后面3个king都没有加进去。)set.add("1");set.add("10");set.add("2");for(String s : set){System.out.println("--->" + s);}// 创建Set集合,存储Student数据Set<Student> students = new HashSet<>();Student s1 = new Student(111, "zhangsan");Student s2 = new Student(222, "lisi");Student s3 = new Student(111, "zhangsan");students.add(s1);students.add(s2);students.add(s3);System.out.println(students.size()); // 2// 遍历for(Student stu : students){System.out.println(stu);}}}class Student {int no;String name;public Student() {}public Student(int no, String name) {this.no = no;this.name = name;}@Overridepublic String toString() {return "Student{" +"no=" + no +", name='" + name + '\'' +'}';}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return no == student.no &&Objects.equals(name, student.name);}@Overridepublic int hashCode() {return Objects.hash(no, name);}}
TreeSet主要知识点
package com.bjpowernode.javase.review;import java.util.Comparator;import java.util.Iterator;import java.util.TreeSet;/*1.1、每个集合对象的创建(new)1.2、向集合中添加元素1.3、从集合中取出某个元素1.4、遍历集合1.5、测试TreeSet集合中的元素是可排序的。1.6、测试TreeSet集合中存储的类型是自定义的。1.7、测试实现Comparable接口的方式1.8、测试实现Comparator接口的方式(最好测试以下匿名内部类的方式)*/public class TreeSetTest {public static void main(String[] args) {// 集合的创建(可以测试以下TreeSet集合中存储String、Integer的。这些类都是SUN写好的。)//TreeSet<Integer> ts = new TreeSet<>();// 编写比较器可以改变规则。TreeSet<Integer> ts = new TreeSet<>(new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {return o2 - o1; // 自动拆箱}});// 添加元素ts.add(1);ts.add(100);ts.add(10);ts.add(10);ts.add(10);ts.add(10);ts.add(0);// 遍历(迭代器方式)Iterator<Integer> it = ts.iterator();while(it.hasNext()) {Integer i = it.next();System.out.println(i);}// 遍历(foreach)for(Integer x : ts){System.out.println(x);}// TreeSet集合中存储自定义类型TreeSet<A> atree = new TreeSet<>();atree.add(new A(100));atree.add(new A(200));atree.add(new A(500));atree.add(new A(300));atree.add(new A(400));atree.add(new A(1000));// 遍历for(A a : atree){System.out.println(a);}//TreeSet<B> btree = new TreeSet<>(new BComparator());// 匿名内部类方式。TreeSet<B> btree = new TreeSet<>(new Comparator<B>() {@Overridepublic int compare(B o1, B o2) {return o1.i - o2.i;}});btree.add(new B(500));btree.add(new B(100));btree.add(new B(200));btree.add(new B(600));btree.add(new B(300));btree.add(new B(50));for(B b : btree){System.out.println(b);}}}// 第一种方式:实现Comparable接口class A implements Comparable<A>{int i;public A(int i){this.i = i;}@Overridepublic String toString() {return "A{" +"i=" + i +'}';}@Overridepublic int compareTo(A o) {//return this.i - o.i;return o.i - this.i;}}class B {int i;public B(int i){this.i = i;}@Overridepublic String toString() {return "B{" +"i=" + i +'}';}}// 比较器class BComparator implements Comparator<B> {@Overridepublic int compare(B o1, B o2) {return o1.i - o2.i;}}
HashMap主要知识点
package com.bjpowernode.javase.review;import java.util.HashMap;import java.util.Map;import java.util.Set;/*1.1、每个集合对象的创建(new)1.2、向集合中添加元素1.3、从集合中取出某个元素1.4、遍历集合*/public class HashMapTest {public static void main(String[] args) {// 创建Map集合Map<Integer, String> map = new HashMap<>();// 添加元素map.put(1, "zhangsan");map.put(9, "lisi");map.put(10, "wangwu");map.put(2, "king");map.put(2, "simth"); // key重复value会覆盖。// 获取元素个数System.out.println(map.size());// 取key是2的元素System.out.println(map.get(2)); // smith// 遍历Map集合很重要,几种方式都要会。// 第一种方式:先获取所有的key,遍历key的时候,通过key获取valueSet<Integer> keys = map.keySet();for(Integer key : keys){System.out.println(key + "=" + map.get(key));}// 第二种方式:是将Map集合转换成Set集合,Set集合中每一个元素是Node// 这个Node节点中有key和valueSet<Map.Entry<Integer,String>> nodes = map.entrySet();for(Map.Entry<Integer,String> node : nodes){System.out.println(node.getKey() + "=" + node.getValue());}}}

若有收获,就点个赞吧
0 人点赞
