
前言:
ComfyUI 支持了 Stable Video Diffusion,可以在具有 8GB vram 的 GTX 1080 上生成 25 帧长的 1024x576 视频。也支持 AMD 6800XT with ROCm on Linux。
更新下载:
- 更新 ComfyUI(怎么更新就不用说了吧)
- 下载下方链接中的模型:(网盘中有我下载好的,大家也可以去文末查看百度网盘链接)
- https://huggingface.co/stabilityai/stable-video-diffusion-img2vid/blob/main/svd.safetensors(下载 svd.safetensors 这个模型)
- https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt/blob/main/svd_xt.safetensors(下载 svd_xt.safetensors 这个模型)
- 这个两个模型分别支持生成 14 帧视频和 25 帧视频,将它们放在 ComfyUI/models/checkpoints 文件夹中。
如何使用:
SVD模型加载器:
- 我们首先加载一个SVD加载器,“右键——新建节点——加载器——video_models——Image Only Checkpoint Loader(img2vid model)”
- 选择我们需要的 SVD 模型。

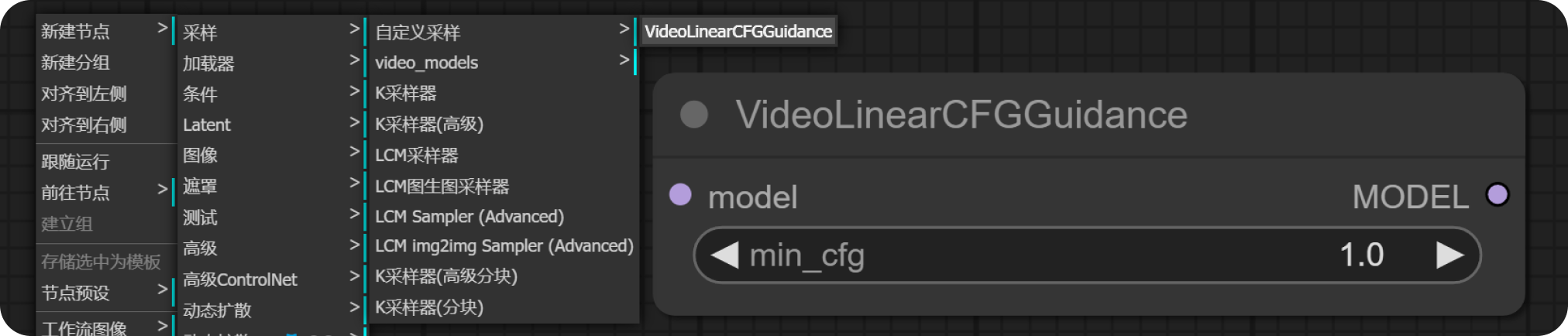
VideoLinearCFGGuidance 节点:
- “右键——新建节点——采样——video_models——VideoLinearCFGGuidance”
- 设置min_cfg数值:1;
- 左侧“model”链接“SVD模型加载器的model”
SVD_img2vid_Conditioning 节点:
- “右键——新建节点——条件——video_models——SVD_img2vid_Conditioning”
- SVD_img2vid_Conditioning 节点参数介绍:
- video_frames:要生成的视频帧数;
- motion_bucket_id:数字越大,视频中的运动越多;
- fps:fps 越高,视频的断断续续就越少;
- augmentation level:添加到初始图像的噪声量,越高,视频看起来就越不像初始图像。增加它以获得更多运动。
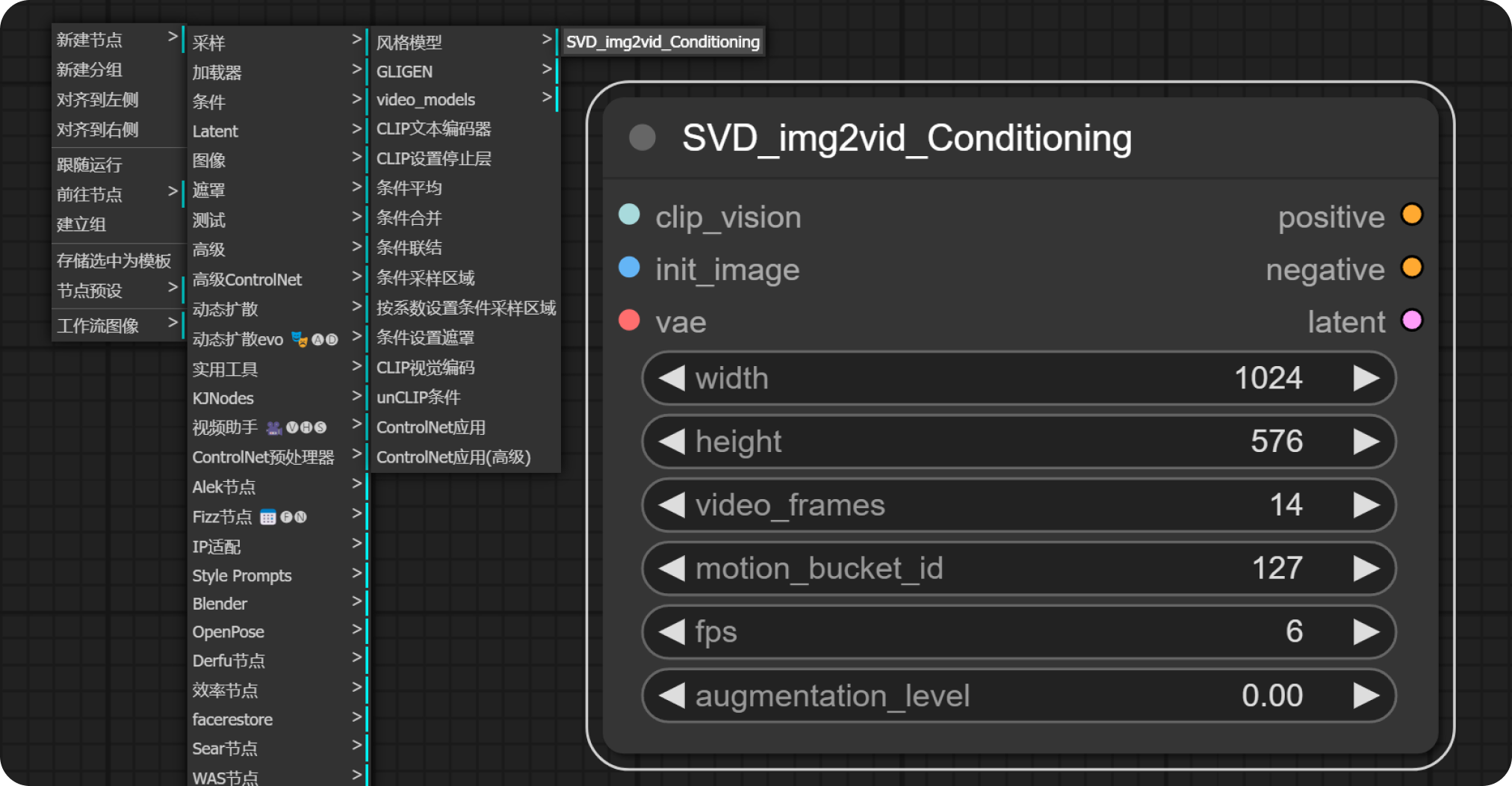
- 左侧的“clip_vision,vae”分别与“SVD 模型加载器”连接;
- 左侧的“init_image”通过拖拽或右键去连接一个“加载图像”节点。
K采样器
- “右键——新建节点——条采样器——K采样器”
- 左侧的“模型”连接“VideoLinearCFGGuidance”节点的“model”
- 左侧的“正面提示词、负面提示词、Latent”分别连接“SVD_img2vid_Conditioning”节点的“positive、negative、latent”
- 右侧就简单了,连接我们的“VAE解码”,“VAE解码”节点的“VAE”连接“SVD模型加载器”
导出视频:
- 虽然官方给了一个生成 webp 格式的节点(右键——新建节点——测试——SaveAnimated WEBP),但是我们平常生成需要生成 mp4、GIF 格式时就需要安装其他节点插件了;
- 我平常用的是“Video Helper Suite”插件的合成视频节点,大家可以去安装这个插件使用,他可以合成多种动图、视频格式。
- 连接完成我们就可以跑图了。
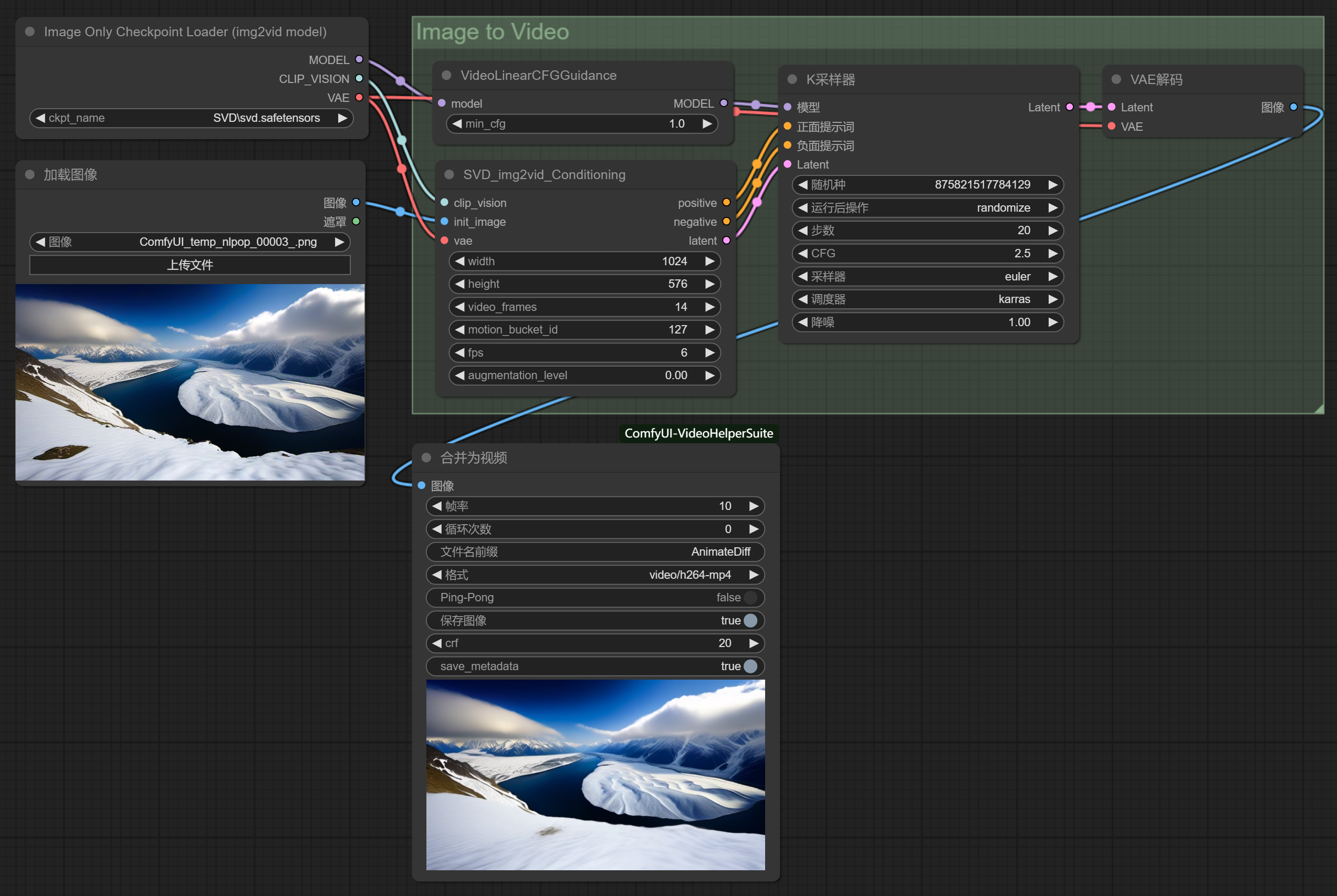
工作流连接如下:(网盘中有我建好的工作流文件)
百度网盘链接:

若有收获,就点个赞吧
0 人点赞
