JMM
JMM抽象模型**
JMM定义了Java 虚拟机(JVM)在计算机内存(RAM)中的工作方式。从抽象的角度来看,JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存(Main Memory)中,每个线程都有一个私有的本地内存(Local Memory),本地内存中存储了该线程以读/写共享变量的副本。本地内存是JMM的一个抽象概念,并不真实存在。它涵盖了缓存、写缓冲区、寄存器以及其他的硬件和编译器优化。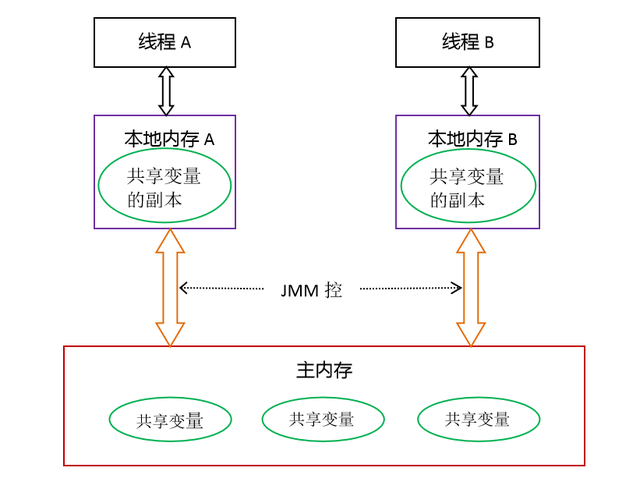
在JVM内部使用的Java内存模型(JMM)将线程堆栈和堆之间的内存分开
线程堆栈(thread stack):
1.运行在java虚拟机上的每个线程都有自己的线程堆栈(thread stack)2.线程堆栈还包含正在执行的每个方法的所有局部变量,一个线程只能访问它自己的线程堆栈。由线程创建的局部变量对于除创建它的线程之外的所有其他线程都是不可见的。3.即使两个线程正在执行完全相同的代码,两个线程仍然会在每个线程堆栈中创建该代码的局部变量,一个线程可能会将一个有限变量的副本传递给另一个线程,但它不能共享原始局部变量本身。
堆:
1.堆包含在Java应用程序中创建的所有对象,而不管是不是由线程创建的该对象。
2.堆中的对象可以被具有对象引用的所有线程访问。当一个线程访问一个对象时,它也可以访问该对象的成员变量。
3.如果两个线程同时调用同一个对象上的一个方法,它们都可以访问该对象的成员变量,但每个线程都有自己的局部变量副本
4.堆中的数据是共享的,线程不安全的
重排序
在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排序。
重排序的种类包含三种:
1)编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
2)指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-LevelParallelism,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
3)内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
- 数据依赖性
如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性。数据依赖分为下列3种类型,这3种情况,只要重排序两个操作的执行顺序,程序的执行结果就会被改变。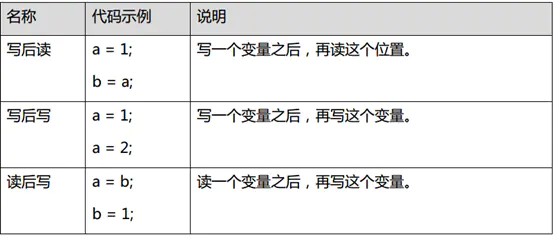
- as-if-serial
as-if-serial语义的意思是:不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变。编译器、runtime和处理器都必须遵守as-if-serial语义。为了遵守as-if-serial语义,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。

若有收获,就点个赞吧
0 人点赞
