1.基本
①源URL:必填,用于书源唯一性(注:想要一个源共存,可以在url后面加上任意符号或字符。如:https://www.9txs.com#1)
②源名称:必填,一般使用网站名称。
③源分组:选填,用于方便管理书源分类。
④源注释:选填,用于描述该书源的一些问题。
⑤登录URL:用于登录账号,如https://www.9txs.com/login.html?jumpurl=%2Fmark.html。
⑥书籍URL正则:用于网址添加书籍,如
https://www.9txs.com/book/\d+.html,更多参考正则写法。
⑦请求头:选填,部分网站需要填写,如下写法:
{
“User-Agent”: “Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.73 Safari/537.36”
}
效果如图
2.搜索
①搜索地址(必填)
第三方网站搜索后得到的网址,一般分为post类型(稍微复杂:点击下一页或者电脑审查元素得到字符串,手机通过抓包工具获取到字符串)和get类型(简单:一般搜索关键词能获取到字符串)。
例如:https://www.ranwen.com/s.php?ie=gbk&q=%B6%BC%CA%D0
q=%B6%BC%CA%D0等号后面的就是搜索关键词得到的字符串(以实际情况为准)。
(1)GET类型
找到网站搜索框,输入关键字搜索后得到的网址就是搜索地址了。这种URL有关键词的就是get方式(搜索“都市”获取到的字符串一般为“%B6%BC%CA%D0”,需要将搜索得到的字符串替换为“{{key}}”)
例如:https://www.ranwen.com/s.php?ie=gbk&q=%B6%BC%CA%D0字符串替换为
https://www.ranwen.com/s.php?ie=gbk&q={{key}}
注:搜索下一页,用{{page}}表示页码1,2…
例如:https://www.wenxuemi.cc/search.php?q={{key}}&p={{page}}
下一页调试乱码或无内容
网站搜索关键词得到的网址为:
https://www.52bqg.net/modules/article/search.php?searchkey=%B6%BC%CA%D0
或者
点击下一页为:
https://www.52bqg.net/modules/article/search.php?searchkey=%B6%BC%CA%D0&page=2
我们通过测试会发现直接写为(需要余下内容写完):
https://www.52bqg.net/modules/article/search.php?searchkey={{key}}&page={{page}}
调试为乱码或没有内容,这时需要转码,写法为:
,{
“charset”: “gbk”
}
结合起来的写法为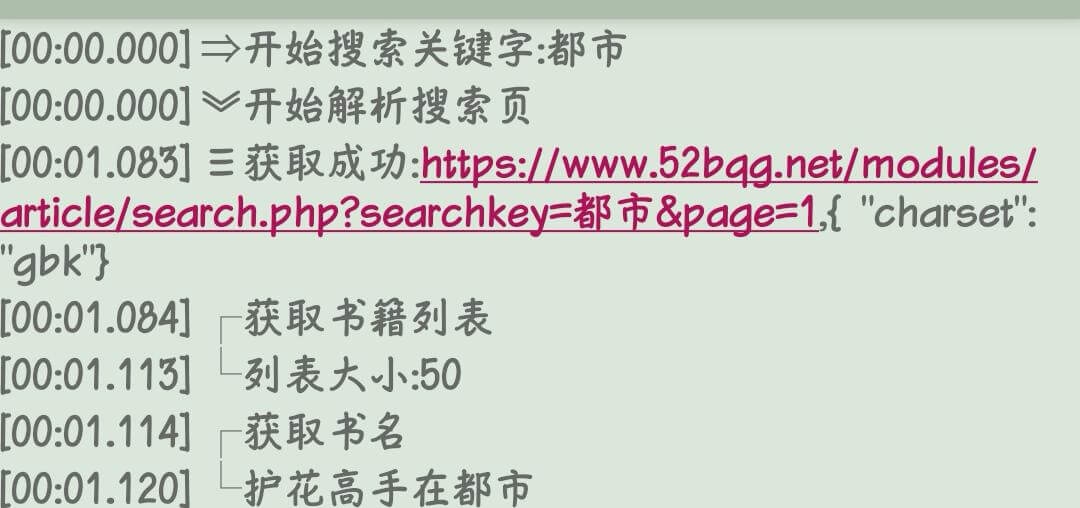
https://www.52bqg.net/modules/article/search.php?searchkey={{key}}&page={{page}},{
“charset”: “gbk”
}
(2)POST类型
提交格式为:
,{
“charset”: “”,
“method”: “POST”,
“body”: “”,
“headers”: {“User-Agent”: “”}
}
·charset 字符编码(一般填写gbk)
·body 提交数据(获取到的请求数据)
(User-Agent非必填,有时调试源没内容可以尝试将charset 一行删除)
电脑:用审核元素,刷新下获取到post提交的数据。
手机:借用抓包工具,获取到请求的数据。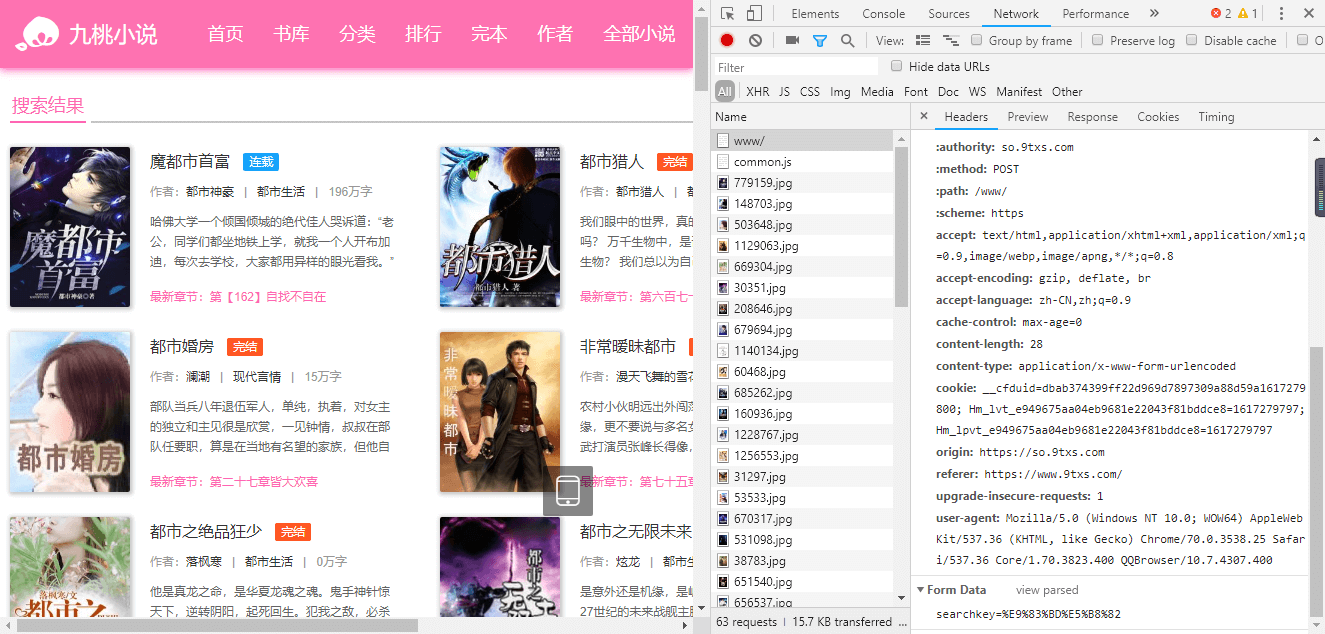
例如:
https://so.9txs.com/www/,{
“method”: “POST”,
“body”: “searchkey={{key}}”
}
或者
https://www.shuhaiwu.com/modules/article/search.php,{
“charset”: “gbk”,
“method”: “POST”,
“body”: “searchkey={{key}}&action=login”
②书籍列表规则(必填)
查看网页源码或审查元素,定位到搜索结果的内容,如图
获取class:novelslistss下的li标签
写法为:class.novelslistss@tag.li
③书名规则(以上搜索结果为例)
写法一:获取class元素文本内容
class.s2@text
写法二:发现多了内容,因为列表下有多个a标签都获取了。(多个标签元素规则:
排序规则是从0开始到n,第一个就是0,第二个就是1,以次类推)
获取书名,就是第一个a标签文本内容
tag.a.0@text
写法三:可以看到列表下多个span标签都获取了(按照多个标签元素规则)
获取书名,就是第二个span标签文本内容
tag.span.1@text或tag.span.1@tag.a@text
④作者规则
写法参考书名规则
有些获取到获取到多余内容如:作者:唐家三少
这时通过正则表达删除,例如:
class.s4@text##作者:
⑤分类规则
写法参考书名规则和作者规则,如需多个内容共存则使用&&,如下:
class.s1@text&&
class.s7@text
⑥字数规则
写法参考书名规则和作者规则
⑦最新章节规则
搜索结果有最新章节的,写法参考书名规则和作者规则
非必要:有些搜索无最新章节,详情有最新章节的,则可以通过ajax
获取详情也获取到最新章节,我的写法如下(增加搜索时间)
tag.a.1@href
或者
tag.a.1@href
⑧简介规则
写法参考书名规则和作者规则
⑨封面规则
第一种:搜索结果有图片的,可以直接写,一般为src ,如果遇到src和data-original共存的写data-original以图片在img标签下,且只有一个img标签,如下
img@src或者img@data-original
第二种:搜索结果无图片,且详情页图片有规律的,则可以通过书籍url链接拼接获取到图片链接,我的写法为(不会影响搜索加载时间)
class.s2@tag.a@href
var id = result.match(/(\d+)\/?$/)[1];
var iid = parseInt(id/1000);
‘https://www.52bqg.net/files/article/image/'+iid+'/'+id+'/'+id+'s.jpg‘;
第三种:搜索结果无图片,详情页的图片无规律的,则可以通过ajax加载详情页获取图片,我的写法(增加搜索加载时间)
class.col-xs-3@a@href
或者
书籍网址完整的写法
class.col-xs-3@a@href
⑩详情页url规则
一般将书名规则的text改为href
如tag.a.0@href
特殊的书籍网址不在书名标签内的,找到书籍网址的标签,写法一样
3.详情页
如图片为例

①预处理规则
非必填,可以看到书籍详情内容在的id:maininfo标签下
可写为
id.maininfo
②书名规则
建议填写(有些网站搜书全名跳转到详情页)
可以看到书名在h1标签内,父标签为id:info
这样有几种写法,分别为
h1@text或者id.info@h1@text
③作者规则
建议填写(参考书名规则)
可以看到作者在第一个p标签内,父标签为id:info
写法为
id.info@tag.p.0@text
④分类规则
这个网站有更新时间,我一般把更新时间写在分类规则内,
可以看到更新在第3个p标签内,父标签为id:info
写法为
id.info@tag.p.2@text
会多出’更新时间:’几个,用正则后为
id.info@tag.p.2@text##更新时间:
⑤字数规则
写法和分类相同
⑥最新章节规则
可以看到作者在第4个p标签的a标签内,父标签为id:info
写法为
id.info@tag.p.3@a@text
⑦简介规则
可以看到书籍简介id:intro标签内,
写法为
id.intro@text
⑧封面规则
可以看到封面图片在id:fmimg内的子标签img内
写法为
id.fmimg@img@src
⑨目录URL规则
用于获取书籍目录,书籍详情和目录在同一页面的不需要填写
4.目录
如图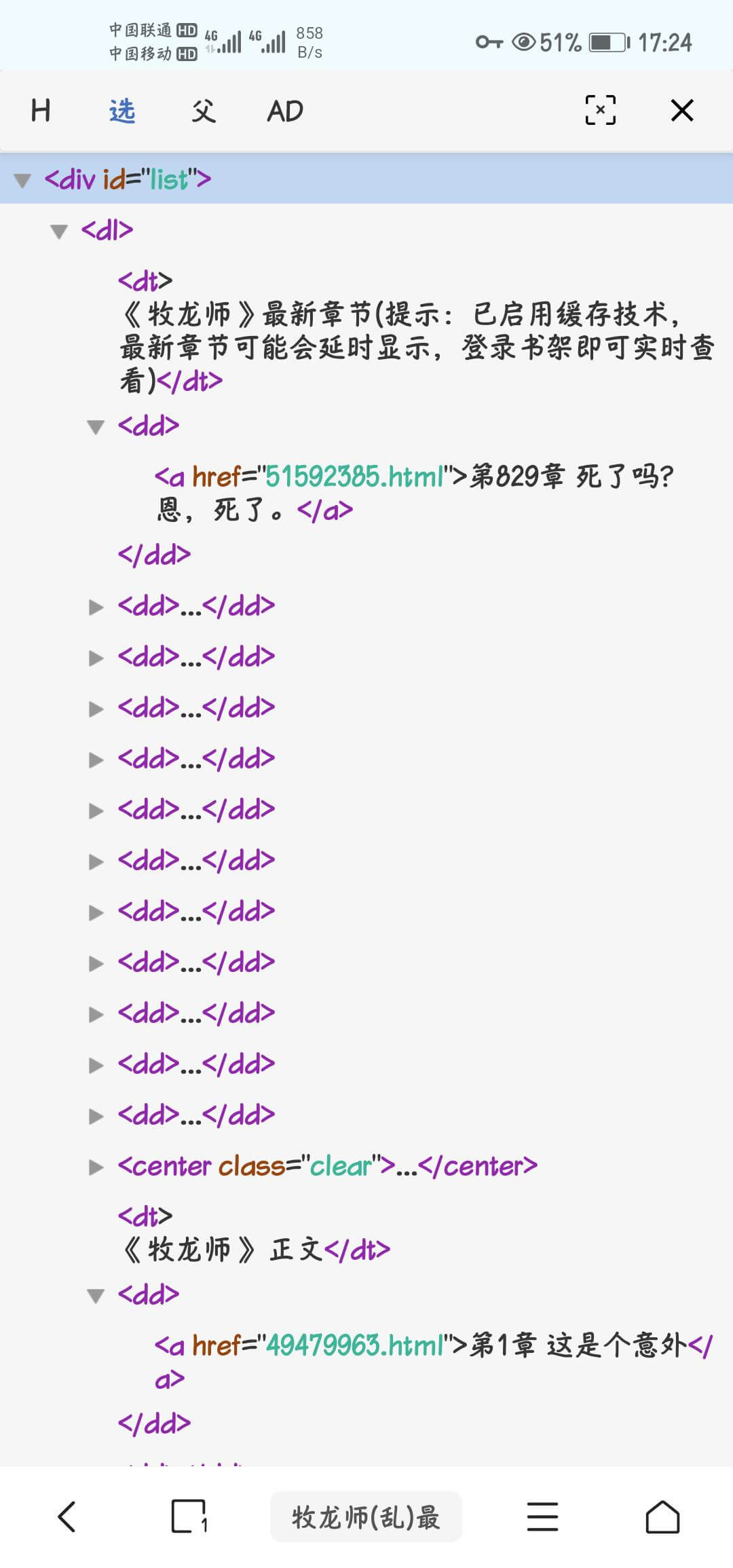
这种上面多余最新多少章的可不用管
①目录列表规则
必填,可以看到目录再id:list标签内,子标签为dd
写为
id.list@tag.dd
②章节名称规则
必填,可以看到书名在a标签内,
可写为
tag.a@text
③章节url规则
可以看到章节url在a标签内,
写为
tag.a@href
④vip标识
⑤更新时间
⑥目录下一页规则
有些目录不在同一个页面,分页的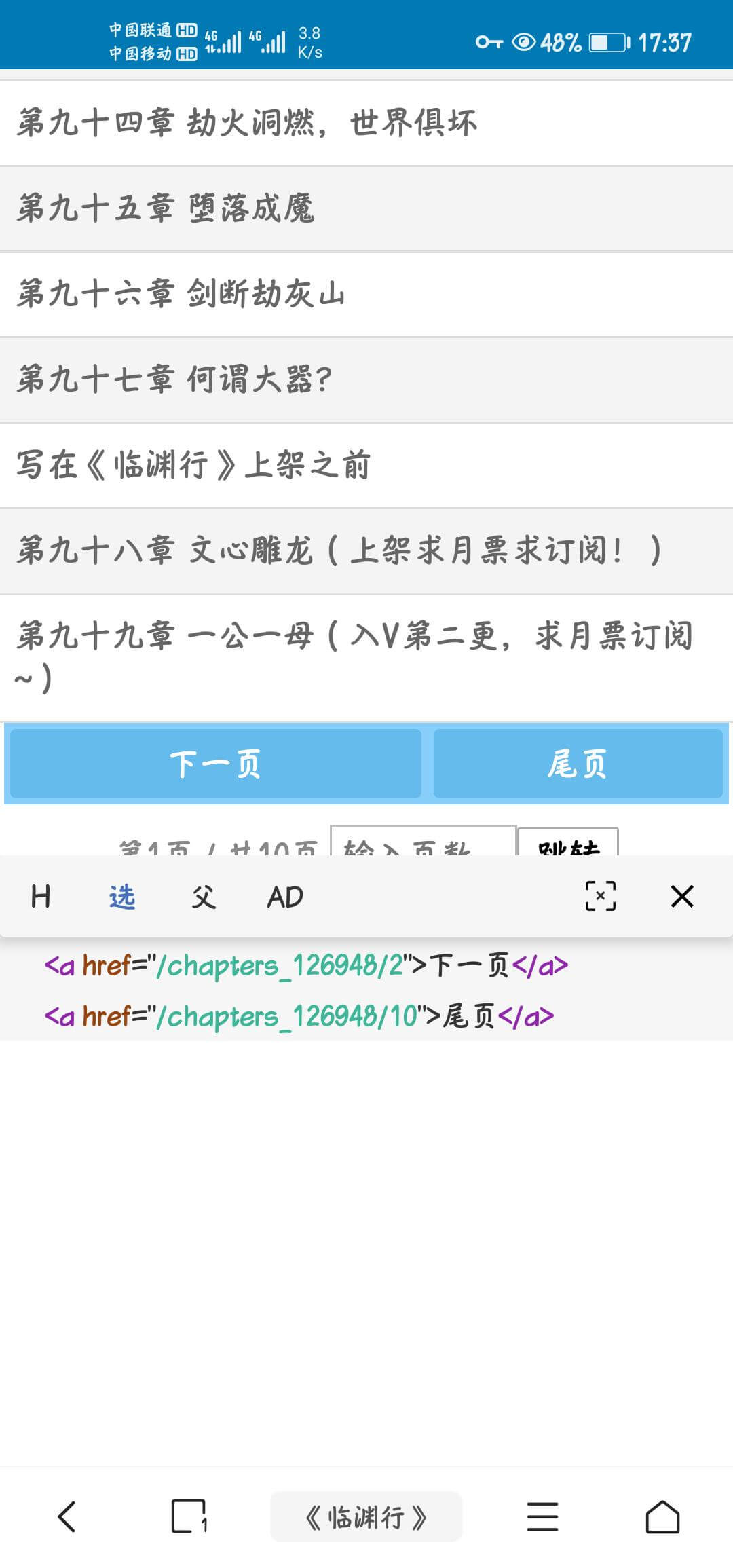
如图,这种下一页和网址同在a标签内可写为
text.下一页@href
其余则需要定位href标签
5 .正文
①正文规则
可以看到正文内容在id:content标签内
写法为
id.content@html或者id.content@textNodes
②正文下一页url规则
有些网站正文内容分多页显示
常见写法有(具体以实际为准)
text.下一页@href或者text.下一章@href
③webviewjs
④资源正则
⑤替换规则
请参考正则写法
⑥图片样式
用于看图片内容,
一般填full

若有收获,就点个赞吧
0 人点赞

{kind=link}
{kind=link}