Hash算法
什么是Hash算法:
在安全加密领域MD5、SHA等加密算法,在数据存储和查找方面有Hash表等,这些都用到了Hash算法。
应用在数据存储和查找领域很多,典型就是hash表,它的查询效率非常高,一个哈希算法设计合理的话,Hash表查询的时间复杂度可以接近与O(1)。
Hash:,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
哈希表:是根据设定的哈希函数H(key)和处理冲突方法将一组关键字映射到一个有限的地址区间上,并以关键字在地址区间中的象作为记录在表中的存储位置,这种表称为哈希表或散列,所得存储位置称为哈希地址或散列地址。作为线性数据结构与表格和队列等相比,哈希表无疑是查找速度比较快的一种。
Hash算法示例
需求:提供⼀组数据 1,5,7,6,3,4,8,找出给定数N是否存在上述集合中
1. 直接寻址法:取关键字或关键字的某个线性函数值为散列地址。即H(key)=key或H(key) = a?key + b,其中a和b为常数(这种散列函数叫做自身函数)
定义一个下标数组,将一组数据中的每个数按下标存放。
缺陷:浪费空间,存在hash冲突
2. 除留余数法:取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。即 H(key) = key MOD p, p《=m。
缺陷:存在hash冲突
3.开放寻址法:在除留余数法上做改进,当遇到hash冲突时,下一个数向前或者向后找可以存入的位置
缺陷:长度定死了,难扩展
4.拉链法:在线性表中每个位置设置一个链表,通过哈希函数计算每个数据应该存入哪个位置的链表中,完善空间小的缺陷。这种方法的性能还要取决于算法是否能将所有数据均摊到不同的位置上。
应用场景
分布式集群架构Redis、Hadoop、ElasticSearch、MySql分库分表、Nginx负载均衡
1)请求的负载均衡(eg:nginx中的ip_hash策略)
Nginx的ip_hash策略可以在客户端ip不变的情况下,将返送的请求始终路由到同一个目标服务器上,实现会话绑定,避免处理session共享问题。
同一个ip使用相同散列函数算出的key是相同的,那么也就能路由到同一个服务器上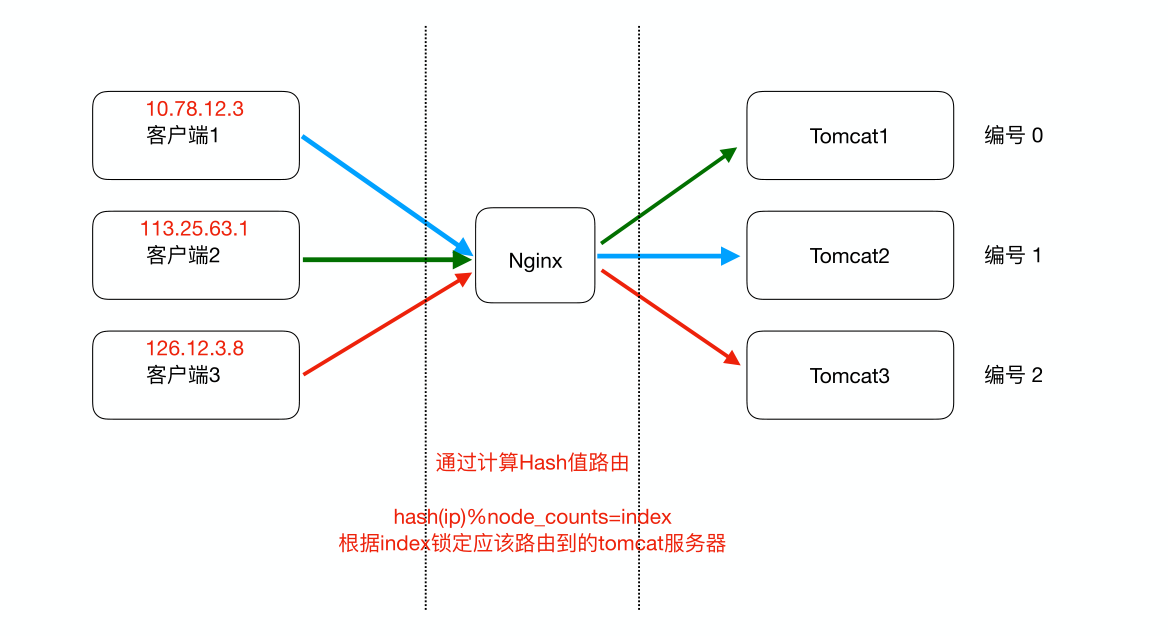
查看对应c代码
ngx_http_upstream_ip_hash_module.c文件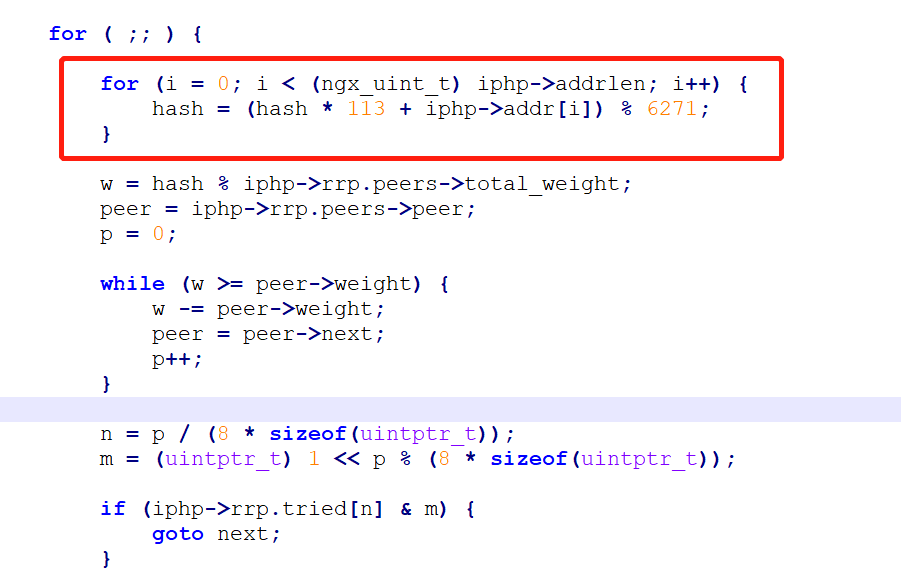
2)分布式存储
以分布式内存数据库Redis为例,集群中有redis1,redis2,redis3 三台Redis服务器那么,在进⾏数据存储时,
普通hash算法存在的问题
缩容扩容时(服务器宕机,增加新的服务器时),当客户端和服务器数量居多,重新路由时对系统影响很大(主要是存在大量的哈希计算,所有ip都要重新计算再去路由)。缩容和扩容都会存在这样的问题,⼤量⽤户的请求会被路由到其他的⽬标服务器处理,⽤户在原来服务器中的会话都会丢失。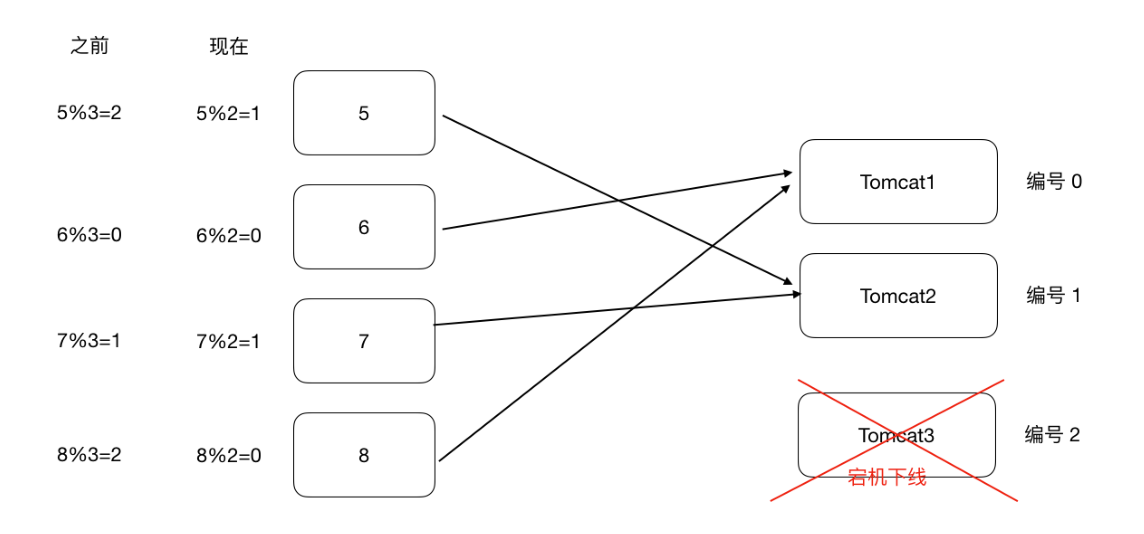
一致性哈希算法(解决普通hash带来的问题)
原理
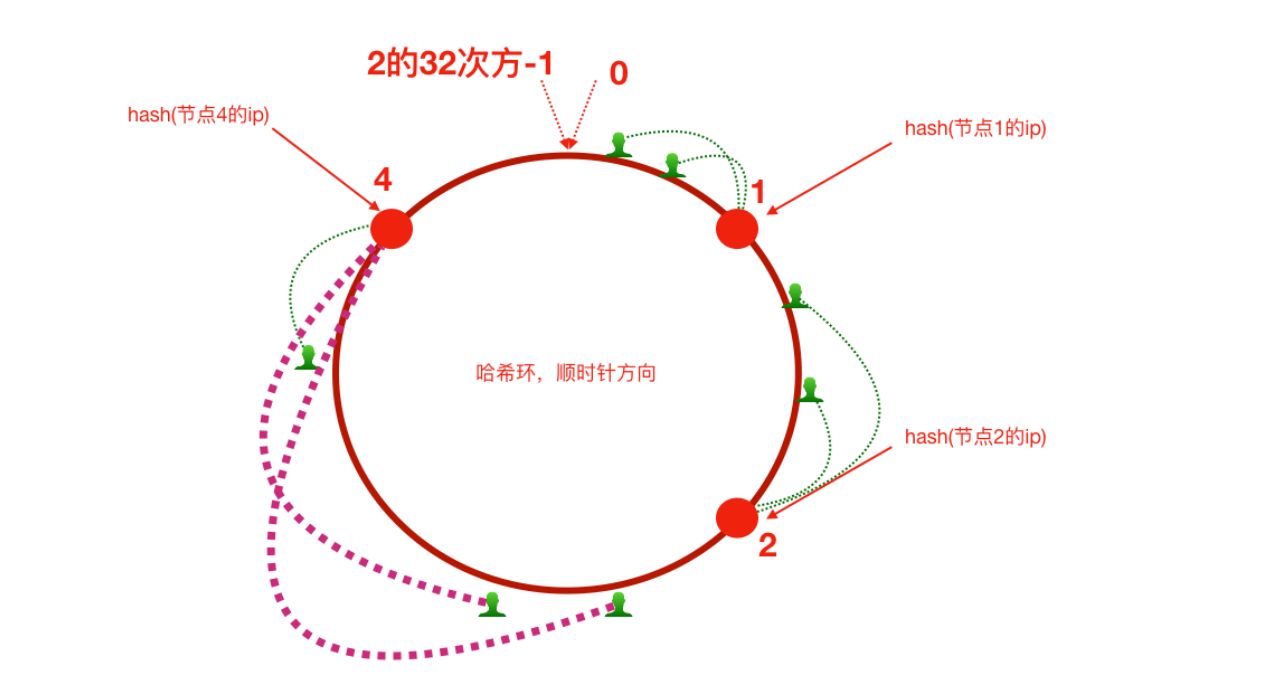
将服务器的ip和客户端ip都定位在hash环上,客户端按照顺时针找离它最近的服务器节点做处理。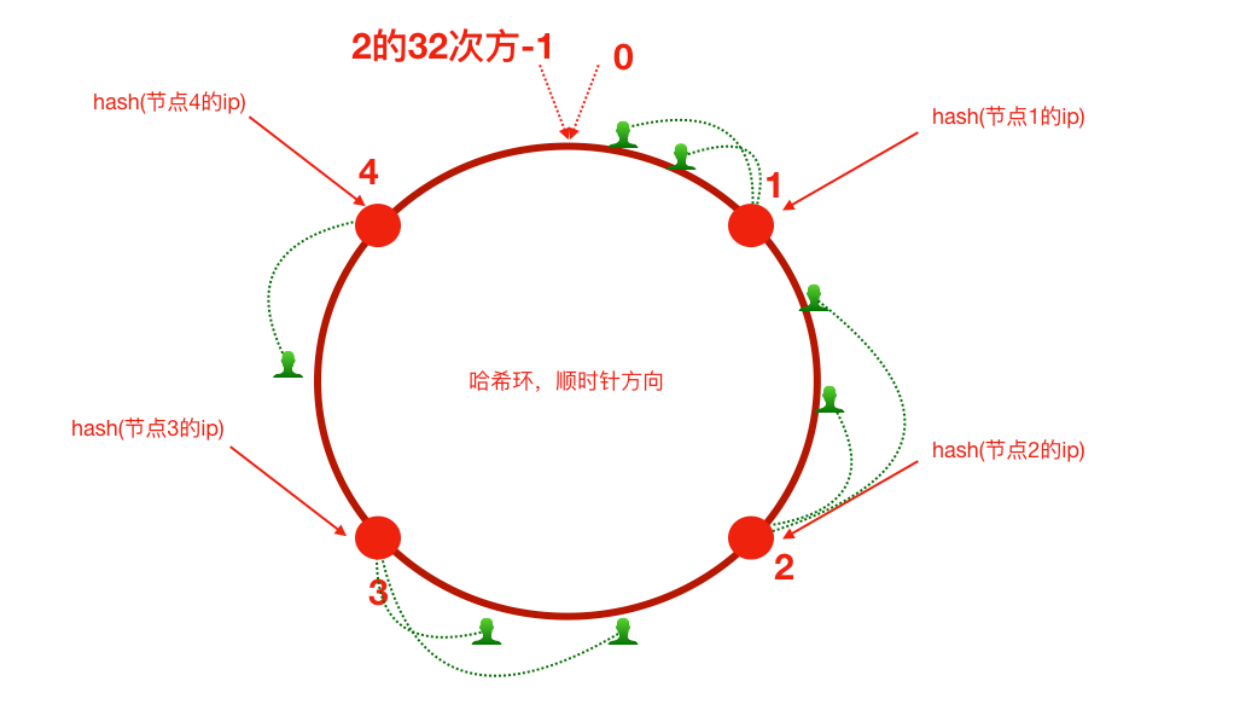
扩容缩容时的变化
缩容
原来路由到3的客户端重新路由到服务器4,请求的迁移达到了最⼩,这样的算法对分布式集群来说⾮常合适的,避免了⼤量请求迁移
扩容
原来路由到3的客户端路由到5上,请求的迁移达到了最⼩,这样的算法对分布式集群来说⾮常合适的,避免了⼤量请求迁移 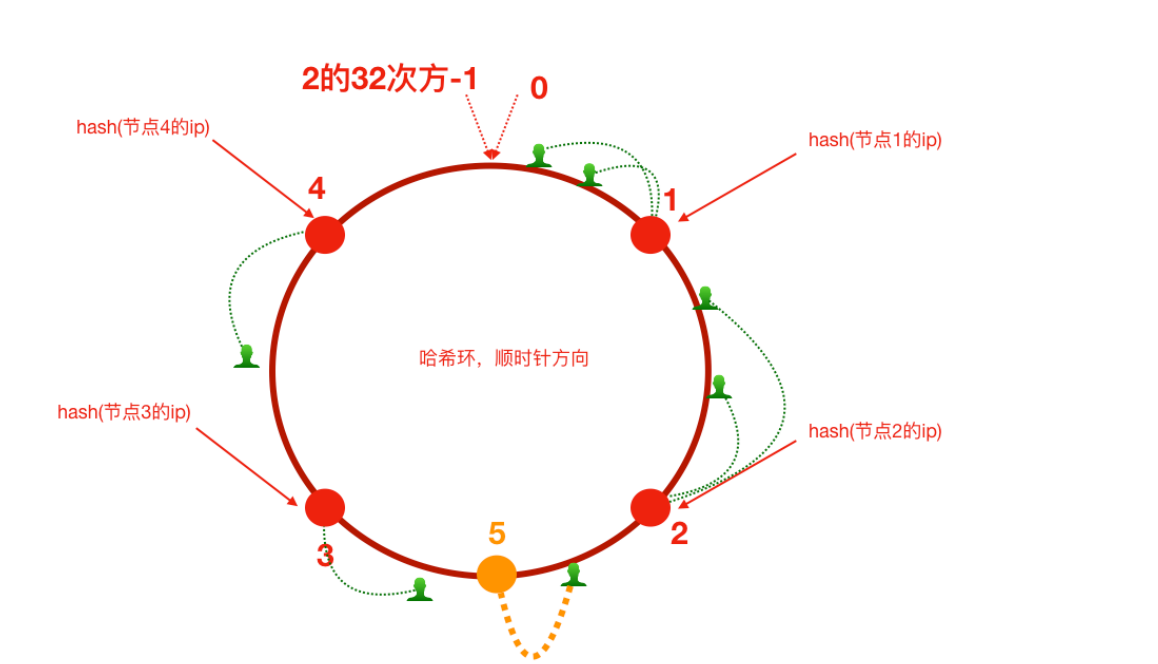
一致性hash算法+虚拟节点
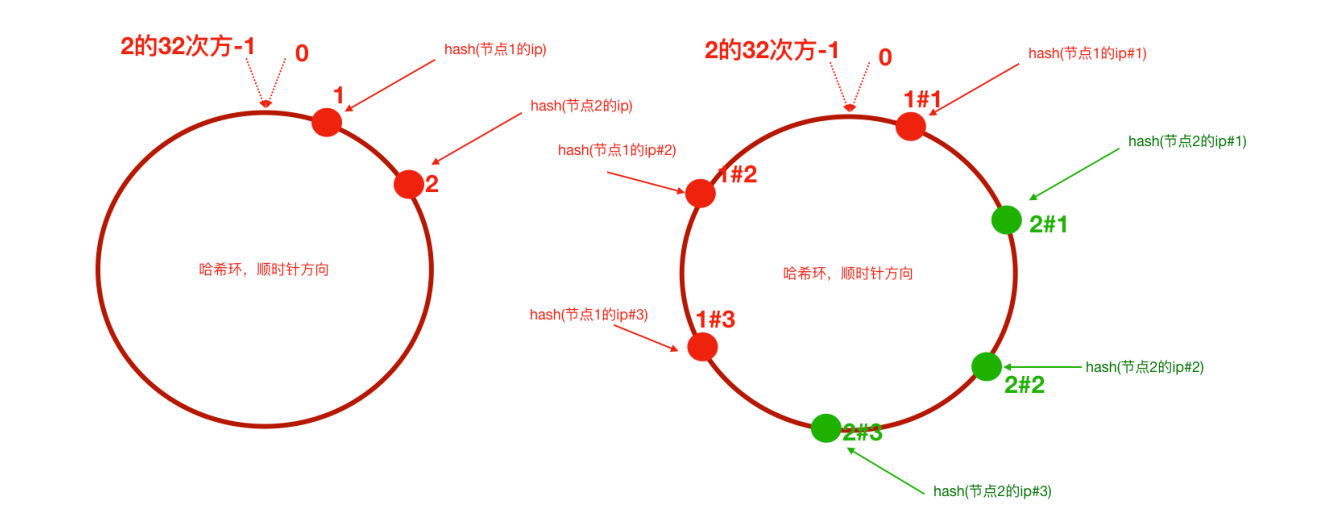
单纯的一致性hash算法对于节点的增减都只需定位换空间中的一小部分数据,具有良好的容错性和可扩展性。
产生问题:当服务器节点在哈希环上较少时,容易因为节点分布不均匀而造成数据倾斜问题。
也就是图中服务器2只能负责1->2中间这一段中客户端的请求,而大量请求(2->1这一段)被交给了服务器1做处理
解决:对服务器增加虚拟节点,虚拟节点也是由真实节点产生,对真实服务器ip做多次hash计算,将服务器ip地址按hash值放置在哈希环上,相当于服务器均匀分布在哈希环上已解决数据倾斜问题。

若有收获,就点个赞吧
0 人点赞
