一、字符函数
字符函数接受字符参数,这些参数可以是表中的列,也可以是一个字符串表达式。
常用的字符函数:
| 函数 | 说明 |
|---|---|
| ASCII(X) | 返回字符X的ASCII码 |
| CONCAT(X,Y) | 连接字符串X和Y |
| INSTR(X,STR[,START][,N) | 从X中查找str,可以指定从start开始,也可以指定从n开始 |
| LENGTH(X) | 返回X的长度 |
| LOWER(X) | X转换成小写 |
| UPPER(X) | X转换成大写 |
| LTRIM(X[,TRIM_STR]) | 把X的左边截去trim_str字符串,缺省截去空格 |
| RTRIM(X[,TRIM_STR]) | 把X的右边截去trim_str字符串,缺省截去空格 |
| TRIM([TRIM_STR FROM]X) | 把X的两边截去trim_str字符串,缺省截去空格 |
| REPLACE(X,old,new) | 在X中查找old,并替换成new |
| SUBSTR(X,start[,length]) | 返回X的字串,从start处开始,截取length个字符,缺省length,默认到结尾 |
二、数字函数
数字函数接受数字参数,参数可以来自表中的一列,也可以是一个数字表达式。
| 函数 | 说明 | 示例 |
|---|---|---|
| ABS(X) | X的绝对值 | ABS(-3)=3 |
| ACOS(X) | X的反余弦 | ACOS(1)=0 |
| COS(X) | 余弦 | COS(1)=0.54030230586814 |
| CEIL(X) | 大于或等于X的最小值 | CEIL(5.4)=6 |
| FLOOR(X) | 小于或等于X的最大值 | FLOOR(5.8)=5 |
| LOG(X,Y) | X为底Y的对数 | LOG(2,4)=2 |
| MOD(X,Y) | X除以Y的余数 | MOD(8,3)=2 |
| POWER(X,Y) | X的Y次幂 | POWER(2,3)=8 |
| ROUND(X[,Y]) | X在第Y位四舍五入 | ROUND(3.456,2)=3.46 |
| SQRT(X) | X的平方根 | SQRT(4)=2 |
| TRUNC(X[,Y]) | X在第Y位截断 | TRUNC(3.456,2)=3.45 |
说明:
1. ROUND(X[,Y]),四舍五入。
在缺省 y 时,默认 y=0;比如:ROUND(3.56)=4。
y 是正整数,就是四舍五入到小数点后 y 位。ROUND(5.654,2)=5.65。
y 是负整数,四舍五入到小数点左边|y|位。ROUND(351.654,-2)=400。
2. TRUNC(x[,y]),直接截取,不四舍五入。
在缺省 y 时,默认 y=0;比如:TRUNC (3.56)=3。
Y是正整数,就是四舍五入到小数点后 y 位。TRUNC (5.654,2)=5.65。
y 是负整数,四舍五入到小数点左边|y|位。TRUNC (351.654,-2)=300。
三、日期函数
日期函数对日期进行运算。常用的日期函数有:
1、ADD_MONTHS(d,n),在某一个日期 d 上,加上指定的月数 n,返回计算后的新日期。
d 表示日期,n 表示要加的月数。
例:SELECT SYSDATE,add_months(SYSDATE,5) FROM dual;
2、LAST_DAY(d),返回指定日期当月的最后一天。
例:SELECT SYSDATE,last_day(SYSDATE) FROM dual;
3、ROUND(d[,fmt]),返回一个以 fmt 为格式的四舍五入日期值, d 是日期, fmt 是格式
模型。默认 fmt 为 DDD,即月中的某一天。
Ø ① 如果 fmt 为“YEAR”则舍入到某年的 1 月 1 日,即前半年舍去,后半年作为下一年。
Ø ② 如果 fmt 为“MONTH”则舍入到某月的 1 日,即前月舍去,后半月作为下一月。
Ø ③ 默认为“DDD”,即月中的某一天,最靠近的天,前半天舍去,后半天作为第二天。
Ø ④ 如果 fmt 为“DAY”则舍入到最近的周的周日,即上半周舍去,下半周作为下一周周日。
例:SELECT SYSDATE,ROUND(SYSDATE),ROUND(SYSDATE,’day’),
ROUND(SYSDATE,’month’),ROUND(SYSDATE,’year’) FROM dual;
与 ROUND 对应的函数时 TRUNC(d[,fmt])对日期的操作, TRUNC 与 ROUND 非常相似,只是不对日期进行舍入,直接截取到对应格式的第一天。
返回两个日期之间的时间间隔自定义函数
首先在oracle中没有datediff()函数
可以用以下方法在oracle中实现该函数的功能:
1.利用日期间的加减运算
天:
ROUND(TO_NUMBER(END_DATE - START_DATE))
小时:
ROUND(TO_NUMBER(END_DATE - START_DATE) 24)
分钟:
ROUND(TO_NUMBER(END_DATE - START_DATE) 24 60)
秒:
ROUND(TO_NUMBER(END_DATE - START_DATE) 24 60 60)
毫秒:
ROUND(TO_NUMBER(END_DATE - START_DATE) 24 60 60 60)
4、EXTRACT(fmt FROM d),提取日期中的特定部分。
fmt 为:YEAR、MONTH、DAY、HOUR、MINUTE、SECOND。其中 YEAR、MONTH、DAY可以为 DATE 类型匹配,也可以与 TIMESTAMP 类型匹配;但是 HOUR、MINUTE、SECOND 必须与 TIMESTAMP 类型匹配。
HOUR 匹配的结果中没有加上时区,因此在中国运行的结果小 8 小时。
例:SELECT SYSDATE “date”,
EXTRACT(YEAR FROM SYSDATE)”year”,
EXTRACT(MONTH FROM SYSDATE)”month”,
EXTRACT(DAY FROM SYSDATE)”day”,
EXTRACT(HOUR FROM SYSTIMESTAMP)”hour”,
EXTRACT(MINUTE FROM SYSTIMESTAMP)”minute”,
EXTRACT(SECOND FROM SYSTIMESTAMP)”second”
FROM dual;
四、转换函数
转换函数将值从一种数据类型转换为另外一种数据类型。常见的转换函数有:
1、TO_CHAR(d|n[,fmt])
把日期和数字转换为制定格式的字符串。Fmt是格式化字符串
代码演示:TO_CHAR对日期的处理
SELECT TO_CHAR(SYSDATE,’YYYY”年”MM”月”DD”日” HH24:MI:SS’)”date” FROM dual;
代码解析:
在格式化字符串中,使用双引号对非格式化字符进行引用
针对数字的格式化,格式化字符有:
| 参数 | 示例 | 说明 |
|---|---|---|
| 9 | 999 | 指定位置处显示数字 |
| . | 9.9 | 指定位置返回小数点 |
| , | 99,99 | 指定位置返回一个逗号 |
| $ | $999 | 数字开头返回一个美元符号 |
| EEEE | 9.99EEEE | 科学计数法表示 |
| L | L999 | 数字前加一个本地货币符号 |
| PR | 999PR | 如果数字式负数则用尖括号进行表示 |
代码演示:TO_CHAR对数字的处理
SELECT TO_CHAR(-123123.45,’L9.9EEEEPR’)”date” FROM dual;
2、TO_DATE(X,[,fmt])
把一个字符串以fmt格式转换成一个日期类型
3、TO_NUMBER(X,[,fmt])
把一个字符串以fmt格式转换为一个数字
代码演示:TO_NUM函数
SELECT TO_NUMBER(‘-$12,345.67’,’$99,999.99’)”num” FROM dual;
五、其它单行函数
1、NVL(X,VALUE)
如果X为空,返回value,否则返回X
2、NVL2(x,value1,value2)
如果x非空,返回value1,否则返回value2
六、聚合函数
聚合函数同时对一组数据进行操作,返回一行结果,比如计算一组数据的总和,平均值
等。
| 名称 | 作用 | 语法 |
|---|---|---|
| AVG | 平均值 | AVG(表达式) |
| SUM | 求和 | SUM(表达式) |
| MIN、MAX | 最小值、最大值 | MIN(表达式)、MAX(表达式) |
| COUNT | 数据统计 | COUNT(表达式) |
七、转换函数
WM_CONCAT
wm_concat(列名)这个神奇的函数,他可以把列值用“,”分隔开,而且是显示成一行
八、分析函数
一、分析函数、窗口函数一般形式
1、分析函数的形式
分析函数带有一个开窗函数over(),包含三个分析子句:分组(partition by), 排序(order by), 窗口(rows) ,
他们的使用形式如下:分析函数名(参数) over (partition by 子句 order by 子句 rows/range.. 子句)
(注:若窗口函数内和sql语句末尾共存在两个order by
a) order by 字段两者一致:即sql语句中的order by子句里的内容和开窗函数over()中的order by子句里的内容一样,
那么sql语句中的排序将先执行,分析函数在分析时就不必再排序;
b) order by 字段两者不一致:即sql语句中的order by子句里的内容和开窗函数over()中的order by子句里的内容不一样,
那么sql语句中的排序将最后在分析函数分析结束后执行排序。)
rank(),dense_rank()与row_number():求排序
rank,dense_rank,row_number函数为每条记录产生一个从1开始至n的自然数,n的值可能小于等于记录的总数。这3个函数的唯一区别在于当碰到相同数据时的排名策略。
①row_number:
row_number函数返回一个唯一的值,当碰到相同数据时,排名按照记录集中记录的顺序依次递增。
②dense_rank:
dense_rank函数返回一个唯一的值,当碰到相同数据时,此时所有相同数据的排名都是一样的。
③rank:
rank函数返回一个唯一的值,当碰到相同的数据时,此时所有相同数据的排名是一样的,同时会在最后一条相同记录和下一条不同记录的排名之间空出排名。
lag()与lead():求之前或之后的第N行
lag和lead函数可以在一次查询中取出同一字段的前n行的数据和后n行的值。这种操作可以使用对相同表的表连接来实现,不过使用lag和lead有更高的效率。
lag(arg1,arg2,arg3)
第一个参数是列名,
第二个参数是偏移的offset,
第三个参数是超出记录窗口时的默认值。
九、开窗函数
开窗函数(over())包含三个分析子句:
分组子句(partition by)
排序子句(order by)
窗口子句(rows)
开窗函数(over())使用形式如下:函数名(列) over(partition by xxx order by yyy rows between zzz)
OVER关键字表示把函数当成开窗函数而不是聚合函数。SQL标准允许将所有聚合函数用做开窗函数,使用OVER 关键字来区分这两种用法。
row_number() over(partition by … order by …)排序,无重复值,partition by 可选,order by 必选
SELECT dept_id,name,age,row_number() over(partition by dept_id order by age)from employee;
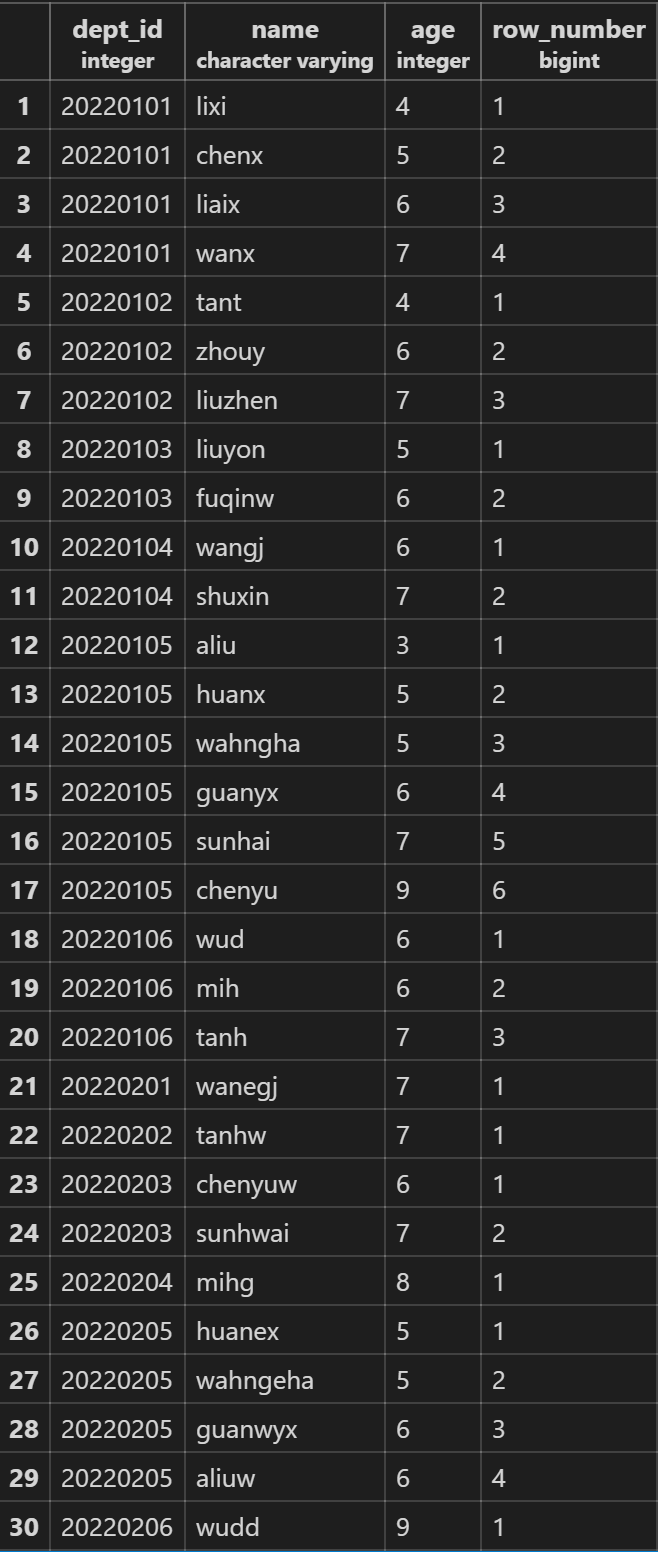
rank() over(partition by … order by …)跳跃排序,partition by 可选,order by 必选
SELECT dept_id,name,age,rank() over(partition by dept_id order by age)from employee;
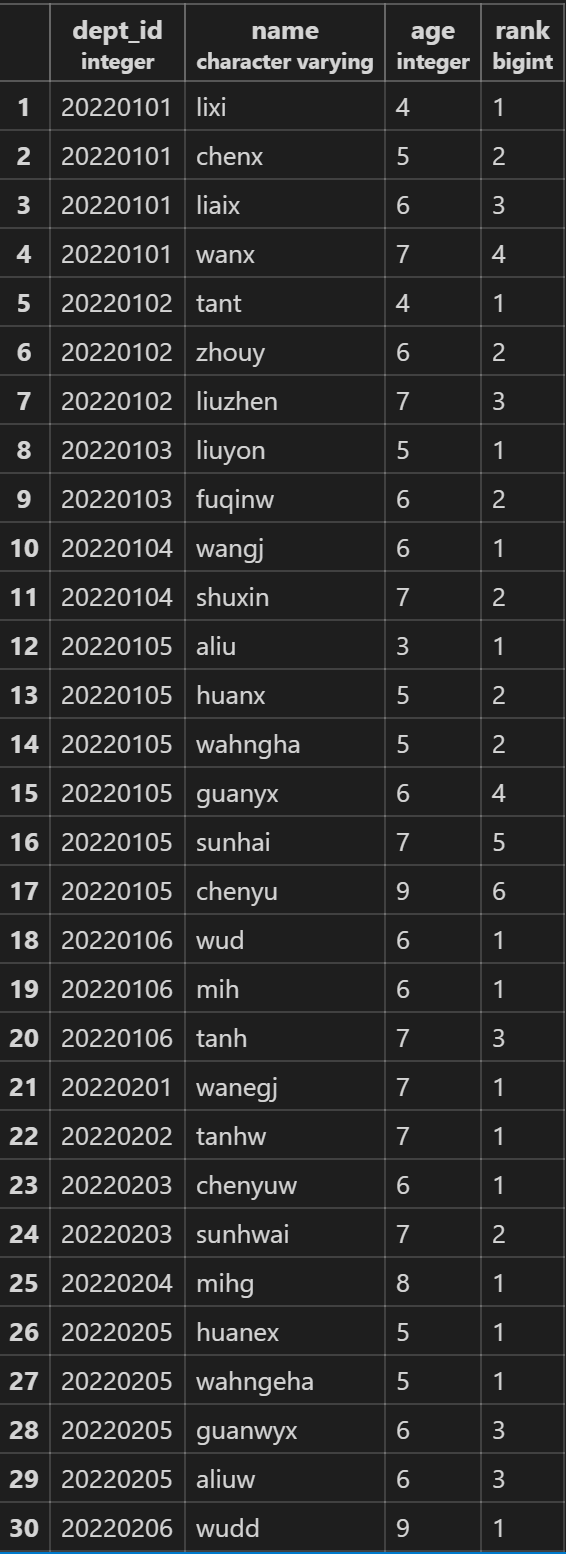
dense_rank() over(partition by … order by …)连续排序,partition by 可选,order by 必选
SELECT dept_id,name,age,dense_rank() over(partition by dept_id order by age)from employee;
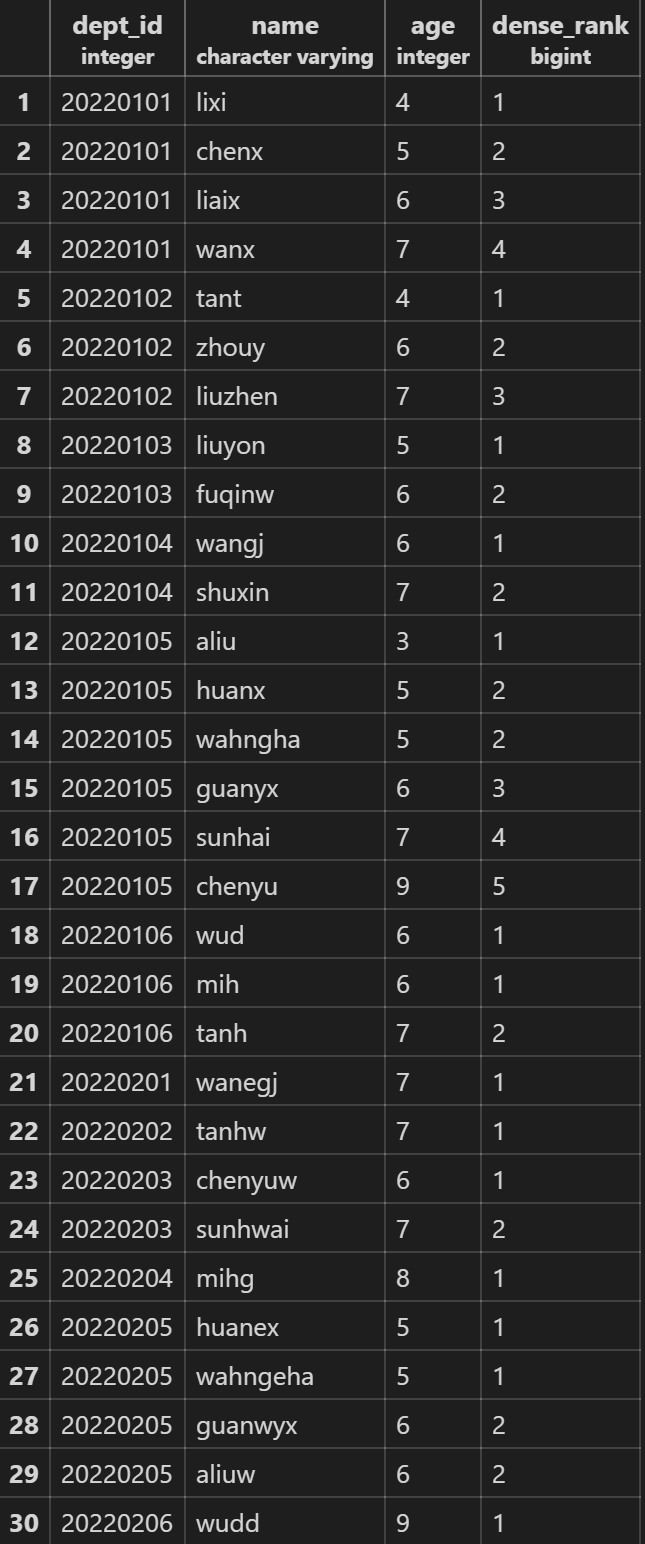
count() over(partition by … order by …)统计分区中各组的行数,partition by 可选,order by 可选
select ename,esex,eage,count(*) over() from emp; --总计数select ename,esex,eage,count(*) over(order by eage) from emp; --递加计数select ename,esex,eage,count(*) over(partition by esex) from emp; --分组计数select ename,esex,eage,count(*) over(partition by esex order by eage) from emp;--分组递加计数
max() over(partition by … order by …)统计分区中记录的最大值,partition by 可选,order by 可选
select ename,esex,eage,salary,max(salary) over() from emp; --求总最大值select ename,esex,eage,salary,max(salary) over(order by eage) from emp; --递加求最大值select ename,esex,eage,salary,max(salary) over(partition by esex) from emp; --分组求最大值select ename,esex,eage,salary,max(salary) over(partition by esex order by eage) from emp; --分组递加求最大值
min() over(partition by … order by …)统计分区中记录的最小值,partition by 可选,order by 可选
select ename,esex,eage,salary,min(salary) over() from emp; --求总最小值select ename,esex,eage,salary,min(salary) over(order by eage) from emp; --递加求最小值select ename,esex,eage,salary,min(salary) over(partition by esex) from emp; --分组求最小值select ename,esex,eage,salary,min(salary) over(partition by esex order by eage) from emp; --分组递加求最小值
sum() over(partition by … order by …)统计分区中记录的总和,partition by 可选,order by 可选
select ename,esex,eage,sum(salary) over() from emp; --总累计求和select ename,esex,eage,sum(salary) over(order by eage) from emp; --递加累计求和select ename,esex,eage,sum(salary) over(partition by esex) from emp; --分组累计求和select ename,esex,eage,sum(salary) over(partition by esex order by eage) from emp; --分组递加累计求和
avg() over(partition by … order by …)统计分区中记录的平均值,partition by 可选,order by 可选
select ename,esex,eage,avg(salary) over() from emp; --总平均值select ename,esex,eage,avg(salary) over(order by eage) from emp; --递加求平均值select ename,esex,eage,avg(salary) over(partition by esex) from emp; --分组求平均值select ename,esex,eage,avg(salary) over(partition by esex order by eage) from emp; --分组递加求平均值
first_value() over(partition by … order by …)取出分区中第一条记录的字段值,partition by 可选,order by 可选
select ename,first_value(salary) over() from emp;select ename,first_value(salary) over(order by salary desc) from emp;select ename,first_value(salary) over(partition by job) from emp;select ename,first_value(salary) over(partition by job order by salary desc) from emp;
last_value() over(partition by … order by …)取出分区中最后一条记录的字段值,partition by 可选,order by 可选
select ename,last_value(ename) over() from emp;select ename,last_value(ename) over(order by salary desc) from emp;select ename,last_value(ename) over(partition by job) from emp;select ename,last_value(ename) over(partition by job order by salary desc) from emp;
lag() over(partition by … order by …)取出前n行数据,partition by 可选,order by 必选
lead() over(partition by … order by …)取出后n行数据,partition by 可选,order by 必选
select ename,eage,lag(eage,1,0) over(order by salary),lead(eage,1,0) over(order by salary) from emp;select ename,eage,lag(eage,1) over(partition by esex order by salary),lead(eage,1) over(partition by esex order by salary) from emp;
十、case when函数
—简单Case函数
CASE sex
WHEN ‘1’ THEN ‘男’
WHEN ‘2’ THEN ‘女’
ELSE ‘其他’ END
—Case搜索函数
CASE WHEN sex = ‘1’ THEN ‘男’
WHEN sex = ‘2’ THEN ‘女’
ELSE ‘其他’ END

若有收获,就点个赞吧
0 人点赞
