一、存储引擎
什么是存储引擎
存储引擎就是在如何存储数据、提取数据、更新数据等技术方法的实现上,底层的实现方式不同,那么就会呈现出不同存储引擎有着一些自己独有的特点和功能,对应着不同的存取机制。
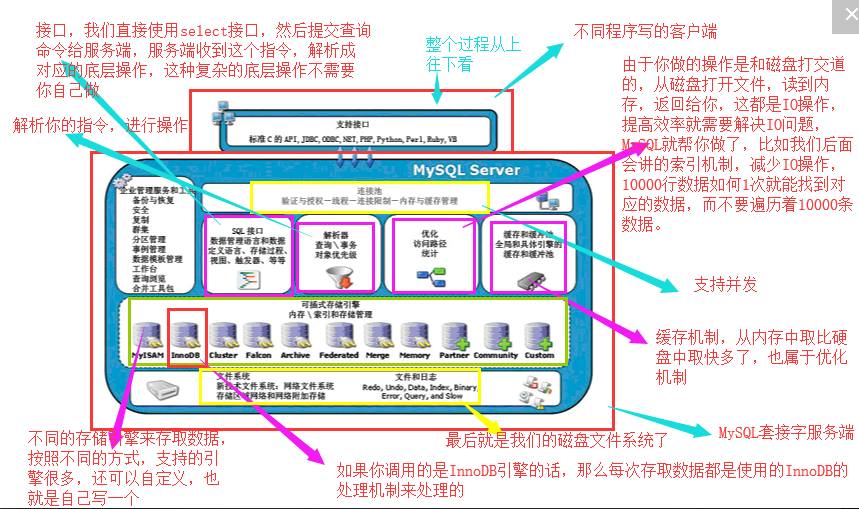
存储引擎分类
最常用的存储引擎主要有MylSAM,MEMORY,Archive,InnoDB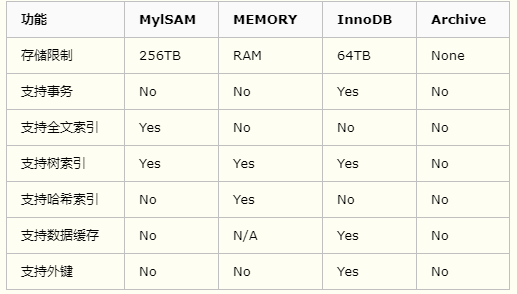
存储引擎的应用场景
MylSAM:不支持事务,读写时锁表,读取和插入不互相阻塞,更新时互相阻塞,适用于大量查询和插入的场景。
Memory:内存型存储引擎,速度快,可存储量偏小,断电时数据丢失,不太安全,适用于少量的,固定不变数据存储例如字典。
Archive:只允许插入和查询,不允许修改,数据会压缩,节省空间,只允许在自增ID列上加索引,数据量非常大的时候插入速度比MylSAM引擎还要快,适用于日志记录等操作
InnoDB:支持事务,使用的锁粒度为行级锁,可以支持更高的并发,数据安全级别和一致性是最高的,但是会牺牲些许性能,适用于更新操作频繁的绝大部分场景,也是使用量最高的存储引擎;
二、事务
事务: 控制一个或者一组sql语句要么不执行,要么全部执行,默认的存储引擎innodb是支持事务的, 而其他存储引擎,如myisam,是不支持事务的
事务的ACID:
- 原子性(Atomicity): 原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生
- 一致性(Consistemcy):不能破坏数据库的一致性状态。
- 隔离性(Isolation): 不同的事务之间互相不能影响。
- 持久性(Durability):事务提交以后,即保存数据,不会再回滚。
mysql中事务的使用
mysql中的insert,update和delete默认会有隐式事务的提交,即每执行一个增删,改的sql,都会自动提交事务
显式事务:事务有明显的开始和结束标记
- 先设置自动提交的功能为禁用
set autocommit=0; - 开启事务: start transaction;(此语句默认会设置自动提交为关闭)
- 结束事务并提交: commit;
- 如果回滚: rollback;
mysql中事务的隔离级别
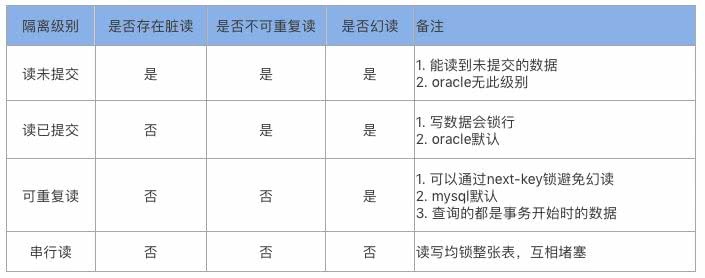
事务并发造成的问题:
1、脏读
事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据。
比如:
B把小明的年龄更新成12岁,但是事务还未提交。此时A来读小明的年龄,读到了12岁,然后去做自己的处理。之后B把小明的年龄回滚到11岁。这个例子中A读到的12岁就是脏数据。
2、不可重复读
事务A多次读取同一数据,事务B在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果不一致。
比如:
B先把小明的余额更新为100元,A来读的时候读到的是100元,然后B又把余额更新为90元,此时A来读的时候读到的就是90元,也就是A读到的数据前后不一致。
3、幻读
事务A对表中的数据进行了修改,涉及到表中的全部行。同时,事务B也修改这个表中的数据,向表中插入一行新数据。那么,事务A发现表中还有自己没有修改的行,就好象发生了幻觉一样。
比如:
A先把所有人的余额清零,同时,B往表中插入了一条余额为100的数据。A提交以后,发现竟然还有100的,命名刚刚都更新成0了呀。
数据库规定了多种事务的隔离级别,不同的隔离级别对应不同的干扰程度,数据一致性就越好,但是相应的并发性能会减弱:
mysql中的4中隔离级别
1、读未提交(read uncommited):能读到未提交的数据。
2、读已提交(read commited):读已提交的数据。
3、可重复读(repeatable read)(默认):mysql默认,查询的都是事务开始时的数据。
4、串行读(serializable):完全串行化,每次开启事务都会锁表,写入互相阻塞。
查看当前的事务隔离级别是什么:
show variables like 'transaction_isolation';
修改事务的隔离级别命令
set [global|session] transaction ISOLATION LEVEL [Read uncommitted|Read committed|Repeatable read|Serializable];
如果选择global,意思是此语句将应用于之后的所有session,而当前已经存在的session不受影响。
如果选择session,意思是此语句将应用于当前session内之后的所有事务。
案例参照:
https://www.cnblogs.com/shihaiming/p/11044740.html
三、索引
什么是索引
索引用于快速的查询某些特殊列的某些行。如果没有索引, MySQL 必须从第一行开始,然后通过搜索整个表来查询有关的行。表越大,查询的成本越大。如果表有了索引的话,那么 MySQL 可以很快的确定数据的位置,而不用查询整个表格。这比顺序的读取每一行要快的多。索引就像我们查字典时的目录一样,我们通过查询字典的目录,可以定位到某一行数据。
专业的话来概括:索引是存储引擎快速找到记录的一种有序的数据结构。(没有特殊指明,这种数据结构一般都是B+树,只不过各个存储引擎在实现的方式上有些许差异)
在创建表时,同时创建普通索引,例如
CREATE TABLE t_user1(id INT ,
userName VARCHAR(20),
PASSWORD VARCHAR(20),
INDEX (userName) #关键字INDEX
);
或者在创建表之后,添加一个索引,
CREATE 【UNIQUE】 INDEX INDEX_NAME ON TABLE_NAME(cloumn1...)
或者
ALTER TABLE TABLE_NAME ADD 【UNIQUE】 INDEX INDEX_NAME(cloumn1...);
适用show index 命令查看索引查看索引
show index from tablename;
常见的索引分类
按照实现方式分类
1. BTREE
InnoDB引擎的mysql表必定会有一个主键
如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键)
InnoDB数据文件本身就是索引文件,这个索引就是主键索引。在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶结点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。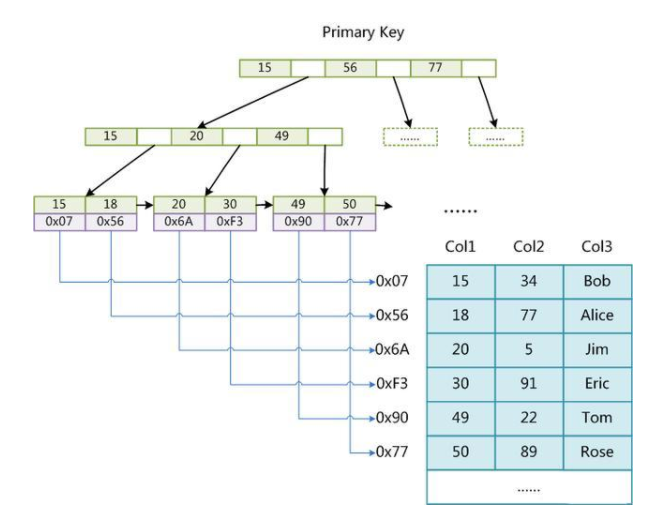
2. HASH 索引
由于HASH的唯一(几乎100%的唯一)及类似键值对的形式,很适合作为索引。HASH索引可以一次定位,不需要像树形索引那样逐层查找,因此具有极高的效率。但是,这种高效是有条件的,即只在“=”和“in”条件下高效,对于范围查询、排序及组合索引仍然效率不高。
3. 全文索引
MySQL 5.6 及以后的版本,MyISAM 和 InnoDB 存储引擎均支持全文索引;
只有字段的数据类型为 char、varchar、text 及其系列才可以建全文索引。
语法:
alter table employee ADD FULLTEXT INDEX INDEX_NAME(column)
#或者
CREATE FULLTEXT INDEX INDEX_NAME ON TABLE_NAME(cloumn1...)
查看最小查询长度命令:
show variables like 'ft_min_word_len';
创建全文索引时指定分词器
CREATE FULLTEXT INDEX INDEX_FULLTEXT_MYDESC ON employee(mydesc) WITH PARSER ngram;
在my.ini初始化文件中添加最小分词器和最小查询长度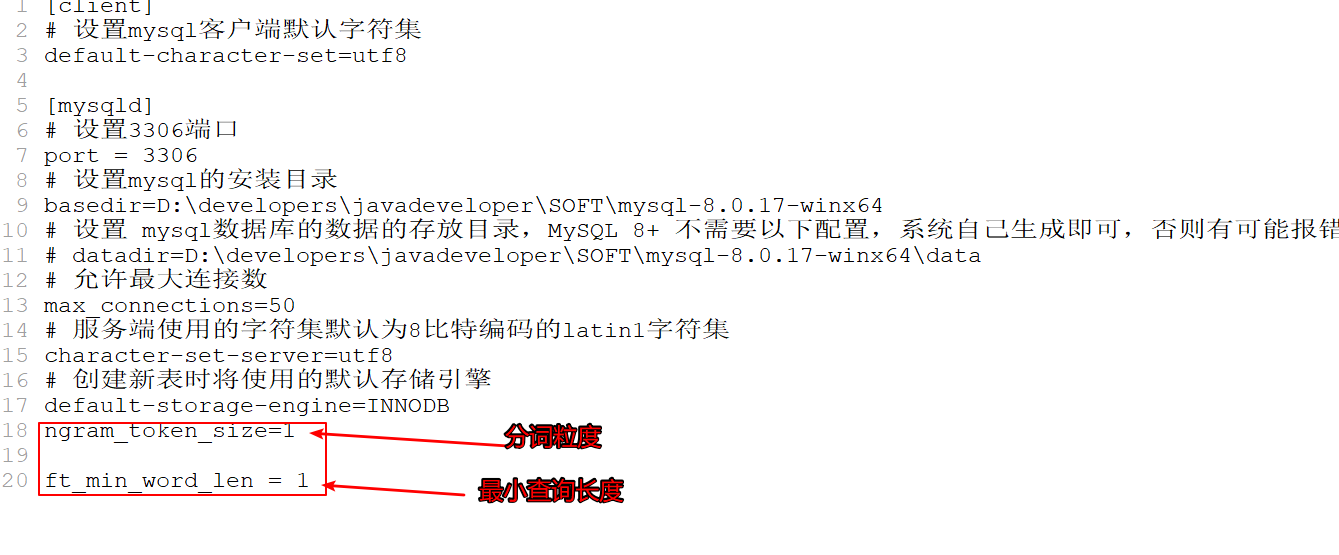
使用全文索引,通过MATCH 和AGAINST函数,例如在desc字段中搜索含有”我爱”的所有数据:
SELECT * FROM employee WHERE MATCH(`desc`) against('我爱' IN BOOLEAN MODE)
4. RTREE
RTREE在MySQL很少使用,仅支持geometry数据类型(适用于坐标点,坐标线计算等),底层为RTREE实现,适用于范围查找
按照种类分类
按照种类分类可以分为:
- 普通索引:仅加速查询
- 唯一索引:加速查询 + 列值唯一(可以有null)
- 主键索引:加速查询 + 列值唯一(不可以有null)+ 表中只有一个
- 组合索引:多列值组成一个索引,专门用于组合搜索

若有收获,就点个赞吧
0 人点赞
