Towards an Intelligent-Interaction Honeypot for IoT Devices
ABSTRACT
近年来,新兴的物联网(IoT)导致了人们对网络嵌入式设备的安全性的关注。现在非常需要开发合适的、成本低廉的方法来发现物联网设备的漏洞,以便在攻击者利用这些漏洞之前解决这些问题。在传统的IT安全领域,蜜罐通常被用来了解动态的威胁情况,而不暴露关键资产。在以前的BlackHat会议上,传统的蜜罐技术已经被多次讨论。在这项工作中,我们专注于蜜罐在提高物联网安全方面的适应性,并论证了为什么我们需要有巨大的创新来构建物联网设备的蜜罐。
由于物联网设备的异质性,手工制作低交互性的蜜罐是不可能的;另一方面,购买所有物理物联网设备来建立高交互性的蜜罐也是不可能的。这种困境迫使我们寻求一种创新的方式来建立物联网设备的蜜罐。我们建议使用机器学习技术来自动学习物联网设备的行为知识并建立 “智能互动 “蜜罐。我们还利用多种机器学习技术来提高质量和数量。
Introduction
近年来,新兴的物联网(IoT)导致人们对网络连接设备的安全性越来越关注。与传统的个人电脑不同,这种物联网设备通常开放网络端口,允许物理世界和虚拟世界之间的互动。2020年,互联设备的数量将从50亿增长到240亿,在医疗、交通、公共服务和电子等不同领域和应用中吸引6万亿投资[5]。著名的物联网设备探索网站Shodan[22]显示,数以百万计的物联网设备暴露在互联网上,没有得到适当的保护。因此,发现物联网设备上的漏洞成为白与黑之间斗争的前沿阵地。
蜜罐是发现0day漏洞的常用方法之一,被安全从业者广泛使用。一般来说,蜜罐模仿现实中的互动,鼓励未经请求的连接来进行攻击。尽管蜜罐是一种被动的方法,但它仍然可以在大规模攻击的早期阶段有效地发现零日漏洞的企图。目前有许多商业蜜罐产品,Github上有超过1000个蜜罐项目。然而,我们发现,大多数物联网设备的蜜罐都是低交互性的,具有固定的回复逻辑和有限的交互水平。
另一方面,物联网设备上的漏洞通常高度依赖于特定的设备品牌甚至是固件版本。这就导致了攻击者在启动攻击代码之前,往往要对远程主机进行多次检查,以收集更多的设备信息。事实证明,对于现有的蜜罐项目来说,这样有限的互动水平不足以通过检查,而无法捕捉到真正的攻击。虽然物联网设备的恶意软件比传统设备相对简单,但如果不正确处理反应,物联网蜜罐的有效性就会受到影响。
在本文中,我们提出了一种以自动和智能方式建立物联网蜜罐的方法,名为智能互动。利用互联网上公开的物联网设备来收集我们蜜罐捕获的请求的潜在响应,我们能够获得不同类型的物联网设备的行为。然而,为了通过攻击者的检查,我们还需要学习最佳的响应,它有更高的概率成为攻击者的预期。我们利用多种启发式方法和机器学习机制来定制扫描程序,并改进回复逻辑,以延长会话,提高捕获利用代码的机会。
本文的其余部分组织如下。第2节简要介绍了蜜罐以及我们建立智能交互式物联网蜜罐的动机。第3节解释了我们如何定制扫描模块,IoTScanner,以收集来自互联网的原始行为知识。第4节讲述了我们如何对物联网反应进行聚类并生成物联网ID,以准确定位物联网设备。第5节讨论了我们如何利用机器学习技术来改善回复逻辑。第6节介绍了评估和我们从捕获的traffic中得出的感兴趣的结论。
2.background and motivation
在本节中,我们讨论了一种模拟物联网设备行为的新方法,以建立一个智能交互式蜜罐。我们面临的困境是,无论是低互动还是高互动的方法,都不能用来建立物联网设备的蜜罐。我们的蜜罐可以同时实现高覆盖率(低交互式蜜罐的优势)和行为缺陷(高交互式蜜罐的优势)。由于我们的蜜罐只模拟物联网设备的行为,攻击者向我们的蜜罐发出的请求和代码将被当作真实设备来处理。因此,与高交互式蜜罐不同,我们的蜜罐不存在被破坏的风险。
2.1 传统的蜜罐
在蜜罐研究领域,有两类蜜罐:高互动和低互动。低互动蜜罐只不过是一个模拟的服务,给攻击者非常有限的互动水平,比如一个流行的叫做honeyd的蜜罐[18];高互动蜜罐是完全伪造的操作系统,使用真实系统让攻击者进行互动。一篇很好的调查报告[4]重新审视了自2005年以来的所有蜜罐研究项目。
低互动和高互动的蜜罐都有优点和缺点。低互动的蜜罐是有限的,而且容易被发现;高互动的蜜罐通常比较复杂,而且部署和维护往往需要更多时间。此外,部署高互动蜜罐时涉及更多的风险,因为攻击者可以完全控制蜜罐并滥用它,例如,攻击互联网上的其他系统。因此,有必要引入和实施数据控制机制,以防止蜜罐的滥用。这通常是使用非常危险和资源密集型的技术,如第三代蜜网中的全系统模拟器或rootkit型软件[2]。
关于自动构建高交互性蜜罐的研究。[7, 13, 14]已经研究了自动构建蜜罐的交互系统。他们研究了如何以独立于协议的方式对某些请求产生响应,包括traffic聚类、建立状态机和简化状态。然而,我们的工作与之前的研究的主要区别在于,所有之前的项目都依赖于一个从实时traffic捕获的特定协议的大型数据集。以这个数据集为基础,他们从traffic中提取共同的结构作为模板,并生成随机数据来填充模板。另一方面,由于物联网设备的各种定制协议,很难找到这样一个干净和完整的traffic数据集。此外,实时的traffic只包含小部分的恶意traffic,很难从数据集中识别它们。由于蜜罐只需要模拟攻击者感兴趣的行为,而这些行为会导致漏洞的出现。没有必要学习所有的行为,但重要的是学习关键的行为,这些行为极有可能从实时的traffic中被遗漏。
物联网蜜罐的挑战。蜜罐并不是一个新话题。大量的蜜罐框架(如honeyd [18], GenIII honeynet [2], and nepenthes [1])已经开源或商业化。为什么我们要讨论在物联网设备上建立一个蜜罐?简短的回答是,物联网蜜罐不能建立在传统的蜜罐技术上。物联网设备的异质性特点使得开发低交互性的物联网蜜罐非常耗时;而真实设备的价格以及仿真器的缺乏使得构建高交互性的物联网蜜罐成为不可能。
我们必须用我们为物联网设备创建原型蜜罐的历程来解释它。非常直接的方法是搜索开源的物联网蜜罐,我们确实找到了很多,如IoTPot [17], SIPHON [9]等。然而,所有这些都是低互动的蜜罐,如 “Honeyd”[18],它只不过是一个模拟的服务,给攻击者的互动水平非常有限。显然,那些低交互性的蜜罐只能为我们获得有限的信息。由于物联网设备的异质性,模仿来自不同供应商的不同类型的物联网设备的互动是具有挑战性的。虽然不是不可能,但这需要大量的技术工作,不容易被重复使用。例如,考虑到IP摄像机的情况,为了以现实的方式可视化或模拟其行为,我们不仅需要向攻击者播放一些视频,还需要对倾斜摄像机等命令做出忠实的反应。
既然低交互式蜜罐不能满足我们的需要,我们就转向另一个方向,建立高交互式蜜罐,这也是不可能的。有两种方法可以建立一个高互动的蜜罐:物理或虚拟。在传统的定义中,物理蜜罐是网络上的一台真实机器,有自己的IP地址。在物联网的背景下,这意味着我们需要购买不同品牌和不同类型的真实物联网设备,并将它们连接到互联网。由于空间有限和资金限制,这种解决方案并不实用,更不用说引入和实施数据控制机制以防止蜜罐被滥用的风险。另一方面,虚拟蜜罐是一种模拟脆弱系统或网络的软件。但事实是,与操作系统(如安卓、Windows)不同,大多数物联网设备没有任何可用的模拟器。
2.2 智能交互式蜜罐
为了应对这些挑战,我们提出了一个通用框架,为物联网设备建立一个智能交互式蜜罐。我们将解释如何以及为什么我们需要智能交互式蜜罐。
什么是智能互动?智能互动的目标是学习 “正确 “的行为,从对物联网设备的零知识中与客户进行互动。对客户端的正确反应应该能够延长与潜在攻击者的会话,欺骗他们通过检查并发送利用请求。为了实现这一目标,需要我们的系统自动收集有效的响应作为候选人,通过与攻击者互动,学习过程帮助蜜罐优化每个请求的正确行为。
智能互动是如何工作的?图1说明了我们系统的概况。有4个主要组件分别运行,但在学习过程中相互共享数据。IoT-Oracle是一个中央数据库,存储了我们获得的有关物联网设备的所有信息。蜜罐模块包含我们在亚马逊AWS和数字海洋上部署的蜜罐实例。它们的目的是接收攻击的轨迹,并与攻击者互动,诱使他们进行真正的开发。他们将定期与物联网甲骨文同步,将新收到的原始请求推送到原始请求表中,并检索物联网知识表,以了解物联网设备的最新情况。
IoTScanner模块利用捕获的攻击请求作为种子知识,并在互联网上扫描任何能够响应这些请求的物联网设备。收集到的响应将被存储在原始响应表中,以便进一步分析。IoTLearner模块利用机器学习算法,根据攻击者对给定响应的反馈来训练一个模型。经过几轮的学习迭代,我们的蜜罐可以优化一个模型来回复攻击者。
在最开始的时候,我们的系统表现得完全像低交互式蜜罐,因为我们的系统从对物联网设备及其行为的零知识开始。我们已经评估过,在很短的时间内,蜜罐可以覆盖很多物联网设备。
仿真是否足够?对于高互动性的蜜罐,它们通常在虚拟机中部署真实的系统或模拟器,以对攻击者作出反应(例如,响应请求或执行上传/注入的脚本)。我们的蜜罐纯粹是根据学到的知识来生成反应,但不运行它。由于物联网设备的攻击面,大多数攻击是使用HTTP请求和其他物联网相关协议发起的,并最终试图在没有认证的情况下注入命令或获得登录凭证。注入的命令非常简单和简洁,通常由一个wget命令组成,从恶意服务器向设备投放一个shell(busybox)代码,为其分配权限并执行它。攻击和注入的命令的细节可以在第3.4节中找到。我们的目标是捕获注入的脚本并从中提取恶意的shell代码。因此,与攻击者的互动并不复杂,只需对他们作出回应。因此,模拟物联网设备的行为就足以建立一个有效的蜜罐。
为什么是智能交互?正如我们在前面的段落中所讨论的,当代对物联网设备的攻击往往是简单而直接的,使用蜜罐不难捕捉到它们。然而,对于大多数攻击,攻击者通常对目标设备做一些检查,以了解设备是否有漏洞。利用前面的例子(CVE-2016-6433),在发送攻击请求之前,攻击者可能会检查设备是否为Cisco Firepower,版本是否为6.0.1。这可以通过发送请求到{ ip } :443/img/favicon.png?v=6.0.1-1213并检查响应状态是否为200来完成。如果这些步骤中的任何一个失败了,攻击者将停止攻击,我们的蜜罐可能无法捕捉到真正的漏洞。
3.物联网扫描器:主动探测物联网行为
构建智能交互蜜罐的第一步是收集所有类型的物联网设备的响应。幸运的是,从互联网上,我们可以找到所有可以访问的物联网设备。因此,我们设计并实现了一个模块,即物联网扫描器,以主动探测互联网上的物联网设备,并收集它们对我们从蜜罐中捕获的各种请求的响应。扫描的结果将存储在中央数据库中,作为我们的 “原始 “知识,用于进一步的学习过程。
重要的是,我们希望我们的探测是有礼貌的,并防止不需要的访问互联网。我们探测的细节可以在我们以前的工作中找到[24]。为了使扫描过程既有效又不违法,我们采用了多种方法来缩小远程主机的范围,使追踪更与物联网相关,并消除有害的请求。
3.1 IP过滤
与43亿的IPv4地址空间相比,物联网设备的数量仍然很小。收集物联网设备的IP地址子集不仅可以提高我们扫描结果的质量,还可以加快扫描过程。据我们所知,我们无法找到一个可靠而完整的物联网设备IP地址集。因此,我们从头开始建立自己的物联网IP地址数据库。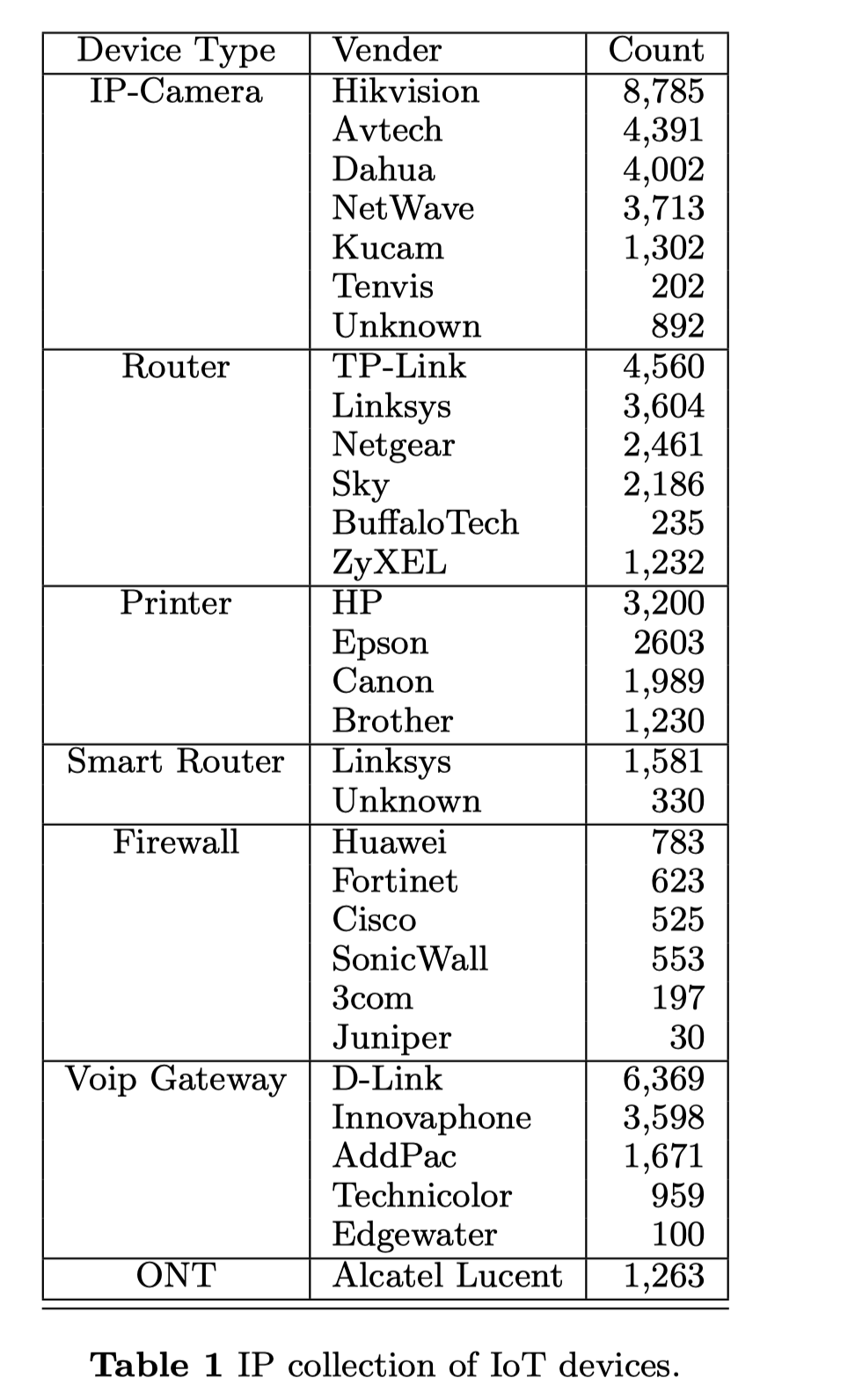
我们从Censys[6]、ZoomEye[25]和Shodan[22]等在线平台或者我们自己部署的端口扫描工具(例如MASSCAN[15])获取原始IP信息。
我们使用端口扫描工具来收集某个IP地址的基本信息,比如远程机器的开放端口,以及该开放端口的标语信息。这些在线平台也收集了类似的信息,但他们提供了查询工具,以更方便地搜索他们的数据库,其中(1)给定一个端口号,有哪些IP地址打开了这个端口?(2)给定一个关键词,有哪些IP地址提供含有该关键词的内容?
目前,广泛采用的方式是使用不同类型的横幅信息来确定给定IP地址背后的机器是否是物联网设备。例如,Telnet banner 信息可以用来识别设备类型。自 “1990年计算机滥用法 “公布以来,人们强烈建议计算机在允许用户登录前显示横幅。登录横幅是在未经授权的访问之前通知off者的最佳方式。
因此,我们在这些平台上连续进行两次搜索。1)搜索端口号(2)搜索关键词,即物联网设备的品牌名称。我们定期在我们的数据库中存储和更新这些信息。首先,我们定期通过现有的开放平台搜索信息。在使用这些信息之前,我们会再进行一圈同步扫描,以验证端口是否确实开放。如果是这样,我们将把这些IP视为更优先的,并探测它们以收集可能的回应。到目前为止,我们已经收集了超过40000个物联网设备的IP地址,如表1所示。除了来自开放平台的反馈,如果我们的目标端口对物联网设备来说是唯一的,我们也会进行全互联网的探测。
3.2 端口过滤.
在65535个端口中,物联网设备可能只监听其中一小部分进行交互。其中最受欢迎的是TR-069服务的7547端口,它是基于SOAP的终端用户设备远程管理协议。它通常被物联网设备使用,如调制解调器、门路、路由器、VoIP电话和机顶盒。另一个例子是用于通用即插即用(UPnP)协议的1900端口,67%的路由器开放了这个端口,以方便设备和程序发现路由器和它们的相应配置。对于通过嵌入式网络服务器提供远程配置的物联网设备,它们通常会开放80、8080、81等端口。我们还监测和扫描了物联网设备大量使用的协议所使用的端口,包括XMPP的端口5222,CoAP的端口5683,以及MQTT的端口1883/8883。表2强调了我们从分析和先前的调查[16]中确定的端口列表,我们将优先扫描这些端口上的traffic.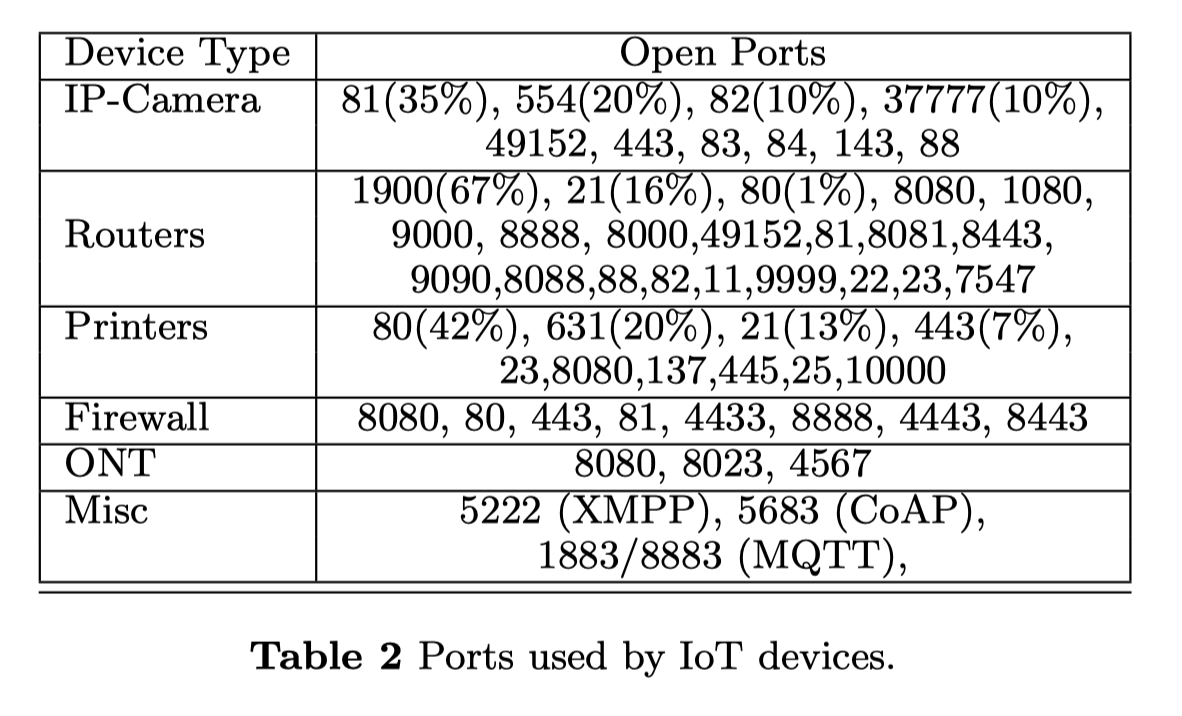
3.3 种子请求过滤。
我们的扫描器的关键输入之一是由蜜罐捕获的请求。我们的目标是学习物联网设备对每个请求的反应,以便模拟这些行为。在我们的数据库中,我们在过去几个月中总共存储了大约1800万个原始请求。扫描所有这些请求是不可行的,也是不科学的,我们清理了原始请求数据库,以消除明显与物联网无关的痕迹。例如,近一半(53%)的捕获请求不包含有效载荷。其他非物联网请求包括BitTorrent协议(7%)、MS-RDP协议(5%)和SIP协议(4%)。值得注意的是,在HTTP流量中,有两类特殊流量:HTTP代理流量(6%)是由代理机构重定向的(通常看起来像 “GET http://full-url HTTP/1.1”),以及仅用于根路径的扫描流量(1%)。对于UDP traffics,我们还发现其中大部分(6%)是一些外壳代码,如使用busybox的命令。通过应用我们上面解释的启发式方法,我们成功地将扫描的原始请求总数从1800万个减少到100万个以下(如图2所示)。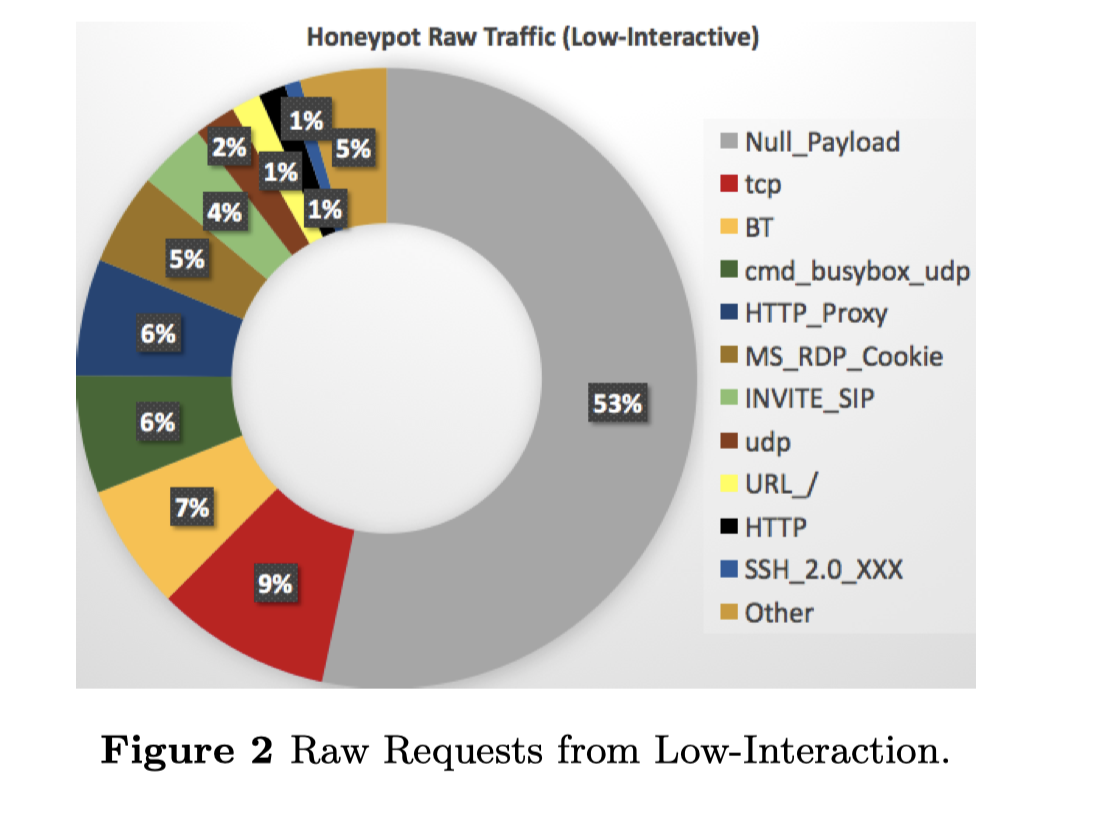
此外,我们根据端口对traffic进行分组,并进一步减少每组中的重复和类似请求。图3显示了每个端口的请求数量。最受欢迎的端口攻击者倾向于扫描80端口,超过90%的traffic是有意义的HTTP请求。由于最近的僵尸网络Mirai,在过去几个月里,7547端口的扫描突然增加。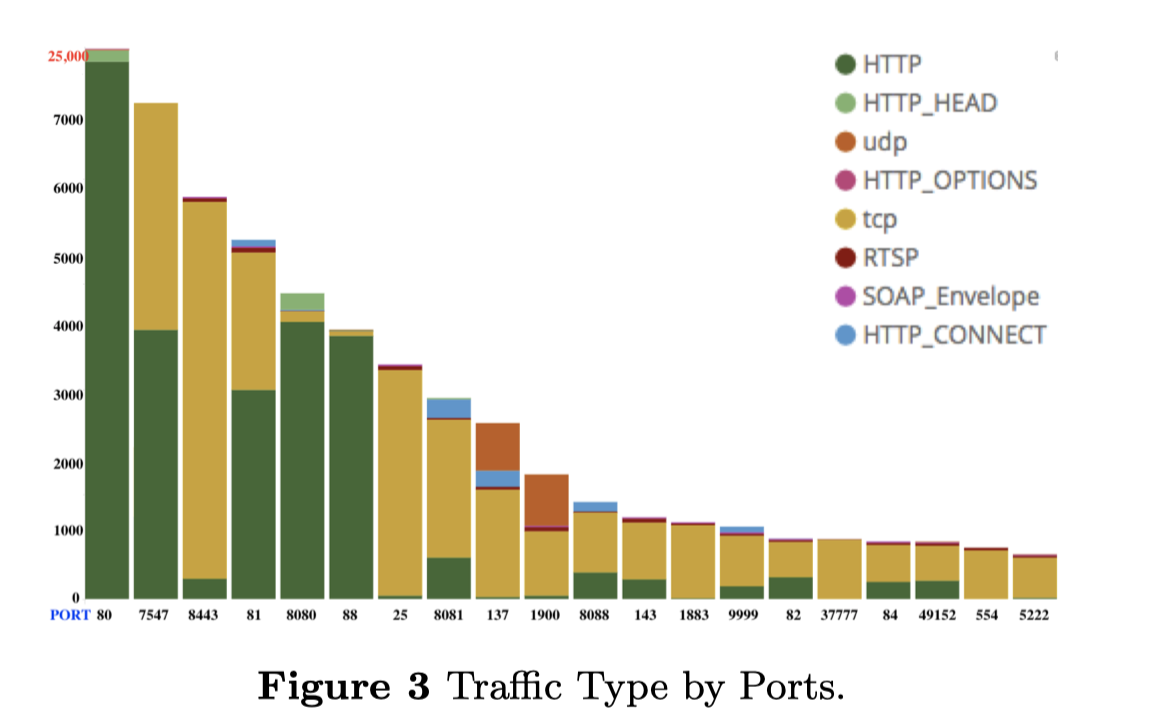
3.4 漏洞追踪过滤
当我们使用捕获的流量作为扫描互联网的内容时,重要的是要过滤掉危险的流量,如含有漏洞代码的请求。在我们的系统中,我们利用多种启发式方法和现有的检测工具(例如Snort规则,我们的防火墙)来检测流量中的漏洞代码。一旦检测到攻击请求,我们将对其进行标记,不会用它来扫描,这意味着我们的模拟将在这个阶段停止。
远程命令执行(RCE)。命令注入是物联网设备上最普遍的攻击之一。攻击者通常在请求中嵌入恶意的shell代码,并将其发送给易受攻击的设备。由于执行不力,易受攻击的物联网设备将在未经授权的情况下执行注入的命令。通常情况下,注入的代码可以以处理请求的脆弱程序(如网络服务器)的权限执行。
HTTP POST请求中的主体是最常见的嵌入命令的地方。其他协议也可以用来注入命令。例如,Mirai僵尸网络使用一个记录在案的SOAP漏洞入侵其他设备,该服务允许ISP使用TR-069协议(端口7547)配置和修改特定调制解调器的设置。其中一个设置允许错误地执行Busybox命令,如wget来下载恶意软件。例如,NewNTPServer1 field中的嵌入式shell-code会丢弃恶意代码并执行它。
其他协议也可以用来嵌入恶意的shellcode。例如,多种类型的D-Link路由器容易受到UPnP远程代码执行攻击,允许在SSDP广播包中嵌入壳代码。M-SEARCH数据包的内容变成了shell参数。
混淆和解码是逃避检测的一种常见方式。例如,我们捕捉到了网址/shell?%75%6E%61%6D%65%20%2D%61的踪迹,它是由原始网址/shell?uname+-a解码而来,用于命令注入。我们还整合了对常用的混淆机制的检测。
信息泄露。由于缺乏访问控制和认证,大量的物联网设备无意中泄露了其配置信息和系统的其他敏感信息。通常,这些信息可以被利用来发动更强大的攻击。虽然这对目标远程设备没有危害,但我们也会对这类请求进行净化处理。例如,D-Link个人Wi-Fi热点,DWR-932,暴露了CGI脚本/cgi-bin/dget.cgi来处理大部分的用户端和服务器端请求。它回复来自未授权用户的请求,因此攻击者可以通过填充DEVICE web passwd作为url中cmd参数的值来查看管理或wifi密码的明文。路径遍历是另一种收集泄漏信息的攻击方式,例如通过像…/…/…/etc/shadow这样的url。
数据篡改。物联网设备上的很多漏洞都允许攻击者篡改设备上的数据。例如,由操作系统AirOS 6.x驱动的物联网设备允许未经认证的用户通过AirOS Web服务器的HTTP上传和替换任意文件到airMAX设备,因为 “php2”(也许是因为一个补丁)不验证POST请求的 “filename “值。攻击者可以通过覆盖/etc/passwd或/tmp/system.cfg等文件来利用该设备。与检测路径遍历攻击类似,我们对请求中敏感文件的路径进行净化处理。
3.5 扫描结果
由于预算问题,我们只在实验室的3台机器上部署了我们的物联网扫描器。它们从一个共享的Redis队列中获取种子请求,新捕获的请求也将被插入这个队列中。每一秒钟,我们使用不同的线程发送300个不同的请求,并设置超时为3秒。为了加快扫描过程,我们倾向于重复使用已建立的会话到之前扫描的IP地址。因此,我们在同一时间向同一台主机发送10个请求。我们也有3台机器定期检查现有标记的物联网设备的开放端口的变化,并通过互联网扫描以找到更多可用的主机。
对于现有的种子请求,我们在一周左右成功完成了扫描,并在数据库中收集了200万个响应,尽管很多开放端口未能回复任何响应或重置连接。由于大部分的扫描数据是HTTP traffic,我们从中提取状态码(表3)来快速分析它们。对于所有的端口,403(禁止)、404(未找到)和401(未授权)的响应代码是来自物联网设备的前三个状态代码。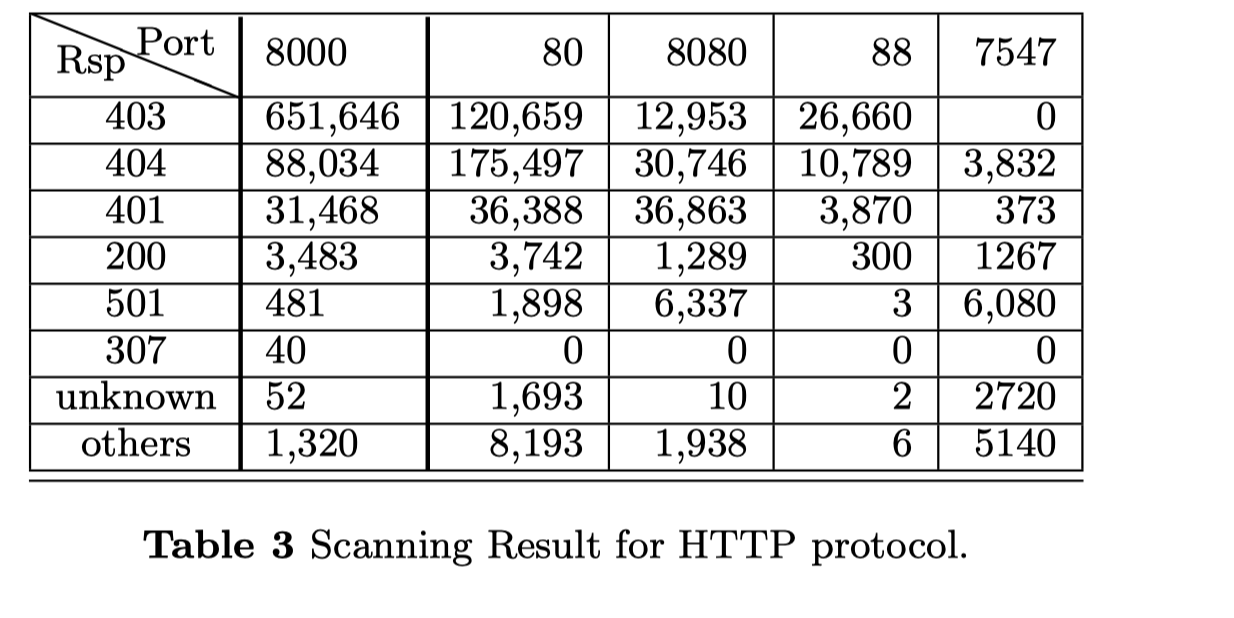
4. iot-id: 精确定位iot设备
目前,我们确定一个给定的IP地址背后的机器是检查响应中是否存在一些预先设定的关键字或模式。例如,如果我们发现给定的IP地址中的一个端口返回一个包含模式 “NETGEAR WNR1000v3 “的头,我们就可以知道这个IP地址背后的机器是一个netgear路由器和它的版本。然而,许多因素可能导致物联网设备的信息不明确甚至错误。例如,我们观察到一些IP地址返回多个物联网设备在不同端口的横幅内容。它在80端口返回一个摄像头的登录入口,在99端口返回一个交换机的管理页面。 另一个问题是,我们发现成千上万的物联网设备经常改变它们的IP地址。结果,当我们从它那里获取横幅内容时,我们将IP地址标记为物联网设备,而当我们扫描它以收集对各种请求的响应时,它又变成了非物联网设备。
因此,我们提出了IoT-ID的概念,使我们能够区分不同的IoT设备并获得它们的准确知识。我们的想法是利用机器学习算法对扫描结果进行聚类,并从中提取模式作为某类物联网设备的特征。
基于LDA的解决方案。为了找到签名,我们仔细研究了我们收集的物联网轨迹。我们对traffic的见解是,类似设备的traffic应该包含类似的模式。在此基础上,我们把我们的问题当作自然语言处理问题。我们的目标是找到一些词的组合,这在NLP中被称为主题,这样的组合可以唯一地标记共同的图书馆、相同品牌和软件的共同表达。
我们建议使用一种生成性统计模型,即Latent Dirichlet分配(LDA)[11],它允许用未观察到的(话题)来解释观察结果。详细来说,我们把每个回应当作一个文档,把回复回应的物联网设备的类型当作它的主题。我们通过预先设定的分隔符将每个文件分成一系列的词。然后,我们计算语料库中每个词的统计分布,并将它们组织成n个类别。每个类别被进一步表述为主题,每个主题被表述为生成统计分布。
我们的实现是基于一个开源的实现[12]。我们生成的一个模型由开源的LDA可视化工具pyLDAvis[20]展示,如图4。这个模型包含了来自6个不同路由器供应商的HTTP流量,我们为它们总结了15个不同的主题。如图所示,LDA模型可以成功地将每个库和固件中的独特词汇聚集起来。图中右侧显示的是一个图书馆的例子。这个库提供了多种语言支持,LDA可以将这些语言特定的词作为一个主题来分组。同时,我们可以发现一些主题有一些共同的词,这意味着它们的traffic符合共同的HTTP语法。
我们的LDA模型的输出是一些主题,它是一系列单词和它的概念概率之间的映射关系。根据输出结果,我们可以对收集到的类似traffic进行合理的聚类,并提取topic到word的映射关系作为其IOT-ID。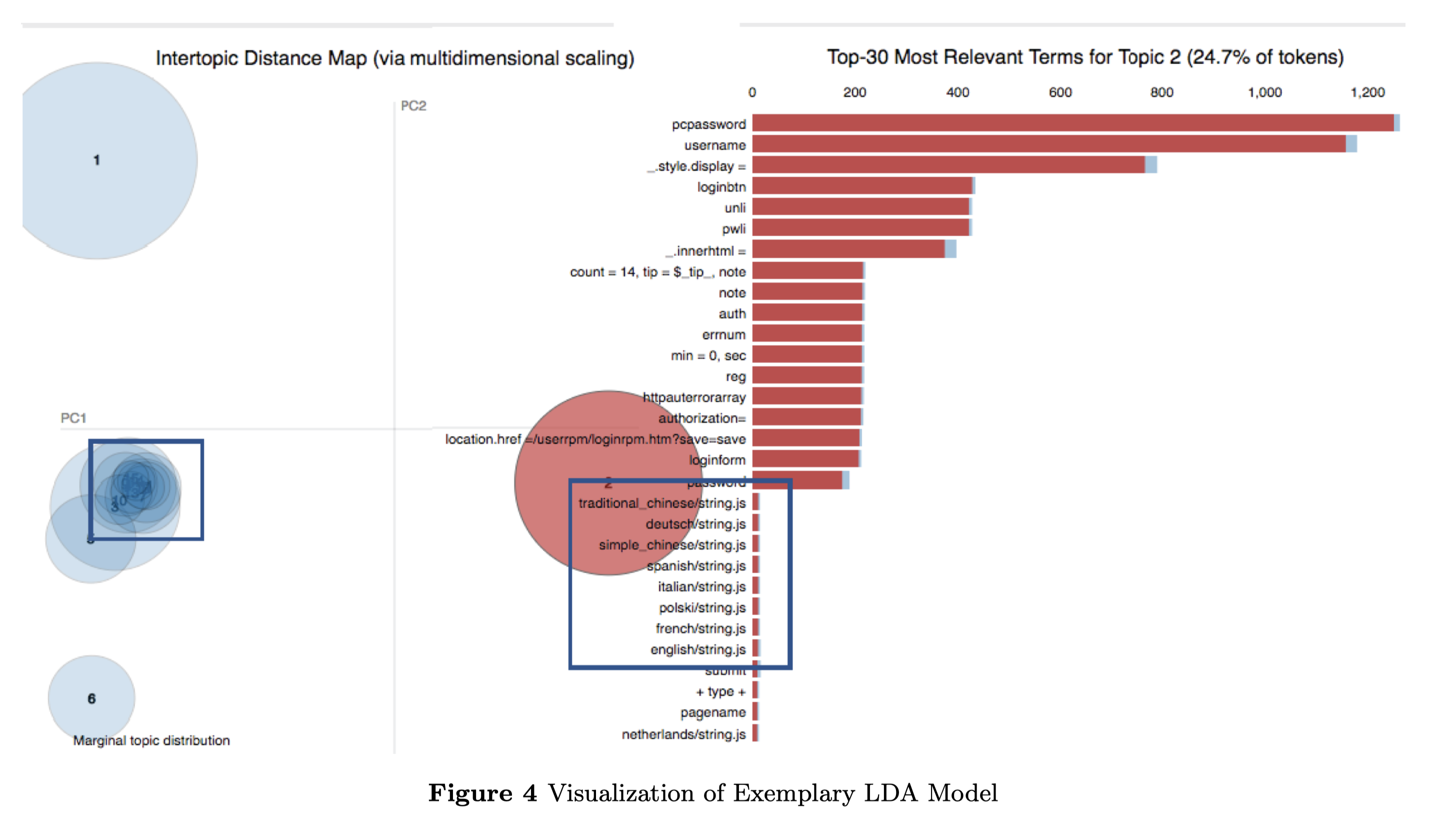
5. iotlearner:一个学习物联网行为的智能引擎。
在IoTScanner的帮助下,我们的蜜罐能够根据收到的请求向客户做出有效的回应,而不是回应一成不变的请求。在本节中,我们将讨论如何利用马尔科夫决策过程模型来优化响应选择,以最大限度地捕捉攻击。
5.1 IoTLearner概述。
对于每个单独的请求,IoTScanner模块可以从远程主机收集至少数百甚至数千个响应。所有这些都是有效的响应,但只有少数是正确的。这是因为,对于一个给定的请求,各种物联网设备可以根据它们自己的逻辑来处理它并产生响应。最直接的例子是访问其网络服务的根路径的请求:一些设备可能会回复登录门户页面,其他设备可能会将其重定向到另一个资源,其余设备可能会回应一个错误页面。因此,所有的扫描结果都有可能成为对客户的响应,但挑战在于如何找到攻击者所期望的那个。
我们的方法。我们的方法背后的想法是,首先从候选池中随机选择响应,并记录客户端的下一步行动。我们假设如果我们碰巧选择了正确的响应,攻击者会认为我们的蜜罐是脆弱的目标物联网设备,他们会继续发送恶意的有效载荷(如注入的命令)。因此,我们需要将每个交易存储在一个会话表中,并利用机器学习技术从数据集中提取正确的行为。
系统架构。IoTLeaner模块的架构如图5所示,从数据库中获取原始响应,并将每个交易记录到数据库中。每个传入蜜罐的请求都会被转发到该模块,并将选择的响应返回给客户端。该模块的核心部分是选择引擎,它将请求规范化,并从扫描结果中获取潜在的响应列表。在随机选择模式下,它只是从候选列表中随机挑选一个并返回。在MDP选择模式下,它首先从规范化的请求中找到图中的状态,然后通过模型选择最佳状态。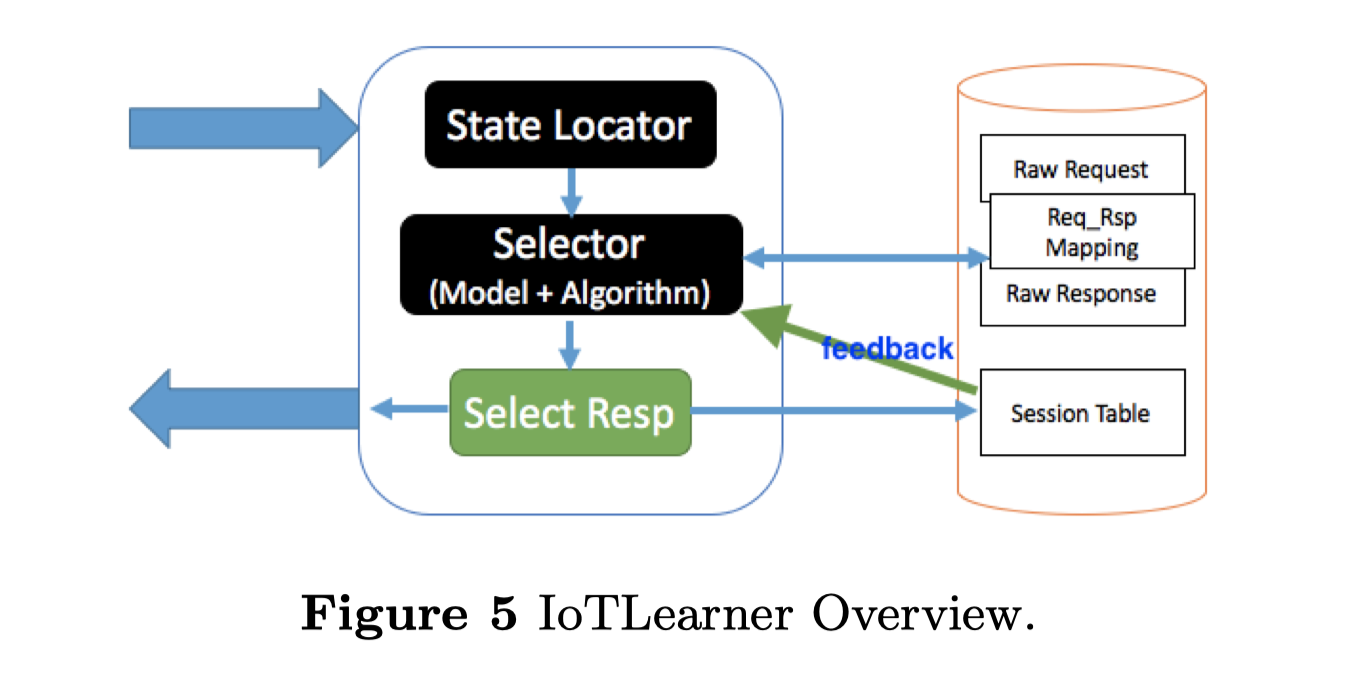
选择引擎做出的每个决定都将创建一个新的事务,以延长当前会话。所有的会话信息将被存储在会话表中。表中的每一行都代表一个事务,如元组
学习最佳响应的挑战。有许多因素使学习过程变得困难。首先,并非所有与我们的蜜罐对话的客户都是攻击者。这导致的问题是,并非所有的会话都对我们有恶意。只有那些能达到利用目的的才是对我们重要的。
5.2 模型的形成 妈的 看不懂
我们讨论了如何将响应选择问题表述为马尔科夫决策过程模型。我们假设客户是否继续会话或执行攻击,仅仅由前一个请求的响应决定。根据我们对现有恶意软件样本的最佳知识,这是一个合理的假设,我们已经分析过。因此,我们可以使用一个简单的数学模型来近似地描述会话活动的统计结构,该模型被称为order-1马尔科夫属性。
马尔可夫决策过程(MDP)。马尔科夫决策过程[19],也被称为随机控制问题,是标准(非隐藏)马尔科夫模型的一个扩展。MDP是当结果不确定时进行顺序决策的模型,例如计算一个行动的策略,使一些关于预期奖励的效用最大化。在该特定状态下可以执行一系列行动,这些行动的作用是使系统进入一个新的状态。在每个决策纪元,下一个状态将根据所选择的行动通过一个过渡概率函数来确定。它可以被视为一个马尔科夫链,其中状态的转换完全由过渡函数和上一步中采取的行动决定。行动的后果(即奖励)和策略的效果并不总是立即知道。因此,当当前状态空间的奖励不确定时,我们需要一些机制来控制和调整策略。这种机制被统称为强化学习。
问题的提出。在标准的强化学习模型中,代理人与环境进行互动。这种互动的形式是代理感知环境,并根据输入选择在环境中执行的行动。每个强化学习模型通过与动态环境的试错互动,学习从情况到行动的映射。
该模型由多个变量组成,包括决策历时(t)、状态(x,s)、转换概率(T)、奖励(r)、行动(a)、价值函数(V)、折扣(γ)和估计误差(e)。
强化学习任务的基本规则是贝尔曼方程[3],表示为: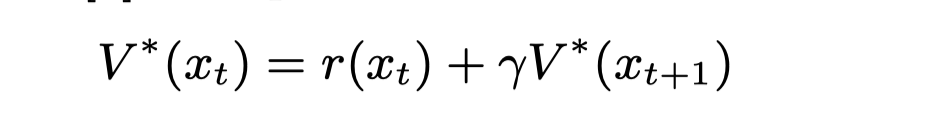
它可以解释为:最优策略的状态x t的值是指从状态x t开始并执行最优行动直到研究出终端状态时的强化值之和。贴现因子γ用于指数化地降低未来收到的增援的权重。从定义上看,RL的问题本质上是解决一个动态编程问题。因此,RL的标准解决方案是使用价值迭代,将价值V表示为一个查找表。然后,算法可以通过对状态空间进行扫描,通过更新策略更新每个状态的值,直到状态值没有变化(状态值已经收敛),从而找到最佳值函数V∗。一般的更新策略可以表示为:。
然而,要在我们的问题中应用RL,有一个限制。我们的问题本质上是一个非确定性的马尔科夫决策过程,这意味着在每个状态下,存在一个过渡概率函数T来决定下一个状态。换句话说,我们的学习策略是一种概率上的权衡,即探索,用以前没有用过的回答来回答,和用已知的高回报的回答来开发。应用一般的估值迭代不可能在不增加知识或不修改决策的情况下计算出必要的积分。因此,我们应用Q-learning[21]来解决必须对一组积分取最大值的问题。
Q-learning不是寻找从状态到状态值的映射,而是寻找从状态/动作对到值(称为Q值)的映射[10]。Q-learning没有相关的价值函数,而是利用了Q-函数。在每个状态下,都有与每个行动相关的Q值。Q值的定义是执行相关行动并在此后遵循给定政策时收到的再赋值之和。同样地,最佳Q值的定义是在执行相关行动时收到的强化物的总和,然后再遵循最佳政策。
因此,在我们使用Q-learning的问题中,贝尔曼方程的等价物被形式化为:
奖赏函数。奖励函数r : (x , a ) → r为处于状态和行动对(x, a)分配一些价值r。奖励的目标是确定每一对的偏好,并使最终的奖励最大化(最优政策)。
在我们的背景下,即时奖励r(x, a)反映了我们在互动过程中所取得的进展,当我们选择响应a t来请求x t时,我们将进入下一个状态x。由于进度可以是负的,也可以是正的,所以奖励函数也可以是负的或正的。定义奖励的启发式方法是,如果响应a是攻击者所期望的目标设备类型,并且攻击者在下一个请求中发送漏洞代码来发动攻击,那么奖励必须是正的和巨大的。相反,如果响应不是预期的(例如,反映了一个不脆弱的设备版本),攻击者可以停止攻击并结束会话。这导致了死胡同状态,并导致了负奖励。换句话说,我们奖励那些能让我们找到最终攻击数据包的回应,而惩罚那些导致死循环的回应。
我们的设计之一是将奖励作为一个等于最终会话长度的值,因为我们相信攻击者发送的请求越长,包含恶意有效载荷的机会就越大。标准会话是2,这意味着在我们发送我们的响应后,至少有另一个来自同一IP的相同端口的传入请求。如果没有观察到进一步的过渡,我们为该响应分配一个负的奖励。其他的奖励分配可以基于我们是否收到一些已知的漏洞数据包。
5.3 MDP模型的建立
我们解释如何启动模型所需的参数,以便从我们现有的结果进行计算。
状态和行动。在没有任何协议语义概念的情况下建立马尔科夫模型的状态可能会导致缺乏通用性和稀疏的状态空间。因此,它不能够处理任何尚未见过的东西。解决办法是通过将相似的状态归为一个单一的状态来简化和概括状态。在我们的案例中,我们想把类似的请求和类似的响应归入同一个组。由于物联网设备使用了大量的通信协议,我们必须以独立于协议的方式进行。以前的研究[7, 13, 14]已经研究了如何在不了解协议的情况下简化HTTP、SDP、NSS、NTS等的状态。详细的实现可以在这些论文中找到。总的来说,他们都依赖于对齐算法来识别多个字符串的相似部分,作为协议的结构。
状态转换概率。状态转换概率可以用转换函数T(s, a, s ′ )来描述,其中a是在当前状态s期间可执行的动作,s ′是某个新状态。更正式地说,函数过渡函数T(s, a, s ′ )可以用公式描述。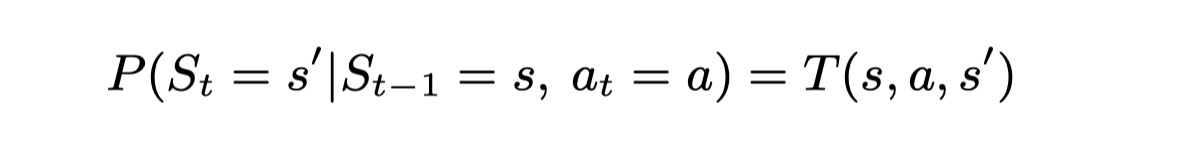
其中a是在当前状态s下可执行的动作,而s′是一些新的状态。在我们的语境中,过渡函数T(s, a, s ′)是指如果我们将响应a作为当前请求s的回复回复给客户端,那么在同一会话中收到请求s ′的概率。为了测量每个组合(s, a, s ′)的概率,我们部署了一个天真的算法,从候选集合中随机返回一个响应,并将会话信息保存到会话表中。在运行一段时间后,我们能够收集到很多会话,我们对每个会话进行解析,计算每个组合(s, a, s ′)的出现次数,表示为C(s, a, s ′)。过渡函数T(s, a, s ′)的值被定义如下。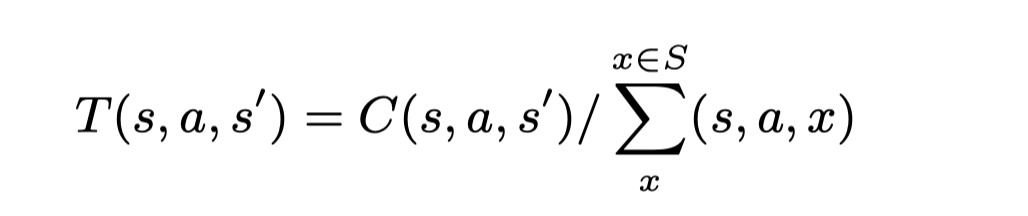
响应选择的在线Q-learning算法。基于Q-learning模型,我们的学习过程从在t 0决策纪元收到一个请求开始。鉴于该请求,我们应用我们的匹配算法来选择一组相同的响应。我们采用-贪婪[23]政策进行行动选择。特别是,我们为每个可用的响应分配统一的概率作为初始交易函数。使用这个政策,我们可以选择具有概率的随机行动,也可以选择具有1-概率的行动,在给定的状态下给予最大的奖励。
然后我们开始我们的Q-learning迭代并更新我们的Q-learning表。当我们对一个状态和行动对进行强化学习时,r(x t , a),我们首先进行反向传播并更新Q查找表。据此,我们可以通过删除以负奖励结束的反应并更新数值来做调整。迭代结束,直到模型收敛。
在实践中,我们的模型是在线运行并实时更新的。因此,它可能不会收敛并达到全局最优。然而,我们认为这个模型仍然是有价值的,因为它只允许我们抛弃这些不受欢迎的反应,但也尽可能地保持会话的进行。
5.4 物联网蜜罐的MDP。
我们将使用现实世界的例子来解释我们如何建立MDP并计算每个反应的概率。出于演示的目的,我们简化了图中的状态和行动的数量,并将模型表示为一个状态空间图。在图中,每个矩形(黑色)代表一个单一的状态,每个圆圈(橙色)代表在特定状态下可以采取的行动。图中的箭头指的是采取某种行动后从一个状态到下一个状态的转换。在我们的环境中,每个状态都是一个独特的请求抽象,而请求的每个动作都是唯一的候选响应。
从HNAP协议的会话表建立MDP。HNAP协议相当简单,特别是对于攻击场景。例如,在攻击我们的蜜罐之前,攻击者通常向网址/HNAP1/发送请求,以获得SOAP响应(一个XML格式的文档,包含所产生的数据),其中包含主机的信息和其支持的SOAP动作。有些设备不支持HNAP协议,如SonicWall防火墙会返回404 Not Found页面,TRENDnet路由器会返回401 Unauthorized页面。其他设备可能会回复有效的SOAP响应,但响应中却有不同的信息,例如LinkSys路由器的响应中的型号名称是WRT110,而D-Link路由器的响应中的型号名称是DIR-615。由于我们没有任何关于HNAP协议和预期行为的知识,我们可以尝试在第一阶段向攻击者发送他们中的每一个,并记录会话信息。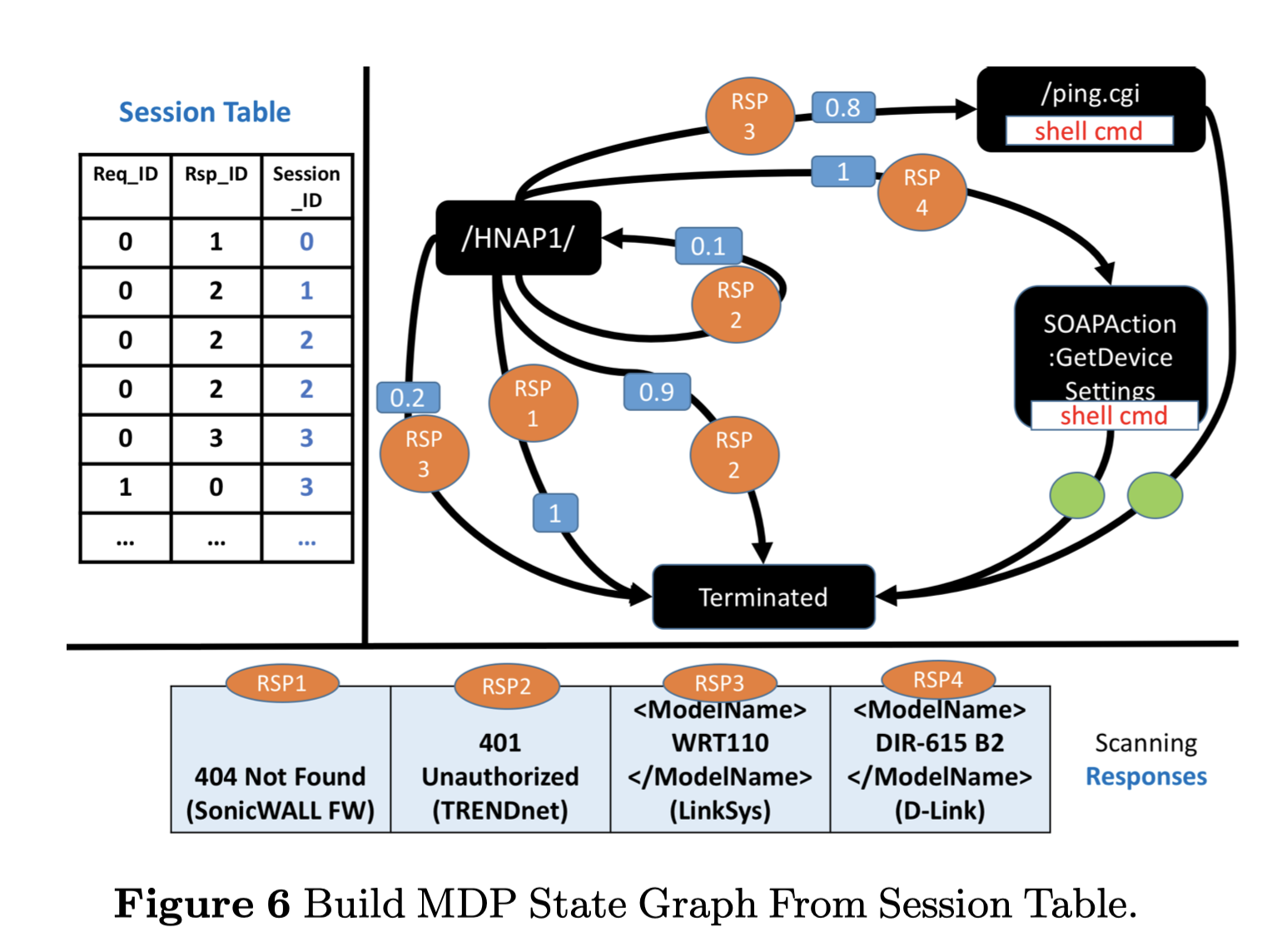
CGI-Script MDP图。由我们捕获的完整的会话数据建立的图更加复杂。我们选择对CGi脚本的URL的请求并生成它们的图。CGI脚本被许多类型的物联网设备所使用,包括摄像头、路由器等。对CGI脚本已经进行了大量的初步检查和漏洞。如图7所示,诸如get_status. cgi check-user. cgi和get_camera-params cgi等URLS经常被攻击者扫描。由于它们可以在没有任何权限的情况下被访问,攻击者倾向于从它们那里收集设备信息。在几个请求之后,会话进入有权限的CGI 脚本和易受攻击的脚本.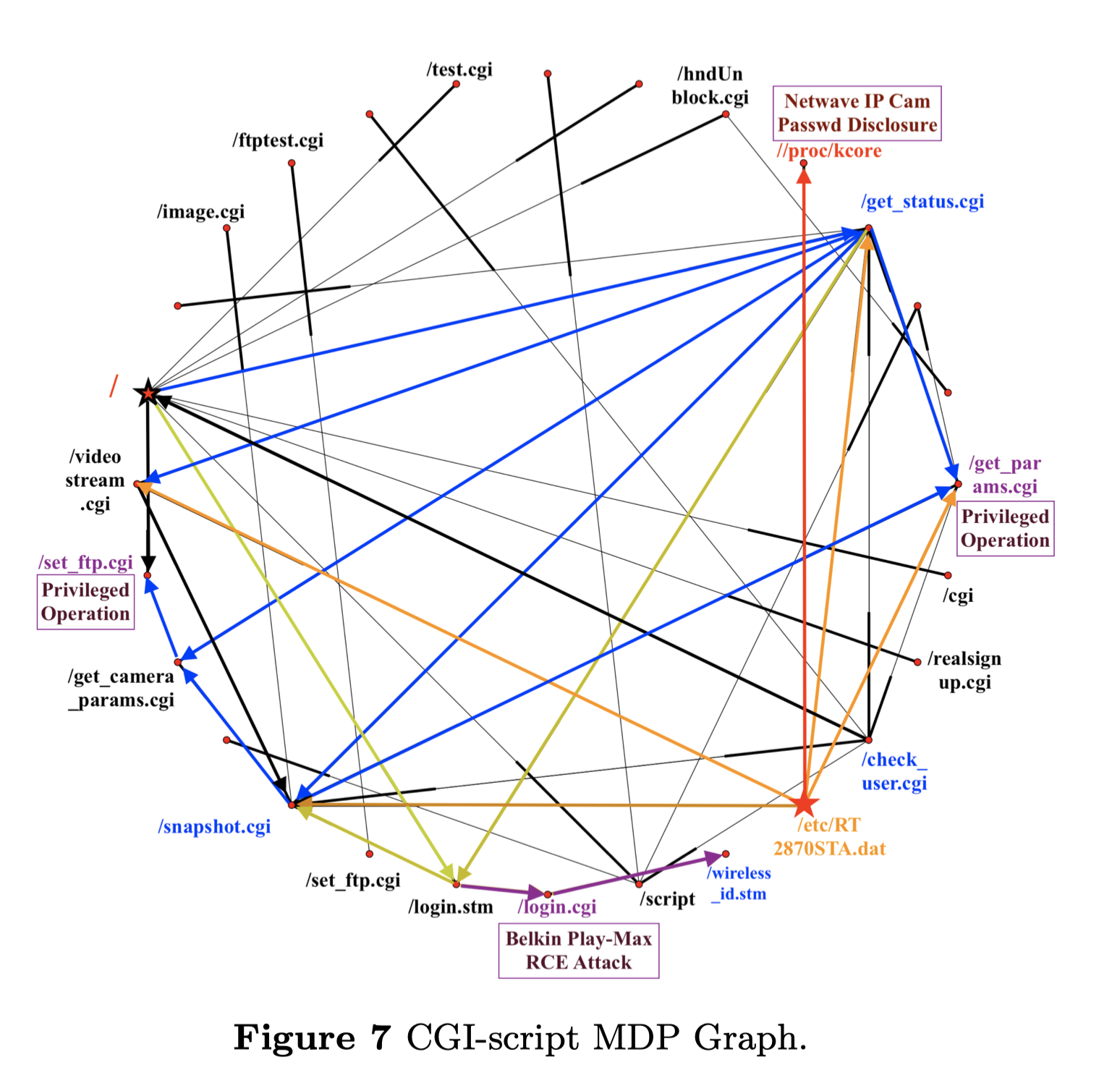
6. 评估
在这一节中,我们评估了我们的智能互动蜜罐的有效性,并分享了一些从捕获的请求中得出的有趣结论。我们在Digital Ocean的5个虚拟机上部署了它。由于预算问题,我们只选择了最小的一个,其配置为。512MB内存,1个CPU,20G SSD磁盘,以及标准网络带宽。在准备过程中,我们利用低交互性蜜罐捕获的100万个请求作为种子来扫描互联网,并使用我们上面解释的扫描器收集数百万个响应。
在我们的设置中,我们从扫描结果中选择30k个独特的响应,并下载一个副本到每个蜜罐实例。 响应和相应的种子请求之间的映射也被下载。在最初的两周,我们将蜜罐设置为随机回复模式,以便收集客户的反应。通过随机选择机制,我们成功地收到了更多来自客户端的请求。然而,如图8所示,大多数会话仍然很短。考虑到我们可以从扫描器中得到几百甚至上千个对单个请求的独特响应,这个结果是合理的。
每个蜜罐实例包含我们选择的30万个响应以及它与某些请求的映射。其中2个蜜罐实例使用随机选择算法,该算法将从使用当前收到的请求收集的池中随机选择一个响应;其余的蜜罐实例部署了MDP算法,正如我们在前面解释的那样。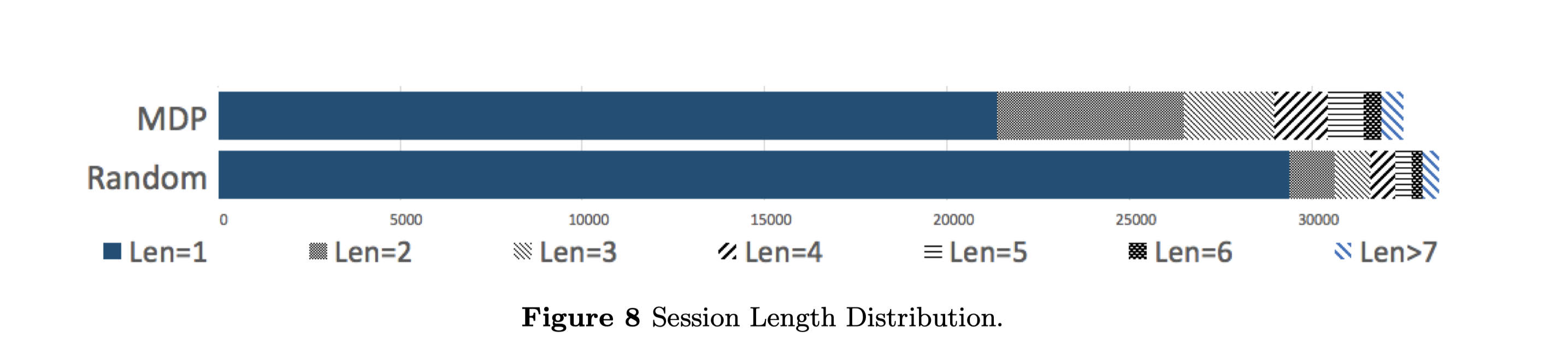
6.2 捕获的攻击前检查和利用。
利用智能交互蜜罐,我们从攻击者那里捕捉到了更多精心制作的恶意请求。利用会话信息,我们还从MDP状态图中找出了50个不同类型的物联网设备(如IPCam、Router、Projector)协议中的攻击前检查。我们在这一部分中强调了几个案例。
6.2.1 在HTTP协议中
HTTP协议被物联网设备广泛用于管理。设备信息可以直接或间接地从所有类型的HTTP响应中泄露出来。我们根据响应的状态代码来讨论我们的观察。
200 OK。这是成功的HTTP请求的最标准响应。几个版本的Netgear路由器在对/currentsetting.htm的请求的响应中容易泄露型号版本、firmware和其他信息。如果攻击者不能解析或从响应内容中获得有效的令牌,他们就不会执行攻击行动。对于Netwave IP摄像机,我们观察到在URL get status.cgi、/etc/RT2870STA.dat和login.stm上有相当多的请求。访问这些页面不需要认证,这些页面显示了固件版本(ui和系统)、时间戳、序列号、p2p端口号或wifi SSID。
401 未授权。HTTP状态代码401未授权,意味着由于认证方法不正确或根本没有认证,资源不能被加载。看起来,401响应几乎不包含任何其他有意义的信息。然而,它仍然可能包含帮助客户执行下一步行动的信息(例如,重新认证、重定向)。
例如,响应头中的WWW-Authenticate field是用来描述认证模式的[8]。通常情况下,该响应一般从网络服务器返回给物联网设备,而不是从网络应用1。具有相同品牌的所有类型的物联网设备共享相同的机制。因此,攻击者可以利用这个字段的值来确定当前物联网设备是否有漏洞,尤其是Netgear调制解调器或路由器。我们的蜜罐观察到NETGEAR R7000和NETGEAR R6400的检查模式,在这个特定的路由器版本上发起远程代码注入攻击(CVE-2016-6277)。
有时,401-unauthorized响应的内容也可能泄露敏感信息。例如,netgear无线路由器(N150 WNR1000v3)在基本登录尝试中请求失败时,包含凭证(token),如下所示:
HTTP/1.0 401 Unauthorized WWW-Authenticate: Basic realm="NETGEAR WNR1000v3"<html><head><title>401 Unauthorized</title></head>...<form method="post" action="unauth.cgi?id=2143918018"name="aForm"></form></body></html>
403 Forbidden响应与网络应用程序的逻辑相联系。我们发现,攻击者需要成功找到模式并从中提取令牌,然后再制作恶意的有效载荷来进一步利用路由器。
404未找到。当请求的资源无法找到时,服务器将返回404-not-found响应。404页面也可以被攻击者用来识别物联网设备。例如,我们已经观察到对ZyXEL的调制解调器Eir D1000的攻击。攻击者向URL /globe发送合法请求,并期望得到一个404-not-found页面,其中有模式home wan.htm。这个特殊的404页面告诉攻击者,该主机支持基于SOAP的协议TR-069,他们可以通过在请求的’NewNTPServer’字段中嵌入命令来注入它。
6.2.2 在定制的协议中
除了HTTP协议,初步检查还发生在物联网协议,甚至是定制协议。家庭网络管理协议(HNAP)就是其中一个例子。这个基于SOAP的协议由思科在2007年首次发明,用于网络设备管理,它允许网络设备(如路由器、NAS设备、网络摄像机等)被静默管理。由于它的实施历史悠久,已经发现了很多攻击,例如利用GetDeviceInfo动作绕过认证,并向SOAPAction字段注入shell命令以发起RCE攻击。正如我们在第5节中所讨论的,攻击者通常会检查对URL /HNAP1/的响应,以获得设备支持的服务列表。另一个例子是Netcore和Netis路由器使用的定制协议,它打开一个UDP端口53413作为远程配置的后门。攻击者发送一个带有8个字节的值”\ x00 “的有效载荷,并期待其中有”\ xD0\ xA5Login: “这样的模式,以确认设备是脆弱的。
6.2.3 使用Echo命令。
远程命令执行是物联网设备上常见的攻击之一,有些漏洞允许攻击者查看命令的输出。例如,最近发现的路由器NETGEAR DGN2200的所有firmware版本(v1-v4)的漏洞,不需要管理员权限就可以在路由器上执行shell命令。漏洞的脚本是ping.cgi,它是为用户提交诊断信息给路由器而设计的。然而,由于实施的缺陷,如果攻击者向这个网址发送POST http请求,并将命令作为有效载荷中的参数ping IPAddr的值,他们就能够在无人许可的情况下执行该命令。返回的页面包含注入的命令的结果。
我们已经捕获了试图利用这一漏洞的恶意请求,但命令非常简单,如echo命令。我们观察到,大多数的恶意会话都是在有echo命令的请求中被终止的。这是因为攻击者通常在echo命令后生成一个随机字符串,如果命令被执行,响应内容应该包含完全相同的字符串。然而,由于随机字符串在每个请求中都有变化,因此扫描结果中的字符串极有可能与当前收到的请求相匹配.
POST /ping.cgi HTTP/1.1 referer:http://x.x.x.x/DIAG_diag.htm
IPAddr1=1&IPAddr2=2&IPAddr3=3&IPAddr4=4&ping=Ping&ping_ IPAddr=12.12.12.12; echo "zP8ZDXwQCC";
正如上面的请求例子所示,攻击者在发送真正的漏洞壳代码之前,检查随机字符串zP8ZDXwQCC是否在响应中。我们通过将echo命令中的字符串插入到响应页面的正确位置来处理这种类型的检查。
- 结语
由于物联网的特殊性,使用传统的方法为物联网设备建立蜜罐是具有挑战性的。然而,对物联网设备的攻击在发起攻击前会对设备信息进行初步检查。如果没有适当的与攻击者的互动机制,就很难捕捉到完整的攻击有效载荷。我们提出了一种自动和智能的方式,使用扫描仪收集潜在的反应,并利用机器学习技术来学习与攻击者互动过程中的正确行为。我们的评估表明,我们的系统可以改善与攻击者的会话,捕获更多的攻击。

若有收获,就点个赞吧
0 人点赞
