环境
- 浏览器想要运行JS代码,一个是【执行者】(cpu分配线程来执行),另一个是执行所需的【空间】。
- 执行者:cpu分配一个主线程来自上而下的执行栈中的JS代码。
- 空间:从电脑的内存当中分配一块内存给程序,用来执行代码(称为【当前】程序的栈内存=>Stack)
栈内存
栈内存是用来执行代码和存储基本类型值的(创建的变量也存栈里面了)
- 不仅全局代码执行(EC(G)全局执行上下文),
- 而且函数执行(EC(X)私有上下文),最后也都会进栈执行的
- 基于ES6中的let/const形成的块作用域也是栈内存
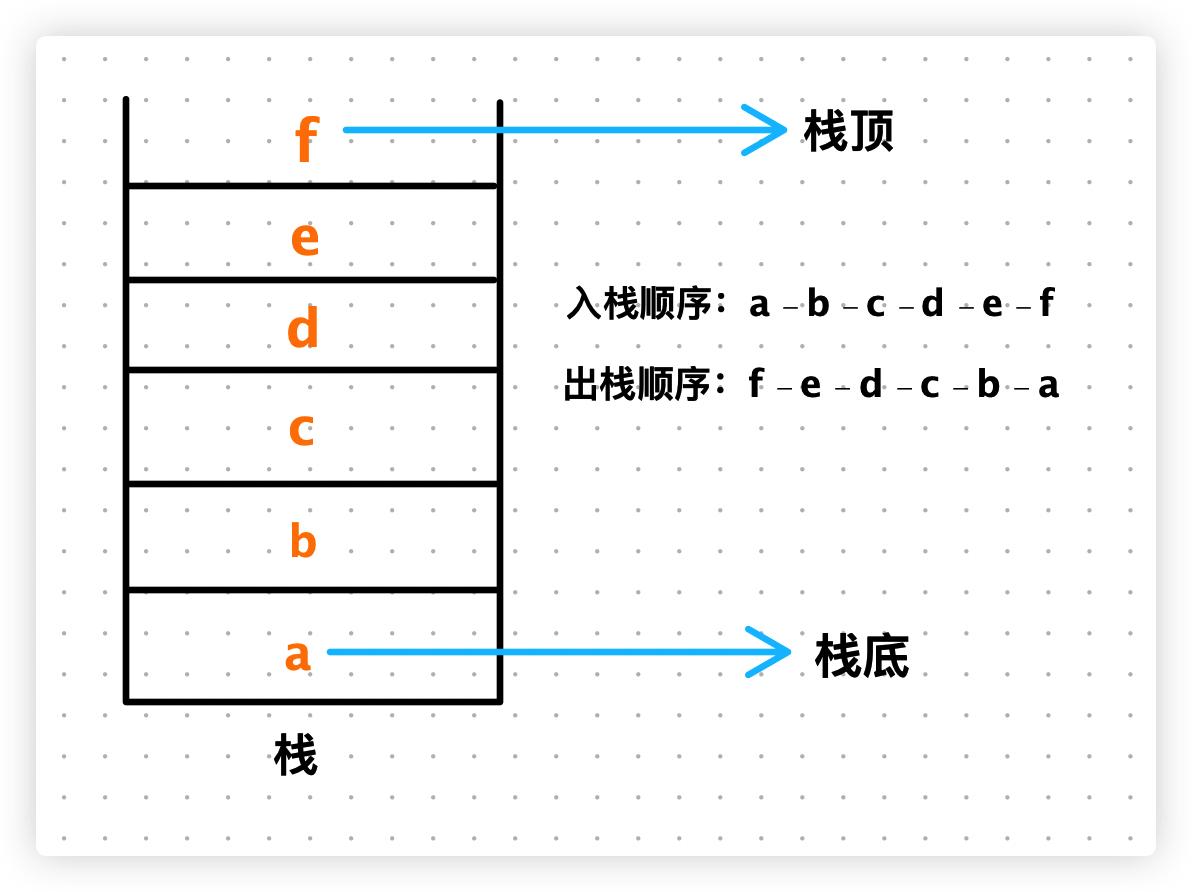
- 栈的特点:
- 后进先出,最后添加进栈的元素最先出。
- 访问栈底元素,必须拿掉它上面的元素。
栈内存中语句的执行
- 线程在栈内存当中自上而下执行语句,而语句进入栈内存执行称为【进栈执行】,当前语句进栈执行完毕之后必须要【出栈】下一条语句才能继续的进栈执行。
堆内存Heap
我们所说的 堆 数据结构指的是 二叉堆
- 堆内存是用来存储引用数据类型值的
- (例如:创建函数和创建对象,就是开辟一个堆内存,把代码字符串或者键值对存储到堆内存中的)
基本数据类型的声明和定义过程
- 首先声明一个变量,将这个【变量】存储到【当前栈内存】的【变量存储区】当中
- 创建一个值,将这个【值】存储到【当前栈内存】的【值存储区】当中
- 注意:只有简单的基本数据类型是这样存储的,【复杂的引用数据类型的【值】】不是这样存储的。
- ‘=’ 赋值符号赋值的过程称为【定义】,实际上就是让【变量和值相关联的过程】。
let a = 12;//声明一个变量a//创建一个值12//定义a为12(定义就是为变量赋值的过程)
引用数据类型的声明和定义过程
- 首先声明一个变量,将这个【变量】存储到【当前栈内存】的【变量存储区】当中
- 除了【当前栈内存】,内存会新分配一块内存(分配出的内存都会有一个十六进制的地址),称为【堆内存Heap】用来存储【引用数据类型】的【值】
- 把对象当中的键值对(属性名:属性值)依次存储到【为此对象分配的堆内存】中,并将【该堆内存的地址】存储到【当前栈内存的值存储区】当中
- 在当前栈内存当中,把【值存储区】中的【堆内存地址】赋值给【变量】,使之相关联。
注意:一旦创建新的引用类型的【值】(如a={n:1}、b=[10,20]…),都是要创建新的堆内存!!!!!【结合后面练习题理解一下】
区别
- 基本数据类型:按值操作(直接操作的是值),所以也叫【值类型】
- 引用数据类型:按引用地址操作(直接操作的是地址),操作的是堆内存的地址,所以叫【引用类型】
变量和属性名的区别
- 一个对象的属性名只有两种格式:【字符串和数字】(等基本类型,但其他的基本不用)
- 获取一个对象的某个属性值可以用:
- 对象.字符串属性名 【.点只支持字符串属性名】
- 对象[‘字符串属性名’]
- 对象[字符串]:此时的字符串是作为一个变量存在,代表其存储的值\color{red}{对象[字符串]: 此时的字符串是作为一个变量存在,代表其存储的值}对象[字符串]:此时的字符串是作为一个变量存在,代表其存储的值
- {属性名} 【在ES6中,如果属性名和属性值一样,如obj{name:name,age:12}(后面这个是变量),则可以简写成obj{name,age:12}】
- 对象[数字属性名]
- 对象[‘数字属性名’]
- ==对象[数字索引] :仅数组可用=
- ‘字符串’ 值->代表属性值本身
- 字符串 对象->代表该字符串变量所存储的值
//定义一个变量name,值为10var name = 10,gender = '性别';//定义一个对象objvar obj = {name:'zhangsan',性别:'male'};//读取obj对象的属性值console.log(obj.name);//=>'zhangsan'console.log(obj['name']);//=>'zhangsan'//读取obj对象的属性值,obj[name]代表着要读取【name变量的值】作为【obj对象的属性名】所对应的【属性值】console.log(obj[name]);//此时的name是作为一个变量存在,代表其存储的值=>obj[10]=>undefinedconsole.log(obj[gender]);//=>obj['性别']=>'male'
深拷贝与浅拷贝
引用数据类型在复制时,改了其中一个数据的值,另一个数据的值也会跟着改变,这种拷贝方式我们称为浅拷贝。
在实际开发中,我们希望引用类型复制到新的变量后,二者是独立的,不会因为一个的改变而影响到另一个。这种拷贝方式就称为深拷贝。
深拷贝,实际上就是重新在堆内存中开辟一块新的空间,把原对象的数据拷贝到这个新地址空间里来,通常来说,我们有两种方法:
- 转一遍JSON再转回来 ,但是这个办法有一个问题,这只能转化一般常见数据,function,undefined等类型都无法通过这种变回来
- 手动去写循环遍历
我们来看下第一种方法,代码如下所示:
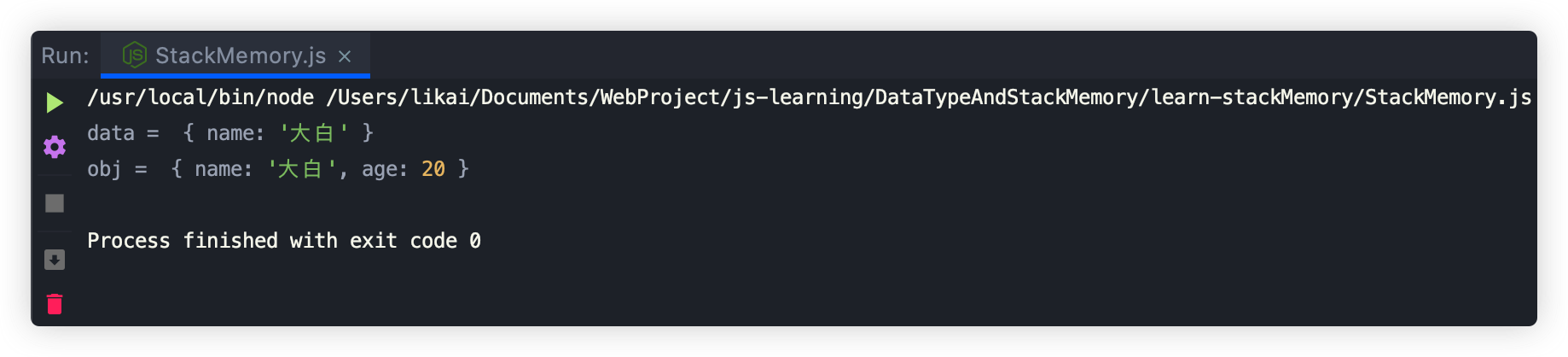
const data = { name: "大白" };const obj = JSON.parse(JSON.stringify(data));obj.age = 20;console.log("data = ", data);console.log("obj = ", obj);
运行结果如下:
最后,我们来看下第二种写法,代码如下所示:
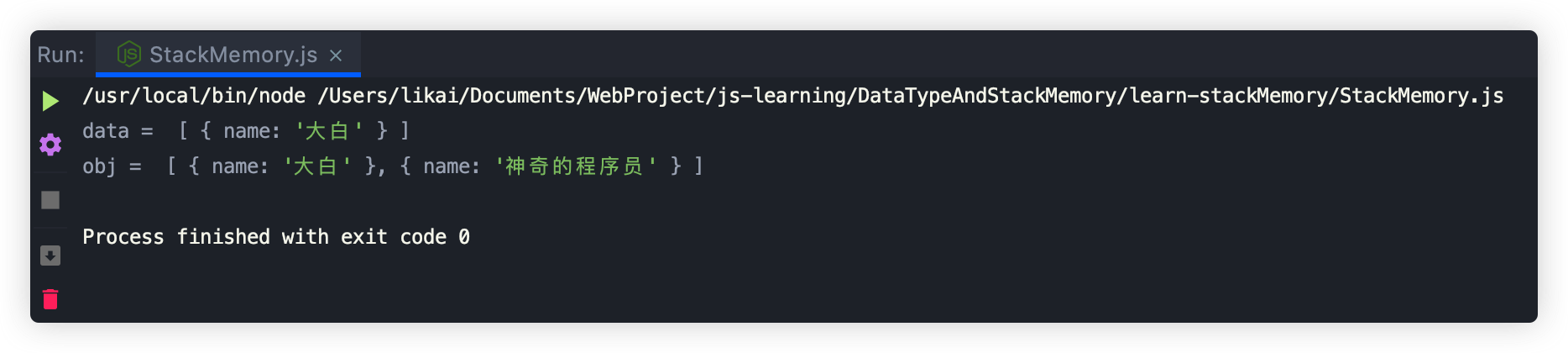
const data = [{ name: "大白" }];let obj = data.map(item => item);obj.push({ name: "神奇的程序员" });console.log("data = ", data);console.log("obj = ", obj);
运行结果如下:
练习
let n = [10,20];//创建变量n,创建堆内存1,相关联//此时堆内存1[10,20]let m = n;//创建变量m,与堆内存1相关联let x = m;//创建变量x,与堆内存1相关联m[0] = 100;//修改变量m对应的堆内存1中的第一个元素//此时堆内存1[100,20]x = [30,40];//创建新的堆内存2,并与变量x相关联//此时堆内存1[100,20]//此时堆内存2[30,40]x[0] = 200;//修改变量x对应的堆内存2中的第一个元素//此时堆内存2[200,40]m = x;//将变量x对应的堆内存2的地址与m相关联m[1] = 300;//修改m对应的堆内存2的元素2//此时堆内存2[200,300]n[2] = 400;//修改变量n对应的堆内存1,添加新元素3//此时堆内存1[100,20,400]//此时堆内存2[200,300]console.log(n,m,x);//[100,20,400]//[200,300]//[200,300]

面试题
- 原题
let a = {n:1};let b = a;a.x = a = {n:2};console.log(a.x);console.log(b);复制代码
- 解析
- 如let a = b = 12 ;
- 从右向左
- 创建一个值12
- b = 12
- let a = 12
- 运算符优先级
- a.x = a = {};
- 因为成员访问(a.x)的优先级高于赋值运算符 ,运算时会先执行a.x
- 如let a = b = 12 ;
let a = {n:1};//创建变量a,创建堆内存1(地址为0X1)//此时堆内存1中{n:1}let b = a;//创建变量b,与堆内存1相关联a.x = a = {n:2};//【像此类连等的,就是先左边与最右边关联,再往右与最右边关联】//1.创建堆内存2,当中存储{n:2}(地址为0X2)//2.在a相关联的堆内存1中,存储新的元素x,属性值为堆内存2的地址//3.将a与堆内存2相关联//此时,a与堆内存2关联,b与堆内存1相关联//堆内存1中{n:1,x:0X2}//堆内存2中{n:2}console.log(a.x);//输出堆内存2中的属性名为x的属性值//【堆内存2中没有x的属性值】=>输出undefinedconsole.log(b);//输出堆内存1中的元素{n:1,{n:2}}console.log(b.x.n);//输出2console.log(b.n);//输出1复制代码
- 关键点
- a.x = a = {n:2};
- 【像此类连等的,就是先左边与最右边关联,再往右与最右边关联】
- 创建堆内存2,当中存储{n:2}(地址为0X2)
- 在a相关联的堆内存1中,存储新的元素x,属性值为堆内存2的地址
- 将a与堆内存2相关联
练习题2(是错误用法,形成了堆的嵌套,导致内存无限溢出)
原题
let a = {n:1};let b = a;a.x = b;
解析
let a = {n:1};//创建变量a,创建堆内存1(地址为0X1)//此时堆内存1中{n:1}let b = a;//创建变量b,与堆内存1相关联a.x = b;//将b所关联的堆内存1的地址,作为属性名x的属性值,存储到堆内存1中。//每一个x中存的都是该堆内存的地址//结果{n:1,x:{{n:1,x:{{n:1,x:{{n:1,x:{{n:1,x:{......}}}}}}}}}}
关于对象数据类型中【属性名类型】的深入
- 在对象数据类型当中,存在着零到多组的键值对(属性名和属性值)
- 而关于属性名的类型有两种说法:
- 【说法一:属性名类型只能是字符串或者Symbol】
- 【说法二:属性名类型可以是任何 基本类型值 ,处理中可以和字符串互通】
- 注意: 但 【属性名绝对不能是引用数据类型,如果设置为引用数据类型,最后也是把对象转换为字符串作为属性名来处理的’[object object]’】
- 在forin循环中
- for in遍历中获取到的属性名,typeof读取其类型都会变为字符串
- 且Symbol类型的属性名将无法被(迭代)获取到
- 关于obj[x]和obj[‘x’]的区别:【变量和属性名的区别】
- 首先属性名肯定得是一个值
- obj[x]:相当于把x变量储存的值作为属性名,来获取对象中该属性名对应的属性值
- obj[‘x’](obj.x):如果加上‘’引号,则意为获取属性名为x的属性值=>100
let sy = Symbol('AA');let x = {0:0};let obj = {0:12,true:'xxx',null:20,sy1:100,[sy]:'zhangsan',[x]:10};console.log(obj["Symbol('AA')"]);//=>undefined//直接用字符串来获取获取不到,只能通过sy(代表Symbol('AA'))console.log(obj[sy]); //=> 'zhangsan';//=>Symbol('AA'):'zhangsan'//【相当于把sy变量储存的值作为属性名,来获取对象中该属性名对应的属性值】console.log(obj[x]); //=>obj['[object object]']=> 10;//引用类型值作为属性名,最后也是把对象转换为字符串作为属性名来处理的'[object object]'console.log(obj['sy1']); //=> 100//如果加上‘’引号,则意为获取属性名为x的属性值=>100//////注意,如果设置为引用数据类型,最后也是把对象转换为字符串作为属性名来处理的'[object object]'//↓obj[x] = 100;//相当于obj['[object object]']=100//得到结果是将属性[object object]的值设置为:100//////for(let key in obj){//for in遍历中获取到的属性名,读取其类型都会变为字符串//且Symbol类型的属性名将无法被(迭代)获取到console.log(key,typeof key)}/* 0 stringtrue stringnull stringsy1 string[object Object] string*/
三个例子:
- 用变量作为属性名
var a = {},b = '0',c = 0;///* 因为都是用变量存储的值作为属性名,所以两个0都指同一个属性值 *///a[b] = 'zhang';//a['0'] = 'zhang'//指属性名为‘0’的属性值a[c] = 'san';//a[0] = 'san'//指属性名为‘0’的属性值console.log(a[b]);//=>'sanconsole.log(a);//=>{0: "san"}
- 用两个唯一值做属性名
var a = {},b = Symbol('1'),c = Symbol('1');//两个唯一值不同,所以是两个不同的属性名a[b] = 'zhang';a[c] = 'san';console.log(a[b]);//=>'zhang'console.log(a);//=>{Symbol(1): "zhang", Symbol(1): "san"}
- 用引用数据类型做属性名
var a = {},b = {n:'1'},c = {m:'2'};//设置为引用数据类型,最后也是把对象转换为字符串作为属性名来处理的'[object object]'a[b] = 'zhang';//a['[object object]']='zhang'a[c] = 'san';//a['[object object]']='san'console.log(a[b]);//=>'san'console.log(a);//=>{[object Object]: "san"}

若有收获,就点个赞吧
0 人点赞
