Spring Cloud Sleuth简介
Spring Cloud Sleuth为微服务之间调用提供了一套完整的服务链路跟踪解决方案。通过Sleuth可以很请求地了解一个用户请求经过了哪些微服务,每个微服务处理花费了多长时间,从而让开发者可以方便地理清各微服务间的调用关系。
- 耗时分析:通过Sleuth可以很方便地了解到每个采样请求的耗时,从而分析出哪些微服务调用比较耗时。
- 可视化错误:对于程序未捕捉的异常,可以在继承Zipkin服务界面上看到。
- 链路优化:通过Sleuth可以请求识别出调用比较频繁的微服务,可以针对这些微服务实施相应的优化措施。
Sleuth的实现原理:
- 服务追踪:对于同一个用户请求,认为是同一条链路,并赋值一个相同的TraceID,在后续中通过该表示就可以在多个微服务之间找到完整的处理链路。
- 服务监控:对于链路上的每一个微服务处理,Sleuth会再生成一个独立的SpanID,同时记录请求到达时间和离开时间等信息,以作为用户请求追中的依据,从而判断每一个微服务的处理效率。
Sleuth主要术语:
- Span:是Sleuth中最基本的工作单元。微服务发起一个请求就是一个新Span。Span使用唯一的、长度为64位的ID作为标识。在Span中可以带有其他数据,如描述、时间戳、键值对、起始Span的ID等数据。Span都是成对出现。
- Trace:一次用户请求所涉及的所有Span的集合,采用树形结构进行管理。
- Annotation:用于记录时间信息。
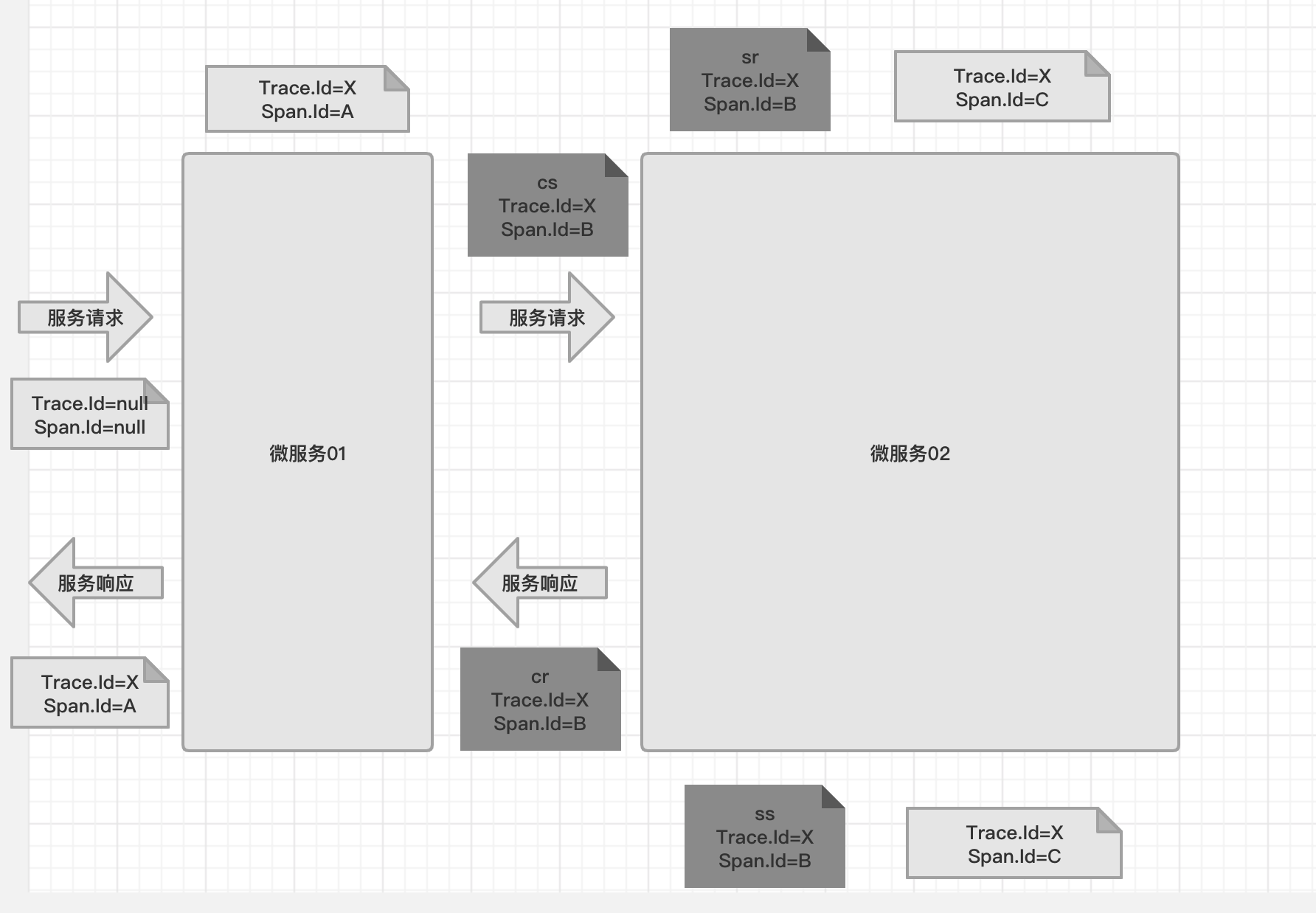
- cs:客户端发送,表示一个Span的起始点。
- sr:服务端接受,表示服务端接受到请求并开始处理。减去cs的时间戳,可以计算出网络传输耗时。
- ss:服务端完成请求处理,应答信息被发回客户端。减去sr的时间戳,能计算出服务端处理请求的耗时。
- cr:客户端接受,标志着一个Span生命周期的结束,客户端成功地接收到服务端的应答信息,如果减去cs的时间戳,则可以计算出整个请求的响应耗时。
1、快速启动Sleuth
修改配置文件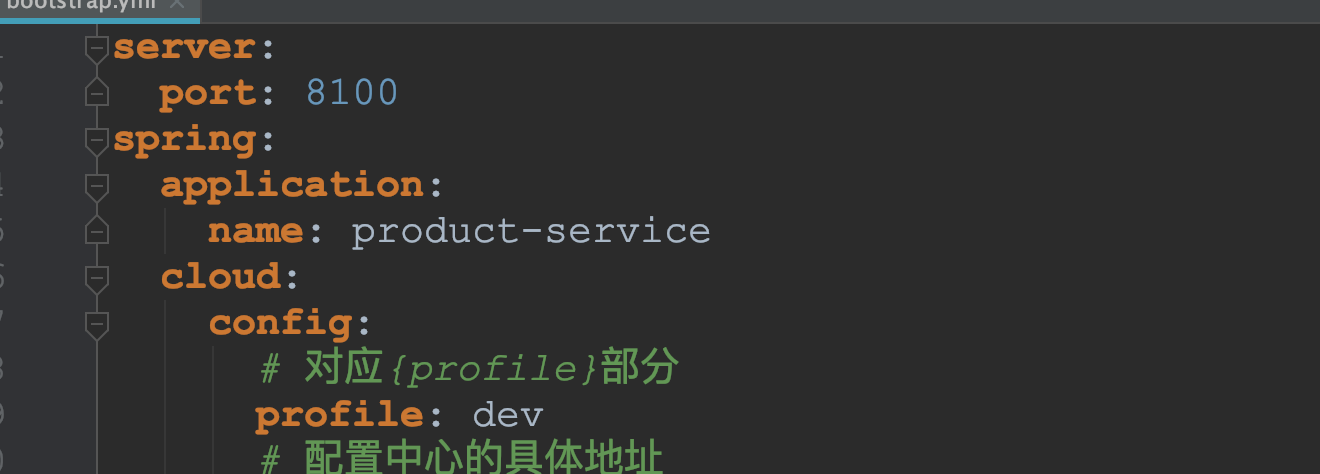
修改POM文件,增加依赖。
一旦在项目中增加Sleuth依赖,那么在微服务启动运行后,响应的调用就就会启用Sleuth监控追踪机制。
机制是:Sleuth会监视该微服务中的所有请求,查看请求中是否包含了追踪数据,如果没有,将会创建一个新的追踪数据,并将该追踪数据添加到请求的header中。
启动测试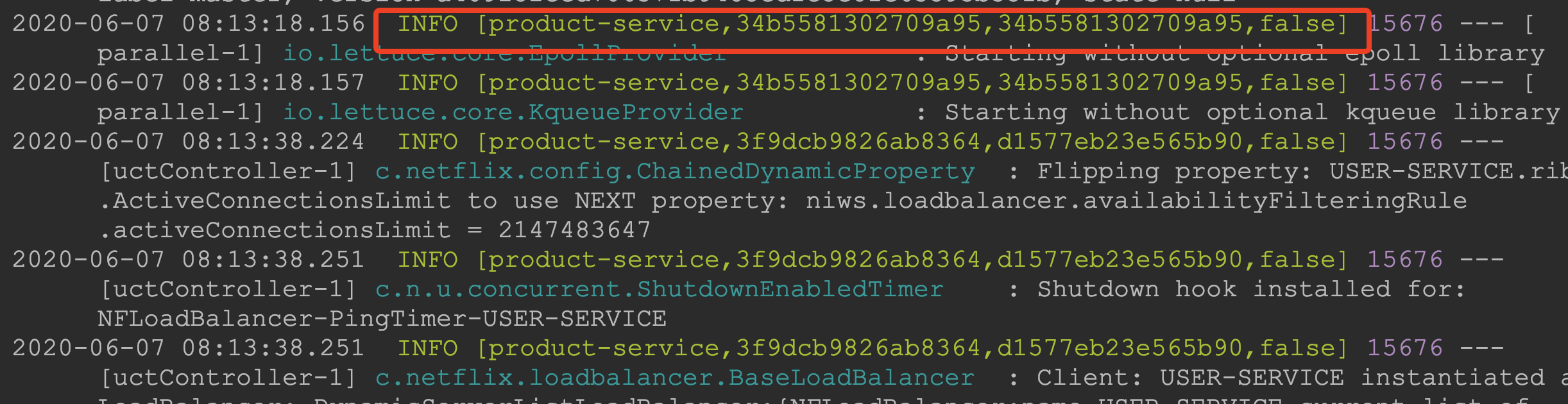
Sleuth所生成的追踪数据,格式为【ApplicationName,TraceId,SpanId,Exportable】
- ApplicationName:product-service,是Sleuth当前所追踪服务的服务名称。
- TraceId:34b5581302709a95,对应于客户端的每次请求,也就是一次请求处理的链路。通过该标识符就可以找到一次客户端请求完成的处理链路。
- SpanId:34b5581302709a95,对应于每次请求中每一个处理部分,也就是该请求链路中的每一环,是Sleuth追中的最基础工作单元。
- Exportable:false,是否将追踪到的信息输出到Zipkin服务器等日志采集服务上。
2、有关Span
Span是由Tracer创建的。Tracer的源码:
- 创建一个Span
当启动一个Span时,Tracer就会根据给定的名称创建一个新的Span,并记录该Span的创建时间和开始时间。
使用@NewSpan注解.
- 关闭一个Span
关闭Span时Sleuth才会根据配置将采集到的数据通过spanReporter发送采集器,关闭Span的核心代码: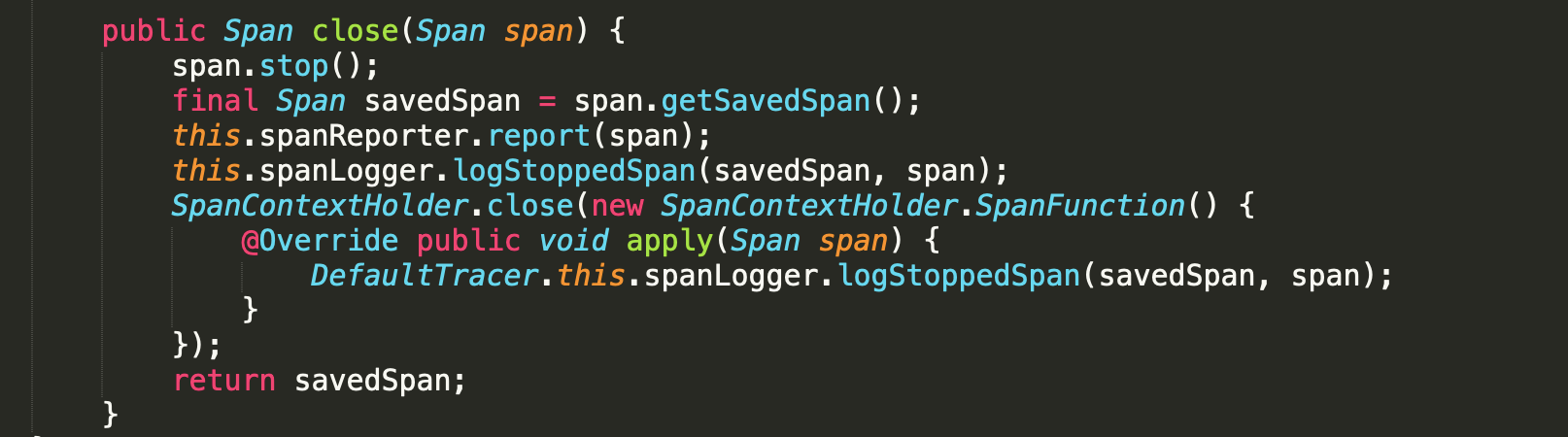
在Span关闭的最后,会通过SpanContextHolder.close()方法从当前线程中移除。所以,当使用Tracer创建自己的Span时,一定要记住最后使用close()方法将其关闭,否则Sleuth是不会将采集到的数据发送给采集服务器的。
注意:正确关闭Span是非常重要的,否则在系统日志中会出现很多警告,并且,Zipkin服务器可能因此将无法获取到采集的数据。
- 继续使用一个Span
Span是Sleuth所追踪的最小工作单元,但有时候可能想把一些列的处理作为一个工作单元,而不是割裂的小单元。
- 当使用Hystrix时:HystrixCommand执行只是当前处理过程中的一部分,因此进行分析时也不想将其分开。
- 当使用AOP时:只是通过基础层面将一个业务也分开处理而已。
可以通过继续使用同一个Span来达到目的。
整合Zipkin服务
Zipkin致力于收集分布式系统中的时间数据,并进行跟踪。通过Zipkin可以为开发者采集一个外部请求所跨多个微服务之间的服务跟踪数据,同时以可视化的方式为开发者展现服务请求所跨多个微服务中耗费的总时间及各个微服务所耗费的时间。
Zipkin主要涉及4个组件:
- collector:数据收集组件,用来收集Sleuth所生成的跟踪数据
- storage:数据存储时间,将采集的数据进行存储以便后续进行分析。
- search:数据查询组件,对采集到的数据处理后,可以通过查询组件进行过滤、分析等
- UI:数据展示组件
Zipkin在数据存储上提供了可插拔式数据存储方案:
- In-Memory:将采集到的数据保存在内存中。
- MySql:将采集到的数据保存到MySQL数据库中
- Cassandra:是一个使用非常广泛的关系型开源数据库
- Elasticsearch:ELK
1、构建Zipkin服务器
增加pom文件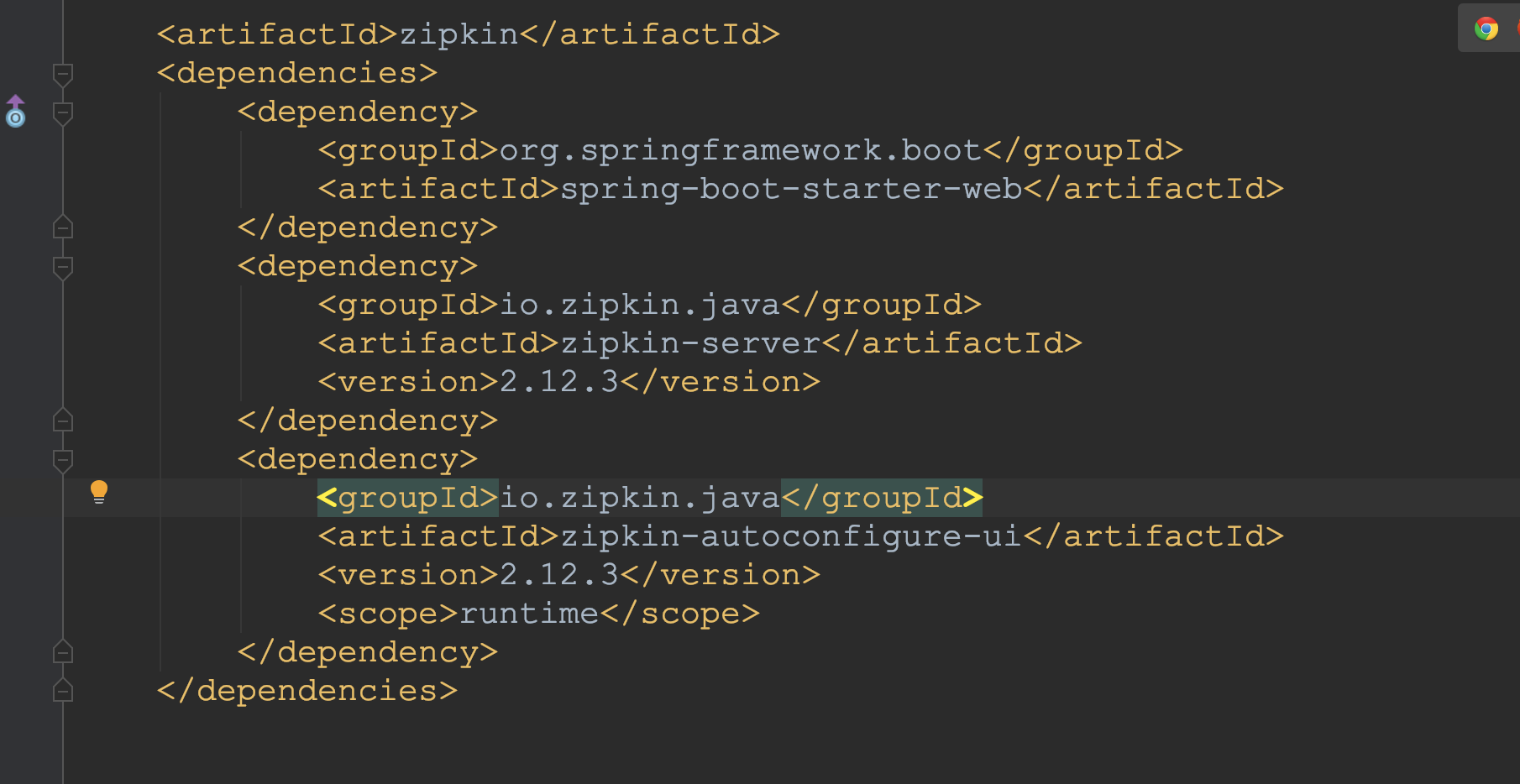
编写引导类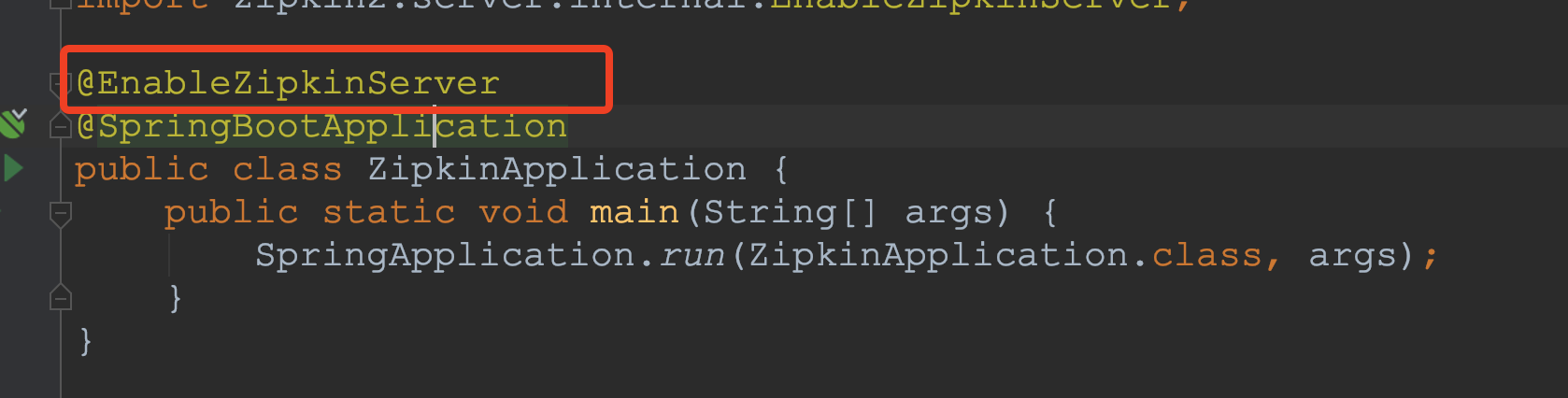
编写配置文件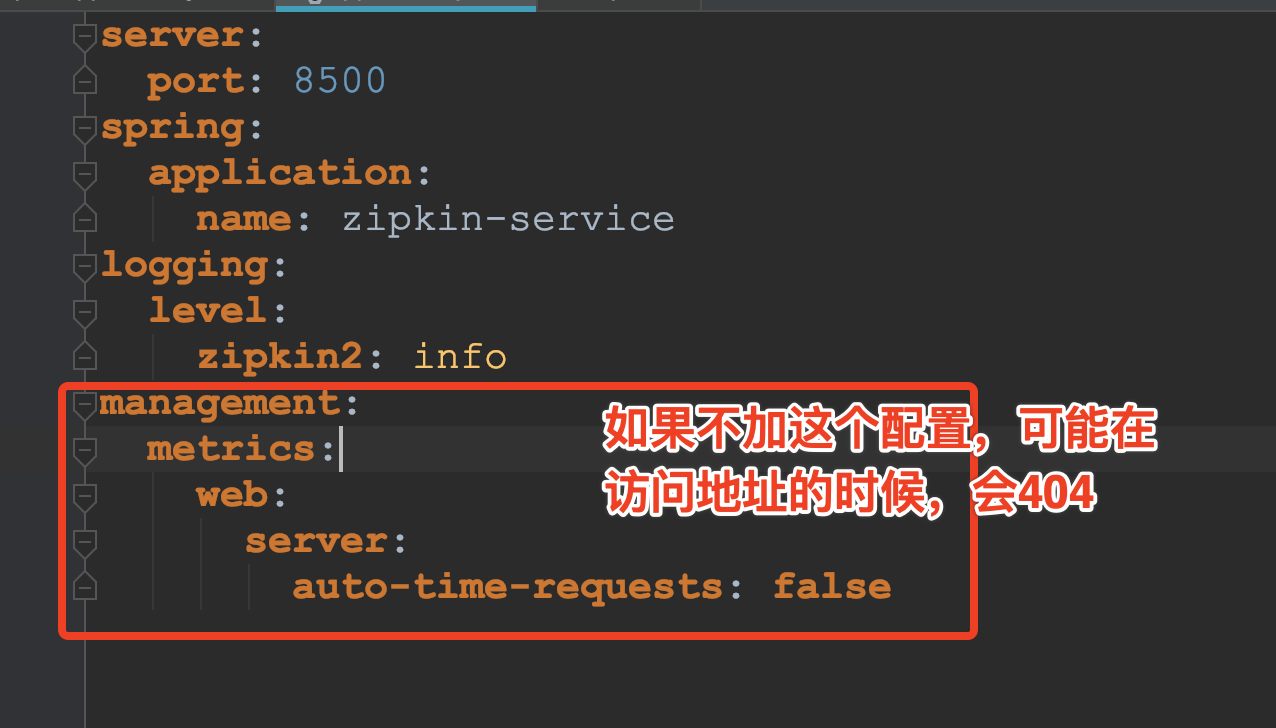
启动程序,访问localhost:8500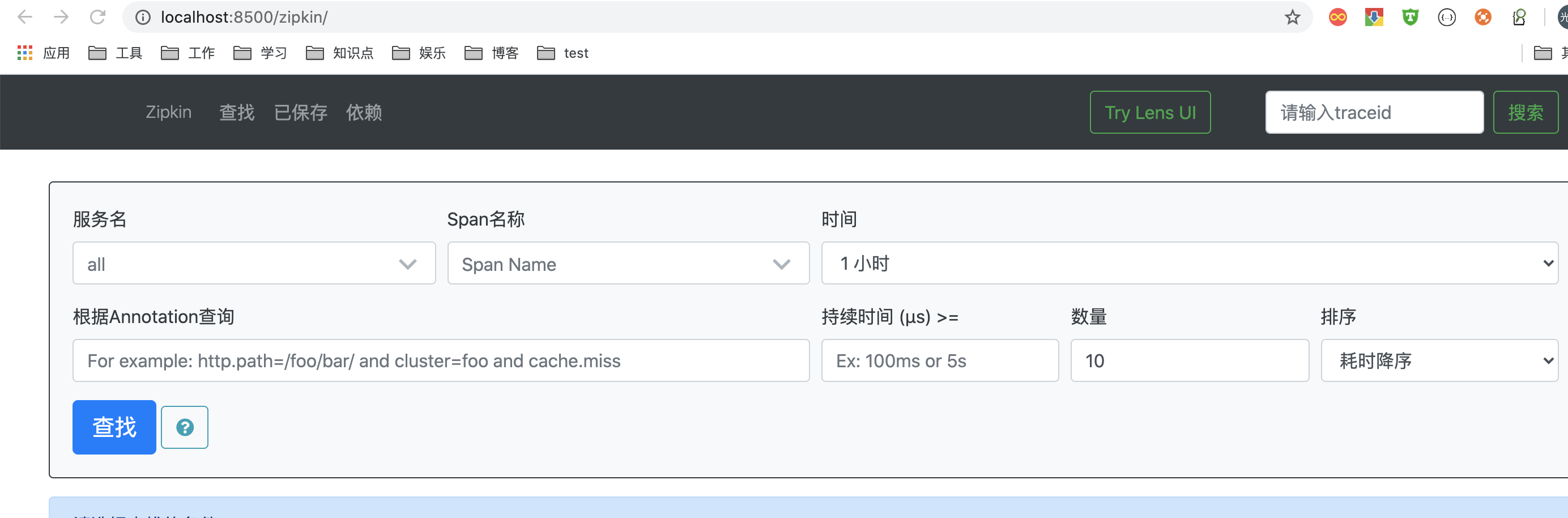
2、整合微服务
对商品微服务、用户微服务增加pon依赖,及配置修改
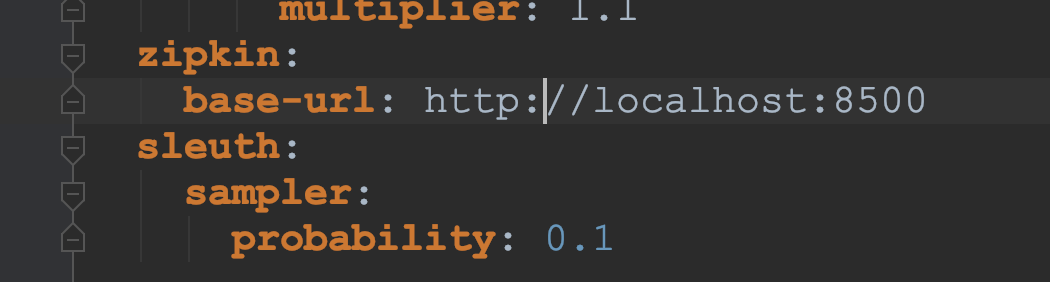
3、Zipkin分析
依次启动Eureka、Config、Zipkin、User、Product服务。
多次访问该接口:http://localhost:8100/product/comment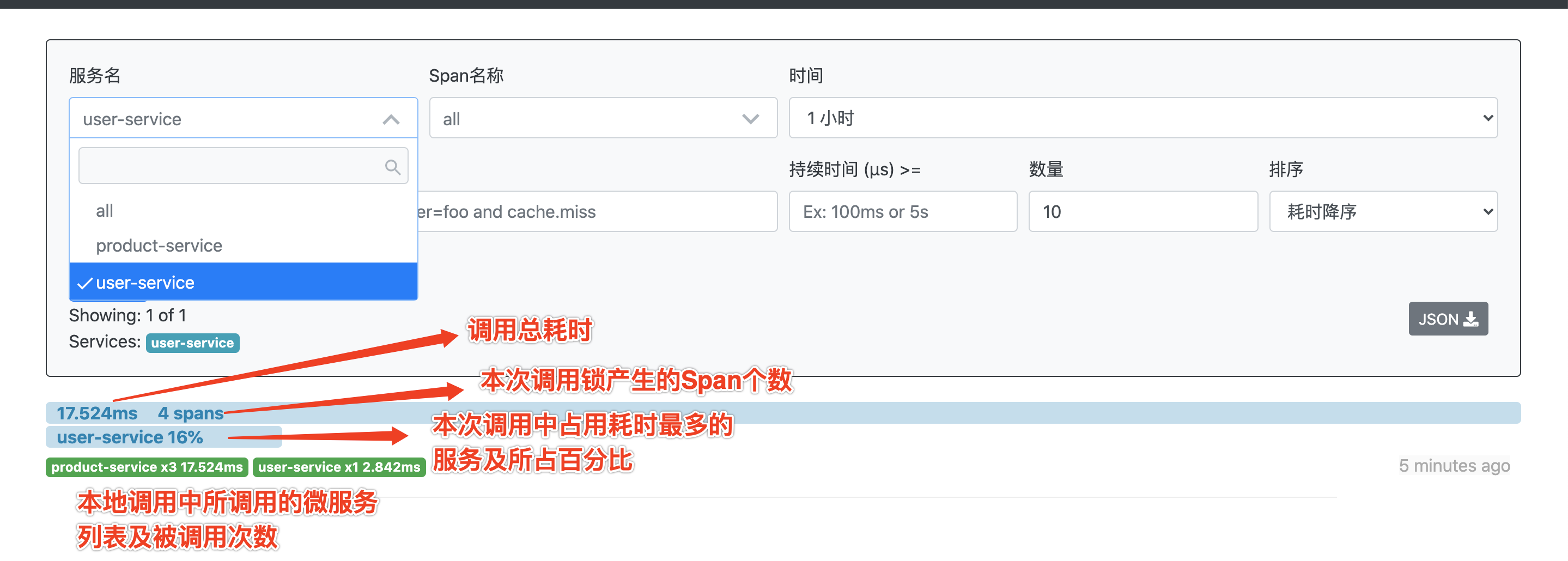
单个请求的详细数据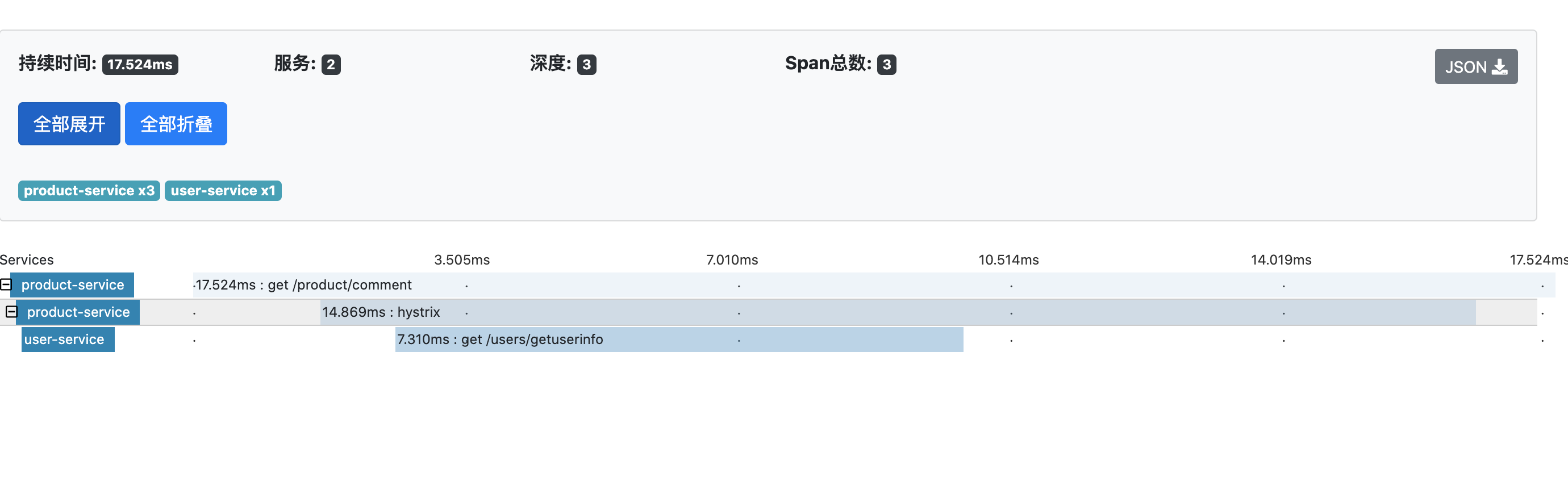
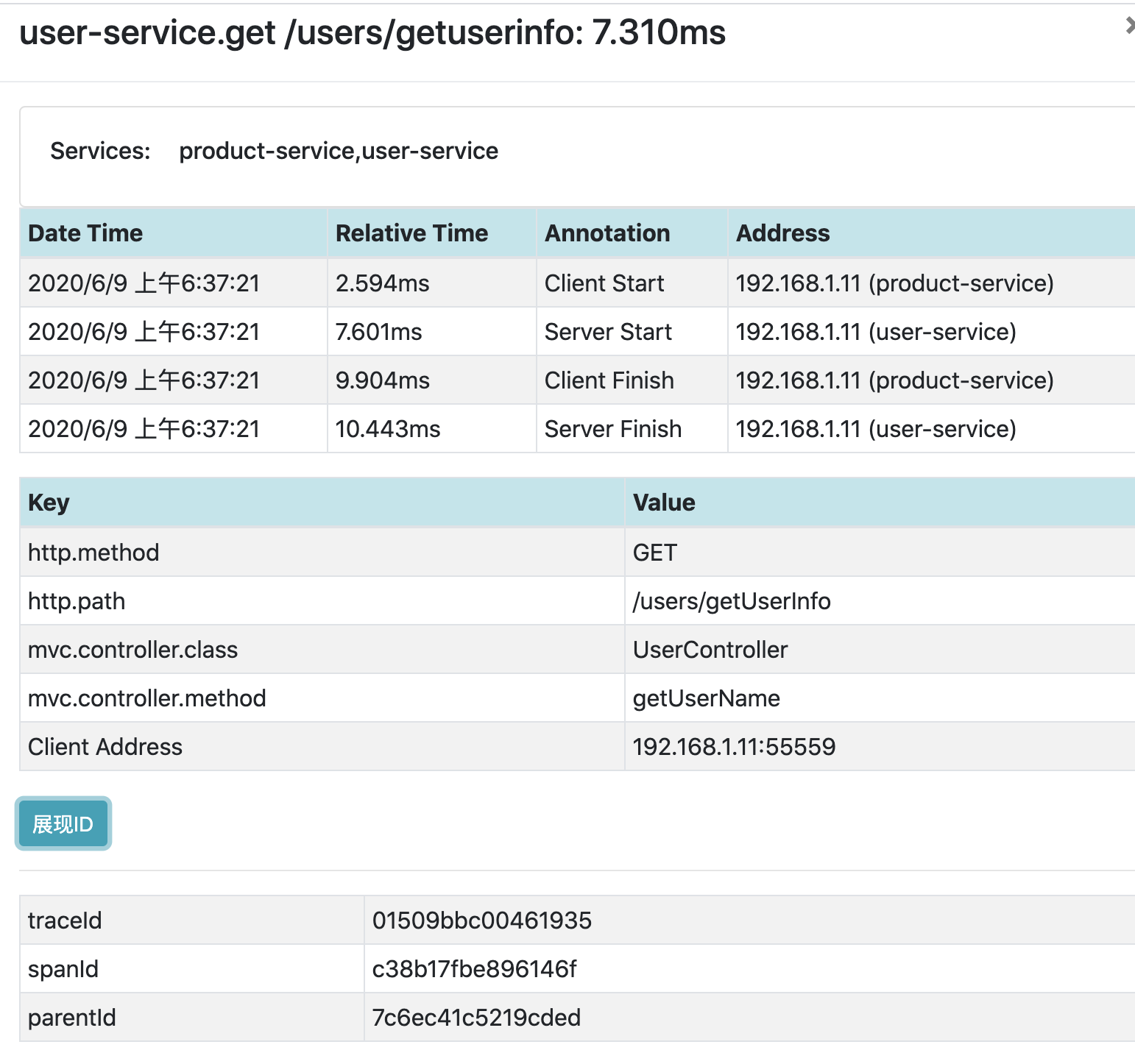
通过Dependencies标签查看服务请求中各微服务之间的依赖关系: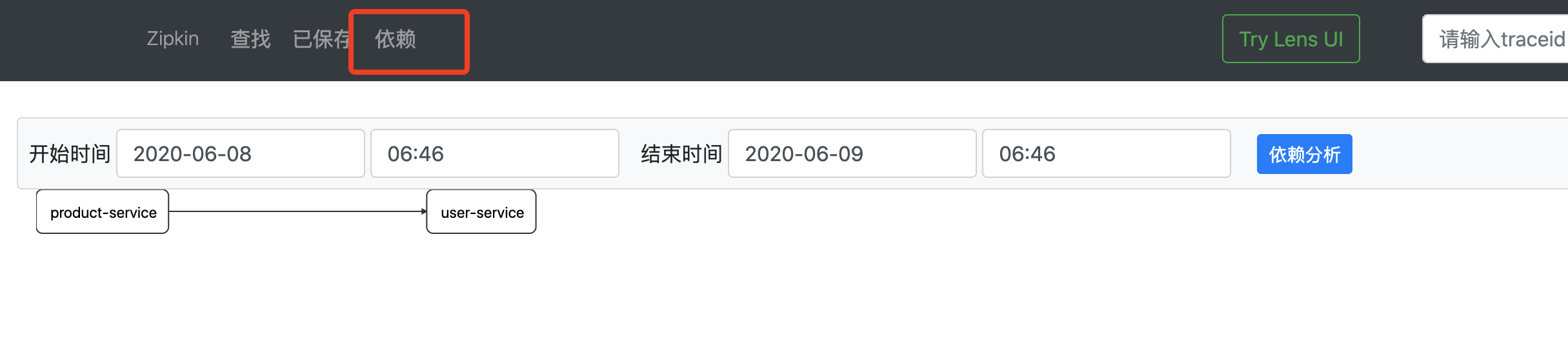
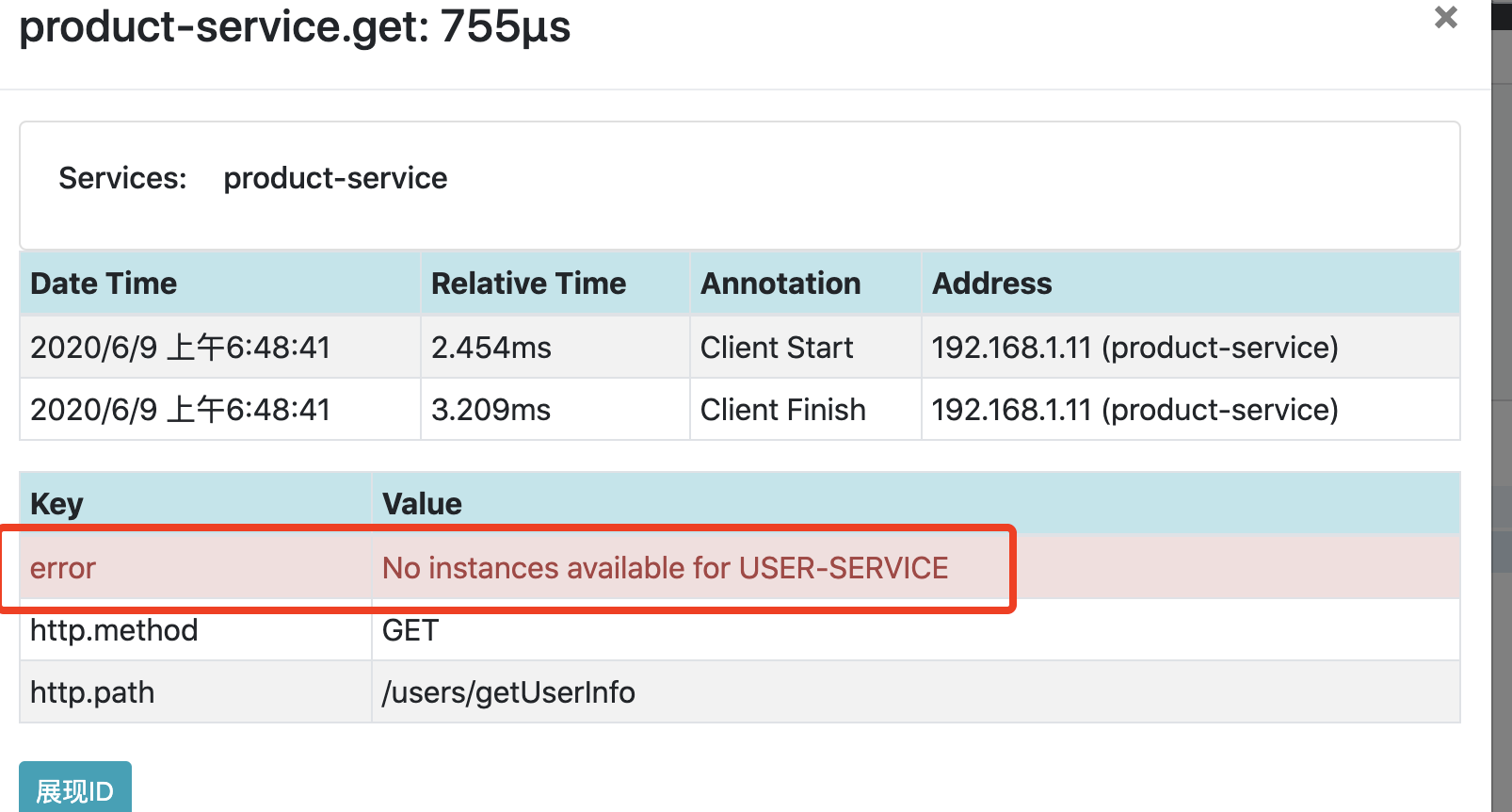
当调用异常并且没哟捕获时,Zipkin会自动将本次调用标记为红色。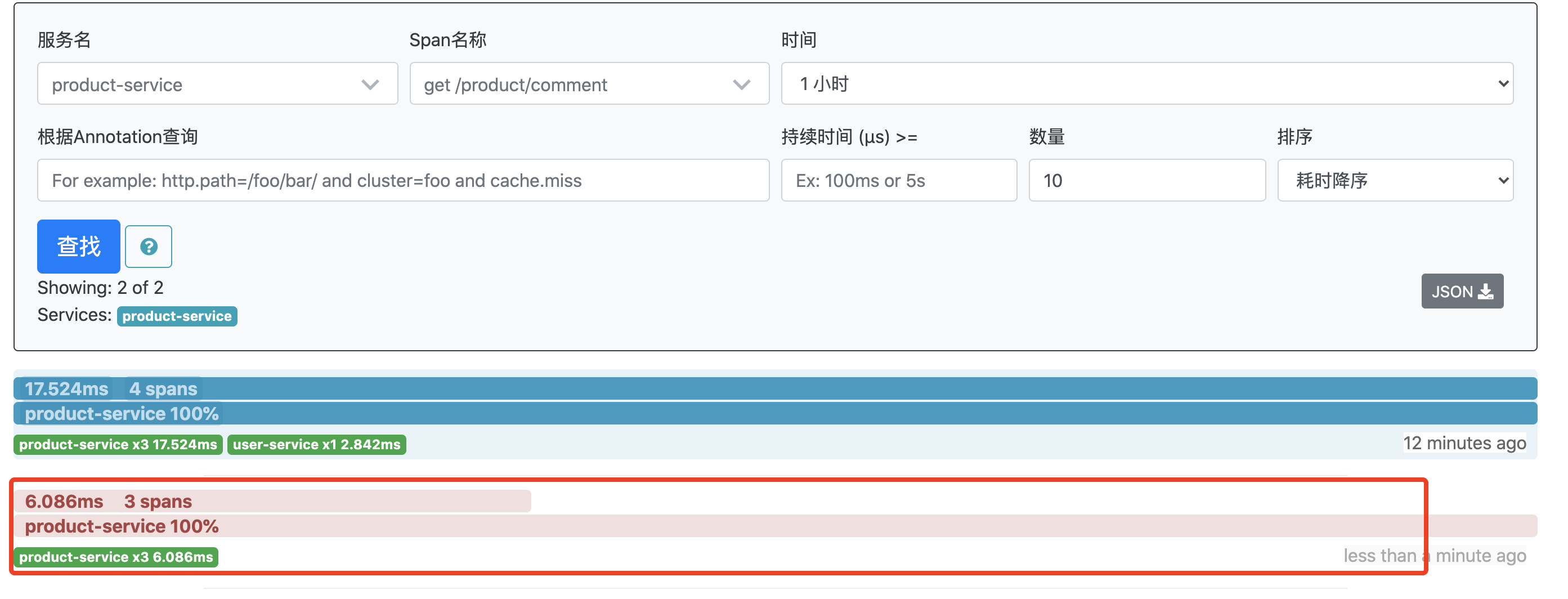
Sleuth抽样采集与采样率
Sleuth提供了一个Sampler策略,可以通过该策略来控制采样算法。
Sleuth默认采样算法的实现是水塘抽样算法。是指对给定一个长度很大或者未知的数据流进行抽样,使得数据流中的所有数据被选中的概率相等。
我们通过设置配置spring.sleuth.sampler.percentage属性进行更改,0.0~1.0之间的数值。

若有收获,就点个赞吧
0 人点赞
