1、windows下的服务开启与关闭
1)net stop 服务名称;
2)net start 服务名称
3)exit退出服务
4)Windows下MySql功能查找:计算机—>右键—>管理—>服务和应用程序—>服务—>找mysql服务
2、登录MySQL(Windows/Linux)
1)本地登录(显示密码)
mysql-uroot-p密码
eg: mysql-uroot-pmima*
2)本地登录(显示密码)
mysql-uroot-p
密码
eg: mysql-uroot-p
mima*
3、数据库整体操作
- show databases;//显示所有数据库
- use test;//表示正在使用一个名字叫做test的数据库。
- show tables;//显示数据库test的所有表
- create database zzx;//创建数据库zzx
- select version();//查询数据库版本号
- select ‘database’;或者select database();//查看当前数据库
额外补充
mysql是不见“;”不执行,“;”表示结束!
\c用来终止一条命令的输入。注意是反斜杠
4、SQL语句的分类
DDL的增删改和DML不同,这个主要是对表结构进行操作。DML是操作表中的数据data。
对于SQL语句来说,是通用的,所有的SQL语句以“;”结尾。另外SQL语句不区分大小写
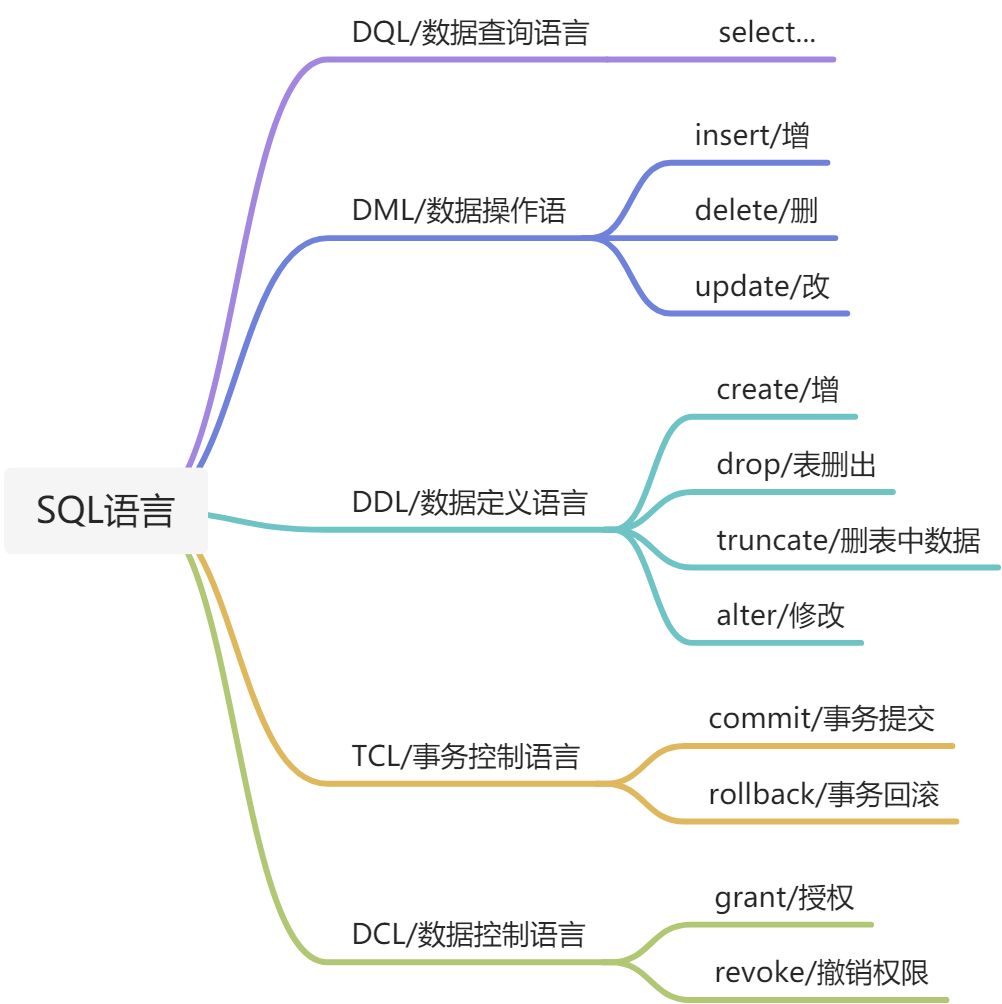
5、导入数据
source 数据库路径//注意:路径中不要有中文!!!!,无分号?<br />error:直接输入发现会报错=>ERROR 1046 (3D000): No database selected<br />solution:在导入数据前,最好先create,必须use 数据库,才能source<br />error:Unknown command '\0'.<br />solution: mysql -uroot -p --default-character-set=utf8<br /> 把'\'改为'/'<br />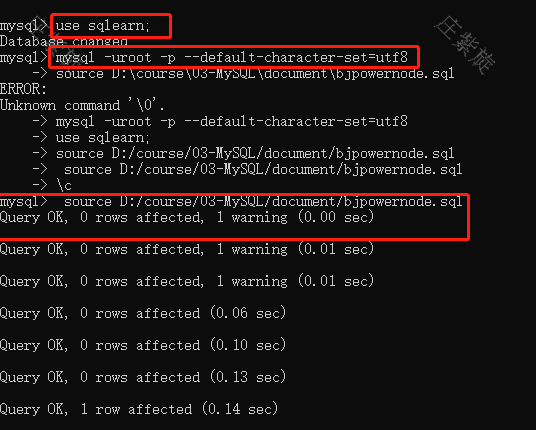<br />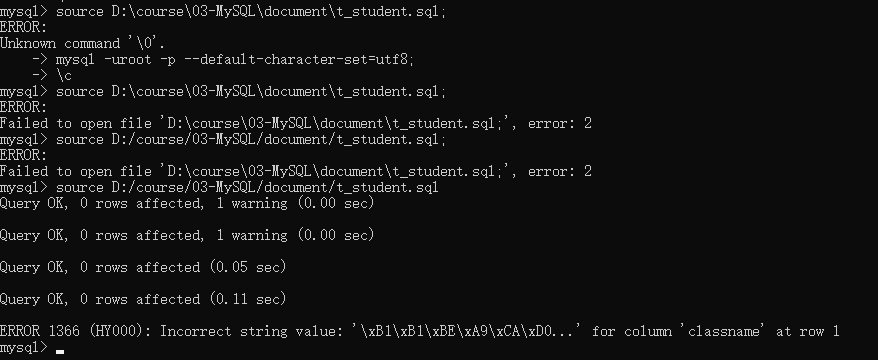<br />后来在纯MySQL下试了试,没有报任何错误<br />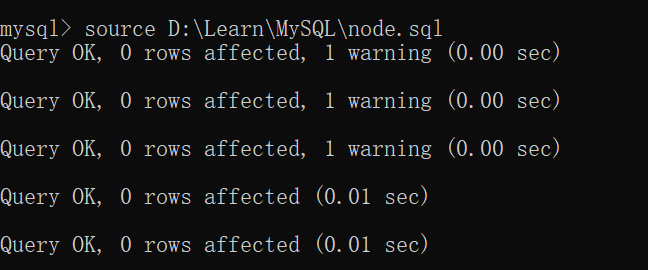
6、导入的表
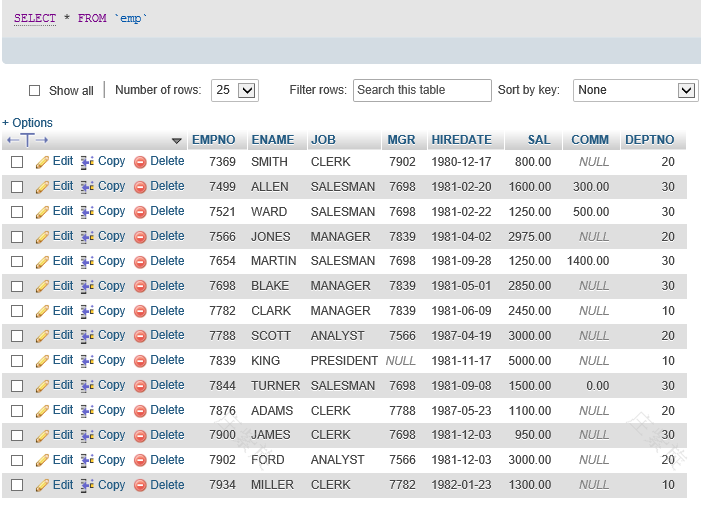
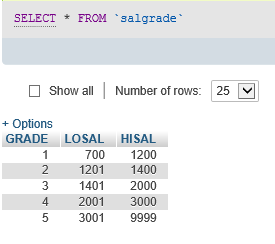
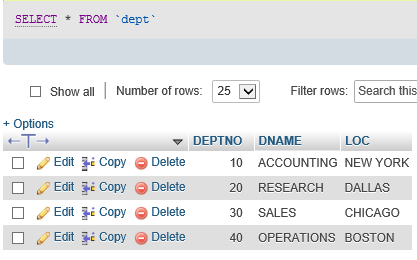
7、单表操作
1)查看表结构
- desc 表名;//只看表的结构
-
2)Select
select 字段名 from 表名;//查询一个字段
- select 字段名1,字段名2 from 表名;//查询多个字段
select * from 表名;//查询所有字段
select 字段名1,字段名2 as 字段名2的别名 from 表名;//起别名
- select 字段名1 字段名1的别名,字段名2 字段名2的别名 from 表名;//省略as
- select deptno,dname ‘dept name’ from dept; //加单引号
//数据库中的字符串都是采用单引号括起来。这是标准的。双引号不标准。
//别名是中文或者是有空格,必须加单引号
select ename,sal*12 from emp; // 结论:字段可以使用数学表达式!
把查询结果去除重复记录【distinct】
- select distinct job from emp;//去重job
- select distinct job,deptno from emp;//表示两个字段联合起来去重
select ename,distinct job from emp; // 这样编写是错误的,语法错误。
distinct只能出现在所有字段的最前方。
3)条件查询(where)
- select 字段1,字段2,字段3….from 表名 where 条件;
| 条件 | 例子 |
|---|---|
| = 等于 | 查询薪资等于800的员工姓名和编号? - select empno,ename from emp where sal = 800; |
查询SMITH的编号和薪资?
- select empno,sal from emp where ename = ‘SMITH’;
//字符串使用单引号 |
| <>或!= 不等于 | 查询薪资不等于800的员工姓名和编号?
- select empno,ename from emp where sal != 800;
- select empno,ename from emp where sal <> 800;
// 小于号和大于号组成的不等号 |
| < 小于 | 查询薪资小于2000的员工姓名和编号?
- select empno,ename,sal from emp where sal < 2000;
|
| <= 小于等于 | |
| > 大于 | |
| >= 大于等于 | |
| between … and ….
等同于
>= and <= |
- select empno,ename,sal from emp where sal >= 2450 and sal <= 3000;
- select empno,ename,sal from emp where sal between 2450 and 3000;
|
| is null 为null
is not null 不为空 | 注意:在数据库当中null不能使用等号进行衡量。需要使用is null
因为数据库中的null代表什么也没有,它不是一个值;
- select empno,ename,sal,comm from emp where comm = null;(error)
- select empno,ename,sal,comm from emp where comm is null;
- select empno,ename,sal,comm from emp where comm is not null;
|
| and 并且 | and和or同时出现的话,有优先级问题吗?and优先级比or高。
- select from emp where sal > 2500 and deptno = 10 or deptno = 20;
//找出工资大于2500并且部门编号为10的员工,或者20部门所有员工找出来。
- select from emp where sal > 2500 and (deptno = 10 or deptno = 20);
//找出(部门编号为10的员工或者20部门)并且工资大于2500所有员工找出来。 |
| or 或者 | |
| in 包含
not in 不在这个范围中 | 注意:in不是一个区间。in后面跟的是具体的值。
查询薪资是800和5000的员工信息?
- select ename,sal from emp where sal = 800 or sal = 5000;
- select ename,sal from emp where sal in(800, 5000);
//上面均表示查找sal=800与5000
// not in 表示不在这几个值当中的数据。
- select ename,sal from emp where sal not in(800, 5000, 3000);
|
| not 取非 |
- is null =>is not null
- in => not in
|
| like 模糊查询 | |
| %匹配任意多个字符 | 找出名字中含有O的?
select ename from emp where ename like ‘%O%’;
找出名字以K开始的?
select ename from emp where ename like ‘K%’; |
| :任意一个字符。 | 找出第二个字每是A的?
- select ename from emp where ename like ‘_A%’;
找出第三个字母是R的?
- select ename from emp where ename like ‘__R%’;
(%是一个特殊的符号, 也是一个特殊符号 ==>查询需要转义)
找出名字中有“”的?
- select name from t_student where name like ‘%%’; //这样不行。
- select name from tstudent where name like ‘%\%’; // \转义字符。
|
4)排序
select 字段名 from 表名 order by 字段名;// 默认是升序!!!
select 字段名 from 表名 order by 字段名 desc ;// 指定降序
select 字段名 from 表名 order by 字段名 asc ;// 指定升序
可以两个字段排序吗?或者说按照多个字段排序?
eg:查询员工名字和薪资,要求按照薪资升序,如果薪资一样的话,再按照名字升序排列。
select ename,sal from emp order by sal asc, ename asc;
// sal在前,起主导,只有sal相等的时候,才会考虑启用ename排序。
5) 数据处理函数(单行处理函数)
数据处理函数又被称为单行处理函数,单行处理函数的特点:一个输入对应一个输出。和单行处理函数相对的是:多行处理函数。(多行处理函数特点:多个输入,对应1个输出!比如select sum(sal) from emp)
| lower 转换小写 | - select lower(ename) from emp; |
|---|---|
| upper 转换大写 | - select upper(ename) from emp; |
| substr取子串 ( 被截取的字符串, 起始下标,截取的长度) |
- select substr(ename, 1, 1) as ename from emp; |
注意:起始下标从1开始,没有0. |
| concat
函数进行字符串的拼接 |
- select concat(empno,ename) from emp;
|
| length 取长度 |
- select length(ename) as length from emp;
|
| trim 去空格 |
- select from emp where ename = ‘ KING’;
//Empty set (0.00 sec)
- select from emp where ename = trim(‘ KING’);//去空格可搜索
|
| str_to_date
将字符串转换成日期 | |
| date_format 格式化日期 | |
| format 格式化数字 |
- SELECT FORMAT(column_name,’格式’) FROM table_name;
- select empno, ename, Format(sal, m) from emp;
//加入千分位和保留m位小数 |
| round 四舍五入 |
- select ‘abc’ from emp; // select后面直接跟“字面量/字面值”
- select round(1236.567, 0) as result from emp; //保留整数位。
- select round(1236.567, 1) as result from emp; //保留1个小数
- select round(1236.567, 2) as result from emp; //保留2个小数
- select round(1236.567, -1) as result from emp; // 保留到十位。
|
| rand() 生成随机数 |
- select round(rand()100,0) from emp; // 100以内的随机数
|
| ifnull 空处理函数 | 在所有数据库当中,只要有NULL参与的数学运算,最终结果就是NULL。
ifnull函数用法:ifnull(数据, 被当做哪个值)
- select ename, (sal + ifnull(comm, 0)) 12 as yearsal from emp;
|
| case..when..then..when..then..else..end |
- case..when..then..when..then..else..end
当员工的工作岗位是MANAGER的时候,工资上调10%,当工作岗位是SALESMAN的时候,工资上调50%,其它正常。
(注意:不修改数据库,只是将查询结果显示为工资上调)
select ename ,job, sal as oldsal,(case job when ‘MANAGER’ then sal1.1 when ‘SALESMAN’ then sal1.5 else sal end) as newsal from emp;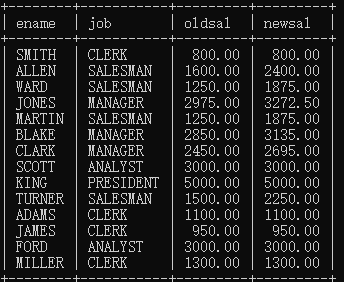 |
|
6)分组函数(多行处理函数)
多行处理函数的特点:输入多行,最终输出一行。
| count 计数 | - select count(ename) from emp;//计算员工数量 |
|---|---|
| sum 求和 | - select sum(sal) from emp;//计算工资和 |
| avg 平均值 | - select avg(sal) from emp;//计算平均工资 |
| max 最大值 | - select max(sal) from emp;//找出最高工资 |
| min 最小值 | - select min(sal) from emp;//找出最低工资 |
| 注意:分组函数在使用的时候必须先进行分组,然后才能用。 如果你没有对数据进行分组,整张表默认为一组。 |
分组函数在使用的时候需要注意哪些?
1)分组函数自动忽略NULL,你不需要提前对NULL进行处理。
2)分组函数中count(*)和count(具体字段)有什么区别?
- count(具体字段):表示统计该字段下所有不为NULL的元素的总数。
count(*):统计表当中的总行数。(只要有一行数据count则++)因为每一行记录不可能都为NULL,一行数据中有一列不为NULL,则这行数据就是有效的。
3)分组函数不能够直接使用在where子句中。
eg:找出比最低工资高的员工信息。
select ename,sal from emp where sal > min(sal);
表面上没问题,运行一下?
ERROR 1111 (HY000): Invalid use of group function
4)所有的分组函数可以组合起来一起用。
select sum(sal),min(sal),max(sal),avg(sal),count() from emp;
+—————+—————+—————+——————-+—————+
| sum(sal) | min(sal) | max(sal) | avg(sal) | count() |
+—————+—————+—————+——————-+—————+
| 29025.00 | 800.00 | 5000.00 | 2073.214286 | 14 |
+—————+—————+—————+——————-+—————+
7)分组查询(非常重要:五颗星*)
格式:select …from…where …group by…having…order by…
(以上关键字的顺序不能颠倒,需要记忆。)<br />
1) 找出每个工作岗位的工资和?
select job,sum(sal) from emp group by job;
select ename,job,sum(sal) from emp group by job;//ename不是分组字段
以上语句在mysql中可以执行,但是毫无意义。以上语句在oracle中执行报错。<br /> oracle的语法比mysql的语法严格。(mysql的语法相对来说松散一些!)<br />重点结论:在一条select语句当中,如果有group by语句的话,<br /> select后面只能跟:参加分组的字段,以及分组函数。<br /> 其它的一律不能跟。
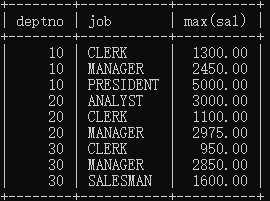
2) 找出“每个部门,不同工作岗位”的最高薪资?
技巧:两个字段联合成1个字段看。(两个字段联合分组)
select deptno, job, max(sal) from emp group by deptno, job;
使用having可以对分完组之后的数据进一步过滤。
having不能单独使用,having不能代替where,having必须
和group by联合使用。
3)找出每个部门最高薪资,要求显示最高薪资大于3000的?
- 使用having可以对分完组之后的数据进一步过滤。
- having不能单独使用,having不能代替where,having必须和group by联合使用。
select deptno,max(sal) from emp group by deptno having max(sal) > 3000;
思考一个问题:以上的sql语句执行效率是不是低?比较低,实际上可以这样考虑:先将大于3000的都找出来,然后再分组。
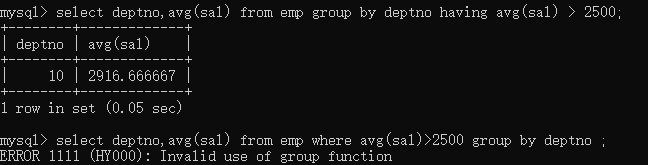
select deptno,max(sal) from emp where sal>3000 group by deptno ;
优化策略:where和having,优先选择where,where实在完成不了了,再选择having。
eg: 找出每个部门平均薪资,要求显示平均薪资高于2500的。select deptno,avg(sal) from emp group by deptno having avg(sal) > 2500;

若有收获,就点个赞吧
0 人点赞
