netty编解码的优势
java里面的序列化/反序列化就是一种编解码 类->流->类
为什么netty需要自己的编解码?
java自带序列化的缺点:
1)无法跨语言
2)序列化后的码流太大,也就是数据包太大
3)序列化与反序列化性能比较差
Netty里面的编解码:
- 解码器:负责处理“入站 InboundHandler”数据
- 编码器:负责“出站 OutboundHandler” 数据
Netty里面提供默认的编解码器,也支持自定义编解码器
- Encoder:编码器
- Decoder:解码器
- Codec:编解码器
解码器decoder
https://www.cnblogs.com/sloong/p/5047743.html
它也是一个InHandler
为什么编码器需要重复读取bytebuf?
buf区的数据没有读完会反复进入编码器,直到读完为止,所以如果不想读后面的需要把标移动最后,但是容易引发问题。常常编解码器也需要反复读取
如下图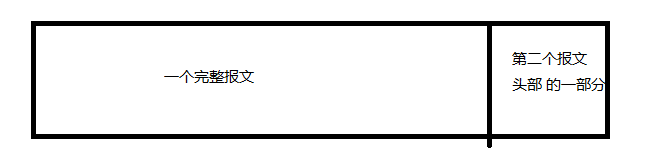
如图所示不光要能识别首部,也应当识别尾部。把完整报文流入下面的handler,剩下报文连通后面的缓冲区一起再读进来。

解码实例


包括前面的读取会不会引发异常
while (true) {// 获取包头开始的indexbeginReader = byteBuf.readerIndex();// 标记包头开始的indexbyteBuf.markReaderIndex();// 读到了协议的开始标志,结束while循环if (byteBuf.readByte() == ProtocolConstant.FRAME_HEAD_FLAG ) {byte[] lengthBytes1 = new byte[2];lengthBytes1[0] = byteBuf.readByte();lengthBytes1[1] = byteBuf.readByte();int length1 = FrameCommUtil.bytes2Int(lengthBytes1,0, lengthBytes1.length);//读取长度System.out.println(length1+" ]");// if(byteBuf.readableBytes() < length1 + 3){//报文不够最小数目// log.info("报文不够最小数目3");// byteBuf.resetReaderIndex();// return;// }if(byteBuf.readByte() == ProtocolConstant.FRAME_MIDDLE_FLAG) {//如果跳过长度字节后一个为标志位if (byteBuf.readableBytes() >= length1 + 2){byteBuf.readBytes(length1);//跳过数据区byteBuf.readByte();//跳过校验和//看看是否是尾帧if (byteBuf.readByte() == ProtocolConstant.FRAME_TAIL_FLAG) {byteBuf.resetReaderIndex();//还原到包头位置byteBuf.readByte();break;}} else {byteBuf.resetReaderIndex();return ;}}}
知识补充:tcp粘包的原因

编码器:encoder
- Encoder对应的就是ChannelOutboundHandler,消息对象转换为字节数组
- Netty本身未提供和解码一样的编码器,是因为场景不同,两者非对等的
- MessageToByteEncoder消息转为字节数组,调用write方法,会先判断当前编码器是否支持需要发送的消息类型,如果不支持,则透传;(透传全传到下一个handler里面)
- MessageToMessageEncoder用于从一种消息编码为另外一种消息(例如POJO到POJO)
注意
https://blog.csdn.net/zougen/article/details/79047252?utm_source=blogxgwz0
https://www.orchome.com/915

若有收获,就点个赞吧
0 人点赞
