MLP Model
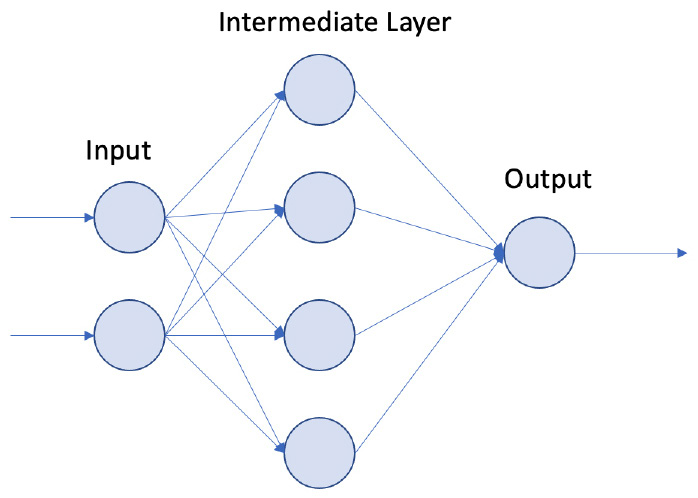
输入层 中间层 输出层
XOR输入 XOR输出
构建模型
XOR模型
- 导入库
- 准备数据
- 配置模型
- 训练模型
- 加载模型
- 做出预测
导入库
import pytorch_lightning as plimport torchfrom torch import nn, optimfrom torch.autograd import Variableimport pytorch_lightning as plfrom pytorch_lightning.callbacks import ModelCheckpointfrom torch.utils.data import DataLoaderprint("torch version:",torch.__version__)print("pytorch ligthening version:",pl.__version__)
准备数据
# 对应异或4种输入 A B为两个输入(特征)xor_input = [Variable(torch.Tensor([0, 0])),Variable(torch.Tensor([0, 1])),Variable(torch.Tensor([1, 0])),Variable(torch.Tensor([1, 1]))]# 对应目标变量xor_target = [Variable(torch.Tensor([0])),Variable(torch.Tensor([1])),Variable(torch.Tensor([1])),Variable(torch.Tensor([0]))]# 创造数据加载器 我们可以通过多种方式创建数据集并将其作为数据加载器传递给 PyTorch Lightningxor_data = list(zip(xor_input, xor_target))train_loader = DataLoader(xor_data, batch_size=1)# [(tensor([0., 0.]), tensor([0.])),# (tensor([0., 1.]), tensor([1.])),# (tensor([1., 0.]), tensor([1.])),# (tensor([1., 1.]), tensor([0.]))]
配置模型
- 初始化模型
- 将输入映射到模型
- 配置优化器
- 设置训练参数
初始化模型
class XORModel(pl.LightningModule):def __init__(self):# super().__init__()super(XORModel,self).__init__()self.input_layer = nn.Linear(2, 4)self.output_layer = nn.Linear(4,1)self.sigmoid = nn.Sigmoid()# mean squared errorself.loss = nn.MSELoss()
将输入映射到模型
# 将输入映射到模型# 将接收的特征传递到输入层# 输入层生成结果传递到激活函数中# 激活函数生成的结果传递到输出层中def forward(self, input):#print("INPUT:", input.shape)x = self.input_layer(input)#print("FIRST:", x.shape)x = self.sigmoid(x)#print("SECOND:", x.shape)output = self.output_layer(x)#print("THIRD:", output.shape)return output
配置优化器
def configure_optimizers(self):# 模型所有参数params = self.parameters()# 创建优化器optimizer = optim.Adam(params=params, lr = 0.01)return optimizer
设置训练参数
# batch_idx为当前批次序号def training_step(self, batch, batch_idx):# 批量数据batch 里面包括输入/特征以及target目标xor_input, xor_target = batch# print("XOR INPUT:", xor_input.shape)# print("XOR TARGET:", xor_target.shape)# self会间接调用forward方法outputs = self(xor_input)# print("XOR OUTPUT:", outputs.shape)loss = self.loss(outputs, xor_target)return loss
训练模型
# 训练模型from pytorch_lightning.utilities.types import TRAIN_DATALOADERS# 创建模型检查点回调函数 保存模型并不限于训练模型后 在训练模型中也要保存checkpoint_callback = ModelCheckpoint()model = XORModel()# Trainer是一些关键事物的抽象,例如循环数据集、反向传播、清除梯度和优化器步骤# Trainer类支持许多帮助构建模型的功能# 其中一些功能是各种回调、模型检查点、提前停止、开发运行单元测试、对GPU和TPU、记录器、日志、时期等的支持# 创建训练器trainer = pl.Trainer(max_epochs=100, callbacks=[checkpoint_callback])# 传递模型和训练数据 开始训练trainer.fit(model, train_dataloaders=train_loader)



加载模型
# 加载模型# 获取最新版本模型路径print(checkpoint_callback.best_model_path)# 从检测点中加载模型train_model = model.load_from_checkpoint(checkpoint_callback.best_model_path)
做出预测
# 获取最新版本模型路径print(checkpoint_callback.best_model_path)# 从检测点中加载模型train_model = model.load_from_checkpoint(checkpoint_callback.best_model_path)test = torch.utils.data.DataLoader(xor_input, batch_size=1)for val in xor_input:_ = train_model(val)print([int(val[0]),int(val[1])], int(_.round()))from torchmetrics.functional import accuracyprint(checkpoint_callback.best_model_path)train_model = model.load_from_checkpoint(checkpoint_callback.best_model_path)total_accuracy = []for xor_input, xor_target in train_loader:for i in range(100):output_tensor = train_model(xor_input)test_accuracy = accuracy(output_tensor, xor_target.int())total_accuracy.append(test_accuracy)total_accuracy = torch.mean(torch.stack(total_accuracy))print("TOTAL ACCURACY FOR 100 ITERATIONS: ", total_accuracy.item())

若有收获,就点个赞吧
0 人点赞
