一 排序算法(冒泡,快排)
冒泡排序:
- 算法步骤
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
针对所有的元素重复以上的步骤,除了最后一个。
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
- 动图演示
3Java代码实现
public class BubbleSort implements IArraySort {@Overridepublic int[] sort(int[] sourceArray) throws Exception {// 对 arr 进行拷贝,不改变参数内容int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);for (int i = 1; i < arr.length; i++) {// 设定一个标记,若为true,则表示此次循环没有进行交换,也就是待排序列已经有序,排序已经完成。boolean flag = true;for (int j = 0; j < arr.length - i; j++) {if (arr[j] > arr[j + 1]) {int tmp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = tmp;flag = false;}}if (flag) {break;}}return arr;}}
快速排序
- 算法步骤
从数列中挑出一个元素,称为 “基准”(pivot);
重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
- 动图演示
3 实现代码
public class QuickSort implements IArraySort {@Overridepublic int[] sort(int[] sourceArray) throws Exception {// 对 arr 进行拷贝,不改变参数内容int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);return quickSort(arr, 0, arr.length - 1);}private int[] quickSort(int[] arr, int left, int right) {if (left < right) {int partitionIndex = partition(arr, left, right);quickSort(arr, left, partitionIndex - 1);quickSort(arr, partitionIndex + 1, right);}return arr;}private int partition(int[] arr, int left, int right) {// 设定基准值(pivot)int pivot = left;int index = pivot + 1;for (int i = index; i <= right; i++) {if (arr[i] < arr[pivot]) {swap(arr, i, index);index++;}}swap(arr, pivot, index - 1);return index - 1;}private void swap(int[] arr, int i, int j) {int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}}
二 查找算法(二分)
三 数组元素去重法
方法一
我们可以创建一个空的List,遍历数组,依次将数组中的值传入List,利用List的 contains()方法,如果List已经包含当前遍历到的数组元素,则不添加进List,保证其唯一性;用List的toArray()方法把集合转换成数组。
方法二
利用Map集合键的不可重复性,遍历数组,把每个数组元素都传进Map集合,得到乱序而不重复的Map集合;再用Map的keySet().toArray()方法把集合转换成数组。
- 方法三
利用数组去重,先创建一个新的数组B,与原数组A等长,先不传入值(则B = { null , null , null , … , null });立一个flag并遍历A,依次取A中每一个值与B中所有值作比较,一旦值比较出相等的,则flag设false,当A中这一个值与B中所有值比较完之后,flag如果还是true,则把A的当前值传给B,如为false则不做操作,进入下一轮循环,保证唯一性;当遍历完A后,得到一个等长、无重复的B(末尾可能有多个null值),并得到末位非null的索引值index;创建新数组C,长度为index,遍历B数组(仅取到索引为index),传入C。
- 方法四//这个比较简单
实例化一个Set集合,遍历数组并存入集合,如果元素已存在则不会重复存入,最后返回Set集合的数组形式。
- 方法五
通过链表去重,遍历数组,传入LinkedHashSet,得到无重复的元素集合;创建迭代器,迭代集合。
四 ArrayList底层,初始容量,扩容
五 HashMap底层结构
数据结构底层:
(1)Hash表就是类似于数组的形式,具有像数组那样根据随机访问的特性,是根据关键码值(Key value)而直接进行访问的数据结构。
解决hash冲突:
有一组数据19 01 23 14 55 68 11 86 37要存储在表长11的数组中,其中H(key)=key MOD 11
开放定制法中的线性探测再散列,平方探测再散列等方法处理hash冲突
平方探测再散列就是先按照线性探测计算出原本的hash值,然后一次加上1的平方得到一个新的hash值判断是否冲突,如果不行就拿原本的hash值加上2的平方,依次。
链地址法:
除此之外还有再哈希法,以及建立一个公共溢出区。
红黑树:
(1)每个节点或者是黑色,或者是红色。(2)根节点是黑色。(3)每个叶子节点(nli)是黑色。 (注意:这里叶子节点,是指为空(nli)的叶子节点)(4)如果一个节点是红色的,则它的子节点必须是黑色的(也就是不能连续的两个红色节点)。(5)从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
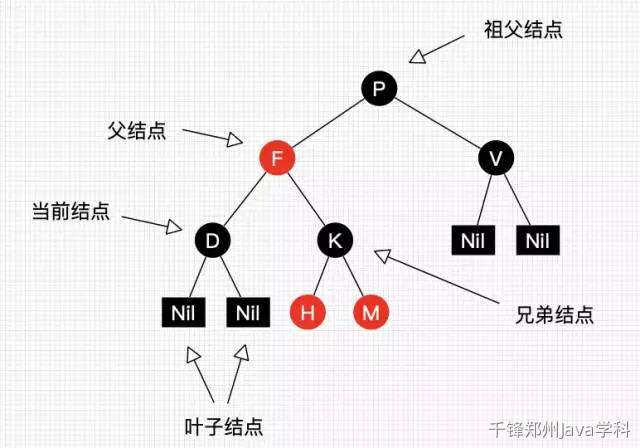
数据结构:JDK1.8之前:哈希表+单向链表;JDK1.8之后:哈希表+单向链表+红黑树,当链表长度超过8、数组长度超过64的时候,链表将转换为红黑树,JDK1.8之前采用的是头插法插入数据,JDK1.8采用的尾插法插入数据。
特点:查询快,元素无序,key值不允许重复但可以为null,value可以重复。
底层分析:JDK1.8之前采用的哈希表+单向链表,当链表中的元素较多的时候,hash值相同的元素就多了,再次通过hash值查询的时候,效率比较低。JDK1.8之后采用哈希表+单向链表+红黑树,当链表的长度超过8的时候,就会采用红黑树去存储。
扩容机制:jdk1.8中链表长度大于8的时候,转换为红黑树,低于6的时候转换为链表。
jdk1.8中链表的长度大于8,并且数组长度大于64,链表转换为红黑树,如果数组长度小于64,对数组进行扩容。
六 HashMap的头插法和尾插法
七 HashMap的put源码过程
map.put(k,v)实现原理
(1)首先将k,v封装到Node对象当中(节点)。
(2)然后它的底层会调用K的hashCode()方法得出hash值。
(3)通过哈希表函数/哈希算法,将hash值转换成数组的下标,下标位置上如果没有任何元素,就把Node添加到这个位置上。如果说下标对应的位置上有链表。此时,就会拿着k和链表上每个节点的k进行equal。如果所有的equals方法返回都是false,那么这个新的节点将被添加到链表的末尾。如其中有一个equals返回了true,那么这个节点的value将会被覆盖。
[
](https://blog.csdn.net/qq_43370771/article/details/111353046)
八ConCurrentHashMap底层1.7和1.8安全(JUC)
九 常用的数据结构(数组,栈,队列,红黑二叉树)
十 红黑二叉树的转换
十一 hash冲突

若有收获,就点个赞吧
0 人点赞
