不深入源码,只讲大致逻辑,毕竟源码还是需要自己去研究的。

根据官方文档的介绍,总结一下这个框架的特性,知道特性后,再去根据每个特性去分析下原理,除去一些没特点的特性,总结了一下,有下面几个:
- 支持URI正则匹配
- 页面配置支持Java代码动态注册,或注解配置自动注册
- 支持配置全局和局部拦截器,可在跳转前执行同步/异步操作,例如定位、登录等
- 支持配置全局和局部降级策略
- ServiceLoader模块,实现组件化、模块间通信
接下来,首先wmrouter是一个路由框架,那么最重要的功能当然是模块间跳转和通信,分析原理,重点自然是这两个,该框架也根据这两个功能衍生出两个特性,URI的分发过程和ServiceLoader模块,下面就讲这两点。
从官方copy一份URI跳转的核心设计思路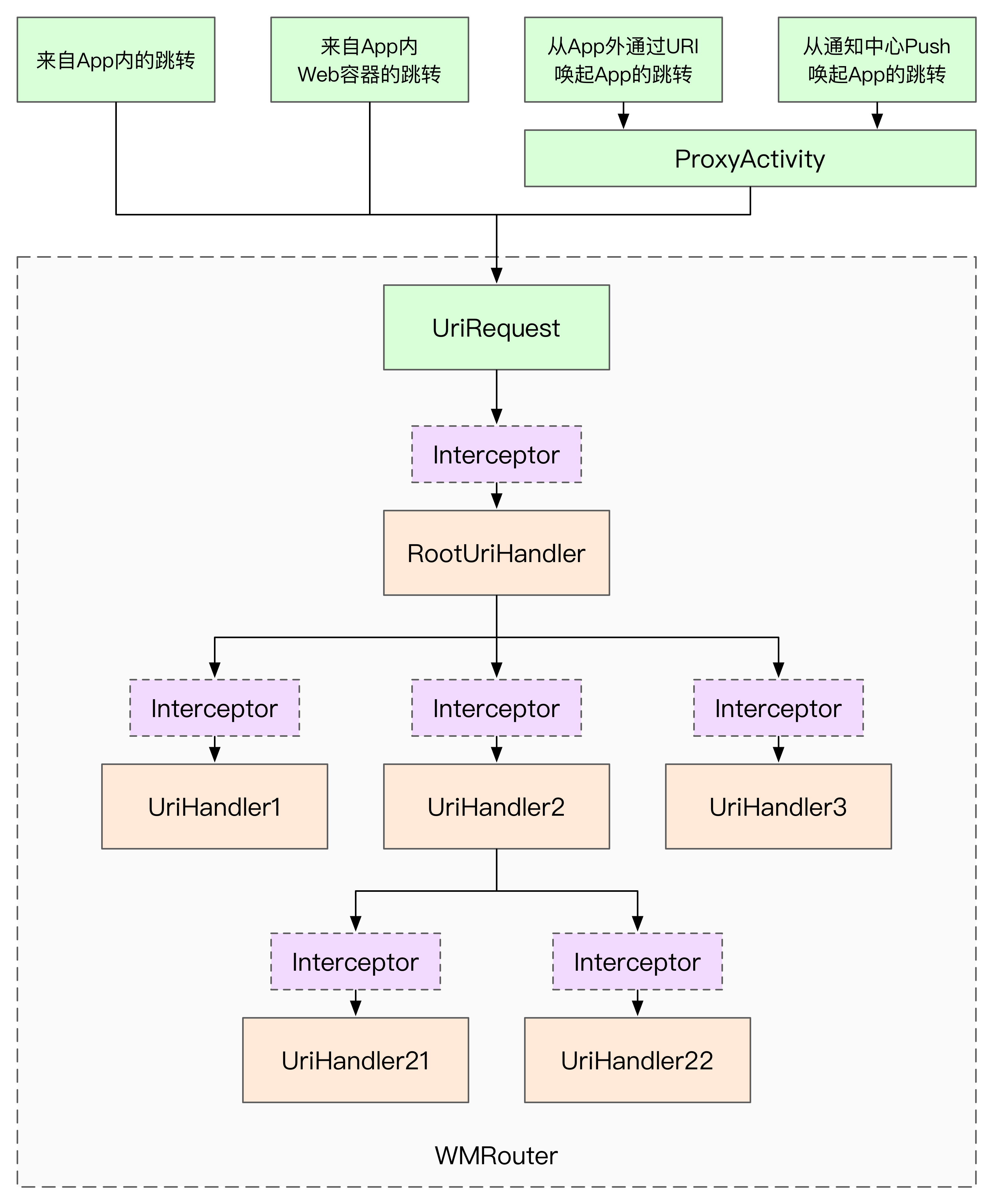
看起来好像东西挺少的,简单说说,所有的跳转包括外部(浏览器发起的)跳转,都会被封装为UriRequest,每一个UriRequest都会经历一个RooterUriHandler(可以自己设计,wmrouter有提供默认),RooterUriHandler根据优先级处理不同的UriHandler,在整个过程中,拦截器和
UriHandler挂钩,也就是在处理Handler,可以做一些拦截操作,具体什么操作下面会分析到。
了解了大致流程,在开始具体分析前,需要先了解一下apt的作用,https://www.yuque.com/mikaelzero/cg3abf/yudshn 之前一篇博客有根据wmrouter单独设计了一个跳转功能,大体上能够理解apt在wmrouter中的作用。
接下来看下具体的URI分发过程图,别看图复杂,逻辑很简单
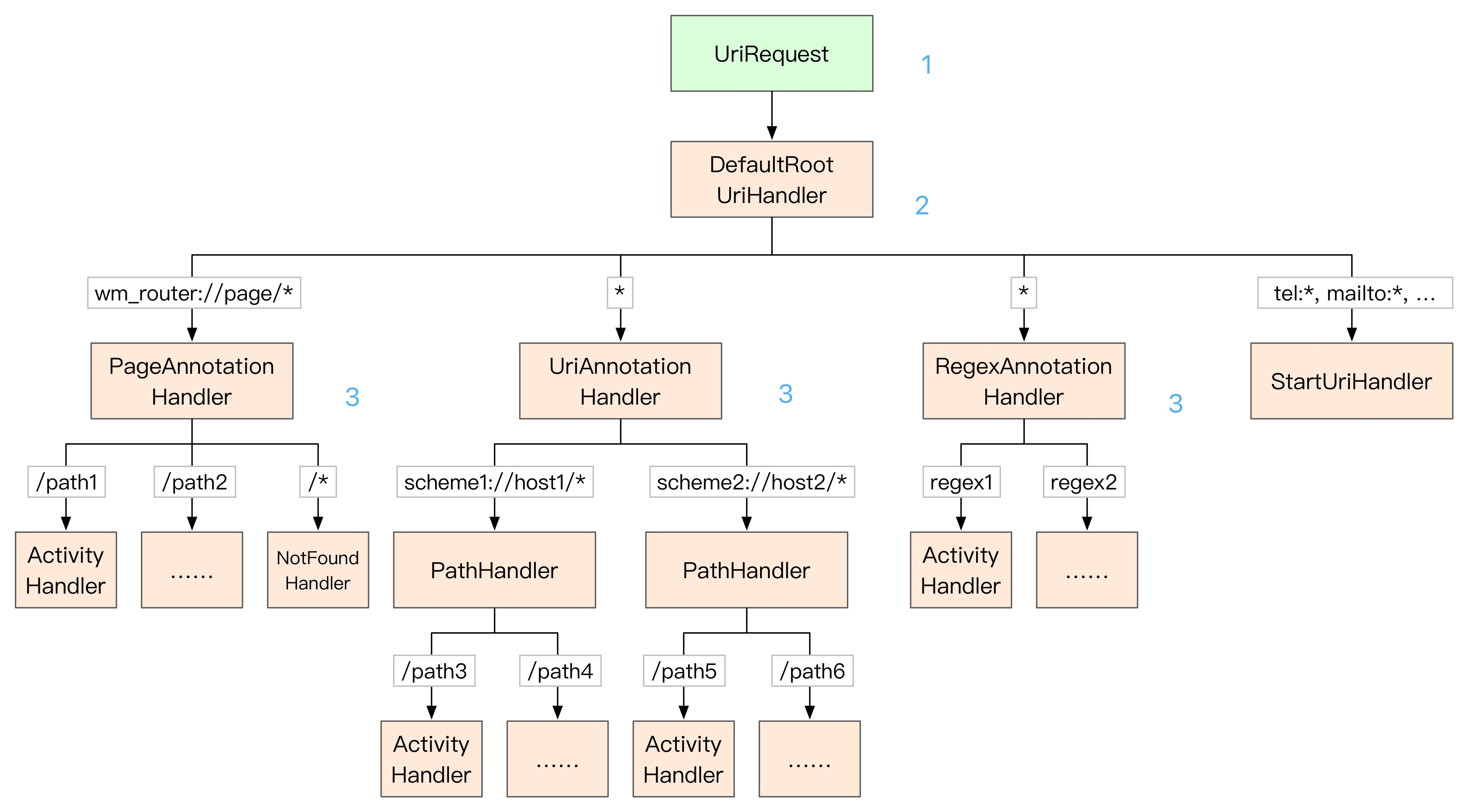
第一步,生成UriRequest
第二步,进入RootUriHandler处理过程
第三步,处理不同的Handler
RootUriHandler是使用者调用init函数进行初始化,一般使用默认的DefaultRootUriHandler
DefaultRootUriHandler rootHandler = new DefaultRootUriHandler(context);Router.init(rootHandler);
在DefaultRootUriHandler中添加了四个Handle,对应图上的四种Handler
addChildHandler(mPageAnnotationHandler, 300);addChildHandler(mUriAnnotationHandler, 200);addChildHandler(mRegexAnnotationHandler, 100);addChildHandler(new StartUriHandler(), -100);
最后一个参数优先级,那么对应图上刚好是第三步中从左到右进行处理

怎么分发?
处理方法在UriHandle中,他是所有XXXHandle的老爹
public void handle(@NonNull final UriRequest request, @NonNull final UriCallback callback) {if (shouldHandle(request)) {if (mInterceptor != null && !request.isSkipInterceptors()) {......} else {handleInternal(request, callback);}} else {callback.onNext();}}
handleInternal由不同特性的Handle进行处理,但基本上都是对自身包含的Handle列表进行串行调用,like this
@Overrideprotected void handleInternal(@NonNull final UriRequest request, @NonNull final UriCallback callback) {next(mHandlers.iterator(), request, callback);}private void next(@NonNull final Iterator<UriHandler> iterator, @NonNull final UriRequest request,@NonNull final UriCallback callback) {if (iterator.hasNext()) {UriHandler t = iterator.next();t.handle(request, new UriCallback() {@Overridepublic void onNext() {next(iterator, request, callback);}@Overridepublic void onComplete(int resultCode) {callback.onComplete(resultCode);}});} else {callback.onNext();}}
其他不重要,知道他会对他的所有ChildHandler进行处理就可以了,这是主要的分发流程。
现在从图中的左到右,分析下他们的工作流程,很简单
PageAnnotationHandler对应的是WMRouter提供的RouterPage注解,如果你看过上面发的那篇关于apt的文章,你应该知道他大致的流程了。
如果 scheme为 wm_router host为 page的uri,那么他会处理,否则给下一个Handler,框架会对RouterPage注解的类进行扫描后获取需要的信息,并注册到PageAnnotationHandler中,这样PageAnnotationHandler就知道有多少个子Handler需要去处理了 like this
public class PageAnnotationInit_98a9894a5c616338294a4e09f7a7bc91 implements IPageAnnotationInit {public void init(PageAnnotationHandler handler) {handler.register("/test/handler", new TestPageAnnotation.TestHandler());handler.register("/test/interceptor", new TestPageAnnotation.TestInterceptorHandler(), new UriParamInterceptor());}}
至于这个init方法怎么调用的,分析ServiceLoader再说。
还有其他三个Handler,不需要分析了,相信聪明的你马上就知道原理和PageAnnotationHandler大体上是一致的
UriAnnotationHandler对应的注解为 RouterUri注解
RegexAnnotationHandler对应的注解为 RouterRegex注解
StartUriHandler对应尝试直接用setData(Uri)隐式跳转启动Uri的Handler
现在你知道了,关于注解的原理都是通过apt来进行代码生成,然后再去调用生成的代码就行了,问题来了,生成代码的类名不都是随机名字吗?怎么调用?

如果你看了上面的分析,并且去自己生成了下代码,你会发现,这些类的共性都是他们都会实现接口

ServiceLoader类是根据SPI进行扩展,功能就是获取到实现了某个接口的所有实现类,大致说下原理,怎么调用函数?当然是要先实例化,wmrouter分出了单例的参数,如果是单例会在单例池中找,如果没有就会根据类的信息尝试在Provider(也是一个池,可以使用者自己使用RouterProvider注解来实例化)中找,如果没有就直接newInstance,这样类的实例拿到了,就可以直接调用用apt生成的类的函数
那么类的信息怎么来?想要get,当然要先put了,怎么put,wmrouter用的是通过asm插件来生成一个类,叫ServiceLoaderInit,该插件会去扫描service包(在生成类的时候,会统一放在service包名下)下的ServiceInit_xxx1的类,然后进行调用,like this
* public class ServiceLoaderInit {** public static void init() {* ServiceInit_xxx1.init();* ServiceInit_xxx2.init();* }* }
那ServiceLoaderInit这个类怎么调用?反射,因为ServiceLoaderInit是在gradle的任务中生成的,所以编译期获取不到
Class.forName(Const.SERVICE_LOADER_INIT).getMethod(Const.INIT_METHOD).invoke(null);
大致逻辑明白了后,去看wmtouer提供的比如函数调用什么的,逻辑都是类似的。

若有收获,就点个赞吧
0 人点赞
