SELECT
-- 选择数据库;USE <dadtabase>;# 查找数据;SELECT <column>,… FROM <table>;
子查询
基本用法
SELECT nameFROM productsWHERE unit_price > (SELECT unit_priceFROM productsWHERE product_id = 3)
IN用法
SELECT *FROM productsWHERE product_id NOT In (SELECT DISTINCT product_idFROM order_items)
ALL
下面两种写法的结果相同,都是查询invoice_total大于所以client_id=3的invoice_total。
SELECT *FROM invoicesWHERE invoice_total > (SELECT MAX(invoice_total)FROM invoicesWHERE client_id = 3)SELECT *FROM invoicesWHERE invoice_total > ALL (SELECT invoice_totalFROM invoicesWHERE client_id = 3)
ANY
表示查询的invoic_total大于一个或多个client_id=3的invoice_total。
SELECT *FROM invoicesWHERE invoice_total > ANY (SELECT invoice_totalFROM invoicesWHERE client_id = 3)
相关子查询
SELECT *FROM employees eWHERE salary > (SELECT AVG(salary)FROM employeesWHERE e.office_id = office_id)
EXISTS
EXISTS的作用就是“判断是否存在满足某种条件的记录”。如果存在这样的记录就返回真(TRUE),如果不存在就返回假(FALSE)。
SELECT *FROM clientsWHERE client_id in (SELECT DISTINCT client_idFROM invoices)SELECT *FROM clients cWHERE EXISTS(SELECT client_idFROM invoicesWHERE client_id = c.client_id)
INSERT
INSERT INTO customers (first_name,last_name,birth_date,address,city,state)VALUES ('John','Smith','1990-01-01','address','city','CA')
插入多行
INSERT INTO shippers (name)VALUES ('rook'),('jfk'),('jack')
插入分层行

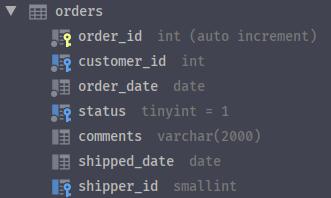
在order_items和orders表中,有一个相同的列叫做order_id,如果希望在orders表中插入一条记录,同时在order_items表中插入一个相同order_id的记录,MySQL提供了一个函数LAST_INSERT_ID(),用于获取上一条插入语句的主键,可以通过这个函数实现插入相同order_id的记录。
INSERT INTO orders (customer_id,order_date,status)VALUES (1,'2019-01-02',1);INSERT INTO order_itemsVALUES(LAST_INSERT_ID(),1,1,2.95),(LAST_INSERT_ID(),2,1,3.95);
创建表复制
SELECT * FROM orders为子查询语句。
CREATE TABLE orders_archived ASSELECT * FROM orders;USE sql_invoicing;CREATE TABLE invoices_archived ASSELECTinvoice_id, number, invoice_total, payment_total, invoice_date, due_date,FROM invoices iJOIN clients c on i.client_id = c.client_idWHERE payment_date IS NOT NULL;
UPDATE
基本用法
UPDATE invoicesSET payment_total = 10,payment_date = '2019-03-01'WHERE invoice_id = 1
更新多行
UPDATE invoicesSETpayment_total = 10,payment_date = '2019-03-01'WHERE client_id IN (3,4)
UPDATE 中的子查询
UPDATE invoicesSETpayment_total = 10,payment_date = '2019-03-01'WHERE client_id IN( SELECT client_idFROM clientsWHERE state IN ('CA','NY'))
DELETE
DELETE FROM invoicesWHERE client_id = (SELECT clients.client_idFROM clientsWHERE name = 'Myworks')
where
基本用法
SELECT * FROM customers WHERE birth_date > '1990-01-01';
AND、OR 和 NOT
-- 必须同时满足AND两边的条件;SELECT * FROM customers WHERE birth_date > '1990-01-01' AND point > 1000;-- 满足OR两边的一个条件即可;SELECT * FROM customers WHERE birth_date > '1990-01-01' OR point > 1000;-- 不满足条件;SELECT * FROM customers WHERE NOT birth_date > '1990-01-01';
IN
-- 返回state为VA或FL或GA的数据;SELECT * FROM customers WHERE state in ('VA','FL','GA')-- 返回point在1000~3000的数据;SELECT * FROM customers WHERE points BETWEEN 1000 AND 3000
匹配字符串
- LIKE
-- % 匹配不确定长度的字符串,_ 匹配一个字符-- 'b%'查找以b开头的字符串,'%b'查找以b结束的字符串,'%b%'表示b的前后可以有任意字符串,不管在开头还是中间结尾;-- 'b_'表示b后只有一个字符。SELECT * FROM Customers WHERE last_name LIKE 'b%'
REGEXP
-- 'field'字符串中有field即可,无论在开头还是中间结尾;-- '^field'表示字符串必须以field开头;-- 'field$'表示字符串必须以field结尾;-- 'field|mac'查找多个单词,表示字符串中有field或mac其中一个即可;-- '[gm]e' 查找的字符串中有e,而且e的前面有g或m或gm;-- '[a-h]e' e的前面一个字符在a·h的范围内;SELECT * FROM customers WHERE last_name REGEXP 'field'
IS NULL
SELECT * FROM customers WHERE phone IS NULL-- 匹配NULL值
OEDER BY
SELECT * FROM customers ORDER BY first_name-- 按某一列排序
LIMIT
SELECT * FROM customers LIMIT 3-- 筛选出前3行数据SELECT * FROM customers LIMIT 6, 3-- 6是偏移量,指的是跳过前6行数据,在返回3行数据
联结(连接)
INNER JOIN(内连接)
所谓内联结运算,一言以蔽之,就是“以A中的列作为桥梁,将B中满足同样条件的列汇集到同一结果之中”,其中的条件是A和B中有相同的一列。
本数据库连接
SELECT p.product_id, nameFROM order_items o-- 别名,o是order_items的别名,使用order_items的地方都可以用o;JOIN products pON o.product_id = p.product_id-- 指定两个表联结所用的列(联结列);
跨数据库连接
SELECT *FROM order_items oiJOIN sql_inventory.products p-- 跨数据库联结,联结sql_store和sql_inventory的products表;on oi.product_id = p.product_id
自连接
在sql_hr库的employees表中,存在库员的id employee_id,和对应的管理人员id report_to,同时雇员和管理人员都在employee的信息这个表里,如果需要同时返回雇员的信息和管理人员的信息并且在同一行显示,可以使用自连接。
USE sql_hr;SELECTe.employee_id,e.first_name,m.first_name AS mmanagerFROM employees eJOIN employees mon e.reports_to =m.employee_id
多表连接
USE sql_store;SELECTo.order_id,o.order_date,c.first_name,c.last_name,os.order_status_idFROM orders oJOIN customers con o.customer_id = c.customer_idJOIN order_statuses oson o.status = os.order_status_id
复合连接
SELECT *FROM order_items oiJOIN order_item_notes oinon oi.order_id = oin.order_IdAND oi.product_id = oin.product_id
OUTER JOIN(外连接)
外连接也是通过ON子句的联结键将两张表进行连接,并从两张表中同时选取相应的列的。基本的使用方法并没有什么不同,只是结果却有所不同。内联结只能选取出同时存在于两张表中的数据,而对于外联结来说,只要数据存在于某一张表当中,就能够读取出来。
SELECTc.customer_id,c.first_name,o.order_idFROM customers cRIGHT JOIN orders o on c.customer_id = o.customer_idORDER BY c.customer_id
RIGHT 和 LEFT
外连接有两个关键字RIGHT和LEFT,它们的区别在于要把哪张表作为主表,使用LEFT时FROM子句中写在左侧的表是主表,使用RIGHT时右侧的表是主表。这里的左侧住的是FROM后面接的表名,右侧指的是JOIN后面接的表名。使用RIGHT时,在打印结果是右侧表的所有行都会打印出来,同样的,使用LEFT是,打印的结果包含左表的所有行。
USING
SELECTo.order_id,c.first_name,shippers.name AS shipperFROM orders oJOIN customers c-- ON o.customer_id = c.customer_idUSING (customer_id)-- 当列名相等时,可以使用USING语句代替ON语句
自然连接
SELECTo.order_id,c.first_nameFROM orders oNATURAL JOIN customers c-- 这个语句会自动根据两个表相同的列进行连接
CROSS JOIN(交叉连接)
使用这个语句可以连接第一个表的每条记录和第二个表的每条记录,对两张表中的全部记录进行交叉组合,因此结果中的记录数通常是两张表中行数的乘积。
内联结是交叉联结的一部分,“内”也可以理解为“包含在交叉联结结果中的部分”。相反,外联结的“外”可以理解为“交叉联结结果之外的部分”。
SELECTc.first_name AS customer,p.name AS productFROM customers cCROSS JOIN products p-- FROM customers c,products p
集合运算
集合运算,就是对满足同一规则的记录进行的加减等四则运算。通过集合运算,可以得到两张表中记录的集合或者公共记录的集合,又或者其中某张表中的记录的集合。像这样用来进行集合运算的运算符称为集合运算符。
SELECTorder_id,order_date,'Active' AS statusFROM ordersWHERE order_date >= '2019-01-01'UNIONSELECTorder_id,order_date,'Archived' AS statusFROM ordersWHERE order_date < '2019-01-01'-- UNION是并集,进行记录加法运算,将两个语句的结果加起来显示;

注意:
- 作为运算对象的记录的列数必须相同;
- 作为运算对象的记录中列的类型必须一致;
- 可以使用任何SELECT语句,但ORDER BY子句只能在最后使用一次。
ALL
保留重复行
SELECTorder_id,order_date,'Active' AS statusFROM ordersWHERE order_date >= '2019-01-01'UNION ALLSELECTorder_id,order_date,'Archived' AS statusFROM ordersWHERE order_date < '2019-01-01'
表分组
GROUP BY
在GROUP BY子句中指定的列称为聚合键或者分组列。不使用GROUP BY子句时,是将表中的所有数据作为一组来对待的,而使用GROUP BY子句时,会将表中的数据分为多个组进行处理。会将查询结果按指定分组列划分。
GROUP BY子句的书写位置也有严格要求,一定要写在FROM语句之后(如果有WHERE子句的话需要写在WHERE子句之后)。
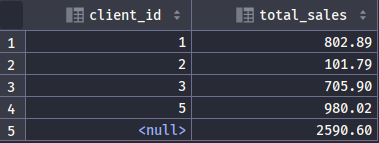
SELECTclient_id,SUM(invoice_total) AS total_salesFROM invoicesGROUP BY client_idORDER BY total_sales DESC;SELECTstate,city,SUM(invoice_total) AS total_salesFROM invoicesJOIN clients c on invoices.client_id = c.client_idGROUP BY state,cityORDER BY total_sales DESC


HAVING(为聚合结果指定条件)
为GROUP BY得到的表分组后的结果指定条件。WHERE子句只能指定记录(行)的条件,而不能用来指定组的条件。
HAVING子句必须写在GROUPBY子句之后,其在DBMS内部的执行顺序也排在GROUP BY子句之后。
HAVING的条件语句中的条件主体必须是SELECT的列(即SELECT后接的列名)。
SELECTclient_id,SUM(invoice_total) AS total_sales,COUNT(*) AS number_of_invoicesFROM invoicesGROUP BY client_idHAVING total_sales > 500 AND number_of_invoices > 5;
ROLLUP
一次计算出不同聚合键组合的结果,对聚合键有效,如SUM(invoice_total)。
SELECTclient_id,SUM(invoice_total) AS total_salesFROM invoicesGROUP BY client_id WITH ROLLUP ;
基本函数
数值函数
ROUND(对象数值,保留小数位数),ROUND函数用来进行四舍五入操作。
SELECT ROUND(5.73,1)
TRUNCATE(对象数值,保留小数位),TRUNCATE函数用于截断数字。
SELECT TRUNCATE(5.73,1)
CEILILNG(对象数值),用于找到大于或等于这个数字的最小整数。
SELECT CEILING(5.7)
FLOOR(对象数字),找到小于或等于这个数字的最大整数。
SELECT FLOOR(5.7)
RAND(),返回一个在【0.1】区间的随机数。
SELECT RAND()

若有收获,就点个赞吧
0 人点赞
