背景介绍
事务隔离级别及错误情况
MySQL中共有4中事务隔离级别,分别是
- 未提交读(Read uncommitted)
- 已提交读(Read committed)
- 可重复读(Repeatable read)
- 可串行化(Serializable )
同时也有三种可能出现的错误情况
- 脏读(Dirty Read)
- 不可重复读(NonRepeatable Read)
- 幻读(Phantom Read)
其对应关系如下: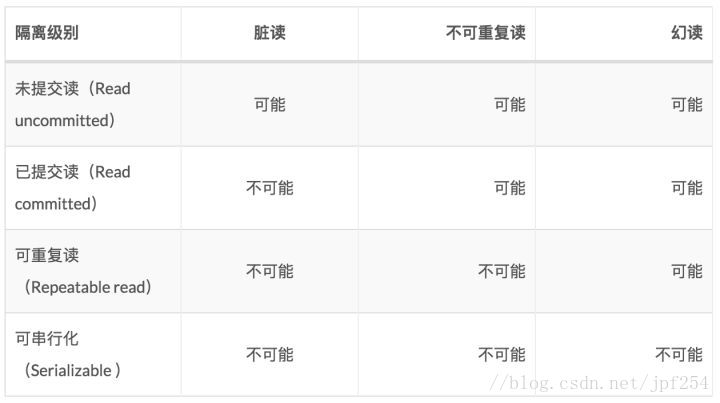
我在学习的过程中,共有两个难点
- 由于隔离级别与错误情况名称过于相似,有时会将二者搞混
相关知识
- 如何开启事务?
三个语句可以开启事务,分别是begin,start transaction,set autocommit=0 - 如何查看及修改MySQL当前事务隔离级别?
查看会话事务隔离级别:select @@tx_isolation;
查看全局事务隔离级别:select @@global.tx_isolation;
设置会话事务隔离级别:set session transaction isolation level ...;
设置全局事务隔离级别:set global transaction isolation level ...; - 示例数据表建表语句如下:
create table tbl(id int primary key,name varchar(30))engine=innodb;
三种错误情况的含义
脏读:若事务A对数据进行了修改(包括insert和update),但这种修改还未提交到数据库中,此时事务B能访问事务A修改的数据,即为脏读
不可重复读:在事务B事务开始后,事务A对数据进行了修改并提交,事务B可以读取到的事务A修改后的数据,导致在事务B的整个过程中可以读取到的数据不一致,即不可重复读.
幻读:幻读是我在学习MySQL事务隔离级别中一直没有弄清含义的术语,在网上相关资料也未找到一个较为准确的解释.所以,在我的理解中,幻读有一个非常流氓的含义,即在串行化中不会出现但在可重复读会出现的异常情况.
其实在我看来,若知道在相应事务隔离级别下,两个事务在特定执行顺序下会出现什么结果即可,三种错误情况是为了区分四种事务级别而提出的术语,无需深究.
实验分析
未提交读
事务B可以读取到事务A未提交(commit)的数据,导致了脏读。如果事务A回滚了,就会造成数据的不一致。RU是事务隔离级别最低的。
首先设置事务隔离级别为未提交读.
set session transaction isolation level read uncommitted;set global transaction isolation level read uncommitted;
| 事务A | 事务B |
|---|---|
| begin; | |
| begin; | |
| insert into tbl (id) values(1); | |
| select * from tbl; | |
| insert into tbl (id) values(2); | |
| select * from tbl; | |
| update tbl set name=’22’ where id=2; | |
| select * from tbl; | |
| commit; | |
| commit; |
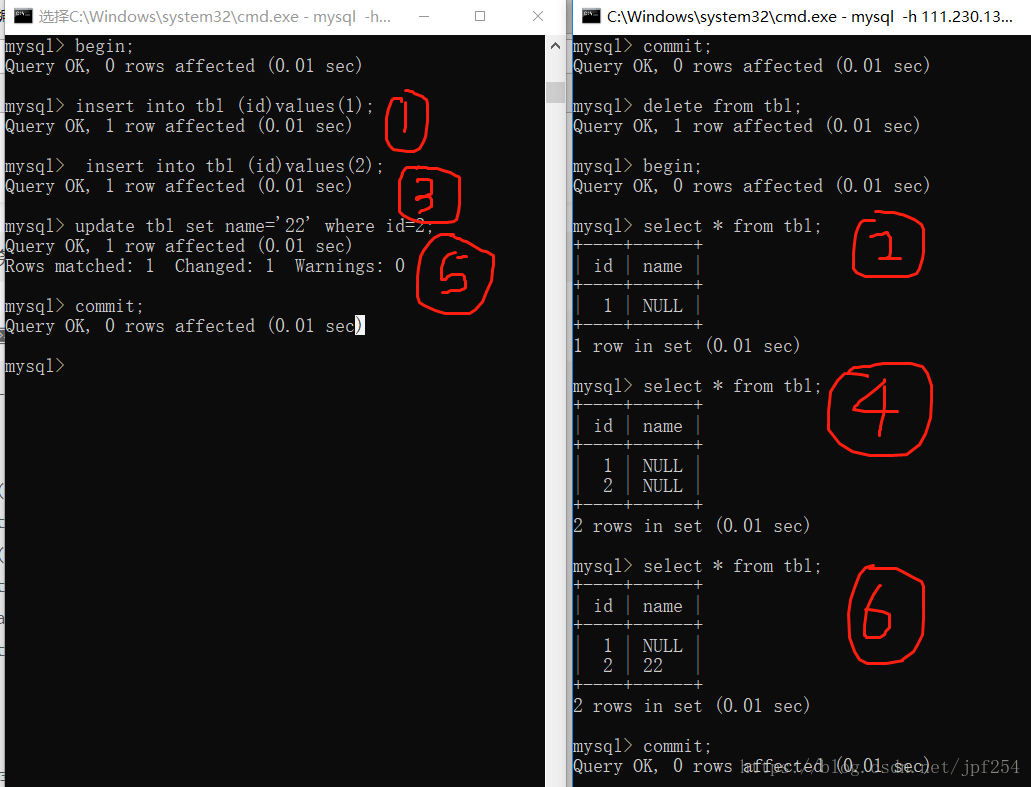
从上图可以看出,事务A(左边)即使没有提交,其执行的两次insert和一次update都可以在事务B中读到,即出现脏读.
提交读
只有事务A提交后,事务B方可看到事务A执行的操作.
首先设置事务隔离级别为提交读.
set session transaction isolation level read committed;set global transaction isolation level read committed;
| 事务A | 事务B |
|---|---|
| begin; | |
| begin; | |
| select * from tbl; | |
| insert into tbl (id) values(3); | |
| select * from tbl; | |
| commit; | |
| select * from tbl; | |
| commit; |
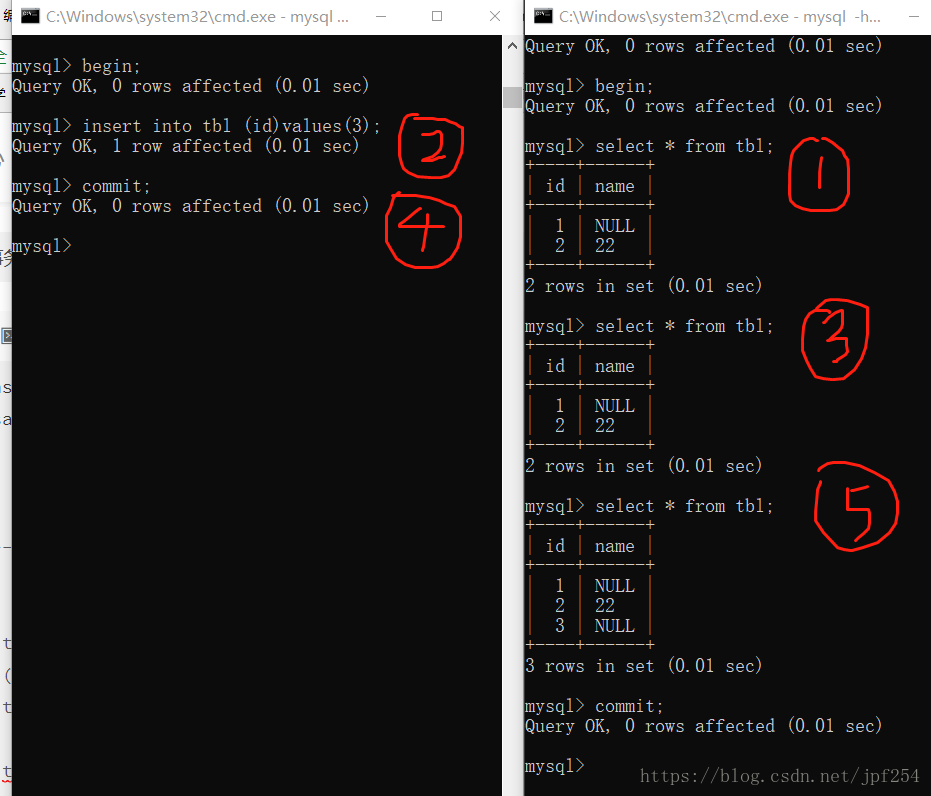
从上图可以看出,即使在事务A(左边)中执行了insert,若事务A没有提交,在事务B中无法读到事务A的insert数据,只有在事务A提交之后,事务B才可以读到事务A的insert数据,即避免了脏读.
虽然提交读避免了脏读,但仍然无法避免不可重复读.
| 事务A | 事务B |
|---|---|
| begin; | |
| select * from tbl; | |
| begin; | |
| insert into tbl (id) values(4); | |
| commit; | |
| select * from tbl; | |
| commit; |
由上图可知,由于事务A提交了,导致事务B可以看到事务A的操作,导致事务B中的两次select * from tbl返回了不一致的数据,即不可重复读.
请思考一个问题,若在第2步执行之后,此时在事务B中无法读到事务A新增的id=3的数据,但,若此时事务B执行insert into tbl (id)values(3);再插入一条id=3的数据,会出现什么情况呢?
可重复读
首先设置事务隔离级别为可重复读.
set session transaction isolation level repeatable read;set global transaction isolation level repeatable read;
| 事务A | 事务B |
|---|---|
| begin; | |
| select * from tbl; | |
| begin; | |
| insert into tbl (id) values(5); | |
| commit; | |
| select * from tbl; | |
| commit; |
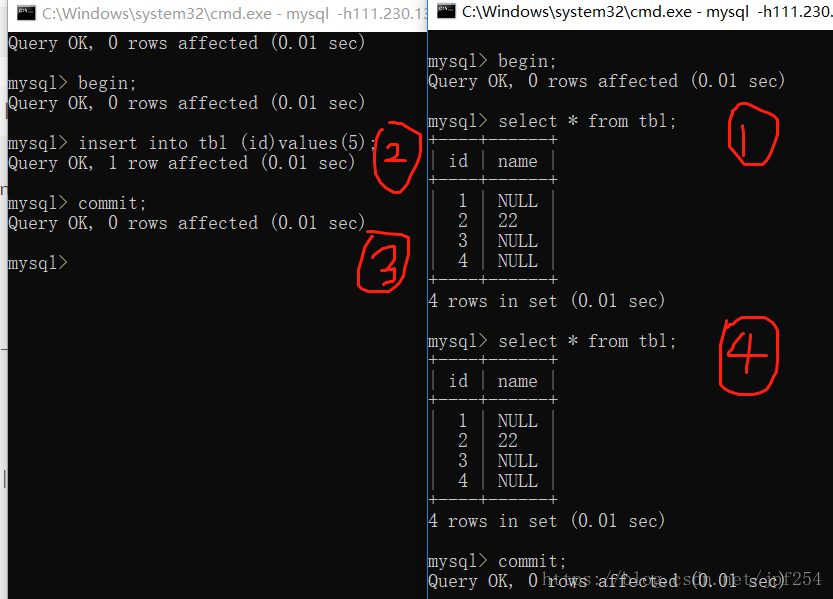
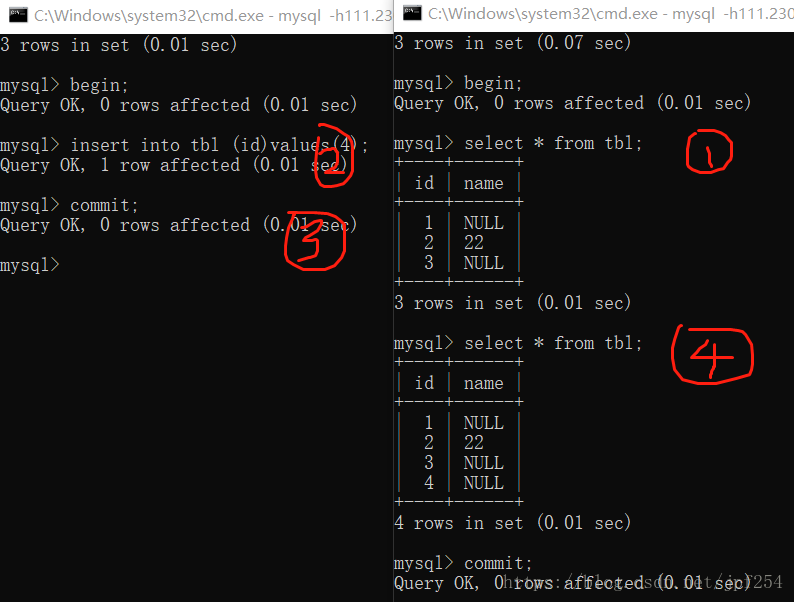
由上图可知,即使事务A提交了,但为了保证在事务B中看到的数据是一致的,第4步返回的数据和第1步是一致的,仍然无法看到事务A插入的新数据,即解决了不可重复读.
思考两个个问题,如果第3步之后,此时在事务B中执行insert into tbl (id)values(5)会出现什么情况?此时事务B是读不到id=5的数据的,能插入成功吗?
若第3步之后在事务B中执行update tbl set name='55' where id=5可以更新成功吗?若更新成功,此时执行select * from tbl会返回id=5的数据吗?
最好的回答是做实验,结果如下: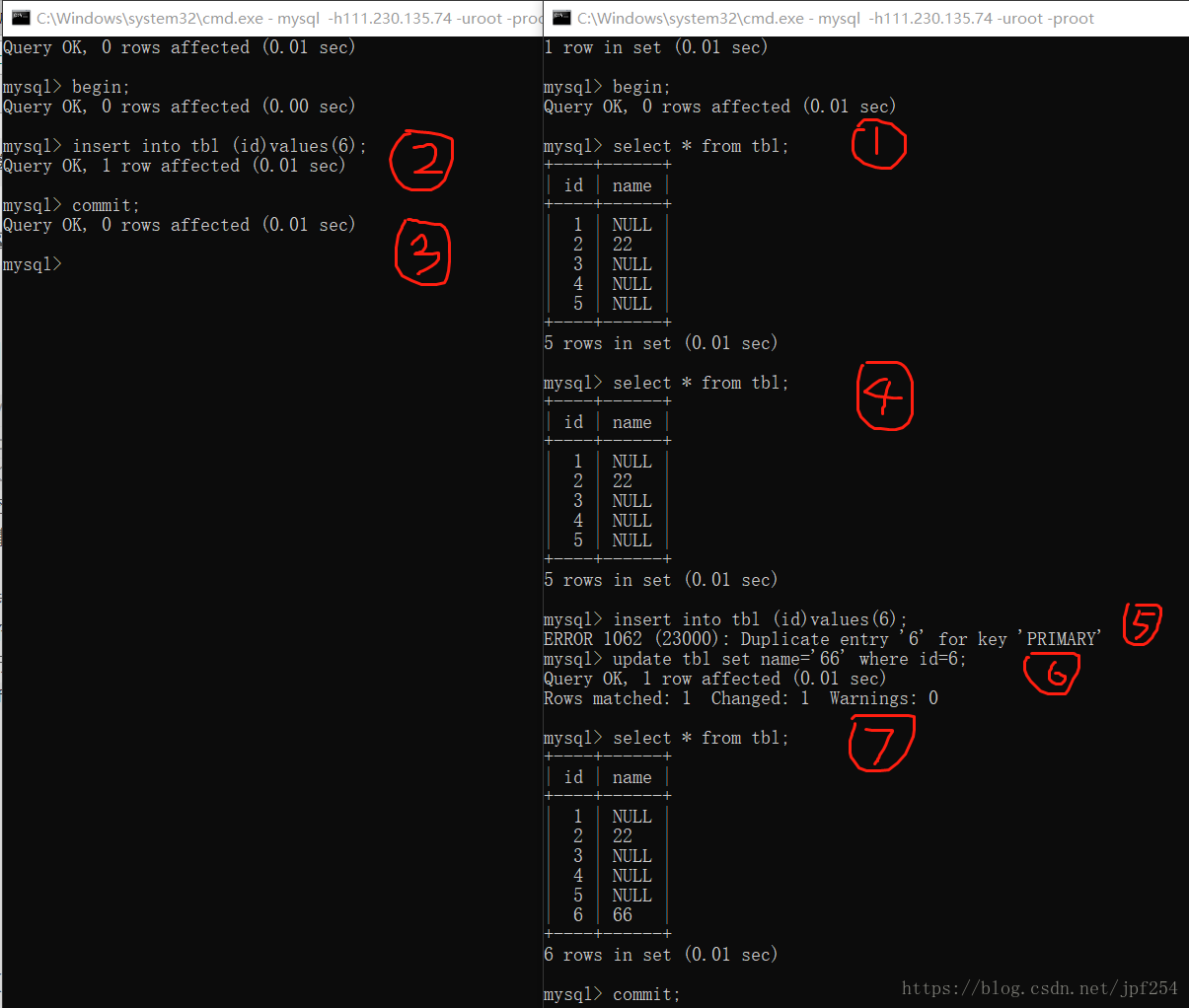
答案显而易见.
(1)虽然事务B无法读取到id=6的数据,但id=6的数据确实存在,因此因为主键冲突插入失败.
(2)update是可以执行成功的,因为事务A已经提交,释放了id=6的数据上的锁,所以事务B可以更新id=6的数据(若事务A没有commit,则update语句因无法获取锁而阻塞).而且更新之后,因为MySQL使用MVCC机制实现事务隔离,此时id=6的数据最高版本号即为事务B,所以事务B可以查看id=6的数据.
备注:由于id=5的数据已存在,实验中插入了id=6的数据,因此问题中问的是id=5的情况,而回答中回答的是id=6的情况.
可串行化
首先设置事务隔离级别为可串行化.
set session transaction isolation level serializable ;set global transaction isolation level serializable ;
可串行化严格使用锁来进行隔离控制,select对数据加S锁,update和insert对数据加X锁.因此在可串行化级别更易发生死锁.
原理
MySQL中使用锁和MVCC(Multi-Version Concurrency Control 多版本并发控制)实现隔离,在此不再深入.
mysql死锁问题分析
轻松理解MYSQL MVCC 实现机制
总结
参考

若有收获,就点个赞吧
0 人点赞
