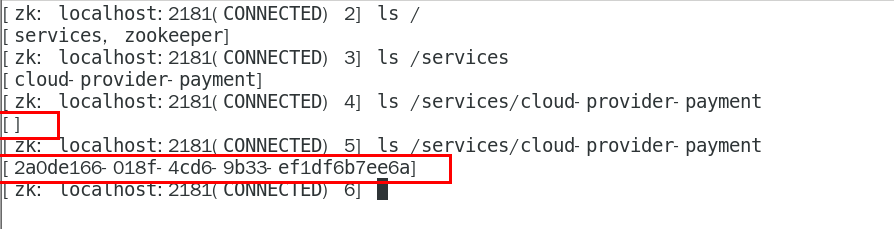
SpringCloud
springcloud是分布式微服务架构一揽子的解决方案,有多种技术的落地
git源码地址
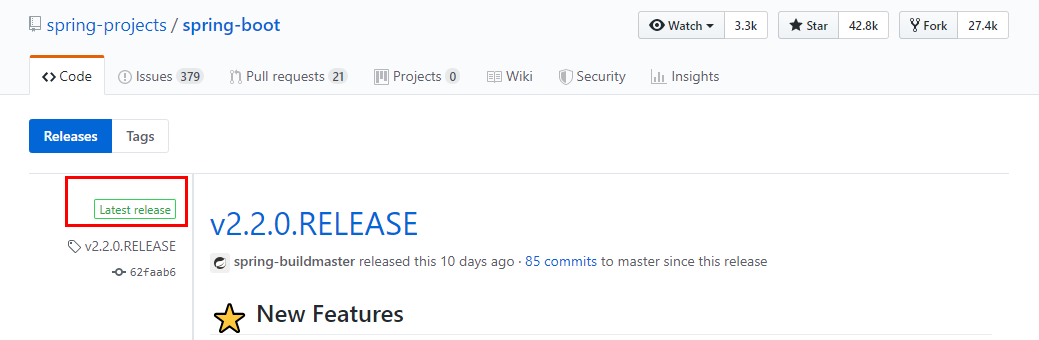
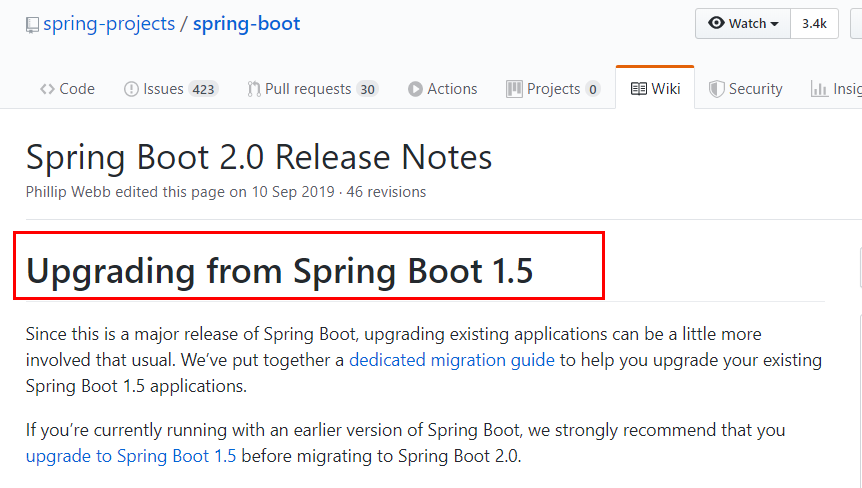
https://github.com/spring-projects/spring-boot/wiki/Spring-Boot-2.0-Release-Notes
通过上面官网发现,Boot官方强烈建议你升级到2.X以上版本
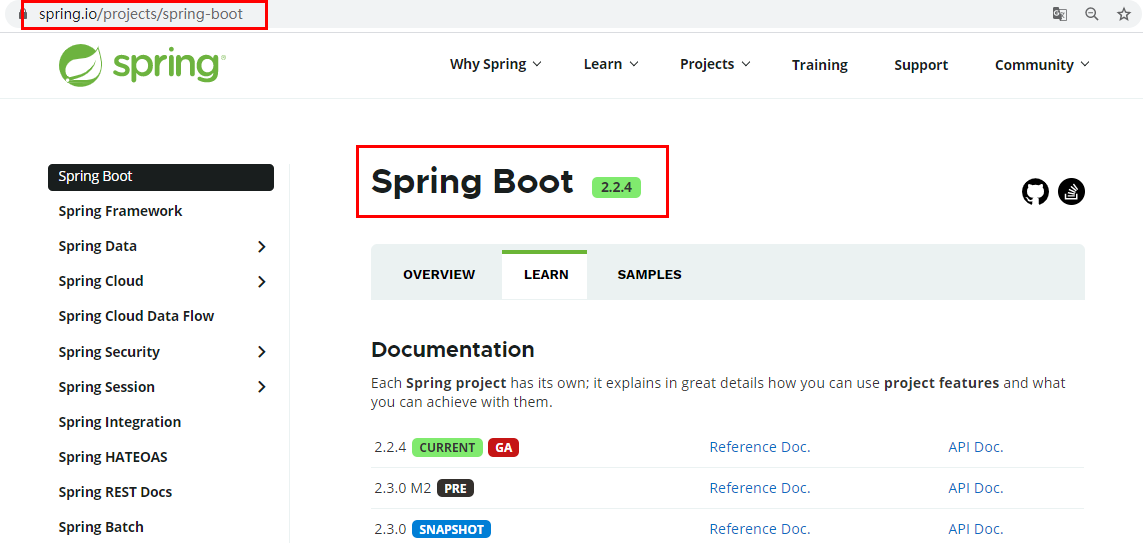
git源码地址 https://github.com/spring-projects/spring-cloud
官网:https://spring.io/projects/spring-cloud
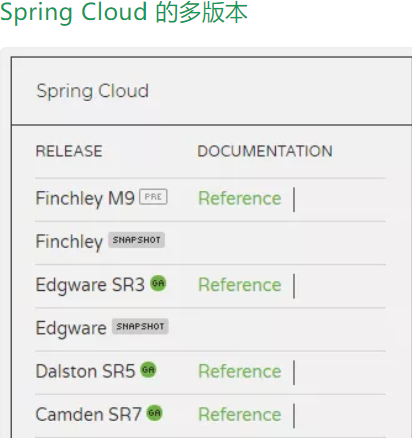
SpringCloud的版本关系
SpringCloud的版本关系Spring Cloud 采用了英国伦敦地铁站的名称来命名,并由地铁站名称字母A-Z依次类推的形式来发布迭代版本SpringCloud是一个由许多子项目组成的综合项目,各子项目有不同的发布节奏。为了管理SpringCloud与各子项目的版本依赖关系,发布了一个清单,其中包括了某个SpringCloud版本对应的子项目版本。为了避免SpringCloud版本号与子项目版本号混淆,SpringCloud版本采用了名称而非版本号的命名,这些版本的名字采用了伦敦地铁站的名字,根据字母表的顺序来对应版本时间顺序。例如Angel是第一个版本, Brixton是第二个版本。当SpringCloud的发布内容积累到临界点或者一个重大BUG被解决后,会发布一个"service releases"版本,简称SRX版本,比如Greenwich.SR2就是SpringCloud发布的Greenwich版本的第2个SRX版本。
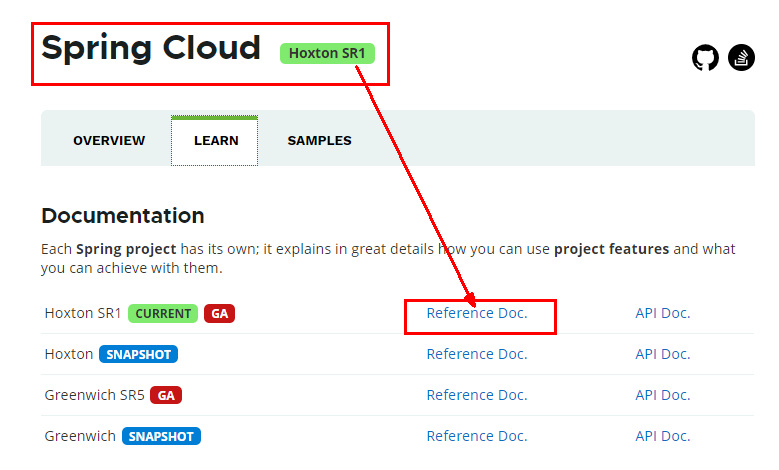
Springcloud和Springboot之间的依赖关系如何看
https://spring.io/projects/spring-cloud#overview
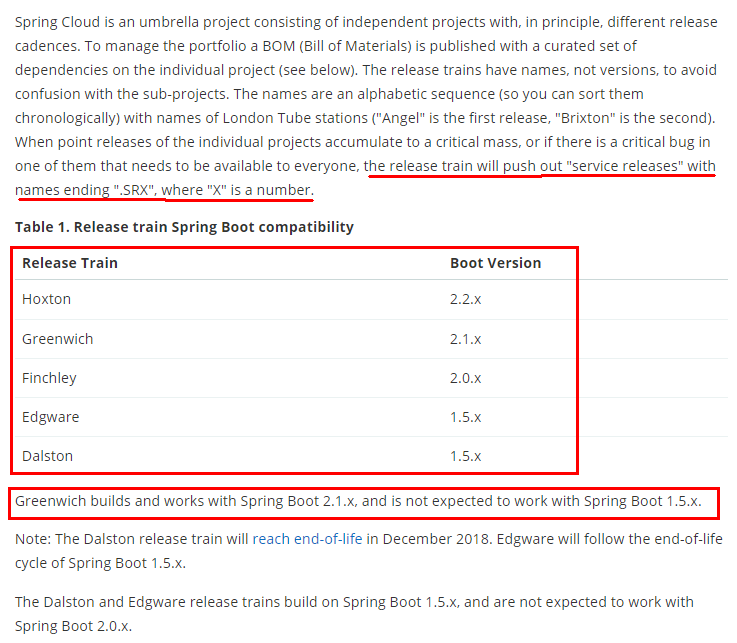
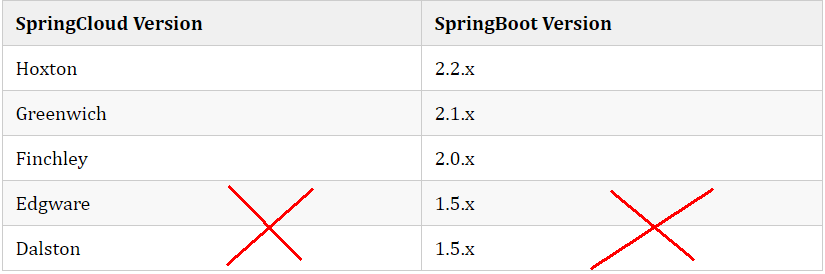
Finchley 是基于 Spring Boot 2.0.x 构建的不再 Boot 1.5.x
Dalston 和 Edgware 是基于 Spring Boot 1.5.x 构建的,不支持 Spring Boot 2.0.x
Camden 构建于 Spring Boot 1.4.x,但依然能支持 Spring Boot 1.5.x
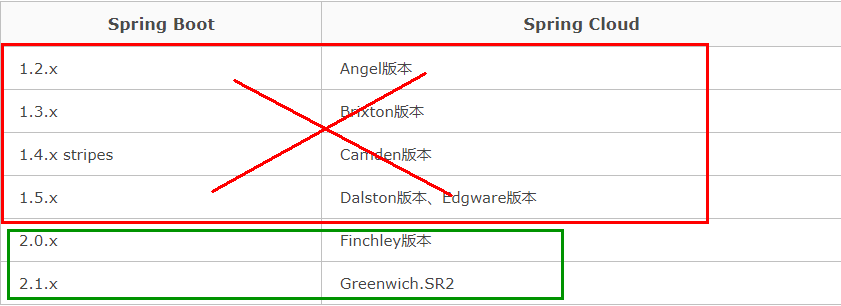
更详细的版本对应查看方法 :https://start.spring.io/actuator/info
查看json串返回结果
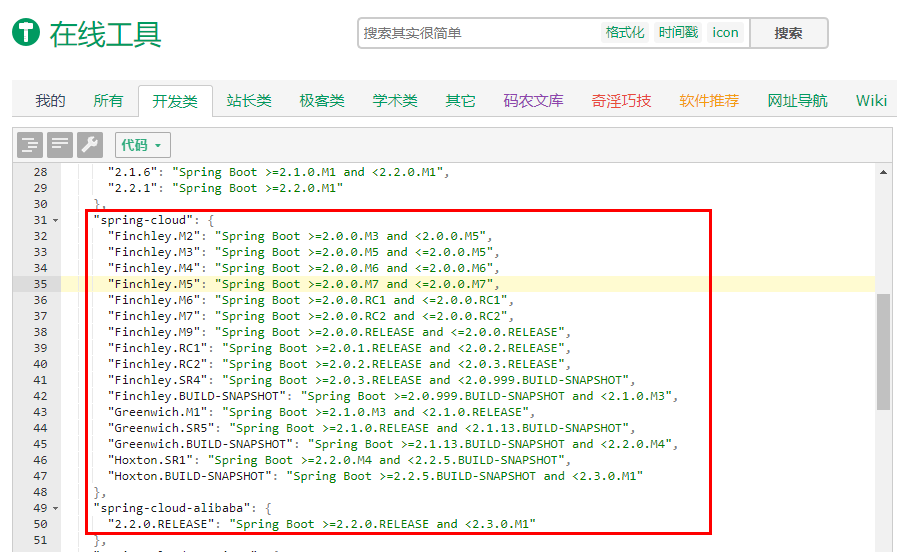
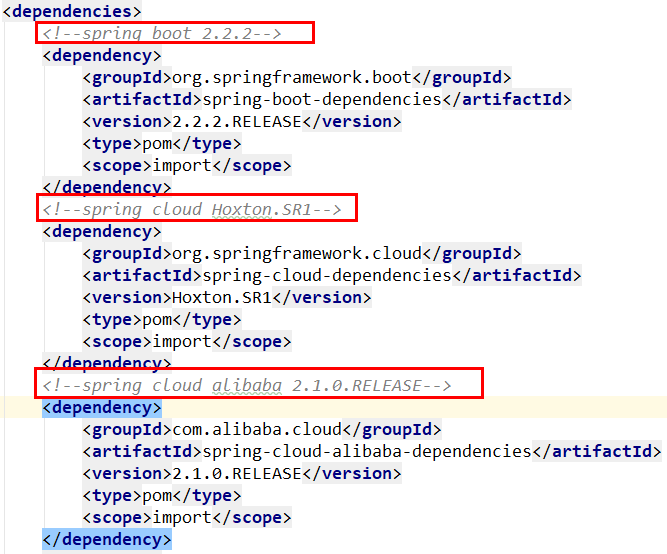
cloud Hoxton.SR1
boot 2.2.2.RELEASE
cloud alibaba 2.1.0.RELEASE
Java Java8
Maven 3.5及以上
Mysql 5.7及以上
只用boot,直接用最新,同时用boot和cloud,需要照顾cloud,由cloud决定boot版本
SpringCloud和SpringBoot版本对应关系
SpringCloud和SpringBoot版本对应关系
Spring Cloud文档: https://cloud.spring.io/spring-cloud-static/Hoxton.SR1/reference/htmlsingle/
Spring Cloud中文文档: https://www.bookstack.cn/read/spring-cloud-docs/docs-index.md
Spring Boot文档: https://docs.spring.io/spring-boot/docs/2.2.2.RELEASE/reference/htmlsingle/
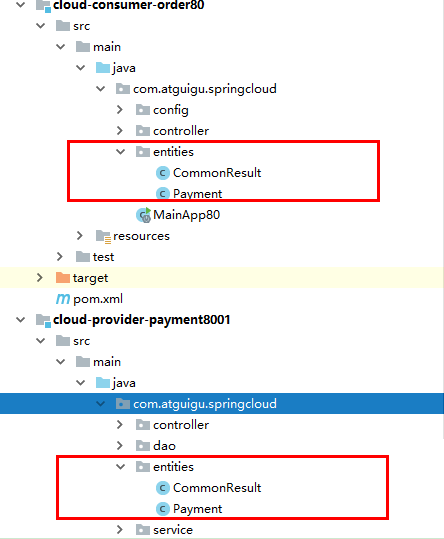
一、工程构建
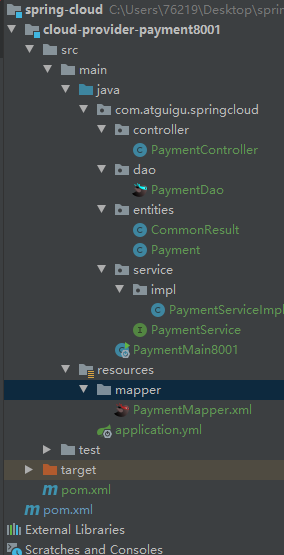
1、cloud-provider-payment8001
微服务提供者支付Module模块
1、new project
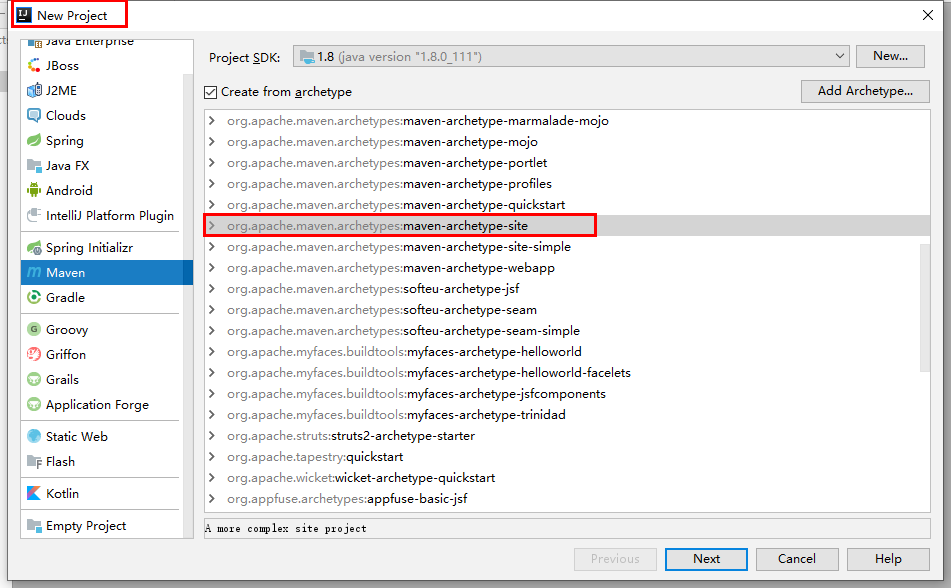
2、聚合总父工程名字
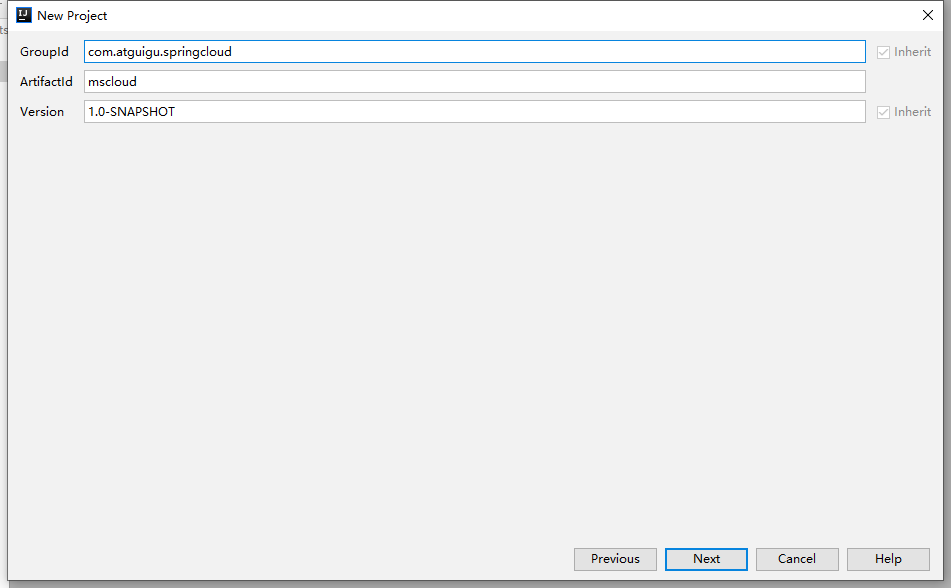
3、Maven选版本
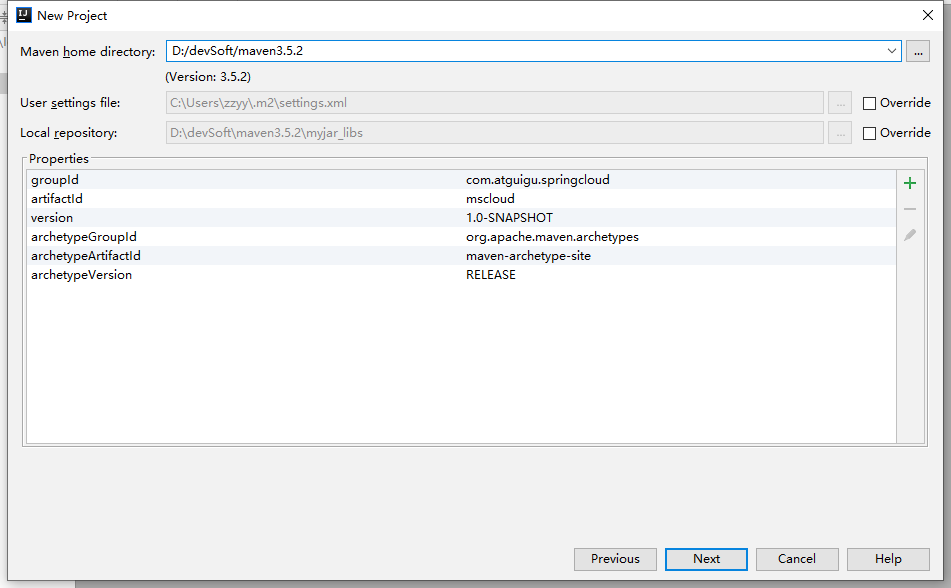
4、工程名字
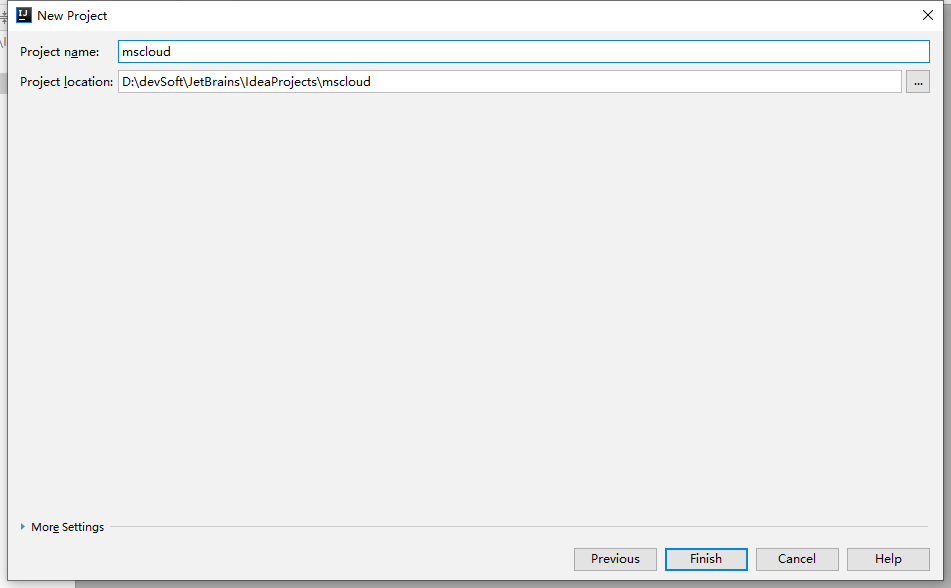
5、字符编码
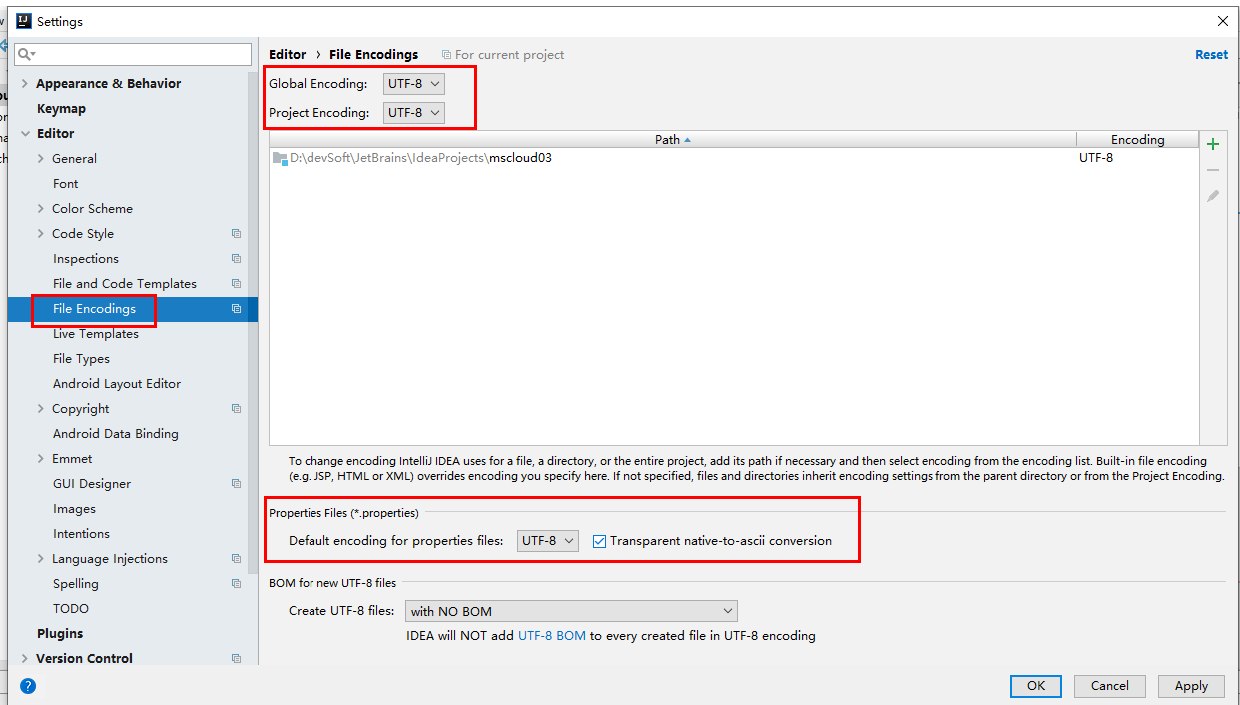
6、注解生效激活
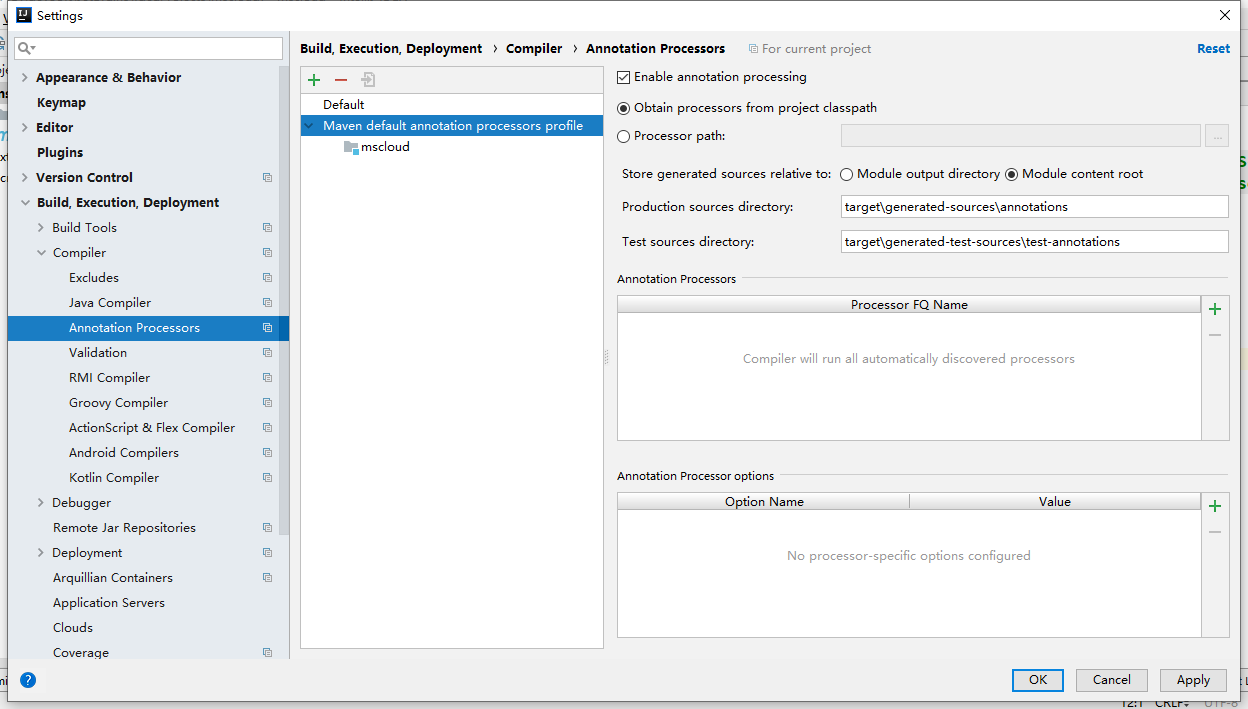
7、java编译版本选8
8、File Type过滤
pom依赖
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>spring-cloud</artifactId><version>1.0-SNAPSHOT</version><!--统一管理jar包版本--><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>12</maven.compiler.source><maven.compiler.target>12</maven.compiler.target><junit.version>4.12</junit.version><lombok.version>1.18.10</lombok.version><log4j.version>1.2.17</log4j.version><mysql.version>8.0.18</mysql.version><druid.version>1.1.16</druid.version><mybatis.spring.boot.version>2.1.1</mybatis.spring.boot.version></properties><!-- 子模块继承之后,提供作用:锁定版本+子modlue不用写groupId和version --><dependencyManagement><dependencies><!--spring boot 2.2.2--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-dependencies</artifactId><version>2.2.2.RELEASE</version><type>pom</type><scope>import</scope></dependency><!--spring cloud Hoxton.SR1--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-dependencies</artifactId><version>Hoxton.SR1</version><type>pom</type><scope>import</scope></dependency><!--spring cloud alibaba 2.1.0.RELEASE--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-alibaba-dependencies</artifactId><version>2.1.0.RELEASE</version><type>pom</type><scope>import</scope></dependency><!-- mysql--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>${mysql.version}</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>${druid.version}</version></dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>${mybatis.spring.boot.version}</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>${junit.version}</version></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>${log4j.version}</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>${lombok.version}</version><optional>true</optional></dependency></dependencies></dependencyManagement><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><fork>true</fork><addResources>true</addResources></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.1</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin></plugins></build></project>
cloud-provider-payment8001-pom
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><artifactId>spring-cloud</artifactId><groupId>org.example</groupId><version>1.0-SNAPSHOT</version></parent><modelVersion>4.0.0</modelVersion><artifactId>cloud-provider-payment8001</artifactId><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.1.10</version></dependency><!--mysql-connector-java--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><!--jdbc--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies></project>
微服务模块构建步骤:
1、建module2、改pom3、写yml4、主启动5、业务类
application.yml
server:port: 8001spring:application:name: cloud-payment-servicedatasource:type: com.alibaba.druid.pool.DruidDataSource # 当前数据源操作类型driver-class-name: com.mysql.cj.jdbc.Driver # mysql驱动包 com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/crimsdbs?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=UTCusername: rootpassword: abc123mybatis:mapperLocations: classpath:mapper/*.xmltype-aliases-package: com.atguigu.springcloud.entities # 所有Entity别名类所在包
启动类:
@SpringBootApplicationpublic class PaymentMain8001 {public static void main(String[] args) {SpringApplication.run(PaymentMain8001.class,args);}}
2、简单payment的工程的创建
目录结构:
创数据库:
create table `payment`(`id` bigint(20) not null auto_increment comment 'ID',`serial` varchar(200) default '',PRIMARY key (`id`))engine=INNODB auto_increment=1 default charset=utf8
dao:
@Mapperpublic interface PaymentDao {public int create(Payment payment);public Payment getPaymentById(@Param("id") Long id);}
entities:
- 实体类
@Data@AllArgsConstructor@NoArgsConstructorpublic class Payment implements Serializable {private Long id;private String serial;}
- result:
@Data@AllArgsConstructor@NoArgsConstructorpublic class CommonResult<T> {private Integer code;private String message;private T data;public CommonResult(Integer code,String message){this(code,message,null);}}
mapper:
<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" ><mapper namespace="com.atguigu.springcloud.dao.PaymentDao"><resultMap id="BaseResultMap" type="com.atguigu.springcloud.entities.Payment"><id column="id" property="id" jdbcType="BIGINT"/><result column="serial" property="serial" jdbcType="VARCHAR"/></resultMap><insert id="create" parameterType="Payment" useGeneratedKeys="true" keyProperty="id">INSERT INTO payment(SERIAL) VALUES(#{serial});</insert><select id="getPaymentById" parameterType="Long" resultMap="BaseResultMap" >SELECT * FROM payment WHERE id=#{id};</select></mapper>
service:
public interface PaymentService {public int create(Payment payment);public Payment getPaymentById(@Param("id") Long id);}
impl:
@Servicepublic class PaymentServiceImpl implements PaymentService {@Resourceprivate PaymentDao paymentDao;@Overridepublic int create(Payment payment) {return paymentDao.create(payment);}@Overridepublic Payment getPaymentById(Long id) {return paymentDao.getPaymentById(id);}}
controller:
@RestController@Slf4j@RequestMapping("/payment")public class PaymentController {@Autowiredprivate PaymentService paymentService;@PostMapping("/save")public CommonResult<Object> create(Payment payment){int result = paymentService.create(payment);log.info("插入成功{}",result);if (result > 0){return new CommonResult(0,"插入数据库成功",result);}else {return new CommonResult(1,"插入数据库失败",null);}}@GetMapping("/get/{id}")public CommonResult<Object> getById(@PathVariable("id") Long id){Payment paymentById = paymentService.getPaymentById(id);log.info("插入成功{}",paymentById);if (paymentById != null){return new CommonResult(0,"插入数据库成功",paymentById);}else {return new CommonResult(1,"插入数据库失败",null);}}}
测试接口调用:
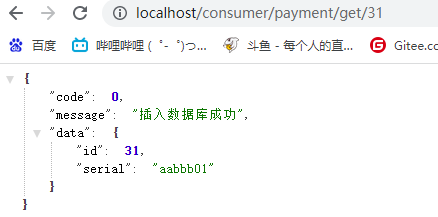
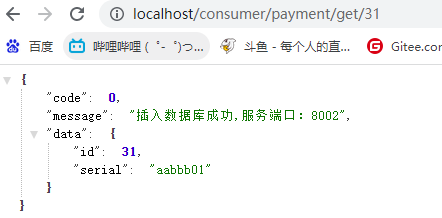
http://localhost:8001/payment/get/31
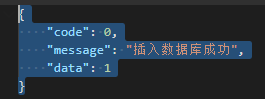
{"code": 0,"message": "插入数据库成功","data": {"id": 31,"serial": "aabbb01"}}
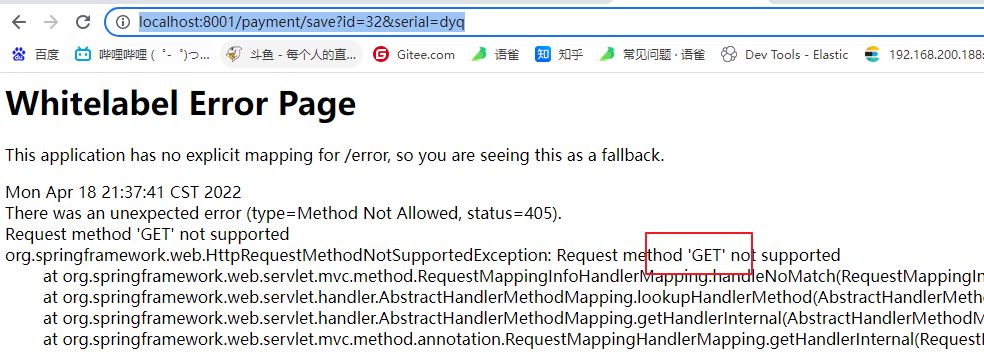
chrome浏览器默认get请求,因此要用接口测试工具
3、热部署Devtools
1、Adding devtools to your project
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency>
2、Adding plugin to your pom.xml
<build><finalName>你自己的工程名字</finalName><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><fork>true</fork><addResources>true</addResources></configuration></plugin></plugins></build>
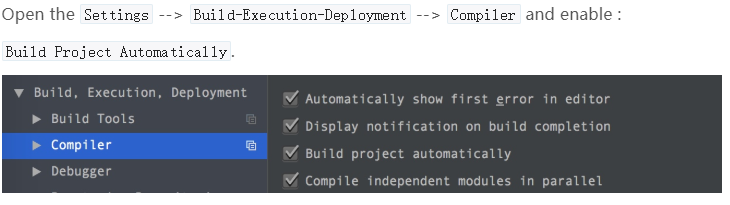
3、Enabling automatic build
4、Update the value of
重启idea
3、cloud-consumer-order80
微服务消费者订单Module模块
pom
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><artifactId>spring-cloud</artifactId><groupId>org.example</groupId><version>1.0-SNAPSHOT</version></parent><modelVersion>4.0.0</modelVersion><artifactId>cloud-consumer-order80</artifactId><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies></project>
yml
server:port: 80
目录结构
entities略
RestTemplate
RestTemplate提供了多种便捷访问远程Http服务的方法,是一种简单便捷的访问restful服务模板类,是Spring提供的用于访问Rest服务的客户端模板工具集
官网地址
使用restTemplate访问restful接口非常的简单粗暴无脑。(url, requestMap, ResponseBean.class)这三个参数分别代表REST请求地址、请求参数、HTTP响应转换被转换成的对象类型。
配置类:
@Configurationpublic class ApplicationContextConfig {@Beanpublic RestTemplate getRestTemplate(){return new RestTemplate();}}//applicationcontext.xml <bean id="" class="">
需要entities目录的两个类,CommonResult、Payment
controller:
@RestController@Slf4jpublic class OrderController {public static final String PAYMENT_URL = "http://localhost:8001";@Resourceprivate RestTemplate restTemplate;@GetMapping("/consumer/payment/create")public CommonResult<Payment> create(Payment payment){return restTemplate.postForObject(PAYMENT_URL + "/payment/create",payment,CommonResult.class);}@GetMapping("/consumer/payment/get/{id}")public CommonResult<Payment> getPayment(@PathVariable("id")Long id){return restTemplate.getForObject(PAYMENT_URL + "/payment/get/"+id,CommonResult.class);}}
测试:get
测试:save
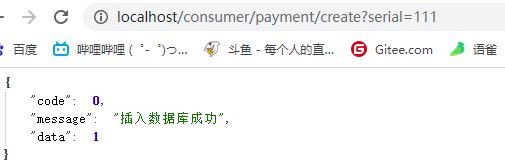
虽然请求成功,但是数据未携带过去,数据库存的是null
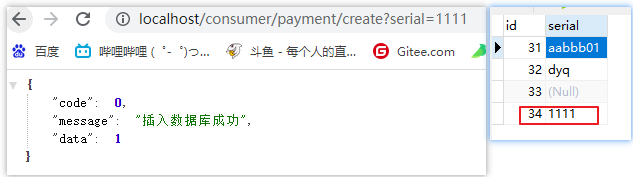
8001save请求未加@RequestBody才能生效
4、工程重构
系统中有重复部分,重构
公共模块:cloud-api-commons —> 删除各自有的entities,导入依赖
clean install检查是否依赖引入正确 —-> 测试接口调用
二、Eureka服务注册与发现
什么是服务治理
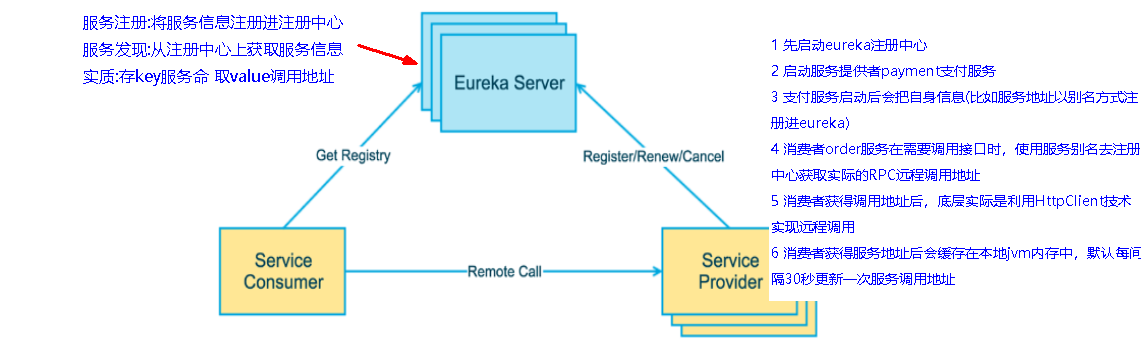
SpringCloud 封装了 Netflix 公司开发的 Eureka 模块来实现服务治理在传统的rpc远程调用框架中,管理每个服务与服务之间依赖关系比较复杂,管理比较复杂,所以需要使用服务治理,管理服务于服务之间依赖关系,可以实现服务调用、负载均衡、容错等,实现服务发现与注册。
什么是服务注册与发现
Eureka采用了CS的设计架构,Eureka Server 作为服务注册功能的服务器,它是服务注册中心。而系统中的其他微服务,使用 Eureka的客户端连接到 Eureka Server并维持心跳连接。这样系统的维护人员就可以通过 Eureka Server 来监控系统中各个微服务是否正常运行。在服务注册与发现中,有一个注册中心。当服务器启动的时候,会把当前自己服务器的信息 比如 服务地址通讯地址等以别名方式注册到注册中心上。另一方(消费者|服务提供者),以该别名的方式去注册中心上获取到实际的服务通讯地址,然后再实现本地RPC调用RPC远程调用框架核心设计思想:在于注册中心,因为使用注册中心管理每个服务与服务之间的一个依赖关系(服务治理概念)。在任何rpc远程框架中,都会有一个注册中心(存放服务地址相关信息(接口地址))
下左图是Eureka系统架构,右图是Dubbo的架构,请对比
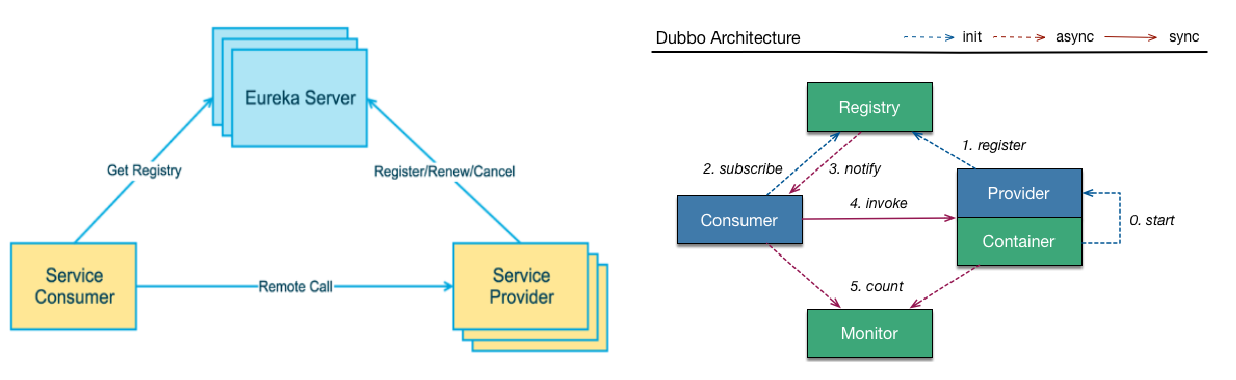
Eureka包含两个组件:Eureka Server 和 Eureka Client
Eureka Server提供服务注册服务各个微服务节点通过配置启动后,会在EurekaServer中进行注册,这样EurekaServer中的服务注册表中将会存储所有可用服务节点的信息,服务节点的信息可以在界面中直观看到。EurekaClient通过注册中心进行访问是一个Java客户端,用于简化Eureka Server的交互,客户端同时也具备一个内置的、使用轮询(round-robin)负载算法的负载均衡器。在应用启动后,将会向Eureka Server发送心跳(默认周期为30秒)。如果Eureka Server在多个心跳周期内没有接收到某个节点的心跳,EurekaServer将会从服务注册表中把这个服务节点移除(默认90秒)
服务端7001
module: cloud-eureka-server7001
pom:
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><artifactId>spring-cloud</artifactId><groupId>org.example</groupId><version>1.0-SNAPSHOT</version></parent><modelVersion>4.0.0</modelVersion><artifactId>cloud-eureka-server7001</artifactId><dependencies><!--eureka-server--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-server</artifactId></dependency><!-- 引入自己定义的api通用包,可以使用Payment支付Entity --><dependency><groupId>org.example</groupId><artifactId>cloud-api-commons</artifactId><version>1.0-SNAPSHOT</version><scope>compile</scope></dependency><!--boot web actuator--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><!--一般通用配置--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId></dependency></dependencies></project>
yml:
server:port: 7001eureka:instance:hostname: localhost #eureka服务端的实例名称client:#false表示不向注册中心注册自己。register-with-eureka: false#false表示自己端就是注册中心,我的职责就是维护服务实例,并不需要去检索服务fetch-registry: falseservice-url:#设置与Eureka Server交互的地址查询服务和注册服务都需要依赖这个地址。defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
启动类:
@SpringBootApplication@EnableEurekaServerpublic class EurekaMain7001{public static void main(String[] args){SpringApplication.run(EurekaMain7001.class,args);}}
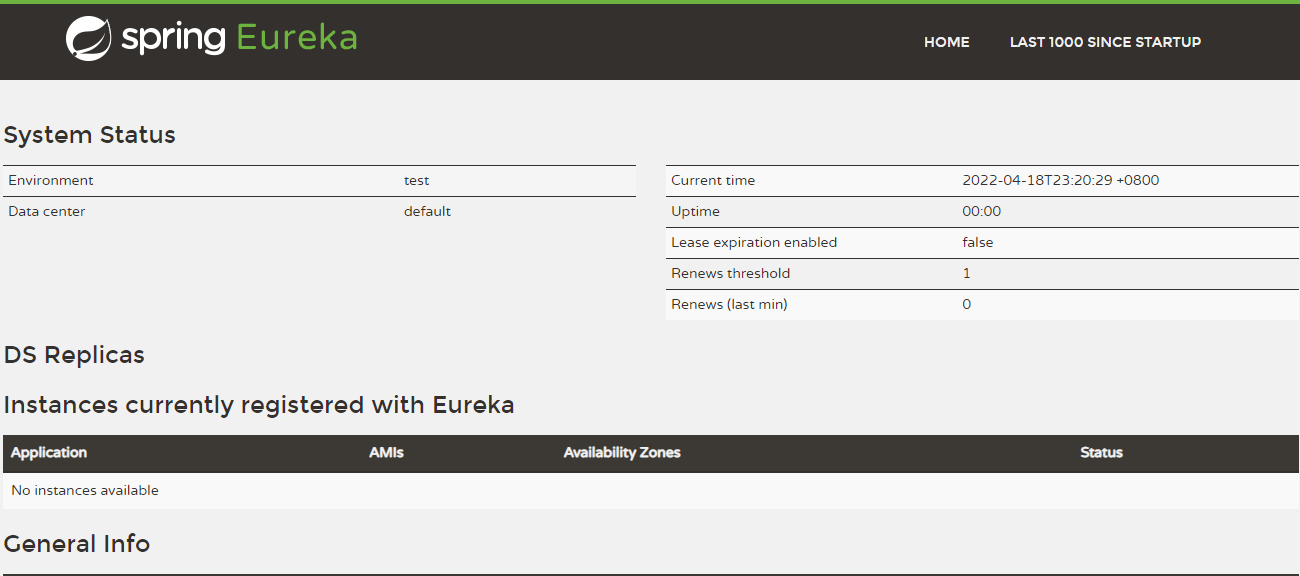
单机服务端完成。。。
X和2.X的对比说明
以前的老版本(当前使用2018)<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-eureka</artifactId></dependency>现在新版本(当前使用2020.2)<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-server</artifactId></dependency>
客户端8001
使用刚创建的 cloud-provider-payment8001===>服务提供者provider
改pom文件
<!--eureka-client--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency>
改yml
eureka:client:#表示是否将自己注册进EurekaServer默认为true。register-with-eureka: true#是否从EurekaServer抓取已有的注册信息,默认为true。单节点无所谓,集群必须设置为true才能配合ribbon使用负载均衡fetchRegistry: trueservice-url:defaultZone: http://localhost:7001/eureka
启动类
@SpringBootApplication@EnableEurekaClientpublic class PaymentMain8001{public static void main(String[] args){SpringApplication.run(PaymentMain8001.class,args);}}
先要启动EurekaServer ===> 测试: http://localhost:7001/
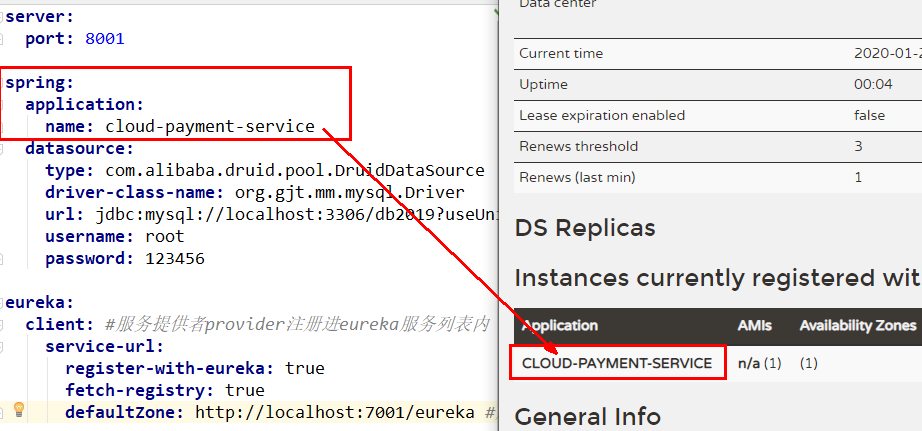
yml配置文件的spring.application.name 与之对应
自我保护机制。
使用刚创建的cloud-consumer-order80作为===>服务消费者consumer
改pom
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency>
yml加
spring:application:name: cloud-order-serviceeureka:client:#表示是否将自己注册进EurekaServer默认为true。register-with-eureka: true#是否从EurekaServer抓取已有的注册信息,默认为true。单节点无所谓,集群必须设置为true才能配合ribbon使用负载均衡fetchRegistry: trueservice-url:defaultZone: http://localhost:7001/eureka
启动类上加@EnableEurekaClient注解
@EnableEurekaClient
先要启动EurekaServer,7001服务,再要启动服务提供者provider,8001服务
eureka服务器

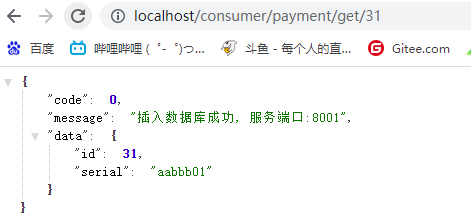
测试接口调用: http://localhost/consumer/payment/get/31
可能产生的 bug:

Eureka集群原理说明
问题:微服务RPC远程服务调用最核心的是什么
高可用,试想你的注册中心只有一个only one, 它出故障了那就呵呵( ̄▽ ̄)”了,会导致整个为服务环境不可用,所以 ; 解决办法:搭建Eureka注册中心集群 ,实现负载均衡+故障容错
EurekaServer集群环境构建步骤
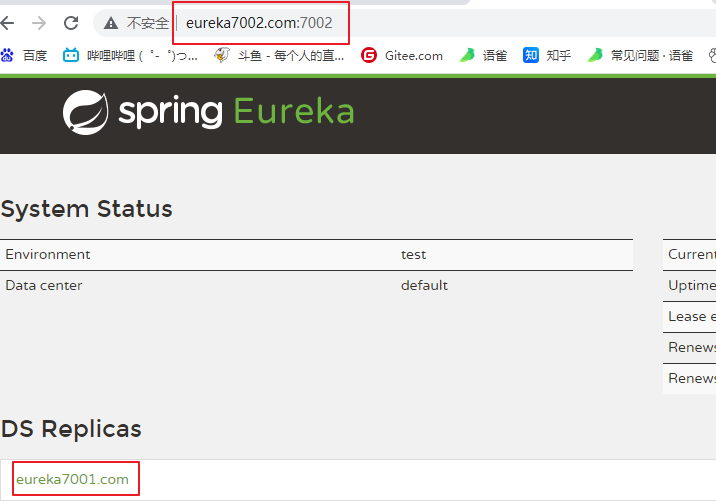
参考cloud-eureka-server7001,新建cloud-eureka-server7002
改POM
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><artifactId>mscloud03</artifactId><groupId>com.atguigu.springcloud</groupId><version>1.0-SNAPSHOT</version></parent><modelVersion>4.0.0</modelVersion><artifactId>cloud-eureka-server7002</artifactId><dependencies><!--eureka-server--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-server</artifactId></dependency><!-- 引入自己定义的api通用包,可以使用Payment支付Entity --><dependency><groupId>com.atguigu.springcloud</groupId><artifactId>cloud-api-commons</artifactId><version>${project.version}</version></dependency><!--boot web actuator--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><!--一般通用配置--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId></dependency></dependencies></project>
修改映射配置
找到C:\Windows\System32\drivers\etc路径下的hosts文件
修改映射配置添加进hosts文件
127.0.0.1 eureka7001.com
127.0.0.1 eureka7002.com
写YML(以前单机)
server:port: 7001eureka:instance:hostname: localhost #eureka服务端的实例名称client:#false表示不向注册中心注册自己。register-with-eureka: false#false表示自己端就是注册中心,我的职责就是维护服务实例,并不需要去检索服务fetch-registry: falseservice-url:#设置与Eureka Server交互的地址查询服务和注册服务都需要依赖这个地址。defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
7001
server:port: 7001eureka:instance:hostname: eureka7001.com #eureka服务端的实例名称client:register-with-eureka: false #false表示不向注册中心注册自己。fetch-registry: false #false表示自己端就是注册中心,我的职责就是维护服务实例,并不需要去检索服务service-url:defaultZone: http://eureka7002.com:7002/eureka/
7002
server:port: 7002eureka:instance:hostname: eureka7002.com #eureka服务端的实例名称client:register-with-eureka: false #false表示不向注册中心注册自己。fetch-registry: false #false表示自己端就是注册中心,我的职责就是维护服务实例,并不需要去检索服务service-url:defaultZone: http://eureka7001.com:7001/eureka/
主启动
@SpringBootApplication@EnableEurekaServerpublic class EurekaMain7002{public static void main(String[] args){SpringApplication.run(EurekaMain7002.class,args);}}
相互注册,相互守望
将支付服务8001微服务发布到上面2台Eureka集群配置中
server:port: 8001spring:application:name: cloud-payment-servicedatasource:type: com.alibaba.druid.pool.DruidDataSource # 当前数据源操作类型driver-class-name: org.gjt.mm.mysql.Driver # mysql驱动包url: jdbc:mysql://localhost:3306/db2019?useUnicode=true&characterEncoding=utf-8&useSSL=falseusername: rootpassword: 123456eureka:client:#表示是否将自己注册进EurekaServer默认为true。register-with-eureka: true#是否从EurekaServer抓取已有的注册信息,默认为true。单节点无所谓,集群必须设置为true才能配合ribbon使用负载均衡fetchRegistry: trueservice-url:#defaultZone: http://localhost:7001/eurekadefaultZone: http://eureka7001.com:7001/eureka,http://eureka7002.com:7002/eureka # 集群版mybatis:mapperLocations: classpath:mapper/*.xmltype-aliases-package: com.atguigu.springcloud.entities # 所有Entity别名类所在包
将订单服务80微服务发布到上面2台Eureka集群配置中
server:port: 80spring:application:name: cloud-order-serviceeureka:client:#表示是否将自己注册进EurekaServer默认为true。register-with-eureka: true#是否从EurekaServer抓取已有的注册信息,默认为true。单节点无所谓,集群必须设置为true才能配合ribbon使用负载均衡fetchRegistry: trueservice-url:#defaultZone: http://localhost:7001/eurekadefaultZone: http://eureka7001.com:7001/eureka,http://eureka7002.com:7002/eureka # 集群版
测试01
先要启动EurekaServer,7001/7002服务再要启动服务提供者provider,8001再要启动消费者,80http://localhost/consumer/payment/get/31
支付服务提供者8001集群环境构建
参考cloud-provider-payment8001新建cloud-provider-payment8002
pom
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><artifactId>spring-cloud</artifactId><groupId>org.example</groupId><version>1.0-SNAPSHOT</version></parent><modelVersion>4.0.0</modelVersion><artifactId>cloud-provider-payment8002</artifactId><dependencies><!--eureka-client--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.1.10</version></dependency><!--mysql-connector-java--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><!--jdbc--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><!-- 热部署--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><!-- 公共模块--><dependency><groupId>org.example</groupId><artifactId>cloud-api-commons</artifactId><version>1.0-SNAPSHOT</version><scope>compile</scope></dependency><dependency><groupId>org.example</groupId><artifactId>cloud-provider-payment8001</artifactId><version>1.0-SNAPSHOT</version><scope>compile</scope></dependency></dependencies></project>
server:port: 8002spring:application:name: cloud-payment-servicedatasource:type: com.alibaba.druid.pool.DruidDataSource # 当前数据源操作类型driver-class-name: org.gjt.mm.mysql.Driver # mysql驱动包url: jdbc:mysql://localhost:3306/db2019?useUnicode=true&characterEncoding=utf-8&useSSL=falseusername: rootpassword: 123456eureka:client:#表示是否将自己注册进EurekaServer默认为true。register-with-eureka: true#是否从EurekaServer抓取已有的注册信息,默认为true。单节点无所谓,集群必须设置为true才能配合ribbon使用负载均衡fetchRegistry: trueservice-url:defaultZone: http://eureka7001.com:7001/eureka,http://eureka7002.com:7002/eureka # 集群版#defaultZone: http://localhost:7001/eureka # 单机版mybatis:mapperLocations: classpath:mapper/*.xmltype-aliases-package: com.atguigu.springcloud.entities # 所有Entity别名类所在包
启动类
@SpringBootApplication@EnableEurekaClientpublic class PaymentMain8002{public static void main(String[] args){SpringApplication.run(PaymentMain8002.class,args);}}
直接从8001粘
修改8001/8002的Controller
@Value("${server.port}")private String serverPort;
在return new CommonResult上拼接个serverPort用以区分
负载均衡
订单服务访问地址不能写死
使用@LoadBalanced注解赋予RestTemplate负载均衡的能力
//public static final String PAYMENT_SRV = "http://localhost:8001";// 通过在eureka上注册过的微服务名称调用public static final String PAYMENT_SRV = "http://CLOUD-PAYMENT-SERVICE";
RestTemplate ApplicationContextBean
@Configurationpublic class ApplicationContextConfig {@Bean@LoadBalancedpublic RestTemplate getRestTemplate(){return new RestTemplate();}}
两次请求不同服务,轮询
Ribbon和Eureka整合后Consumer可以直接调用服务而不用再关心地址和端口号,且该服务还有负载功能了。
actuator微服务信息完善
主机名称:服务名称修改
含有主机名称:
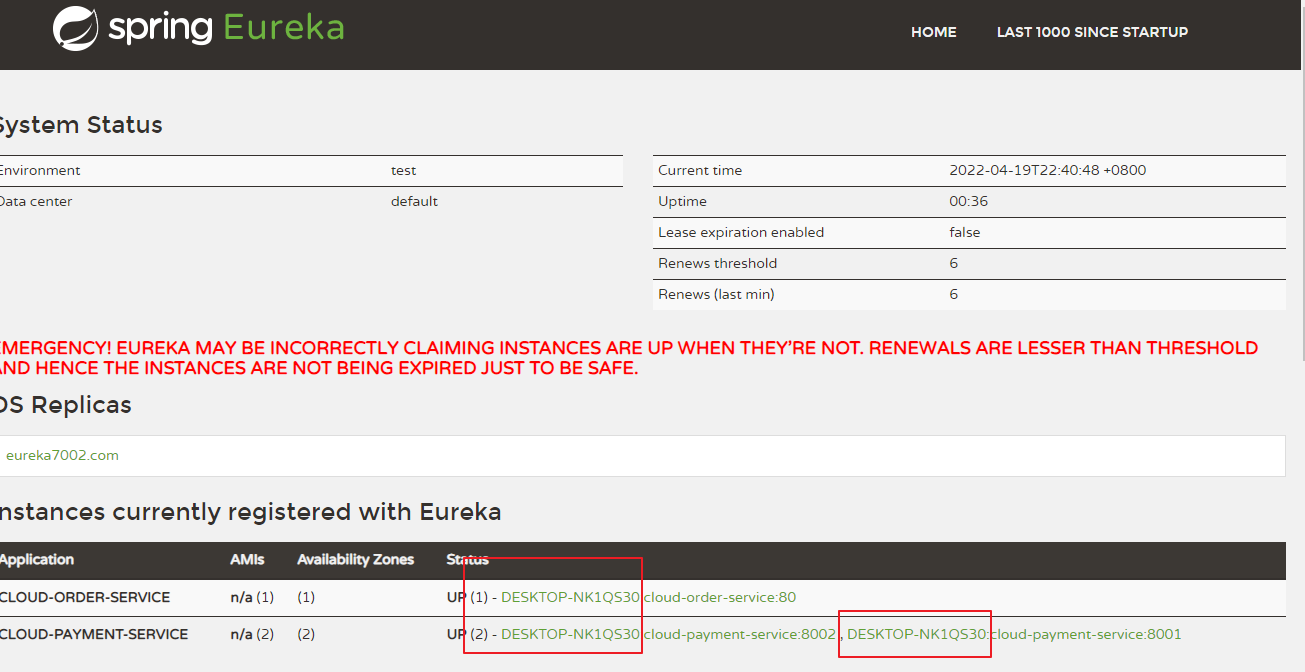
修改cloud-provider-payment8001 yml文件
eureka:client:#表示是否将自己注册进EurekaServer默认为true。register-with-eureka: true#是否从EurekaServer抓取已有的注册信息,默认为true。单节点无所谓,集群必须设置为true才能配合ribbon使用负载均衡fetchRegistry: trueservice-url:defaultZone: http://eureka7001.com:7001/eureka,http://eureka7002.com:7002/eureka # 集群版#defaultZone: http://localhost:7001/eureka # 单机版instance:instance-id: payment8001
加instance.instance-id:
访问信息有IP信息提示:
instance:instance-id: payment8001prefer-ip-address: true #访问路径可以显示IP地址

服务发现Discovery
对于注册进eureka里面的微服务,可以通过服务发现来获得该服务的信息
修改cloud-provider-payment8001的Controller
public class PaymentController{@Autowiredprivate DiscoveryClient discoveryClient;@GetMapping(value = "/payment/discovery")public Object discovery(){List<String> services = discoveryClient.getServices();for (String element : services) {System.out.println(element);}List<ServiceInstance> instances = discoveryClient.getInstances("CLOUD-PAYMENT-SERVICE");for (ServiceInstance element : instances) {System.out.println(element.getServiceId() + "\t" + element.getHost() + "\t" + element.getPort() + "\t"+ element.getUri());}return this.discoveryClient;}}
8001主启动类
@EnableDiscoveryClient //服务发现
自测:
先要启动EurekaServer再启动8001主启动类,需要稍等一会儿http://localhost:8001/payment/discovery
Eureka自我保护机制
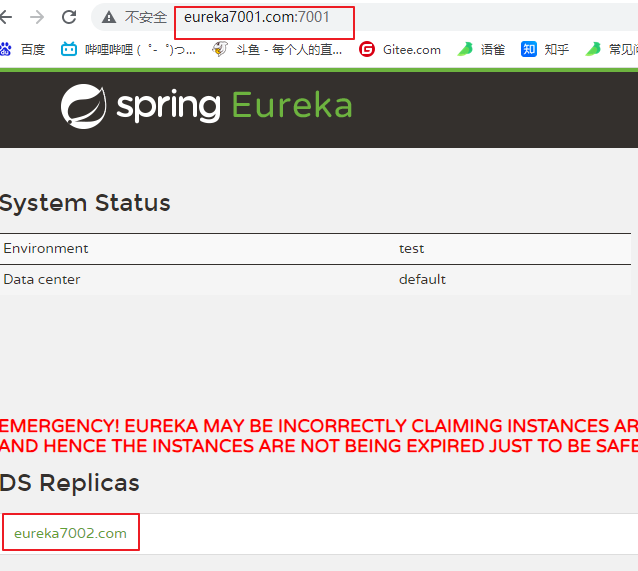
概述保护模式主要用于一组客户端和Eureka Server之间存在网络分区场景下的保护。一旦进入保护模式,Eureka Server将会尝试保护其服务注册表中的信息,不再删除服务注册表中的数据,也就是不会注销任何微服务。如果在Eureka Server的首页看到以下这段提示,则说明Eureka进入了保护模式:EMERGENCY! EUREKA MAY BE INCORRECTLY CLAIMING INSTANCES ARE UP WHEN THEY'RE NOT.RENEWALS ARE LESSER THAN THRESHOLD AND HENCE THE INSTANCES ARE NOT BEING EXPIRED JUST TO BE SAFE

导致原因
一句话:某时刻某一个微服务不可用了,Eureka不会立刻清理,依旧会对该微服务的信息进行保存
属于CAP里面的AP分支
什么是自我保护模式?
默认情况下,如果EurekaServer在一定时间内没有接收到某个微服务实例的心跳,EurekaServer将会注销该实例(默认90秒)。但是当网络分区故障发生(延时、卡顿、拥挤)时,微服务与EurekaServer之间无法正常通信,以上行为可能变得非常危险了——因为微服务本身其实是健康的,此时本不应该注销这个微服务。Eureka通过“自我保护模式”来解决这个问题——当EurekaServer节点在短时间内丢失过多客户端时(可能发生了网络分区故障),那么这个节点就会进入自我保护模式。

在自我保护模式中,Eureka Server会保护服务注册表中的信息,不再注销任何服务实例。<br />
它的设计哲学就是宁可保留错误的服务注册信息,也不盲目注销任何可能健康的服务实例。一句话讲解:好死不如赖活着
综上,自我保护模式是一种应对网络异常的安全保护措施。它的架构哲学是宁可同时保留所有微服务(健康的微服务和不健康的微服务都会保留)也不盲目注销任何健康的微服务。使用自我保护模式,可以让Eureka集群更加的健壮、稳定。
怎么禁止自我保护
注册中心eureakeServer端7001
出厂默认,自我保护机制是开启的eureka.server.enable-self-preservation=true
使用eureka.server.enable-self-preservation = false 可以禁用自我保护模式
server:port: 7001spring:application:name: eureka-cluster-servereureka:instance:hostname: eureka7001.comclient:register-with-eureka: falsefetch-registry: falseservice-url:#defaultZone: http://eureka7002.com:7002/eureka,http://eureka7003.com:7003/eurekadefaultZone: http://eureka7001.com:7001/eurekaserver:#关闭自我保护机制,保证不可用服务被及时踢除enable-self-preservation: falseeviction-interval-timer-in-ms: 2000
关闭效果

在eurekaServer端7001处设置关闭自我保护机制
生产者客户端eureakeClient端8001 单位为秒(默认是30秒)
eureka.instance.lease-renewal-interval-in-seconds=30 #单位为秒(默认是30秒)eureka.instance.lease-expiration-duration-in-seconds=90 #单位为秒(默认是90秒)
配置
server:port: 8001###服务名称(服务注册到eureka名称)spring:application:name: cloud-provider-paymenteureka:client: #服务提供者provider注册进eureka服务列表内service-url:register-with-eureka: truefetch-registry: true# cluster version#defaultZone: http://eureka7001.com:7001/eureka,http://eureka7002.com:7002/eureka,http://eureka7003.com:7003/eureka# singleton versiondefaultZone: http://eureka7001.com:7001/eureka#心跳检测与续约时间#开发时设置小些,保证服务关闭后注册中心能即使剔除服务instance:#Eureka客户端向服务端发送心跳的时间间隔,单位为秒(默认是30秒)lease-renewal-interval-in-seconds: 1#Eureka服务端在收到最后一次心跳后等待时间上限,单位为秒(默认是90秒),超时将剔除服务lease-expiration-duration-in-seconds: 2
测试
7001和8001都配置完成先启动7001再启动8001
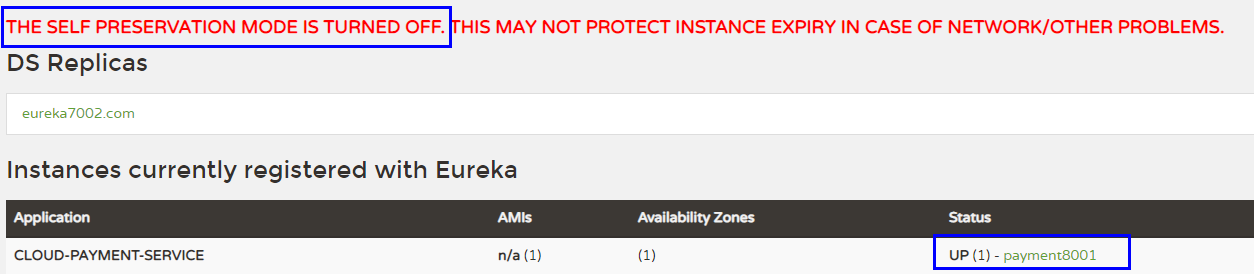
先关闭8001
马上被删除了
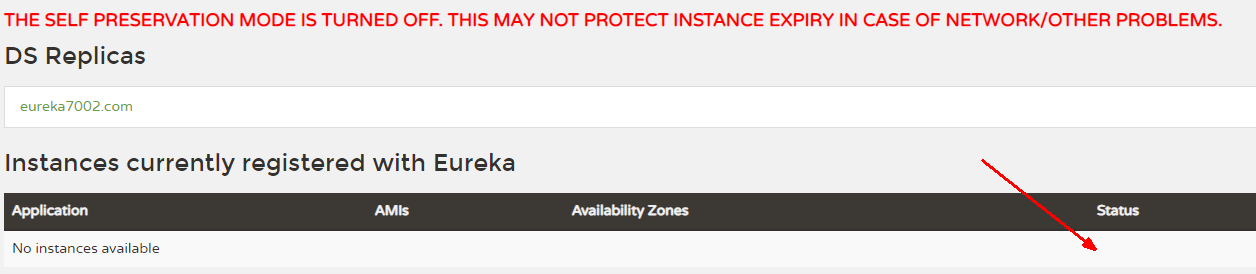
那么不显式的设置enable-self-preservation: true,即使不配置自我保护机制,也同样会被马上剔除掉,这里阳哥讲错了。
eureka:instance:hostname: eureka7002.com #eureka服务端的实例名称client:#false表示不向注册中心注册自己。register-with-eureka: false#false表示自己端就是注册中心,我的职责就是维护服务实例,并不需要去检索服务fetch-registry: falseservice-url:#设置与Eureka Server交互的地址查询服务和注册服务都需要依赖这个地址。# defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/defaultZone: http://eureka7001.com:7001/eureka/server:#关闭自我保护机制,保证不可用服务被及时踢除enable-self-preservation: trueeviction-interval-timer-in-ms: 200000
手动关掉8001服务

超时时间过后才被剔除

三、Zookeeper
Eureka停止更新了你怎么办 https://github.com/Netflix/eureka/wiki
第一章、基础知识
1、概述
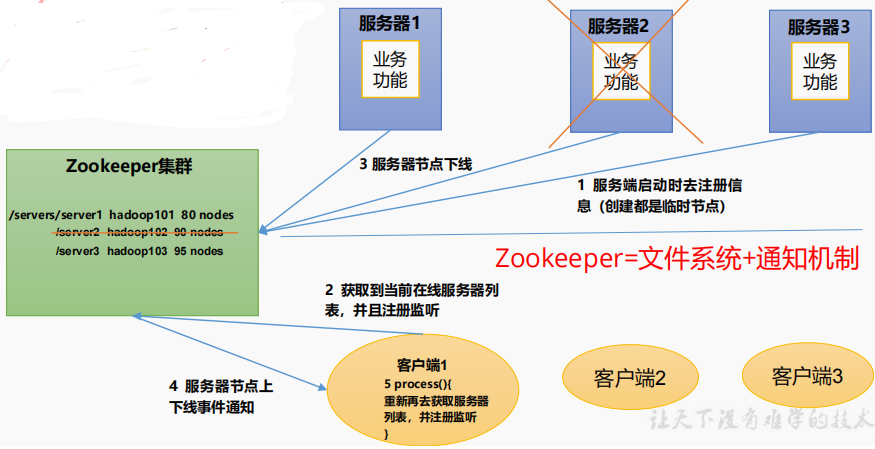
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。
文件系统+通知机制
2、特点
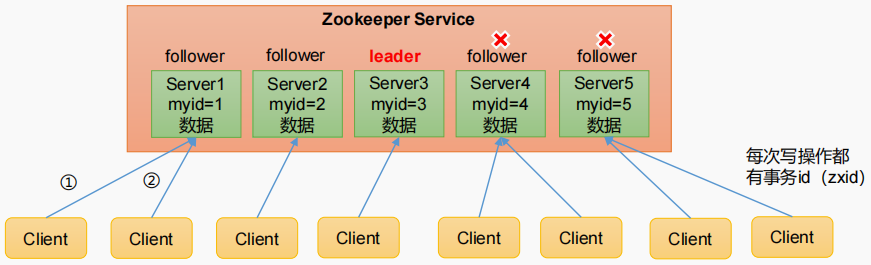
1)Zookeeper:一个领导者(Leader),多个跟随者(Follower)组成的集群。2)集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。所以Zookeeper适合安装奇数台服务器。3)全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。4)更新请求顺序执行,来自同一个Client的更新请求按其发送顺序依次执行。5)数据更新原子性,一次数据更新要么成功,要么失败。6)实时性,在一定时间范围内,Client能读到最新数据。
3、数据结构
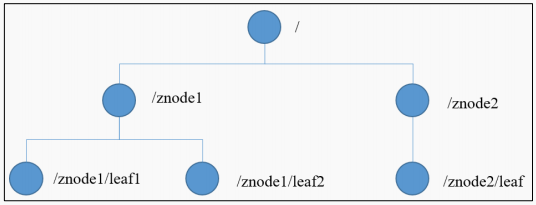
ZooKeeper 数据模型的结构与 Unix 文件系统很类似,整体上可以看作是一棵树,每个节点称做一个 ZNode。每一个 ZNode 默认能够存储 1MB 的数据,每个 ZNode 都可以通过其路径唯一标识。
4 应用场景
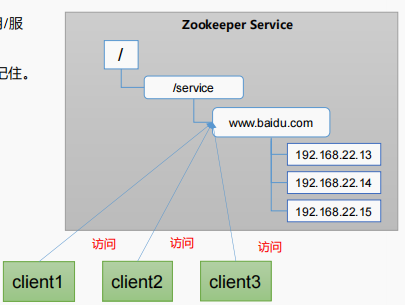
提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。
在分布式环境下,经常需要对应用/服务进行统一命名,便于识别。例如:IP不容易记住,而域名容易记住。
统一命名服务:
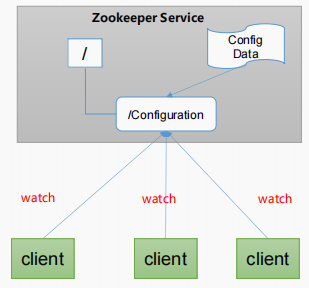
统一配置管理:
1)分布式环境下,配置文件同步非常常见。
(1)一般要求一个集群中,所有节点的配置信息是一致的,比如 Kafka 集群。
(2)对配置文件修改后,希望能够快速同步到各个节点上。
2)配置管理可交由ZooKeeper实现。
(1)可将配置信息写入ZooKeeper上的一个Znode。
(2)各个客户端服务器监听这个Znode。
(3)一 旦Znode中的数据被修改,ZooKeeper将通知各个客户端服务器。
统一集群管理
1)分布式环境中,实时掌握每个节点的状态是必要的。
(1)可根据节点实时状态做出一些调整。
2)ZooKeeper可以实现实时监控节点状态变化
(1)可将节点信息写入ZooKeeper上的一个ZNode。
(2)监听这个ZNode可获取它的实时状态变化。
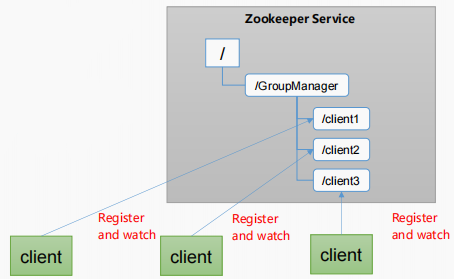
服务器动态上下线
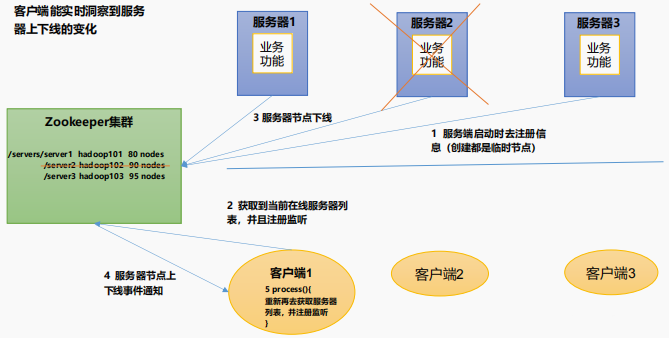
软负载均衡
在Zookeeper中记录每台服务器的访问数,让访问数最少的服务器去处理最新的客户端请求

5 下载地址
1)官网首页:
2)下载截图

第二章、Zookeeper本地安装
将zookeeper安装包用xftp放到/opt/software 目录中,没有就创建一个。
改个名(名太长,但是一般留个版本号): mv apache-zookeeper-3.5.7-bin/ zookeeper-3.5.7
去配置文件:conf/zoo_sample.cfg 改名 mv zoo_sample.cfg zoo.cfg
在zookeeper上创建个zkData目录,为了保存zookeeper的数据文件,在zoo.cfg上改文件
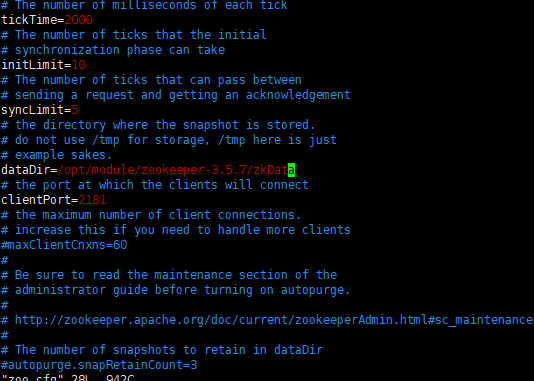
把目录换成自己建的,可以进入目录用pwd命令获取目录绝对路径
启动zookeeper服务端
bin/zkServer.sh start
启动zookeeper客户端
bin/zkCli.sh
退出客户端
quit
查看进程
jpsjps -l
查看状态
bin/zkServer.sh status
关闭zk服务端命令
bin/zkServer.sh stop
2.2 配置参数解读
Zookeeper中的配置文件zoo.cfg中参数含义解读如下:
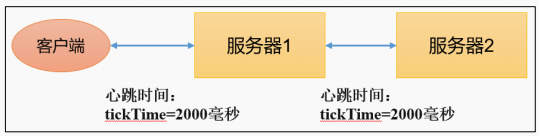
1)tickTime = 2000:通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
2)initLimit = 10:LF初始通信时限

Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量)
默认initLimit*tickTime
3)syncLimit = 5:LF同步通信时限

Leader和Follower之间通信时间如果超过syncLimit * tickTime,Leader认为Follwer死掉,从服务器列表中删除Follwer。
4)dataDir:保存Zookeeper中的数据
注意:默认的tmp目录,容易被Linux系统定期删除,所以一般不用默认的tmp目录。
5)clientPort = 2181:客户端连接端口,通常不做修改。
第三章、Zookeeper集群操作
3.1 集群操作
3.1.1 集群安装
1)集群规划
在 hadoop102、hadoop103 和 hadoop104 三个节点上都部署 Zookeeper。
思考:如果是 10 台服务器,需要部署多少台Zookeeper?
2)解压安装
(1)在 hadoop102 解压 Zookeeper 安装包到/opt/module/目录下
[atguigu@hadoop102 software]$ tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/
(2)修改 apache-zookeeper-3.5.7-bin 名称为 zookeeper-3.5.7
[atguigu@hadoop102 module]$ mv apache-zookeeper-3.5.7-bin/ zookeeper-3.5.7
3)配置服务器编号
(1)在/opt/module/zookeeper-3.5.7/这个目录下创建 zkData
[atguigu@hadoop102 zookeeper-3.5.7]$ mkdir zkData
(2)在/opt/module/zookeeper-3.5.7/zkData 目录下创建一个 myid 的文件
[atguigu@hadoop102 zkData]$ vi myid
在文件中添加与 server 对应的编号(注意:上下不要有空行,左右不要有空格)
注意:添加 myid 文件,一定要在 Linux 里面创建,在 notepad++里面很可能乱码
(3)拷贝配置好的 zookeeper 到其他机器上
[atguigu@hadoop102 module ]$ xsync zookeeper-3.5.7
并分别在 hadoop103、hadoop104 上修改 myid 文件中内容为 3、4
…………………..
Jdk环境变量
部集群
改ip地址
vim /etc/sysconfig/network/network-scripts/ifcfg-ens33
改主机名
vim /etc/hostname
reboot重启
ifconfig检查ip修改情况
hadoop100 192.168.200.188hadoop102 192.168.200.189hadoop103 192.168.200.190
搭集群,集群之间的文件同步配置:
xsync需要先安装rsync,去bin目录下安装cd /bin
yum install -y rsync
vim xsync 复制脚本文件
exit 0fi#获取文件名称f=$1fname=`basename $f`echo $fname#获取文件绝对路径pdir=`cd -P $(dirname $f); pwd`echo $pdir#获取当前用户user=`whoami`echo "$user"#循环拷贝for host in 192.168.200.189 192.168.200.188 192.168.200.190doecho "**********$host*********"rsync -av $pdir/$fname $user@$host:$pdirdone
修改权限
chmod 777 xsync
去配置文件怎加如下配置 vim /opt/moudle/zookeeper-3.5.7/conf/zoo.cfg
#######################cluster##########################server.1=192.168.200.188:2888:3888server.2=192.168.200.189:2888:3888server.3=192.168.200.190:2888:3888
执行命令即可集群间传输数据
sudo xsync “xxxxx”
zk.sh脚本
#!/bin/bashcase $1 in"start"){for i in 192.168.200.188 192.168.200.189 192.168.200.190doecho ---------- zookeeper $i 启动 ------------ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start"done};;"stop"){for i in 192.168.200.188 192.168.200.189 192.168.200.190doecho ---------- zookeeper $i 停止 ------------ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop"done};;"status"){for i in 192.168.200.188 192.168.200.189 192.168.200.190doecho ---------- zookeeper $i 状态 ------------ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh status"done};;esac
jpsall.sh脚本
#!/bin/bash# 执行jps命令查询每台服务器上的节点状态echo ======================集群节点状态====================for i in 192.168.200.188 192.168.200.189 192.168.200.190doecho ====================== $i ====================ssh $i "/opt/moudle/jdk1.8.0_152/bin/jps"doneecho ======================执行完毕====================
启动zookeeper集群,并查看状态
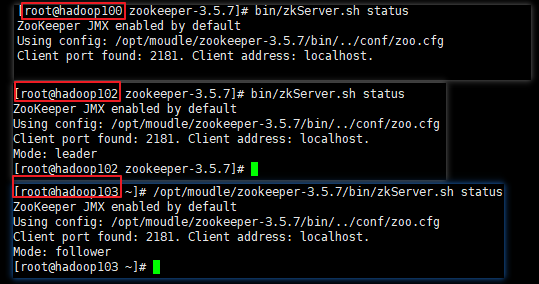
启动第二个的时候,zookeeper服务器超过半数,集群启动成功,选出leader,follower
3.1.2 选举机制(面试重点)
第一次启动
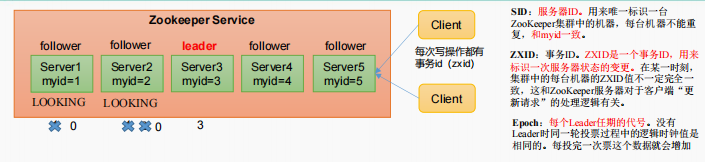

非第一次启动
3.1.3 ZK 集群启动停止脚本
1)在 hadoop102 的/home/atguigu/bin 目录下创建脚本
vim zk.sh
在脚本中编写如下内容
#!/bin/bashcase $1 in"start"){for i in 192.168.200.188 192.168.200.189 192.168.200.190doecho ---------- zookeeper $i 启动 ------------ssh $i "/opt/moudle/zookeeper-3.5.7/bin/zkServer.sh start"done};;"stop"){for i in 192.168.200.188 192.168.200.189 192.168.200.190doecho ---------- zookeeper $i 停止 ------------ssh $i "/opt/moudle/zookeeper-3.5.7/bin/zkServer.sh stop"done};;"status"){for i in 192.168.200.188 192.168.200.189 192.168.200.190doecho ---------- zookeeper $i 状态 ------------ssh $i "/opt/moudle/zookeeper-3.5.7/bin/zkServer.sh status"done};;esac
2)增加脚本执行权限
chmod u+x zk.sh
3)Zookeeper 集群启动脚本
zk.sh start
4)Zookeeper 集群停止脚本
zk.sh stop
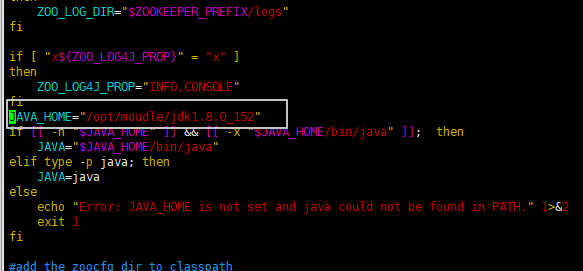
bug:
Error: JAVA_HOME is not set and java could not be found in PATH.
在zookeeper目录下bin打开zkEnv.sh 添加一行jdk的安装路径
脚本文件都需要用xsync同步一下。。。
3.2 客户端命令行操作
3.2.1 命令行语句
| 命令基本语法 | 功能描述 |
|---|---|
| help | 显示所有操作命令 |
| ls path | 使用 ls 命令来查看当前 znode 的子节点 [可监听] -w 监听子节点变化 -s 附加次级信息 |
| create | 普通创建 -s 含有序列 -e 临时(重启或者超时消失) |
| get path | 获得节点的值 [可监听] -w 监听节点内容变化 -s 附加次级信息 |
| set | 设置节点的具体值 |
| stat | 查看节点状态 |
| delete | 删除节点 |
| deleteall | 递归删除节点 |
1)启动客户端
bin/zkCli.sh -server hadoop102:2181
2)显示所有操作命令
help
3.2.2 znode 节点数据信息
1)查看当前znode中所包含的内容
ls /
[zookeeper]
2)查看当前节点详细数据
[zk: hadoop100:2181(CONNECTED) 3] ls -s /[zookeeper]cZxid = 0x0ctime = Thu Jan 01 08:00:00 CST 1970mZxid = 0x0mtime = Thu Jan 01 08:00:00 CST 1970pZxid = 0x0cversion = -1dataVersion = 0aclVersion = 0ephemeralOwner = 0x0dataLength = 0numChildren = 1
(1)czxid:创建节点的事务 zxid
每次修改 ZooKeeper 状态都会产生一个 ZooKeeper 事务 ID。事务 ID 是 ZooKeeper 中所有修改总的次序。每次修改都有唯一的 zxid,如果 zxid1 小于 zxid2,那么 zxid1 在 zxid2 之前发生。
(2)ctime:znode 被创建的毫秒数(从 1970 年开始)
(3)mzxid:znode 最后更新的事务 zxid
(4)mtime:znode 最后修改的毫秒数(从 1970 年开始)
(5)pZxid:znode 最后更新的子节点 zxid
(6)cversion:znode 子节点变化号,znode 子节点修改次数
(7)dataversion:znode 数据变化号
(8)aclVersion:znode 访问控制列表的变化号
(9)ephemeralOwner:如果是临时节点,这个是 znode 拥有者的 session id。如果不是临时节点则是 0。
(10)dataLength:znode 的数据长度
(11)numChildren:znode 子节点数量
3.2.3 节点类型(持久/短暂/有序号/无序号)
分别创建2个普通节点(永久节点+不带序号)
[zk: hadoop100:2181(CONNECTED) 4] ls /[zookeeper][zk: hadoop100:2181(CONNECTED) 5] create /sanguo "diaochan"Created /sanguo[zk: hadoop100:2181(CONNECTED) 6] ls /[sanguo, zookeeper][zk: hadoop100:2181(CONNECTED) 7] create /sanguo/shuguo "liubei"Created /sanguo/shuguo[zk: hadoop100:2181(CONNECTED) 8] ls /[sanguo, zookeeper][zk: hadoop100:2181(CONNECTED) 9] ls /sanguo[shuguo][zk: hadoop100:2181(CONNECTED) 10] get -s /sanguodiaochancZxid = 0x400000002ctime = Sat Apr 23 10:44:06 CST 2022mZxid = 0x400000002mtime = Sat Apr 23 10:44:06 CST 2022pZxid = 0x400000003cversion = 1dataVersion = 0aclVersion = 0ephemeralOwner = 0x0dataLength = 8numChildren = 1[zk: hadoop100:2181(CONNECTED) 11]
获得节点的值
[zk: hadoop100:2181(CONNECTED) 11] get -s /sanguo/shuguoliubeicZxid = 0x400000003ctime = Sat Apr 23 10:44:33 CST 2022mZxid = 0x400000003mtime = Sat Apr 23 10:44:33 CST 2022pZxid = 0x400000003cversion = 0dataVersion = 0aclVersion = 0ephemeralOwner = 0x0dataLength = 6numChildren = 0[zk: hadoop100:2181(CONNECTED) 12]
创建带序号的节点(永久节点 +带序号)
先创建一个普通的根节点/sanguo/weiguo
[zk: localhost:2181(CONNECTED) 1] create /sanguo/weiguo "caocao"Created /sanguo/weiguo
创建带序号的节点
[zk: hadoop100:2181(CONNECTED) 18] create -s /sanguo/weiguo/zhangliao "zhangliao"Created /sanguo/weiguo/zhangliao0000000001[zk: hadoop100:2181(CONNECTED) 19] create -s /sanguo/weiguo/zhangliaozhangliao zhangliao0000000001[zk: hadoop100:2181(CONNECTED) 19] create -s /sanguo/weiguo/zhangliao "zhangliao"Created /sanguo/weiguo/zhangliao0000000002[zk: hadoop100:2181(CONNECTED) 20] create -s /sanguo/weiguo/xuchu "xushu"Created /sanguo/weiguo/xuchu0000000003
如果原来没有序号节点,序号从 0 开始依次递增。如果原节点下已有 2 个节点,则再排序时从 2 开始,以此类推。
创建短暂节点(短暂节点 + 不带序号 or 带序号)
(1)创建短暂的不带序号的节点[zk: localhost:2181(CONNECTED) 7] create -e /sanguo/wuguo "zhouyu"Created /sanguo/wuguo(2)创建短暂的带序号的节点[zk: localhost:2181(CONNECTED) 2] create -e -s /sanguo/wuguo "zhouyu"Created /sanguo/wuguo0000000001(3)在当前客户端是能查看到的[zk: localhost:2181(CONNECTED) 3] ls /sanguo[wuguo, wuguo0000000001, shuguo](4)退出当前客户端然后再重启客户端[zk: localhost:2181(CONNECTED) 12] quit[atguigu@hadoop104 zookeeper-3.5.7]$ bin/zkCli.sh(5)再次查看根目录下短暂节点已经删除[zk: localhost:2181(CONNECTED) 0] ls /sanguo[shuguo]
5)修改节点数据值
[zk: localhost:2181(CONNECTED) 6] set /sanguo/weiguo “simayi”
3.2.4 监听器原理
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、节点删除、子目录节点增加删除)时,ZooKeeper 会通知客户端。监听机制保证 ZooKeeper 保存的任何的数据的任何改变都能快速的响应到监听了该节点的应用程序。
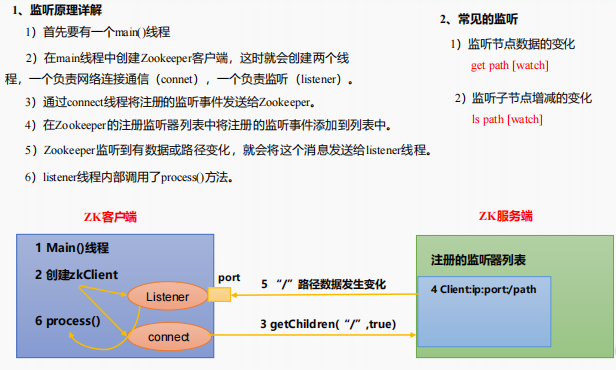
1)节点的值变化监听
(1)在 hadoop104 主机上注册监听/sanguo 节点数据变化
[zk: localhost:2181(CONNECTED) 26] get -w /sanguo
(2)在 hadoop103 主机上修改/sanguo 节点的数据
[zk: localhost:2181(CONNECTED) 1] set /sanguo “xisi”
(3)观察 hadoop104 主机收到数据变化的监听
WATCHER::WatchedEvent state:SyncConnected type:NodeDataChanged path:/sanguo
注意:在hadoop103再多次修改/sanguo的值,hadoop104上不会再收到监听。因为注册
一次,只能监听一次。想再次监听,需要再次注册。
2)节点的子节点变化监听(路径变化)
(1)在 hadoop104 主机上注册监听/sanguo 节点的子节点变化
[zk: localhost:2181(CONNECTED) 1] ls -w /sanguo
[shuguo, weiguo]
(2)在 hadoop103 主机/sanguo 节点上创建子节点
[zk: localhost:2181(CONNECTED) 2] create /sanguo/jin “simayi”
Created /sanguo/jin
(3)观察 hadoop104 主机收到子节点变化的监听
WATCHER::WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/sanguo
注意:节点的路径变化,也是注册一次,生效一次。想多次生效,就需要多次注册。
3.2.5 节点删除与查看
1)删除节点
[zk: localhost:2181(CONNECTED) 4] delete /sanguo/jin
2)递归删除节点
[zk: localhost:2181(CONNECTED) 15] deleteall /sanguo/shuguo
3)查看节点状态
[zk: localhost:2181(CONNECTED) 17] stat /sanguocZxid = 0x100000003ctime = Wed Aug 29 00:03:23 CST 2018mZxid = 0x100000011mtime = Wed Aug 29 00:21:23 CST 2018pZxid = 0x100000014cversion = 9dataVersion = 1aclVersion = 0ephemeralOwner = 0x0dataLength = 4numChildren = 1
3.3 客户端API操作
前提:保证 hadoop102、hadoop103、hadoop104 服务器上 Zookeeper 集群服务端启动。做好win的hosts映射
3.3.1 IDEA 环境搭建
1)创建一个工程:zookeeper
2)添加pom文件
<dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>RELEASE</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>2.8.2</version></dependency><dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>3.5.7</version></dependency></dependencies>
3)拷贝log4j.properties文件到项目根目录
需要在项目的 src/main/resources 目录下,新建一个文件,命名为“log4j.properties”,在文件中填入。
log4j.rootLogger=INFO, stdoutlog4j.appender.stdout=org.apache.log4j.ConsoleAppenderlog4j.appender.stdout.layout=org.apache.log4j.PatternLayoutlog4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%nlog4j.appender.logfile=org.apache.log4j.FileAppenderlog4j.appender.logfile.File=target/spring.loglog4j.appender.logfile.layout=org.apache.log4j.PatternLayoutlog4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
4)创建包名com.atguigu.zk
5)创建类名称zkClient
3.3.2 创建 ZooKeeper 客户端
public class ZkClient {// 注意:都好左右不能有空格private String connectString = "hadoop100:2181,hadoop102:2181,hadoop103:2181";// 超时时间private int sessionTimeout = 2000;private ZooKeeper zkClient;@Beforepublic void init() throws IOException {zkClient = new ZooKeeper(connectString, sessionTimeout, new Watcher() {@Overridepublic void process(WatchedEvent watchedEvent) {}});}@Testpublic void create(){try {String nodeCreated = zkClient.create("/atguigu", "ss.avi".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);} catch (KeeperException e) {e.printStackTrace();} catch (InterruptedException e) {e.printStackTrace();}}}
3.3.3 创建子节点
@Testpublic void create(){try {String nodeCreated = zkClient.create("/atguigu", "ss.avi".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);} catch (KeeperException e) {e.printStackTrace();} catch (InterruptedException e) {e.printStackTrace();}}
测试:在 hadoop102 的 zk 客户端上查看创建节点情况 get -s /atguigu
3.3.4 获取子节点并监听节点变化
@Testpublic void getChildren() throws KeeperException, InterruptedException {List<String> children = zkClient.getChildren("/", true);for (String child : children) {System.out.println(child);}//延时阻塞Thread.sleep(Long.MAX_VALUE);}
public class ZkClient {// 注意:都好左右不能有空格private String connectString = "hadoop100:2181,hadoop102:2181,hadoop103:2181";// 超时时间private int sessionTimeout = 2000;private ZooKeeper zkClient;@Beforepublic void init() throws IOException {zkClient = new ZooKeeper(connectString, sessionTimeout, new Watcher() {@Overridepublic void process(WatchedEvent watchedEvent) {System.out.println("-------------------------");List<String> children =null;try {children = zkClient.getChildren("/", true);for (String child : children) {System.out.println(child);}System.out.println("-------------------------");} catch (KeeperException e) {e.printStackTrace();} catch (InterruptedException e) {e.printStackTrace();}}});}@Testpublic void create(){try {String nodeCreated = zkClient.create("/atguigu", "ss.avi".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);} catch (KeeperException e) {e.printStackTrace();} catch (InterruptedException e) {e.printStackTrace();}}@Testpublic void getChildren() throws KeeperException, InterruptedException {List<String> children = zkClient.getChildren("/", true);for (String child : children) {System.out.println(child);}//延时阻塞Thread.sleep(Long.MAX_VALUE);}}
此时创建/删除节点,都有监听到,并打印才控制台
3.3.5 判断Znode是否存在
@Testpublic void exist() throws KeeperException, InterruptedException {Stat stat = zkClient.exists("/atguigu", false);System.out.println(stat == null ? "not exist" : "exist");}
3.4 客户端向服务端写数据流程
写流程之写入请求直接发送给Leader节点
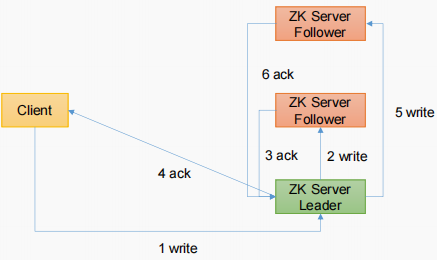
写流程之写入请求发送给follower节点

第四章、服务器动态上下线监听案例
4.1 需求
某分布式系统中,主节点可以有多台,可以动态上下线,任意一台客户端都能实时感知到主节点服务器的上下线。
4.2 需求分析
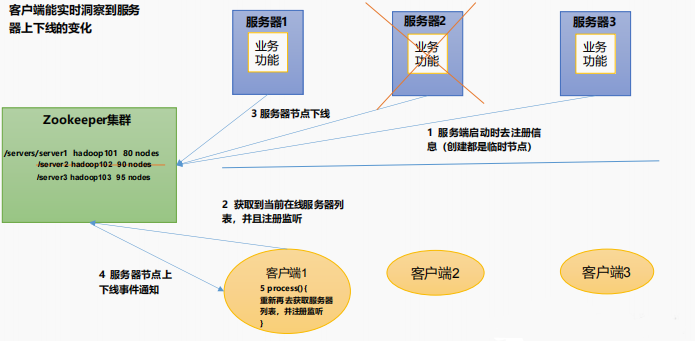
4.3 具体实现
(1)先在集群上创建/servers 节点
create /servers “servers”
(2)在 Idea 中创建包名:com.atguigu.zkcase1
(3)服务器端向 Zookeeper 注册代码
public class DistributeServer {// 注意:都好左右不能有空格private String connectString = "hadoop100:2181,hadoop102:2181,hadoop103:2181";// 超时时间private int sessionTimeout = 2000;private ZooKeeper zkClient;public static void main(String[] args) throws IOException, KeeperException, InterruptedException {DistributeServer server = new DistributeServer();// 1 获取zk连接server.getConnect();// 2 注册服务器到zk集群server.registServer(args[0]);// 3 启动业务逻辑server.business();}private void business() {try {Thread.sleep(Long.MAX_VALUE);} catch (InterruptedException e) {e.printStackTrace();}}private void registServer(String hostname) throws KeeperException, InterruptedException {String created = zkClient.create("/servers/", hostname.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);System.out.println("hostname = " + hostname + " is online");}private void getConnect() throws IOException {zkClient = new ZooKeeper(connectString, sessionTimeout, new Watcher() {@Overridepublic void process(WatchedEvent watchedEvent) {}});}}
客户端代码:
public class DistributeClient {// 注意:都好左右不能有空格private String connectString = "hadoop100:2181,hadoop102:2181,hadoop103:2181";// 超时时间private int sessionTimeout = 2000;private ZooKeeper zk;public static void main(String[] args) throws IOException, KeeperException, InterruptedException {DistributeClient client = new DistributeClient();// 1 获取zk连接client.getConnect();// 2 监听/servers 下面子节点的增加和删除client.getServerList();// 3 业务逻辑(sleep)client.business();}private void business() {try {Thread.sleep(Long.MAX_VALUE);} catch (InterruptedException e) {e.printStackTrace();}}private void getServerList() throws KeeperException, InterruptedException {List<String> children = zk.getChildren("/servers", true);List<String> servers = new ArrayList<>();for (String child : children) {//System.out.println("child = " + child);byte[] data = zk.getData("/servers/" + child, false, null);servers.add(new String(data));}// 打印System.out.println(servers);}private void getConnect() throws IOException {zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() {//ctrl + alt + f@Overridepublic void process(WatchedEvent watchedEvent) {try {getServerList();} catch (KeeperException e) {e.printStackTrace();} catch (InterruptedException e) {e.printStackTrace();}}});}}
4.4 测试
1)在 Linux 命令行上操作增加减少服务器
(1)启动 DistributeClient 客户端
(2)在 hadoop102 上 zk 的客户端/servers 目录上创建临时带序号节点
create -e -s /servers/hadoop100 “hadoop100”
create -e -s /servers/hadoop100 “hadoop102”

(3)观察 Idea 控制台变化

(4)执行删除操作
delete /servers/hadoop1000000000000

2)在 Idea 上操作增加减少服务器
(1)启动 DistributeClient 客户端(如果已经启动过,不需要重启)
(2)启动 DistributeServer 服务
①点击 Edit Configurations…

②在弹出的窗口中(Program arguments)输入想启动的主机,例如,hadoop100
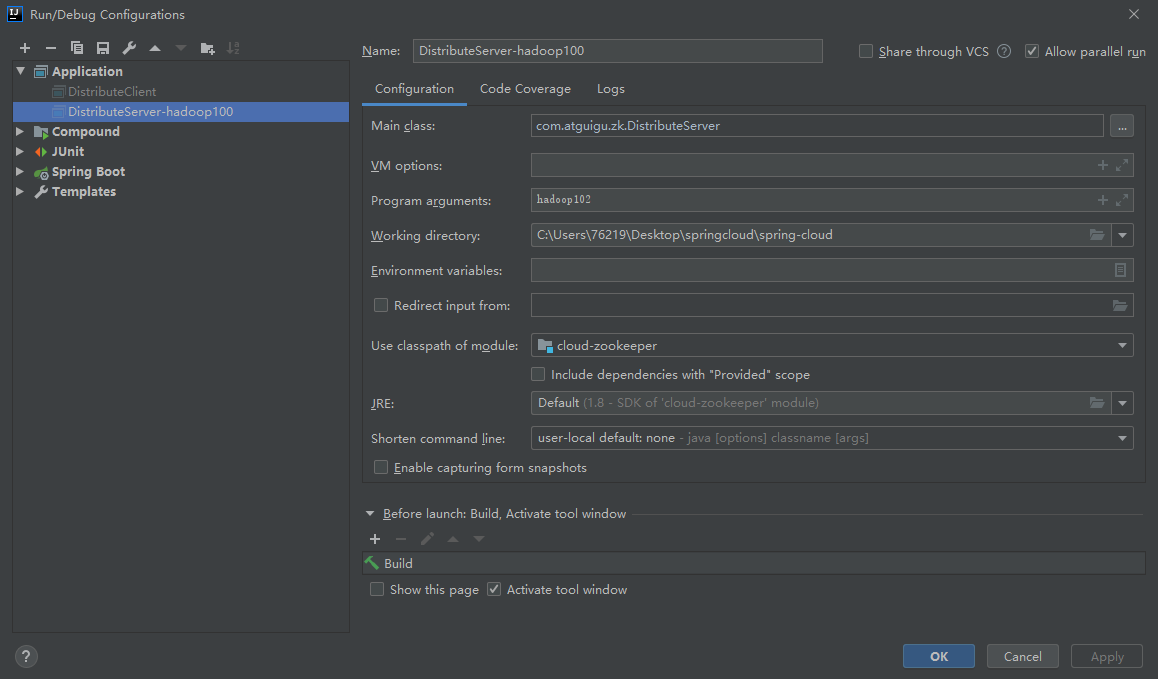
③回到 DistributeServer 的 main 方 法 , 右 键 , 在 弹 出 的 窗 口 中 点 击 Run“DistributeServer.main()”
还可以
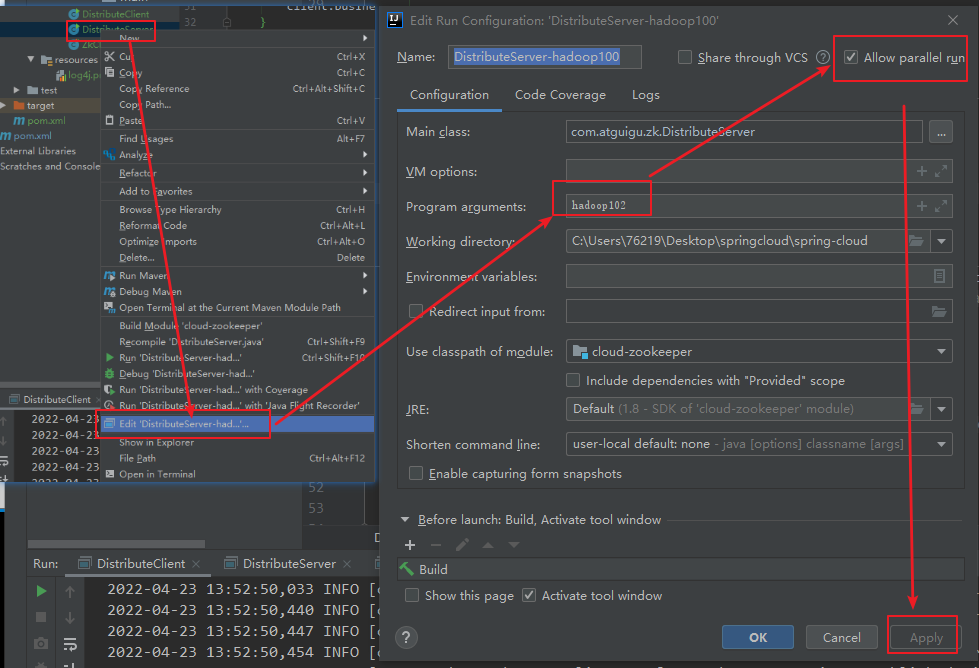
更换不同的参数,启动多个服务端
④观察 DistributeServer 控制台,提示 hadoop102 is working
⑤观察 DistributeClient 控制台,提示 hadoop102 已经上线

第 5 章、ZooKeeper 分布式锁案例
什么叫做分布式锁呢?比如说"进程 1"在使用该资源的时候,会先去获得锁,"进程 1"获得锁以后会对该资源保持独占,这样其他进程就无法访问该资源,"进程 1"用完该资源以后就将锁释放掉,让其他进程来获得锁,那么通过这个锁机制,我们就能保证了分布式系统中多个进程能够有序的访问该临界资源。那么我们把这个分布式环境下的这个锁叫作分布式锁。
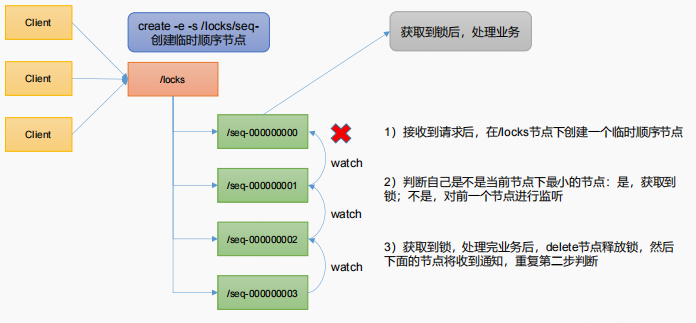
5.1 原生Zookeeper实现分布式锁案例
1)分布式锁实现
public class DistributedLock {// 注意:都好左右不能有空格private String connectString = "hadoop100:2181,hadoop102:2181,hadoop103:2181";// 超时时间private int sessionTimeout = 2000;private final ZooKeeper zk;// Zookeeper 连接private CountDownLatch connectLatch = new CountDownLatch(1);private CountDownLatch waitLatch = new CountDownLatch(1);private String waitPath;private String currentMode;public DistributedLock() throws IOException, InterruptedException, KeeperException {// 获取连接zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() {@Overridepublic void process(WatchedEvent watchedEvent) {// connectLatch 如果连接上zk 可以释放if (watchedEvent.getState() == Event.KeeperState.SyncConnected){connectLatch.countDown();}// waitLatch 需要释放if (watchedEvent.getType() == Event.EventType.NodeDeleted && watchedEvent.getPath().equals(waitPath)){waitLatch.countDown();}}});// 等待zk 正常连接后,往下走程序connectLatch.await();// 判断根节点/locks 是否存在Stat stat = zk.exists("/locks", false);if (stat == null){// 创建一下根节点zk.create("/locks","locks".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);}}// 对zk加锁public void zkLock(){// 创建对应的临时带序号节点try {currentMode = zk.create("/locks/" + "seq-", null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);Thread.sleep(10);// 判断当前节点是不是整个目录下最小的序号节点,如果是,获取到锁,如果不是,监听它前一个节点List<String> children = zk.getChildren("/locks", false);// 如果children 只有一个值,那就直接获取锁,如果有多个节点,需要判断,谁最小if (children.size() == 1){return;} else {Collections.sort(children);// 获取节点名称 seq-00000000String thisNode = currentMode.substring("/locks/".length());// 通过seq-000000000 获取该节点在children集合的位置int index = children.indexOf(thisNode);//判断if (index == -1){System.out.println("数据异常");} else if (index == 0){//就一个节点,可以获取锁了return;} else {// 需要监听 他前一个节点变化waitPath = "/locks/" + children.get(index - 1);zk.getData(waitPath,true,new Stat());//等待监听waitLatch.await();return;}}} catch (KeeperException e) {e.printStackTrace();} catch (InterruptedException e) {e.printStackTrace();}}// 解锁public void unZkLock(){//删除节点try {zk.delete(currentMode,-1);} catch (InterruptedException e) {e.printStackTrace();} catch (KeeperException e) {e.printStackTrace();}}}
创两个线程测试:
public class DistributedLockTest {public static void main(String[] args) throws InterruptedException, IOException, KeeperException {final DistributedLock lock1 = new DistributedLock();final DistributedLock lock2 = new DistributedLock();new Thread(new Runnable() {@Overridepublic void run() {try {lock1.zkLock();System.out.println("线程1 启动,获取到锁");Thread.sleep(5 * 1000);lock1.unZkLock();System.out.println("线程1 启动,释放到锁");} catch (InterruptedException e) {e.printStackTrace();}}}).start();new Thread(new Runnable() {@Overridepublic void run() {try {lock2.zkLock();System.out.println("线程2 启动,获取到锁");Thread.sleep(5 * 1000);lock2.unZkLock();System.out.println("线程2 启动,释放到锁");} catch (InterruptedException e) {e.printStackTrace();}}}).start();}}
测试结果:

5.2 Curator 框架实现分布式锁案例
1)原生的 Java API 开发存在的问题
(1)会话连接是异步的,需要自己去处理。比如使用 CountDownLatch
(2)Watch 需要重复注册,不然就不能生效
(3)开发的复杂性还是比较高的
(4)不支持多节点删除和创建。需要自己去递归
2)Curator 是一个专门解决分布式锁的框架,解决了原生JavaAPI 开发分布式遇到的问题。
详情请查看官方文档:https://curator.apache.org/index.html
3)Curator 案例实操
(1)添加依赖:
<dependency><groupId>org.apache.curator</groupId><artifactId>curator-framework</artifactId><version>4.3.0</version></dependency><dependency><groupId>org.apache.curator</groupId><artifactId>curator-recipes</artifactId><version>4.3.0</version></dependency><dependency><groupId>org.apache.curator</groupId><artifactId>curator-client</artifactId><version>4.3.0</version></dependency>
(2)代码实现:
public class CuratorLockTest {private String rootNode = "/locks";// 注意:都好左右不能有空格private static String connectString = "hadoop100:2181,hadoop102:2181,hadoop103:2181";// connection 超时时间private static int connectionTimeout = 2000;// session 超时时间private static int sessionTimeout = 2000;public static void main(String[] args) {//创建分布式锁 1InterProcessMutex lock1 = new InterProcessMutex(getCuratorFramework(), "/locks");//创建分布式锁 2InterProcessMutex lock2 = new InterProcessMutex(getCuratorFramework(), "/locks");new Thread(new Runnable() {@Overridepublic void run() {try {lock1.acquire();System.out.println("线程1 获取到锁");lock1.acquire();System.out.println("线程1 再次获取到锁");Thread.sleep(5 * 1000);lock1.release();System.out.println("线程1 释放锁");lock1.release();System.out.println("线程1 再次释放锁");} catch (Exception e) {e.printStackTrace();}}}).start();new Thread(new Runnable() {@Overridepublic void run() {try {lock2.acquire();System.out.println("线程2 获取到锁");lock2.acquire();System.out.println("线程2 再次获取到锁");Thread.sleep(5 * 1000);lock2.release();System.out.println("线程2 释放锁");lock2.release();System.out.println("线程2 再次释放锁");} catch (Exception e) {e.printStackTrace();}}}).start();}private static CuratorFramework getCuratorFramework() {ExponentialBackoffRetry retry = new ExponentialBackoffRetry(3000, 3);CuratorFramework client = CuratorFrameworkFactory.builder().connectString(connectString).connectionTimeoutMs(connectionTimeout).sessionTimeoutMs(sessionTimeout).retryPolicy(retry).build();// 启动客户端client.start();System.out.println("zookeeper 启动成功...");return client;}}
第六章、企业面试真题(面试重点)
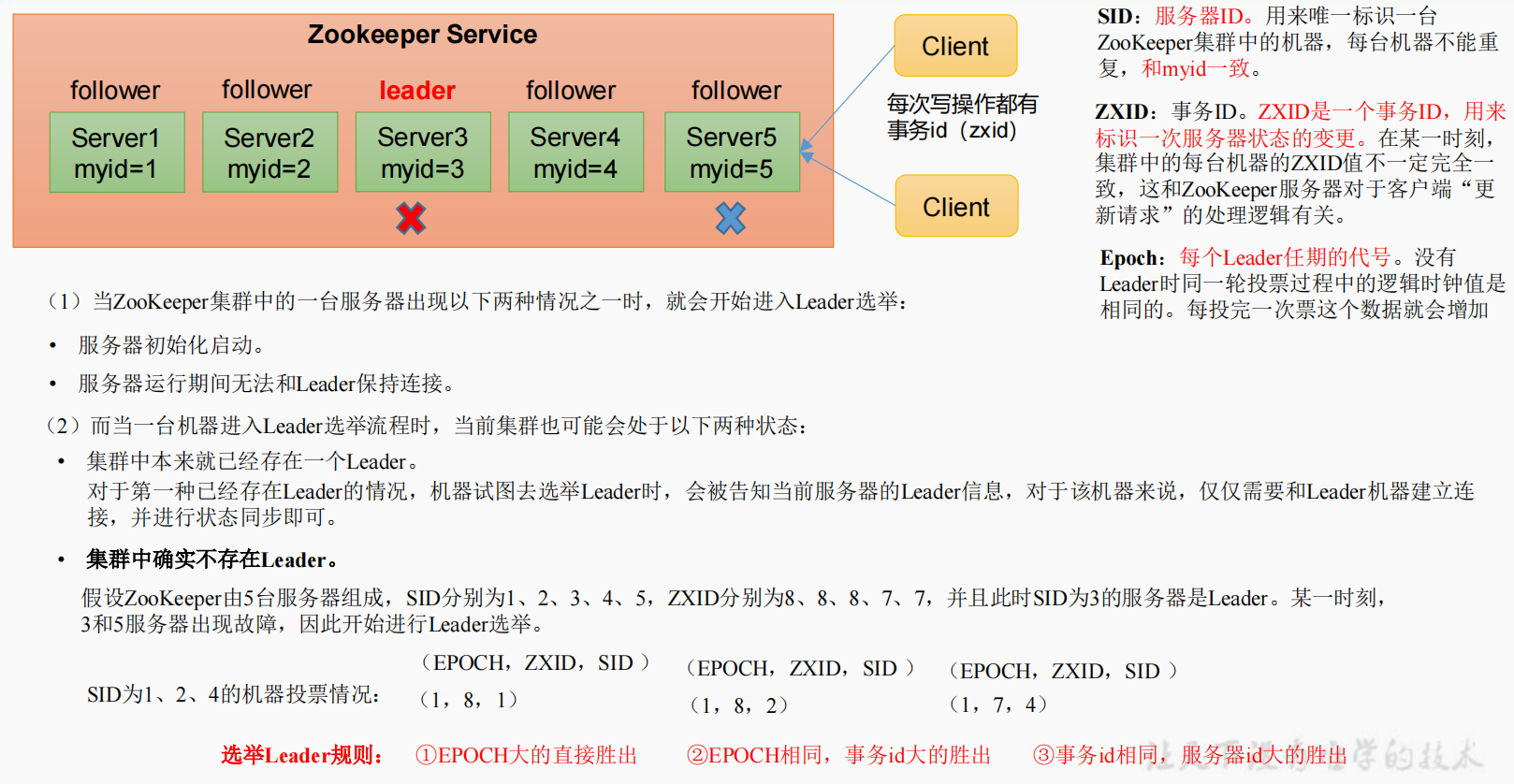
6.1 选举机制
半数机制,超过半数的投票通过,即通过。
(1)第一次启动选举规则:
投票过半数时,服务器 id 大的胜出
(2)第二次启动选举规则:
①EPOCH 大的直接胜出
②EPOCH 相同,事务 id 大的胜出
③事务 id 相同,服务器 id 大的胜出
6.2 生产集群安装多少 zk 合适?
安装奇数台。
生产经验:
⚫ 10 台服务器:3 台 zk;
⚫ 20 台服务器:5 台 zk;
⚫ 100 台服务器:11 台 zk;
⚫ 200 台服务器:11 台 zk
服务器台数多:好处,提高可靠性;坏处:提高通信延时
6.3 常用命令
ls、get、create、delete
SpringCloud整合zookeeper
服务提供者
新建cloud-provider-payment8004
pom:
<!-- SpringBoot整合Web组件 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><!-- 引入自己定义的api通用包,可以使用Payment支付Entity --><groupId>com.atguigu.springcloud</groupId><artifactId>cloud-api-commons</artifactId><version>${project.version}</version></dependency><!-- SpringBoot整合zookeeper客户端 --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-zookeeper-discovery</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency>
yml:
#8004表示注册到zookeeper服务器的支付服务提供者端口号server:port: 8004#服务别名----注册zookeeper到注册中心名称spring:application:name: cloud-provider-paymentcloud:zookeeper:connect-string: 192.168.200.188:2181
主启动类:
@SpringBootApplication@EnableDiscoveryClient //该注解用于向使用consul或者zookeeper作为注册中心时注册服务public class PaymentMain8004{public static void main(String[] args){SpringApplication.run(PaymentMain8004.class,args);}}
controller:
@RestControllerpublic class PaymentController{@Value("${server.port}")private String serverPort;@RequestMapping(value = "/payment/zk")public String paymentzk(){return "springcloud with zookeeper: "+serverPort+"\t"+ UUID.randomUUID().toString();}}
启动8004注册进zookeeper
启动后问题
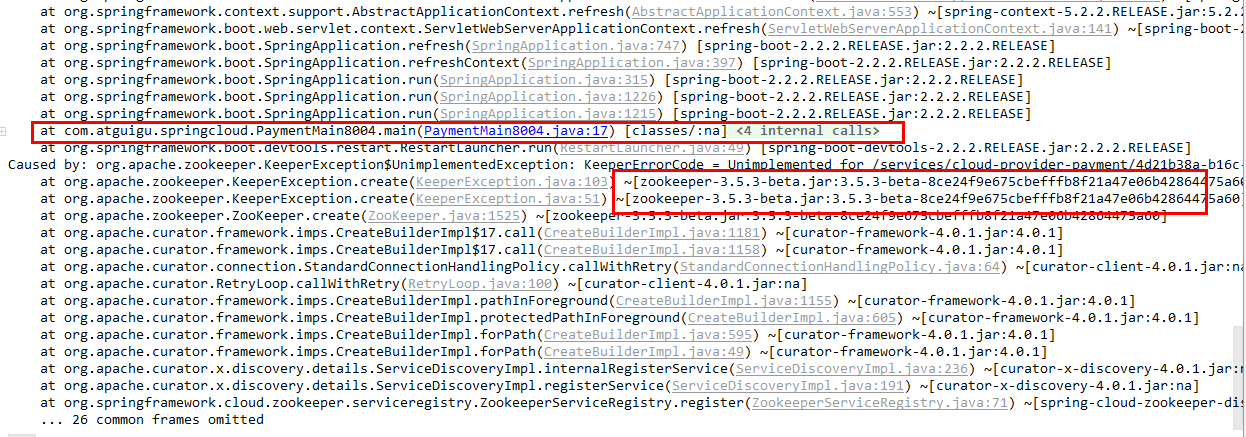
解决zookeeper版本jar包冲突问题

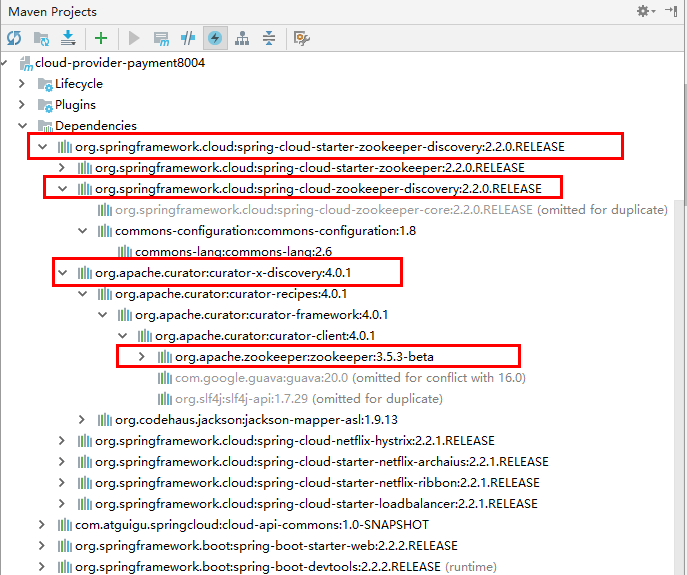
排出zk冲突后的新POM
<!-- SpringBoot整合zookeeper客户端 --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-zookeeper-discovery</artifactId><!--先排除自带的zookeeper3.5.3--><exclusions><exclusion><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId></exclusion></exclusions></dependency><!--添加zookeeper3.4.9版本--><dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>3.4.9</version></dependency>
验证测试:
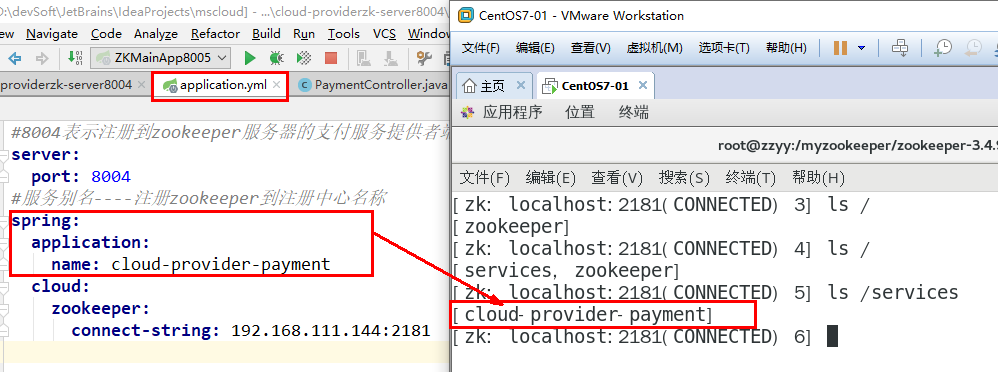

http://localhost:8004/payment/zk

验证测试2

获得json串后用在线工具查看试试
{"name": "cloud-provider-payment","id": "05ddbd78-2241-41e1-8b81-2ffbfa0354e8","address": "DESKTOP-NK1QS30","port": 8004,"sslPort": null,"payload": {"@class": "org.springframework.cloud.zookeeper.discovery.ZookeeperInstance","id": "application-1","name": "cloud-provider-payment","metadata": {}},"registrationTimeUTC": 1650706247412,"serviceType": "DYNAMIC","uriSpec": {"parts": [{"value": "scheme","variable": true},{"value": "://","variable": false},{"value": "address","variable": true},{"value": ":","variable": false},{"value": "port","variable": true}]}}
思考:服务节点是临时节点还是持久节点?
是临时节点。。。一段时间以后,从注册表中清除

服务消费者
新建cloud-consumerzk-order80
pom:
<dependencies><!-- SpringBoot整合Web组件 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- SpringBoot整合zookeeper客户端 --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-zookeeper-discovery</artifactId><!--先排除自带的zookeeper--><exclusions><exclusion><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId></exclusion></exclusions></dependency><!--添加zookeeper3.5.7版本--><dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>3.5.7</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies>
application.yml
server:port: 80spring:application:name: cloud-consumer-ordercloud:#注册到zookeeper地址zookeeper:connect-string: 192.168.200.188:2181
主启动:
@SpringBootApplicationpublic class OrderZK80{public static void main(String[] args){SpringApplication.run(OrderZK80.class,args);}}
业务类
配置Bean
@Configurationpublic class ApplicationContextBean {@Bean@LoadBalancedpublic RestTemplate getRestTemplate() {return new RestTemplate();}}
Controller
@RestControllerpublic class OrderZKController {public static final String INVOKE_URL = "http://cloud-provider-payment";@Autowiredprivate RestTemplate restTemplate;@RequestMapping(value = "/consumer/payment/zk")public String paymentInfo() {String result = restTemplate.getForObject(INVOKE_URL + "/payment/zk", String.class);System.out.println("消费者调用支付服务(zookeeper)--->result:" + result);return result;}}
验证测试

{"name": "cloud-consumer-order","id": "80cb7b07-1bb0-4fa0-a44e-e76ad37a1ec2","address": "DESKTOP-NK1QS30","port": 80,"sslPort": null,"payload": {"@class": "org.springframework.cloud.zookeeper.discovery.ZookeeperInstance","id": "application-1","name": "cloud-consumer-order","metadata": {}},"registrationTimeUTC": 1650707226040,"serviceType": "DYNAMIC","uriSpec": {"parts": [{"value": "scheme","variable": true},{"value": "://","variable": false},{"value": "address","variable": true},{"value": ":","variable": false},{"value": "port","variable": true}]}}
访问测试地址 http://localhost/consumer/payment/zk

四、Consul
Consul简介
Consul 是一套开源的分布式服务发现和配置管理系统,由 HashiCorp 公司用 Go 语言开发。
提供了微服务系统中的服务治理、配置中心、控制总线等功能。这些功能中的每一个都可以根据需要单独使用,也可以一起使用以构建全方位的服务网格,总之Consul提供了一种完整的服务网格解决方案。
它具有很多优点。包括: 基于 raft 协议,比较简洁; 支持健康检查, 同时支持 HTTP 和 DNS 协议 支持跨数据中心的 WAN 集群 提供图形界面 跨平台,支持 Linux、Mac、Windows
官网 https://www.consul.io/intro/index.html
Spring Cloud Consul 具有如下特性:

特性:
服务发现:提供HTTP和DNS两种发现方式。健康监测: 支持多种方式,HTTP、TCP、Docker、Shell脚本定制化监控KV存储: Key、Value的存储方式多数据中心: Consul支持多数据中心可视化Web界面
下载地址: https://www.consul.io/downloads.html
文档: https://www.springcloud.cc/spring-cloud-consul.html
安装并运行Consul
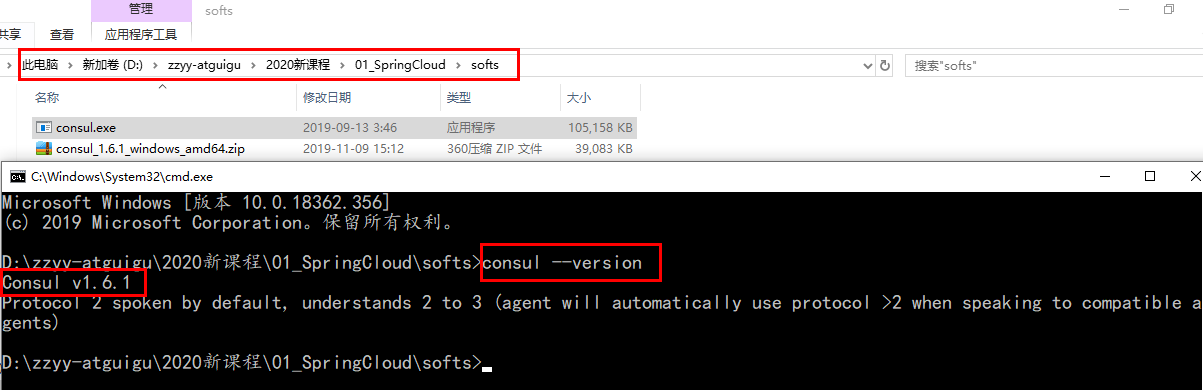
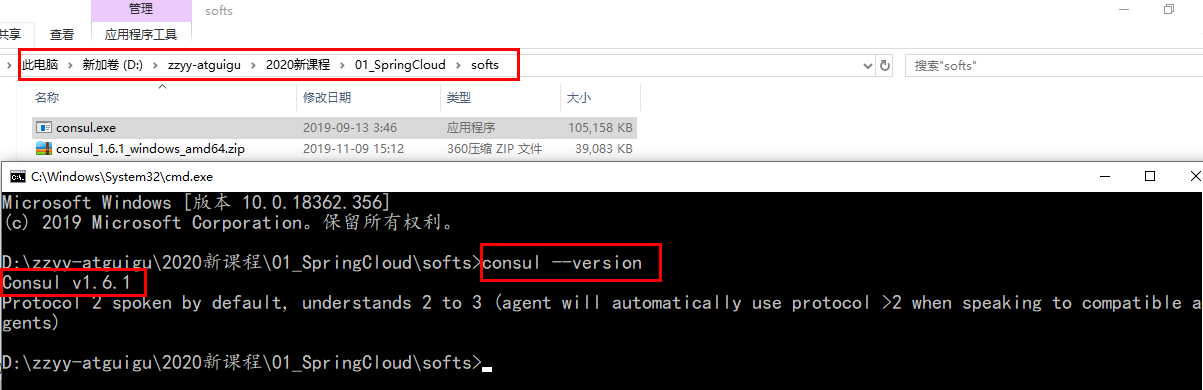
官网安装说明 https://learn.hashicorp.com/consul/getting-started/install.html
下载完成后只有一个consul.exe文件,硬盘路径下双击运行,查看版本号信息
使用开发模式启动
consul agent -dev
通过以下地址可以访问Consul的首页:http://localhost:8500
结果页面
sudo yum install -y yum-utilssudo yum-config-manager --add-repo https://rpm.releases.hashicorp.com/RHEL/hashicorp.reposudo yum -y install consul
服务提供者
新建Module支付服务provider8006 cloud-providerconsul-payment8006
pom:
<dependencies><!--SpringCloud consul-server --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-consul-discovery</artifactId></dependency><!-- SpringBoot整合Web组件 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies>
yml:
###consul服务端口号server:port: 8006spring:application:name: consul-provider-payment####consul注册中心地址cloud:consul:host: localhostport: 8500discovery:#hostname: 127.0.0.1service-name: ${spring.application.name}
启动类:
@SpringBootApplication@EnableDiscoveryClientpublic class PaymentMain8006 {public static void main(String[] args) {SpringApplication.run(PaymentMain8006.class, args);}}
业务类Controller
@RestControllerpublic class PaymentController {@Value("${server.port}")private String serverPort;@GetMapping("/payment/consul")public String paymentInfo() {return "springcloud with consul : " + serverPort + "\t\t" + UUID.randomUUID().toString();}}
验证测试
http://localhost:8006/payment/consul

服务消费者
pom:
<dependencies><!--SpringCloud consul-server --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-consul-discovery</artifactId></dependency><!-- SpringBoot整合Web组件 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency></dependencies>
yml:
###consul服务端口号server:port: 80spring:application:name: consul-consumer-order####consul注册中心地址cloud:consul:host: localhostport: 8500discovery:#hostname: 127.0.0.1service-name: ${spring.application.name}
启动类:
@SpringBootApplication@EnableDiscoveryClientpublic class OrderConsulMain80 {public static void main(String[] args) {SpringApplication.run(OrderConsulMain80.class,args);}}
配置bean:
@Configurationpublic class ApplicationContextBean {@Bean@LoadBalancedpublic RestTemplate getRestTemplate() {return new RestTemplate();}}
controller:
@RestControllerpublic class OrderConsulController{//consul-provider-paymentpublic static final String INVOKE_URL = "http://consul-provider-payment";@Autowiredprivate RestTemplate restTemplate;@GetMapping(value = "/consumer/payment/consul")public String paymentInfo(){String result = restTemplate.getForObject(INVOKE_URL+"/payment/consul", String.class);System.out.println("消费者调用支付服务(consule)--->result:" + result);return result;}}
验证测试:
http://localhost:8006/payment/consul
访问测试地址:
http://localhost/consumer/payment/consul

三个注册中心异同点
CAP:
C:Consistency(强一致性)A:Availability(可用性)P:Partition tolerance(分区容错性)CAP理论关注粒度是数据,而不是整体系统设计的策略
经典CAP图
最多只能同时较好的满足两个。CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三 大类:CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。CP - 满足一致性,分区容忍必的系统,通常性能不是特别高。AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
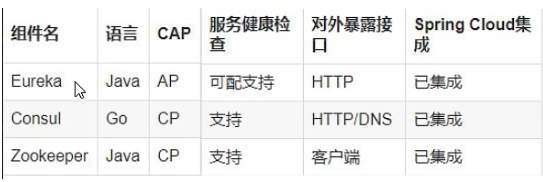
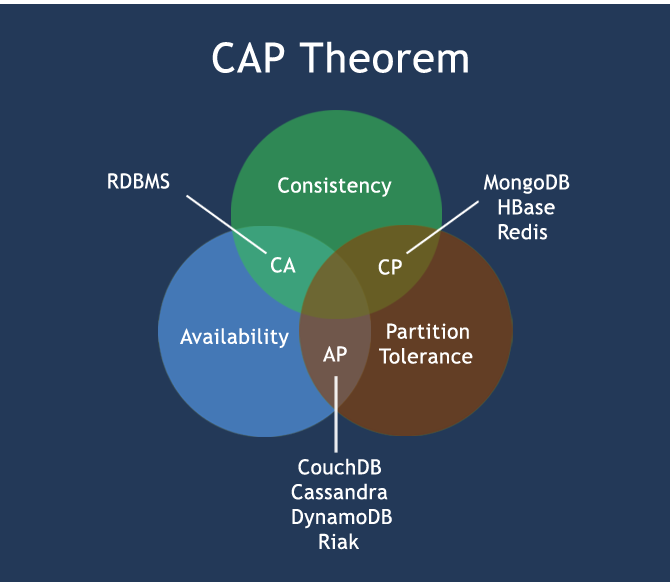
AP(Eureka)
AP架构
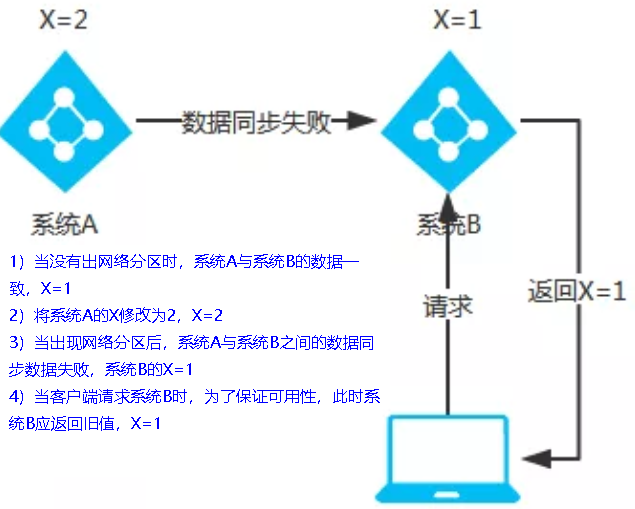
当网络分区出现后,为了保证可用性,系统B可以返回旧值,保证系统的可用性。
结论:违背了一致性C的要求,只满足可用性和分区容错,即AP
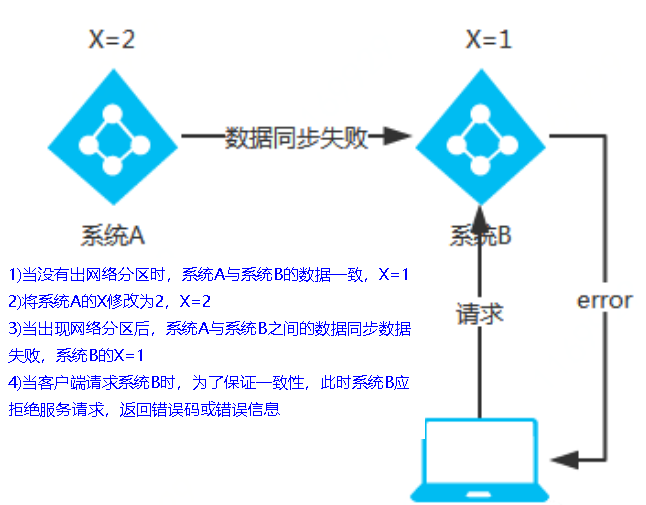
CP(Zookeeper/Consul)
CP架构
当网络分区出现后,为了保证一致性,就必须拒接请求,否则无法保证一致性
结论:违背了可用性A的要求,只满足一致性和分区容错,即CP
五、Ribbon
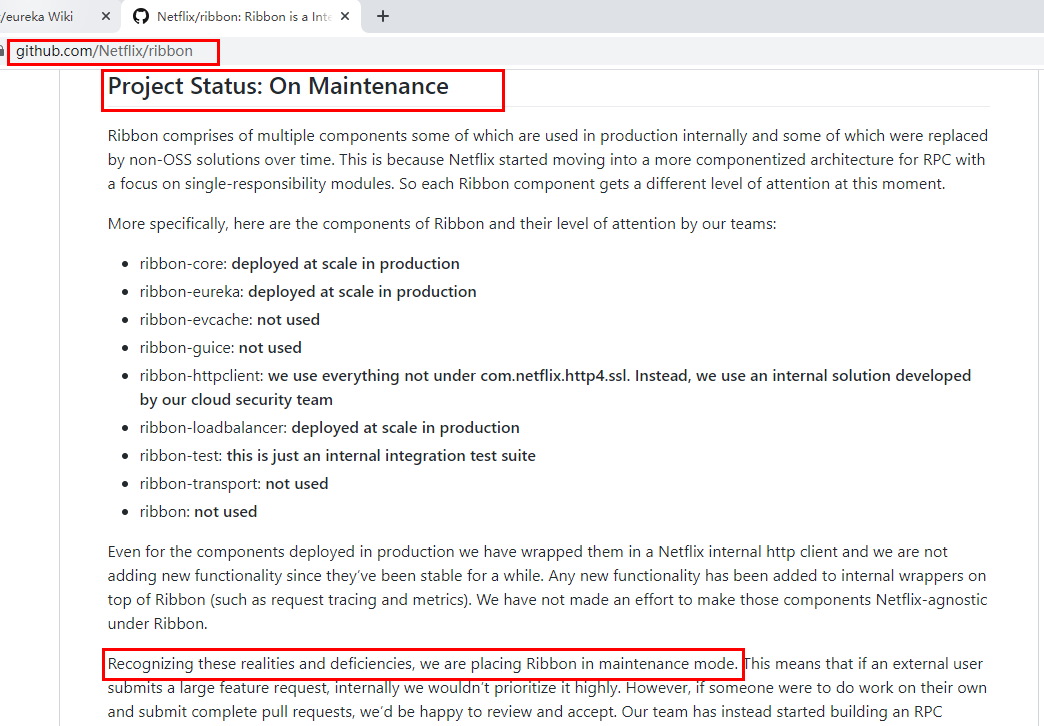
Spring Cloud Ribbon是基于Netflix Ribbon实现的一套客户端负载均衡的工具。
简单的说,Ribbon是Netflix发布的开源项目,主要功能是提供客户端的软件负载均衡算法和服务调用。Ribbon客户端组件提供一系列完善的配置项如连接超时,重试等。简单的说,就是在配置文件中列出Load Balancer(简称LB)后面所有的机器,Ribbon会自动的帮助你基于某种规则(如简单轮询,随机连接等)去连接这些机器。我们很容易使用Ribbon实现自定义的负载均衡算法。
官网资料 https://github.com/Netflix/ribbon/wiki/Getting-Started
Ribbon目前也进入维护模式
未来替换方案
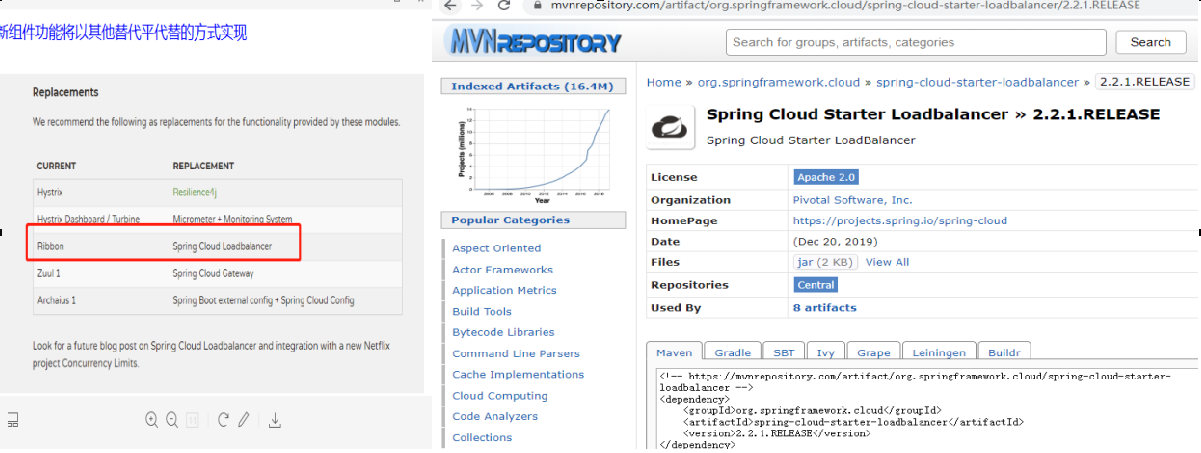
能干嘛
LB(负载均衡)
LB负载均衡(Load Balance)是什么
简单的说就是将用户的请求平摊的分配到多个服务上,从而达到系统的HA(高可用)。常见的负载均衡有软件Nginx,LVS,硬件 F5等。
Ribbon本地负载均衡客户端 VS Nginx服务端负载均衡区别 Nginx是服务器负载均衡,客户端所有请求都会交给nginx,然后由nginx实现转发请求。即负载均衡是由服务端实现的。
Ribbon本地负载均衡,在调用微服务接口时候,会在注册中心上获取注册信息服务列表之后缓存到JVM本地,从而在本地实现RPC远程服务调用技术。
集中式LB
即在服务的消费方和提供方之间使用独立的LB设施(可以是硬件,如F5, 也可以是软件,如nginx), 由该设施负责把访问请求通过某种策略转发至服务的提供方;
进程内LB
将LB逻辑集成到消费方,消费方从服务注册中心获知有哪些地址可用,然后自己再从这些地址中选择出一个合适的服务器。
Ribbon就属于进程内LB,它只是一个类库,集成于消费方进程,消费方通过它来获取到服务提供方的地址。
前面我们碰到过了80通过轮询负载访问8001/8002
一句话 负载均衡+RestTemplate调用
Ribbon负载均衡演示
架构说明
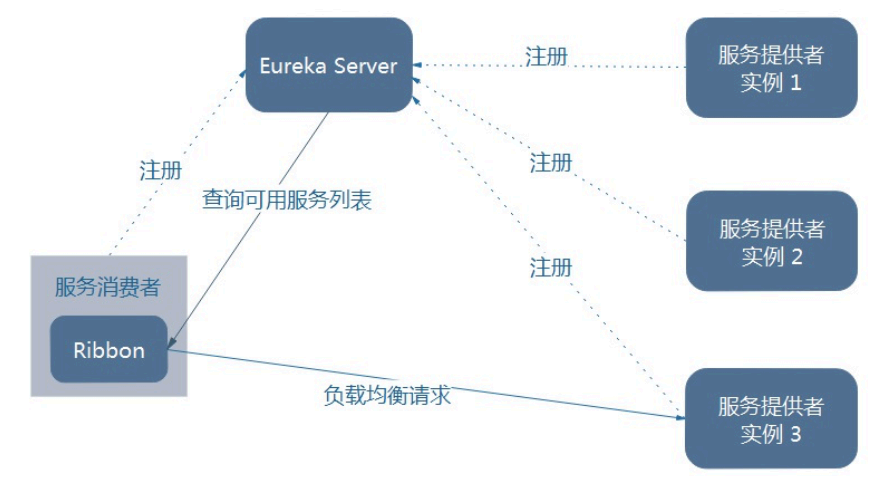
总结:Ribbon其实就是一个软负载均衡的客户端组件,
他可以和其他所需请求的客户端结合使用,和eureka结合只是其中的一个实例。
pom:
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-ribbon</artifactId></dependency>
之前写样例时候没有引入spring-cloud-starter-ribbon也可以使用ribbon,
二说RestTemplate的使用
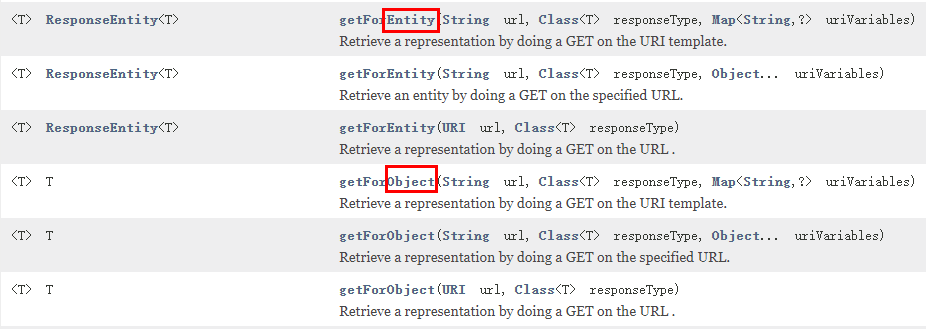
getForObject方法/getForEntity方法
返回对象为响应体中数据转化成的对象,基本上可以理解为Json

返回对象为ResponseEntity对象,包含了响应中的一些重要信息,比如响应头、响应状态码、响应体等

postForObject/postForEntity

GET请求方法
<T> T getForObject(String url, Class<T> responseType, Object... uriVariables);<T> T getForObject(String url, Class<T> responseType, Map<String, ?> uriVariables);<T> T getForObject(URI url, Class<T> responseType);<T> ResponseEntity<T> getForEntity(String url, Class<T> responseType, Object... uriVariables);<T> ResponseEntity<T> getForEntity(String url, Class<T> responseType, Map<String, ?> uriVariables);<T> ResponseEntity<T> getForEntity(URI var1, Class<T> responseType);
POST请求方法
<T> T postForObject(String url, @Nullable Object request, Class<T> responseType, Object... uriVariables);<T> T postForObject(String url, @Nullable Object request, Class<T> responseType, Map<String, ?> uriVariables);<T> T postForObject(URI url, @Nullable Object request, Class<T> responseType);<T> ResponseEntity<T> postForEntity(String url, @Nullable Object request, Class<T> responseType, Object... uriVariables);<T> ResponseEntity<T> postForEntity(String url, @Nullable Object request, Class<T> responseType, Map<String, ?> uriVariables);<T> ResponseEntity<T> postForEntity(URI url, @Nullable Object request, Class<T> responseType);
Ribbon核心组件IRule
IRule:根据特定算法中从服务列表中选取一个要访问的服务

1、com.netflix.loadbalancer.RoundRobinRule——轮询
2、com.netflix.loadbalancer.RandomRule——随机
3、com.netflix.loadbalancer.RetryRule——先按照RoundRobinRule的策略获取服务,如果获取服务失败则在指定时间内会进行重试,获取可用的服务
4、WeightedResponseTimeRule——对RoundRobinRule的扩展,响应速度越快的实例选择权重越大,越容易被选择
5、BestAvailableRule——会先过滤掉由于多次访问故障而处于断路器跳闸状态的服务,然后选择一个并发量最小的服务
6、AvailabilityFilteringRule——先过滤掉故障实例,再选择并发较小的实例
7、ZoneAvoidanceRule——默认规则,复合判断server所在区域的性能和server的可用性选择服务器
如何替换
修改cloud-consumer-order80
注意配置细节
官方文档明确给出了警告:
这个自定义配置类不能放在@ComponentScan所扫描的当前包下以及子包下,
否则我们自定义的这个配置类就会被所有的Ribbon客户端所共享,达不到特殊化定制的目的了。
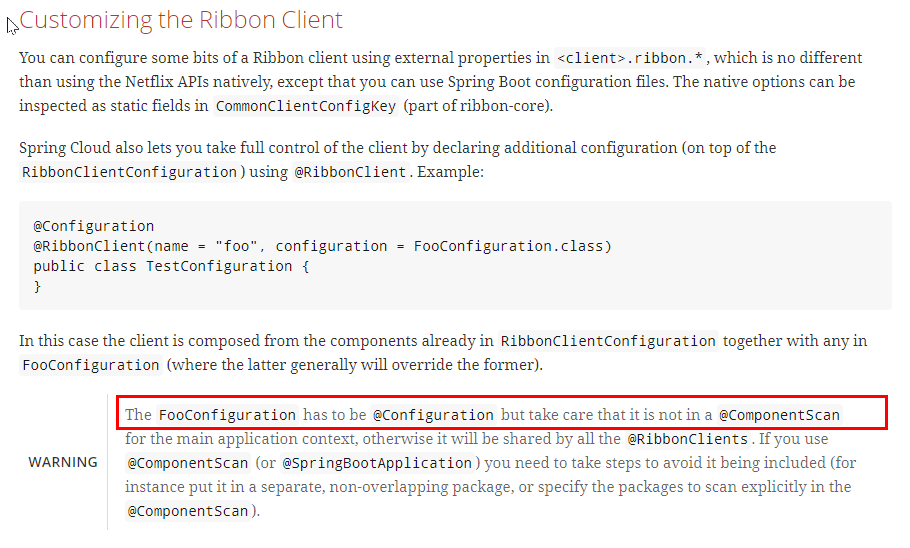
新建package —> com.atguigu.myrule
上面包下新建MySelfRule规则类
@Configurationpublic class MySelfRule{@Beanpublic IRule myRule(){return new RandomRule();//定义为随机}}
主启动类添加@RibbonClient
@SpringBootApplication@EnableEurekaClient@RibbonClient(name = "CLOUD-PAYMENT-SERVICE",configuration=MySelfRule.class)public class OrderMain80{public static void main(String[] args){SpringApplication.run(OrderMain80.class,args);}}
测试
http://localhost/consumer/payment/get/31
Ribbon负载均衡算法
原理
负载均衡算法:rest接口第几次请求数 % 服务器集群总数量 = 实际调用服务器位置下标 ,每次服务重启动后rest接口计数从1开始。
List instances = discoveryClient.getInstances(“CLOUD-PAYMENT-SERVICE”);
如: List [0] instances = 127.0.0.1:8002
List [1] instances = 127.0.0.1:8001
8001+ 8002 组合成为集群,它们共计2台机器,集群总数为2, 按照轮询算法原理:
当总请求数为1时: 1 % 2 =1 对应下标位置为1 ,则获得服务地址为127.0.0.1:8001
当总请求数位2时: 2 % 2 =0 对应下标位置为0 ,则获得服务地址为127.0.0.1:8002
当总请求数位3时: 3 % 2 =1 对应下标位置为1 ,则获得服务地址为127.0.0.1:8001
当总请求数位4时: 4 % 2 =0 对应下标位置为0 ,则获得服务地址为127.0.0.1:8002
如此类推……
RoundRobinRule源码
手写
自己试着写一个本地负载均衡器试试
7001/7002集群启动
8001/8002微服务改造
controller:
@RestController@Slf4jpublic class PaymentController{@Value("${server.port}")private String serverPort;@Resourceprivate PaymentService paymentService;@Resourceprivate DiscoveryClient discoveryClient;@PostMapping(value = "/payment/create")public CommonResult create(@RequestBody Payment payment){int result = paymentService.create(payment);log.info("*****插入操作返回结果:" + result);if(result > 0){return new CommonResult(200,"插入成功,返回结果"+result+"\t 服务端口:"+serverPort,payment);}else{return new CommonResult(444,"插入失败",null);}}@GetMapping(value = "/payment/get/{id}")public CommonResult<Payment> getPaymentById(@PathVariable("id") Long id){Payment payment = paymentService.getPaymentById(id);log.info("*****查询结果:{}",payment);if (payment != null) {return new CommonResult(200,"查询成功"+"\t 服务端口:"+serverPort,payment);}else{return new CommonResult(444,"没有对应记录,查询ID: "+id,null);}}@GetMapping(value = "/payment/discovery")public Object discovery(){List<String> services = discoveryClient.getServices();for (String element : services) {System.out.println(element);}List<ServiceInstance> instances = discoveryClient.getInstances("CLOUD-PAYMENT-SERVICE");for (ServiceInstance element : instances) {System.out.println(element.getServiceId() + "\t" + element.getHost() + "\t" + element.getPort() + "\t"+ element.getUri());}return this.discoveryClient;}@GetMapping(value = "/payment/lb")public String getPaymentLB(){return serverPort;}}
80订单微服务改造
1、ApplicationContextBean去掉注解@LoadBalanced
@Configurationpublic class ApplicationContextBean{@Bean//@LoadBalancedpublic RestTemplate getRestTemplate(){return new RestTemplate();}}
2、LoadBalancer接口
public interface LoadBalancer{ServiceInstance instances(List<ServiceInstance> serviceInstances);}
3、MyLB
@Componentpublic class MyLB implements LoadBalancer{private AtomicInteger atomicInteger = new AtomicInteger(0);public final int getAndIncrement(){int current;int next;do{current = this.atomicInteger.get();next = current >= 2147483647 ? 0 : current + 1;} while(!this.atomicInteger.compareAndSet(current, next));System.out.println("*****next: "+next);return next;}@Overridepublic ServiceInstance instances(List<ServiceInstance> serviceInstances){int index = getAndIncrement() % serviceInstances.size();return serviceInstances.get(index);}}
4、OrderController
@RestControllerpublic class OrderController{//public static final String PAYMENT_SRV = "http://localhost:8001";public static final String PAYMENT_SRV = "http://CLOUD-PAYMENT-SERVICE";@Resourceprivate RestTemplate restTemplate;//可以获取注册中心上的服务列表@Resourceprivate DiscoveryClient discoveryClient;@Resourceprivate LoadBalancer loadBalancer;@GetMapping("/consumer/payment/create")public CommonResult<Payment> create(Payment payment){return restTemplate.postForObject(PAYMENT_SRV+"/payment/create",payment,CommonResult.class);}@GetMapping("/consumer/payment/get/{id}")public CommonResult<Payment> getPayment(@PathVariable("id") Long id){return restTemplate.getForObject(PAYMENT_SRV+"/payment/get/"+id,CommonResult.class);}@GetMapping("/consumer/payment/getForEntity/{id}")public CommonResult<Payment> getPayment2(@PathVariable("id") Long id){ResponseEntity<CommonResult> entity = restTemplate.getForEntity(PAYMENT_SRV+"/payment/get/"+id, CommonResult.class);if(entity.getStatusCode().is2xxSuccessful()){return entity.getBody();}else {return new CommonResult(444, "操作失败");}}@Resourceprivate LoadBalancer loadBalancer;@GetMapping("/consumer/payment/lb")public String getPaymentLB(){List<ServiceInstance> instances = discoveryClient.getInstances("CLOUD-PAYMENT-SERVICE");if(instances == null || instances.size()<=0) {return null;}ServiceInstance serviceInstance = loadBalancer.instances(instances);URI uri = serviceInstance.getUri();return restTemplate.getForObject(uri+"/payment/lb",String.class);}}
5、测试

若有收获,就点个赞吧
0 人点赞
