一 JVM必会知识
1.1 类的加载过程
jvm 是 读取字节码文件、执行字节码文件中的指令 jvm读取字节码文件过程就被称为JVM类加载过程
存放在方法区中。
类的加载被分为5个部分
加载 、验证 、准备、解析、初始化、使用、卸载
1.2 双亲委派模型
如果一个类加载器收到类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派
给父类加载器完成。每个类加 载器都是如此,只有当父加载器在自己的搜索范围内找不到指定的
类时(即 ClassNotFoundException),子加载器才会尝试自己去加载。
1.3 类的加载器
bootstrap类加载器
extension类加载器
Application类加载器
Custom自定义加载器
1.4 JVM内存模型
本地栈 :native修饰的方法 一般都是由C语言
虚拟机栈:用来存储方法运行时,局部变量
pc计数器: 记录线程执行行数。
堆:引用类型的对象 新生代 和老年代 持久代 在新生代中又划分ende 和 幸存区 —minjorGC在新生代
和 ManjorGC 在老年代。
元空间 或者 方法区:
1.5 堆内存的分析
一般java中堆划分为新生代 和老年代,这样根据各个年代的特点进行垃圾回收算法,因为新生代中的对象存活率低,一般都是采用复制算法进行垃圾回收,然而在老年代中对象的存活率较高。一般采用标记清除和标记整理算法进行垃圾回收。
在新生代中有划分为1个Eden区和2个Survivor 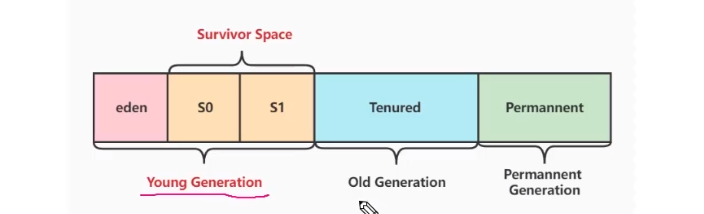
在HotSpot虚拟机中,eden和survivor占比8:1 eden占新生代80%;
1.6 方法区和元空间
1.7 回收期:G1和CMS
1.8 回收算法
第一种:标记-清除 :
GC分为两个部分,标记和清除,首先标记所有可回收的对象,在标记完成后统一回收被标记的对象。同时会产生不连续内存碎片。过多会导致程序运行时需要分配较大对象,无法找到足够的连续内存,而不得已再次触发GC。
第二种:复制
将内存按容量划分两块,每次只是用一块,当一块内存使用完之后,就会将存活的对象copy到另一个内存上,然后在把已使用的内存空间一次清理掉。
第三种:标记-整理
首先标记可回收对象,再将存活对象都向一端移动,然后在清理掉边界以外的内存。避免标记-清除法问题,也避免复制算法问题。一般年轻代中执行GC后,会有少量的对象存活,就会选择复制算法。而老年代对象存活高。
第四种:分代收集算法
当前商业虚拟机垃圾回收都大多采用分代收集算法,只是根据对象存活生命周期进行分为新生代 和老年代
在新生代中可以发现大多对象死去,只有少量存活使用复制算法。只需要付出少量的存活对象复制成本。但是老年代对象存活高,使用标记清除 和标记整理进行回收。
1.9 垃圾判定(程序计数法和可达性分析算法)或者怎么判断对象死去?
引用计数法:给每个对象设置一个引用计数器,每当有一个地方引用这个对象时,就将计数器加一,引用失效就减一。当一个对象计数器减到为零时,说明对象没有引用。将会被垃圾回收。但是很难解决对象之间循环引用问题。
可达性分析算法:从一个被称为GC roots的对象开始向下搜索,如果一个对象到GC没有引用链相连时,则说明此对象不可用。本地方法栈,常量。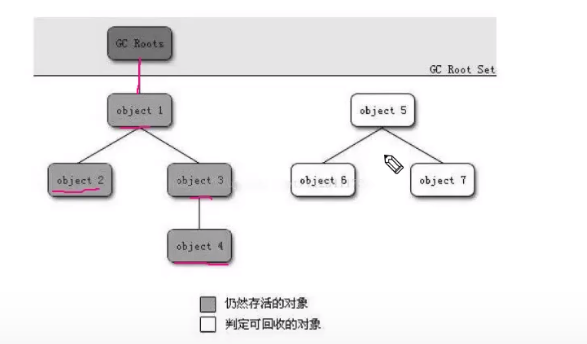
2.0 HotSpot GC分类?
1 Partial GC:并不搜集整个堆的模式
Young GC 只收集新生代
Old GC只收集老年代
Mixed GC 收集整个新生代和部分老年代的GC
2 Full GC /Major GC 收集整个GC堆模式 老年代 新生代 永久代
2.1 四大引用;强引用,弱引用,虚引用,软引用
强引用:在程序代码中经常使用,类似 使用new关键创建对象,只要强引用一直在,那么垃圾回收器就不会回收。
软引用:描述一些还有用但非必须对象,SoftReference类来实现的。在系统中发生内存溢出,就会被回收对象进行第二次回收。
弱引用:用来描述非必需的对象,使用weakreference来实现,被弱引用关联对象只能生存下一次垃圾回收之前
虚引用:是最弱的一种关系,为对象设置虚引用的唯一id来判定这个对象被垃圾回收器进行通知。
二 基础知识
2.1 OOP(面向对象)
封装、继承、多态、抽象类
封装是把一个类中相同的代码块进行抽取成一个静态方法,供类中所有需要用的方法使用,简化代码,提高开发效率
继承:是发生在父子类中,是指父类中的方法不能满足子类的需求,在子类从新定义的方法,便于扩展。解耦。
多态:不同类对象调用同一个类,会产生不同的结果。多态要有动态绑定 有继承 有重写,权限修饰符不低父类。
抽象:将一类对象的特征抽取出来,只关注对象的属性和行为。
2.2 关键字(final、static、this、super等)
final关键字:
被final修饰的变量,不能被改变。
被final修饰的方法,不能被重载
被final修饰的类,不能被重写
被final修饰的常量,jvm就尝试内联,存在常量池中。
被final修饰引用对象,引用对象地址不能改变,对象可以改变。
static:
static可以修饰方法,代码块,变量,类
static修饰方法静态方法,可以使用类.方法名进行调用。
static修饰代码块 被称为静态代码块,实例化一次。常用作优化的作用。
static修饰变量 属于类变量。在整个类中全局共享。
static修饰的类,静态类,不能实例化。随这类的加载而加载。
this:
this是指当前类对象。this需要定义方法首位,
this可以引用本类构造方法。
this可以用在有参构造方法中形参和成员变量重名使用this区分
super:
super定义在方法中放在首位。
super是指当前类的父类的引用。
super用来区分子类成员方法,变量 跟父类重名是进行区分
super也可以引用父类构造函数
this 和super 不能同时出现。
2.3 异常、常用类(String)
异常
1 常见的异常有运行时异常,编译时异常。
运行时异常有 NullExecption,栈溢出异常,类转换器异常。除数不能为0异常等等。
编译时异常:io异常,sql异常,找不到类途径异常。EOF异常
使用try-catch-finally 进行异常朴拙异常。
常用类:
2 stringbuilder 、stringbuffter 都是可变长字符串 stringbuilder线程不安全安全,效率高。
在进行字符串进行拼接时 直接使用加号就可以实现。可变字符串中定义很对静态放法,字符串进行反转,大小写转换等。
3 包装类 实现装箱和拆箱之间的转换
4 Math中全部是静态方法 可以使用类.方法进行调用
绝对值,最大值,最小值,向上取整,取整,随机数,四舍五入
5 random类 这个类是专门处理随机数的,提供了大量的随机数的方法
2.4 & 和&&的区别?
首先一个&为按位与运算符,在表达式中不管左右是否为false 都要执行后面的,只要有一个为false都为false。
二个&&为短路与运算,一般在表达式中当前面的条件为true时,可以执行后面的条件表达式 。只要有一个为false,都为false。
2.5 String类型是否可以继承?
不可以,因为String这个类被final修饰了,一旦一个类被final修饰,就不能被继承。
2.6 == 和equals区别?
使用== 是比较基本数据类型,是比较值是否相等。也可以比较实例是不是指向同一个内存空间。
然而:equals是一个方法,只有对象才可以调用这个方法,默认是用来比较两个对象的地址是否相等。
2.7 静态类型有什么特点
静态属性:随着类的加载而加载,不是属于某个对象,而是作用于整个类。
静态方法:可以直接使用类名.方法名进行调用。
静态类:不能直接创建,不能被继承。
2.8 Object中有哪些公共方法
Object是所有类的父类,Object中有clone保护方法,实现对象之间的浅复制。toString()返回对象的字符串表达形式。wait()是导致线程进行等待,直到另一个线程该对象notify()或者notifyall方法被幻想。hashcode 返回对象的哈希值码。finalize实现垃圾收集确定不在有改对象引用,然后在执行这个方法进行对象回收。
2.9 string stringBuilder stringBuffter区别?
string是不可变字符串,当进行字符串进行拼接,会产生两个对象引用地址。带给堆中压力
stringbuilder 是可变字符串,直接在后面追加拼接条件。线程不安全,但是执行效率高。
stringbuffter 是可变字符串,直接在后面追加拼接条件。线程安全,但执行效率低。
2.10深拷贝和浅拷贝区别?
浅拷贝:对于基本数据类型 ,直接复制数据值,对于引用数据类型,是只复制对象引用地址,新旧指向同一个地址,那么修改其中内容,那么随之改变。
深拷贝:对于基本数据类型,直接复制数据值,对于引用数据类型,新开辟一个空间,复制内存空间跟旧的一样大,其中修改中内容,之间不会影响的。
2.11 并发 和并行之间区别?
并发:是指两个或者多个事件同一时间间隔发生。
并行:是指两个或者多个时间同一时刻发生。
2.12 构造器是否可以被重写?
2.13 单例模式有什么好处?
单例就是 一个类创建出一个对象,这个对象可以在整个系统中去调用使用,减少资源的占用,提高工作效率,
单例模式:先私有化无参构造函数,在创建私有化静态对象,然后在创建一个公开类的方法。
常见单例模式有:饿汉式 懒汉式(线程不安全 加java关键字) 静态内部内
三 集合
3.1 说一说list set map的特点
首先list在添加元素到集合中有序元素可以重复。set则是无序元素不可以重复。map是采用基于key-value进行存储元素,key不可以重复,值可以重复。
3.2 谈一谈ArrayList的实现原理
arraylist低层是基于数组实现的。jdk1.7 默认通过初始化默认为10的容器。在jdk1.8 默认初始容器为0 一旦添加元素数量大于默认的容器初始值,就是自动进行扩容,最小容量大于元素长度 会调用grow方法,扩容是原来的1.5倍。基于数组进行存储数据肯定有下标,所以查询快,增删慢。一旦调用add添加元素,首先ensureCapacityInternal,然后调用calculateCapacity 在静态方法中去判断 elementData是否为空,等于空就去取初始化容器最大随机数进行生成空间容器 把元素进行存放。
3.3 谈一谈 LinkedList的实现原理?
LinkedList是双向链表实现的。默认size大小是0 ,Node类型first 和last,first指向链表中第一个数据,last是执向链表最后一个数据。在LinkedList添加元素调用addFirst方法,会去判断添加元素的前节点跟上一个后节点进行连接,然后添加在链表中。查询慢 但是增删快。
3.4 Hashtable 和Hashmap的区别
Hashtable线程安全,但是不允许有空值存在,但是hashmap线程不安全,可以存在空值。遍历方式不同。
3.5 谈一谈hashmap的实现原理
hashmap低层是基于数组加双向链表,当向hashmap进行存储元素,会将存储数据封装一个Entry数组,数组默认初始化长度1<<4 16 ,当数组元素容量以存满,就会实现进行链表进行存储。在jdk1.7 中,会在Entry对象中计算hash值 和容器初始化值进行&运算,计算存储的位置 然后采用头插法进行实现。在1.8之后 采用红黑树进行存储链表数据。hashmap中put添加方法会有返回值。一旦key值一样就会发生覆盖的状态。采用链地址法解决冲突问题。默认扩充因子是0.75f。
3.6 你对ConcurrentHashmap了解吗?为什么线程安全?
ConcurrentHashmap 使用锁分段技术实现在jdk1.7 ,将一段一段数据存储匹配一把锁,这样就避免多个线程去访问同一个数据,避免的线程阻塞。保证的线程安全。jdk1.8使用cas算法。属于乐观锁,ConcurrentHashmap是由Segment数组结构和Entry数组组成。Segment是可重入锁。HashEntry主要用来存数据。所以每个Segment会守护一个HashEntry数组里元素,确保修改里面的数据,必须先获取Segment锁。
线程安全:至于为什么安全,我没有往这一方面了解。
3.7 hash冲突解决方式?
1 开放定定址法:一旦所求hash值在数组中存放有数据,那么就是用向后移动法,直到找到数组中有空位进行插入
2 使用在hash值法:所计算出的hash值在数组存储下标存在,然后在对hash的值进行hash。
四 线程
4.1 线程创建的4中方式?
第一种 直接使用继承Thread,重写run方法。
第二种:直接去实现Callable接口,并重写里面的call方法,有返回值。
第三种:直接去实现Runnable接口,并重写里面的run方法,没有返回值。
第四种:直接使用线程池,重要里面的七大参数,核心线程池数。ThreadPoolExecutor 对象有7大参数
核心池大小,最大容纳线程数,线程活跃时间,时间单位,缓存队列,线程工厂,拒绝策略。
4.2 线程交互(wait\notify)
线程中调用wait方法,一旦线程启动起来,执行到wait()就会让线程进行等待状态,直到另一个线程去调用notify方法,必须是等待的对象,这样才能幻想等待幻醒的线程,往下执行,执行线程结束。销毁。wait()和notify()和notifyAll()一起使用。
4.3 生命周期
线程的生命周期有5种:新建状态,就绪状态,运行状态,阻塞状态,销毁。
新建状态:一旦创建Thread对象。就会进入新建状态。
就绪状态:然后使用线程对象去调用start()方法,让线程进入就绪状态。
运行状态:运行状态是通过CPU进行调用。
阻塞状态:一旦线程在运行中,遇到wait()或者sleep()或者join()就会让线程让出其它线程执行,自己处于 阻塞状态。直到另一个线程去唤醒就可以往下执行。
销毁状态:当线程执行完毕,该线程声明周期就结束了。
五 jdk1.8新特性
5.1 请问接口中可以定义带有方法体的方法吗 接口可以实例化对象吗?
可以,因为jdk1.8声明有,在接口中定义带有方法体的方法,一般权限修饰符被default修饰。这就是jdk1.8的新特性。 接口实例化对象是匿名内部类实现的。使用它实例化对象必须要重写接口的方法体。
5.2 在项目中使用过函数式编写代码吗?
使用过。一般在集合遍历中使用lambol表达式使用,这样使用非常高效,简化代码。
5.3 函数式接口如何定义?
在自定义接口上添加@FunctionalInterface 注解 要求这个函数式接口里必须定义一个方法体。然后在使用lambal表达式创建定义的接口实例化。
5.4 jdk1.8 四大核心函数式接口?
消费型:有参无返回值。使用方式:(s)->{ serr….(“ “)};
供给型:无参有返回值。
函数型:有参有返回值
断言型:有参数返回值boolean
5.5 StreamApi 增强对集合的增强操作
Stream它专注操作对集合对象的增强高效操作。
方式一:对数组操作时。首先需要定义数组,然后使用Arrays去调用stream方法 改方法有参数 有返回值。获得Stream数组,然后在进行遍历就可以得到数组中定义数字。
方式二:操作集合。跟上面的数组操作一样。
中间操作: 会返回一个新的Stream对象,可以继续执行下一个中间操作filter:过滤,符合条件的数据被留下来生成一个新Streamsorted:排序,对Stream中元素进行排序,排序后的的数据生成一个新Streamdistinct:去掉重复值,将不重复的元素生成一个新的Streammap: map接口一个函数作为参数,该函数作用用于流每一个元素遍历遍历流中每一个元素,生成一个新Stream对象flatMap: 将每一个元素被拆分一个新的流limit:截断流,返回一个不超过给定长度的新Stream对象终端操作: 返回的结果,终端操作此流的生命周期结束。forEach() 遍历流中每一个元素,会关闭流findFirst()findAny()allMatch 要求所有Stream中所有元素都满足条件才返回truenoneMatch 要求所有的元素都不满足条件才返回trueanyMatch, 只要有1个元素满足就返回truereduce: 把Stream中元素按照一种规则串起来字符串拼接,数值类型元素avg,sum,max,mincount : 返回Stream中元素的个数collect:实际项目中用的很多,将Stream转换成数组,List、Set、Stack等等Map集合进行分组groupingBy:分组条件
5.6 对stream用过操作数组 集合 去重 排序 倒序
package com.mmc.thread;import com.sun.corba.se.spi.orbutil.threadpool.ThreadPool;import java.util.Arrays;import java.util.concurrent.ThreadPoolExecutor;import java.util.stream.IntStream;import java.util.stream.Stream;/*** @author mmc* @version 1.0* @date 2022/5/12 23:36*/public class StreamDemo {public static void main(String[] args) {//定义一个数组Integer[] as=new Integer[]{1,2,4,3,6,1,8,4,1};//实现数组去重Stream<Integer>stream = Arrays.stream(as).distinct();//实现数组去重 和升序排序Stream<Integer> sorted = Arrays.stream(as).sorted().distinct();//实现数组倒序排序 实现comparator里面有个compare进行对象比较Stream<Integer> sorted = Arrays.stream(as).sorted((s, s1) -> {return (s1 - s);}).distinct();sorted.forEach(System.out::println);}}
5.7Date API
Java 8 在包java.time下包含了一组全新的时间日期API。新的日期API和开源的Joda-Time库差不多,但又不完全一样,下面的例子展示了这组新API里最重要的一些部分:
这一部分我没过深的了解。我使用过注解定义时间格式。
5.8 Annotation 注解
六 数据库相关面试题
6.1 数据库的存储引擎 Innodb 和mylsam的区别?
InnoDB存储引擎支持事务,支持行锁定和外键,InnoDB给MYSQL提供了具有提交,回滚和崩溃。
然而mylsam MyISAM拥有较高的插入、查询速度,但不支持事物和外键。
6.2 事务(ACID)特征?
事务具有原子性,一致性,隔离性,持久性。
原子性:要么同时成功,要么同时失败。
一致性:在事务开启之前和事务结束,保证添加的数据到数据库中完整性没有波坏。
隔离性:多个事务操作数据库修改和读写的能力;事务具有隔离级别:读以提交,读未提交,可重复读,串行化
持久性:操作数据库中数据存储在磁盘上,是永久存储。
6.3 脏读、幻读、不可重复读
脏读:就是事务A对数据进行修改,但是没有提交到数据中 然而事务B就从数据库读取这个修改后数据。隔离级别属于 读未提交。
幻读:就是事务1通过查询语句查询出2条数据,然后 事务B又添加一条数据到数据库中,然后事务A查询发现出现3条数据,这就是幻读。隔离级别是 可重复读。
不可重复读:事务A查询一条数据,结果事务没有结束,事务B就修改这条数据信息。导致两次读取数据信息不一致。隔离级别是读以提交。
6.4 什么是索引?
索引就是帮助mysql高效获取数据的基本类型。相当于字典中目录。 create index 索引名 on 主表名加条件字段。
6.4 索引常见类型(聚簇、覆盖、联合索引-最佳左匹配、B+Tree)
我使用索引。直接创建index索引 然后 on 条件是关联这个真实的表。可以通过
6.5 SQL优化(定位-分析-解决)
首先 通过打印日志进行看查询sql耗时多的sql语句,然后在项目中把sql进行分片。
例如代码
public class LogerDemo {Log log= LogFactory.getLog(LogerDemo.class); //创建日志对象@Testpublic void t1(){log.info("输出日志"); //输出日志信息for (int i = 0; i < 20; i++) {System.out.println("第"+i+"的输出信息");}try {System.out.println(9/0);}catch (Exception e){log.error(e.getMessage());}log.info("out the one");}}
sql优化:在where或者order by 设计的列上加索引,
在where条件判断语句中减少null
减少使用in notin 的使用
查询语句中减少* 使用。
6.6 mysql中有些函数 (除聚合函数出外)
七 Spring框架
7.0 spring的启动执行流程
首先先使用类加载器加载class配置文件到内存,然后初始化所有类,然后给成员变量进行复制,
7.1 谈谈对springioc的理解?原理和实现?
springioc是控制反转,以前使用new关键字创建对象,简化传统的创建对象的过程,现在使用注解或者使用xml方式创建对象。依赖注入也可以为对象的属性进行复制操作。比如有参构造。使用注解一般有@componce, @service 等
ioc也是容器,
7.2淡一下spring ioc的底层实现原理?
首先使用new ClassPathXmlApplicationContext去加载spring配置文件,得到ApplicationContext 对象,然后在使用对象去嗲用getbean获取实体类对象,这里是通过反射的方式去获取,然后在执行对象中的定义的方法。
7.3 描述一下bean的生命周期?
7.2 springAop理解?
springAop是一种面向切面编程的思想,就是在业务处理上不改变原有的代码上进行增强处理。采用是一种横切的技术实现的。采用的是动态代理方式进行实现。
AOP的使用场景:参数校验,自定义注解。
Aop相关概念:切面 连接点 通知 切入点表达式,等
代理对象的创建过程(advice,切面,切点)
通过jdk和cglib的方式来生成代理对象。
7.3 Spring 中@Autowire 与@Resource 的区别
Autowire 是spring自带的注解,默认这个依赖对象存在。如果按照type类型注入 。required为false
如果想按照name注入 需要跟required进行联合使用。
resource是jdk带的,默认是按照by-name装配,如果不写就代表类名首字母小写 全了类名称。
如果指定名称:就按照指定名称进行装配
7.4 bean factory 和factorybean区别?
相同点:都是用来创建bean对象。
不同点:使用beanfactory创建对象的要遵守bean的声明周期,太复杂了,所以一般使用factorybean接口,isSingletion表示是否单例创建。
7.5 spring中用到的设计模式?
1 单例模式:bean默认创建是单例模式。
2 工厂模式;beanFactory
3 代理模式:
7.6 spring事务是如何回滚的
spring事务是由aop来实现的,首先要生成具体的代理对象,但是事务不是由aop来实现的,而是通过一个
TransactionIncterptor类中invoke实现。
1 在配置文件中来开启注解扫描机制;
2 连接数据库,关闭自动提交功能,开启事务
3执行具体sql逻辑操作
4 在操作过程中,若执行失败,那么会通过completeTrancationAfteringThrowing进行回滚,使用rollback进行回滚。
7.7说一下spring事务的传播行为 和 隔离级别 ?
传播特性有7种,
REQUIRED(0), required
SUPPORTS(1), supports
MANDATORY(2), mandatory
REQUIRES_NEW(3), requires_new
NOT_SUPPORTED(4), not_supported
NEVER(5), never
NESTED(6); nested
事务的不同分类:支持当前事务,不支持当前事务,嵌套事务。
如果外层是required 内层是 required,required_new nested
如果外层是required_new 内层是 required,required_new nested
如果外层是nested 内层是 required,required_new nested
DEFAULT(-1), default 一般都是使用默认
READ_UNCOMMITTED(1), read_uncommitted 读未提交
READ_COMMITTED(2), read_committed 读已提交
REPEATABLE_READ(4), repeatable_read 可重复读
SERIALIZABLE(8); serializable 串行化
7.8 spring springmvc springboot的区别?
spring是一款轻量级的开源框架,主要的核心是ioc 和aop
springmvc主要解决web开发问题,是基于servlet的一个mvc框架,通过xml配置,统一开发前端视图和后端逻辑。
springboot是是用来解决ssm一些复杂的配置文件,简化开发,
7.9springboot自动装配原理?
首先在springboot启动类中定义 @SpringBootApplication 启动类,里面实现
@SpringBootConfiguration 和@Configuration进行组合 说明这个类是配置类。
@EnableAutoConfiguration 打开自动装配功能。去加载 spring. factory
@ComponentScan 这个注解说明当前类是ioc创建对象。
8.0 springboot自动装配原理实现?
在springboot项目中启动类上有一个@SpringbootApplicaton注解,里面实现了@EnableAutoConfiguration 然后在这个注解里又 跟@Import注解去实现AutoConfigurationImportSelectorl去加载spring.factory需要被自动装配类,然后在返回对象。
8.1 springboot中如何解决跨域问题?
@CrossOrigin //这个注解可以实现跨域问题 直接在控制层类上添加一个注解 就可以实现跨域问题。
8.2 如何在springboot项目中使用log4j日志框架?
springboot项目中提供了日志框架logback,所以我们需要引入log4j,必须先移除logback,然后在导入log4j依赖。就可以直接使用了。
8.3 Spring 中 bean 的作用域
单例模式:singletor
多例模式: prototype
request:
session
application
gloab_serssion
8.4 spring 中的声明周期
八 Redis 面试题
8.1 为什么redis单线程操作速度快
1 它是基于内存操作,
2 在执行命令中是单线程操作
3 基于非阻塞io多路复用。
8.2 Redis低层数据是如何用跳表来存储的
跳表:将有序链表改造成 折半查找,可以进行快速的插入,删除,查找操作。
8.3 redis中如何保证持久化
使用AOF和RDB
RDB:在指定时间间隔将内存中数据快照写入磁盘中,然后保证数据持久性。
AOF:是以日志形式记录服务器处理的每一个写,删除操作,查询不会记录。以文本记录。
8.4 Redis分布式锁低层如何实现?
1 首先利用setnx来保证,如果key存在可以获取锁,不存在获取不到锁。
2 利用lua脚本来保证多个redis操作的原子性。
3 同时需要考虑锁是否过期,需要一个监听锁是否需要续命。
8.4 Redis和Mysql如何保证数据一致性?
1 使用延迟双删,先删除redis缓存数据,在更新mysql,延迟几百秒进行删除redis缓存数据,这样更新mysql,有其它线程读mysql,把老数据读到redis中,那么也会删除掉,从而保证数据一致性。
8.5 redis如何配置key的过期时间,它的实现原理是什么?
redis设置key的过期时间:expire 、setex
实现原理
1 定期·删除:每隔一段时间,执行一次 删除过期key的操作。
2 懒汉式删除:当使用get getset等指令获取key对应数据,判断key是否过期,过期后,就先把key删除,
8.6 redis有哪些数据结构?分别应用场景?
redis数据结构:string set hash list zset bitmap 地图位置
8.7 redis主从复制的核心原理?
8.8 布隆过滤器原理,优缺点?
位图:int【10】,每个int 类型的整数是4*8=32bit则int【10】有320bit 每个bit非0是1,初始化为0
添加数据:将数据进行hash得到hash值,确定数据在index中的位置,把它改成1 ,
查询数据:hash函数计算得到hash值,对应bit中位置,如果有1 就数据可能在,为0 是不存在。
优点:占内存小 缺点:不能使用布隆过滤器删除数据
8.9 什么是缓存穿透?缓存击穿,缓存雪崩?怎么解决?
1 缓存穿透 是指 redis缓存查不到数据,MySQL中也查不到。
解决方案:1 在业务层进行参数合法性校验,2 在用户操作redis前引入布隆过滤器,判断redis中数据是否存在
2 缓存击穿: redis缓存中没有数据 但是MySQL中有数据,一般出现在存数据初始化,或者key设置有效时间过期,出现问题就是:大量的查询条件不走缓存 直接都从DB本地数据库进行查询,导致DB过多请求造成压力。
解决方案:1设置热点缓存永不过期,可以设置定期更新key
3 缓存雪崩: 缓存大面积过期 导致请求都被转发到DB
解决方案:把缓存的时效时间分散开,在原有基础上设计随机值
8.10 缓存如何回收?
在内存不足的情况下
淘汰机制里不允许淘汰。
通过设置过期key集合。

若有收获,就点个赞吧
0 人点赞
