0 前言
本文将分为两个部分,第一部分介绍gitlabCI相关的内容和实践,第二部分介绍持续集成的思想和个人的一些思考。文中有错误的地方欢迎指正~
文章旨在达到这样的效果,读者看完以后:
- 增长对gitlabCI和持续集成的理解,学习到一些“新知识”、“新观点”;
- 了解gitlabCI和持续集成对快速交付项目的意义;
- 想要进一步学习gitlabCI,并在自己的项目中实践敏捷开发模式下的持续集成。
1 gitlabCI入门和实践
1. 1 gitlabCI是什么
1.1.1 认识gitlabCI
有关gitlabCI相关知识的学习,强烈推荐阅读官方文档:https://docs.gitlab.com/ee/ci/ 如果你第一次接触gitlabCI,强烈推荐阅读官方quick start文档:https://docs.gitlab.com/ee/ci/quick_start/README.html
gitlabCI是GitLab CI/CD的习惯称呼,GitLab CI/CD是GitLab从8.0版本开始内置的一套用于持续集成(Continuous Integration,CI)、持续交付(Continuous Delivery,CD)、持续部署(Continuous Deployment,CD)的工具。
| 步骤 | 构建 | 测试 | 集成 | 测试/类生产部署 | 线上部署 |
|---|---|---|---|---|---|
| 持续集成 | ✅ | ✅ | ✅ | 手动 | 手动 |
| 持续交付 | ✅ | ✅ | ✅ | ✅ | 手动 |
| 持续部署 | ✅ | ✅ | ✅ | ✅ | ✅ |
有关三个持续的区分的讨论,推荐阅读知乎问题:https://www.zhihu.com/question/23444990
总之,gitlabCI是持续集成在真实项目中落地可使用的工具平台之一
以下是一个gitlabCI的基本工作流程,图片来源how-gitlab-cicd-works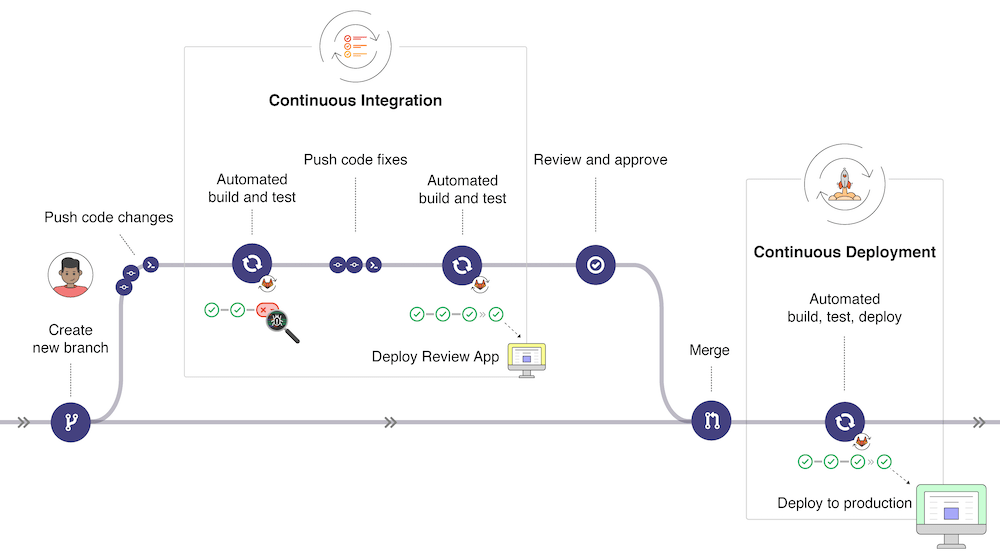
使用gitlabCI后,我们可以实现push代码以后,进行自动化的编译、测试、部署、上线。
实现一站式管理,整个项目过程都可以在gitlabCI一个平台上完成。
下面介绍几个gitlabCI的核心概念。
| Concept | Description |
|---|---|
| Pipelines 流水线/管道 |
Structure your CI/CD process through pipelines. 用于组织持续集成或持续部署的流程。由.gitlab-ci.yml脚本定义,组织的内容为Job,组织形式为Stage。如build → test → deploy |
| Environment variables 环境变量 |
Reuse values based on a variable/value key pair. 定义一些可重用的变量和值 |
| Environments 环境 |
Deploy your application to different environments (e.g., staging, production). 应用部署的不同环境,如测试环境、类生产环境、生产环境等 |
| Job artifacts Job的artifacts(工件) |
Output, use, and reuse job artifacts. 输出、使用或重用一些Job的文件,一般用于在stages之间传递文件以达到缓存效果 |
| Cache dependencies 缓存依赖 |
Cache your dependencies for a faster execution. 缓存一些依赖以获得更快的执行,一般用于缓存一些依赖数据 |
| GitLab Runner GitLab Runner |
Configure your own GitLab Runners to execute your scripts. 执行.gitlab-ci.yml脚本内容的执行器 |
下面仅介绍一下Pipeline和GitLab Runner相关的概念。
1.1.2 Stages(阶段)
Stages是pipeline的子概念,表示Job执行的阶段。每个pipeline都至少定义一个stage。
Stages如何定义?
- 使用stages关键字(全局配置项,即.gitlab-ci.yml脚本的顶级元素),顺序定义一组阶段名称
stages:- build- test- deploy
Stages如何执行?
- Stages存在先后关系,按脚本中的定义从前往后顺序执行
- 当一个Stage开始执行时,同一Stage的所有任务都会执行;如果有多个gitlab runner空闲,它们会并行执行
- 只有前一个Stage的所有任务全部完成,才可能自动执行下一Stage的任务
- 默认情况下,Stage中所有任务执行成功(passed)为完成,有任何任务执行失败(failed)都不会自动进入下一阶段,整个pipeline被标记为失败
Stage可以包含哪些内容?
根据不同项目需求来定义,一般可以包含:
- static_code_analysis 静态代码检查
- compile 编译
- unit_test 单元测试
- build 构建
- package 打包
- deploy 测试环境部署(test_deploy、dev_deploy、staging_deploy等)
- auto_test 自动化测试(api_test、e2e_test、ui_test等)
- code_review 代码review
- prod_deploy/release 线上环境部署/发布
- notify 通知
-
1.1.3 Job(任务)
Job是pipeline的子概念,用于定义在各个阶段中具体执行的内容。每个pipeline都由多个Job从前往后顺序执行组成。
Job如何定义? Job可以指定在一个Stage中执行,若没有定义默认分配为test阶段
- Job由一组配置定义,常用的包括stage、script、before_script/after_script、only/except、tags等,可参考官方文档configuration-parameters
- script(脚本)是Job唯一要求必须包含的配置,script定义了由gitlab-runner执行的shell脚本
myjob:tags:- k8s # 指定使用tag为k8s的runner执行stage:- build # 定义stage为buildscript: # 定义该stage执行的shell脚本- mvn install- mvn buildonly:- master # 只有master分支push commit或merge时执行这个jobcache:key: "$CI_BUILD_REF_NAME"path:- build/ # 以正在构建的branch或tag名称为key,缓存build/目录的内容
Job如何执行?
- 默认情况下,只要进入Job所属的Stage,Job即开始执行
- 可通过灵活定义使Job只在某些条件达到时执行,如when:manual、only:master等
- 已在pipeline中运行过的Job支持在平台上操作手动Retry
已在pipeline中运行过的Job支持通过API调用Retry
1.1.4 Pipeline
一个pipeline即一次任务流程,由自定义的不同阶段(Stage)执行的不同任务(Job)组成。pipeline是最外层的概念。
pipeline如何定义?在一个gitlab repository的根目录下定义一个.gitlab-ci.yml,即定义了该项目的CI pipeline
- gitlab-ci脚本具配置推荐参考官方文档:https://docs.gitlab.com/ee/ci/yaml/README.html
pipeline如何触发?
- 默认情况下,每次提交(Commit)或合并代码(merge)都会触发。如果一次push动作包含多个commit,pipeline自动关联到最新的commit上
- pipeline支持在gitlab平台上手动触发
-
1.1.5 gitlab-runner
gitlab-runner是什么?
gitlab-runner用于执行Job定义的任务,是一群启动在不同机器上的后台服务。
gitlab-runner有2种类型: Shared Runner:所有项目都可以使用,仅系统管理员可创建
- Specific Runner:仅指定项目可以使用
gitlab如何使用?
- gitlab-runner安装和注册
这里不再赘述gitlab-runner的安装和注册过程,详细步骤请阅读:https://docs.gitlab.com/runner/install/
- 每个runner启动注册后都会分配一个唯一标识,gitlab平台会可以查询到它的信息并监控它的状态,当active时可被使用
- 不同的runner可以设置相同的tag
- 一个Job可以通过tags指定哪些runner有权限来执行它
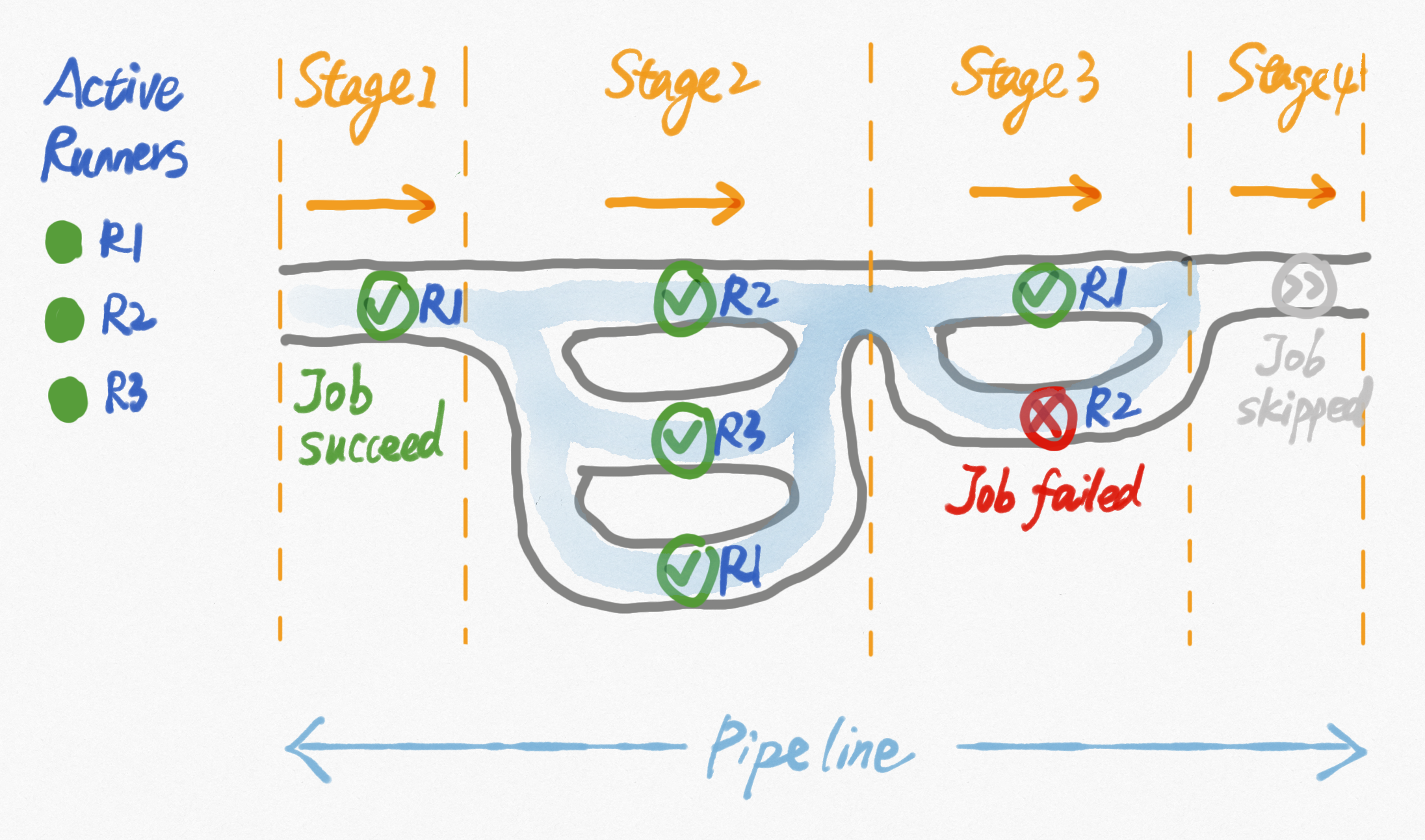
1.1.6 总结一下
gitlabCI作为持续集成的实践,提供了一种拆分任务、逐个验证的模型。
- 将项目流程看做一个pipeline,它被拆分成多个阶段,Stage像流水的闸门一样控制住整体流程
- 每个Stage定义了一些Job,每个Job都是独立且可重复执行的
- Job中定义的脚本会被当时任意一个可用的runner执行
- 每个Stage的所有Job成功后,闸门放开,流向下一个Stage;否则整个pipeline结束
1.2 gitlabCI实践经验
1.2.1 前提准备
没有前提!
只要你在使用gitlab管理代码(是的,我们在用),任何时候都可以适合开始接入持续集成,而gitlabCI是一个好的选择。
毕竟,持续集成是一件看似麻烦,其实超低成本、稳赚不赔的事情。
1.2.2 如何开始
开始使用gitlabCI,你需要:
- ✅ 使用gitlabCI 8.0 +进行代码管理
- ✅ 启动至少1个gitlab runner
- ✅ 在项目中添加格式正确的.gitlab-ci.yml脚本以定义pipeline流程
- ✅ push/merge代码自动触发CI or 手动触发 CI
怎样开始写.gitlab-ci.yml?
1. 明确需求:我期望项目被push后分为哪些阶段、分别做哪些验证?画出pipeline流程图
2. 开发脚本:使用.gitlab-ci.yml的语法实现这个pipeline
3. 环境确认:gitlab-runner所在的机器/环境可以执行所有script中定义的指令
4. 进行测试:fork一个项目(你将拥有一个有权限进行CI/CD配置的个人实验项目),进行push操作验证pipeline是否符合预期、job是否执行成功
1.2.3 常见问题解决方案 //TODO
由于本文侧重gitlabCI的概念讲解和持续集成思想传播,已经比较长了,该部分会在以后补上。(我不会承认是因为肝不动了。。。)
可能会涉及以下内容:
1. 在stage之间传递/缓存内容: cache、dependencies、artifacts
2. 更灵活的多线pipeline:when、only/exception、needs(only GitLab 12.0+)
3. 重复的参数、脚本如何整合:variables、befor_script、after_script
4. 使用docker-in-docker
1.2.4 我们实际是怎样使用的 —— gitlabCI与rancher结合
有了gitlabCI,可以帮助我们串联起整个开发到上线的项目流程:
- 一站式项目流程
- 提供环境管理
- “限制”失败的构建merge到主干
- 所有人都能看到统一的构建信息
而推行容器化和rancher以后,相比物理机部署时代,持续集成更顺畅了:
- 容器化改造敦促我们拿出完整而稳定的代码->运行软件的构建脚本
- 更加一致的环境和配置
- 更规范的镜像管理、workload管理
- 更平滑的环境更新和上线
1. 开发、测试、上线流程变化
以前 → 现在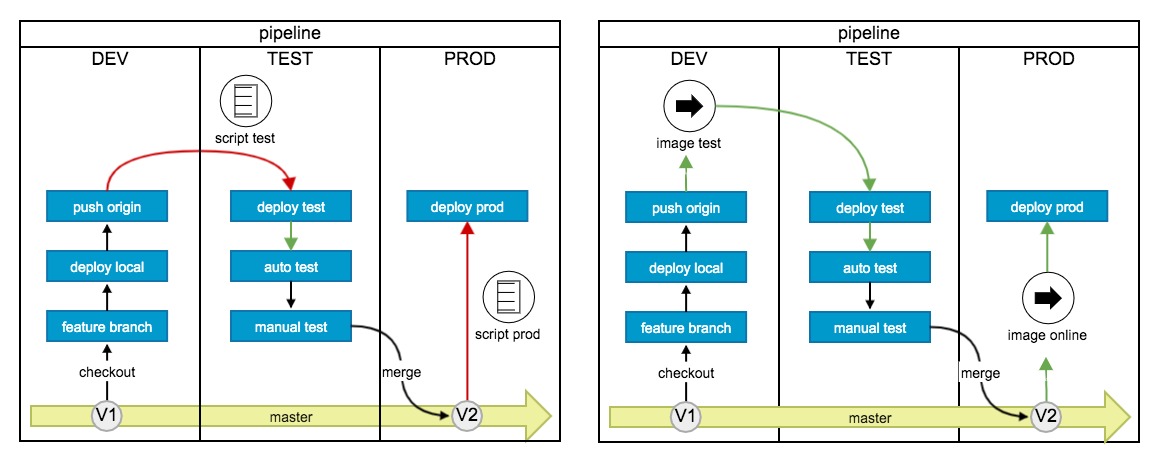
| 阶段 | 以前:多平台切换、不一致 | 现在:一站式管理 |
|---|---|---|
| 开发 | 提测时交付代码 gitlab repository只包含逻辑代码,其他全靠自觉 |
提测时交付可正确部署的镜像 or 可测试的服务 gitlab repository包含几乎所有内容:代码、文档、测试脚本、部署脚本、环境配置等 |
| 联调 | 前后端开发相互在本地其服务,约定地址后联调 或找jenkins可用的job自动部署 |
1. 在gitlab上点击执行CI并更新联调环境 2. 在gitlab上打开联调地址开始联调 |
| 测试 | 每个人分别自己手动部署代码后开始测试 | 1. 自动化测试自动触发 2. 需手工测试时在gitlab上直接打开测试环境 3. 任何人都可以获取到测试镜像 4. 测试时无缝切换,无需等待重新部署 |
| 上线 | 1. 交付代码,op上线或jenkins上线 2. 打开其他平台观察jenkins部署过程 3. 寻找线上环境回测 |
1. merge master即触发线上pod更新 2. 在gitlab上观察部署过程 3. 在gitlab上打开线上地址回测 |
| 回滚 | 指定tag,op上线或jenkins上线 | 直接在gitlab上操作回滚 |
2. 实际案例
场景1 - 使用新branch开发代码,push commit
策略1:生成一条pipeline但不执行任何内容
策略2:执行静态代码检查、单元测试等
场景2 - 提测,QA开始测试
打开gitlabCI环境管理,点击执行测试环境更新;执行完成后点击Open打开测试环境开始测试。
场景3 - 修复bug后开发联调
打开gitlabCI环境管理,点击执行开发环境更新;执行完成后点击Open打开开发环境开始测试。
场景4 - 开发自测完成或QA测试完成,准备上线
策略1:merge master动作直接出发上线pipeline,完成后可在gitlabCI环境管理中直接打开线上环境开始回测
策略2:merge master或手动执行branch pipeline触发包含全流程的完整pipeline执行,完成后可通知op操作上线或使用工具自助上线
场景5 - 测试/线上环境出现问题,需要回滚代码
打开gitlabCI环境管理中的test/prod环境,选择期望回滚的commit,点击RollBack;回滚完成后直接打开环境开始回测。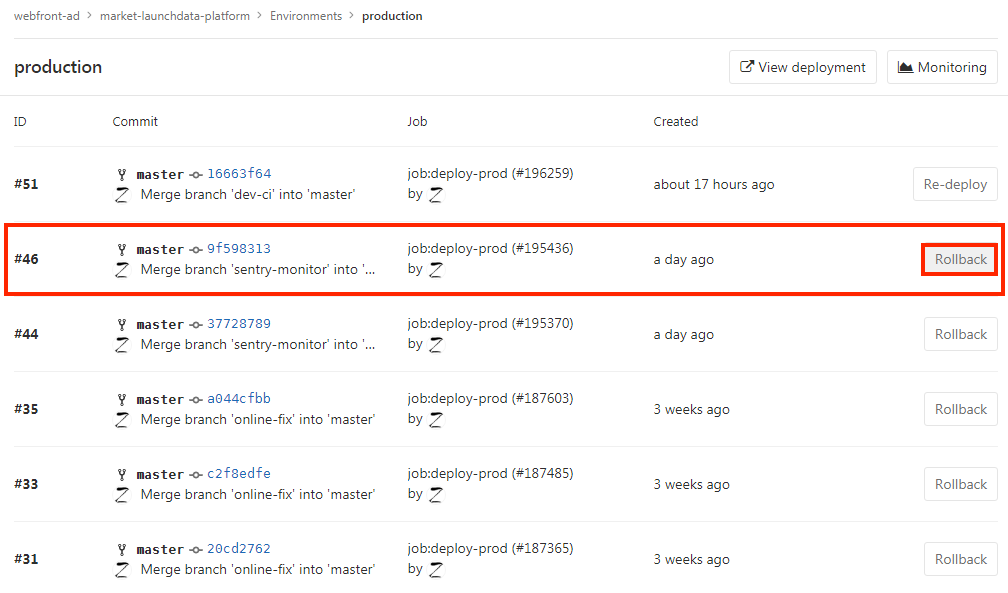
2 持续集成和敏捷
2.1 持续集成/极限编程/敏捷开发/Devops?
大家都说持续集成、devops,它们是一个东西吗?
1995~2001年,软件工程中文档驱动的”重型“开发模式占据主导地位。
1996年,Kent Beck提出了”轻方法论“的极限编程(ExtremeProgramming,XP)适用于小团队开发,并给出了12个最佳实践,“持续集成”就最佳实践之一。
2001年,来自极限编程、Scrum、Crystal等轻量开发模式的17位代表齐聚美国犹他州的雪鸟滑雪基地,组成联盟,著名的敏捷宣言诞生,所有类似的实践方法论都被统一为成为敏捷开发思想(Agile)。
2008年~2010年,从敏捷大会上由Patrick DeBois提出”敏捷基础架构“开始,DevOps的概念被逐步推出并明确了”CAMLS“的中心理论,随后由Amazon、Flickr、Google、Facebook、国内BAT、华为等公司持续发扬并给出具体的实践方法。
从历史发展上来说,包含持续集成概念的极限编程和一众开发思想被整合成敏捷开发的概念,而基于敏捷的思想,在2008年以后又提出了Devops的实践方法。
它们的核心思想都是什么?
极限编程的12个最佳实践(此处引用自博客):
- 计划游戏 ( Planning Game ):快速制定计划、随着细节的不断变化而完善
- 小型发布 ( Small Release ):系统的设计要能够尽可能早地交付
- 系统隐喻( System Metaphor ):找到合适的比喻来描述系统如何运作、新的功能以何种方式加入到系统
- 简单设计( Simple Design ):任何时候都应当将系统设计的尽可能简单
- 测试驱动( Test-driven ):先写测试代码再编写程序
- 重构( Refactoring ):不改变系统行为的前提下,重新调整、优化系统的内部结构以减少复杂性、消除冗余、增加灵活性和提高性能
- 结对编程( Pair Programming ):由两个程序员在同一台电脑上共同编写解决同一问题的代码。通常一个人负责写编码,而另一个负责保证代码的正确性与可读性
- 集体所有权(Collective Ownership):每个成员都有更改代码的权利,所有的人对于全部代码负责
- 持续集成( Continuous Integration ):提倡在一天中集成系统多次,而且随着需求的改变,要不断的进行回归测试,避免了一次系统集成的恶梦
- 每周工作40小时 ( 40-hour Week ):不加班
- 现场客户( On-site Customer ):至少有一名实际的客户代表在整个项目开发周期在现场负责确定需求、回答团队问题以及编写功能验收测试
- 编码标准( Code Standards ):强调通过指定严格的代码规范来进行沟通,尽可能减少不必要的文档
敏捷开发的12原则:
- 我们最重要的目标,是通过持续不断地及早交付有价值的软件使客户满意。
- 欣然面对需求变化,即使在开发后期也一样。为了客户的竞争优势,敏捷过程掌控变化。
- 经常地交付可工作的软件,相隔几星期或一两个月,倾向于采取较短的周期。【持续集成】
- 业务人员和开发人员必须相互合作,项目中的每一天都不例外。
- 激发个体的斗志,以他们为核心搭建项目。提供所需的环境和支援,辅以信任,从而达成目标。
- 不论团队内外,传递信息效果最好效率也最高的方式是面对面的交谈。
- 可工作的软件是进度的首要度量标准。
- 敏捷过程倡导可持续开发。责任人、开发人员和用户要能够共同维持其步调稳定延续。
- 坚持不懈地追求技术卓越和良好设计,敏捷能力由此增强。
- 以简洁为本,它是极力减少不必要工作量的艺术。
- 最好的架构、需求和设计出自自组织团队。
- 团队定期地反思如何能提高成效,并依此调整自身的举止表现。
Devops文化——CALMS
- Culture(文化):拥抱变革,促进协作和沟通
- Automation(自动化):将人为干预的环节从价值链中消除【持续集成:自动化】
- Lean(精益):通过使用精益原则促使高频率循环周期和交付价值【持续集成:小步迭代】
- Metrics(指标):指衡量每一个环节,并通过数据来改进循环周期
- Sharing(分享):与他人开放分享成功与失败的经验,并在错误中不断学习改进
=》缩短甚至消除从开发和运维之间gap,持续快速迭代和优化”计划-开发-构建-测试-发布-部署-运维-监控“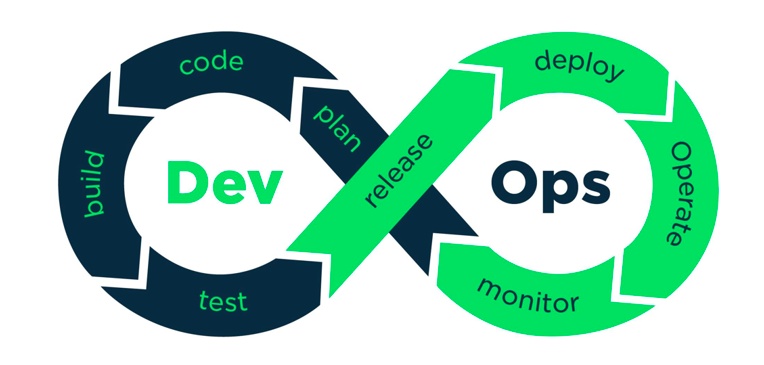
从思想上来说,极限编程侧重给出小团队应该如何快速展开项目开发,敏捷开发侧重给出当今软件产品快速迭代趋势下的指导方法论(侧重项目/团队管理,如Scrum),Devops基于一系列更新更快的技术发展后(虚拟化/容器化、云计算、数据中台、自动化测试等),侧重于给出如何提高团队协作效率的指导思想。
只要公司以”快速上线以更快获取利润“为目标,无论采取哪种思想作为指导,都离不开”持续集成“。
2.2 持续集成应该是什么样的 by Martin Fowler
说明:
- 这里主要讨论CI而很少涉及CD,CD目前距离我们的现状还比较遥远
- 以下讨论均基于Mainline Branch Stragegy的分支管理模式
- 这一部分的思想来自Martin Fowler有关持续集成的文章
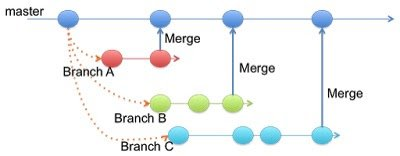
2.2.1 在开发中如何持续集成
假如我们要开发一下很小的功能,可以在几小时内完成。
- 从master分支checkout代码到本地
- 在本地进行开发,同时编写测试代码,如单元测试
- 在本地进行编译、构建和测试并通过,准备push开发分支
- pull master并解决冲突,直到本地的编译、构建和测试全部通过,push开发分支【如,忘记push部分代码】
- 等待被push的新代码在持续集成的机器上再次编译构建和测试(CI)【如,编译失败】
- 尽快修复CI失败的问题,重新push并等待再次CI
-
2.2.2 持续集成的实践原则(推荐指数⭐️⭐️⭐️⭐️⭐️)
| 原则 | 详细内容 | 我们做到了什么 | 还差什么 | | —- | —- | —- | —- | | 1. 维护单一的代码库 |
- 所有的项目内容都应该在代码库中,包括开发代码、测试脚本、依赖脚本、属性文件、数据库定义、部署脚本等
- 合理的版本控制和分支管理
| ❓部分做到
- 使用gitlab管理代码和Dockerfile
- 部分项目规定了分支管理和上线流程
| 测试脚本和代码仍然是分离的 | | 2. 自动化构建 |
- 将代码转换成可运行的软件需要非常多的步骤,这些内容应该尽量自动化
- 原则是:任何人都应该能够在一台新机器上拉下代码库中的代码,并只用一个命令将系统运行起来
- 使用健壮的构建工具,如maven、gradle等;而不是依赖IDE,构建应该可以在一台服务器上稳定完成
| ✅ 可以做到
Dockerfile帮助我们保证从代码到运行系统的一致性 || | 3. 自动化测试构建 |
- 有一组自动化测试来验证代码是否存在bug
- 测试可以通过简单命令来执行
- 测试代码可以自检以保证本身没有问题
- 有测试结果或测试报告来指出具体哪些内容没有通过测试
- 一旦测试失败,这次集成也应当被认为/标注失败
| ❓部分做到
- 部分项目已有自动化测试并加入持续集成
- 测试有报告
- gitlabCI为我们提供pipeline和job的成功/失败标注
|
- 补充有效的自动化测试
- 测试代码自检
| | 4. 频繁向主干提交代码 |
- 频繁提交可以帮助开发快速发现与别人代码的冲突并解决、快速发现bug并修复
| ✅ 可以做到 || | 5. 每次提交都在集成环境执行构建 |
- 手动构建和自动检查代码提交后构建都是可以的,持续集成是一种态度而不是工具
- 每天构建一次不是持续集成,关键在于每次提交构建并尽早发现问题
- CI失败以后应该立即修复
| ✅ 可以做到 || | 6. 快速构建 |
- 构建的时间应越短越好,10分钟以内最佳
- 引入pipeline是一个拆分检查、缩短构建时间的好办法;还可以使用多台机器并行执行任务
| ✅ 可以做到
- gitlabCI的stage定义帮助拆分检查内容以快速
- gitlab-runner使并行执行成为可能,并可以统一管理
| 构建时间可能会长,注意增加缓存(部分项目已添加) | | 7. 在类生产环境中运行测试 |
- 测试的目的是发现在生产环境中可能存在的问题,所以测试环境应该保证与生产环境尽量一致,包括操作系统、软件环境、数据库等
|| ❓目前没有类生产环境 | | 8. 任何人都能轻易获得可执行文件 |
- 保证有一个统一的地方存放最新的已通过测试的可执行文件,用于演示、测试、持续的评估和优化等
| ✅ 可以做到
CI过程中产生的镜像被打上tag统一管理在harbor平台,可以被随时拉起 || | 9. 人人都能看到在发生什么 |
- 持续集成主要在于交流,因此应当保证每人都能轻易看到当前系统的状态和已做的修改
- 构建成功和失败应当有合适的通知
- 历史构建信息应该可以被记录和管理,以便评估CI的稳定性
| ✅ 可以做到
- gitlabCI提供了统一的大家都可见的pipeline管理
- gitlab本身有邮件通知,ydci提供了更及时的notify popo命令
- gitlab提供API可以获取构建信息,质量管理平台已抓取用作CI的评估
|| | 10. 自动化部署 |
- 有测试环境和生产环境的自动部署脚本、自动回滚脚本
- 可以支持自动的集群多节点的发布、灰度发布等
| ❓部分做到
- 大部分项目已有自动部署脚本,目前维护在jenkins上
- 对使用gitlabCI上线的项目,可以实现自动回滚
|
- 大部分项目没有实现自动回滚
- 目前没有实现自动的多节点发布和灰度发布,但rancher的workload管理使之成为可能
|
2.3 QA与持续集成
说了这么多理论知识你问”我为什么要关心持续集成“?
Martin Fowler在文章中提到,持续集成的好处就是降低风险、快速发现Bug,为快速交付提供基础,但这点十分依赖自动测试(这里可以引申为所有形式的自动化检查,如编译检查、部署检查、各种类型的测试等)的脚本写得好不好。
这不正是QA关心的几个大事吗?风险、Bug、效率 <= 依赖自动化。仔细想想,这不也正是所有项目角色都关心的吗?
QA编写更多更快更可靠的自动化脚本和工具,配合开发自测、自动化发布等,通过持续集成的方式融入Devops的大循环,辅助它运转地更好更快。
理想模式: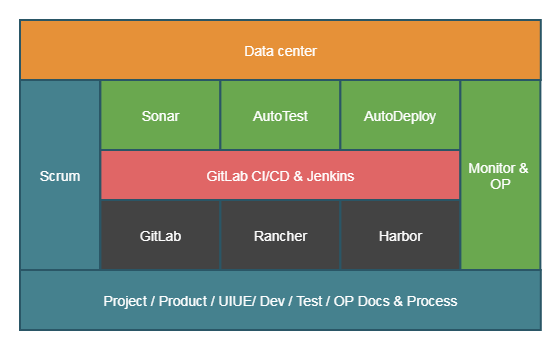
希望大家都Get到了这个高尚的职业方向并为之努力奋斗~ 😄
3 后记
本文的灵感来自2.2节提到的的持续集成文章,看完以后发现“靠摸索去做去总结的许多事情原来早就有大神指明了方向,好在这也应证了我们在向正确的方向努力”。
本文的大部分内容都不那么重要或者说不一定适用于所有团队,使用gitlabCI+rancher作为依托工具是不是最佳实践也不好说,但Martin Fowler的持续集成的思想是强烈推荐大家作为理论指导和自评标准的。
虽然历时比较长久,我们的项目对基于gitlabCI+rancher的的持续集成实践已经初步成型并稳定,未来将推广到更多项目、不断积累经验。
最后感谢所有团队中参与和推进持续集成建设的小伙伴们。
4 扩展阅读
敏捷宣言的历史:http://agilemanifesto.org/history.html
极限编程与敏捷开发:https://www.zhihu.com/question/38168328
The New Methodology(Martin Fowler):https://martinfowler.com/articles/newMethodology.html
关于Devops的那些事儿:https://www.jianshu.com/p/4029a7a7988b
DevOpsCulture(Rouan Wilsenach)https://martinfowler.com/bliki/DevOpsCulture.html
Continuous Integration(Martin Fowler):https://www.martinfowler.com/articles/continuousIntegration.html
GiLab CI ——前端自动化构建及优化:https://juejin.im/post/5e9c38856fb9a03c917fe509

若有收获,就点个赞吧
0 人点赞
