1. 什么是索引?
索引是一种用于快速查询和检索数据的数据结构。
索引的作用就相当于目录的作用。打个比方: 我们在查字典的时候,如果没有目录,那我们就只能一页一页的去找我们需要查的那个字,速度很慢。如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
2. 为什么要用索引?索引的优缺点分析
2.1 索引的优点
✅ 创建索引的最主要的原因 是可以大大加快数据的检索速度(大大减少的检索的数据量)毕竟大部分系统的读请求总是大于写请求的。
✅ 另外,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
✅ 将随机IO变为顺序IO
✅ 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
✅ 帮助服务器避免排序和临时表。
2.2 索引的缺点(为什么不对表中的每一个列创建一个索引呢?)
❌ 创建索引和维护索引需要耗费许多时间:当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低SQL执行效率。(索引也要动态的维护,这样就降低了数据的维护速度。)
❌ 占用物理存储空间 :索引需要使用物理文件存储,也会耗费一定空间。除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
❌ 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
3. Mysql的基本存储结构(页)
首先Mysql的基本存储结构是页(记录都存在页里边):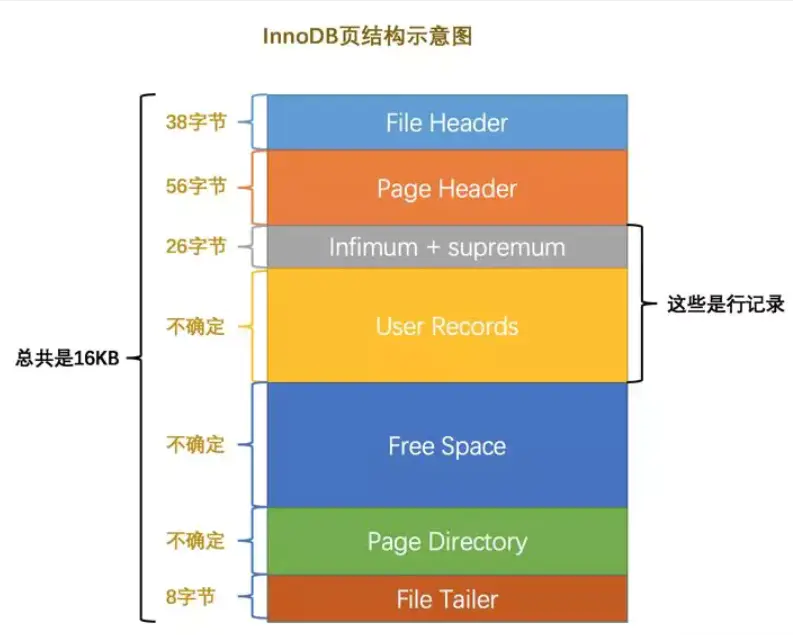
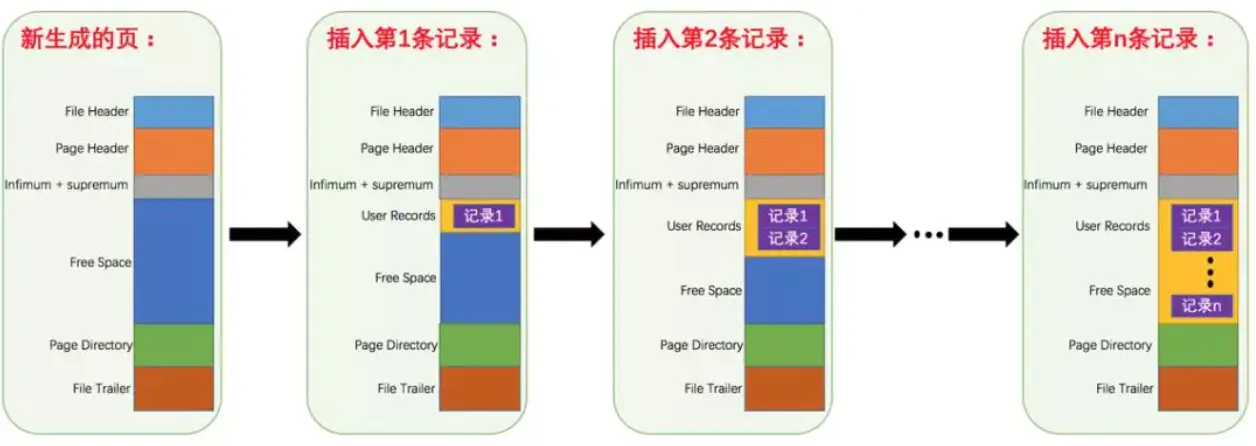
- 各个数据页可以组成一个双向链表
而每个数据页中的记录又可以组成一个单向链表
定位到记录所在的页
- 需要遍历双向链表,找到所在的页
- 从所在的页内中查找相应的记录
- 由于不是根据主键查询,只能遍历所在页的单链表了
3.2 参考文章
4. 索引为加快检索速度做了什么?
索引做了些什么可以让我们查询加快速度呢?
其实就是将无序的数据变成有序(相对):
要找到id为8的记录简要步骤:
很明显的是:没有用索引我们是需要遍历双向链表来定位对应的页,现在通过“目录”就可以很快地定位到对应的页上了!
其实底层结构就是B+树,B+树作为树的一种实现,能够让我们很快地查找出对应的记录。
5. 不建议为频繁改动的数据添加索引( 索引降低增删改的速度 )
B+树是平衡树的一种。
平衡树:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
如果一棵普通的树在极端的情况下,是能退化成链表的(树的优点就不复存在了)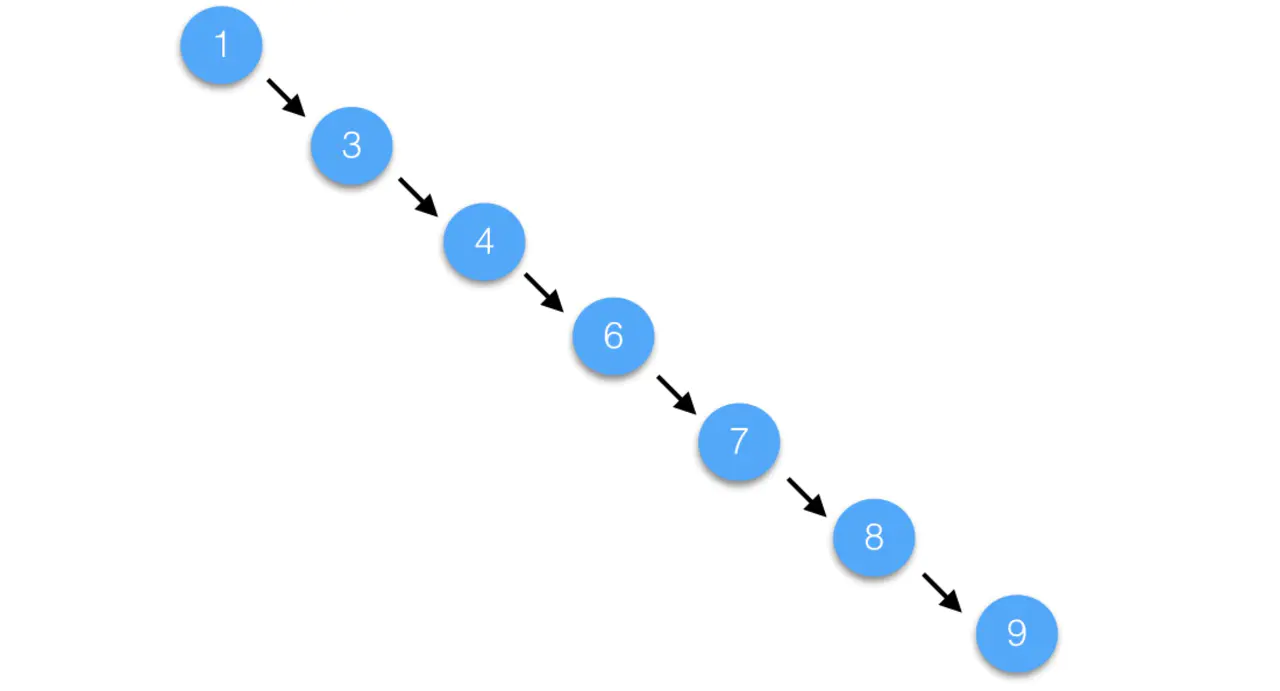
B+树是平衡树的一种,是不会退化成链表的,树的高度都是相对比较低的(基本符合矮矮胖胖(均衡)的结构)【这样一来我们检索的时间复杂度就是O(logn)】!从上一节的图我们也可以看见,建立索引实际上就是建立一颗B+树。
- B+树是一颗平衡树,如果我们对这颗树增删改的话,那肯定会破坏它的原有结构。
- 要维持平衡树,就必须做额外的工作。正因为这些额外的工作开销,导致索引会降低增删改的速度
B+树删除和修改具体可参考:
B+树介绍
6. 另一种索引结构 — 哈希索引
除了B+树之外,还有一种常见的是哈希索引。
哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,速度非常快。
- 本质上就是把键值换算成新的哈希值,根据这个哈希值来定位。
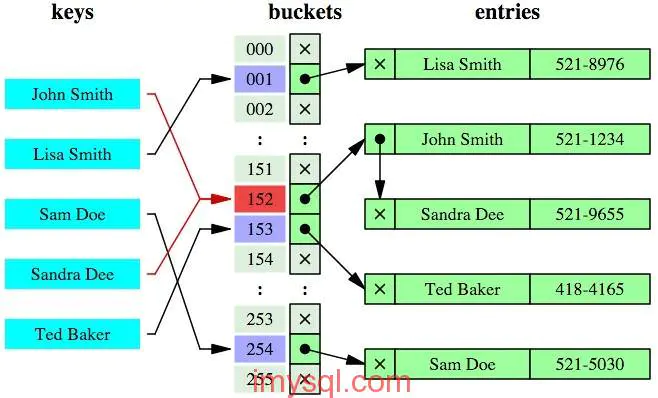
看起来哈希索引很牛逼啊,但其实哈希索引有好几个局限(根据他本质的原理可得):
- 哈希索引也没办法利用索引完成排序
- 不支持最左匹配原则
- 在有大量重复键值情况下,哈希索引的效率也是极低的——>哈希碰撞问题。
- 不支持范围查询
参考资料:
hash索引和b+tree索引
6.1 InnoDB中的哈希索引
主流的还是使用B+树索引比较多,对于哈希索引,InnoDB是自适应哈希索引的(hash索引的创建由InnoDB存储引擎引擎自动优化创建,我们干预不了)!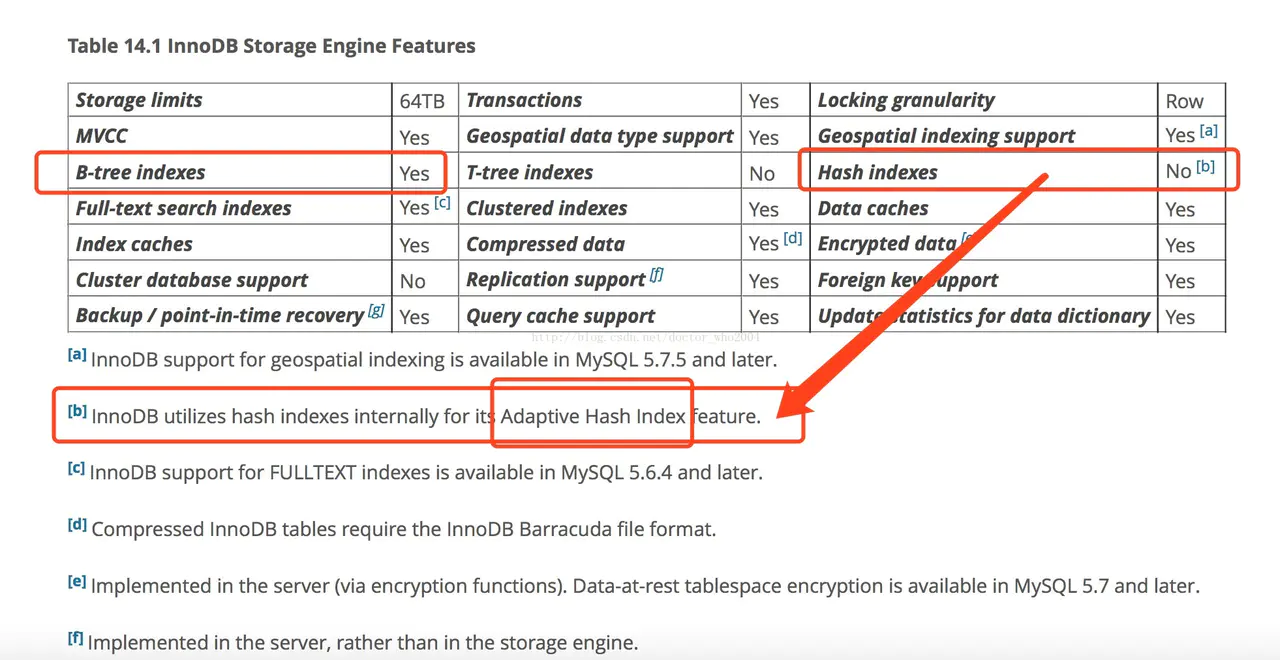
参考资料:
mysql InnoDB引擎支持hash索引吗
7. 聚集和非聚集索引
简单概括:
- 聚集索引就是以主键创建的索引
- 非聚集索引就是以非主键创建的索引
区别:
- 聚集索引在叶子节点存储的是表中的数据
- 非聚集索引在叶子节点存储的是主键和索引列
- 使用非聚集索引查询出数据时,拿到叶子上的主键再去查到想要查找的数据。(拿到主键再查找这个过程叫做回表)
非聚集索引也叫做二级索引,不用纠结那么多名词,将其等价就行了~
非聚集索引在建立的时候也未必是单列的,可以多个列来创建索引。
- 此时就涉及到了哪个列会走索引,哪个列不走索引的问题了(最左匹配原则—>后面有说)
- 创建多个单列(非聚集)索引的时候,会生成多个索引树(所以过多创建索引会占用磁盘空间)

在创建多列索引中也涉及到了一种特殊的索引—>覆盖索引
- 我们前面知道了,如果不是聚集索引,叶子节点存储的是主键+列值
- 最终还是要“回表”,也就是要通过主键再查找一次。这样就会比较慢
- 覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
比如说:
- 现在我创建了索引
(username,age),在查询数据的时候:select username , age from user where username = 'Java3y' and age = 20。 - 很明显地知道,我们上边的查询是走索引的,并且,要查询出的列在叶子节点都存在!所以,就不用回表了~
-
8. 索引最左匹配原则?
最左匹配原则:
索引可以简单如一个列
(a),也可以复杂如多个列(a, b, c, d),即联合索引。- 如果是联合索引,那么key也由多个列组成,同时,索引只能用于查找key是否存在(相等),遇到范围查询
(>、<、between、like左匹配)等就不能进一步匹配了,后续退化为线性查找。 - 因此,列的排列顺序决定了可命中索引的列数。
例子:
如有索引
(a, b, c, d),查询条件a = 1 and b = 2 and c > 3 and d = 4,则会在每个节点依次命中a、b、c,无法命中d。(很简单:索引命中只能是相等的情况,不能是范围匹配)9. =、in自动优化顺序?
不需要考虑=、in等的顺序,mysql会自动优化这些条件的顺序,以匹配尽可能多的索引列。
例子:如有索引
(a, b, c, d),查询条件c > 3 and b = 2 and a = 1 and d < 4与a = 1 and c > 3 and b = 2 and d < 4等顺序都是可以的,MySQL会自动优化为a = 1 and b = 2 and c > 3 and d < 4,依次命中a、b、c。10. 索引总结
索引在数据库中是一个非常重要的知识点!上面谈的其实就是索引最基本的东西,要创建出好的索引要顾及到很多的方面:
1,最左前缀匹配原则。这是非常重要、非常重要、非常重要(重要的事情说三遍)的原则,MySQL会一直向右匹配直到遇到范围查询
(>,<,BETWEEN,LIKE)就停止匹配。- 3,尽量选择区分度高的列作为索引,区分度的公式是
COUNT(DISTINCT col) / COUNT(*)。表示字段不重复的比率,比率越大我们扫描的记录数就越少。 - 4,索引列不能参与计算,尽量保持列“干净”。比如,
FROM_UNIXTIME(create_time) = '2016-06-06'就不能使用索引,原因很简单,B+树中存储的都是数据表中的字段值,但是进行检索时,需要把所有元素都应用函数才能比较,显然这样的代价太大。所以语句要写成 :create_time = UNIX_TIMESTAMP('2016-06-06')。 - 5,尽可能的扩展索引,不要新建立索引。比如表中已经有了a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
- 6,单个多列组合索引和多个单列索引的检索查询效果不同,因为在执行SQL时,MySQL只能使用一个索引,会从多个单列索引中选择一个限制最为严格的索引。
参考资料:
参考文章
🚀 MySQL索引背后的数据结构及算法原理
🚀《Java工程师修炼之道》
🚀《MySQL高性能书籍_第3版》
🚀 数据库两大神器【索引和锁】

若有收获,就点个赞吧
0 人点赞
