分布式与微服务
https://blog.csdn.net/qq_40585800/article/details/109095279?
什么是分布式系统?
分布式系统是由一组通过网络进行通信、为了完成共同的任务而协调工作的计算机节点组成的系统。分布式系统的出现是为了用廉价的、普通的机器完成单个计算机无法完成的计算、存储任务。其本质是利用更多的机器,处理更多的数据。
分布式系统(distributed system)是建立在网络之上的软件系统。
首先需要明确的是,只有当单个节点的处理能力无法满足日益增长的计算、存储任务的时候,且硬件的提升(加内存、加磁盘、使用更好的CPU)高昂到得不偿失的时候,应用程序也不能进一步优化的时候,我们才需要考虑分布式系统。因为,分布式系统要解决的问题本身就是和单机系统一样的,而由于分布式系统多节点、通过网络通信的拓扑结构,会引入很多单机系统没有的问题,为了解决这些问题又会引入更多的机制、协议,带来更多的问题。
因此,随着互联网的发展,网站应用的规模不断扩大,常规的垂直应用架构已无法应对,分布式服务架构以及流动计算架构势在必行,急需一个治理系统确保架构有条不紊的演进。
什么是微服务架构?说说你对微服务的理解?
有一种说法是微服务的分布式的细分,而且微服务跟分布式的架构方式即为相似,只是部署的方式不同,所以微服务它其实是分布式架构的一种。
任何技术的演进都是有迹可循的,任何新技术的出现都是为了解决原有技术无法解决的需求,所以,微服务的出现就是因为原来单体应用架构已经无法满足当前互联网产品的技术需求。
微服要做的第一点件事情就是拆分。因为传统的单体架构所有的业务功能全部写在一起,随着业务越来越复杂,代码也变得耦合得越来越多,将来你想升级维护就会很困难了。所以像一些大型的互联网项目都必须去做拆分。那微服务在做拆分的时候,会根据业务功能模块,把一个单体的项目拆分成许多个独立的项目。每个项目完成一部分业务功能,将来独立开发和部署。那我们把这一个独立的项目称为一个服务。一个大型的互联网项目往往会包含数百甚至上千的服务,最终形成一个服务集群。
微服务架构,核心就是为了解决应用微服务化之后的服务治理问题。
单体架构存在的问题
单体架构在规模比较小的情况下工作情况良好,但是随着系统规模的扩大,它暴露出来的问题也越来越多,主要有以下几点:
1.复杂性逐渐变高
- 比如有的项目有几十万行代码,各个模块之间区别比较模糊,逻辑比较混乱,代码越多复杂性越高,越难解决遇到的问题。
2.技术债务逐渐上升
- 公司的人员流动是再正常不过的事情,有的员工在离职之前,疏于代码质量的自我管束,导致留下来很多坑,由于单体项目代码量庞大的惊人,留下的坑很难被发觉,这就给新来的员工带来很大的烦恼,人员流动越大所留下的坑越多,也就是所谓的技术债务越来越多。
3.部署速度逐渐变慢
- 这个就很好理解了,单体架构模块非常多,代码量非常庞大,导致部署项目所花费的时间越来越多,曾经有的项目启动就要一二十分钟,这是多么恐怖的事情啊,启动几次项目一天的时间就过去了,留给开发者开发的时间就非常少了。
4.阻碍技术创新
- 比如以前的某个项目使用struts2写的,由于各个模块之间有着千丝万缕的联系,代码量大,逻辑不够清楚,如果现在想用spring mvc来重构这个项目将是非常困难的,付出的成本将非常大,所以更多的时候公司不得不硬着头皮继续使用老的struts架构,这就阻碍了技术的创新。
5.无法按需伸缩
比如说电影模块是CPU密集型的模块,而订单模块是IO密集型的模块,假如我们要提升订单模块的性能,比如加大内存、增加硬盘,但是由于所有的模块都在一个架构下,因此我们在扩展订单模块的性能时不得不考虑其它模块的因素,因为我们不能因为扩展某个模块的性能而损害其它模块的性能,从而无法按需进行伸缩。
分布式服务架构与微服务架构概念的区别与联系:
分布式:分散压力。
不同模块部署在不同服务器上通过分布式解决网站高并发带来问题;
- 集群:相同的服务通过多台服务器部署构成一个集群,再通过负载均衡设备共同对外提供服务;
微服务:分散能力。
- 架构设计概念:各服务间隔离(分布式也是隔离),自治(分布式依赖整体组合),其它特性(单一职责,边界,异步通信,独立部署)是分布式概念更加严格的执行;
微服务的意思也就是将模块拆分成一个独立的服务单元通过接口来实现数据的交互。但是微服务不一定是分布式,因为微服务的应用不一定是分散在多个服务器上,他也可以是同一个服务器。这也是分布式和微服务的一个细微差别。
微服务的组件
一个大型的互联网项目往往会包含数百甚至上千的服务,最终形成一个服务集群。而一个业务往往就需要有多个服务共同来完成。
服务注册中心
比如说一个请求来了,他可能先去调了服务 A 而服务 A 可能又调了服务 B 而后又去调了服务 C ,当业务越来越多,越来越复杂的时候,这些服务之间的调用关系就会越来越复杂。那这么复杂的一个调用关系,想靠人去记录和维护,这是不可能的。 那怎么办呢?所以在微服务里一定会有一个组件叫做**注册中心**,**它可以去记录微服务中每一个服务的 IP 端口以及它能干什么事这些信息。**那当有一个服务需要调用另外的服务时,他不需要自己去记录对方的 IP ,只需要去找注册中心就行了。然后从注册中心那里去拉取对应的服务信息。
配置中心
同时随着服务越来越多,每一个服务都有自己的配置文件,将来如果要更改配置,难道我们逐一去修改吗?这就太麻烦了。所以在微服务里还会有一个配置中心,它可以去统一的管理整个服务群里成千上百的这些配置。如果以后你有一些配置需要变更,只需要去找到配置中心就可以了。它会去通知相关的微服务,实现配置的热更新。
服务网关
还有当我们的微服务运行起来以后,用户就可以来访问我们了。但是这个时候还需要一个网关组件,因为你这里有这么多的微服务,那用户怎么知道该访问哪一个呢?我们的服务网关一方面就是对用户身份做校验,另一方面可以把用户的请求路由到我们的具体的服务。当然在路由过程中也可以去做一些负载均衡。而这个时候服务接收到你的请求去处理业务,该访问数据库的时候就去访问数据库,最后再把查询到的数据返回给用户就 OK 了。<br />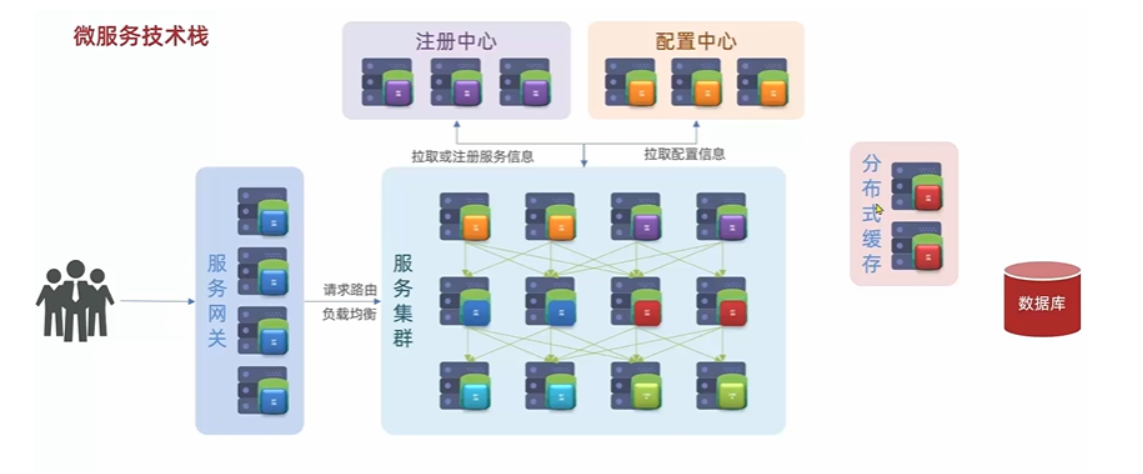
数据库集群以及缓存
这里画的虽然是一个,但是将来数据库肯定是要做集群的,不过集群再庞大也不可能有用户多,所以数据库将来肯定无法扛住这种高的并发。那因此我们还会加入缓存。<br /> 缓存是什么?缓存就是把数据库数据放入到内存当中,那内存查询效率肯定比数据库要快很多。而且这种缓存还不能是单体缓存,为了应对高并发,还要做成这种分布式的缓存,也是一个集群。用户请求,先到缓存,缓存未命中了,再去查询数据库。<br /> 以后我们的业务中还会有一些复杂的搜索功能,简单查询可以作为缓存,一些海量数据的复杂的搜索统计和分析,缓存也做不了。那这个时候我们还需要用到分布式搜索功能。<br />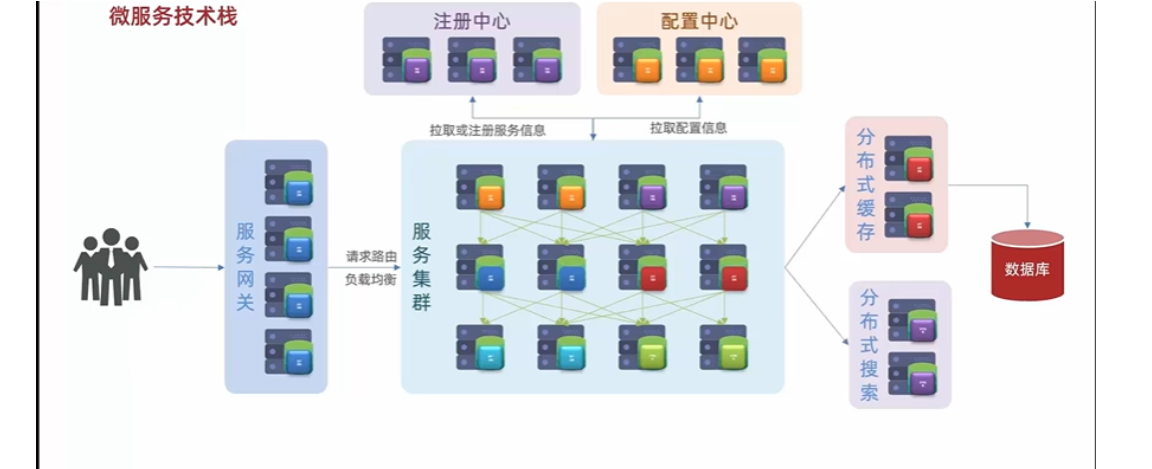<br /> 这样一来数据库将来主要的职责其实就是做一种数据的写操作,还有一些事务类型的,对数据安全要求较高的一些数据存储。
消息队列
最后在微服务里边还需要一种异步通信的消息队列组件。为什么呢?其实对于分布式的服务或者讲微服务里边,它的业务往往会跨越多个服务。一个请求来了,先调了服务 A,A 再调 B,B 再去调 C。 整个业务的链路就很长,那调用时长就会等于每个服务的执行时长之和,所以其实性能是有一定的下降的。

若有收获,就点个赞吧
0 人点赞
