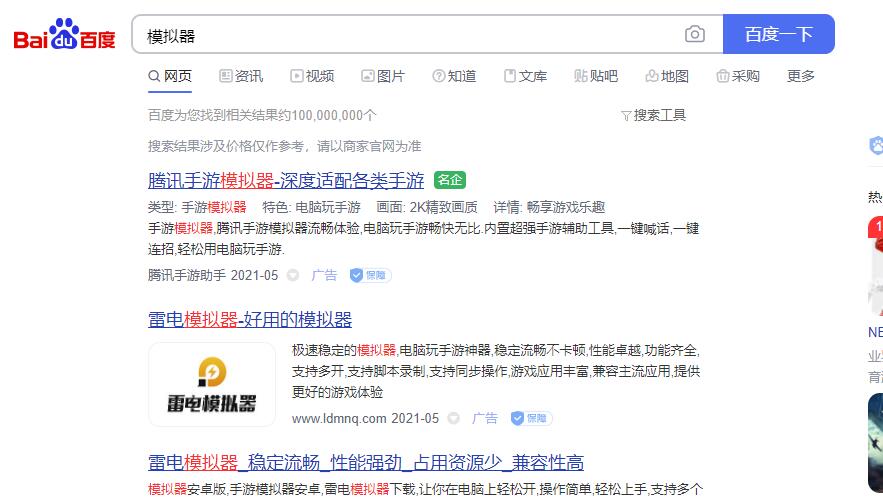
近年来,百度搜索时常因为其搜索时出现的各种广告而被各大网友吐槽,更是爆出了“莆田医院魏则西”这样的令人叹息的事情。如下为百度搜索“模拟器”时,出现了整整4条广告。
但是作为一个商业的搜索引擎,出现广告确实是可能的,不光是百度,连谷歌也会出现各种广告。如下图,为检索“模拟器”时谷歌页面出现的广告。
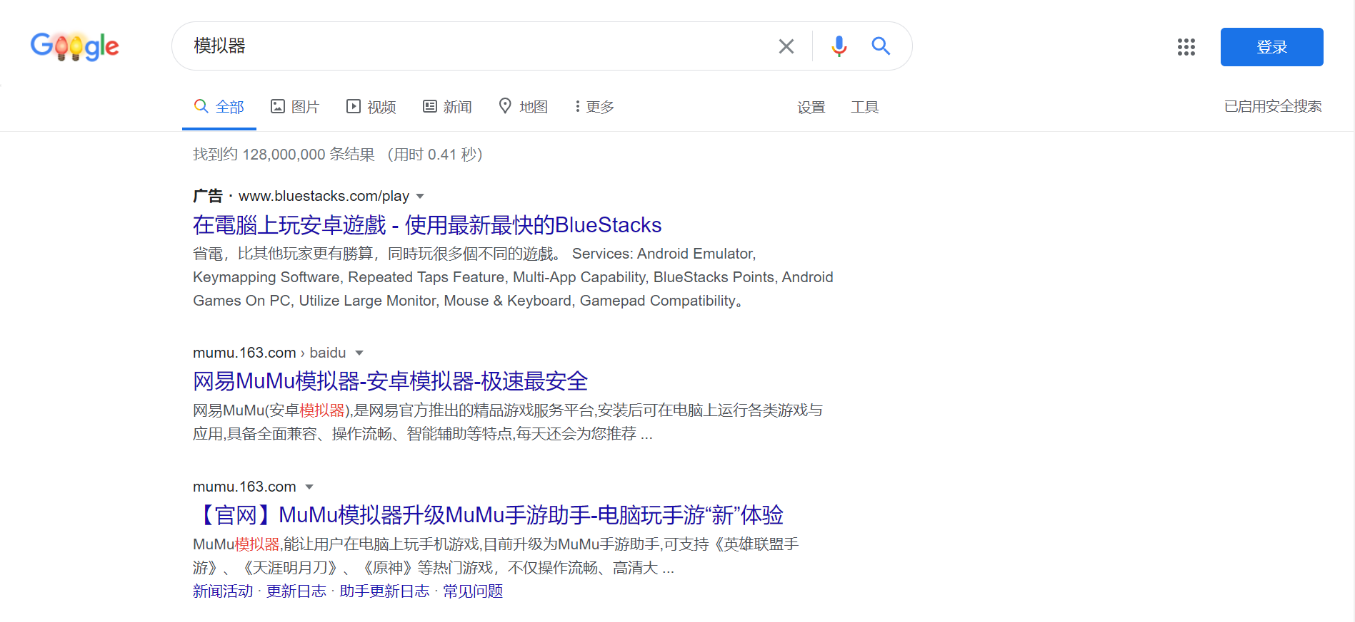
当然,在百度面前,谷歌的搜索结果显得简洁很多,尤其是广告方面也相对较少,但是使用谷歌其实并不方便,需要各种途径才能使用谷歌,这对广大普通网友的时候造成了较大的困扰。所以,在这种情况下,对百度检索的结果进行一个广告的过滤显得尤为重要。正好计网大作业要求做一个爬虫的大作业,所以我就以此为基础,来开发一个爬虫程序。
我的目的在于对百度搜索的结果进行一个过滤,将其中的广告项删除,并以简洁的网页形式展示出来。
首先要用的是Python(Python 3.7.3),利用Python的爬虫技术,可以将百度的搜索结果爬取下来,并进行一系列的筛选。因为输入关键词的部分在前端实现,所以我还需要一个能够连接前后端的框架,此处采用了Django(Django 3.1.0)的框架进行前后端的交互。 在获取到了相应的结果之后,还需要展示在页面上,所以此处依旧需要使用Web前端的三板斧 HTML + CSS + JavaScript,同时本来我想采用React框架进行布局,但是后来发现这样在Django框架下实现前后端分离并不方便,所以还是使用较少。
对源代码进一步分析可以看出,检索项之间的CSS样式是有区别的,
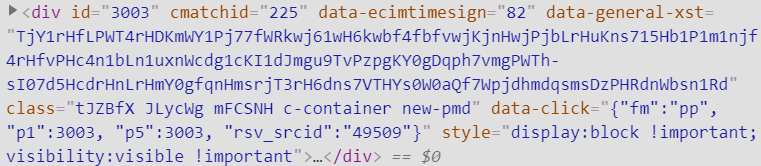
例如这是一条广告的div,可以看到这个div采用的样式是class= “tJZBfX JLycWg mFCSNH c-container new-pmd”,而对正常的检索项,div使用的样式则是class=”result c-container new-pmd”,可以看到,在广告项里的class使用了更多的样式,这就使得我在对爬取到的内容可以进行一些筛选了。

经过了大量的研究,我发现所有的检索结果只要是非推广内容的,均是class=”result c-container new-pmd”,所以只需要对这一项使用正则表达式判断,即可将所有商业推广的内容去除。除此之外,我还发现了一个最简单的方法,那就是对百度检索出来的id进行判断,因为所有非商业推广的内容是会赋值id = “?”,这也就使得我可以用更简单的方法,只需要div中含有id项的即可进行筛选。
部分代码如下:
def get_url(keyword, pages):params = {'wd': str(keyword)}# https://www.baidu.com/s?wd=xpath&pn=21 这是查到第三页的例子url = "https://www.baidu.com/s"url = format_url(url, params)if int(pages) == 1:page = 1else:page = (int(pages) - 1) * 10url = url + '&pn=' + str(page)print(url)return urldef get_page(url):try:headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36','accept-language': 'zh-CN,zh;q=0.9','cache-control': 'max-age=0','accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8'}response = requests.get(url=url,headers=headers)# 更改编码方式,否则会出现乱码的情况response.encoding = "utf-8"if response.status_code == 200:return response.textreturn Noneexcept RequestException:return Nonedef parse_page(url, page):i = pagetitle = ""sub_url = ""abstract = ""flag = 11if i == 1:flag = 10html = get_page(url)content = etree.HTML(html)for j in range(1,flag):data = {}res_title = content.xpath('//*[@id="%d"]/h3/a' % ((i - 1) * 10 + j))if res_title:title = res_title[0].xpath('string(.)').replace('\n','').strip()print("title是")print(title)sub_url = content.xpath('//*[@id="%d"]/h3/a/@href' % ((i - 1) * 10 + j))if sub_url:sub_url = sub_url[0]print("sub_url是")print(sub_url)res_abstract = content.xpath('//*[@id="%d"]/div[@class="c-abstract"]'%((i-1)*10+j))if res_abstract:abstract = res_abstract[0].xpath('string(.)')else:res_abstract = content.xpath('//*[@id="%d"]/div/div[2]/div[@class="c-abstract"]'%((i-1)*10+j))if res_abstract:abstract = res_abstract[0].xpath('string(.)')data['title'] = titledata['sub_url'] = sub_urldata['abstract'] = abstractif sub_url != []:yield data
在这样的处理之后,就基本得到了我所需的检索项标题,检索项链接,检索项摘要。在这样的情况下,再使用爬虫进行内容的爬取,就可以得到相应的结果。
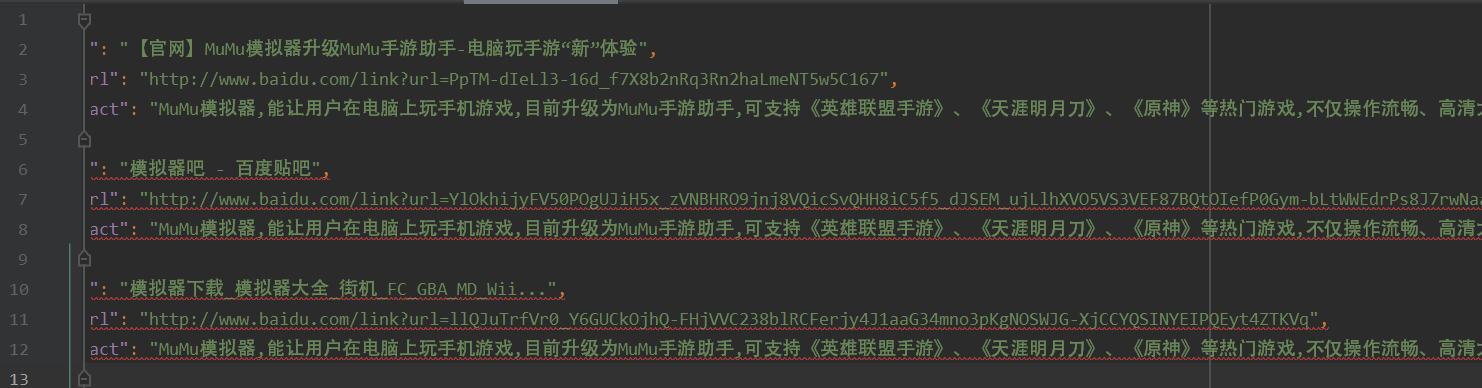
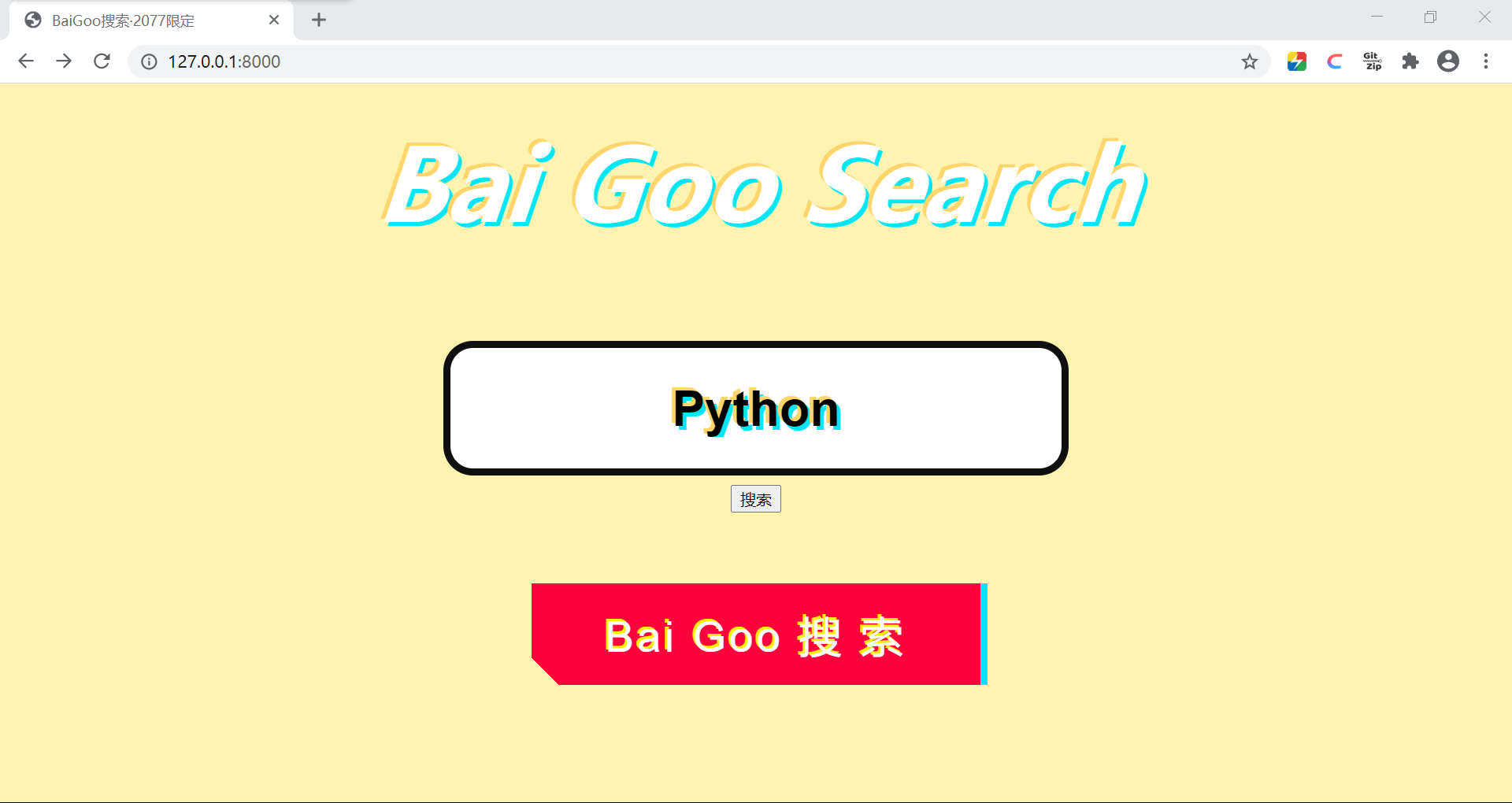
在这样进行爬取之后,获得的结果就是没有商业推广结果的信息了,爬取结果均用json文件的形式保存下来方便之后使用。软件的编写应该对用户友好,所以此处我要新建一个用于前端输入检索关键字的页面,于是我需要使用到Django进行前后端的交互。最终得到了如下的结果:
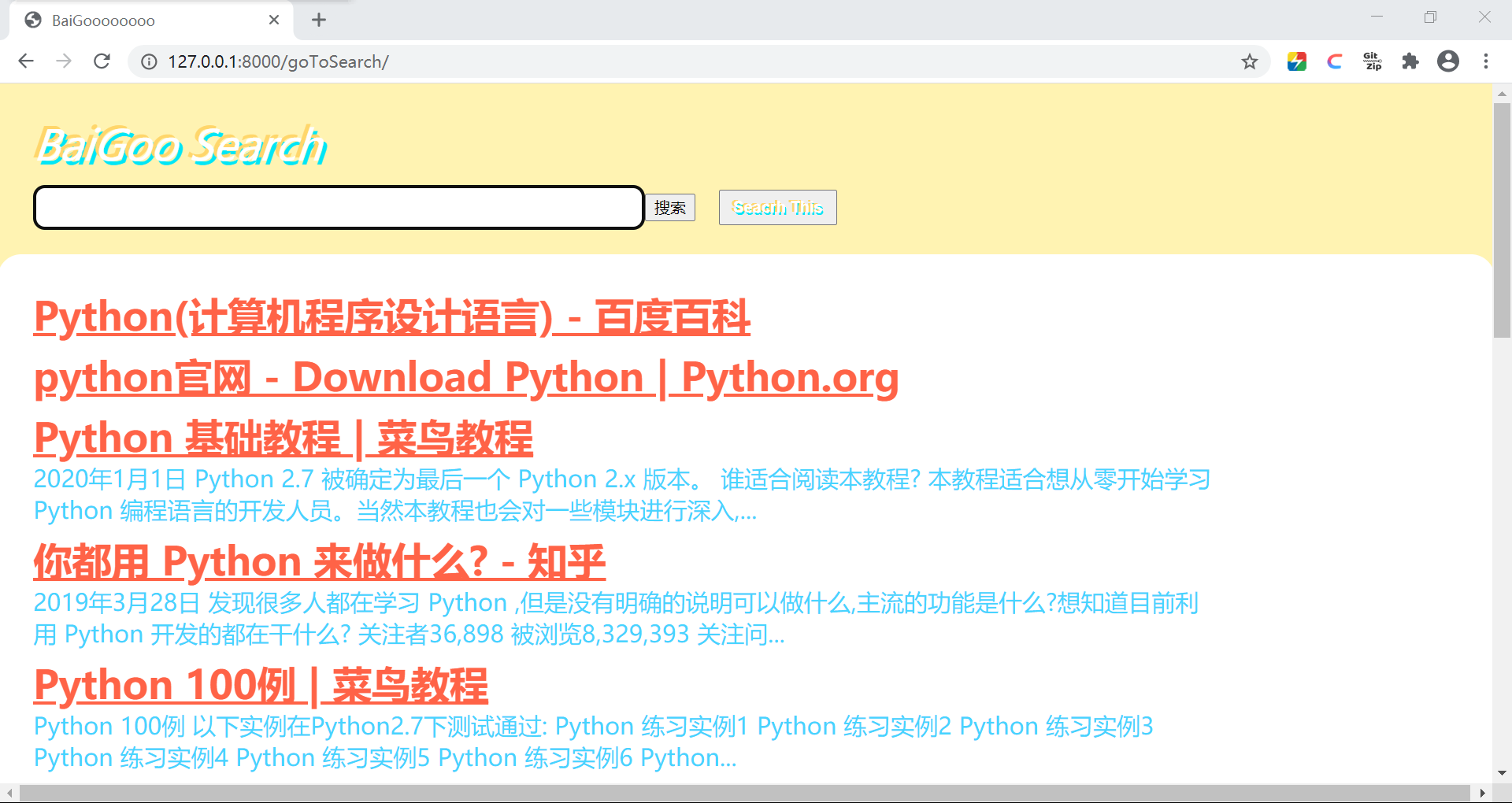
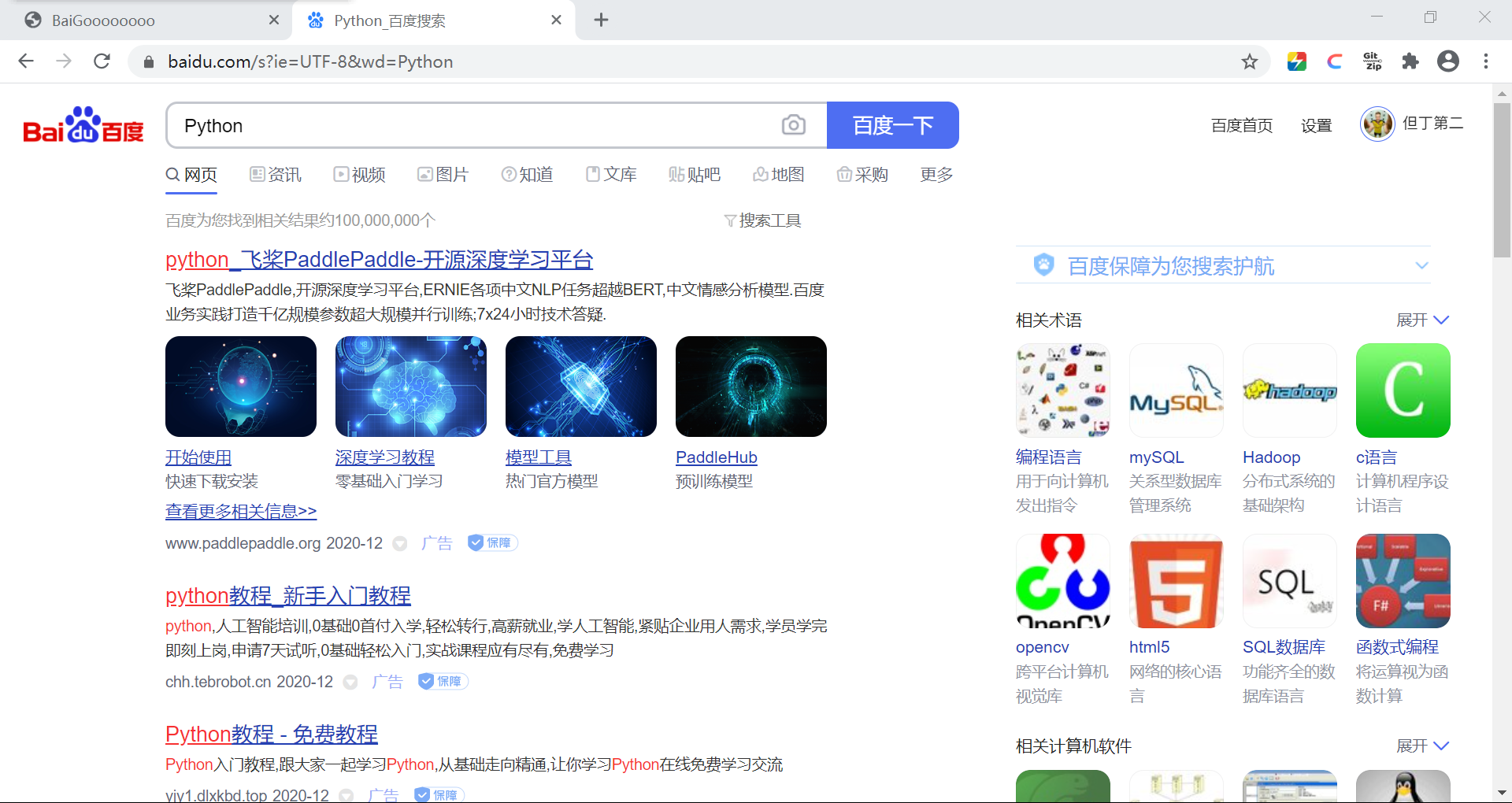
对比没有过滤的搜索结果

若有收获,就点个赞吧
0 人点赞
