运行架构
Spark 框架的核心是一个计算引擎,整体来说,它采用了标准 master-slave 的结构。 如下图所示,它展示了一个 Spark 执行时的基本结构。图形中的 Driver 表示 master, 负责管理整个集群中的作业任务调度。图形中的 Executor 则是 slave,负责实际执行任务。 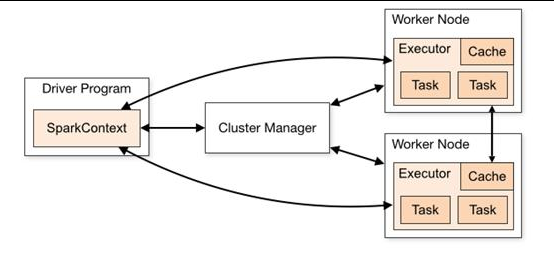
Driver : 驱动
Master:主要的
Executor:执行者
Slave :奴隶,苦工
核心组件
Driver
Spark 驱动器节点,用于执行 Spark 任务中的 main 方法,负责实际代码的执行工作。
Driver 在 Spark 作业执行时主要负责:
➢ 将用户程序转化为作业(job)
➢ 在 Executor 之间调度任务 (task)
➢ 跟踪 Executor 的执行情况
➢ 通过 UI 展示查询运行情况
实际上,我们无法准确地描述 Driver 的定义,因为在整个的编程过程中没有看到任何有关 Driver 的字眼。所以简单理解,所谓的 Driver 就是驱使整个应用运行起来的程序,也称之为 Driver 类。
Executor
Spark Executor 是集群中工作节点(Worker)中的一个 JVM 进程,负责在 Spark 作业 中运行具体任务(Task),任务彼此之间相互独立。Spark 应用启动时,Executor 节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有 Executor 节点发生了 故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他 Executor 节点 上继续运行。
Executor 有两个核心功能:
➢ 负责运行组成 Spark 应用的任务,并将结果返回给驱动器进程
➢ 它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存 式存储。RDD 是直接缓存在 Executor 进程内的,因此任务可以在运行时充分利用缓存 数据加速运算。
Master & Worker
Spark 集群的独立部署环境中,不需要依赖其他的资源调度框架,自身就实现了资源调 度的功能,所以环境中还有其他两个核心组件:Master 和 Worker,这里的 Master 是一个进 程,主要负责资源的调度和分配,并进行集群的监控等职责,类似于 Yarn 环境中的 RM, 而 Worker 呢,也是进程,一个 Worker 运行在集群中的一台服务器上,由 Master 分配资源对数据进行并行的处理和计算,类似于 Yarn 环境中 NM。
ApplicationMaster (应用程序管理器)
Hadoop用户向 YARN 集群提交应用程序时,提交程序中应该包含 ApplicationMaster,用于向资源调度器申请执行任务的资源容器 Container,运行用户自己的程序任务 job,监控整个任务的执行,跟踪整个任务的状态,处理任务失败等异常情况。 说的简单点就是,ResourceManager(资源)和 Driver(计算)之间的解耦合靠的就是 ApplicationMaster。
Container是nodemanager虚拟出来的容器,用来运行task任务的。
耦合是指两个或两个以上的体系或两种运动形式间通过相互作用而彼此影响以至联合起来的现象。 解耦就是用数学方法将两种运动分离开来处理问题,常用解耦方法就是忽略或简化对所研究问题影响较小的一种运动,只分析主要的运动。

若有收获,就点个赞吧
0 人点赞
