bufio 包介绍
bufio包实现了有缓冲的I/O。它包装一个io.Reader或io.Writer接口对象,创建另一个也实现了该接口,且同时还提供了缓冲和一些文本I/O的帮助函数的对象。
bufio 是通过缓冲来提高效率
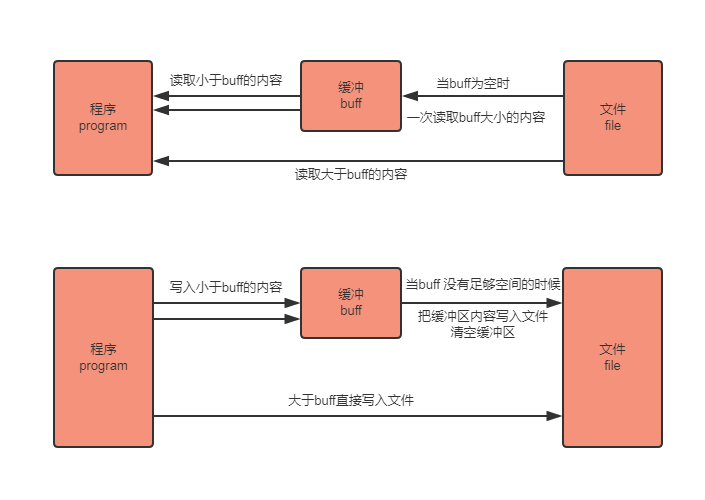
简单的说就是,把文件读取进缓冲(内存)之后再读取的时候就可以避免文件系统的io 从而提高速度。同理,在进行写操作时,先把文件写入缓冲(内存),然后由缓冲写入文件系统。看完以上解释有人可能会表示困惑了,直接把 内容->文件 和 内容->缓冲->文件相比, 缓冲区好像没有起到作用嘛。其实缓冲区的设计是为了存储多次的写入,最后一口气把缓冲区内容写入文件。下面会详细解释
bufio 封装了io.Reader或io.Writer接口对象,并创建另一个也实现了该接口的对象
io.Reader或io.Writer 接口实现read() 和 write() 方法,对于实现这个接口的对象都是可以使用这两个方法的。
bufio 包实现原理
bufio 源码分析
1 Reader类型
1.1 Reader对象
bufio.Reader 是bufio中对io.Reader 的封装
// Reader implements buffering for an io.Reader object.type Reader struct {buf []byterd io.Reader // reader provided by the clientr, w int // buf read and write positionserr errorlastByte intlastRuneSize int}
bufio.Read(p []byte) 相当于读取大小len(p)的内容,思路如下:
- 当缓存区有内容的时,将缓存区内容全部填入p并清空缓存区
- 当缓存区没有内容的时候且len(p)>len(buf),即要读取的内容比缓存区还要大,直接去文件读取即可
- 当缓存区没有内容的时候且len(p)<len(buf),即要读取的内容比缓存区小,缓存区从文件读取内容充满缓存区,并将p填满(此时缓存区有剩余内容)
- 以后再次读取时缓存区有内容,将缓存区内容全部填入p并清空缓存区(此时和情况1一样)
以下是源码
// Read reads data into p.// It returns the number of bytes read into p.// The bytes are taken from at most one Read on the underlying Reader,// hence n may be less than len(p).// At EOF, the count will be zero and err will be io.EOF.func (b *Reader) Read(p []byte) (n int, err error) {n = len(p)if n == 0 {return 0, b.readErr()}if b.r == b.w {if b.err != nil {return 0, b.readErr()}if len(p) >= len(b.buf) {// Large read, empty buffer.// Read directly into p to avoid copy.n, b.err = b.rd.Read(p)if n < 0 {panic(errNegativeRead)}if n > 0 {b.lastByte = int(p[n-1])b.lastRuneSize = -1}return n, b.readErr()}// One read.// Do not use b.fill, which will loop.b.r = 0b.w = 0n, b.err = b.rd.Read(b.buf)if n < 0 {panic(errNegativeRead)}if n == 0 {return 0, b.readErr()}b.w += n}// copy as much as we cann = copy(p, b.buf[b.r:b.w])b.r += nb.lastByte = int(b.buf[b.r-1])b.lastRuneSize = -1return n, nil}
说明:
reader内部通过维护一个r, w 即读入和写入的位置索引来判断是否缓存区内容被全部读出。
举例:缓冲读
// 默认缓冲区大小const (defaultBufSize = 4096)// 最小缓冲区大小 自定义小于次阈值将会被覆盖const minReadBufferSize = 16// 使用默认缓冲区大小bufio.NewReader(rd io.Reader)// 使用自定义缓冲区大小bufio.NewReaderSize(rd io.Reader, size int)
缓冲读的大致过程如下,设定好缓冲区大小buf_size后,读取的字节数为rn,缓冲的字节数为bn:
- 如果缓冲区为空,且
rn >= buf_size,则直接从文件读取,不启用缓冲。 - 如果缓冲区为空,且
rn < buf_size,则从文件读取buf_size字节的内容到缓冲区,程序再从缓冲区中读取rn字节的内容,此时缓冲区剩余bn = buf_size - rn字节。 - 如果缓冲区不为空,
rn < bn,则从缓冲区读取rn字节的内容,不发生文件IO。 - 如果缓冲区不为空,
rn >= bn,则从缓冲区读取bn字节的内容,不发生文件IO,缓冲区置为空,回归1/2步骤。
缓冲读通过预读,可以在一定程度上减少文件IO次数,故提高性能。
代码演示:
package mainimport ("bufio""fmt""strings")func main() {// 用 strings.Reader 模拟一个文件IO对象strReader := strings.NewReader("12345678901234567890123456789012345678901234567890")// go 的缓冲区最小为 16 byte,我们用最小值比较容易演示bufReader := bufio.NewReaderSize(strReader, 16)// bn = 0 但 rn >= buf_size 缓冲区不启用 发生文件IOtmpStr := make([]byte, 16)n, _ := bufReader.Read(tmpStr)// bufReader buffered: 0, content: 1234567890123456fmt.Printf("bufReader buffered: %d, content: %s\n", bufReader.Buffered(), tmpStr[:n])// bn = 0 rn < buf_size 缓冲区启用// 缓冲区从文件读取 buf_size 字节 发生文件IO// 程序从缓冲区读取 rn 字节// 缓冲区剩余 bn = buf_size - rn 字节tmpStr = make([]byte, 15)n, _ = bufReader.Read(tmpStr)// bufReader buffered: 1, content: 789012345678901fmt.Printf("bufReader buffered: %d, content: %s\n", bufReader.Buffered(), tmpStr[:n])// bn = 1 rn > bn// 程序从缓冲区读取 bn 字节 缓冲区置空 不发生文件IO// 注意这里只能读到一个字节tmpStr = make([]byte, 10)n, _ = bufReader.Read(tmpStr)// bufReader buffered: 0, content: 2fmt.Printf("bufReader buffered: %d, content: %s\n", bufReader.Buffered(), tmpStr[:n])// bn = 0 rn < buf_size 启用缓冲读 发生文件IO// 缓冲区从文件读取 buf_size 字节// 程序从缓冲区读取 rn 字节// 缓冲区剩余 bn = buf_size - rn 字节tmpStr = make([]byte, 10)n, _ = bufReader.Read(tmpStr)// bufReader buffered: 6, content: 3456789012fmt.Printf("bufReader buffered: %d, content: %s\n", bufReader.Buffered(), tmpStr[:n])// bn = 6 rn <= bn// 则程序冲缓冲区读取 rn 字节 不发生文件IOtmpStr = make([]byte, 3)n, _ = bufReader.Read(tmpStr)// bufReader buffered: 3, content: 345fmt.Printf("bufReader buffered: %d, content: %s\n", bufReader.Buffered(), tmpStr[:n])// bn = 3 rn <= bn// 则程序冲缓冲区读取 rn 字节 不发生文件IOtmpStr = make([]byte, 3)n, _ = bufReader.Read(tmpStr)// bufReader buffered: 0, content: 678fmt.Printf("bufReader buffered: %d, content: %s\n", bufReader.Buffered(), tmpStr[:n])}
要注意的是当缓冲区中有内容时,程序的此次读取都会从缓冲区读,而不会发生文件IO。只有当缓冲区为空时,才会发生文件IO。如果缓冲区的大小足够,则启用缓冲读,先将内容载入填满缓冲区,程序再从缓冲区中读取。如果缓冲区过小,则会直接从文件读取,而不使用缓冲读。
1.2 NewReader 和 NewReaderSize函数
bufio 包提供了两个实例化 bufio.Reader 对象的函数:NewReader 和 NewReaderSize。其中,NewReader 函数是调用 NewReaderSize 函数实现的:
func NewReader(rd io.Reader) *Reader {// 默认缓存大小:defaultBufSize=4096return NewReaderSize(rd, defaultBufSize)}
我们看一下NewReaderSize的源码:
func NewReaderSize(rd io.Reader, size int) *Reader {// 已经是bufio.Reader类型,且缓存大小不小于 size,则直接返回b, ok := rd.(*Reader)if ok && len(b.buf) >= size {return b}// 缓存大小不会小于 minReadBufferSize (16字节)if size < minReadBufferSize {size = minReadBufferSize}// 构造一个bufio.Reader实例return &Reader{buf: make([]byte, size),rd: rd,lastByte: -1,lastRuneSize: -1,}}
1.3 ReadSlice、ReadBytes、ReadString 和 ReadLine 方法
1.3.1 ReadSlice
事实上,后三个方法最终都是调用ReadSlice来实现的
ReadSlice方法签名如下:
func (b *Reader) ReadSlice(delim byte) (line []byte, err error)
ReadSlice 从输入中读取,直到遇到第一个界定符(delim)为止,返回一个指向缓存中字节的 slice,在下次调用读操作(read)时,这些字节会无效。举例说明:
[root@localhost bufio]# cat bufio1.gopackage mainimport ("fmt""bufio""strings")func main() {reader := bufio.NewReader(strings.NewReader("http://studygolang.com. \nIt is the home of gophers"))line, _ := reader.ReadSlice('\n')fmt.Printf("the line:%s\n", line)// 这里可以换上任意的 bufio 的 Read/Write 操作n, _ := reader.ReadSlice('\n')fmt.Printf("the line:%s\n", line)fmt.Println(string(n))}[root@localhost bufio]# go run bufio1.gothe line:http://studygolang.com.the line:It is the home of gophersIt is the home of gophers
1.3.2 ReadSlice 的err
如果 ReadSlice 在找到界定符之前遇到了 error ,它就会返回缓存中所有的数据和错误本身(经常是 io.EOF)。如果在找到界定符之前缓存已经满了,ReadSlice 会返回 bufio.ErrBufferFull 错误。当且仅当返回的结果(line)没有以界定符结束的时候,ReadSlice 返回err != nil,也就是说,如果ReadSlice 返回的结果 line 不是以界定符 delim 结尾,那么返回的 er r也一定不等于 nil(可能是bufio.ErrBufferFull或io.EOF)。
[root@localhost bufio]# cat bufio4.gopackage mainimport ("fmt""bufio""strings")func main() {reader := bufio.NewReaderSize(strings.NewReader("http://studygolang.com"),16)line, err := reader.ReadSlice('\n')fmt.Printf("line:%s\terror:%s\n", line, err)line, err = reader.ReadSlice('\n')fmt.Printf("line:%s\terror:%s\n", line, err)}[root@localhost bufio]# go run bufio4.goline:http://studygola error:bufio: buffer fullline:ng.com error:EOF
1.3.3 ReadBytes
该方法的参数和返回值类型与 ReadSlice 都一样。 ReadBytes 从输入中读取直到遇到界定符(delim)为止,返回的 slice 包含了从当前到界定符的内容 (包括界定符)。如果 ReadBytes 在遇到界定符之前就捕获到一个错误,它会返回遇到错误之前已经读取的数据,和这个捕获到的错误(经常是 io.EOF)。跟 ReadSlice 一样,如果 ReadBytes 返回的结果 line 不是以界定符 delim 结尾,那么返回的 err 也一定不等于 nil(可能是bufio.ErrBufferFull 或 io.EOF)。
从这个说明可以看出,ReadBytes和ReadSlice功能和用法都很像,那他们有什么不同呢?
在讲解ReadSlice时说到,它返回的 []byte 是指向 Reader 中的 buffer,而不是 copy 一份返回,也正因为如此,通常我们会使用 ReadBytes 或 ReadString。很显然,ReadBytes 返回的 []byte 不会是指向 Reader 中的 buffer,通过查看源码可以证实这一点。
[root@localhost bufio]# cat bufio2.gopackage mainimport ("fmt""bufio""strings")func main() {reader := bufio.NewReader(strings.NewReader("http://studygolang.com. \nIt is the home of gophers"))line, _ := reader.ReadBytes('\n')fmt.Printf("the line:%s\n", line)// 这里可以换上任意的 bufio 的 Read/Write 操作n, _ := reader.ReadBytes('\n')fmt.Printf("the line:%s\n", line)fmt.Println(string(n))}[root@localhost bufio]# go run bufio2.gothe line:http://studygolang.com.the line:http://studygolang.com.It is the home of gophers
1.3.4 ReadString
ReadString方法
看一下该方法的源码:
func (b *Reader) ReadString(delim byte) (line string, err error) {bytes, err := b.ReadBytes(delim)return string(bytes), err}
它调用了 ReadBytes 方法,并将结果的 []byte 转为 string 类型。
[root@localhost bufio]# go run bufio3.gothe line:http://studygolang.com.the line:http://studygolang.com.It is the home of gophers[root@localhost bufio]# cat bufio3.gopackage mainimport ("fmt""bufio""strings")func main() {reader := bufio.NewReader(strings.NewReader("http://studygolang.com. \nIt is the home of gophers"))line, _ := reader.ReadString('\n')fmt.Printf("the line:%s\n", line)// 这里可以换上任意的 bufio 的 Read/Write 操作n, _ := reader.ReadString('\n')fmt.Printf("the line:%s\n", line)fmt.Println(string(n))}[root@localhost bufio]# go run bufio3.gothe line:http://studygolang.com.the line:http://studygolang.com.It is the home of gophers
从结果可以看出,第一次ReadSlice的结果(line),在第二次调用读操作后,内容发生了变化。也就是说,ReadSlice 返回的 []byte 是指向 Reader 中的 buffer ,而不是 copy 一份返回。正因为ReadSlice 返回的数据会被下次的 I/O 操作重写,因此许多的客户端会选择使用 ReadBytes 或者 ReadString 来代替。
注意:这里的界定符可以是任意的字符,可以将上面代码中的'\n'改为'm'试试。同时,返回的结果是包含界定符本身的,上例中,输出结果有一空行就是’\n’本身(line携带一个’\n’,printf又追加了一个’\n’)。
打印换行注意:
package mainimport ("bufio""fmt""io""strings")func main() {s := "a\nb\nc"reader := bufio.NewReader(strings.NewReader(s))for {line, err := reader.ReadString('\n')if err != nil {if err == io.EOF {break}panic(err)}fmt.Printf("%#v\n", line)}}
上面这段代码的输出是:
"a\n""b\n"
为什么c没有输出?这里算是一个坑。之前讨论过,按行读取的话ReadString函数需要以\n作为分割,上面那种特殊情况当数据末尾没有\n的时候,直到EOF还没有分隔符\n,这时候返回EOF错误,但是line里面还是有数据的,如果不处理的话就会漏掉最后一行。简单修改一下:
package mainimport ("bufio""fmt""io""strings")func main() {s := "a\nb\nc"reader := bufio.NewReader(strings.NewReader(s))for {line, err := reader.ReadString('\n')if err != nil {if err == io.EOF {fmt.Printf("%#v\n", line)break}panic(err)}fmt.Printf("%#v\n", line)}}这样执行会输出:"a\n""b\n""c"
1.3.5 ReadLine
ReadLine方法签名如下
func (b *Reader) ReadLine() (line []byte, isPrefix bool, err error)
ReadLine 是一个底层的原始行读取命令。许多调用者或许会使用 ReadBytes(’\n’) 或者 ReadString(’\n’) 来代替这个方法。
ReadLine 尝试返回单独的行,不包括行尾的换行符。如果一行大于缓存,isPrefix 会被设置为 true,同时返回该行的开始部分(等于缓存大小的部分)。该行剩余的部分就会在下次调用的时候返回。当下次调用返回该行剩余部分时,isPrefix 将会是 false 。跟 ReadSlice 一样,返回的 line 只是 buffer 的引用,在下次执行IO操作时,line 会无效。可以将 ReadSlice 中的例子该为 ReadLine 试试。
[root@localhost bufio]# cat bufio5.gopackage mainimport ("fmt""bufio""strings")func main() {reader := bufio.NewReader(strings.NewReader("http://studygolang.com.\nIt is the home of gophers"))line, _, _ := reader.ReadLine()fmt.Printf("the line:%s\n", line)// 这里可以换上任意的 bufio 的 Read/Write 操作n, _, _ := reader.ReadLine()fmt.Printf("the line:%s\n", line)fmt.Println(string(n))}[root@localhost bufio]# go run bufio5.gothe line:http://studygolang.com.the line:It is the home of gopheIt is the home of gophers
注意:返回值中,要么 line 不是 nil,要么 err 非 nil,两者不会同时非 nil。
ReadLine 返回的文本不会包含行结尾(”\r\n”或者”\n”)。如果输入中没有行尾标识符,不会返回任何指示或者错误。
从上面的讲解中,我们知道,读取一行,通常会选择 ReadBytes 或 ReadString。不过,正常人的思维,应该用 ReadLine,只是不明白为啥 ReadLine 的实现不是通过 ReadBytes,然后清除掉行尾的\n(或\r\n),它现在的实现,用不好会出现意想不到的问题,比如丢数据。个人建议可以这么实现读取一行:
line, err := reader.ReadBytes('\n')line = bytes.TrimRight(line, "\r\n")
1.4 Peek 方法
从方法的名称可以猜到,该方法只是“窥探”一下 Reader 中没有读取的 n 个字节。好比栈数据结构中的取栈顶元素,但不出栈。
方法的签名如下:
func (b *Reader) Peek(n int) ([]byte, error)
同上面介绍的 ReadSlice一样,返回的 []byte 只是 buffer 中的引用,在下次IO操作后会无效,可见该方法(以及ReadSlice这样的,返回buffer引用的方法)对多 goroutine 是不安全的,也就是在多并发环境下,不能依赖其结果。
我们通过例子来证明一下:
package mainimport ("bufio""fmt""strings""time")func main() {reader := bufio.NewReaderSize(strings.NewReader("http://studygolang.com.\t It is the home of gophers"), 14)go Peek(reader)go reader.ReadBytes('\t')time.Sleep(1e8)}func Peek(reader *bufio.Reader) {line, _ := reader.Peek(14)fmt.Printf("%s\n", line)// time.Sleep(1)fmt.Printf("%s\n", line)}
输出:
http://studygohttp://studygo
输出结果和预期的一致。然而,这是由于目前的 goroutine 调度方式导致的结果。如果我们将例子中注释掉的 time.Sleep(1) 取消注释(这样调度其他 goroutine 执行),再次运行,得到的结果为:
http://studygong.com. It is
另外,Reader 的 Peek 方法如果返回的 []byte 长度小于 n,这时返回的 err != nil ,用于解释为啥会小于 n。如果 n 大于 reader 的 buffer 长度,err 会是 ErrBufferFull。
1.5 其他方法
Reader 的其他方法都是实现了 io 包中的接口,它们的使用方法在io包中都有介绍,在此不赘述。
这些方法包括:
func (b *Reader) Read(p []byte) (n int, err error)func (b *Reader) ReadByte() (c byte, err error)func (b *Reader) ReadRune() (r rune, size int, err error)func (b *Reader) UnreadByte() errorfunc (b *Reader) UnreadRune() errorfunc (b *Reader) WriteTo(w io.Writer) (n int64, err error)
2 Scanner
2.1 概念
在 bufio 包中有多种方式获取文本输入,ReadBytes、ReadString 和独特的 ReadLine,对于简单的目的这些都有些过于复杂了。在 Go 1.1 中,添加了一个新类型,Scanner,以便更容易的处理如按行读取输入序列或空格分隔单词等,这类简单的任务。它终结了如输入一个很长的有问题的行这样的输入错误,并且提供了简单的默认行为:基于行的输入,每行都剔除分隔标识。这里的代码展示一次输入一行:
scanner := bufio.NewScanner(os.Stdin)for scanner.Scan() {fmt.Println(scanner.Text()) // Println will add back the final '\n'}if err := scanner.Err(); err != nil {fmt.Fprintln(os.Stderr, "reading standard input:", err)}
输入的行为可以通过一个函数控制,来控制输入的每个部分(参阅 SplitFunc 的文档),但是对于复杂的问题或持续传递错误的,可能还是需要原有接口。
Scanner 类型和 Reader 类型一样,没有任何导出的字段,同时它也包装了一个 io.Reader 对象,但它没有实现 io.Reader 接口。
Scanner 的结构定义如下:
type Scanner struct {r io.Reader // The reader provided by the client.split SplitFunc // The function to split the tokens.maxTokenSize int // Maximum size of a token; modified by tests.token []byte // Last token returned by split.buf []byte // Buffer used as argument to split.start int // First non-processed byte in buf.end int // End of data in buf.err error // Sticky error.}
这里 split、maxTokenSize 和 token 需要讲解一下。
然而,在讲解之前,需要先讲解 split 字段的类型 SplitFunc。
SplitFunc 类型定义如下:
type SplitFunc func(data []byte, atEOF bool) (advance int, token []byte, err error)
SplitFunc 定义了 用于对输入进行分词的 split 函数的签名。参数 data 是还未处理的数据,atEOF 标识 Reader 是否还有更多数据(是否到了EOF)。返回值 advance 表示从输入中读取的字节数,token 表示下一个结果数据,err 则代表可能的错误。
举例说明一下这里的 token 代表的意思:
有数据 “studygolang\tpolaris\tgolangchina”,通过”\t”进行分词,那么会得到三个token,它们的内容分别是:studygolang、polaris 和 golangchina。SplitFunc 的功能是:进行分词,并返回未处理的数据中第一个 token。对于这个数据,就是返回 studygolang。
如果 data 中没有一个完整的 token,例如,在扫描行(scanning lines)时没有换行符,SplitFunc 会返回(0,nil,nil)通知 Scanner 读取更多数据到 slice 中,然后在这个更大的 slice 中同样的读取点处,从输入中重试读取。如下面要讲解的 split 函数的源码中有这样的代码:
// Request more data.return 0, nil, nil• 1• 2
如果 err != nil,扫描停止,同时该错误会返回。
如果参数 data 为空的 slice,除非 atEOF 为 true,否则该函数永远不会被调用。如果 atEOF 为 true,这时 data 可以非空,这时的数据是没有处理的。
bufio 包定义的 split 函数,即 SplitFunc 的实例
在 bufio 包中预定义了一些 split 函数,也就是说,在 Scanner 结构中的 split 字段,可以通过这些预定义的 split 赋值,同时 Scanner 类型的 Split 方法也可以接收这些预定义函数作为参数。所以,我们可以说,这些预定义 split 函数都是 SplitFunc 类型的实例。这些函数包括:ScanBytes、ScanRunes、ScanWords 和 ScanLines。(由于都是 SplitFunc 的实例,自然这些函数的签名都和 SplitFunc 一样)
ScanBytes返回单个字节作为一个 token。- ScanRunes 返回单个 UTF-8 编码的 rune 作为一个 token。返回的 rune 序列(token)和 range
string类型 返回的序列是等价的,也就是说,对于无效的 UTF-8 编码会解释为 U+FFFD = “\xef\xbf\xbd”。 - ScanWords 返回通过“空格”分词的单词。如:study golang,调用会返回study。注意,这里的“空格”是unicode.IsSpace(),即包括:’\t’, ‘\n’, ‘\v’, ‘\f’, ‘\r’, ’ ‘, U+0085(NEL), U+00A0 (NBSP)。
- ScanLines 返回一行文本,不包括行尾的换行符。这里的换行包括了Windows下的”\r\n”和Unix下的”\n”。
一般地,我们不会单独使用这些函数,而是提供给 Scanner 实例使用。现在我们回到 Scanner 的 split、maxTokenSize 和 token 字段上来。
split 字段(SplitFunc 类型实例),很显然,代表了当前 Scanner 使用的分词策略,可以使用上面介绍的预定义 SplitFunc 实例赋值,也可以自定义 SplitFunc 实例。(当然,要给 split 字段赋值,必须调用 Scanner 的 Split 方法)
maxTokenSize 字段 表示通过 split 分词后的一个 token 允许的最大长度。在该包中定义了一个常量 MaxScanTokenSize = 64 * 1024,这是允许的最大 token 长度(64k)。
对于Scanner.Scan方法,相当于其他语言的迭代器iterator,并把迭代器指向的数据存放到新的缓冲区里。新的缓冲区(token)可以通过scanner.Text()或者scanner.Bytes()获取到
2.2 bufio.NewScanner(os.Stdin)
package mainimport ("bufio""fmt""os")func main() {scanner := bufio.NewScanner(os.Stdin)for scanner.Scan() {fmt.Println(scanner.Text()) // Println will add back the final '\n'}if err := scanner.Err(); err != nil {fmt.Fprintln(os.Stderr, "reading standard input:", err)}}
[root@localhost bufio]# go run bufio7.gols #输入lsls #输出
2.3 预定义的四种输出模式
package mainimport ("bufio""fmt""strings")func main() {input := "foo bar baz"scanner := bufio.NewScanner(strings.NewReader(input))//scanner.Split(bufio.ScanWords)//scanner.Split(bufio.ScanLines)//scanner.Split(bufio.ScanRunes)//scanner.Split(bufio.ScanBytes)for scanner.Scan() {fmt.Println(scanner.Text())}}
[root@localhost bufio]# go run bufio6.go #Scanner.Scan方法默认是以换行符\n,作为分隔符foo bar baz[root@localhost bufio]# go run bufio6.go #bufio.ScanWords返回通过“空格”分词的单词foobarbaz[root@localhost bufio]# go run bufio6.go #bufio.ScanLines返回一行文本foo bar baz[root@localhost bufio]# go run bufio6.go #bufio.ScanRunes返回单个 UTF-8 编码的 rune 作为一个 tokenfoobabaz[root@localhost bufio]# go run bufio6.go #bufio.ScanBytes返回单个字节作为一个 tokenfoobarbaz
2.4 split函数定义输出
package mainimport ("bufio""fmt""strings")func main() {input := "abcdefghijkl"scanner := bufio.NewScanner(strings.NewReader(input))split := func(data []byte, atEOF bool) (advance int, token []byte, err error) {fmt.Printf("%t\t%d\t%s\n", atEOF, len(data), data)return 0, nil, nil}scanner.Split(split)buf := make([]byte, 2)scanner.Buffer(buf, bufio.MaxScanTokenSize)for scanner.Scan() {fmt.Printf("%s\n", scanner.Text())}}
[root@localhost bufio]# go run bufio8.gofalse 2 abfalse 4 abcdfalse 8 abcdefghfalse 12 abcdefghijkltrue 12 abcdefghijkl
split 方法非常简单而且贪婪 – 总是想要更多的数据。Scanner 会试图读取更多,但是当然前提条件是缓冲区需要充足的空间。在我们的例子中空间大小从 2 开始:
buf := make([]byte, 2)scanner.Buffer(buf, bufio.MaxScanTokenSize)
在第一次调用 split 方法后,Scanner 会将缓冲区的大小加倍,读取更多的数据并第二次调用分割函数。
2.5 atEOF输出
atEOF 这个参数,它被设计用来通知 split 方法是否没有更多的数据可以读取了,如果到达 EOF,或者出现错误,任何一个发生,scanner 就停止不在读取了,这个标记可以返回错误,scanner.Split() 会返回 false 并停止执行。错误后面可以使用 Err 方法来获取:
package mainimport ("bufio""errors""fmt""strings")func main() {input := "abcdefghijkl"scanner := bufio.NewScanner(strings.NewReader(input))split := func(data []byte, atEOF bool) (advance int, token []byte, err error) {fmt.Printf("%t\t%d\t%s\n", atEOF, len(data), data)if atEOF {return 0, nil, errors.New("bad luck")}return 0, nil, nil}scanner.Split(split)buf := make([]byte, 12)scanner.Buffer(buf, bufio.MaxScanTokenSize)for scanner.Scan() {fmt.Printf("%s\n", scanner.Text())}if scanner.Err() != nil {fmt.Printf("error: %s\n", scanner.Err())}}
[root@localhost bufio]# go run bufio9.gofalse 12 abcdefghijkltrue 12 abcdefghijklerror: bad luck
2.6 atEOF不是真正的错误
package mainimport ("bufio""errors""fmt""strings")func main() {input := "abcdefghijkl"scanner := bufio.NewScanner(strings.NewReader(input))split := func(data []byte, atEOF bool) (advance int, token []byte, err error) {return 0, nil, errors.New("bad luck")}scanner.Split(split)for scanner.Scan() {fmt.Printf("%s\n", scanner.Text())}if scanner.Err() != nil {fmt.Printf("error: %s\n", scanner.Err())}}
[root@localhost bufio]# go run bufio11.goerror: bad luck
2.7 Maximum token size / ErrTooLong
默认情况下,下面使用的缓冲区的最大长度是 64 * 1024 字节。这意味着找到的 token 不能超过此限制:
package mainimport ("bufio""fmt""strings")func main() {input := strings.Repeat("x", bufio.MaxScanTokenSize)scanner := bufio.NewScanner(strings.NewReader(input))for scanner.Scan() {fmt.Println(scanner.Text())}if scanner.Err() != nil {fmt.Println(scanner.Err())}}
[root@localhost bufio]# go run bufio12.gobufio.Scanner: token too long
这个限制可以通过 Buffer 方法来设置
package mainimport ("bufio""fmt""strings")func main() {buf := make([]byte, 30)input := strings.Repeat("x", 20)scanner := bufio.NewScanner(strings.NewReader(input))scanner.Buffer(buf, 20)for scanner.Scan() {fmt.Println(scanner.Text())}if scanner.Err() != nil {fmt.Println(scanner.Err())}}
[root@localhost bufio]# go run bufio13.goxxxxxxxxxxxxxxxxxxxx
2.8 防止无限循环(Protecting against endless loop)
package mainimport ("bufio""bytes""fmt""strings")func main() {input := "foo|bar"scanner := bufio.NewScanner(strings.NewReader(input))split := func(data []byte, atEOF bool) (advance int, token []byte, err error) {if atEOF && len(data) == 0 {return 0, nil, nil}if i := bytes.IndexByte(data, '|'); i >= 0 {return i + 1, data[0:i], nil}if atEOF {return len(data), data[:len(data)], nil}return 0, nil, nil}scanner.Split(split)for scanner.Scan() {if scanner.Text() != "" {fmt.Println(scanner.Text())}}}
[root@localhost bufio]# go run bufio14.gofoobar
3 Writer类型
3.1 Writer对象
bufio.Writer 是bufio中对io.Writer 的封装
// Writer implements buffering for an io.Writer object.type Writer struct {err errorbuf []byten intwr io.Writer}
bufio.Write(p []byte) 的思路如下
- 判断buf中可用容量是否可以放下 p
- 如果能放下,直接把p拼接到buf后面,即把内容放到缓冲区
- 如果缓冲区的可用容量不足以放下,且此时缓冲区是空的,直接把p写入文件即可
- 如果缓冲区的可用容量不足以放下,且此时缓冲区有内容,则用p把缓冲区填满,把缓冲区所有内容写入文件,并清空缓冲区
- 判断p的剩余内容大小能否放到缓冲区,如果能放下(此时和步骤1情况一样)则把内容放到缓冲区
- 如果p的剩余内容依旧大于缓冲区,(注意此时缓冲区是空的,情况和步骤2一样)则把p的剩余内容直接写入文件
以下是源码
// Write writes the contents of p into the buffer.// It returns the number of bytes written.// If nn < len(p), it also returns an error explaining// why the write is short.func (b *Writer) Write(p []byte) (nn int, err error) {for len(p) > b.Available() && b.err == nil {var n intif b.Buffered() == 0 {// Large write, empty buffer.// Write directly from p to avoid copy.n, b.err = b.wr.Write(p)} else {n = copy(b.buf[b.n:], p)b.n += nb.flush()}nn += np = p[n:]}if b.err != nil {return nn, b.err}n := copy(b.buf[b.n:], p)b.n += nnn += nreturn nn, nil}
说明:
b.wr 存储的是一个io.writer对象,实现了Write()的接口,所以可以使用b.wr.Write(p) 将p的内容写入文件
b.flush() 会将缓存区内容写入文件,当所有写入完成后,因为缓存区会存储内容,所以需要手动flush()到文件
b.Available() 为buf可用容量,等于len(buf) - n
下图解释的是其中一种情况,即缓存区有内容,剩余p大于缓存区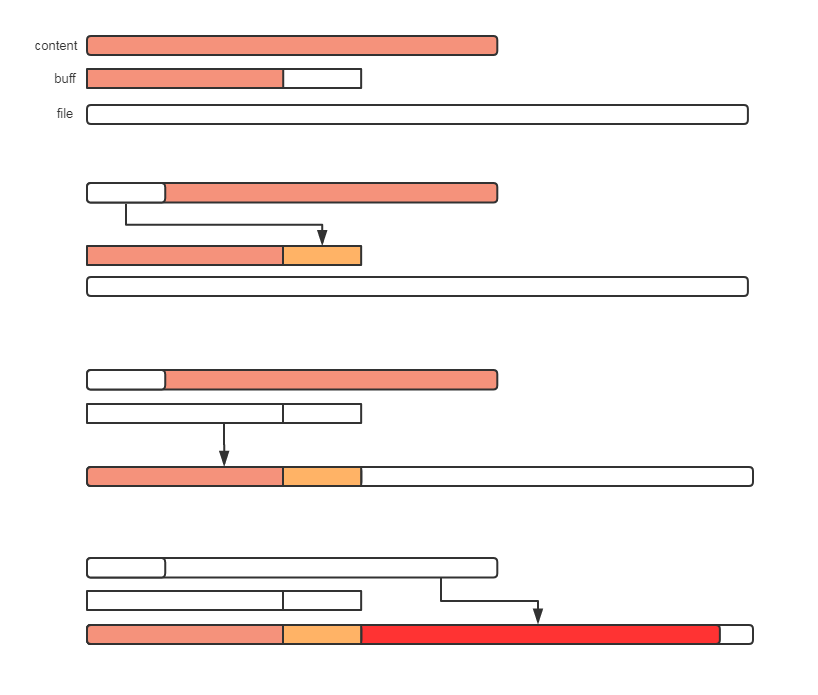
举例:缓冲写
// 使用 defaultBufSize 大小func NewWriter(w io.Writer)// 如果 size <= 0 则使用 defaultBufSizefunc NewWriterSize(w io.Writer, size int)
缓冲写的大致过程如下,设定好缓冲区大小buf_size后,写入的字节数为wn,缓冲的字节数为bn:
- 如果缓冲区为空,且
wn >= buf_size,则直接写入文件,不启用缓冲,发生文件IO。 - 如果缓冲区为空,且
wn < buf_size,则程序将内容写入缓冲区,不发生文件IO。 - 如果缓冲区不为空,
wn + bn < buf_size,则程序将内容写入缓冲区,不发生文件IO。 - 如果缓冲区不为空,
wn + bn >= buf_size,则缓冲区将buf_size字节内容写入文件,缓冲区wn + bn - buf_size的剩余内容。
简单说就是要写入的内容先缓冲着,缓冲不下了则将缓冲区内容写入文件。
代码演示:
package mainimport ("bufio""fmt""io""strings")// 自定义一个 io.Writer 对象type StringWriter struct {}func (s StringWriter) Write(p []byte) (n int, err error) {fmt.Printf("io write: %s\n", p)return len(p), nil}func main() {strReader := strings.NewReader("12345678901234567890")bufReader := bufio.NewReader(strReader)// 自定义的 io.Writer 对象var stringWriter io.WriterstringWriter = StringWriter{}// 写缓冲大小为 6 为了更好的演示我们自定义了一个 io.WriterbufWriter := bufio.NewWriterSize(stringWriter, 6)tmpStr := make([]byte, 8)for true {rn, err := bufReader.Read(tmpStr)if nil != err && io.EOF == err {break}_, err = bufWriter.Write(tmpStr[:rn])fmt.Printf("\nread and write: %s\n", tmpStr[:rn])fmt.Printf("bufWriter buffered: %d, available: %d, size: %d\n", bufWriter.Buffered(), bufWriter.Available(), bufWriter.Size())fmt.Printf("----------------------\n")}// 缓冲区最后剩余的一些内容_ = bufWriter.Flush()}
运行结果:
go run main.go// 没有发生写动作 '1234' 被缓冲read and write: 1234bufWriter buffered: 4, available: 2, size: 6----------------------io write: 123456// '12345678' 缓冲区满 则会写 '123456',继续缓冲 '78'read and write: 5678bufWriter buffered: 2, available: 4, size: 6----------------------// 没有发生写动作 '789012' 被缓冲read and write: 9012bufWriter buffered: 6, available: 0, size: 6----------------------io write: 789012// '7890123456' 缓冲区满 则会写 '789012',继续缓冲 '3456'read and write: 3456bufWriter buffered: 4, available: 2, size: 6----------------------io write: 345678// '34567890' 缓冲区满 则会写 '345678',继续缓冲 '90'read and write: 7890bufWriter buffered: 2, available: 4, size: 6----------------------// 文件读取完毕,输出剩余的 '90'io write: 90
参考:
https://blog.csdn.net/xixihahalelehehe/article/details/105113174
https://medium.com/golangspec/in-depth-introduction-to-bufio-scanner-in-golang-55483bb689b4

若有收获,就点个赞吧
0 人点赞
