由于喜欢看小说,然后爱看的小说越来越多,正版付费越来越高,迫于贫穷,经常使用浏览器搜索盗版小说看,有需求就有市场,市面上出现了多种盗版小说的软件,比如追书神器,笔趣阁之类的.但是通常这一类软件的广告都特别多,每次打开都有广告,熄屏以后打开也有广告,甚至于每一个章节结尾都有广告,虽然浏览器很多都能清爽的看书,但是依旧操作很不方便.
于是,便产生了打造一个属于自己的看书软件的念头,那么问题来了,数据来源怎么办?
经过搜索,确定了两种方案:
1.通过爬虫实时爬去盗版网站上的数据,自己解析,难点在于需要一个服务器,或者使用内网穿透,接受来自前端application的请求
2.通过第三方网站的数据接口,请求接口,自己处理.
经过一番努力,弄出了一个基本的Demo
效果图如下:
1.首页
2.搜索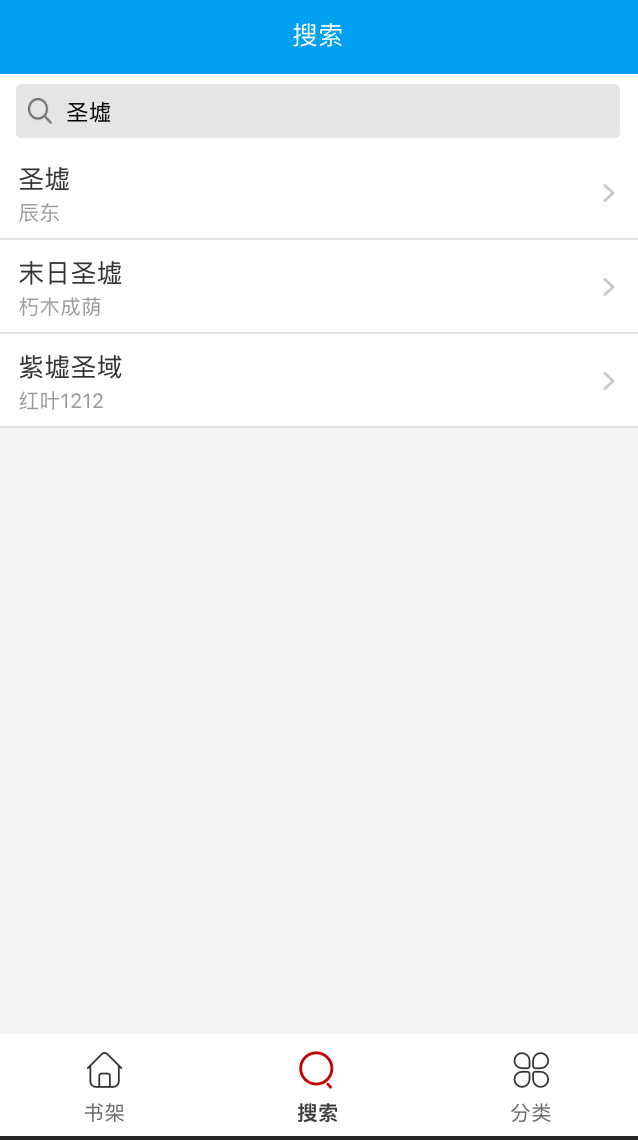
3.分类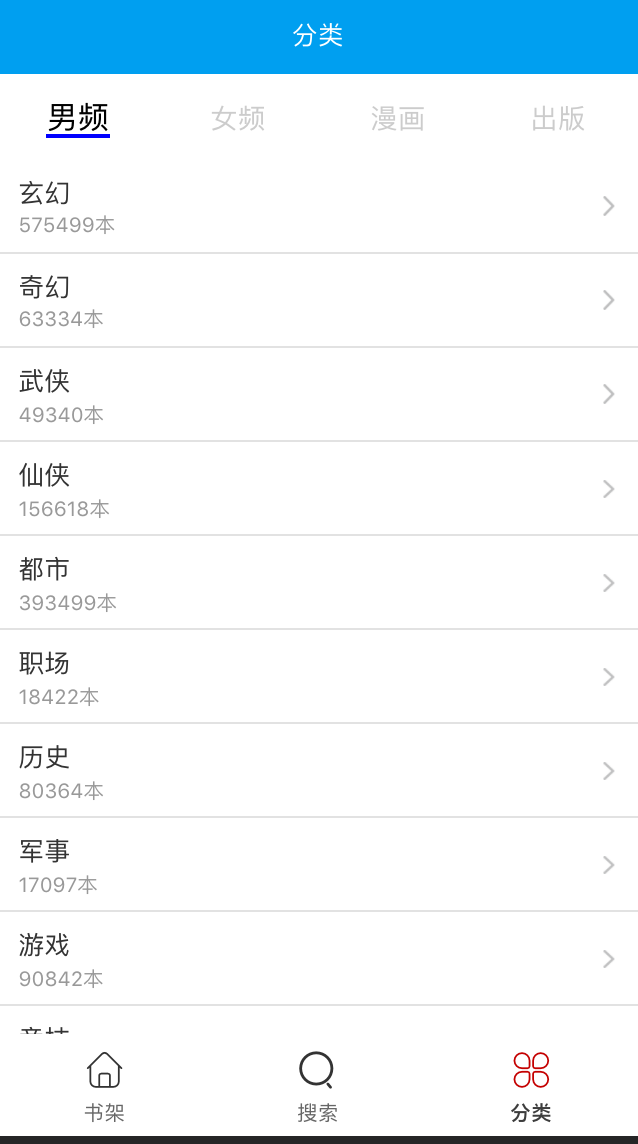
4.分类排行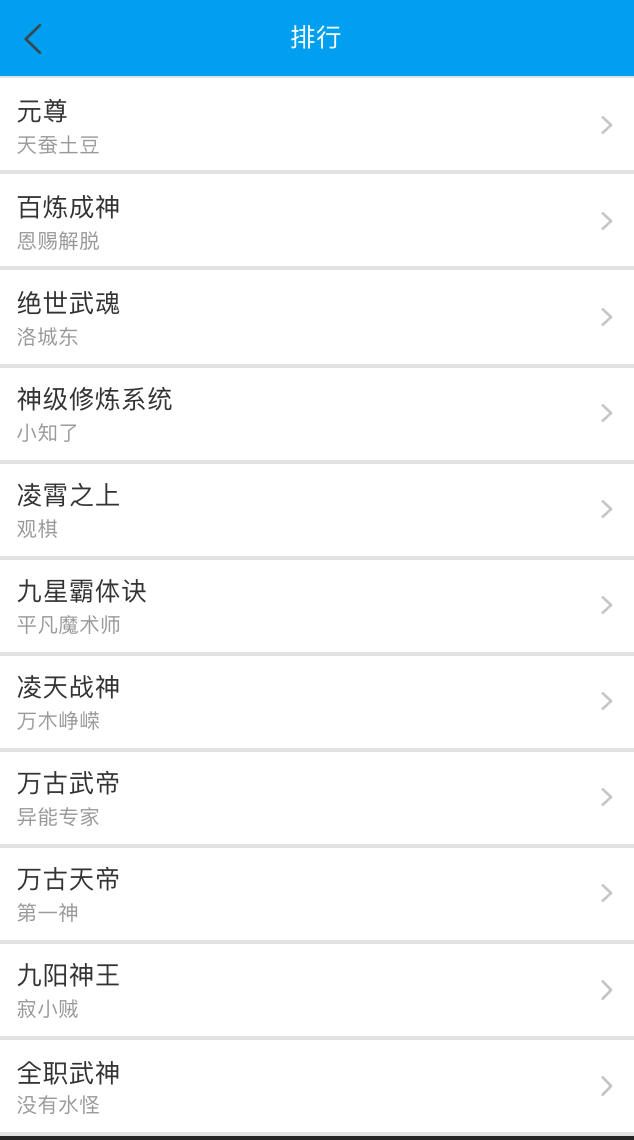
5.书籍详情
6.书籍目录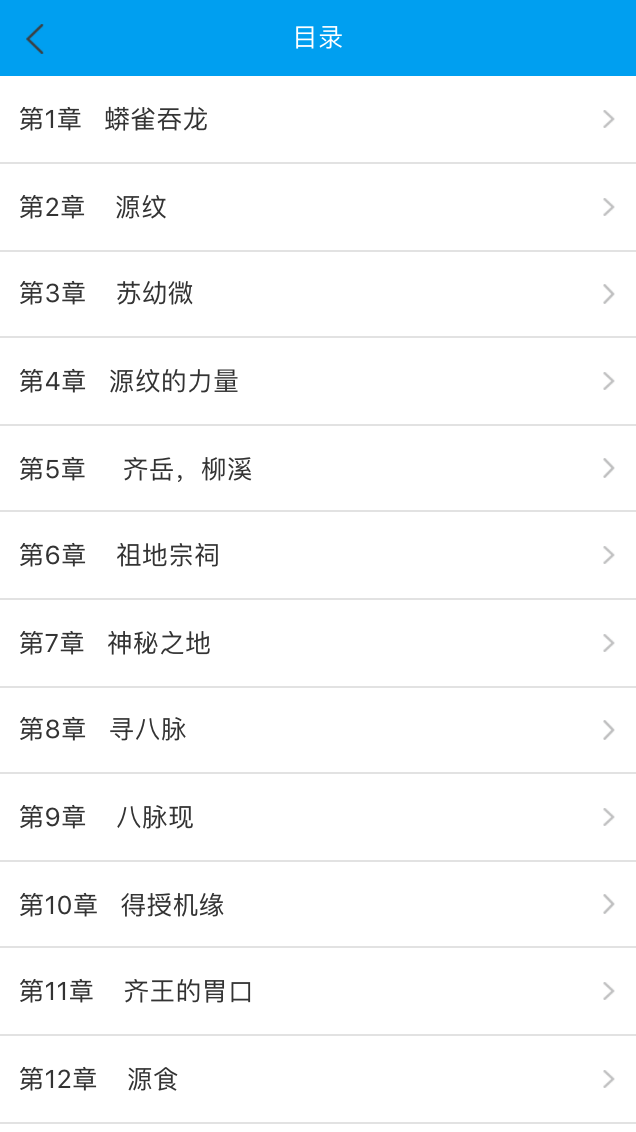
7.章节内容
剩余功能待完善

若有收获,就点个赞吧
0 人点赞
