前言:本节我们一起来总结下Zookeeper几个实战应用场景。
1、分布式任务选主
在分布式系统设计中,选主是一个常见的场景。比如:Job执行,从某个服务模块的多个服务器节点中选择一个主节点,只有主节点可以执行job任务。Zookeeper实现了安全可靠的选主机制,作为zookeeper的高级api封装库curator选主算法主要有以下两个:Leader Latch 和 Leader Election。
1.1 公平锁&非公平锁
在介绍Curator 选主算法之前,我们先来看下面这张梳理图,帮助理解各种锁的概念: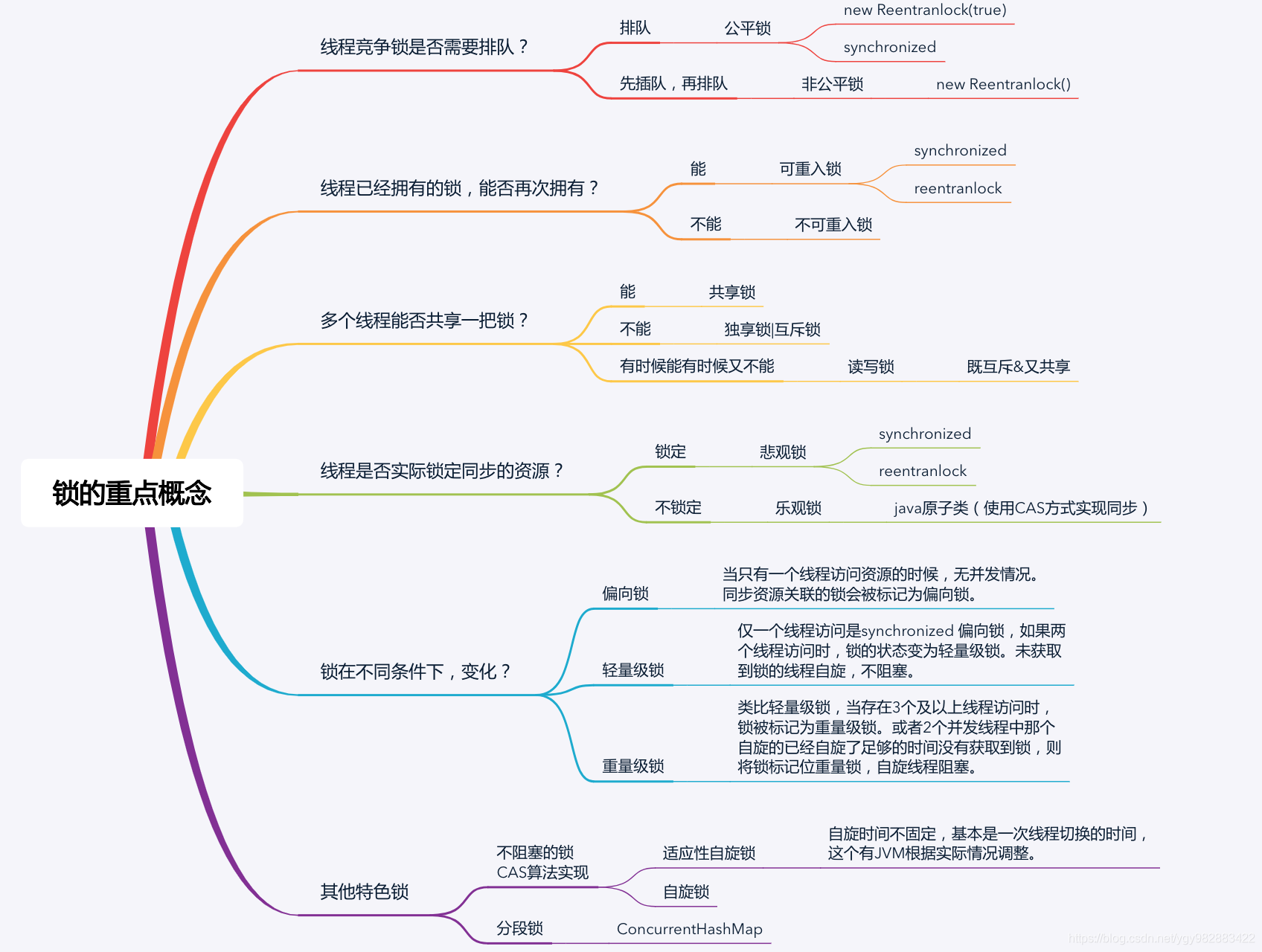
本小节我们只讲公平锁和非公平锁:
公平锁:
是指多个线程按照申请锁的顺序来获取锁,也就是遵循先来后到。每个线程在获取锁时会先查看此锁维护的等待队列,如果为空,或者当前线程是等待队列的第一个,就占有锁,否则就会加入到等待队列中,以后会按照FIFO的规则从队列中取到自己。
举个例子:上银行办理业务,取号,按照号码来排队办理。
非公平锁:
1.2 Leader Latch
基本原理:
LeaderLatch方式就是以一种抢占方式来决定选主,是一种非公平的领导选举,谁抢到谁就是Leader。
原理如图所示:这三个客户端同时向zookeeper集群注册临时无序(Ephemeral Non-sequence)类型的节点,路径都为/zkroot/leader。由于Zookeeper临时无序节点的特性,这三个客户端只会有一个创建成功,其它节点均创建失败。此时,创建成功的客户端即成功竞选为 Leader 。其它客户端此时匀为 Follower,并且还会向/zkroot/leader注册一个 Watch ,一旦 Leader 放弃领导权,所有的 Follower 会收到通知,所有的 Follower 可以再次发起新一轮的领导选举。
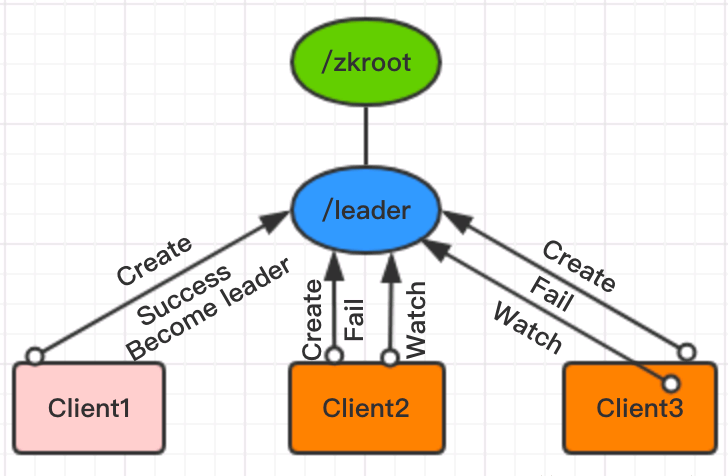
缺点:一旦 Leader 放弃领导权,Zookeeper 需要同时通知上所有 Follower,大数据量下负载较大。
Curator代码:
相关的类LeaderLatch
构造LeaderLatch ,构造方法如下:
public LeaderLatch(CuratorFramework client, String latchPath);public LeaderLatch(CuratorFramework client, String latchPath, String id);
启动
通过start()方法启动之后,再等待几秒钟后,Curator会自动从中选举出Leader。
public void start() throws Exception;
可以调用实例的hasLeadership()判断该实例是否为leader。
public boolean hasLeadership();
尝试获取leadership
调用await()方法会使线程一直阻塞到获得leadership为止。
public void await() throws InterruptedException, EOFException;public boolean await(long timeout, TimeUnit unit) throws InterruptedException;
释放leadership
只能通过close()释放leadership, 只有leader将leadership释放时,其他的候选者才有机会被选为leader
public void close() throws IOException;public synchronized void close(CloseMode closeMode) throws IOException;
以上是LeaderLatch 基本用法,完整Demo请看: https://gitee.com/lwqlwq/zookeeper-learning
1.3 Leader Election
基本原理:
LeaderElection选举策略不同之处在于每个实例都能公平获取领导权,而且当获取领导权的实例在释放领导权之后,该实例还有机会再次获取领导权。通过LeaderSelectorListener可以对领导权进行控制, 在适当的时候释放领导权,这样每个节点都有可能获得领导权。
原理如图所示:LeaderElection选举中,各客户端均创建/zkroot/leader节点,且其类型为(临时有序 Ephemeral Sequence)。由于是临时有序节点特性,图中三个客户端均创建成功,只是序号不一样。此时,每个客户端都会判断自己创建成功的节点的序号是不是当前最小的。如果是,则该客户端为 Leader,否则即为 Follower。每个 Follower 并非都 Watch 由 Leader 创建出来的节点,而是 Watch 序号刚好比自己序号小的节点,一旦Leader弃权或者宕机,各节点会判断自己的序号是不是当前最小的序号,是则成为Leader。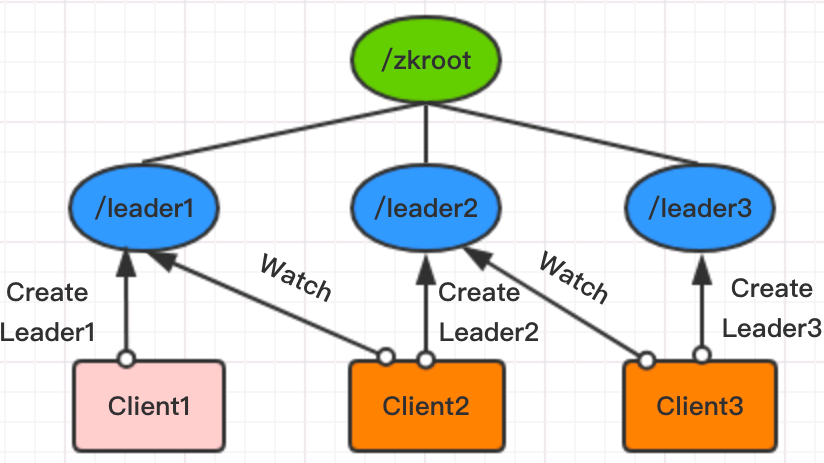
缺点:延迟相对非公平模式要高,因为它必须等待特定节点得到通知才能选出新的 Leader。
Curator代码:
相关的类LeaderSelectorLeaderSelectorListenerLeaderSelectorListenerAdapterCancelLeadershipException
使用方法 创建 LeaderSelector
public LeaderSelector(CuratorFramework client, String leaderPath, LeaderSelectorListener listener);public LeaderSelector(CuratorFramework client, String leaderPath, ExecutorService executorService, LeaderSelectorListener listener);public LeaderSelector(CuratorFramework client, String leaderPath, CloseableExecutorService executorService, LeaderSelectorListener listener);
启动leaderSelector.start();
一旦启动,如果获取了leadership的话,takeLeadership()会被调用,只有当leader释放了leadership的时候,takeLeadership()才会返回。
释放
调用close()释放 leadershipleaderSelector.close();
以上是Election 基本用法,完整Demo请看: https://gitee.com/lwqlwq/zookeeper-learning
2、分布式锁
Zookeeper分布式锁的原理,和选举leader的原理实际上类似,都是利用了Zookeeper Zode节点的特性。
Curactor实现的锁有五种:
2.1 Shared Reentrant Lockf分布式可重入锁:
全局同步的可重入分布式锁,任何时刻不会有两个客户端同时持有该锁。Reentrant和JDK的ReentrantLock类似, 意味着同一个客户端在拥有锁的同时,可以多次获取,不会被阻塞。
2.2 Shared Lock 分布式非可重入锁:
与Shared Reentrant Lock类似,但是不能重入。
2.3 Shared Reentrant Read Write Lock可重入读写锁
读写锁负责管理一对相关的锁,一个负责读操作,一个负责写操作。读锁在没有写锁没被使用时能够被多个读进行使用。但是写锁只能被一个进得持有。 只有当写锁释放时,读锁才能被持有,一个拥有写锁的线程可重入读锁,但是读锁却不能进入写锁。 这也意味着写锁可以降级成读锁, 比如请求写锁 —>读锁 —->释放写锁。 从读锁升级成写锁是不行的。可重入读写锁是“公平的”,每个用户将按请求的顺序获取锁。
2.4 Shared Semaphore共享信号量
一个计数的信号量类似JDK的Semaphore,所有使用相同锁定路径的jvm中所有进程都将实现进程间有限的租约。此外,这个信号量大多是“公平的” - 每个用户将按照要求的顺序获得租约。
有两种方式决定信号号的最大租约数。一种是由用户指定的路径来决定最大租约数,一种是通过SharedCountReader来决定。
如果未使用SharedCountReader,则不会进行内部检查比如A表现为有10个租约,进程B表现为有20个。因此,请确保所有进程中的所有实例都使用相同的numberOfLeases值。
acuquire()方法返回的是Lease对象,客户端在使用完后必须要关闭该lease对象(一般在finally中进行关闭),否则该对象会丢失。如果进程session丢失(如崩溃),该客户端拥有的所有lease会被自动关闭,此时其他端能够使用这些lease。
2.5 Multi Shared Lock 多共享锁
多个锁作为一个锁,可以同时在多个资源上加锁。一个维护多个锁对象的容器。当调用 acquire()时,获取容器中所有的锁对象,请求失败时,释放所有锁对象。同样调用release()也会释放所有的锁。
以上是Curactor实现的五种锁,具体代码实现可参考官网,这里不再赘述。
3、命名服务/注册中心
命名服务,主要的应用场景在于rpc服务,比如dubbo等框架,可以将相应的服务注册在zk上,这样服务调用就可以根据其所命名的服务来提供对外服务等,这是最常用的功能,不再赘述。
4、分布式配置中心
利用持久节点+事件通知实现。这个功能用的较少,毕竟Zookeeper不是专门干这个的。

若有收获,就点个赞吧
0 人点赞
