说实在的,我对于多线程的理解还停留在理论上,就是操作系统那块的理论,三态模式和五态模式;甚至还把三态和五态说混了。
现在,首先来回顾一下线程的三种状态:就绪、执行、阻塞;其中,
(1)当一个线程处于执行状态,时间片用完以后,就变成了就绪状态;
(2)当一个线程处于执行状态,遇到I/O请求后,就变成了阻塞状态;
(3)当一个线程处于阻塞状态,I/O完成以后,就变成了就绪状态;
(4)当一个线程处于就绪状态,当进程被调用后,就成了执行状态;
这就是三态模式;
而在Java中,线程的生命周期,大概可以分为5中状态,分别是新建(new)、可运行(runnable)、运行(running)、阻塞(blocked)和死亡(dead)。可以发现的是,Java的五态模式,不过是在原来三态模式的基础上,增加了初始和销毁状态;然后把就绪状态改了个名字,改成了可运行状态。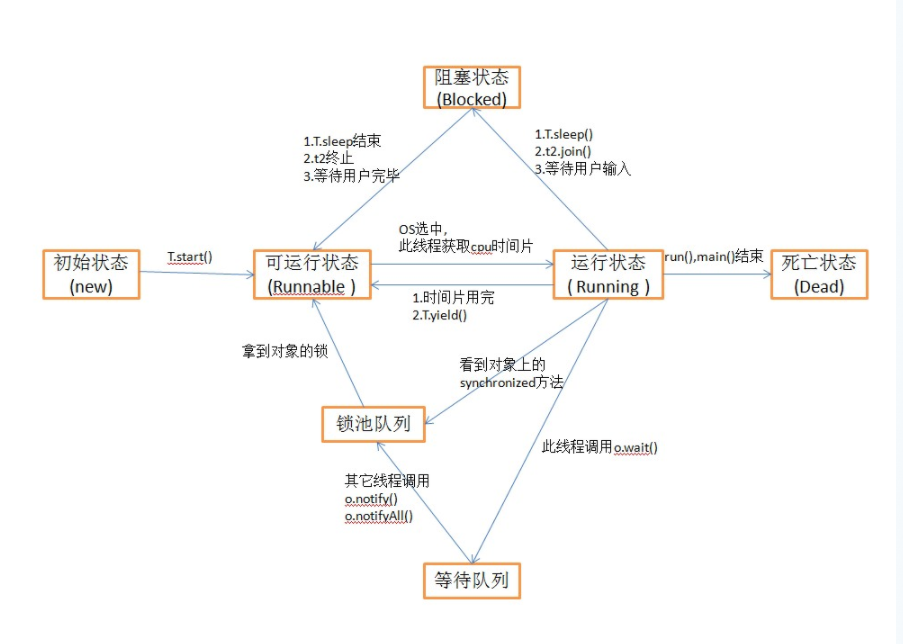
以上就是线程的基本理论,理论学完了,但是代码还是一行都不会写。
其中多线程的代码,勉强还是会写几行的,不就是一个类继承thread类或者实现runnable接口吗?在重写run方法,通过new thread() 调用,用start()方法启动线程,就完成了多线程的调用。但最大的问题是,这种代码如果用在项目里面,可能就是灾难。所以就推荐用线程池,但是线程池是什么?和线程有什么区别?
(1)线程和线程池,谁更好,那自然不用说,但我们用代码来证明一下。
/*** @description 测试一下多线程和线程池的执行时间* @author: huangyeqin* @create : 2020/12/17 22:01*/public class TestThread {public static void main(String[] args) throws InterruptedException {Long start = System.currentTimeMillis();List<Integer> list = new ArrayList<>();final Random random = new Random();for (int i = 0; i < 100000; i++) {Thread thread = new Thread(){@Overridepublic void run() {list.add(random.nextInt());}};thread.start();thread.join();}System.out.println("运行时间:"+(System.currentTimeMillis() - start));System.out.println("数组大小:"+list.size());}}
就是new十万个线程,然后每个线程都在list中加入一个随机数,看执行时间是多少,这段代码还是非常简单的 。执行结果如下:运行时间:16104数组大小:100000
如果用线程池的方式
/*** @description 测试线程池的执行时间* @author: huangyeqin* @create : 2020/12/17 22:04*/public class TestThreadPool {public static void main(String[] args) {Long start = System.currentTimeMillis();List<Integer> list = new ArrayList<>();final Random random = new Random();ExecutorService service = Executors.newSingleThreadExecutor();for (int i = 0; i < 100000; i++) {service.execute(new Runnable() {@Overridepublic void run() {list.add(random.nextInt());}});}// 这两行关键代码千万不能少,少了线程池就不会关闭,而且执行结果不对service.shutdown();service.awaitTermination(1, TimeUnit.DAYS);System.out.println("运行时间:"+(System.currentTimeMillis() - start));System.out.println("数组大小:"+list.size());}}
其实大部分代码都没有变,就是把new一个thread改成了ExecutorService service = Executors.newSingleThreadExecutor(); 而有意思的是,因为我的idea安装了阿里开发规约,所以我的Executors被阿里的规约报错了,提示我说手动创建线程池,效果会更好,但不管了,我不会手动创建。还是先来看看执行结果吧!运行时间:24 数组大小:23623 这结果,有问题啊…那么问题在哪里呢?一看,从网上抄的代码么没抄全,少了两行;补上以后,执行结果为 运行时间:72 数组大小:100000
线程池的关键代码,就是下面图片上的一个接口和三个实现类;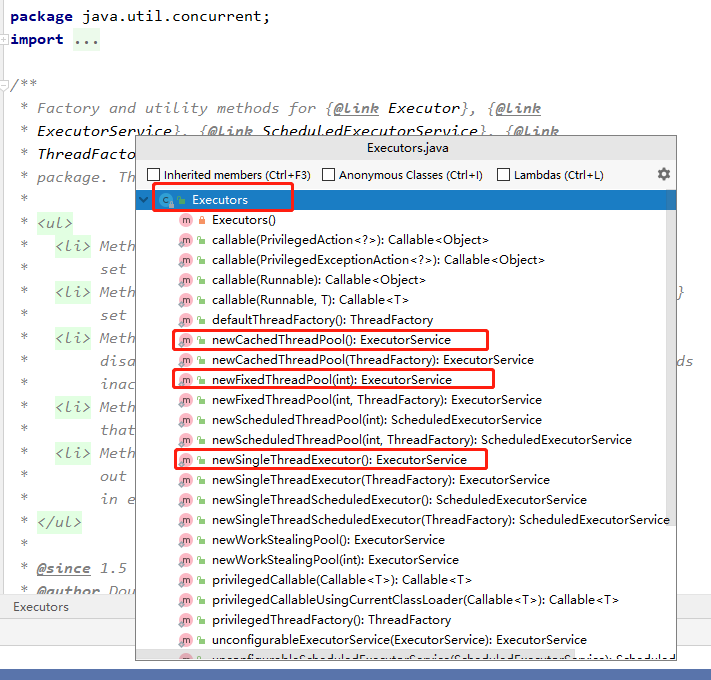
从测试结果上来看,newCachedThreadPool 的执行速度是最快的,newSingleThreadExecutor是最慢的;
从这里开始,我们就要学习源码了,要学会从源码中寻找答案。我发现一件事,就是这三个方法,都是调用了同一个方法,只不过是参数不同而已。
//最快public static ExecutorService newCachedThreadPool() {return new ThreadPoolExecutor(0,Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());}// 次快public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads,nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());}// 最慢public static ExecutorService newSingleThreadExecutor() {return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1,1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));}
那么,想要了解这几个方法的差别,首先要了解这几个参数有什么差别?
(1)corePoolSize :核心线程数。线程池中会维护一个最小的线程数量,即使这些线程处理空闲状态,他们也不会 被销毁,除非设置了allowCoreThreadTimeOut
(2)maximumPoolSize :线程池最大线程数量 一个任务被提交到线程池后,首先会缓存到工作队列(后面会介绍)中,如果工作队列满了,则会创建一个新线程,然后从工作队列中的取出一个任务交由新线程来处理,而将刚提交的任务放入工作队列。线程池不会无限制的去创建新线程,它会有一个最大线程数量的限制,这个数量即由maximunPoolSize来指定。 应该是一个任务被提交到线程池以后,首先会找有没有空闲存活线程,如果有则直接执行,如果没有则会缓存到工作队列中,如果工作队列满了,才会创建一个新线程,然后从工作队列的头部取出一个任务交由新线程来处理,而将刚提交的任务放入工作队列尾部。线程池不会无限制的去创建新线程,它会有一个最大线程数量的限制,这个数量即由maximunPoolSize的数量减去corePoolSize的数量来确定,最多能达到maximunPoolSize即最大线程池线程数量。
(3)keepAliveTime :空闲线程存活时间。一个线程如果处于空闲状态,并且当前的线程数量大于corePoolSize,那么在指定时间后,这个空闲线程会被销毁,这里的指定时间由keepAliveTime来设定
(4)unit :空闲线程存活时间单位
(5)workQueue 新任务被提交后,会先进入到此工作队列中,任务调度时再从队列中取出任务。jdk中提供了四种工作队列:
①ArrayBlockingQueue
基于数组的有界阻塞队列,按FIFO排序。新任务进来后,会放到该队列的队尾,有界的数组可以防止资源耗尽问题。当线程池中线程数量达到corePoolSize后,再有新任务进来,则会将任务放入该队列的队尾,等待被调度。如果队列已经是满的,则创建一个新线程,如果线程数量已经达到maxPoolSize,则会执行拒绝策略。
②LinkedBlockingQuene
基于链表的无界阻塞队列(其实最大容量为Interger.MAX),按照FIFO排序。由于该队列的近似无界性,当线程池中线程数量达到corePoolSize后,再有新任务进来,会一直存入该队列,而不会去创建新线程直到maxPoolSize,因此使用该工作队列时,参数maxPoolSize其实是不起作用的。
③SynchronousQuene
一个不缓存任务的阻塞队列,生产者放入一个任务必须等到消费者取出这个任务。也就是说新任务进来时,不会缓存,而是直接被调度执行该任务,如果没有可用线程,则创建新线程,如果线程数量达到maxPoolSize,则执行拒绝策略。
④PriorityBlockingQueue
具有优先级的无界阻塞队列,优先级通过参数Comparator实现。
(6)handler 拒绝策略。当工作队列中的任务已到达最大限制,并且线程池中的线程数量也达到最大限制,这时如果有新任务提交进来,该如何处理呢。这里的拒绝策略,就是解决这个问题的,jdk中提供了4中拒绝策略:
①CallerRunsPolicy
该策略下,在调用者线程中直接执行被拒绝任务的run方法,除非线程池已经shutdown,则直接抛弃任务。
②AbortPolicy
该策略下,直接丢弃任务,并抛出RejectedExecutionException异常。
③DiscardPolicy
该策略下,直接丢弃任务,什么都不做。
④DiscardOldestPolicy
该策略下,抛弃进入队列最早的那个任务,然后尝试把这次拒绝的任务放入队列
————-《以上说法来自于百度》
那么从上面的解释可以看出,为什么阿里不推荐使用默认的线程池了,而是要我们自己去实现线程池。
newCachedThreadPool() 这种方法是很快,但会出现CPU占用率太高的问题,而CPU是计算机中最宝贵的资源,所以一般是不推荐这种办法。
剩下的两种,在任务量过大的时候,会把任务都放到阻塞队列中,特别是像LinkedBlockingQuene 是链表队列,可以存放非常多的数据,而这些数据会导致内存溢出。

若有收获,就点个赞吧
0 人点赞
